导 论:原始的知识蒸馏都需要原域数据,不幸的是,这种假设在许多情况下违反了实际设置,因为由于隐私或版权原因,原始培训数据甚至数据域通常无法访问。本文中作者先引入了域外知识提取(OOD-KD)的概念,它允许我们仅使用成本非常低且易于获得的OOD数据进行知识提取。由于不可知领域的差距,OOD-KD本质上是一项极具挑战性的任务。为此,作者介绍了一种简便但出人意料的有效方法,称为MosaicKD。MosaicKD背后的关键在于,来自不同领域的样本共享共同的局部模式,尽管它们的全局语义可能会有显著差异。反过来,这些共享的局部模式可以像马赛克拼接一样重新组合,以近似域内数据并进一步缓解域差异。在MosaicKD中,有四个网络模型分别是已经训练好的教师模型、生成器、鉴别器和学生网络以对抗的方式进行集体训练,部分在预先培训过的教师的指导下进行。
代码地址:https://github.com/zju-vipa/MosaicKD
论文地址:https://arxiv.org/abs/2110.15094
原文作者:Gongfan Fang;Yifan Bao;Jie Song;Xinchao Wang;Donglin Xie; Chengchao Shen;Mingli Song;
发表于:2021年NeurIPS
作者的动机:我们的动机源于这样一个事实,即尽管来自不同领域的数据呈现出不同的全局分布,但它们的局部分布(如图像中的补丁)可能彼此相似。这一观察结果进一步启发我们利用OOD和目标域数据共享的本地模式来解决OOD-KD中的域转移问题。因此,MosaicKD的核心思想是合成域内数据,其中的局部模式模仿真实世界的OOD数据,而由局部模式组合而成的全局分布预计会愚弄预先培训过的教师。如图1所示,共享的本地模式从OOD数据中提取并重新组装到域内数据中。从直觉上看,这一过程类似于图2马赛克瓷砖,在马赛克瓷砖中使用镶嵌线来构成整个艺术作品。
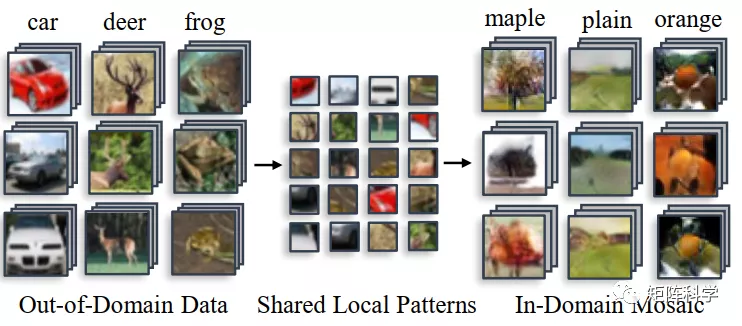
图1 自然图像具有共同的局部模式。在MosaicKD中,这些局部模式首先从OOD数据中分离出来,然后组合起来合成域内数据。

图2 马赛克瓷砖通过镶嵌方式不同构成不同的样式
框架结构:整个框架由四个部分组成,分别是生成器、判别器、教师模型、学生模型。教师模型是预训练好的,权重参数固定不变;学生模型是需要学习教师的能力,在训练中不断更新。生成器与先前GANs中的生成器一样,生成器将随机噪声向量作为输入,并在其他三个参与者的监督下学习到如何生成域内的生成样本。另一方面,鉴别器学习区分从真实世界的OOD数据样本和合成样本中提取的局部面片。整个合成图像被输入到预培训教师和待培训学生,教师根据这些图像为数据合成提供类别知识,学生模仿教师的行为,从而执行KD。这四个模型以对抗的方式相互加强,共同完成学生训练。
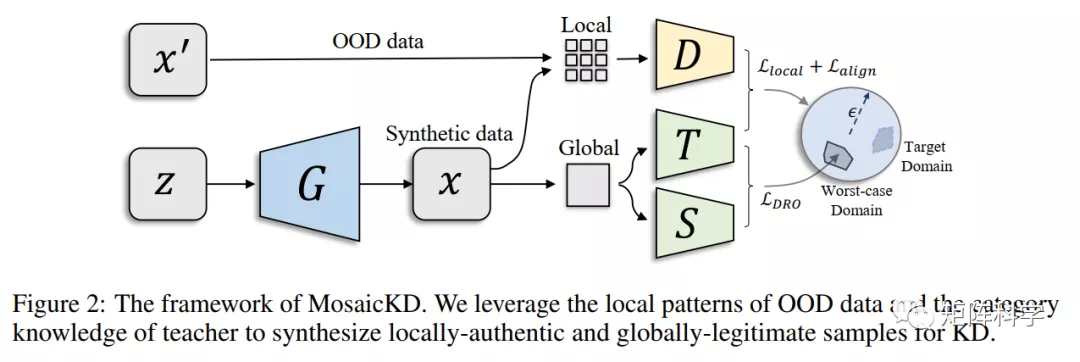
小总结:作者目的是想利用已有的数据集(域外数据集,简称OOD)来为缺失源域的教师模型做蒸馏,其实相比于以前的DFKD、DAFL等彻底Data-Free的方法,多了OOD数据。相当于把问题简化了一点,多了一些先验知识。这才是本文的核心,然后作者提出说图片的局部(【patch】补丁)都是共享特征,只要把OOD剥离成局部补丁就能合成域内数据。也就是说剥离裁剪的过程相当于连接OOD数据与ID源域数据的桥梁?如图1所示。
问题定义: 所以到目前为止,总的一个核心就是我们现在拥有已经训练好了的Teacher模型,但是我们用不了常规的数据蒸馏来教会一个小型Student网络,因为我们没有训练Teacher的源域。所以我们有的只是另外的一个OOD数据集,其分布与源域有一定的差距。
下文解读:下文的联合分布Px*y指的是样本x被Teacher预测为y的概率。(1)式是常规的知识蒸馏优化公式,如果直接用OOD来做Teacher的数据蒸馏则结果会坏掉,因为在OOD-KD中,由于OOD数据和原始训练数据之间的领域差异,一些重要的模式可能会丢失,并且关于这些模式的相应知识可能无法从教师适当地转移给学生。所以作者针对这个问题提出了马赛克知识蒸馏(Mosaick-KD)。

