1. 知识点
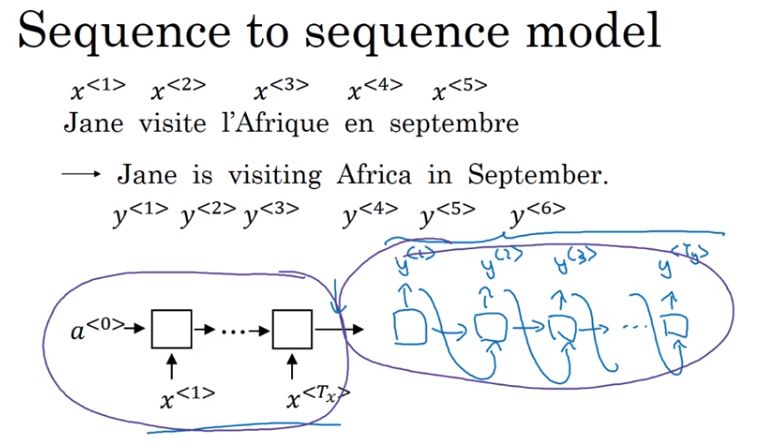
- sequence to sequence模型:编码网络和解码网络
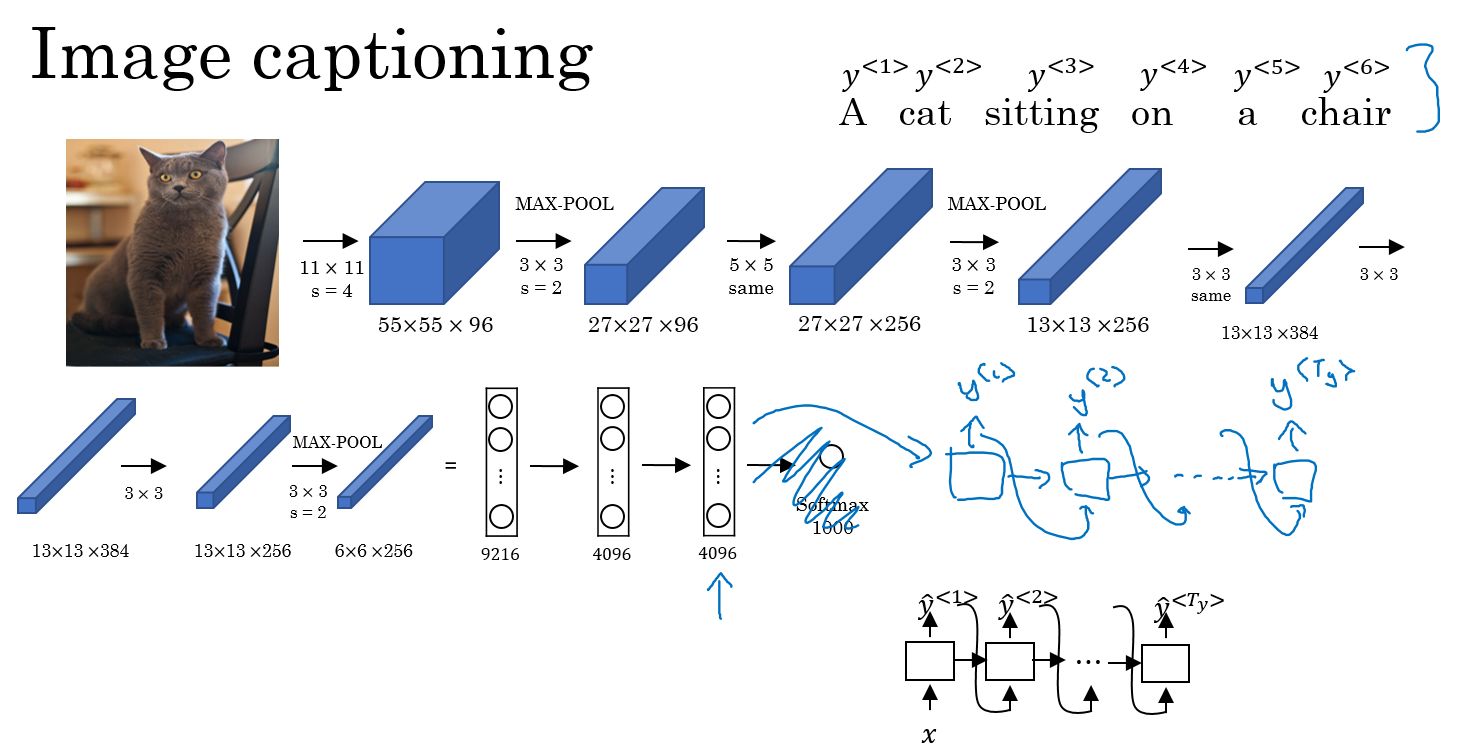
- image to sequence模型:卷积,全连接,输出序列,对序列解码
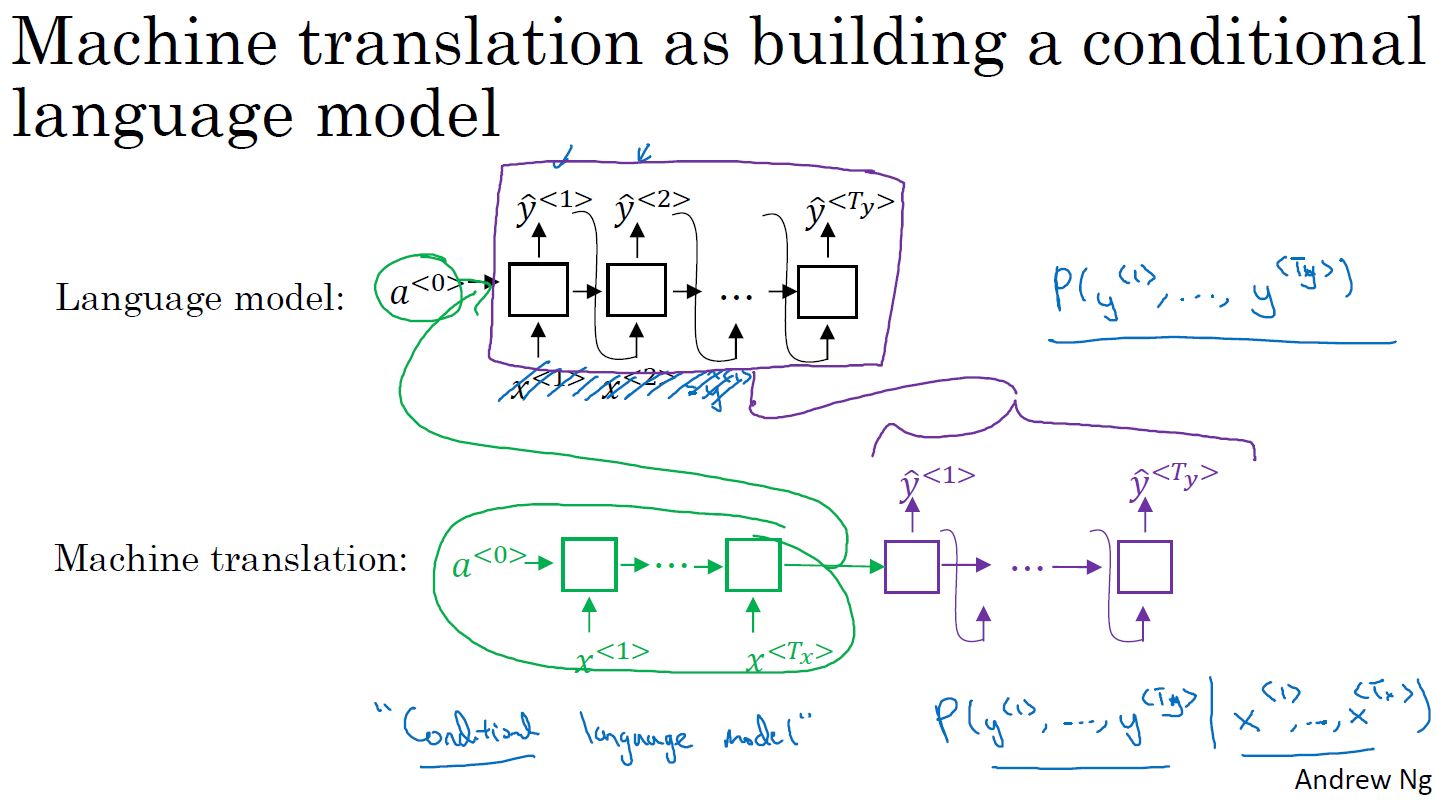
- 机器翻译:条件语言模型,相对于语言模型总是以零向量开始,机器翻译以每个单词的一系列向量作为输入。
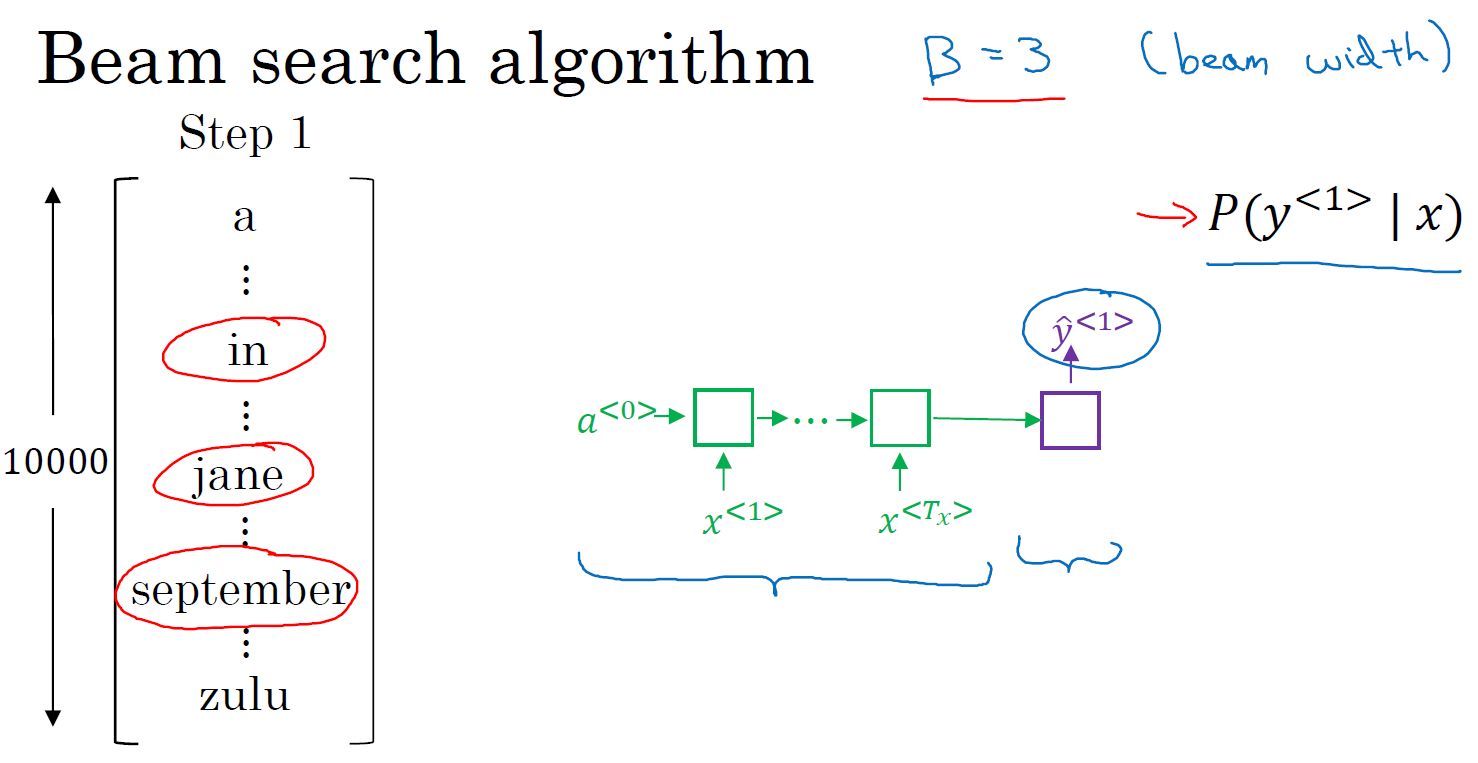
- 机器翻译,寻找最大的概率输出:

- 机器学习为什么不用贪心算法:原因一,机器翻译的目标是一次性输入整体概率最大的序列,而不是逐步寻找概率最大的单词;原因二,贪心算法需要计算词库中每个单词出现的概率,计算量过大。

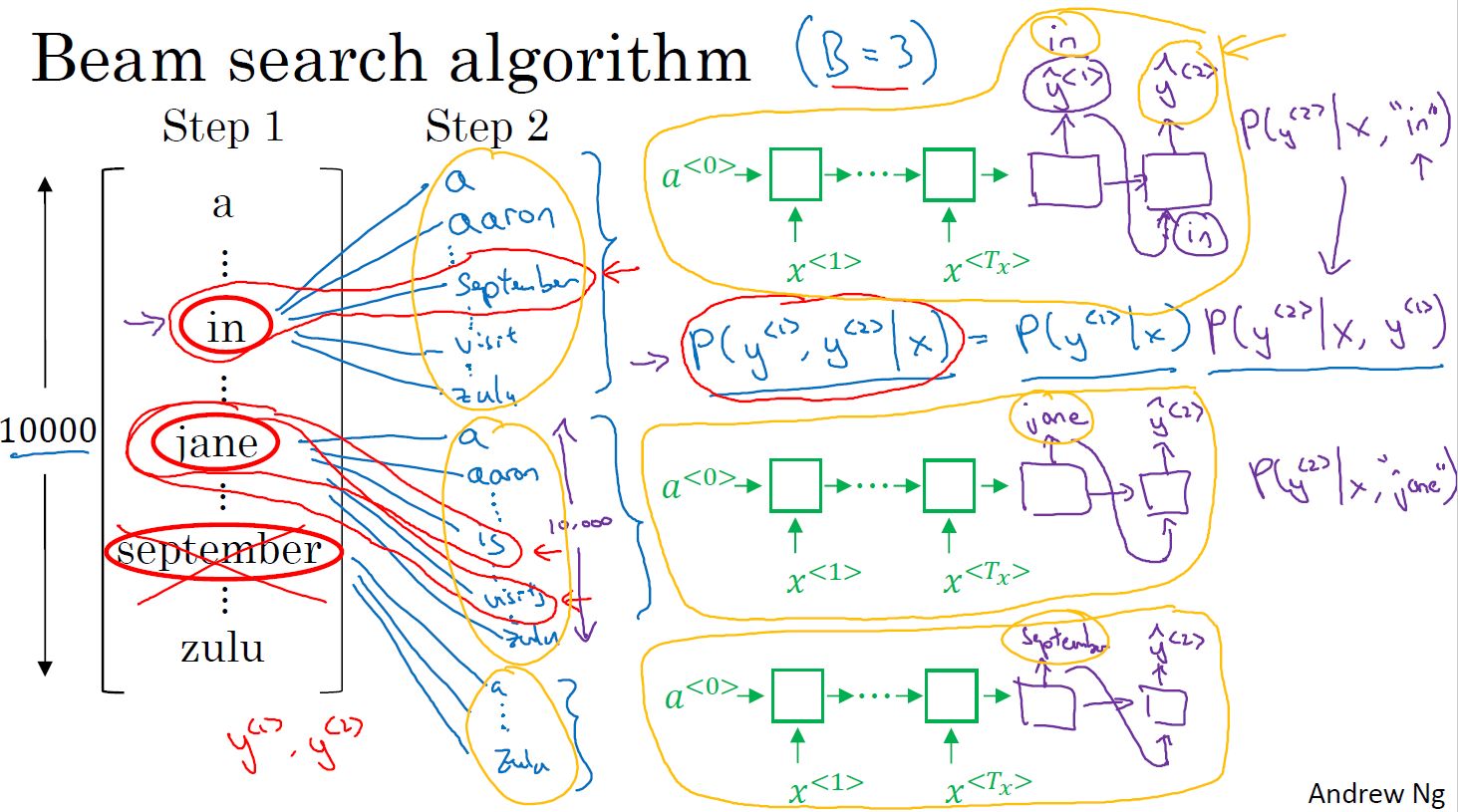
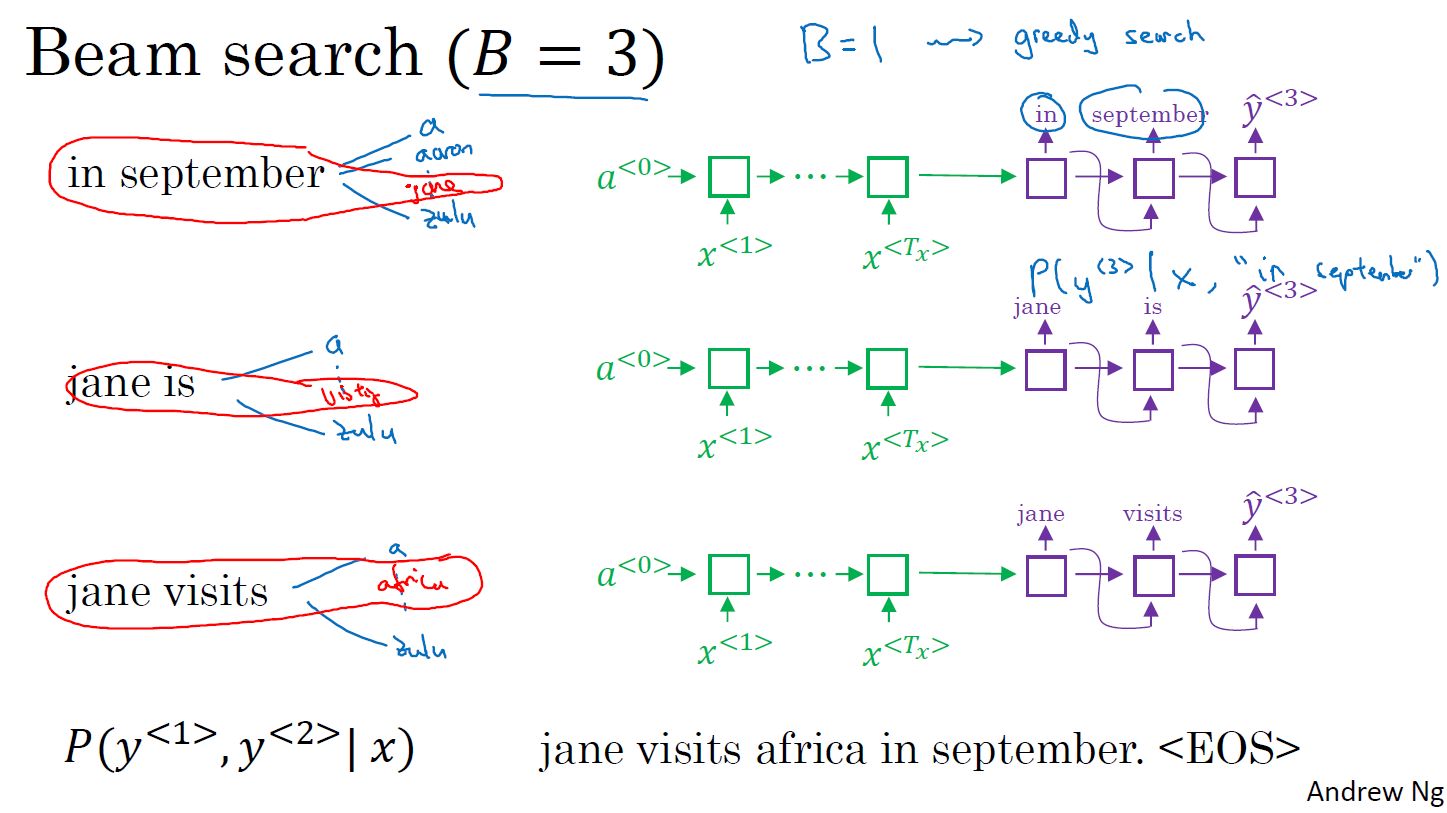
- 集束搜索:
- 对输入序列用编码网络进行编码,输出编码向量,维度为词库大小,值为每个单词的概率。设置集束宽带,比如3,则取前3个最大输出概率的单词。
- 对得到的3个单词,对词库中的每个单词进行配对,分别计算词对出现的概率。同样选择前3个单词对。
- 与第2)步类似,直到遇到结束符。
- 集束搜索的改进:1)最大化的目标为概率相乘,值会非常小,取对数运算,使运算更稳定。2)用输出单词长度值Ty和超参数
对目标进行归一化,使其得到更好的效果。
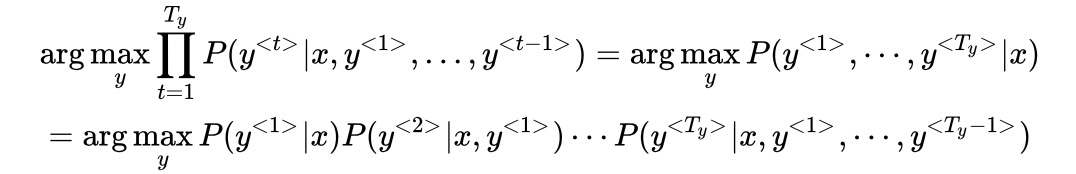
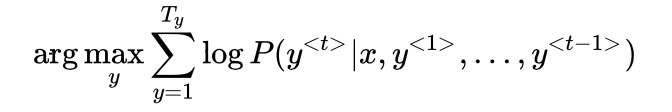
?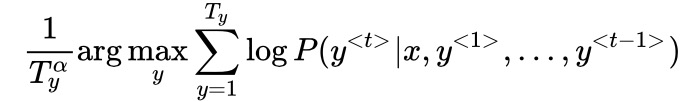
- 集束搜索误差分析:用RNN模型计算人工翻译和集束搜索机器翻译哪个概率更大,如果人工大于机器,可能是机器翻译错了,如果机器大于人工,可能是RNN错了。


- Bleu?Score评估翻译系统的准确性:观察机器翻译输出的每个词是否出现在参考中。并设置每个词的得分上限,避免机器输出中重复出现在参考中的词。

- 二元词组的bleu scroe:将二元启组作为评估的对象,得出机器翻译的二元词组的得分和其相应的得分上限,改进精确度?
