一、数据预处理
实验数据来自genki4k

提取含有完整人脸的图片
def init_file():
num = 0
bar = tqdm(os.listdir(read_path))
for file_name in bar:
bar.desc = "预处理图片: "
# a图片的全路径
img_path = (read_path + "/" + file_name)
# 读入的图片的路径中含非英文
img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), cv2.IMREAD_UNCHANGED)
# 获取图片的宽高
img_shape = img.shape
img_height = img_shape[0]
img_width = img_shape[1]
# 用来存储生成的单张人脸的路径
# dlib检测
dets = detector(img, 1)
for k, d in enumerate(dets):
if len(dets) > 1:
continue
num += 1
# 计算矩形大小
# (x,y), (宽度width, 高度height)
# pos_start = tuple([d.left(), d.top()])
# pos_end = tuple([d.right(), d.bottom()])
# 计算矩形框大小
height = d.bottom() - d.top()
width = d.right() - d.left()
# 根据人脸大小生成空的图像
img_blank = np.zeros((height, width, 3), np.uint8)
for i in range(height):
if d.top() + i >= img_height: # 防止越界
continue
for j in range(width):
if d.left() + j >= img_width: # 防止越界
continue
img_blank[i][j] = img[d.top() + i][d.left() + j]
img_blank = cv2.resize(img_blank, (200, 200), interpolation=cv2.INTER_CUBIC)