提出的方法: 接下来的公式有点多,需要具备GAN、DAFL等论文的阅读基础。在缺乏原始训练数据X的情况下,由于数据域的分歧,直接最小化OOD集上的损失将是有问题的。所以需要使用到生成器G合成有用的分布供Student模型学习。而本文的MosaicKD是根据分布式鲁棒优化(DRO)框架提出的,它被广泛用于解决域偏移问题。DRO基本框架如下所示:
这里的是定义的衡量源域与域外数据分布的距离,是KL散度,是一个生成样本,是一个输入到生成器G的随机向量。是预训练的Teacher模型,是Student模型。超参数ε指定以为中心的球空间的半径。根据这一定义,DRO框架旨在从搜索空间中找到最坏情况分布,从而为搜索空间所涵盖的其他分布的经验风险建立一个上界。原始训练数据的目标域可能不被搜索空间覆盖,也不受DRO框架的限制。解决此问题的方法是使用足够大的半径ε。不幸的是,这只会导致难以处理的搜索空间,充斥着毫无意义的分布。
如上所述,基于OOD数据的搜索空间不足以建立可靠的优化上限。针对这一问题,MosaicKD提出了一种基于局部面片构建搜索空间的新方法。我们的动机源于这样一个事实,即自然图像的模式通常是分层组织的,其中高级模式是由低级模式组合而成的。虽然原始训练数据和OOD数据的域是不同的,但它们的局部模式可能仍然彼此相似。例如,“毛皮”的图案可以由来自不同领域的不同动物物种共享。每个图像都是由局部补丁组装而成的,作者提出了一种分解组装策略来重新组织共享的局部补丁,并合成域内数据进行训练。
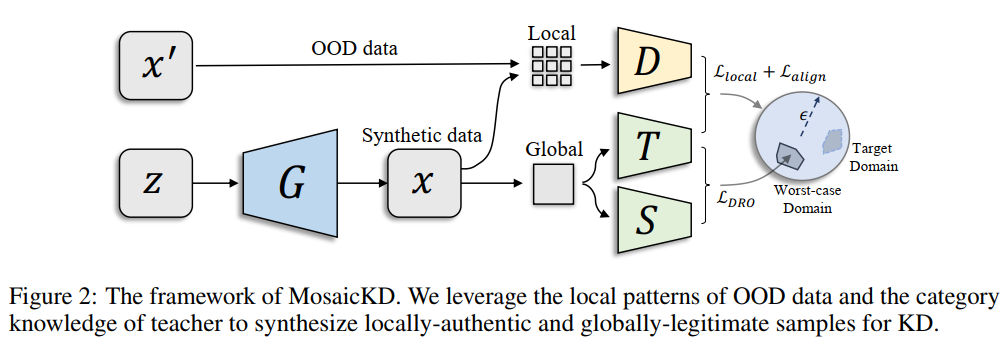
Patch Learning: MosaicKD的第一步就是抽取OOD域外数据局部特征(将OOD数据进行裁剪)并且评价生成器生成图片的补丁的分布。一张图片裁剪的越碎(补丁越多)即局部信息越便于共享,极端情况就是每个像素点为一个补丁,则每个像素代表的是颜色,这是通用的特征。另一个极端情况是每个图片本身作为一个补丁,这样就是全局特征难以共享。这里的生成器G是输入一个随机向量,输出一张分布上接近源域的图片(而不是一些补丁),判别器D输出的是OOD的补丁与生成器G产生的图片的补丁。所以G合成一张图片后,输入到D之前还需要裁剪操作。(3)式就是生成对抗网络GAN的优化公式,这里唯一的区别就是进行了裁剪操作。那我们试想如果不进行裁剪,那么G学到的将是OOD的分布,所以将会生成类似OOD的图片。而这里将判别器要区分的并不是图片而是补丁,这里的目的是要让G生成的图片的补丁要类似于OOD的补丁,因为补丁是可以共享的,简而言之就是源域其实也是由这些补丁组装而成,所以先生成具有相似补丁的图片,而后进行针对组装成类似源域的数据。如上所述,全局模式可以从局部模式组装而来,MosaicKD通过标签空间对齐将这些补丁组装成域内数据。

