�����������ѧϰ�ʼǡ��� 2 �� �ع���������Ԫģ��(DL�ʼ�����ϵ��)
https://fanfansann.blog.csdn.net/
https://github.com/fanfansann/fanfan-deep-learning-note
����:����
version 1.0 ?2022-1-20
?
����:
1)�����������ѧϰ�ʼǡ�������ѧ������ѧϰ��صĽ̲ġ��γ̡����ġ���Ŀʵս������֮��,�����ܽ�����������ѧϰ�ʼǡ�д���¾�ͼһ��,����ܿ��ÿ���,��ѧ��Щ��֪ʶ,���Ҷ��Ծ��Ѿ��㹻�� ^q^ ��
2)�����ʱ�䡢������ˮƽ����,���IJ������Ҹ�����ȫԭ��,���²������������Ի������ϵĸ�����Դ,�������ݱ�ע��ÿ��ĩ�IJο�����֮�С�
3)���Ľ���ѧ������,�����á�����ÿһ���־���IJο����ϲ�û����ϸ��Ӧ�����ij���ֲ�С���ַ��˴�ҵ�����,��������,����ϵ����ɾ��,�dz���л��λΪ֪ʶ���������Ĺ���!
4)���˲���ѧdz,�����ܽ��ʱ���������,������λǰ������ָ��,лл��
5)�������Ҹ���( CSDN ���� ����������(����) , ֪������ ��������(ר��), Github ��fanfansann��(ȫ��Դ��) , �Ź��ں� ��������С�����š�(���� P D F ����))������������,�ҽ����������ĸ�ƽ̨,��������ѧϰʹ��,���κ���ҵ��;��
6)����ϣ���ܹ�������һ�����������ɰ���Ȥ��������ʵ�����ѧϰ�ʼ�,��������ֻ��֪ʶ�ļ�������
7)���ġ����������ѧϰ�ʼǡ�ȫ��������:�����������ѧϰ�ʼǡ�ǰ�ԡ�Ŀ¼��� https://fanfansann.blog.csdn.net/article/details/121702108
8)���ĵ�Github ��ַ:https://github.com/fanfansann/fanfan-deep-learning-note/ ���ӵĵ�һ�� ��Github��!���Ҹ� ? ??? Starred \boxed{? \,\,\,\text{Starred}} ?Starred? ��!лл!!o(��^��^��)o
9)���� version 1.0 ,���д���,���������������ɾ,������Ҷ��ָ�㡣���Ļ������ҵ�����ѧϰ���ϵؽ������Ƹ���,Github �е� P D F ��Ҳ�ᾡ��ÿ�½���һ�θ���,���Խ�������ղط����ӹ�ע,�Ա㾭�������ؿ�!
����Ŀ¼
���»���(���������תӴ):
���� 1 :ʲô�ǻع����?ʲô���ǻع�����?
���� 5 :ʲô����ʧ����?Ϊʲô��Ҫʹ����ʧ����?
���� 6 :�ع������г��õ���ʧ��������Щ?
���� 10 :�ݶ��½��㷨Ϊʲô�����Ż�Ŀ�꺯��?(ѡѧ)
���� 11 :ѵ����������α�������ֲ����Ž�?������배��?
���� 12 : Ȥζ����:��ʱ������û�취ֱ�Ӽ����ݶ�,���Գ��Թ����ݶȴ�С��?- ����ַ���ԳƵ�����(ѡѧ)
���� 13 :ʲô����С���˷�?���ʹ����С���˷�������Իع�����?
���� 14 :�����Ҷ���,��ô�ô���ʵ�ֲ������Ԫ����ģ����?
���� 15 :����ģ���Ѿ���ȫѧ����!������ɷ����Ե�ģ����ô����?
�����������ѧϰ�ʼǡ��� 2 �� �ع���������Ԫģ��
���� 1 :ʲô�ǻع����?ʲô���ǻع�����?
??�ع����(Regression Analysis)��һ��ͳ��ѧ�Ϸ������ݵķ���,Ŀ�������˽����������������Ƿ���ء���ط�����ǿ��,��������ѧģ���Ա�۲��ض������� Ԥ�� (prediction)�о��߸���Ȥ�ı���������Ȼ��ѧ������ѧ����,�ع龭��������ʾ ��������֮��Ĺ�ϵ ��
??�ڻ���ѧϰ�����еĴ��������ͨ������ Ԥ�� �йء� �����ǽ��лع����,��ҪԤ��һ��Ԥ��ֵ��������ʵ����Χ��ʱ,���dz�֮Ϊ �ع����� ��������������:Ԥ�ⷿ�� / ��Ʊ��Ԥ������ / �����ȡ����������е� Ԥ�� ���ǻع����⡣����һ�½���,���ǽ����� �������� �����������Ŀ����Ԥ����������һ������е���һ��,Ҳ��Ԥ��Ԥ��ֵ����ijһ��������ʵ������ķ�����
??ͳ��ѧ�еĻع��������һ���� ���Իع�(�����Իع顢���ع顢�������Իع�)�������Իع����������ʻع���ƫ�ع����Իع�(�Իع黬��ƽ��ģ�͡�����Իع黬��ƽ��ģ�͡������Իع�ģ��)��������Ҫ̽�����Իع�������Իع�,������������Ļع鷽��������һЩ�Ľ���,������ϸ���⡢����ʵ�ּ���Ӧ��,����������Ļ���ѧϰ�ʼǡ���
? ? ?\, ?���Իع�
??�ڻع�������,���ʹ������ģ��ȥ�ƽ���ʵģ��,��ô���ǰ���һ����������Իع�(Linear Regression),���Իع��ǻع������е�һ�־����ʵ�֡�
??���Իع���ڼ����ļ���:����,�����Ա��� x \mathbf{x} x ������� y y y ֮��Ĺ�ϵ�����Ե�,�� y y y ���Ա�ʾΪ x \mathbf{x} x ��Ԫ�صļ�Ȩ��,����ͨ�����������۲�ֵ��һЩ����;���,���Ǽ����κ��������Ƚ�����,��������ѭ��̬�ֲ� (NormalDistribution) N ( �� , �� 2 ) \mathcal{N}\left(\mu, \sigma^{2}\right) N(��,��2)��
??�����Իع�(simple linear regression),��ͳ��ѧ��ָֻ��һ�����ͱ��������Իع�ģ�͡��������Ե�һ����Ԥ��,�����ж�������֮����صķ���ͳ̶ȡ�
??���ع����(multiple regression analysis),Ҳ�ƶ�����ع�,�Ǽ����Իع��һ������Ӧ��,�����˽�һ������������������Ա����ĺ�����ϵ��
??�������Իع�(Log-linear model),�ǽ��Ա������������ȡ����ֵ֮���ٽ������Իع�,���Ը����Ա���������,�����Ƕ��������Իع�,Ҳ�����Ƕ������ع顣
? ? ?\, ?�����Իع�
??�����Իع�(non-linear regression),�ǻع麯������δ֪�ع�ϵ�����з����Խṹ�Ļع顣
? ? ?\, ?�������ʻع�
??�������ʻع�(Logistic Regression),�ֳ����ع�,��һ����������ģ��(Ӣ��:Logit model,��������ģ�͡�����ģ�͡���������ģ��)����ɢѡ��ģ��֮һ,���ڶ��ر�����������,�����ѧ������ͳ��ѧ���ٴ�����������ѧ����������ѧ���г�Ӫ����ͳ��ʵ֤�����ij��÷��������ڶ������ʻع�ĸ��ི��,���**�����������ѧϰ�ʼǡ� �� 3 �� ������������Ϣ�ۻ��� 3.2 ���ع�**��
? ? ?\, ?�Իع�ģ��
�Իع�ģ��(Autoregressive model),���ARģ��,��ͳ����һ�ִ���ʱ�����еķ���,��ͬһ�������� x {\displaystyle x} x ��֮ǰ����,�༴ x 1 {\displaystyle x_{1}} x1? �� x t ? 1 {\displaystyle x_{t-1}} xt?1? ��Ԥ�Ȿ�� x t {\displaystyle x_{t}} xt? �ı���,����������Ϊһ���Թ�ϵ����Ϊ���Ǵӻع�����е����Իع鷢չ����,ֻ�Dz��� x {\displaystyle x} x Ԥ�� y {\displaystyle y} y ,������ x {\displaystyle x} x Ԥ�� x {\displaystyle x} x (�Լ�);���Խ����Իع���
2.1 ���Իع�
??������ ���� 2 ���Ѿ��������ʲô�����Իع�,���Ǽ�������̽��,������ν�����Իع����⡣
2.1.1 ����ģ��
??����һ��ʵ��:��Ϊһ����־����,������ҪԤ��δ���ij��з���!����ϣ�����Ը��ݷ��ݵ�����ͷ��������㷿�ݵļ۸�Ϊ�˿���һ����Ԥ�ⷿ�۵�ģ��,����������Ҫ�ռ�һ����ʵ�����ݼ���������ݼ������˷��ݵ����ۼ۸�����ͷ��䡣�ڻ���ѧϰ��������,ͨ�������ݼ���֮Ϊ ѵ�����ݼ�(training data set)�� ѵ����(training set)���������ݼ��ڵ�ÿ������(���������һ�η��ݽ������Ӧ�ĸ�������)��Ϊ����(sample),�� ���ݵ�(data point)�� ��������(data instance)����������ҪԤ���Ŀ��(������Ȼ�Ƿ��ݵļ۸�)��֮Ϊ��ǩ(label)��Ŀ��(target)��Ԥ�������ݵ��Ա���(����ͷ���)��Ϊ����(feature)��Э����(covariate)��
??ͨ��,����ʹ�� n n n ���� m m m ����ʾ���ݼ��е���������������Ϊ i i i ������,�������ʾΪ x ( i ) = [ x 1 ( i ) , x 2 ( i ) ] T \boldsymbol {x}^{(i)} = [x_1^{(i)}, x_2^{(i)}]^{\mathrm{T}} x(i)=[x1(i)?,x2(i)?]T ,���Ӧ�ı�ǩ�� y ( i ) y^{(i)} y(i) ��
??�������Իع�����Լ���ָĿ��(���ݼ۸�)���Ա�ʾΪ����(����ͷ���)�ļ�Ȩ��,�������ʽ��:
p
r
i
c
e
=
w
a
r
e
a
?
a
r
e
a
+
w
a
g
e
?
a
g
e
+
b
.
(2.1)
\mathrm{price} =w_{\mathrm{area}} \cdot \mathrm{area} +w_{\mathrm{age}} \cdot \mathrm{age} + b.\tag{2.1}
price=warea??area+wage??age+b.(2.1)
ʽ�е� w a r e a w_{\mathrm{area}} warea??? �� w a g e w_{\mathrm{age}} wage??? ��ΪȨ��(weight), b b b?? ��Ϊƫ��(bias),���Ϊƫ����(offset)���ؾ�(intercept)��
??Ȩ�ؾ�����ÿ������������Ԥ��ֵ��Ӱ�졣ƫ����ָ������������ȡֵΪ 0 0 0 ʱ,Ԥ��ֵӦ��Ϊ���١����û��ƫ����,����ģ�͵ı����������ܵ����ơ� �ϸ���˵,��ʽ������������һ������任(affine transformation)������任���ص���ͨ����Ȩ�Ͷ������������Ա任(linear transformation),��ͨ��ƫ����������ƽ��(translation)��
??��������ͱ�Ϊ��:����һ�����ݼ�,���ǵ�Ŀ����Ѱ��ģ�͵�Ȩ�� w \boldsymbol w w? ��ƫ�� b b b? ,ʹ�ø���ģ��������Ԥ�����������������ʵ�۸������Ԥ��ֵ����������ͨ������ģ���ķ���任����,����任����ѡȨ�غ�ƫ��ȷ������Ȼ����ֻ��Ҫ�������ʵ�������ģ�Ͳ��� w , b \boldsymbol w,b w,b?,�Ϳ��Եõ�һ�����Դ���Ԥ�ⷿ�ݼ۸������ģ�͡�����ģ�ͱ��������������Ԫģ��ʮ���Ǻ�,���ǿ��Ǵ���Ԫģ�͵ĽǶȳ��������������⡣
2.2 ��Ԫģ��
2.2.1 ��Ԫ
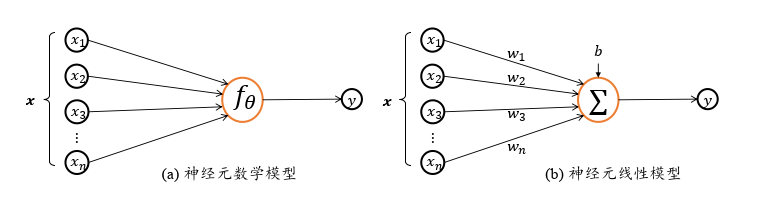
??��Ԫ(Neuron),����Ԫϸ��(Nerve Cell),����ϵͳ������Ľṹ���ܵ�λ����ͼ 2.1 ��ʾ,���͵�������Ԫ�ṹ��Ϊϸ�����ͻ�����֡������˴����а�����Լ 1000 �ڸ���Ԫ,ÿ����Ԫͨ����ͻ��ȡ�����ź�,ͨ����ͻ��������ź�,��Ԫ֮������ӹ����˾��������,�Ӷ��γ������Եĸ�֪����ʶ������

??
??����Ԫ��,��ͻ�н��յ�����������Ԫ������Ĥ�Ȼ�������������Ϣ x i x_i xi??? ������Ϣͨ��ͻ��Ȩ�� w i w_i wi??? ����Ȩ,��ȷ�������Ӱ��(��ͨ������ͻ��Ȩ�صĴ�С,ʹ w i w_i wi??? �� x i x_i xi?? ��� �� ���� �� ������������Ϣ)�� ���Զ��Դ�ļ�Ȩ�����Լ�Ȩ�� y = �� i x i w i + b \displaystyle y = \sum_i x_i w_i + b y=i��?xi?wi?+b?? ����ʽ�����ϸ������,Ȼ����Щ��Ϣ���͵���ͻ y y y?? �н�һ������,ͨ����ͨ�� �� ( y ) \sigma(y) ��(y)?? ����һЩ�����Դ�����֮��,��Ҫô����Ŀ�ĵ�(���缡��),Ҫôͨ����ͻ������һ����Ԫ(һ����һ������������)��
??���ǽ�������Ԫ (Neuron) ��ģ�ͳ���ɾ������ѧģ�͵õ� ��Ԫģ��:������Ԫ���������� 𝒙 = [ 𝑥 1 , ? ? 𝑥 2 , 𝑥 3 , �� , 𝑥 𝑛 ] T 𝒙 = [𝑥_1, ??𝑥_2, 𝑥_3, �� , 𝑥_𝑛]^\mathrm{ T } x=[x1?,??x2?,x3?,��,xn?]T,��������ӳ��: 𝑓 �� : 𝒙 �� 𝑦 𝑓_{\theta}: 𝒙 �� 𝑦 f��?:x��y ��õ���� 𝑦 𝑦 y ,���� �� {\theta} �� Ϊ���� 𝑓 𝑓 f �����IJ���������һ�ּ����,�����Ա任,�������������� 𝒙 , 𝒘 𝒙,𝒘 x,w,����ϣ�����Լ���õ�������Ԫģ�� y = �� i x i w i + b \displaystyle y = \sum_i x_i w_i + b y=i��?xi?wi?+b ��ֵ,���ǿ��Խ�����һ��������ת��֮�����: 𝑓 ( 𝒙 ) = 𝒘 T 𝒙 + 𝑏 𝑓(𝒙) = 𝒘^\mathrm{ T } 𝒙 + 𝑏 f(x)=wTx+b,չ��Ϊ������ʽ:
f ( x ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + ? + w n x n + b (2.2) f(x) = w_1x_1 + w_2x_2 + w_3x_3 + \cdots + w_nx_n + b\tag{2.2} f(x)=w1?x1?+w2?x2?+w3?x3?+?+wn?xn?+b(2.2)
��ʽ����ֱ�۵�չʾΪ��ͼ 2.2 ��ʾ:
??
??���� �� = 𝑤 1 , 𝑤 2 , 𝑤 3 , . . . , 𝑤 𝑛 , 𝑏 \theta= {𝑤_1, 𝑤_2, 𝑤_3, . . . , 𝑤_𝑛,𝑏} ��=w1?,w2?,w3?,...,wn?,b ȷ������Ԫ��״̬,ͨ���̶� 𝜃 ��������ȷ������Ԫ�Ĵ�����������Ԫ����ڵ��� 𝑛 = 1 𝑛 = 1 n=1 Ҳ��������ʱ,��Ԫ��ѧģ�Ϳɽ�һ����Ϊ:
y
=
w
x
+
b
(2.3)
y = wx + b\tag{2.3}
y=wx+b(2.3)
??��ʱ���ǿ��Ի��Ƴ���Ԫ�����
𝑦
𝑦
y? ������
𝑥
𝑥
x? �ı仯����,��ͼ 2.3 ��ʾ,���������ź�
𝑥
𝑥
x? ������,�����ƽ
𝑦
𝑦
y? Ҳ��֮��������,����
𝑤
𝑤
w?������������Ϊֱ�ߵ�б�� (Slope),
b
b
b? ����Ϊֱ�ߵ�ƫ�� (Bias)��

??
??����֪�� n + 1 n+1 n+1 ����ȷ�� n n n �������ʽ, n + 1 n+1 n+1 ����ȷ�� n n n Ԫһ�η���(��С���˷�), ��Ȼ����һ������������,����ֻ��Ҫ�۲�õ�������ͬ���ݵ�,�Ϳ���õ�����������Ԫģ�͵IJ�����ͬ����,���� n n n �����������Ԫģ��,ֻ��Ҫ�۲���� n + 1 n + 1 n+1 �鲻ͬ���ݵ㼴�ɵõ����в���,�ƺ��ʹ�������Ԫģ�Ϳ��Եõ������Ľ������ô���������Ƿ������ʲô������?
���� 5 :ʲô����ʧ����?Ϊʲô��Ҫʹ����ʧ����?
??���Ƕ����κβ�����,���п��ܴ����۲���������Ǽ���۲�������
?
\epsilon
? ���ھ�ֵΪ
��
\mu
��,����Ϊ
��
2
\sigma^{2}
��2 ����̬�ֲ� (NormalDistribution) ���˹�ֲ� (Gaussian Distribution):
N
(
��
,
��
2
)
\mathcal{N}\left(\mu, \sigma^{2}\right)
N(��,��2),��ô���ǹ۲�����õ�����������:
y
=
w
x
+
b
+
?
,
?
��
N
(
��
,
��
2
)
(2.4)
y=w x+b+\epsilon, \epsilon \sim \mathcal{N}\left(\mu, \sigma^{2}\right)\tag{2.4}
y=wx+b+?,?��N(��,��2)(2.4)
������̬�ֲ������ܶȺ�������:
p ( x ) = 1 2 �� �� 2 exp ? ( ? 1 2 �� 2 ( x ? �� ) 2 ) . (2.5) p(x) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2 \sigma^2} (x - \mu)^2\right).\tag{2.5} p(x)=2����2?1?exp(?2��21?(x?��)2).(2.5)
??���Ƿ���һ������۲�����Ժ�,��ʹ��������ģ��,����������������ݵ�,���ܻ�����ϴ� ����ƫ�� ����ͼ 2.4 ��ʾ,ͼ�е����ݵ�����й۲����,���������ɫ���ο���������ݵ���й���,����������ɫ��������ʵ��ɫֱ�ߴ��ڽϴ�ƫ�
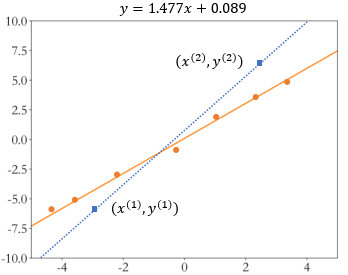
??
??Ϊ�˼��ٹ۲��������Ĺ���ƫ��,����ͨ���������������������� 𝔻 = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , �� , ( x ( n ) , y ( n ) ) } 𝔻 = \left\{\left(x^{(1)}, y^{(1)}\right),\left(x^{(2)}, y^{(2)}\right), \ldots,\left(x^{(n)}, y^{(n)}\right)\right\} D={(x(1),y(1)),(x(2),y(2)),��,(x(n),y(n))},Ȼ���ҳ�һ�� ����á� ��ֱ��,ʹ���������ܵ������в����㵽��ֱ�ߵ� ��� (Error) �� ��ʧ (Loss) ֮����С���ɡ�
??Ҳ����˵,���ڹ۲���� ? \epsilon ? �Ĵ���,�����Dzɼ��˶�����ݵ� 𝔻 𝔻 D ʱ,���ܲ�����һ��ֱ�������Ĵ������в����㡣�������ϣ�����ҵ�һ���Ƚ� ���á� ��λ�ڲ������м��ֱ��,������̾ͽ��� ���(fit)��
??Ϊ���б���ϳ���ֱ���Dz��� ���á� ��,������Ҫȷ��һ����ϳ̶ȵĶ���,������������ ��ʧ���� �����к�����
??��ʧ����(loss function),�ֳ� ���ۺ���(cost function),�ǽ�����¼������й����������ȡֵӳ��Ϊ�Ǹ�ʵ���Ա�ʾ������¼��ġ����ա�����ʧ���ĺ�������Ӧ����,��ʧ����ͨ����Ϊѧϰ�����Ż���������ϵ,��ͨ����С����ʧ������������ģ�͡���ʧ���� �ܹ�����Ŀ���ʵ��ֵ��Ԥ��ֵ֮��IJ�ࡣͨ�����ǻ�ѡ��Ǹ�����Ϊ��ʧ,����ֵԽС��ʾ��ʧԽС,����Ԥ��ʱ����ʧΪ 0 0 0? ��
���� 6 :�ع������г��õ���ʧ��������Щ?
�ع������г��õ���ʧ������ƽ��������������ƽ������ֵ��ƽ��ƽ����������ȡ�
? ? ?\, ??������� (Mean Squared Error, MSE)
??����һ������Ȼ���뷨����,�����ǰģ�͵����в������ϵ�Ԥ��ֵ
w
x
(
i
)
+
b
w x^{(i)}+b
wx(i)+b? ����ʵֵ
y
(
i
)
y^{(i)}
y(i)? ֮��IJ��ƽ������Ϊ�����
L
\mathcal{L}
L??��������
i
i
i? ��Ԥ��ֵΪ
y
^
(
i
)
=
w
x
(
i
)
+
b
\hat{y}^{(i)}=w x^{(i)}+b
y^?(i)=wx(i)+b? (ͨ��ʹ�á���ǡ�hat ���ű�ʾ����ֵ��Ԥ��ֵ),����Ӧ����ʵ��ǩΪ
y
(
i
)
y^{(i)}
y(i)? ʱ,ƽ���������Զ���Ϊ:
L
(
i
)
(
w
,
b
)
=
1
n
��
i
=
1
n
(
y
^
(
i
)
?
y
(
i
)
)
2
.
(2.6)
\mathcal{L}^{(i)}(\boldsymbol {w}, b) =\frac{1}{n} \sum_{i=1}^{n} \left(\hat{y}^{(i)} - y^{(i)}\right)^2.\tag{2.6}
L(i)(w,b)=n1?i=1��n?(y^?(i)?y(i))2.(2.6)
??��ѵ��ģ��ʱ,����ϣ��������һ�����( w ? , b ? \boldsymbol {w}^* , b^* w?,b? ),�����������С��������ѵ�������ϵ�����ʧ L \mathcal{L} L,���Ӧ��ֱ�߾�������ҪѰ�ҵ�����ֱ��:
w ? , b ? = argmin ? w , b 1 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) 2 (2.7) \boldsymbol {w}^{*}, b^{*}=\underset{\boldsymbol {w}, b}{\operatorname{argmin}} \frac{1}{n} \sum_{i=1}^{n} \left(w x^{(i)}+b-y^{(i)}\right)^{2}\tag{2.7} w?,b?=w,bargmin?n1?i=1��n?(wx(i)+b?y(i))2(2.7)
??���� 𝑛 𝑛 n ��ʾ������ĸ��������������㷽����Ϊ������� (Mean Squared Error) ��� MSE��
��:
MSE
=
1
n
��
i
=
1
n
(
y
^
(
i
)
?
y
(
i
)
)
2
(2.8)
\text{MSE}=\dfrac 1 n \sum^{n}_{i=1}(\hat y^{(i)}-y^{(i)})^2\tag{2.8}
MSE=n1?i=1��n?(y^?(i)?y(i))2(2.8)
?
?
?\,
?���������(Root Mean Square Error, RMSE)
RMSE
=
1
n
��
i
=
1
n
(
y
^
(
i
)
?
y
(
i
)
)
2
(2.9)
\text{RMSE}=\sqrt{\dfrac {1} {n} \sum_{i=1}^n(\hat y^{(i)}-y^{(i)})^2}\tag{2.9}
RMSE=n1?i=1��n?(y^?(i)?y(i))2?(2.9)
���������,Ҳ�лع�ϵͳ����ϱ���,��
MSE
\text{MSE}
MSE ��ƽ����,�������쳣��(���ܴ�ĵ�)Ӱ��,�׳���С�쳣�����ķ����н��������������ܡ�
?
?
?\,
?ƽ���������(Mean Absolute Error, MAE)
MAE
=
1
n
��
i
=
1
n
�O
?
y
^
(
i
)
?
y
(
i
)
?
�O
(2.10)
\text{MAE}=\frac 1 n \sum_{i=1}^n\mid\,\hat y^{(i)}-y^{(i)}\,\mid\tag{2.10}
MAE=n1?i=1��n?�Oy^?(i)?y(i)�O(2.10)
����ֵ����ƽ��ֵ,���ڵ����dz���,�������ݶ��½������¡��Ҹú�����
0
0
0 ��������
?
?
?\,
?ƽ��ƽ���������(HuberLoss)
L
��
(
y
i
)
=
{
1
2
(
y
^
(
i
)
?
y
(
i
)
)
2
,
�O
y
^
(
i
)
?
y
(
i
)
�O
��
��
��
�O
y
^
(
i
)
?
y
(
i
)
�O
?
1
2
��
2
,
?otherwise?
(2.11)
L_{\delta}\left(y_{i}\right)=\left\{\begin{array}{ll}\dfrac{1}{2}\left(\hat{y}^{(i)}-y^{(i)}\right)^{2}, & \left|\hat{y}^{(i)}-y^{(i)}\right| \leq \delta \\\delta\left|\hat{y}^{(i)}-y^{(i)}\right|-\dfrac{1}{2} \delta^{2}, & \text { otherwise }\end{array}\right.\tag{2.11}
L��?(yi?)=??????21?(y^?(i)?y(i))2,���O�O?y^?(i)?y(i)�O�O??21?��2,?�O�O?y^?(i)?y(i)�O�O?����?otherwise??(2.11)
Huber Loss ��һ�����ڻع�����Ĵ�����ʧ����,�����
MSE
\text{MSE}
MSE ��
MAE
\text{MAE}
MAE ���ŵ�, �ŵ�������ǿ
MSE
\text{MSE}
MSE ����Ⱥ���³����,���쳣�㲻���ر�����ͬʱ��
0
0
0 ��Ҳ������Ԥ��ƫ��С��
��
\delta
�� ʱ,������ƽ�����,��Ԥ��ƫ�����
��
\delta
�� ʱ,���õ�������Ҳ�������,������Ҫ���ϵص���������
��
\delta
�� ,Ҳ��˴���һЩ���㡣
?? �ص����Ȿ��,��������ѡ���������Ϊ��ʧ�������������Ԫģ�����⡣������Ҫ�ҳ����Ų��� (Optimal Parameter) w ? , b ? \boldsymbol {w}^{*}, b^{*} w?,b? ,ʹ�����������������Թ�ϵ y ( i ) = w x ( i ) + b , i �� [ 1 , n ] y^{(i)}=w x^{(i)}+b, i \in[1, n] y(i)=wx(i)+b,i��[1,n]���������ڹ۲���� ? \epsilon ? �Ĵ���,��Ҫͨ�������㹻���������������ɵ����ݼ� (Dataset): 𝔻 = ( 𝑥 ( 1 ) , 𝑦 ( 1 ) ) , ( 𝑥 ( 2 ) , 𝑦 ( 2 ) ) , �� , ( 𝑥 ( 𝑛 ) , 𝑦 ( 𝑛 ) ) 𝔻 ={(𝑥(1),𝑦(1)), (𝑥(2),𝑦(2)),�� , (𝑥(𝑛), 𝑦(𝑛))} D=(x(1),y(1)),(x(2),y(2)),��,(x(n),y(n)),���ҵ�һ�����ŵIJ��� 𝒘 ? , b ? 𝒘^{*}, b^{*} w?,b? ʹ�þ����� L = 1 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) 2 \mathcal{L} =\displaystyle \frac{1}{n} \sum_{i=1}^{n} \left(w x^{(i)}+b-y^{(i)}\right)^{2} L=n1?i=1��n?(wx(i)+b?y(i))2 ��С���ɡ�
2.2.2 �Ż�����
??�����������ݵ�ѧϰ,���Ƕ����ѧϰ����һ�μ��ܽᡣ�ڴ�ͳ�ļල����ѧϰ��,���������ѵ�����ݼ�
D
=
{
(
x
1
,
y
1
)
,
��
,
(
x
N
,
y
N
)
}
\mathcal D = \{(x_1, y_1),��,(x_N, y_N)\}
D={(x1?,y1?),��,(xN?,yN?)},�� (����ͼ��,�����ǩ) �ԡ�����ϣ��ѵ��һ��Ԥ��ģ��
y
^
=
f
��
(
x
)
\hat{y}=f_{\theta }\left ( x \right )
y^?=f��?(x) ,������
��
��
�� ,ͨ�������ʽ�õ�������ȫ�����Ž�:
��
?
=
arg
?
min
?
��
L
(
D
;
��
,
��
)
(2.12)
\theta^{*}=\arg \min _{\theta} \mathcal{L}(\mathcal{D} ; \theta, \omega)\tag{2.12}
��?=arg��min?L(D;��,��)(2.12)
����
L
\mathcal L
L ����һС�ڽ��ܵ����ڲ�����ʵ��ǩ��
f
��
(
?
)
f_{\theta}(\cdot)
f��?(?) Ԥ��ı�ǩ֮���������ʧ������ ����ͨ������������֪��ǩ�Ķ�����Ե�����������������
??���������Ż��IJ�����������Ҫ��������⡣�����������ŵIJ���������ʱ��ռ临�Ӷ���Ȼ�Dz��ܽ��ܵ�,Ϊ�����Ƿ������������Ż��㷨�����Խ�����Ż��㷨�Ĺ�����ͨ������ѵ����ʽ�����Ż���ʧ����,���Լӿ������ٶ�,ʹ��ѵ����ʱ�����,�����Ի�ø��ŵ���ʧ������
??���ѧϰ�е��Ż��㷨�кܶ�,�����ݶ��½��㷨����������AdaGrad�㷨��RMSProp�㷨��Adadelta�㷨��Adam�㷨�ȡ������������ؽ������һ���Ż�����:�ݶ��½��㷨,�Լ���һ�ֿ��Ը�Ч������Իع�����ľ����㷨:��С���˷��������Ż��㷨������ �����������ѧϰ�ʼǡ��� 7 �� ����ϡ��Ż��㷨������Ż� 7.9 �Ż��㷨
2.2.2.1 �ݶ��½��㷨
??�ݶ��½��㷨(Gradient Descent)��������ѵ������õ��Ż��㷨,���ǿ���ͼ�δ���оƬ GPU �IJ��м�������,�dz��ʺ��Ż��������ݵ�������ģ��,��ȻҲ�ʺ��Ż������������Ԫ����ģ�͡������ȼ�Ӧ���ݶ��½��㷨,�Լ����ʹ���������Ԫģ��Ԥ����Ż����⡣
??�����ڸ��ж�ѧ������ (Derivative) �ĸ���,���Ҫ���һ�������ļ���Сֵ,���Լ��������Ϊ 0 0 0??????????,�����Ӧ���Ա����� (��Ϊפ��) ,�ټ���פ�����ͼ��ɡ��Ժ��� 𝑓 ( 𝑥 ) = x 2 sin ? ( 𝑥 ) 𝑓(𝑥) = x^2 \sin(𝑥) f(x)=x2sin(x)?????????? Ϊ��,���ǻ��Ƴ��������䵼���� 𝑥 �� [ ? 1 , 1 ] 𝑥\in [?1 ,1] x��[?1,1]?????????? ����������,������ɫʵ��Ϊ 𝑓 ( 𝑥 ) 𝑓(𝑥) f(x)??????????,��ɫ����Ϊ d f ( x ) d x \dfrac{\mathrm{d} f(x)}{\mathrm{d} x} dxdf(x)???????????�����Կ���,��������Ϊ 0 0 0?????????? �ĵ㼴Ϊ 𝑓 ( 𝑥 ) 𝑓(𝑥) f(x)?????????? ���ٽ��(critical point)�� פ��(stationary point),�����ļ���ֵ�ͼ�Сֵ���������פ���С�
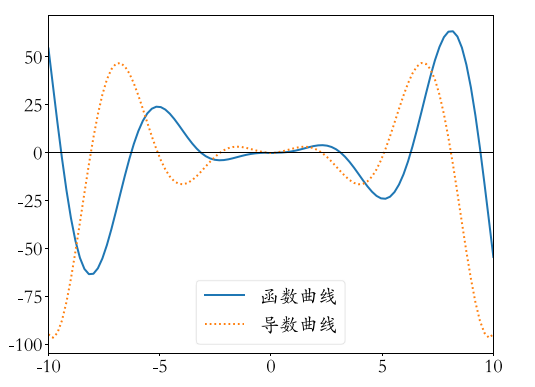
??
??���� f �� ( x ) f'(x) f��(x) ���� f ( x ) f(x) f(x) �ڵ� x x x ����б�ʡ����仰˵,������������������С�仯��������������Ӧ�ı仯: f ( x + ? ) �� f ( x ) + ? f �� ( x ) f(x + ?) �� f(x) + ?f'(x) f(x+?)��f(x)+?f��(x)����˵���������С��һ������������,��Ϊ������������θ��� x x x �����ظ��� y y y������,����֪�������㹻С�� ? ? ? ��˵, f ( x ? ? s i g n ( f �� ( x ) ) ) f(x ? ?sign(f��(x))) f(x??sign(f��(x))) �DZ� f ( x ) f(x) f(x) С�ġ�������ǿ��Խ� x x x? �������ķ������ƶ�һС������С f ( x ) f(x) f(x)�����ּ�������Ϊ �ݶ��½�(gradient descent)��
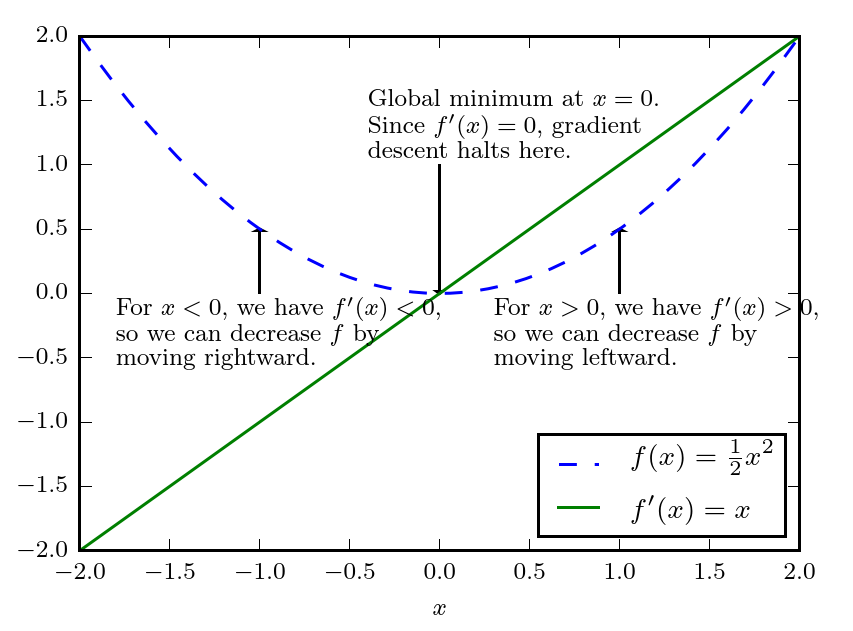
??
??�������ݶ�(Gradient)����Ϊ�����Ը����Ա�����ƫ����(Partial Derivative)��ɵ����������� 3 3 3????????????? ά���� 𝑧 = 𝑓 ( 𝑥 , 𝑦 ) 𝑧 = 𝑓(𝑥, 𝑦) z=f(x,y)?????????????,�������Ա��� 𝑥 𝑥 x????????????? ��ƫ������Ϊ ? z ? x \dfrac{\partial z}{\partial x} ?x?z?????????????? ���Ժ����� x x x???????????? ��ֻ�� x x x??????????? ����ʱ f ( x ) f(x) f(x)?????????? ��α仯�� �ݶ������һ�������ĵ���: f f f???????? �ĵ����ǰ�������ƫ����������,��Ϊ ? x f ( x ) \nabla xf(x) ?xf(x)???????���������Ա���y��ƫ������Ϊ ? z ? y \dfrac{\partial z}{\partial y} ?y?z?????????????? ,���ݶ� ? f \nabla f ?f????????????? Ϊ���� ( ? z ? x , ? z ? y ) \left(\dfrac{\partial z}{\partial x}, \dfrac{\partial z}{\partial y}\right) (?x?z?,?y?z?)?????????????�����ڶ�ά�������,�ݶȵĵ� i i i???? ��Ԫ���� f f f??? ���� x i x_i xi??? ��ƫ��������ʱ���ٽ�����ݶ�������Ԫ�ض�Ϊ��ĵ㡣����ͨ��һ������ĺ����������ݶȵ����ʡ�
??��ͼ 2.2.7 ��ʾ, f ( x , y ) = ? ( cos ? 2 x + cos ? 2 y ) 2 f(x, y)=-\left(\cos ^{2} x+\cos ^{2} y\right)^{2} f(x,y)=?(cos2x+cos2y)2 ,ͼ�� 𝑥 𝑦 𝑥𝑦 xy ƽ��ĺ�ɫ��ͷ�ij��ȱ�ʾ�ݶ�������ģ,��ͷ�ķ����ʾ�ݶ������ķ����Կ���,��ͷ�ķ�������ָ��ǰλ�ú���ֵ�������ķ���,��������Խ����,��ͷ�ij���Ҳ��Խ��,�ݶȵ�ģҲԽ��
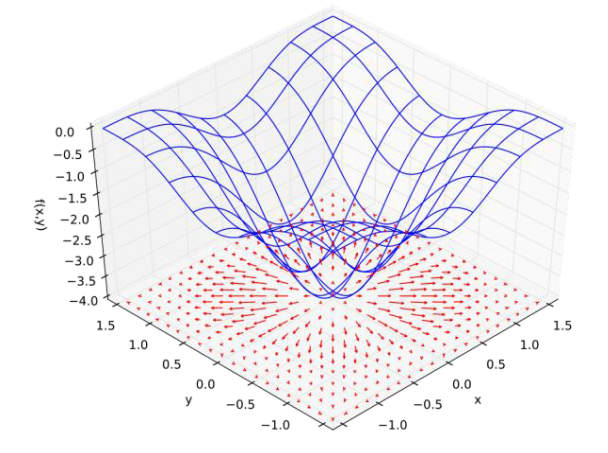
??
?? ͨ�����������,������ֱ�۵ظ��ܵ�,�����ڸ������ݶȷ��� ? 𝑓 ?𝑓 ?f? ����ָ����ֵ����ķ���,��ô�ݶȵķ����� ? ? 𝑓 ??𝑓 ??f?? Ӧָ����ֵ���ٵķ���
??���ǹ涨�� u \boldsymbol u u(��λ����)����� ������(directional derivative)�Ǻ��� f f f �� u \boldsymbol u u �����б�ʡ�Ҳ���������Ǻ��� f ( x + �� u ) f(x + \alpha \boldsymbol u) f(x+��u) ���� �� \alpha �� �ĵ���(�� �� = 0 \alpha = 0 ��=0 ʱȡ��)��ʹ����ʽ����,���ǿ��Է��ֵ� �� = 0 \alpha = 0 ��=0 ʱ, ? ? �� f ( x + �� u ) = u ? ? x f ( x ) \dfrac{\partial}{\partial \alpha} f(\boldsymbol{x}+\alpha \boldsymbol{u})=\boldsymbol{u}^{\top} \nabla_{x} f(\boldsymbol{x}) ?��??f(x+��u)=u??x?f(x)��
??Ϊ����С��
f
f
f,����ϣ���ҵ�ʹ
f
f
f �½������ķ����㷽����:
min
?
u
,
u
?
u
=
1
u
?
?
x
f
(
x
)
=
min
?
u
,
u
?
u
=
1
��
u
��
2
��
?
x
f
(
x
)
��
2
cos
?
��
(2.13)
\begin{array}{c}\min _{u, u^{\top} u=1} \boldsymbol{u}^{\top} \nabla_{x} f(\boldsymbol{x}) \\=\min _{u, \boldsymbol{u}^{\top} \boldsymbol{u}=1}\|\boldsymbol{u}\|_{2}\left\|\nabla_{\boldsymbol{x}} f(\boldsymbol{x})\right\|_{2} \cos \theta\end{array}\tag{2.13}
minu,u?u=1?u??x?f(x)=minu,u?u=1?��u��2?��?x?f(x)��2?cos��?(2.13)
����
��
\theta
��?????????? ��
u
\boldsymbol u
u????????? ���ݶȵļнǡ���
��
u
��
2
=
1
\|\boldsymbol u\|_2 = 1
��u��2?=1???????? ����,��������
u
\boldsymbol u
u???????? �ص���,���ܼõ�
min
?
u
cos
?
��
\displaystyle \min_{\boldsymbol u}\cos ��
umin?cos��???????������
u
\boldsymbol u
u?????? ���ݶȷ����෴ʱȡ����С�����仰˵,�ݶ�����ָ������,
���ݶ�����ָ�����¡������ڸ��ݶȷ������ƶ����Լ�С
f
f
f????? ���ⱻ��Ϊ�����½���(method of steepest descent)�� �ݶ��½�(gradient descent)��
�����������ǰ���
x
��
=
x
?
��
?
?
x
f
(2.14)
x^{\prime}=x-\eta \cdot \nabla_x f\tag{2.14}
x��=x?��??x?f(2.14)
���������� x �� x' x��? ,���ɻ��Խ��ԽС�ĺ���ֵ,���� �� \eta ��? ��һ��ȷ��������С��������,���������ݶ�����,����Ϊ ѧϰ��(learning rate)��
??ѧϰ�ʾ�����Ŀ�꺯���ܷ��������ֲ���Сֵ,�Լ���ʱ��������Сֵ�� ѧϰ�� �� \eta �� �����㷨��������á�һ������Ϊij��С��ֵ,�� 0.01 , 0.001 0.01,0.001 0.01,0.001 �ȡ� ��ע��,�������ʹ�õ�ѧϰ��̫С,������ x x x �ĸ��·dz�����,��Ҫ����ĵ�����
??����,����ͬһ�Ż������� �� = 0.05 \eta = 0.05 ��=0.05? �Ľ��ȡ� ��ͼ 2.8 ��ʾ,���ܾ����� 10 10 10? ��ѵ��,������Ȼ�����Ž��Զ��
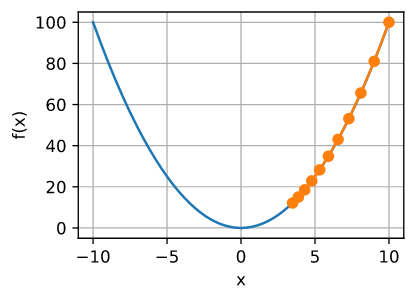
??
??�෴,�������ʹ�ù��ߵ�ѧϰ��, �O �� f �� ( x ) �O \left|\eta f'(x)\right| �O��f��(x)�O?����һ��̩��չ��ʽ����̫�������������, x x x? �ĵ������ܱ�֤���� f ( x ) f(x) f(x)?��ֵ�� ����,��ѧϰ��Ϊ �� = 1.1 \eta=1.1 ��=1.1? ʱ, x x x? ���������Ž� x = 0 x=0 x=0? ����ɢ��

??���ǿ���ͨ�����ֲ�ͬ�ķ�ʽѡ�� �� \eta �����ձ�ķ�ʽ��ѡ��һ��С��������ʱ����ͨ������,ѡ��ʹ��������ʧ�IJ���������һ�ַ����Ǹ��ݼ��� �� \eta �� ���� f ( x ? �� ? x f ( x ) ) f(x ? \eta \nabla xf(x)) f(x?��?xf(x)),��ѡ�������ܲ�����СĿ�꺯��ֵ�� �� \eta �� �����ֲ��Ա���Ϊ ������ (line search)��
?? ����һ��һά��������,ѡ���ѧϰ��
��
\eta
�� ֮��,������ʽ��
x
��
=
x
?
��
?
?
f
x^{\prime}=x-\eta \cdot \nabla f
x��=x?��??f? ���˻����˱�����ʽ:
x
��
=
x
?
��
?
d
y
d
x
(2.15)
x^{\prime}=x-\eta \cdot \frac{\mathrm{d} y}{\mathrm{d} x}\tag{2.15}
x��=x?��?dxdy?(2.15)
??ͨ����ʽ�������� x �� x' x��??? ���ɴ�,�����õ��� 𝑥 �� 𝑥' x��??? ���ĺ���ֵ y �� y' y��???,���Ǹ��п��ܱ��� x x x?? ?���ĺ���ֵ y y y??? С��
??ͨ�����湫ʽ�Ż������ķ�����Ϊ�ݶ��½��㷨,��ͨ��ѭ�����㺯�����ݶ� ? 𝑓 ?𝑓 ?f? �����´��Ż����� �� \theta ��?,�Ӷ��õ����� f f f? ��ü�Сֵʱ���� �� \theta ��? ��������ֵ�⡣��Ҫע�����,�����ѧϰ��,һ�� 𝒙 𝒙 x? ��ʾģ������,ģ�͵Ĵ��Ż�����һ���� �� , 𝑤 , 𝑏 \theta,𝑤,𝑏 ��,w,b? �ȷ��ű�ʾ��
??�������ǽ�Ӧ���ݶ��½��㷨�����
w
?
,
b
?
\boldsymbol w^{*}, b^{*}
w?,b?? ����������Ҫ��С�����Ǿ���������
L
\mathcal{L}
L?:
L
=
1
n
��
i
=
0
n
(
w
x
(
i
)
+
b
?
y
(
i
)
)
2
(2.16)
\mathcal{L}=\frac{1}{n} \sum_{i=0}^{n}\left(w x^{(i)}+b-y^{(i)}\right)^{2}\tag{2.16}
L=n1?i=0��n?(wx(i)+b?y(i))2(2.16)
��Ҫ�Ż���ģ�Ͳ�����
w
\boldsymbol w
w ��
b
b
b ,������ǰ���
w
��
=
w
?
��
?
L
?
w
(2.17)
w^{\prime}=w-\eta \frac{\partial \mathcal{L}}{\partial w}\tag{2.17}
w��=w?��?w?L?(2.17)
b �� = b ? �� ? L ? b (2.18) b^{\prime}=b-\eta \frac{\partial \mathcal{L}}{\partial b}\tag{2.18} b��=b?��?b?L?(2.18)
�ķ�ʽѭ�����²������ɡ�
���� 10 :�ݶ��½��㷨Ϊʲô�����Ż�Ŀ�꺯��?(ѡѧ)
??�ݶ��½��㷨Ϊʲô�����Ż�Ŀ�꺯����?���������֤��:
??����һ��������ʵֵ����
f
:
R
��
R
f: \R \rightarrow \mathbb{R}
f:R��R, ����̩��չ��,���ǿ��Եõ�
f
(
x
+
?
)
=
f
(
x
)
+
?
f
��
(
x
)
+
O
(
?
2
)
.
(2.19)
f(x + \epsilon) = f(x) + \epsilon f'(x) + \mathcal{O}(\epsilon^2).\tag{2.19}
f(x+?)=f(x)+?f��(x)+O(?2).(2.19)
??����һ������,
f
(
x
+
?
)
f(x+\epsilon)
f(x+?) ��ͨ��
x
x
x ���ĺ���ֵ
f
(
x
)
f(x)
f(x) ��һ����
f
��
(
x
)
f'(x)
f��(x) �ó��� ���ǿ��Լ����ڸ��ݶȷ������ƶ���
?
\epsilon
? �����
f
f
f �� Ϊ�˼����,����ѡ��̶�����
��
>
0
\eta > 0
��>0 ,Ȼ��ȡ
?
=
?
��
f
��
(
x
)
\epsilon = -\eta f'(x)
?=?��f��(x) �� �������̩��չ��ʽ���ǿ��Եõ�
f
(
x
?
��
f
��
(
x
)
)
=
f
(
x
)
?
��
f
��
2
(
x
)
+
O
(
��
2
f
��
2
(
x
)
)
.
(2.20)
f(x - \eta f'(x)) = f(x) - \eta f'^2(x) + \mathcal{O}(\eta^2 f'^2(x)).\tag{2.20}
f(x?��f��(x))=f(x)?��f��2(x)+O(��2f��2(x)).(2.20)
??����䵼��
f
��
(
x
)
��
0
f'(x) \neq 0
f��(x)��?=0 û����ʧ,���Ǿ��ܼ���չ��,������Ϊ
��
f
��
2
(
x
)
>
0
\eta f'^2(x)>0
��f��2(x)>0�� ����,�������ǿ�����
��
\eta
�� С������ʹ�߽����ò���ء� ���,
f
(
x
?
��
f
��
(
x
)
)
?
f
(
x
)
.
(2.21)
f(x - \eta f'(x)) \lessapprox f(x).\tag{2.21}
f(x?��f��(x))?f(x).(2.21)
����ζ��,�������ʹ��
x
��
x
?
��
f
��
(
x
)
(2.22)
x \leftarrow x - \eta f'(x)\tag{2.22}
x��x?��f��(x)(2.22)
������ x x x????,���� f ( x ) f(x) f(x)???? ��ֵ���ܻ��½��� ���,���ݶ��½���,��������ѡ���ʼֵ x x x???? �ͳ��� �� > 0 \eta > 0 ��>0???? , Ȼ��ʹ�������������� x x x????? ,ֱ��ֹͣ�������,�ﵽȫ����Сֵ(ȫ�����Ž�)��ֲ���Сֵ��ֹͣ��������ͼ������ͼ 2.10 ��ʾ:
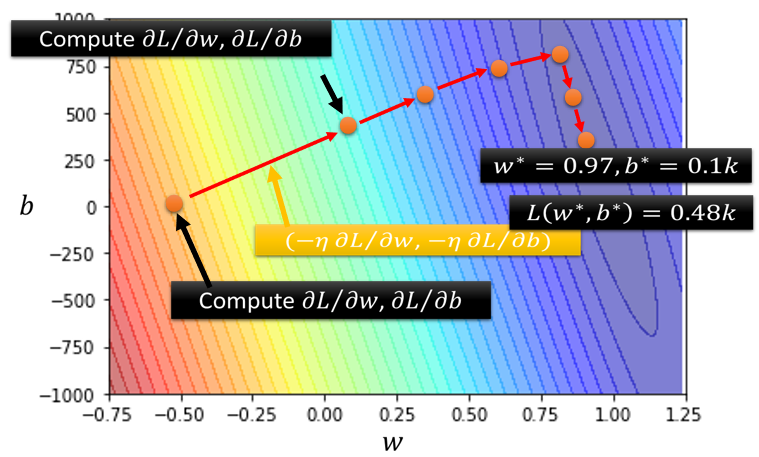
? ? ?\, ???�ֲ����Ž�
??ע����Ǹո��ᵽ��ȫ�����Ž���ֲ����Ž�ĸ���,��ô���Ƿֱ���ʲô��˼��?ȫ�����Ž��������Ϊ������Ҫ���������,��ȫֵ��Χ�����š���ô�ֲ����Ž����ָ����һ������Ľ���һ����Χ������������,����˵����������Ŀ����ֶ���һ����Χ�����������š�������Ȼ��ϣ���õ�ȫ�����Ž�����Ǿֲ����Ž�:
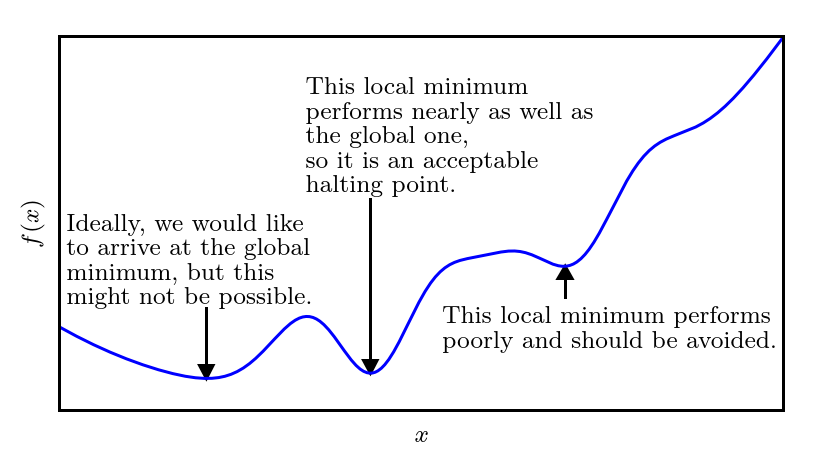
??
??���ݶ��½��Ĺ�����,�������ֲ����Ž�֮��,���������������ѳ���������ͼ���ǿ��Ժ������ط���,�ֲ����Ž���� f �� ( x ) = 0 f'(x) = 0 f��(x)=0??? ���ٽ��,��ʱ�ĵ������ṩ���ĸ������ƶ�����Ϣ��һ�� �ֲ���С��(local minimum)��ζ�������� f ( x ) f(x) f(x)??? С�������ڽ���,��˲�����ͨ���ƶ�����С�IJ�������С f ( x ) f(x) f(x)???��һ�� �ֲ������(local maximum)��ζ�������� f ( x ) f(x) f(x)??? ���������ڽ���,��˲�����ͨ���ƶ�����С�IJ��������� f ( x ) f(x) f(x)????�������µ���,��Щ�ٽ��Ȳ�����С��Ҳ��������,��������ٽ������ĵ���,ͬ���ᵼ���ݶ��½��㷨����������,��Щ�㱻��Ϊ ����(saddle point)�������ٽ������ͼ��ʾ:
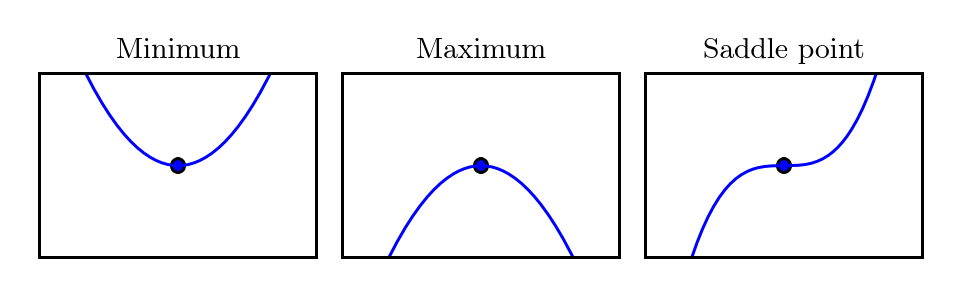
??
���� 11 :ѵ����������α�������ֲ����Ž�?������배��?
������ѵ���Ĺ�����,�϶���Ҫ��������ֲ����Ž�,��ʱ���배�㡣�����ݶ��½��㷨����,����ͨ������Ӧѧϰ�ʡ������ȷ��������Ż�,�����������˸����Ż��㷨��:Adagrad��RMSprop��stochastic GD(SGD)�ȷ������������배���Ч������ͼ��ʾ:
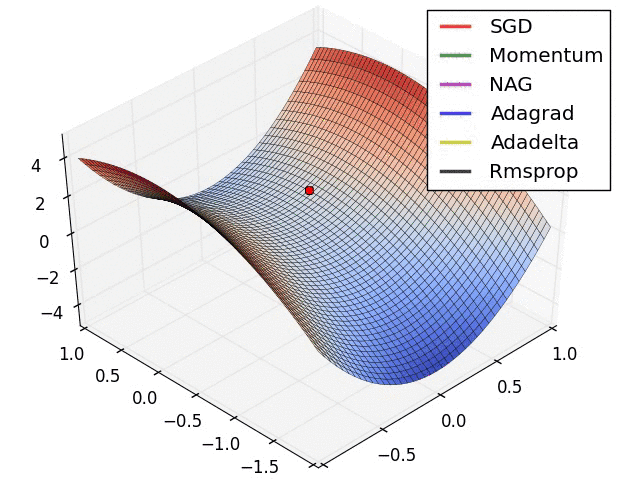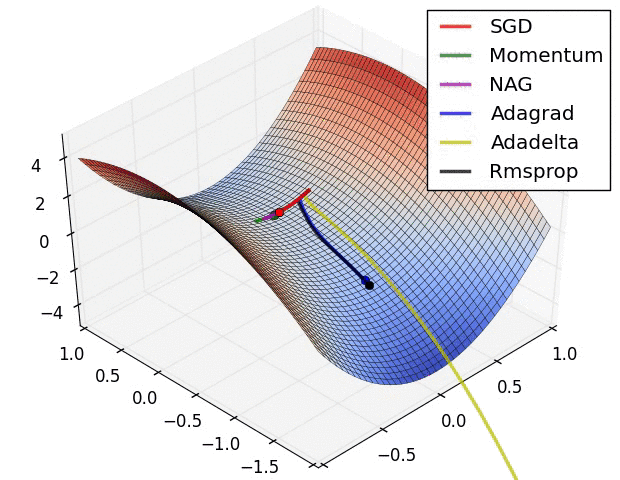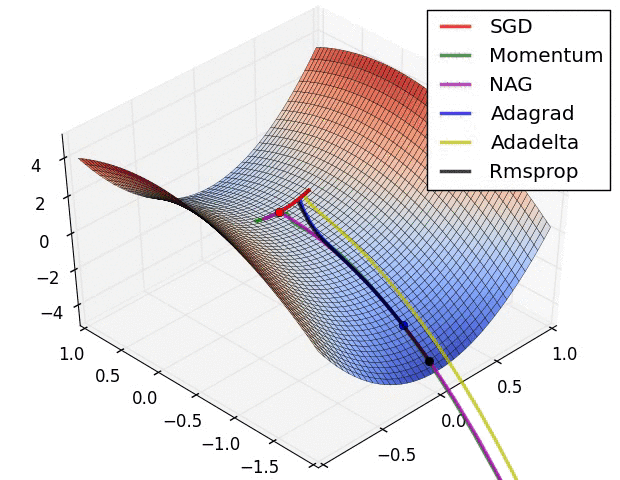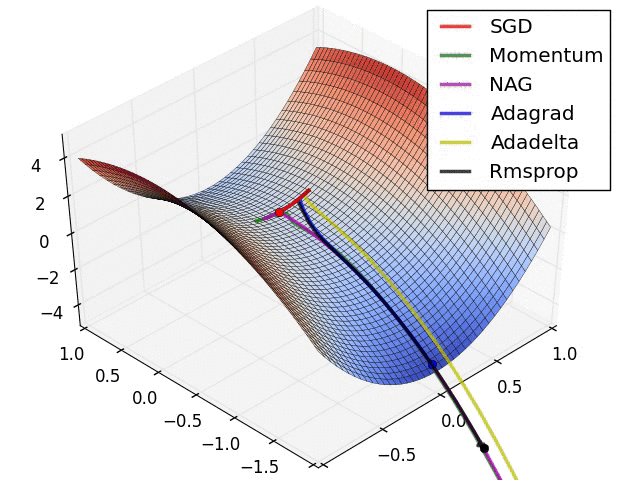
??
���ǽ��� �����������ѧϰ�ʼǡ��� 7 �� ����ϡ��Ż��㷨������Ż� 7.9 �Ż��㷨 �ж���Щ��չ���Ż��㷨���н�һ��������̽�֡�
2.2.2.1.1 Jacobian �� Hessian ����(ѡѧ)
���ǽ��� �����������ѧϰ�ʼǡ��� 7 �� ����ϡ��Ż��㷨������Ż� 7.9 �Ż��㷨 �и���һ��������̽���ݶ��½��㷨,����Jacobian �� Hessian ���������ϸ���⡣
2.2.2.1.2 ����ַ���ԳƵ����������ݶȴ�С(ѡѧ)
���� 12 : Ȥζ����:��ʱ������û�취ֱ�Ӽ����ݶȸ���ô����?���Գ��Թ����ݶȴ�С��?- ����ַ���ԳƵ�����(ѡѧ)
? ? ?\, ??����ַ�
??����ѧ��,����ַ�(finite-difference methods,FDM),��һ���ַ�����ֵ����,��ͨ������������Ƶ���,�Ӷ�Ѱ���ַ��̵Ľ��ƽ⡣��ʱ���Dz���ֱ�ӻ�ȡ�ݶ�ֵ,�Ϳ���ʹ������ַ�,���ݵ����Ķ���,ȡ���ķ�������ö��ݶȵĹ��ơ�
? ? ?\, ?����ַ����Ƶ�
??���ȼ���Ҫ���ƺ����ĸ��������������õ�����,����̩�ն���,�����γ����µ�̩��չ��ʽ:
f
(
x
0
+
h
)
=
f
(
x
0
)
+
f
��
(
x
0
)
1
!
h
+
f
(
2
)
(
x
0
)
2
!
h
2
+
?
+
f
(
n
)
(
x
0
)
n
!
h
n
+
R
n
(
x
)
,
(2.23)
f(x_{0}+h)=f(x_{0})+{\frac {f'(x_{0})}{1!}}h+{\frac {f^{{(2)}}(x_{0})}{2!}}h^{2}+\cdots +{\frac {f^{{(n)}}(x_{0})}{n!}}h^{n}+R_{n}(x),\tag{2.23}
f(x0?+h)=f(x0?)+1!f��(x0?)?h+2!f(2)(x0?)?h2+?+n!f(n)(x0?)?hn+Rn?(x),(2.23)
����
n
!
n!
n!?????? ��ʾ��
n
n
n??? �Ľ׳�,
R
n
(
x
)
Rn(x)
Rn(x)? Ϊ����,��ʾ̩�ն���ʽ��ԭ����֮��IJ�����Ƶ�����
f
f
f һ�����Ľ���ֵ:
f
(
x
0
+
h
)
=
f
(
x
0
)
+
f
��
(
x
0
)
h
+
R
1
(
x
)
,
(2.24)
f(x_{0}+h)=f(x_{0})+f'(x_{0})h+R_{1}(x),\tag{2.24}
f(x0?+h)=f(x0?)+f��(x0?)h+R1?(x),(2.24)
�趨
x
0
=
a
x_0=a
x0?=a,�ɵ�:
f
(
a
+
h
)
=
f
(
a
)
+
f
��
(
a
)
h
+
R
1
(
x
)
,
(2.25)
f(a+h)=f(a)+f'(a)h+R_{1}(x),\tag{2.25}
f(a+h)=f(a)+f��(a)h+R1?(x),(2.25)
����
h
h
h �ɵ�:
f
(
a
+
h
)
h
=
f
(
a
)
h
+
f
��
(
a
)
+
R
1
(
x
)
h
(2.26)
{f(a+h) \over h}={f(a) \over h}+f'(a)+{R_{1}(x) \over h}\tag{2.26}
hf(a+h)?=hf(a)?+f��(a)+hR1?(x)?(2.26)
���
f
��
(
a
)
f'(a)
f��(a):
f
��
(
a
)
=
f
(
a
+
h
)
?
f
(
a
)
h
?
R
1
(
x
)
h
(2.27)
f'(a)={f(a+h)-f(a) \over h}-{R_{1}(x) \over h}\tag{2.27}
f��(a)=hf(a+h)?f(a)??hR1?(x)?(2.27)
����
R
1
(
x
)
{\displaystyle R_{1}(x)}
R1?(x) �൱С,��˿��Խ� ��f�� ��һ��������Ϊ:
f
��
(
a
)
��
f
(
a
+
h
)
?
f
(
a
)
h
.
(2.28)
f'(a)\approx {f(a+h)-f(a) \over h}.\tag{2.28}
f��(a)��hf(a+h)?f(a)?.(2.28)
?
?
?\,
?�ԳƵ���
??����ѧ��,�ԳƵ���(symmetric derivative)�Ƕ���ͨ�������ƹ㡣��������Ϊ:
lim
?
h
��
0
f
(
x
+
h
)
?
f
(
x
h
)
2
h
.
(2.29)
{\displaystyle \lim _{h\to 0}{\frac {f(x+h)-f(xh)}{2h}}.}\tag{2.29}
h��0lim?2hf(x+h)?f(xh)?.(2.29)
�����µı���ʽ��ʱ��Ϊ�ԳƲ���(symmetric difference quotient.)����������ĶԳƵ��������ڸõ�, ��Ƹú����ڵ�
x
x
x? �� �Գƿ��� ���һ��������һ�����ǿ���(��ͨ��������),��ô��Ҳ�ǶԳƿ���,����֮������
? ? ?\, ??���ԳƵ���
??���ԳƵ�������Ϊ
lim
?
h
��
0
f
(
x
+
h
)
?
2
f
(
x
)
+
f
(
x
h
)
h
2
.
(2.30)
{\displaystyle \lim _{h\to 0}{\frac {f(x+h)-2f(x)+f(xh)}{h^{2}}}.}\tag{2.30}
h��0lim?h2f(x+h)?2f(x)+f(xh)?.(2.30)
�������(ͨ����)������,����ԳƵ������ڲ��ҵ�������Ȼ��,��ʹ(��ͨ)������������,���ԳƵ���Ҳ���ܴ��ڡ�����,���Ƿ��ź���
sgn
?
(
x
)
{\displaystyle \operatorname {sgn}(x)}
sgn(x),�䶨��Ϊ
sgn
?
(
x
)
=
{
?
1
if?
x
<
0
,
0
if?
x
=
0
,
1
if?
x
>
0.
(2.31)
{\displaystyle \operatorname {sgn}(x)={\begin{cases}-1&{\text{if }}x<0,\\0&{\text{if }}x=0,\\1&{\text{if }}x>0.\end{cases}}}\tag{2.31}
sgn(x)=???????101?if?x<0,if?x=0,if?x>0.?(2.31)
���ź������㴦������,��˶���
x
=
0
{\displaystyle x=0}
x=0 �����ڡ����Ƕ��ԳƵ���������
x
=
0
{\displaystyle x=0}
x=0 :
lim
?
h
��
0
sgn
?
(
0
+
h
)
?
2
sgn
?
(
0
)
+
sgn
?
(
0
?
h
)
h
2
=
lim
?
h
��
0
sgn
?
(
h
)
?
2
?
0
+
(
?
sgn
?
(
h
)
)
h
2
=
lim
?
h
��
0
0
h
2
=
0.
(2.32)
{\displaystyle \lim _{h\to 0}{\frac {\operatorname {sgn}(0+h)-2\operatorname {sgn}(0)+\operatorname {sgn}(0-h)}{h ^{2}}}=\lim _{h\to 0}{\frac {\operatorname {sgn}(h)-2\cdot 0+(-\operatorname {sgn}(h))}{h^{ 2}}}=\lim _{h\to 0}{\frac {0}{h^{2}}}=0.}\tag{2.32}
h��0lim?h2sgn(0+h)?2sgn(0)+sgn(0?h)?=h��0lim?h2sgn(h)?2?0+(?sgn(h))?=h��0lim?h20?=0.(2.32)
? ? ?\, ?�����ݶ�
??������ CCS 2017 ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models[14]��,���ڴ������ĺں�ģ��,����ñ�����ģ�͵���ʧ�������ݶ� ? x L ( x , y ) \nabla_xL(x,y) ?x?L(x,y) ,�����������ʹ������ַ��������ݶȡ�
??���������ȶ�����
x
x
x??? �����Ŷ�:
x
=
x
+
h
��
e
x=x+h\times e
x=x+h��e???,�����
h
=
0.0001
h=0.0001
h=0.0001???��
e
e
e??? �DZ���λ��������ģ�͵����Ϊ
f
(
x
)
f(x)
f(x) ,�������öԳƲ��̵õ��ݶȵĹ���ֵ:
g
^
i
:
=
?
f
(
x
)
?
x
i
��
f
(
x
+
h
e
i
)
?
f
(
x
?
h
e
i
)
2
h
(2.33)
\hat{g}_{i}:=\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}_{i}} \approx \frac{f\left(\mathbf{x}+h \mathbf{e}_{i}\right)-f\left(\mathbf{x}-h \mathbf{e}_{i}\right)}{2 h }\tag{2.33}
g^?i?:=?xi??f(x)?��2hf(x+hei?)?f(x?hei?)?(2.33)
������һ�β�ѯ֮�ɻ�ö�����Ϣ:
h
^
i
:
=
?
2
f
(
x
)
?
x
i
i
2
��
f
(
x
+
h
e
i
)
?
2
f
(
x
)
+
f
(
x
?
h
e
i
)
h
2
(2.34)
\hat{h}_{i}:=\frac{\partial^{2} f(\mathbf{x})}{\partial \mathbf{x}_{i i}^{2}} \approx \frac{f\left(\mathbf{x}+h \mathbf{e}_{i}\right)-2 f(\mathbf{x})+f\left(\mathbf{x}-h \mathbf{e}_{i}\right)}{h^{2}}\tag{2.34}
h^i?:=?xii2??2f(x)?��h2f(x+hei?)?2f(x)+f(x?hei?)?(2.34)
������������ݶȹ���ֵ�Ժ�,����ֱ�Ӷ�
x
x
x �����ݶ��½��Ż���
����ţ�ٷ�:
x
=
x
?
��
g
~
h
~
(2.35)
x=x-\eta \frac{\tilde{g}}{\tilde{h}}\tag{2.35}
x=x?��h~g~??(2.35)
����
��
\eta
��? ��ѧϰ��(����)��
ʵ�ֵ�α��������ͼ��ʾ:

??
??���� ICLR 2019 Prior convictions: Black-box adversarial attacks with bandits and priors. [15] �����ʹ������ַ�����ij������
f
f
f? ������
v
v
v? �����ϵĵ�
x
x
x? ���ķ�����
D
v
f
(
x
)
=
?
?
x
f
(
x
)
,
v
?
D_{v} f(x)=\left\langle\nabla_{x} f(x), v\right\rangle
Dv?f(x)=??x?f(x),v?? Ϊ:
D
v
f
(
x
)
=
?
?
x
f
(
x
)
,
v
?
��
(
f
(
x
+
��
v
)
?
f
(
x
)
)
��
(2.36)
D_{v} f(x)=\left\langle\nabla_{x} f(x), v\right\rangle \approx \dfrac {(f(x+\delta v)-f(x))}{\delta}\tag{2.36}
Dv?f(x)=??x?f(x),v?����(f(x+��v)?f(x))?(2.36)
��
>
0
\delta > 0
��>0???? Ϊ����,�����ݶȹ��Ƶ������� ���ھ��Ⱥ�����������,������С��õ���ȷ�Ĺ���,��ͬʱҲ�ή�Ϳɿ��ԡ� ���,��ʵ����,��
��
\delta
��???? ��Ϊһ���ɵ�����ʹ�á�
����ʹ��������������ݶȵĹ���,����ͨ��ʹ�����б�������
e
1
,
.
.
.
,
e
d
e_1,... , e_d
e1?,...,ed?????? �����ݶȵ��ڻ����ҵ��ݶȵ�
d
d
d????? ������:
?
^
x
L
(
x
,
y
)
=
��
k
=
1
d
e
k
(
L
(
x
+
��
e
k
,
y
)
?
L
(
x
,
y
)
)
��
��
��
k
=
1
d
e
k
?
?
x
L
(
x
,
y
)
,
e
k
?
(2.37)
\widehat{\nabla}_{x} L(x, y)=\sum_{k=1}^{d} e_{k}\dfrac {\left(L\left(x+\delta e_{k}, y\right)-L(x, y)\right)}{\delta} \approx \sum_{k=1}^{d} e_{k}\left\langle\nabla_{x} L(x, y), e_{k}\right\rangle\tag{2.37}
?
x?L(x,y)=k=1��d?ek?��(L(x+��ek?,y)?L(x,y))?��k=1��d?ek???x?L(x,y),ek??(2.37)
2.2.2.2 ��С���˷�
���� 13 :ʲô����С���˷�?���ʹ����С���˷�������Իع�����?
? ? ?\, ?��С���˷�?
??��С���˷��������õ���19���ͷ��ֵ�,��ʽ����ʽ:
�� �� �� = �� ( �� �� ֵ ? �� �� ֵ ) 2 (2.38) �꺯��=\sum(�۲�ֵ-����ֵ)^2\tag{2.38} ������=��(����ֵ?����ֵ)2(2.38)
�۲�ֵ�������ǵĶ�������,����ֵ�������ǵļ�����Ϻ�����Ŀ�꺯��Ҳ�����ڻ���ѧϰ�г�˵����ʧ����,���ǵ�Ŀ���ǵõ�ʹĿ�꺯����С��ʱ�����Ϻ�����ģ�͡�
??��һ��������Իع�ļ�����,���������� m m m ��ֻ��һ������������: ( x i , y i ) , i �� [ 1 , m ] (x_i,y_i),i\in[1,m] (xi?,yi?),i��[1,m]?����������һ��� f �� f_{\theta} f��? Ϊ�� n n n �Ķ���ʽ���, f �� = �� 0 + �� 1 x + �� 2 x 2 + ? + �� n x n f_{\theta}=\theta_0+\theta_1x+\theta_2x^2+\cdots+\theta_nx^n f��?=��0?+��1?x+��2?x2+?+��n?xn,���� �� i , i �� [ 1 , m ] \theta_i,i\in[1,m] ��i?,i��[1,m]? Ϊ��������С���˷�����Ҫ�ҵ�һ�� �� i , i �� [ 1 , m ] \theta_i,i\in[1,m] ��i?,i��[1,m]? ʹ�� �� i = 1 n ( f �� ( x i ) ? y i ) 2 \displaystyle \sum_{i=1}^{n}(f_{\theta}(x_i)-y_i)^2 i=1��n?(f��?(xi?)?yi?)2? ��С,����� min ? { �� i = 1 n ( f �� ( x i ) ? y i ) 2 } \min\{\displaystyle \sum_{i=1}^{n}(f_{\theta}(x_i)-y_i)^2\} min{i=1��n?(f��?(xi?)?yi?)2}?? ��
??���Ƿ�������һ�����κ���,���Ƕ�����,�ڵ���Ϊ 0 0 0 ��ʱ��ȡ����Сֵ���ɡ�
??�ص�����֮ǰ���۵���Ԫ����,��� w w w �� b b b ��ʹ��ʧ������С���Ĺ���,��ͳ����,��Ϊ���Իع�ģ�͵���С���˲������� (parameter estimation)�����ǿ��Խ� L ( w , b ) \mathcal{L}(w,b) L(w,b) �ֱ�� w w w �� b b b ��ƫ��,�õ�:
? L ? w = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? ? ( w x ( i ) + b ? y ( i ) ) ? w = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? x ( i ) = 2 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) ? x ( i ) (2.39) \begin{aligned}\frac{\partial \mathcal{L}}{\partial w}&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)}{\partial w} &\\&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot x^{(i)} &\\&=\frac{2}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right) \cdot x^{(i)}\end{aligned}\tag{2.39} ?w?L??=n1?i=1��n?2(wx(i)+b?y(i))??w?(wx(i)+b?y(i))?=n1?i=1��n?2(wx(i)+b?y(i))?x(i)=n2?i=1��n?(wx(i)+b?y(i))?x(i)??(2.39)
�Լ�
? L ? b = ? 1 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) 2 ? b = 1 n �� i = 1 n ? ( w x ( i ) + b ? y ( i ) ) 2 ? b = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? ? ( w x ( i ) + b ? y ( i ) ) ? b = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? 1 = 2 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) (2.40) \begin{aligned}\dfrac{\partial \mathcal{L}}{\partial b}&=\dfrac{\displaystyle \partial \dfrac{1}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right)^{2}}{\partial b}\\&=\frac{1}{n} \sum_{i=1}^{n} \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)^{2}}{\partial b} &\\&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)}{\partial b} &\\&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot 1 &\\&=\frac{2}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right)\end{aligned}\tag{2.40} ?b?L??=?b?n1?i=1��n?(wx(i)+b?y(i))2?=n1?i=1��n??b?(wx(i)+b?y(i))2?=n1?i=1��n?2(wx(i)+b?y(i))??b?(wx(i)+b?y(i))?=n1?i=1��n?2(wx(i)+b?y(i))?1=n2?i=1��n?(wx(i)+b?y(i))??(2.40)
��������ʽΪ 0 0 0?,���ɵõ� w w w? �� b b b? ���Ž�ı�ʽ(closed-form)�⡣
? ? ?\, ?��С���˷��ľ��ⷨ(ѡѧ)
??��С���˷��Ĵ������ⷨ���Ƕ� �� i \theta_i ��i? ��ƫ����,��ƫ����Ϊ 0,�ٽⷽ����,�õ� �� i \theta_i ��i?�����ȴ�����Ҫ��ࡣ
??�����ö�Ԫ���Իع�����������:���躯��
f
��
(
x
1
,
x
2
,
��
,
x
n
)
=
��
0
+
��
1
x
1
+
?
+
��
n
x
n
f_{\theta}(x_1,x_2,\dots,x_n)=\theta_0+\theta_1x_1+\cdots+\theta_nx_n
f��?(x1?,x2?,��,xn?)=��0?+��1?x1?+?+��n?xn? �ľ�����﷽ʽΪ:
f
��
(
X
)
=
X
��
(2.41)
f_{\theta}(\boldsymbol X)=\boldsymbol X\theta\tag{2.41}
f��?(X)=X��(2.41)
??����, ���躯�� f �� ( X ) = X �� f_{\theta}(\boldsymbol X)=\boldsymbol X\theta f��?(X)=X�� Ϊ m �� 1 m\times 1 m��1 ������, �� \theta �� Ϊ n �� 1 n\times 1 n��1������,������ n n n ����������ģ�Ͳ����� X \boldsymbol X X Ϊ n �� m n\times m n��m ά�ľ��� m m m ���������ĸ���, n n n ������������������
��ʧ��������Ϊ
g
(
��
)
=
1
2
(
X
��
?
Y
)
T
(
X
��
?
Y
)
(2.42)
g({\theta}) = \dfrac 1 2(\boldsymbol X\theta-\boldsymbol Y)^\mathrm{T}(\boldsymbol X\theta-\boldsymbol Y)\tag{2.42}
g(��)=21?(X��?Y)T(X��?Y)(2.42)
??���� Y \boldsymbol {Y} Y ���������������,ά��Ϊ m �� 1 m\times 1 m��1�� 1 2 \dfrac 1 2 21? ������Ҫ��Ϊ����ϵ��Ϊ 1 1 1,������㡣
??������С���˷���ԭ��,����Ҫ�������ʧ������
��
\theta
�� ������ȡ
0
0
0���������ʽ:
?
g
(
��
)
?
��
=
X
T
(
X
��
?
Y
=
0
(2.43)
\dfrac {\partial g(\theta)}{\partial \theta}=\boldsymbol {X}^{\mathrm{T}}(\boldsymbol {X}\theta-\boldsymbol {Y}=0\tag{2.43}
?��?g(��)?=XT(X��?Y=0(2.43)
�����ɵ�:
��
=
(
X
T
X
)
?
1
X
T
Y
(2.44)
\theta=(\boldsymbol {X}^{\mathrm T}\boldsymbol {X})^{-1}\boldsymbol {X}^{\mathrm{T}}\boldsymbol {Y}\tag{2.44}
��=(XTX)?1XTY(2.44)
? ? ?\, ?��С���˷��ľ����Ժ����ó���
-
��С���˷���Ҫ���� X T X \boldsymbol {X}^{\mathrm{T}}\boldsymbol {X} XTX �������,�п��������������,������û�а취ֱ������С���˷���,��ʱ�ݶ��½�����Ȼ����ʹ�á���Ȼ,���ǿ���ͨ�����������ݽ�������,ȥ�������������� X T X \boldsymbol {X}^{\mathrm{T}}\boldsymbol {X} XTX ������ʽ��Ϊ 0 0 0 ,Ȼ�����ʹ����С���˷���
-
���������� n n n �dz��Ĵ��ʱ��,���� X T X {\boldsymbol X}^{\mathrm{T}}\boldsymbol {X} XTX ���������һ���dz���ʱ�Ĺ���( n �� n n\times n n��n �ľ�������),���������С�����ʱ���ݶ��½�Ϊ�����ĵ�������Ȼ����ʹ�á���ʱ����ͨ�����ɷַ�������������ά�Ⱥ�������С���˷���
-
�����Ϻ����������Ե�,��ʱ��ʹ����С���˷�,��Ҫͨ��һЩ����ת��Ϊ���Բ���ʹ��,��ʱ�ݶ��½���Ȼ�����á�
2.2.3 ��Ԫ����ģ��ʵս
���� 14 :�����Ҷ���,��ô�ô���ʵ�ֲ������Ԫ����ģ����?
??����������Ԫ����ģ�͵�ԭ���Լ������Ż��㷨�Ժ�,������ʵսѵ����������Ԫ����ģ�͡�
??��������������Ҫ�İ���
?In? [ 1 ] : \text { In }[1]: ?In?[1]:
import numpy as np
import math
# cal y = 1.477x + 0.089 + epsilon,epsilon ~ N(0, 0.01^2)
1. �������ݼ�
??������Ҫ��������ʵģ�͵Ķ�������,������֪��ʵģ�͵� ������� (Toy Example),����ֱ�Ӵ�ָ����
w
=
1.477
,
b
=
0.089
w = 1.477 , b = 0.089
w=1.477,b=0.089 ����ʵģ����ֱ�Ӳ���:
y
=
1.477
��
x
+
0.089
(2.45)
y=1.477 \times x+0.089\tag{2.45}
y=1.477��x+0.089(2.45)
??Ϊ���ܹ��ܺõ�ģ����ʵ�����Ĺ۲����,���Ǹ�ģ����������Ա���
?
\epsilon
? ,�������Ծ�ֵΪ
0
0
0 ,����Ϊ
0.01
0.01
0.01 �ĸ�˹�ֲ�:
y
=
1.477
x
+
0.089
+
?
,
?
��
N
(
0
,
0.01
)
(2.46)
y=1.477 x+0.089+\epsilon, \epsilon \sim \mathcal{N}(0,0.01)\tag{2.46}
y=1.477x+0.089+?,?��N(0,0.01)(2.46)
??����ͨ��������� n = 100 n = 100 n=100 ��,���ǻ�� n n n ��������ѵ�����ݼ� D t r a i n \mathbb D_{\mathrm{train}} Dtrain? ,Ȼ��ѭ������ 100 100 100 �β���,ÿ�δӾ��ȷֲ� U ( ? 10 , 10 ) U ( -10,10) U(?10,10) ���������һ������ x x x ͬʱ�Ӿ�ֵΪ 0 0 0 ,����Ϊ 0. 1 2 0.1^{2} 0.12 �ĸ�˹�ֲ� N ( 0 , 0. 1 2 ) \mathcal{N}\left(0,0.1^{2}\right) N(0,0.12) ������������� ? \epsilon ?,������ʵģ������ y y y ������,������Ϊ Numpy \text{Numpy} Numpy ���顣
?In? [ 2 ] : \text { In }[2]: ?In?[2]:
def get_data():
# ����������
#�������������б�
data = []
for i in range(100):
x = np.random.uniform(-10., 10.) # ������� x
# ��˹����
eps = np.random.normal(0., 0.01) # ��ֵ�ͷ���
# �õ�ģ�͵����
y = 1.477 * x + 0.089 + eps
# ����������
data.append([x, y])
# ת��Ϊ2D Numpy����
data = np.array(data)
return data
2. �������
??ѭ��������ÿ���� ( x ( i ) , y ( i ) ) \left(x^{(i)}, y^{(i)}\right) (x(i),y(i)) ����Ԥ��ֵ����ʵֵ֮����ƽ�����ۼ�,�Ӷ����ѵ�����ϵľ�������ʧֵ��
??�������ͳ���������������,�Ӷ��õ�ÿ�������ϵ�ƽ����
?In? [ 3 ] : \text { In }[3]: ?In?[3]:
def mse(b, w, points) :
totalError = 0
# ���ݵ�ǰ��w,b���������������ʧ
for i in range(0, len(points)) : # ѭ���������е�
# ��� i �ŵ������ x
x = points[i, 0]
# ��� i �ŵ����� y
y = points[i, 1]
# ������ƽ��,���ۼ�
totalError += (y - (w * x + b)) ** 2
# ���ۼӵ������ƽ��,�õ��������
return totalError / float(len(points))
3. �����ݶ�
??��������ʹ�ø��Ӽ��õ��ݶ��½��㷨��������Ҫ�����������ÿһ�����ϵ��ݶ���Ϣ: ( ? L ? w , ? L ? b ) \left(\dfrac{\partial \mathcal{L}}{\partial w}, \dfrac{\partial \mathcal{L}}{\partial b}\right) (?w?L?,?b?L?)���������Ƶ�һ���ݶȵı���ʽ,���ȿ��� ? L ? w \dfrac{\partial \mathcal{L}}{\partial w} ?w?L? ,���������չ��:
? L ? w = ? 1 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) 2 ? w = 1 n �� i = 1 n ? ( w x ( i ) + b ? y ( i ) ) 2 ? w (2.47) \begin{aligned}\frac{\displaystyle \partial \mathcal{L}}{\partial w}&=\frac{\displaystyle \partial \frac{1}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right)^{2}}{\partial w}&\\&=\frac{1}{n} \sum_{i=1}^{n} \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)^{2}}{\partial w}\end{aligned}\tag{2.47} ?w?L??=?w?n1?i=1��n?(wx(i)+b?y(i))2?=n1?i=1��n??w?(wx(i)+b?y(i))2???(2.47)
����:
? g 2 ? w = 2 ? g ? ? g ? w (2.48) \frac{\partial g^{2}}{\partial w}=2 \cdot g \cdot \frac{\partial g}{\partial w}\tag{2.48} ?w?g2?=2?g??w?g?(2.48)
����:
? L ? w = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? ? ( w x ( i ) + b ? y ( i ) ) ? w = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? x ( i ) = 2 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) ? x ( i ) (2.49) \begin{aligned}\frac{\partial \mathcal{L}}{\partial w}&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)}{\partial w} &\\&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot x^{(i)} &\\&=\frac{2}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right) \cdot x^{(i)}\end{aligned}\tag{2.49} ?w?L??=n1?i=1��n?2(wx(i)+b?y(i))??w?(wx(i)+b?y(i))?=n1?i=1��n?2(wx(i)+b?y(i))?x(i)=n2?i=1��n?(wx(i)+b?y(i))?x(i)??(2.49)
? L ? b = ? 1 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) 2 ? b = 1 n �� i = 1 n ? ( w x ( i ) + b ? y ( i ) ) 2 ? b = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? ? ( w x ( i ) + b ? y ( i ) ) ? b = 1 n �� i = 1 n 2 ( w x ( i ) + b ? y ( i ) ) ? 1 = 2 n �� i = 1 n ( w x ( i ) + b ? y ( i ) ) (2.50) \begin{aligned}\dfrac{\partial \mathcal{L}}{\partial b}&=\dfrac{\displaystyle \partial \dfrac{1}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right)^{2}}{\partial b}\\&=\frac{1}{n} \sum_{i=1}^{n} \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)^{2}}{\partial b} &\\&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot \frac{\partial\left(w x^{(i)}+b-y^{(i)}\right)}{\partial b} &\\&=\frac{1}{n} \sum_{i=1}^{n} 2\left(w x^{(i)}+b-y^{(i)}\right) \cdot 1 &\\&=\frac{2}{n} \sum_{i=1}^{n}\left(w x^{(i)}+b-y^{(i)}\right)\end{aligned}\tag{2.50} ?b?L??=?b?n1?i=1��n?(wx(i)+b?y(i))2?=n1?i=1��n??b?(wx(i)+b?y(i))2?=n1?i=1��n?2(wx(i)+b?y(i))??b?(wx(i)+b?y(i))?=n1?i=1��n?2(wx(i)+b?y(i))?1=n2?i=1��n?(wx(i)+b?y(i))??(2.50)
??��������ƫ�����ı���ʽ,����ֻ��Ҫ������ÿһ��������� ( w x ( i ) + b ? y ( i ) ) \left(w x^{(i)}+b-y^{(i)}\right) (wx(i)+b?y(i))? �� ( w x ( i ) + b ? y ( i ) ) \left(w x^{(i)}+b-y^{(i)}\right) (wx(i)+b?y(i))?ֵ,ƽ���ɵõ�ƫ���� ? L ? w \dfrac{\partial \mathcal{L}}{\partial w} ?w?L?? �� ? L ? b \dfrac{\partial \mathcal{L}}{\partial b} ?b?L??? ��
?In? [ 4 ] : \text { In }[4]: ?In?[4]:
# ����ƫ����
def step_gradient(b_current, w_current, points, lr) :
# �������������е��ϵ�����,������w,b
b_gradient = 0
w_gradient = 0
# ��������
M = float(len(points))
for i in range(0, len(points)) :
x = points[i, 0]
y = points[i, 1]
# ƫb
b_gradient += (2 / M) * ((w_current * x + b_current) - y)
# ƫw
w_gradient += (2 / M) * x * ((w_current * x + b_current) - y)
# �����ݶ��½��㷨���µ� w',b',����lrΪѧϰ��
new_b = b_current - (lr * b_gradient)
new_w = w_current - (lr * w_gradient)
return [new_b, new_w]
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
# �ݶȸ���
def gradient_descent(points, starting_b, starting_w, lr, num_iterations) :
b = starting_b
w = starting_w
MSE = []
Epoch = []
for step in range(num_iterations) :
b, w = step_gradient(b, w, np.array(points), lr)
# ���㵱ǰ�ľ������,���ڼ��ѵ������
loss = mse(b, w, points)
MSE.append(loss)
Epoch.append(step)
if step % 50 == 0 :
print(f"iteration:{step}, loss:{loss}, w:{w}, b:{b}")
plt.plot(Epoch, MSE, color='C1', label='������')
plt.xlabel('epoch')
plt.ylabel('MSE')
plt.title('MSE function')
plt.legend(loc = 1)
plt.show()
return [b, w]
4. ������
?In? [ 5 ] : \text { In }[5]: ?In?[5]:
def solve(data) :
# ѧϰ��
lr = 0.01
initial_b = 0
initial_w = 0
num_iterations = 1000
[b, w] = gradient_descent(data, initial_b, initial_w, lr, num_iterations)
loss = mse(b, w, data)
print(f'Final loss:{loss}, w{w}, b{b}')
if __name__ == "__main__":
data = get_data()
solve(data)
?Out? [ 5 ] : \text { Out }[5]: ?Out?[5]:
iteration:0, loss:8.52075121569461, w:0.9683621336270813, b:0.018598967590321615
iteration:50, loss:0.0005939300597845278, w:1.477514542941938, b:0.06613823978315139
iteration:100, loss:0.00016616611251547874, w:1.4772610937560182, b:0.08026637756911292
iteration:150, loss:0.00010824080152649426, w:1.4771678278317757, b:0.08546534407456151
iteration:200, loss:0.00010039689211198855, w:1.4771335072140424, b:0.08737849449355252
iteration:250, loss:9.933471542527609e-05, w:1.4771208776838989, b:0.08808250836281861
iteration:300, loss:9.919088162325623e-05, w:1.477116230185043, b:0.08834157608859644
iteration:350, loss:9.917140448460003e-05, w:1.4771145199673728, b:0.08843690956066241
iteration:400, loss:9.916876700352793e-05, w:1.477113890630052, b:0.08847199100845321
iteration:450, loss:9.916840985114966e-05, w:1.4771136590423013, b:0.08848490051392309
iteration:500, loss:9.916836148764827e-05, w:1.4771135738210939, b:0.08848965103996947
iteration:550, loss:9.916835493854371e-05, w:1.4771135424608248, b:0.08849139917027324
iteration:600, loss:9.916835405170177e-05, w:1.4771135309206636, b:0.08849204245893828
iteration:650, loss:9.916835393161082e-05, w:1.4771135266740378, b:0.08849227918059785
iteration:700, loss:9.916835391534817e-05, w:1.4771135251113363, b:0.08849236629101521
iteration:750, loss:9.916835391314785e-05, w:1.477113524536283, b:0.08849239834648838
iteration:800, loss:9.916835391284828e-05, w:1.477113524324671, b:0.08849241014247554
iteration:850, loss:9.916835391280702e-05, w:1.4771135242468005, b:0.08849241448324166
iteration:900, loss:9.916835391280325e-05, w:1.4771135242181452, b:0.08849241608058574
iteration:950, loss:9.916835391280336e-05, w:1.4771135242076006, b:0.08849241666838711

Final loss:9.916835391280157e-05, w1.4771135242037658, b0.08849241688214672
?���ǿ��Կ���,�� 100 100 100 �ε���ʱ, 𝑤 𝑤 w �� 𝑏 𝑏 b ��ֵ���Ѿ��ȽϽӽ���ʵģ����,���� 1000 1000 1000 �κ�õ��� w ? , b ? w^{*}, b^{*} w?,b?? ��ֵ������ʵģ�͵ķdz��ӽ���
2.3 ��̽�ع�
���� 15 :����ģ���Ѿ���ȫѧ����!������ɷ����Ե�ģ����ô����?
??����������һ���ع�Ԥ������:ʹ�ú�̨����Ԥ��youtube�˺ŵڶ���Ĺۿ�����
??���ڹۿ��������ڵı仯,��Ȼ��������ģ�;Ϳ��Ա�ʾ�ġ�����ģ���ǻ���ѧϰ�м������ѧģ��֮һ,��������,�����,����ֻ�ܱ������Թ�ϵ��һ��ֱ��������������������,�����ܺܺõ���ϳ���ʵ��ģ��:
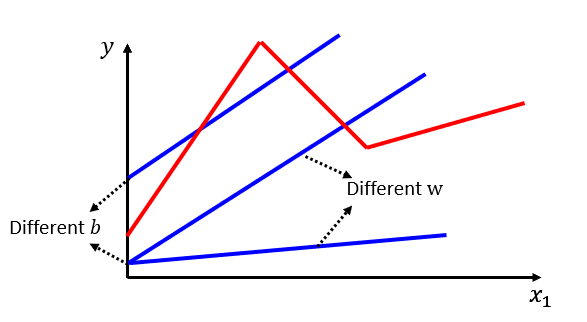
??
��α�ʾ���Ӹ��ӵ�ģ��,���е��Ե�ģ�;�����������,�����Ը��Ӿ��������������⡣��ȻֻҪ���㹻��ķֶ��������߾Ϳ��Աƽ��������ߡ�
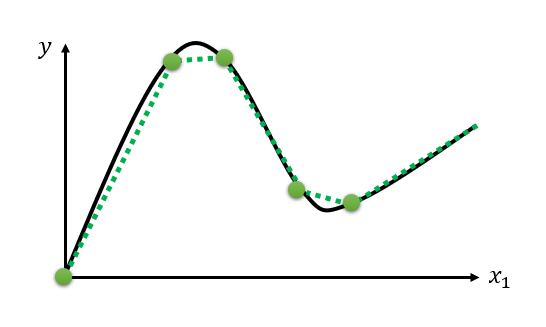
??
��ô��λ��һ���ֶ�����������?һ����Ȼ��˼·�ǽ������������߷ֶκ�ϲ�������һ�����������߽���ƽ�Ƽ��ɵõ�һ���ֶ���������:

??
����������һ������,��ֱ����ɵķֶ���������,��ת�Ǵ���������,Ҳ�Ͳ���ʹ���ݶ��½��㷨�����Ż����㡣
2.3.1 ������ģ��
? ? ? ���������ģ��
??���ѧϰϣ��ʹ����Ԫ�õ���Ҫ�ĺ����Ĵ��µı���,ͨ��ʹ�ô���������ȥ������ϳ���������ĸ�������,�������ճ�������������״��
Ϊ���ܹ���Ϸ����Եĺ���,���ǿ���Ϊ���������ӷ���������,ʹ������������ĺ�����Ҳ���Ǹ�ԭ�ȵ�����ģ��Ƕ��һ�������Ժ���,���ɽ�����ģ��ת��Ϊ������ģ�͡����ǰ���������Ժ�����Ϊ�����(Activation function),�� �� \sigma �� ��ʾ������ģ�;�ת��Ϊ��:
o = �� ( W x + b ) (2.51) \boldsymbol{o}=\sigma(\boldsymbol{W} \boldsymbol{x}+\boldsymbol{b})\tag{2.51} o=��(Wx+b)(2.51)
����� �� \sigma �� ������ij������ķ����Լ����,���� Sigmoid ����:
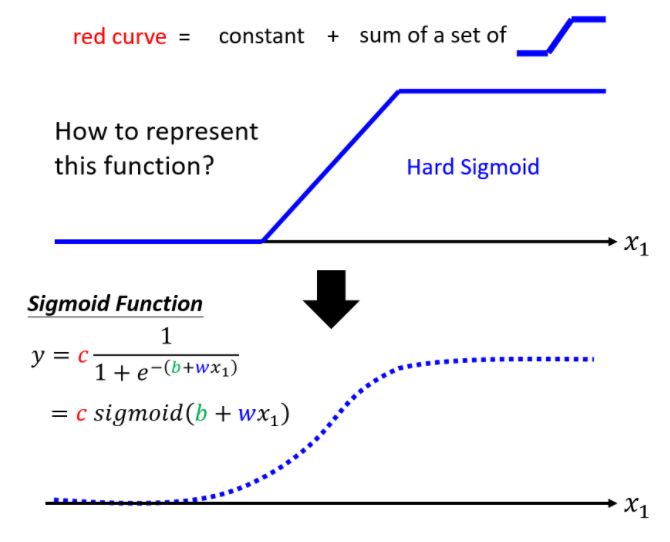
??
? ? ? Sigmoid(S������)
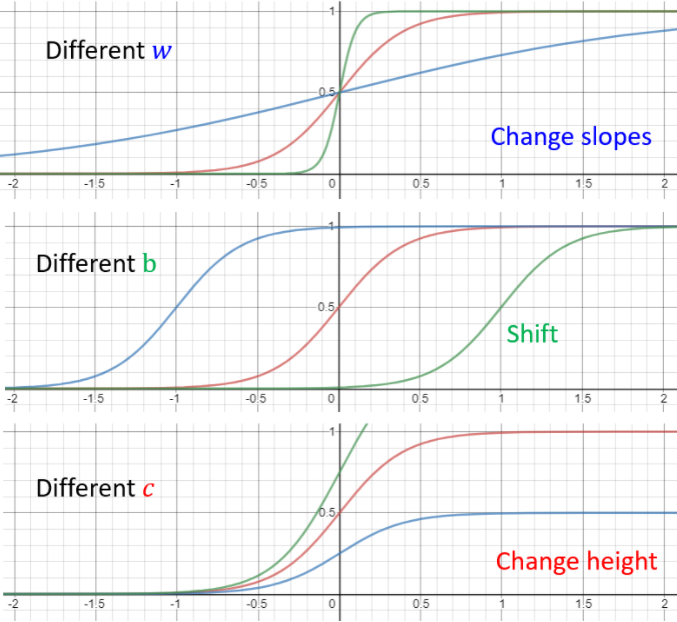
??ͨ������ Sigmoid �����е��������� c , b , w c,b,w c,b,w ����ʵ�ָ��ָ����� S �����ߡ��ı� w w w ���Ըı� S �����ߵ��¶�;�ı� b b b ����ʹ S �����������ƶ�;�ı� c c c ���Ըı� S �����ߵ����¸߶ȡ�
??
���ǽ��ֶ�ֱ���ھ��������֮���ٽ�����ϼ��ɵõ������Ե�ģ�͡�
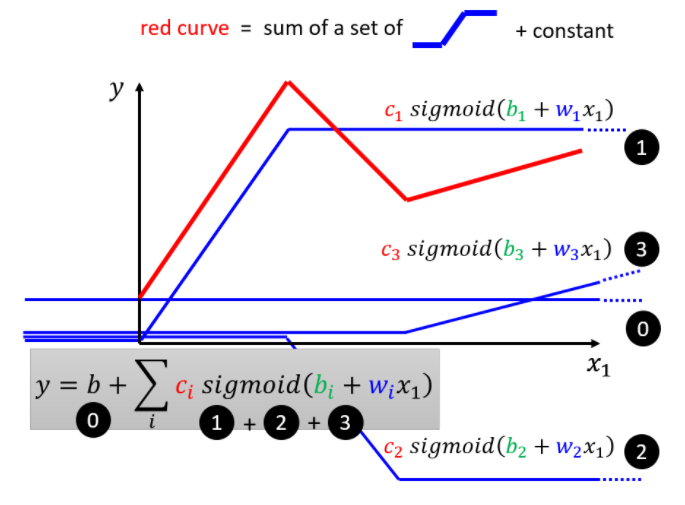
??
��������Ϊ��ԭ���������滻Ϊ������,����������ƴ�Ӷ��ɼ����������һ�������Եĺ�����
2.4 ������Ŀ����
��С�� 2.4 ������Ŀ���� ���ռ�����Ŀ�ʹ𰸴�����������ϵĸ���,����������� 2.5 �ο����� [7] [8] [9]��
? ? ? 1. ����һ�����Իع� (Linear Regression) ��ԭ����
���Թ�ϵ�����������߶������֮��Ĺ�ϵ����һ�κ�����ϵ,��Ӧ��ͼ���Ͼ���һ��ֱ�ߡ��������֮��Ĺ�ϵ������һ�κ���,ͼ��Ͳ���ֱ��,Ҳ���������Թ�ϵ��
�ع���ָԤ��,ϣ��ͨ������ع鵽��ʵֵ��
���Իع�������Ԥ��������мලѧϰ,��һ���������Իع鷽�̵���Сƽ��������һ�������Ա����������֮��ӳ���ϵ���н�ģ������ѧϰ����ӳ���ϵʵ�ֶ�δ֪�����ݽ���Ԥ���һ�ֻع���������ֺ�����һ��������Ϊ�ع�ϵ����ģ�Ͳ�����������ϡ�ֻ��һ���Ա����������Ϊ�ع�,����һ���Ա�������Ľ�����Ԫ�ع顣�������Իع黹��һ������ֵ��
? ? ? 2.���Իع�ļ��躯����ʲô��ʽ?
y ^ i = �� 0 x 0 + �� 1 x 1 + �� 2 x 2 �� + �� n x n = �� ? X (2.52) \hat y_i=\theta_{0} x_{0}+\theta_{1} x_{1}+\theta_{2} x_{2} \ldots+\theta_{n} x_{n}=\boldsymbol {\theta}^\top \boldsymbol X\tag{2.52} y^?i?=��0?x0?+��1?x1?+��2?x2?��+��n?xn?=��?X(2.52)
���� x 0 = 1 x_0=1 x0?=1 Ҳ��ֱ�Ӽ���ƫ�� �� 0 \theta_0 ��0? , �� , X \boldsymbol {\theta}, \boldsymbol X ��,X ������������
X \boldsymbol X X Ϊ����, y y y Ϊ��ǩֵ, y ^ \hat y y^? ΪԤ��ֵ,ע�����Իع�ʵ���ϼȿ��Դ����ع�����Ҳ���Դ�����������,ֻ������Է��������0-1����ı�ǩ,���Իع�����������
? ? ? 3.���Իع�Ĵ���(��ʧ)������ʲô��ʽ?
Ĭ������С����ʧ����:
J ( �� ) = 1 2 m �� i = 1 m ( h �� ( x ( i ) ) ? y ( i ) ) 2 (2.53) J(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}\tag{2.53} J(��)=2m1?i=1��m?(h��?(x(i))?y(i))2(2.53)
? ? ? 4. Ϊʲô���Իع�ʹ�õ���ƽ������ʽ����ʧ����?
ʹ��ƽ����ʽ��ʱ��,ʹ�õ��ǡ���С���˷�����˼��,����ġ����ˡ�ָ������ƽ���������۲������Ƶ�ľ���(Զ��),����С��ָ���Dz���ֵҪ��֤�����۲������Ƶ�ľ����ƽ���ʹﵽ��С����С���˷��Թ���ֵ��۲�ֵ��ƽ������Ϊ��ʧ����,����������̬�ֲ���ǰ����(��һ�����ױ�����),�뼫����Ȼ���Ƶ�˼���ڱ���������ͬ��Ҳ����˵������������ȥѡ��mse��Ϊ���Իع����ʧ����������Ϊ���Ǽ�����������̬�ֲ�,ʹ�ü�����Ȼ��(��������ĿΪ��i������������ֵĸ������)��������,��һ�������Ƶ�֮��õ���mse�Ĺ�ʽ����,�������̼���:
������۲������Ԥ������֮������Ϊ:
�� i = y i ? y ^ i (2.54) \varepsilon_{i}=y_{i}-\hat{y}_{i}\tag{2.54} ��i?=yi??y^?i?(2.54)
����ͨ����Ϊ �� \varepsilon �� ������̬�ֲ�,��:
f ( �� i ; u , �� 2 ) = 1 �� 2 �� �� exp ? [ ? ( �� i ? u ) 2 ( 2 �� 2 + 1 ] (2.55) f\left(\varepsilon_{i} ; u, \sigma^{2}\right)=\frac{1}{\sigma \sqrt{2 \pi}} \times \exp \left[-\frac{\left(\varepsilon_{i}-u\right)^{2}}{\left(2 \sigma^{2}+1\right.}\right]\tag{2.55} f(��i?;u,��2)=��2��?1?��exp[?(2��2+1(��i??u)2?](2.55)
������IJ��� �� �� �� �ļ�����Ȼ���� ( u , �� 2 ) (u,��^2) (u,��2) ,����˵,��ij�� ( u , �� 2 ) (u,��^2) (u,��2) ��,ʹ�÷�����̬�ֲ��� �� �� �� ȡ������������i�ĸ������Ҳ����˵ʵ�������ǵ���ԭʼ��Ŀ����ʹ�������̬�ֲ�����ʽ�����˵ļ�����Ȼ�������
��ô���ݼ�����Ȼ���ƺ����Ķ���,��:
L ( u , �� 2 ) = �� i = 1 n 1 2 �� �� �� exp ? ( ? ( �� i ? u ) 2 ( �� j �� 2 + 1 ) ) (2.56) L\left(u, \sigma^{2}\right)=\prod_{i=1}^{n} \frac{1}{\sqrt{2 \pi} \sigma} \times \exp \left(-\frac{\left(\varepsilon_{i}-u\right)^{2}}{\left(\rho_{j} \pi^{2}+1\right)}\right)\tag{2.56} L(u,��2)=i=1��n?2��?��1?��exp(?(��j?��2+1)(��i??u)2?)(2.56)
ȡ������Ȼ����:
log ? L ( u , �� 2 ) = ? n 2 log ? �� 2 ? n 2 log ? 2 �� ? �� i = 1 n ( �� i ? u ) 2 2 �� 2 (2.57) \log L\left(u, \sigma^{2}\right)=-\frac{n}{2} \log \sigma^{2}-\frac{n}{2} \log 2 \pi -\cfrac { \displaystyle \sum_{i=1}^{n}\left(\varepsilon_{i}-u\right)^{2}}{2\sigma^2}\tag{2.57} logL(u,��2)=?2n?log��2?2n?log2��?2��2i=1��n?(��i??u)2?(2.57)
�ֱ��� ( u , �� 2 ) (u,��^2) (u,��2) ��ƫ����,Ȼ���� 0 0 0 ,�����ò��� ( u , �� 2 ) (u,��^2) (u,��2) �ļ�����Ȼ����Ϊ:
u = 1 n �� i = 1 n �� i �� 2 = 1 n �� i = 1 n ( �� i ? u ) 2 (2.58) \begin{array}{c}\displaystyle u=\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i} \\\displaystyle \sigma^{2}=\frac{1}{n} \sum_{i=1}^{n}\left(\varepsilon_{i}-u\right)^{2}\end{array}\tag{2.58} u=n1?i=1��n?��i?��2=n1?i=1��n?(��i??u)2?(2.58)
���������Իع���Ҫ���������ֱ��:
y ^ i = �� ? X (2.59) \hat y_i=\boldsymbol {\theta}^\top \boldsymbol X\tag{2.59} y^?i?=��?X(2.59)
ʵ��������Ԥ��ֵ y ^ i \hat y_i y^?i?��۲�ֵ y i y_i yi? ֮������ �� i ��_i ��i? ��С(�����û�����)������� �� �� �� ��ֵ������ �� �� �� �Ƿ��Ӳ��� ( u , �� 2 ) (u,��^2) (u,��2) ����̬�ֲ�,�������Ǿ�ֵ u u u �ͷ��� �� �� �� ������ 0 0 0 ��ԽСԽ��,���ݱ���ʽ��֪,��ֵ�ͷ���ԽС,������Ȼ����Խ��:
-
u = 1 n �� ( y i ? y ^ i ) u=\cfrac 1 n\times (y_i?\hat y_i) u=n1?��(yi??y^?i?) Խ������ 0 0 0 Խ��Ҳ��ԽСԽ�á�
-
�� 2 = 1 n �� ( y i ? y ^ i ? u ) 2 �� 1 n �� ( y i ? y ^ i ) 2 ��^2=\cfrac 1 n\times (y_i?\hat y_i?u)^2��\cfrac 1 n\times (y_i?\hat y_i)^2 ��2=n1?��(yi??y^?i??u)2��n1?��(yi??y^?i?)2 ������ 0 0 0 Խ��Ҳ��ԽСԽ�á�
������ǰ�湹����ƽ����ʽ��ʧ�����������ǵȼ۵ġ�
? ? ? 5. ���Իع�ΪʲôҪ�������������̬�ֲ�
���Իع�ļ���ǰ����������Ԥ��ֵ�����Թ�ϵ,�������ϸ�˹ - �����Ʒ�����(���ֵ,�㷽��,�����),��ʱ�����Իع�����ƫ���ơ�����������̬�ֲ�,��ô�����Ҳ���Ϸֲ����ڽ������Իع�֮ǰ,Ҫ����������Ʒ�����̬�ֲ�,�������Իع�Ч������(��ƫ����)��
? ? ? 6. ���й������Իع�˵���������(D)
A. ������ģ����,�����µı���,���õ���R^2��ֵ�ܻ����ӡ�
B. ���Իع��ǰ�����֮һ�Dzв������Ӷ�����̬�ֲ���
C. �в�ķ�����ƫ������ S S E n ? p \cfrac {SSE}{n-p} n?pSSE?��
D. �Ա����Ͳвһ�������������
A: R 2 R^2 R2 ������Ŷ�, R 2 = S S R S S T = 1 ? S S E S S T R2=\cfrac {SSR}{SST}=1-\cfrac {SSE}{SST} R2=SSTSSR?=1?SSTSSE?, S S T SST SST ����ƽ����, S S R SSR SSR �ǻع�ƽ����, S S E SSE SSE �Dzв�ƽ����,��ʽ����:
y �� = 1 n �� i = 1 n y i S S tot = �� i ( y i ? y �� ) 2 S S reg = �� i ( f i ? y �� ) 2 S S res = �� i ( y i ? f i ) 2 = �� i e i 2 R 2 = 1 ? S S res S S tot = S S reg S S tot (2.60) \begin{aligned}&\overline{\mathrm{y}}=\frac{1}{n} \sum_{i=1}^{n} y_{i} \\ &S S_{\text{tot}}=\sum_{i}\left(y_{i}-\overline{\mathrm{y}}\right)^{2} \\&S S_{\text{reg}}=\sum_{i}\left(f_{i}-\overline{\mathrm{y}}\right)^{2} \\&S S_{\text{res}}=\sum_{i}\left(y_{i}-f_{i}\right)^{2}=\sum_{i} e_{i}^{2} \\&R^{2}=1-\frac{S S_{\text{res}}}{S S_{\text{tot}}}=\frac{S S_{\text{reg}}}{S S_\text{{tot}}}\end{aligned}\tag{2.60} ?y?=n1?i=1��n?yi?SStot?=i��?(yi??y?)2SSreg?=i��?(fi??y?)2SSres?=i��?(yi??fi?)2=i��?ei2?R2=1?SStot?SSres??=SStot?SSreg???(2.60)
�ӹ�ʽ�ϱȽϺ�����, R 2 = S S reg S S tot R^2=\cfrac {SS_{\text{reg}}} {SS_{\text{tot}}} R2=SStot?SSreg?? ��ʾ�����Ա�������ı䶯ռ�ܱ䶯�İٷֱ�,ֵԽ��,˵���в��Ӱ��Խ������,��Ȩ�ز��ֵ�Ԥ��Ч��Խ�á��ӹ�ʽ�Ͽ��Կ���,��Ϊ S S tot SS_{\text{tot}} SStot? �Dz����,�����µı���,����� S S reg SS_{\text{reg}} SSreg? ,���� f i f_i fi? ���������µı�������,����ԭ���� w 1 x 1 + w 2 x 2 + w 3 x 3 w_1x_1+w_2x_2+w_3x_3 w1?x1?+w2?x2?+w3?x3? ,����½������� x 4 x_4 x4? ʵ��̫��,�ٲ�������Ҳ��������Ȩ�� w 4 = 0 w_4=0 w4?=0 �Ӷ�ѵ��������� x 4 x_4 x4? ֮ǰ��ģ��һ����ģ��(Ҳ���Դ� pac���������з���),��Ȼ�õ��� R 2 R^2 R2 ��ֵ�ܻ����ӡ�
B:���Իع��ǰ�����֮һ�Dzв������Ӷ�����̬�ֲ�,���Իع����ʧ����mse����:��ij�� ( u , �� 2 ) (u,��^2) (u,��2) ��,ʹ�÷�����̬�ֲ��Ħ�ȡ������������i�ĸ������Ӷ������������ʧ�����ı���ʽ��
C:�в�ķ�����ƫ������ S S E n ? p \cfrac {SSE}{n-p} n?pSSE? ,���� p p p ������������,����Ϊʲô,�ʾ�˵���ǹ�ʽ(
D:����,�в�������������̬�ֲ��ŷ������Իع�Ķ��塣
? ? ? 7. �����Իع�������,����ʹ�þ���ϵ�� (R-squared)����������Ŷȡ����������Իع�ģ��������һ������ֵ,��������ͬ��ģ�͡�����˵����ȷ����(C)
A. ���R-Squared����,���������������
B . ���R-Squared��С,���������������
C. �����۲�R-Squared�ı仯����,���ж���������Ƿ�����
D. ���ϽԷ�
R-squared ��������˵�� R 2 R^2 R2 ,�жϱ����Ƿ�����,��Ҫ���ݱ�����Ӧ��Ȩ��ϵ�� W W W ,���� R 2 R^2 R2 ��ֱ�ӹ�ϵ��
? ? ? 8. ��д��������Ԥ������������δ�����������
8.1 Ϊ��Ԥ��Ħ��ÿ�충����,���ǽ�����һ�����Իع�ģ��,������һ���Ա���Ϊ��������(�������),��Ϊ�硢����������ɳ�������ꡢѩ��6������,������δ������ֱ���
8.2 ��Ȼ�� �� �е����Իع�ģ��,������һ���Ա���Ϊÿ������������,�������������1/4��������ȱʧֵ,��д���������ִ���ȱʧֵ�ķ���
8.3 ��Ȼ�� �� �е�ģ��,�����Ա�����4��,���ǵ����ϵ����������:
[ 1 ? 0.307 0.338 0.302 ? 0.307 1 ? 0.831 ? 0.410 0.338 ? 0.831 1 0.360 0.302 ? 0.410 0.360 1 ] (2.61) \left[\begin{array}{cccc}1 & -0.307 & 0.338 & 0.302 \\-0.307 & 1 & -0.831 & -0.410 \\0.338 & -0.831 & 1 & 0.360 \\0.302 & -0.410 & 0.360 & 1\end{array}\right]\tag{2.61} ?????1?0.3070.3380.302??0.3071?0.831?0.410?0.338?0.83110.360?0.302?0.4100.3601??????(2.61)
8.1:��������ɢ����,û�д�С��ϵ,�������ֻ�� 6 6 6 ��,����ֱ�� one-hot չ����
8.2: 1 4 = 25 % \cfrac 1 4=25\% 41?=25% �����ݴ���ȱʧֵ�����ü�ɾ���������Ǿ�ֵ����λ���������岹�ķ�������Ϊ��ʹ����ͬ�����ݽ�����ô������IJ岹̫���ı�ԭʼ���ݵķֲ������,���ԱȽϺõķ�ʽ�� 1��ͨ��ģ�Ͳ岹;2�����ز岹���ȡ�
8.3:���� 2��3 ���ڽ�ǿ�ĸ������,Ҳ���Ǵ��ڹ����Ե�����,�������Իᵼ��ģ�͵�Ч�����,������Ҫ����ҵ��֪ʶ�����д���,�ϲ�,����ɾ�����ٹ۲촦��֮���Ч���پ���������һ�ִ�����ʽ(��Ҫע�����������������Խ���ʹ�����Իع�����,�����ʹ�� gbdt �����㷨����Ҫ����)��
? ? ? 9. ���Իع��������Ƶ�(���ַ���)
? ? ? 10. ���Իع�Ļ�������?
-
�����������ǩ֮���������Թ�ϵ��
-
�����( �� �� ��)֮��Ӧ�������(����ʱ���������ݳ�����������������������,�����������ݻ��յ������ǰ������ݵ�Ӱ��)��
-
�Ա���֮��Ӧ�������
-
�����( �� �� ��)�ķ���ӦΪ������
-
�����( �� �� ��)Ӧ����̬�ֲ���
? ? ? 11. ���Իع�Ч�����õ�ԭ��
- ��ͨ���Իع������,���Ը��� LASSO ���� RIDGE �ع顣
- ���ݲ��������Իع�ļ��衣
- �������������⡣
- ʵ������л����������Եõ�����(����в������̬�ֲ�)�Ӷ�Ӱ������ģ�͵ľ���
? ? ? 12. Ϊʲô�������Իع�ǰ��Ҫ������������ɢ��������
- ��ɢ��������,������ɢ��֮������ģ�͵Ŀ��ٵ�����
- ϡ���������,ʡ�ڴ档
- ³����ǿ������������ֵ������߹�С�Խ����Ӱ��ᱻ���͡�
- ���Բ�����������(�൱�ڷ�����)
- ģ�͵��ȶ��Լ�ǿ�ˡ�
- ����ģ��,�൱�ڽ����˹���ϵķ��ա�
? ? ? 13. ���Իع鴦������,ʲô����¿�ֹͣ����,��ô�����������?
��������һ����˵Ϊȱʧֵ��������������ֵ��,�쳣ֵ����,����������ɢ���ȵȡ�
�����ε������в����ı仯��С�����ȸ�������ֵʱ,���ߴﵽ�����趨������������,��ֹͣ�������̡�
�����û������ֻ��˵�Ǿ���������ϵ�Ӱ��,ͨ�� ? 1 , ? 2 \ell_1,\ell_2 ?1?,?2? �����������������������������������ȵȡ�
? ? ? 14. ���Իع���ȱ��
�ŵ�:ʵ�ּ�,��ģ��,�����������ģ�͵Ļ�����
ȱ��:ģ�ͼ�����������ϸ�������,�Է����Ե������������á�
2.5 �����
[1] ��2021������ѧϰ�γ̡������ https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
[2] ��TensorFlow���ѧϰ��(������ʦ) https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book
[3] �������������ѧϰ��Coursera����� https://www.deeplearning.ai/
[4] ������ѧ���ѧϰ���ڶ��� https://zh-v2.d2l.ai/
[5] �����ѧϰ��(����) https://book.douban.com/subject/27087503/
[6] ��С���˷�(least sqaure method) https://zhuanlan.zhihu.com/p/38128785
[7] ���Իع��澭�ܽᡪ��from ţ�� https://zhuanlan.zhihu.com/p/66519299
[8] ����ѧϰ������֮���Իع� https://blog.csdn.net/weixin_41761357/article/details/111589392](https://blog.csdn.net/weixin_41761357/article/details/111589392)
[9] RMSE(���������)��MSE(�������)��MAE(ƽ���������)��SD(����)https://blog.csdn.net/FrankieHello/article/details/82024526
[10] ����ѧϰ-�ع�����(Regression) https://zhuanlan.zhihu.com/p/127972563
[11] Ϊʲô�ݶ��½����ҵ���Сֵ? https://www.zhihu.com/question/24258023
[12] ����ַ� https://zh.wikipedia.org/wiki/%E6%9C%89%E9%99%90%E5%B7%AE%E5%88%86%E6%B3%95
[13] Symmetric derivative https://en.wikipedia.org/wiki/Symmetric_derivative#Notes
[14] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Arti?cial Intelligence and Security, pages 15�C26. ACM, 2017.
[15] Andrew Ilyas, Logan Engstrom, and Aleksander Madry. Prior convictions: Black-box adversarial attacks with bandits and priors. In International Conference on Learning Representations, 2019. 1, 2, 5, 7, 8, 11

??
ת����ע������:https://fanfansann.blog.csdn.net/
��Ȩ����:����Ϊ CSDN ���� ����������(����),֪������ ��������(ר��),Github ��fanfansann��(ȫ��Դ��),�Ź��ں� ��������С�����š�(���� P D F ��))��ԭ������,��ѭCC 4.0 BY-SA��ȨЭ��,ת���븽��ԭ�ij������Ӽ���������