# 保存图片
cv2.imencode('.jpg', img_blank)[1].tofile(save_path + "/" + "file" + str(num) + ".jpg")
logging.info("一共", len(os.listdir(read_path)), "个样本")
logging.info("有效样本", num)
二、训练模型
创建模型
# 创建网络
def create_model():
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
return model
训练模型
# 训练模型
def train_model(model):
# 归一化处理
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True, )
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=60,
epochs=12,
validation_data=validation_generator,
validation_steps=30)
# 保存模型
save_path = "../output/model"
if not os.path.exists(save_path):
os.makedirs(save_path)
model.save(save_path + "/smileDetect.h5")
return history
训练结果
准确率
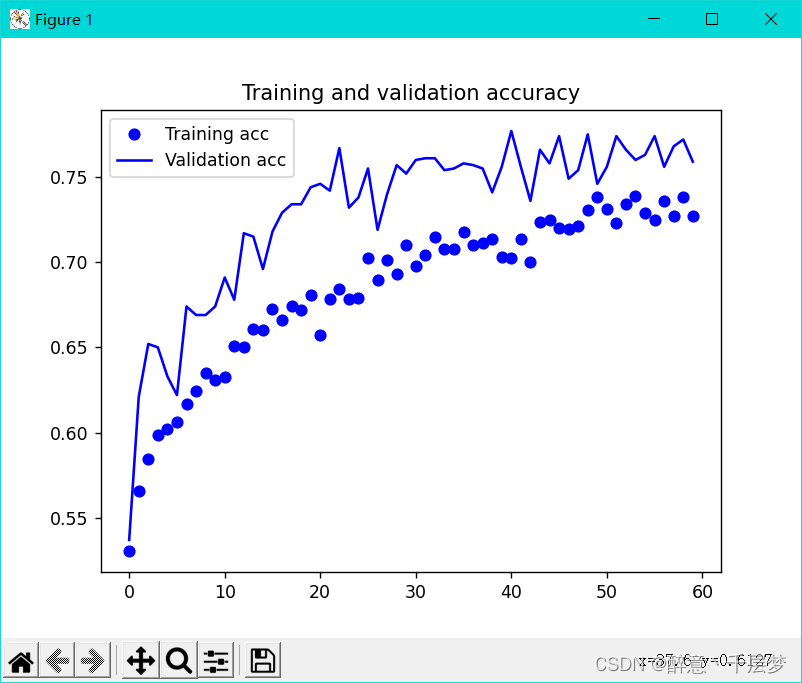
丢失率

训练过程
三、预测
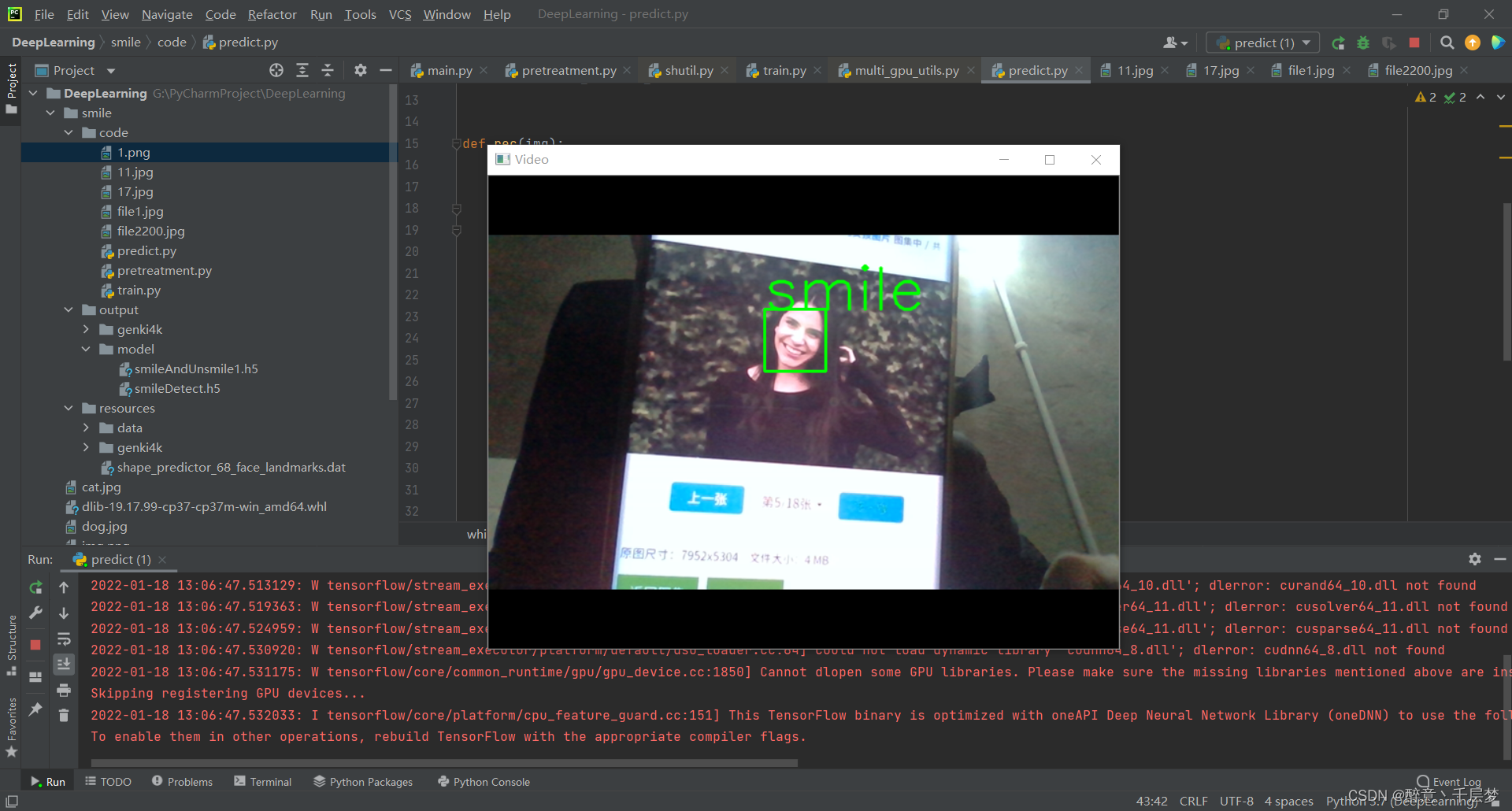
通过读取摄像头内容进行预测
def rec(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1)
if dets is not None:
for face in dets:
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
img1 = cv2.resize(img[top:bottom, left:right], dsize=(150, 150))
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img1 = np.array(img1) / 255.
img_tensor = img1.reshape(-1, 150, 150, 3)
prediction = model.predict(img_tensor)
if prediction[0][0] > 0.5:
result = 'unsmile'
else:
result = 'smile'
cv2.putText(img, result, (left, top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
效果

四、源代码
pretreatment.py
import dlib # 人脸识别的库dlib
import numpy as np # 数据处理的库numpy
import cv2 # 图像处理的库OpenCv
import os
import shutil
from tqdm import tqdm
import logging
# dlib预测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('../resources/shape_predictor_68_face_landmarks.dat')
# 原图片路径
read_path = "../resources/genki4k/files"
# 提取人脸存储路径
save_path = "../output/genki4k/files"
if not os.path.exists(save_path):
os.makedirs(save_path)
# 新的数据集
data_dir = '../resources/data'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
# 训练集
train_dir = data_dir + "/train"
if not os.path.exists(train_dir):
os.makedirs(train_dir)
# 验证集
validation_dir = os.path.join(data_dir, 'validation')
if not os.path.exists(validation_dir):
os.makedirs(validation_dir)
# 测试集
test_dir = os.path.join(data_dir, 'test')
if not os.path.exists(test_dir):
os.makedirs(test_dir)
# 初始化训练数据
def init_data(file_list):
# 如果不存在文件夹则新建
for file_path in file_list:
if not os.path.exists(file_path):
os.makedirs(file_path)
# 存在则清空里面所有数据
else:
for i in os.listdir(file_path):
path = os.path.join(file_path, i)
if os.path.isfile(path):
os.remove(path)
def init_file():
num = 0
bar = tqdm(os.listdir(read_path))
for file_name in bar:
bar.desc = "预处理图片: "
# a图片的全路径
img_path = (read_path + "/" + file_name)
# 读入的图片的路径中含非英文
img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), cv2.IMREAD_UNCHANGED)
# 获取图片的宽高
img_shape = img.shape
img_height = img_shape[0]
img_width = img_shape[1]
# 用来存储生成的单张人脸的路径
# dlib检测
dets = detector(img, 1)
for k, d in enumerate(dets):
if len(dets) > 1:
continue
num += 1
# 计算矩形大小
# (x,y), (宽度width, 高度height)
# pos_start = tuple([d.left(), d.top()])
# pos_end = tuple([d.right(), d.bottom()])
# 计算矩形框大小
height = d.bottom() - d.top()
width = d.right() - d.left()
# 根据人脸大小生成空的图像
img_blank = np.zeros((height, width, 3), np.uint8)
for i in range(height):
if d.top() + i >= img_height: # 防止越界
continue
for j in range(width):
if d.left() + j >= img_width: # 防止越界
continue
img_blank[i][j] = img[d.top() + i][d.left() + j]
img_blank = cv2.resize(img_blank, (200, 200), interpolation=cv2.INTER_CUBIC)
# 保存图片
cv2.imencode('.jpg', img_blank)[1].tofile(save_path + "/" + "file" + str(num) + ".jpg")
logging.info("一共", len(os.listdir(read_path)), "个样本")
logging.info("有效样本", num)
# 划分数据集
def divide_data(file_path, message, begin, end):
files = ['file{}.jpg'.format(i) for i in range(begin, end)]
bar = tqdm(files)
bar.desc = message
for file in bar:
src = os.path.join(save_path, file)
dst = os.path.join(file_path, file)
shutil.copyfile(src, dst)
if __name__ == "__main__":
init_file()
positive_train_dir = os.path.join(train_dir, 'smile')
negative_train_dir = os.path.join(train_dir, 'unSmile')
positive_validation_dir = os.path.join(validation_dir, 'smile')
negative_validation_dir = os.path.join(validation_dir, 'unSmile')
positive_test_dir = os.path.join(test_dir, 'smile')
negative_test_dir = os.path.join(test_dir, 'unSmile')
file_list = [positive_train_dir, positive_validation_dir, positive_test_dir,
negative_train_dir, negative_validation_dir, negative_test_dir]
init_data(file_list)
divide_data(positive_train_dir, "划分训练集正样本", 1, 1001)
divide_data(negative_train_dir, "划分训练集负样本", 2200, 3200)
divide_data(positive_validation_dir, "划分验证集正样本", 1000, 1500)
divide_data(negative_validation_dir, "划分验证集负样本", 3000, 3500)
divide_data(positive_test_dir, "划分测试集正样本", 1500, 2000)
divide_data(negative_test_dir, "划分测试集负样本", 2800, 3500)
train.py
import os
from keras import layers
from keras import models
from tensorflow import optimizers
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
train_dir = "../resources/data/train"
validation_dir = "../resources/data/validation"
# 创建网络
def create_model():
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
return model
# 训练模型
def train_model(model):
# 归一化处理
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True, )
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=60,
epochs=12,
validation_data=validation_generator,
validation_steps=30)
# 保存模型
save_path = "../output/model"
if not os.path.exists(save_path):
os.makedirs(save_path)
model.save(save_path + "/smileDetect.h5")
return history
# 展示训练结果
def show_results(history):
# 数据增强过后的训练集与验证集的精确度与损失度的图形
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 绘制结果
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
if __name__ == "__main__":
model = create_model()
history = train_model(model)
show_results(history)
predict.py
import os
from keras import layers
from keras import models
from tensorflow import optimizers
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
train_dir = "../resources/data/train"
validation_dir = "../resources/data/validation"
# 创建网络
# 检测视频或者摄像头中的人脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('../output/model/smileDetect.h5')
detector = dlib.get_frontal_face_detector()
video = cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1)
if dets is not None:
for face in dets:
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
img1 = cv2.resize(img[top:bottom, left:right], dsize=(150, 150))
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img1 = np.array(img1) / 255.
img_tensor = img1.reshape(-1, 150, 150, 3)
prediction = model.predict(img_tensor)
if prediction[0][0] > 0.5:
result = 'unsmile'
else:
result = 'smile'
cv2.putText(img, result, (left, top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()