Label Space Aligning: 而这就是第二步了,刚刚进行的是第一步生成具有共享性质的补丁的图片,那么哪些补丁组合起来更接近源域呢?这就是第二步要解决的问题。因为等式(3)中没有引入补丁间的限制。生成器可能只生成具有无意义全局语义的图像,尽管它们的局部模式是可信的,但是组合起来既不近似OOD的域也不近似源域。所以要想近似与源域那就必须要有源域的先验知识,而Teacher中就有源域的知识,Teacher对源域的置信度高,对其他域的预测置信度低。一种简单的方法是最大化教师预测的置信度,即最小化熵项。然而之前的工作表明,这种简单的概率最大化可能只会导致一些“垃圾样本”,而没有太多有用的视觉信息用于训练Student。为了解决这个问题,作者提出了一个正则化的目标来对齐标签空间,公式如下:
目的就是要生成器G生成的图片被判别器D高置信度预测为真,也就是说要愚弄过判别器,这里与3式一样。最重要的就是最小化后面的熵,因为如果都是差不多的概率(更加平滑)则熵很大,这里就是要让Teacher高置信度预测为某类,所以要让熵小则更加尖锐。所以到这里就可以用 来更新生成器G与判别器D。
DRO in MosaicKD: 前面已经训练G与D了,那么到这步就该训练Student了。直接看公式(5),最小化损失训练S,就是要让Student学习Teacher对生成样本的预测,即Student与Teacher的预测分布对齐,其实就是知识蒸馏。这里最主要看下最大化损失更新生成器G,作者的目的其实是想让生成器G生成前面Student没有学过的样本,其实Teacher是见怪不怪的因为G生成的样本都是在这个域内,而Student没有见过所以会与Teacher的预测不一致导致损失变大。这其实是一个搜索过程,G已经生成的样本域空间将不会再重复生成,而是继续搜索这个域的其他部位。所以到这一步不仅仅更新了Student模型,还微微改变了G向者S未见过的空间生成样本。而是由公式(3)、(4)推导出来的,在(3)式中优化生成器G等价于最小化OOD域数据集与G生成的数据集的补丁之间的JS散度,正则项迫使生成器G利用OOD数据的局部模式进行数据合成。所以最后最大化损失更新G的时候,将会最小化,让G的补丁近似OOD的补丁。

算法:

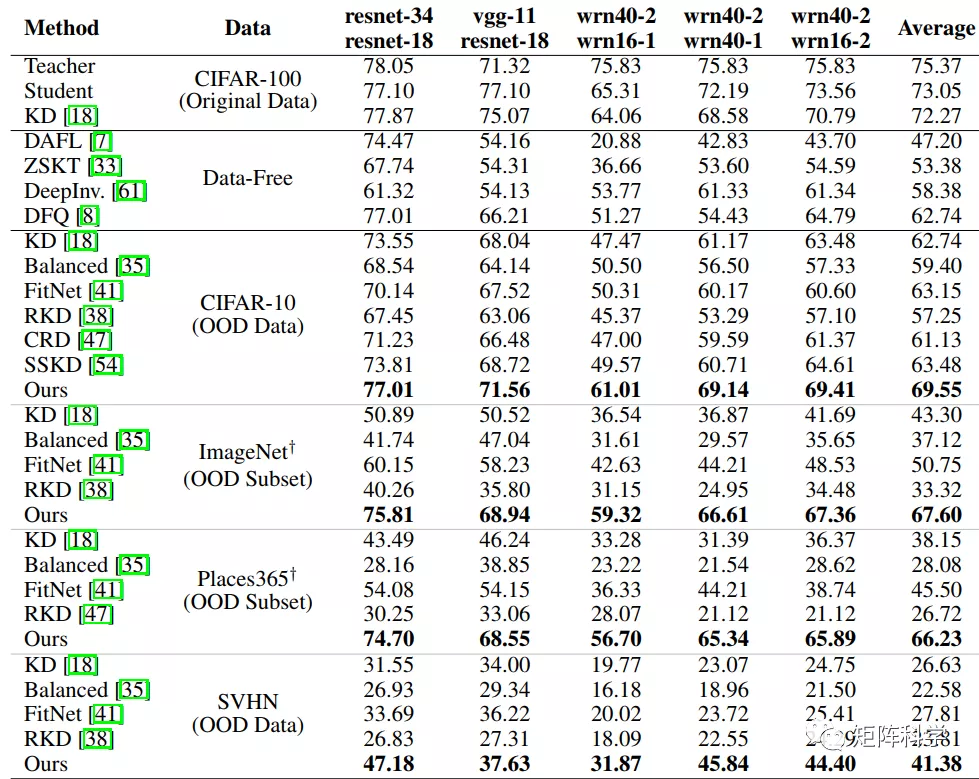
实验结果: