本模型采用的是字符级别的诗歌生成(pytorch)
环境:
python3.X
pytorch GPU或CPU版本都行,
另外天有点冷,建议用GPU训练,电脑绝对比暖手宝好用
目录
项目文件结构:

data:存放预处理好的数据
model:存放训练好的模型
config.py:配置文件
dataHandler.py:数据预处理及生成词典
model.py:模型文件
train.py:训练模型
generation.py:生成诗歌
poetry.txt:全唐诗,四万多首,中华民族艺术瑰宝。
数据已经打包:
链接:https://pan.baidu.com/s/1UAJFf3kKERm_XR0qRNneig?
提取码:e3y5
1、数据集处理
以四万首唐诗的文本作为训练集
它长这样:

文本中每行是一首诗,且使用冒号分割,前面是标题,后面是正文,且诗的长度不一。
对数据的处理流程大致:
- 读取文本,按行切分,构成古诗列表。
- 将全角、半角的冒号统一替换成半角的。
- 按冒号切分诗的标题和内容,只保留诗的内容。
- 最后根据诗的内容构建词典,并将处理好的数据保
?处理后的诗歌大概长这样

?代码如下:
# dataHandler.py
import numpy as np
from config import Config
def pad_sequences(sequences,
maxlen=None,
dtype='int32',
padding='pre',
truncating='pre',
value=0.):
"""
# 填充
code from keras
Pads each sequence to the same length (length of the longest sequence).
If maxlen is provided, any sequence longer
than maxlen is truncated to maxlen.
Truncation happens off either the beginning (default) or
the end of the sequence.
Supports post-padding and pre-padding (default).
Arguments:
sequences: list of lists where each element is a sequence
maxlen: int, maximum length
dtype: type to cast the resulting sequence.
padding: 'pre' or 'post', pad either before or after each sequence.
truncating: 'pre' or 'post', remove values from sequences larger than
maxlen either in the beginning or in the end of the sequence
value: float, value to pad the sequences to the desired value.
Returns:
x: numpy array with dimensions (number_of_sequences, maxlen)
Raises:
ValueError: in case of invalid values for `truncating` or `padding`,
or in case of invalid shape for a `sequences` entry.
"""
if not hasattr(sequences, '__len__'):
raise ValueError('`sequences` must be iterable.')
lengths = []
for x in sequences:
if not hasattr(x, '__len__'):
raise ValueError('`sequences` must be a list of iterables. '
'Found non-iterable: ' + str(x))
lengths.append(len(x))
num_samples = len(sequences)
if maxlen is None:
maxlen = np.max(lengths)
# take the sample shape from the first non empty sequence
# checking for consistency in the main loop below.
sample_shape = tuple()
for s in sequences:
if len(s) > 0: # pylint: disable=g-explicit-length-test
sample_shape = np.asarray(s).shape[1:]
break
x = (np.ones((num_samples, maxlen) + sample_shape) * value).astype(dtype)
for idx, s in enumerate(sequences):
if not len(s): # pylint: disable=g-explicit-length-test
continue # empty list/array was found
if truncating == 'pre':
trunc = s[-maxlen:] # pylint: disable=invalid-unary-operand-type
elif truncating == 'post':
trunc = s[:maxlen]
else:
raise ValueError('Truncating type "%s" not understood' % truncating)
# check `trunc` has expected shape
trunc = np.asarray(trunc, dtype=dtype)
if trunc.shape[1:] != sample_shape:
raise ValueError(
'Shape of sample %s of sequence at position %s is different from '
'expected shape %s'
% (trunc.shape[1:], idx, sample_shape))
if padding == 'post':
x[idx, :len(trunc)] = trunc
elif padding == 'pre':
x[idx, -len(trunc):] = trunc
else:
raise ValueError('Padding type "%s" not understood' % padding)
return x
def load_poetry(poetry_file, max_gen_len):
# 加载数据集
with open(poetry_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 将冒号统一成相同格式
lines = [line.replace(':', ':') for line in lines]
# 数据集列表
poetry = []
# 逐行处理读取到的数据
for line in lines:
# 有且只能有一个冒号用来分割标题
if line.count(':') != 1:
continue
# 后半部分不能包含禁止词,如果包含,直接跳过这一首诗
_, last_part = line.split(':')
if '(' in line:
last_part = last_part.split('(')[0]
# 长度不能超过最大长度
if len(last_part) > max_gen_len - 2:
continue
# 去除这些有禁用词的诗
if '【' in line or '_' in line:
continue
poetry.append(last_part.replace('\n', ''))
# 随机打乱顺序
np.random.shuffle(poetry)
return poetry
def get_data(config):
# 1.获取数据
data = load_poetry(config.poetry_file, config.max_gen_len)
for poetry in data:
print(poetry)
# 2.构建词典
chars = {c for line in data for c in line}
char_to_ix = {char: ix for ix, char in enumerate(chars)}
char_to_ix['<EOP>'] = len(char_to_ix)
char_to_ix['<START>'] = len(char_to_ix)
char_to_ix['</s>'] = len(char_to_ix)
ix_to_chars = {ix: char for char, ix in list(char_to_ix.items())}
# 3.处理样本
# 3.1 每首诗加上首位符号
for i in range(0, len(data)):
data[i] = ['<START>'] + list(data[i]) + ['<EOP>']
# 3.2 文字转id
data_id = [[char_to_ix[w] for w in line] for line in data]
# 3.3 补全既定长度,即填充
pad_data = pad_sequences(data_id,
maxlen=config.poetry_max_len,
padding='pre',
truncating='post',
value=len(char_to_ix) - 1)
# 3.4 保存处理好的数据
np.savez_compressed(config.processed_data_path,
data=pad_data,
word2ix=char_to_ix,
ix2word=ix_to_chars)
return pad_data, char_to_ix, ix_to_chars
if __name__ == '__main__':
config = Config()
pad_data, char_to_ix, ix_to_chars = get_data(config)
for l in pad_data[:10]:
print(l)
n = 0
for k, v in char_to_ix.items():
print(k, v)
if n > 10:
break
n += 1
n = 0
for k, v in ix_to_chars.items():
print(k, v)
if n > 10:
break
n += 1
2、构建模型与训练模型
基于概率语言模型的模型
我们是基于n-gram语言模型的思想,n-gram模型作了一个n?1阶的Markov假设,即认为一个词出现的概率只与它前面的n?1个词相关,所以我们可以通过前n个词预测下一个词,公式表示为:
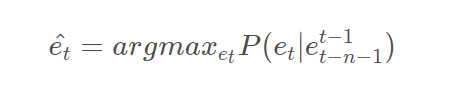
网络结构
基于语言的概率模型本质就是分类模型,基于前面n个字对下一个字进行预测,找到概率最大的字便是预测结果。其网络结构如下:
?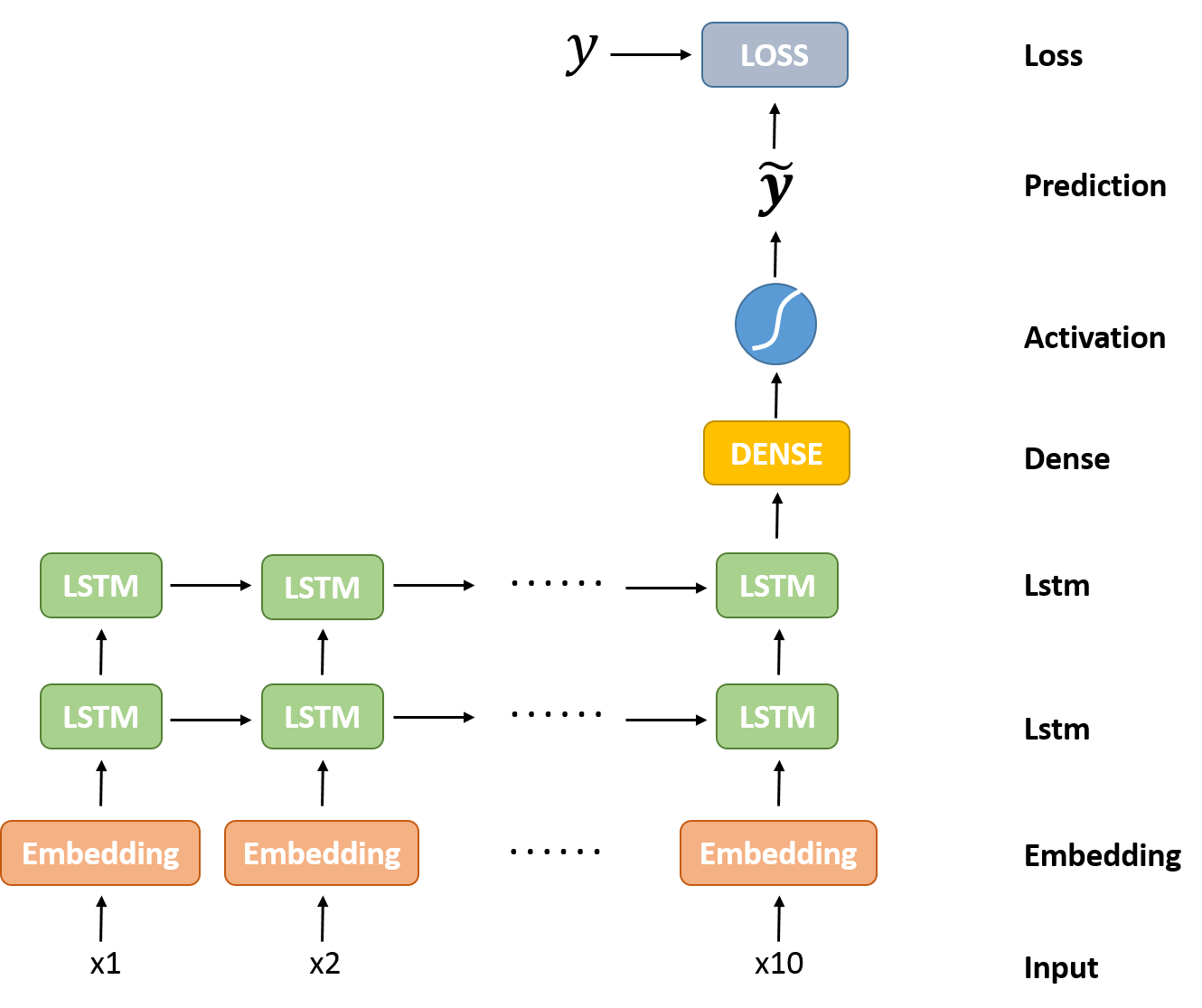
?从图中可以看出,本模型使用了1层词嵌入层,2层LSTM,一层全连接层。
网络输入输出
训练数据 x和标签 y,将诗的内容错开一位分别作为数据和标签,举个例子,假设有诗是“床前明月光,疑是地上霜。举头望明月,低头思故乡。”,则数据为“床前明月光,疑是地上霜。举头望明月,低头思故乡。”,标签为“床前明月光,疑是地上霜。举头望明月,低头思故乡。”,两者一一对应,y 是 x 中每个位置的下一个字符。
以字符的形式举例是为了方便理解,实际上不论是x还是y,都是将字符编码后的编号序列(数字),这样才能输入神经网络。
损失函数
损失函数采用交叉熵损失函数CrossEntropyLoss
代码如下:
# model.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
class PoetryModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, device, layer_num):
super(PoetryModel, self).__init__()
self.hidden_dim = hidden_dim
# 创建embedding层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 创建lstm层,参数是输入输出的维度
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=layer_num)
# 创建一个线性层
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
# 创建一个dropout层,训练时作用在线性层防止过拟合
self.dropout = nn.Dropout(0.2)
self.device = device
def forward(self, inputs, hidden):
seq_len, batch_size = inputs.size()
# 将one-hot形式的input在嵌入矩阵中转换成嵌入向量,torch.Size([length, batch_size, embedding_size])
embeds = self.embeddings(inputs)
# 经过lstm层,该层有2个输入,当前x和t=0时的(c,a),
# output:torch.Size([length, batch_size, hidden_idm]), 每一个step的输出
# hidden: tuple(torch.Size([layer_num, 32, 256]) torch.Size([1, 32, 256])) # 最后一层输出的ct 和 ht, 在这里是没有用的
output, hidden = self.lstm(embeds, hidden)
# 经过线性层,relu激活层 先转换成(max_len*batch_size, 256)维度,再过线性层(length, vocab_size)
# output = F.relu(self.linear1(output.view(seq_len*batch_size, -1)))
output = F.log_softmax(self.linear1(output.view(seq_len * batch_size, -1)), dim=1)
# 输出最终结果,与hidden结果
return output, hidden
def init_hidden(self, layer_num, batch_size):
return (Variable(torch.zeros(layer_num, batch_size, self.hidden_dim)).cuda(),
Variable(torch.zeros(layer_num, batch_size, self.hidden_dim)).cuda())
# train.py
import os
import torch
import torch.utils.data as Data
import torch.nn as nn
import torch.optim as optim
from model import PoetryModel
from dataHandler import *
from config import Config
class TrainModel(object):
def __init__(self):
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
self.config = Config()
self.device = torch.device('cuda') if self.config.use_gpu else torch.device('cpu')
def train(self, data_loader, model, optimizer, criterion, char_to_ix, ix_to_chars):
for epoch in range(self.config.epoch_num):
for step, x in enumerate(data_loader):
# 1.处理数据
# x: (batch_size,max_len) ==> (max_len, batch_size)
x = x.long().transpose(1, 0).contiguous()
x = x.to(self.device)
optimizer.zero_grad()
# input,target: (max_len, batch_size-1)
input_, target = x[:-1, :], x[1:, :]
target = target.view(-1)
# 初始化hidden为(c0, h0): ((layer_num, batch_size, hidden_dim),(layer_num, batch_size, hidden_dim))
hidden = model.init_hidden(self.config.layer_num, x.size()[1])
# 2.前向计算
# print(input.size(), hidden[0].size(), target.size())
output, _ = model(input_, hidden)
loss = criterion(output, target) # output:(max_len*batch_size,vocab_size), target:(max_len*batch_size)
# 反向计算梯度
loss.backward()
# 权重更新
optimizer.step()
if step == 0:
print('epoch: %d,loss: %f' % (epoch, loss.data))
if epoch % 5 == 0:
# 保存模型
torch.save(model.state_dict(), '%s_%s.pth' % (self.config.model_prefix, epoch))
# 分别以这几个字作为诗歌的第一个字,生成一首藏头诗,用于看看训练时的效果
word = '春江花月夜凉如水'
gen_poetry = ''.join(self.generate_head_test(model, word, char_to_ix, ix_to_chars))
print(gen_poetry)
def run(self):
# 1 获取数据
data, char_to_ix, ix_to_chars = get_data(self.config)
vocab_size = len(char_to_ix)
print('样本数:%d' % len(data))
print('词典大小: %d' % vocab_size)
# 2 设置dataloader
data = torch.from_numpy(data)
data_loader = Data.DataLoader(data,
batch_size=self.config.batch_size,
shuffle=True,
num_workers=0)
# 3 创建模型
model = PoetryModel(vocab_size=vocab_size,
embedding_dim=self.config.embedding_dim,
hidden_dim=self.config.hidden_dim,
device=self.device,
layer_num=self.config.layer_num)
model.to(self.device)
# 4 创建优化器
optimizer = optim.Adam(model.parameters(), lr=self.config.lr, weight_decay=self.config.weight_decay)
# 5 创建损失函数,使用与logsoftmax的输出
criterion = nn.CrossEntropyLoss()
# 6.训练
self.train(data_loader, model, optimizer, criterion, char_to_ix, ix_to_chars)
def generate_head_test(self, model, head_sentence, word_to_ix, ix_to_word):
"""生成藏头诗"""
poetry = []
head_char_len = len(head_sentence) # 要生成的句子的数量
sentence_len = 0 # 当前句子的数量
pre_char = '<START>' # 前一个已经生成的字
# 准备第一步要输入的数据
input = (torch.Tensor([word_to_ix['<START>']]).view(1, 1).long()).to(self.device)
hidden = model.init_hidden(self.config.layer_num, 1)
for i in range(self.config.max_gen_len):
# 前向计算出概率最大的当前词
output, hidden = model(input, hidden)
top_index = output.data[0].topk(1)[1][0].item()
char = ix_to_word[top_index]
# 句首的字用藏头字代替
if pre_char in ['。', '!', '<START>']:
if sentence_len == head_char_len:
break
else:
char = head_sentence[sentence_len]
sentence_len += 1
input = (input.data.new([word_to_ix[char]])).view(1,1)
else:
input = (input.data.new([top_index])).view(1,1)
poetry.append(char)
pre_char = char
return poetry3、生成诗歌
# -*- coding: utf-8 -*-
# generation.py
import os
from config import Config
import numpy as np
from model import PoetryModel
import torch
class Sample(object):
def __init__(self):
self.config = Config()
self.device = torch.device('cuda') if self.config.use_gpu else torch.device('cpu')
self.processed_data_path = self.config.processed_data_path
self.model_path = self.config.model_path
self.max_len = self.config.max_gen_len
self.sentence_max_len = self.config.sentence_max_len
self.load_data()
self.load_model()
def load_data(self):
if os.path.exists(self.processed_data_path):
data = np.load(self.processed_data_path, allow_pickle=True)
self.data, self.word_to_ix, self.ix_to_word = data['data'], data['word2ix'].item(), data['ix2word'].item()
def load_model(self):
model = PoetryModel(len(self.word_to_ix),
self.config.embedding_dim,
self.config.hidden_dim,
self.device,
self.config.layer_num)
map_location = lambda s, l: s
state_dict = torch.load(self.config.model_path, map_location=map_location)
model.load_state_dict(state_dict)
model.to(self.device)
self.model = model
def generate_random(self, start_words='<START>'):
"""自由生成一首诗歌"""
poetry = []
sentence_len = 0
input = (torch.Tensor([self.word_to_ix[start_words]]).view(1, 1).long()).to(self.device)
hidden = self.model.init_hidden(self.config.layer_num, 1)
for i in range(self.max_len):
# 前向计算出概率最大的当前词
output, hidden = self.model(input, hidden)
top_index = output.data[0].topk(1)[1][0].item()
# _probas = output.data[0].cpu().numpy() # 在GPU上的Tensor没办法直接转numpy,先转到CPU再转成numpy
# # 按照出现概率,对所有token倒序排列
# p_args = np.argsort(-_probas)[:2]
# # 排列后的概率顺序
# p = _probas[p_args]
# # 先对概率归一
# p = p / sum(p)
# # 再按照预测出的概率,随机选择一个词作为预测结果
# choice_index = np.random.choice(len(p), p=p)
# top_index = p_args[choice_index]
char =self.ix_to_word[top_index]
# 遇到终结符则输出
if char == '<EOP>':
break
# 有8个句子则停止预测
if char in ['。', '!']:
sentence_len += 1
if sentence_len == 8:
poetry.append(char)
break
input = (input.data.new([top_index])).view(1, 1)
poetry.append(char)
return poetry
def generate_head(self, head_sentence):
"""生成藏头诗"""
poetry = []
head_char_len = len(head_sentence) # 要生成的句子的数量
sentence_len = 0 # 当前句子的数量
pre_char = '<START>' # 前一个已经生成的字
# 准备第一步要输入的数据
input = (torch.Tensor([self.word_to_ix['<START>']]).view(1, 1).long()).to(self.device)
hidden = self.model.init_hidden(self.config.layer_num, 1)
for i in range(self.max_len):
# 前向计算出概率最大的当前词
output, hidden = self.model(input, hidden)
top_index = output.data[0].topk(1)[1][0].item()
# _probas = output.data[0].cpu().numpy() # 在GPU上的Tensor没办法直接转numpy,先转到CPU再转成numpy
# # 按照出现概率,对所有token倒序排列
# p_args = np.argsort(-_probas)[:3]
# # 排列后的概率顺序
# p = _probas[p_args]
# # 先对概率归一
# p = p / sum(p)
# # 再按照预测出的概率,随机选择一个词作为预测结果
# choice_index = np.random.choice(len(p), p=p)
# top_index = p_args[choice_index]
char = self.ix_to_word[top_index]
# 句首的字用藏头字代替
if pre_char in ['。', '!', '<START>']:
if sentence_len == head_char_len:
break
else:
char = head_sentence[sentence_len]
sentence_len += 1
input = (input.data.new([self.word_to_ix[char]])).view(1,1)
else:
input = (input.data.new([top_index])).view(1,1)
poetry.append(char)
pre_char = char
return poetry
def generate_poetry(self, mode=1, head_sentence=None):
"""
模式一:随机生成诗歌
模式二:生成藏头诗
:return:
"""
poetry = ''
if mode == 1 or (mode == 2 and head_sentence is None):
poetry = ''.join(self.generate_random())
if mode == 2 and head_sentence is not None:
head_sentence = head_sentence.replace(',', u',').replace('.', u'。').replace('?', u'?')
poetry = ''.join(self.generate_head(head_sentence))
return poetry
if __name__ == '__main__':
obj = Sample()
poetry1 = obj.generate_poetry(mode=2, head_sentence="碧海潮生")
print(poetry1)
4、配置文件
为了方便修改和调试模型,基本上所有的可以改的参数都放到配置模型文件中。很简单
# -*- encoding: utf-8 -*-
# config.py
class Config(object):
processed_data_path = "data/tang.npz" # 保存的数据预处理数据
model_path = 'model/tang_5.pth' # 载入的训练好的模型
model_prefix = 'model/tang' # 模型的保存
batch_size = 64 # batch_size
epoch_num = 10 # 训练的迭代次数epoch
embedding_dim = 128 # 嵌入层的维度
hidden_dim = 128 # LSTM的隐藏层的维度
layer_num = 2 # LSTM的层数
lr = 0.001 # 初始化学习率
weight_decay = 1e-4 # Adam优化器的weight_decay参数
use_gpu = True # 是否使用GPU训练
poetry_file = 'poetry.txt' # 诗歌文件名称
max_gen_len = 200 # 生成诗歌最长长度
sentence_max_len = 4 # 生成诗歌的最长句子
poetry_max_len = 125
sample_max_len = poetry_max_len - 15、生成效果
怎么说呢,有点那味了。
桃殿开华碧色沈,
花间似水水间流。
影中云落风明月,
落日生光未出分。
碧云行自在,
海路几悠游。
潮暗遥还夜,
生游日见长。
6、结语
初次尝试用pytorch,有纰漏之处,还望指正,模型还有待改进。
参考:
基于循环神经网络(RNN)的古诗生成器_python_脚本之家 (jb51.net)![]() https://www.jb51.net/article/137118.htm
https://www.jb51.net/article/137118.htm