���������paddle-openVINO��CPU��-�ӻ�������-ģ�Ͳ���ȫ����
����ƪ�����㽫��Ӵ���:paddle-openvino��ܡ�������Linux��windows�������÷�ʽ��ʹ��LabelMe��paddle���ݵı�עת���뻮�֡�ͼ�����/Ŀ����/ʵ���ָ�/����ָ�����ݸ�ʽ��ģ��ѵ����ѵ������������ģ�ͱ��桢ģ��ѹ��(�ü�����)��ģ�͵���(ONNX2)��
�㽫��Ӵ���6��ʵս��Ŀ:paddle(����ָ�- RGBң��Ӱ��ָ�-��ͨ��ң��Ӱ��ָ�-�ؿ�仯���)��paddle with openvino(paddleyolo��paddleyolo3��paddleOCR )
�ڼ�ο��˰���ƪ�ٷ������ĵ��������intel�����㹤��ʦ�ž���������������������־�ա�ׯ��������ϡ�raymondlo�����Ȱ�λ����ʦ,�ٶȷɽ�����ʦ���б�Ȼ����߷塢����������������һЩ�����Լ�������paddle�ٷ���Դ����
ΪʲôҪѡ��paddle+openVINO?
Paddlepaddle�ǹ��ڰٶ��Ƴ���һ�����ѧϰ���,Openvino��Ӣ�ض�����X86�ܹ���оƬ�����һ�ֲ�����
�ɽ���Ҫ�����������AI�����߶���������Դ�ľ���������,�ɽ��ṩ�����ߵ���ƽ̨,�����ʹ�����ǵ��㿨�豸����ģ�͵�ѵ����������
��openVINO�������������û���Կ��������������AI�����ߵ����⡣
�������ֵ�����,�����AI�����߶���������Դ������ż�,�Ӷ�ʵ�ֽϵͳɱ���AIӦ�ÿ�����ʹ�÷ɽ�ѵ����ģ�Ͳ��ܹ�ֱ�Ӳ���openVINO��,����Ҫ��������ת�����ɽ���ģ�͵���ONNXģ��,Ȼ���ٽ����ģ��ת����ΪIRģ��,�ſ���ʵ����openVINO�ϵIJ���
���TF��pytorch��caffe��ͻ��?
������ֲ�����û�г�ͻ,���һ�������ȥ������������ܡ��ɽ��Ŀ�������Ǻܶ�����Ǻ����߷dz����Ƶ�,���ұȽϼ�,�������֡���������ȥ�ڷɽ�������һЩ���㷨�ϱȽϸ��ӵļܹ����ڶ�����������Ҳ�ǿ�����openVINO�ϲ����
����ͼ����openVINO-�ɽ�
����������Դ����Hackathon��ѵʱ��λintel����ʦ������������ϡ�raymondlo������,����ͼ�Ϳ��Ժܺõذ�������̽�������
1��openVINO��������

�������ģ����Ҫ���������Ż�����������ȥʵ������ѧϰ,�������ǿ�������Ҫ�����ݶ�ģ�ͽ�������ѵ��,����ʵ�����ǶԾ����Ϻ�ҵЧ���ϵ�Ҫ�ȿ����������е�open model zoo�������ǵĿ�����,�����Ի���������TF��pytorch��PP����ģ��ת����
modeloptimizer��inference engine
��ģ�͵��Ż������������õ�������������,modeloptimizer��inference engine��ǰ����Ҫ����һ���Ե�����ģ�͵�һ��ת�ƺ��Ż�������,����ת����ΪOPENVINO��֧�ֵ�IR(intermediate representation.bin .xml)ģ���м����ʽ��inference engine���ȡ��ЩIRģ�ͱ���ʽ,���������ص���Ӧ��Ӳ����,��������һ���ײ���Ż�,�Լ����ӵĺϲ���ģ�ͼ����������ڵ�������,�ڹ�����
post-training optimization tool &deep learning workbench
����post-training optimization tool��Ҫ�����ģ�͵�һЩ�ض��ij���,��һЩģ�͵������ͼ��õĹ�����deep learning workbench����Ҫ�ǿ��Ի���һ�����ӻ���web�ӿڵ���ģ�͵�һЩ����,�Լ�����ÿ�����һ����������������һ�����š�
deep learning streaming
��֮����,Ҳ�����˴����ĵ�������һЩ���ߡ�����˵deep learning streaming����һ������,����������ȥ��decode��encode�������Ĵ�����openCL����ģ�͵�ǰ�����Լ�һЩ�Ż����ٺ����Ӧ�Ŀ�����
����һЩ��Ʒ�ű��ǿ���ȥ�Ա�Ӧ��ģ�͵�һ�����Ⱥ����ܵIJ���,�Լ�������ܵ��Ż���
model server
�����ģ�Ͳ���,���Է���������ʽ������model server�ϵ�,ֻҪͨ��request�ӿڵ���ʽȥ���еĵ�ȡ���ģ�͵�����������ȷ�Ļ�ȡ��һ�������(���ֻ����һ��,�Ƽ����ʹ�ðٶȵĹ����Ʒ���������)
development manager
���һЩ�ض��������Ե����ij���,Ҳ�ṩ��development manager��ͨ��������߿����߾Ϳ���ȥ��Թ�ҵ����IJ��������һ�����á���Ϊ�еij�����,���ǵĿ����߿���ֻ��Ҫcpu,����Ҫ����һЩ�ײ�ԭ����һЩ��,�����ǿ����ڲ����ʱ�����Щ���������,ʵ�������������һ����С����
�����������Ҳ��֧����X86�ܹ����е�Ӳ����Ʒ�IJ���
2��paddlepaddle+OpenVINO
�ɽ���openVINO����֮���Ƕ��,��ʵ�������������һ����,��������������ʹ��paddleģ��,Ȼ�����ǵķɽ�ģ��ͨ��ת����ת����IRģ��,���߿���ֱ�ӽ�һ���ֵķɽ�ģ�Ͳ���Ӳ����,�Ӷ�ʵ�����������̲����뿪����

openVINO�����ܹ�

ǰ��
openVINO�����ܹ����Էֳ����ǰ�˺ͺ����������,����֮���Ӧ�Ĵ�������������read_network�����ӿں�load_network�����������ӿڡ���ǰ����Ҫ���ܾ���ͨ������������read_network�ӿ�ȥ��ȡ������ģ�Ͳ�������һ������,Ȼ��ͨ�����ǵ�һЩͨ�õġ��Ż��ķ�ʽ,��ģ�͵�һЩlayer����һЩ�Ż�.��Щ�Ż�����ͨ�õ�,����˵���ڱ���˵���ijЩlayer�ıȽ�ϡ���һЩͼ����һ��ͼ���ں�,����˵��һЩϵͳ�е��������������п��ܲ���Ҫ��,���ǻ�����û���õ����Ӹ�����������Ȼ���ת���õ�ģ��ת�������ǵ�CNNnetwork,Ҳ����ǰ�˵Ĺ��ܡ�
��ǰ��������벿����������Ҫ�����������Ĺ���������
���ȿ��Ի������ǵ�����ͼ��������һ�������ӿ�,ȥ�Լ��ֶ�ȥ��һ��ģ�͵����˽ṹ�Լ���Ӧ�IJ���,������ת����CNNnetwork����ʽ��
���Ҳͨ��modeloptimizerȥת��һ����������ģ��,�γ�IR��ģ���м����ʽ,��ͨ��IRģ�͵Ľ���һ����ȡ�ͽ���,ֱ��ȥת�������CNNnetwork��
������Ҳ��������ս�Ե�,ͨ��paddle reader ���ֱ�Ӱѷɽ�ģ�ͽ��ж�ȡ�ͼ��ء�ͨ��paddle converter����齨һ��һ��ӳ�䵽���Ӧ������,ʵ�ֶ�ǰ�˵�֧��,���ֱ�ӽ�paddle������CNNnetwork���硣
���
ͨ��load_network��������ӿ�ȥָ��ģ��Ҫ������һ��Ӳ��ƽ̨�ϡ�load_network��������ӿڻ�ȥ���ظղ��Ѿ��Ż�����CNNnetwork,������ȥ�Ƶ�ָ����Ӳ��ƽ̨��ȥ����һ��ǰ�˵�������������������л���Բ�ͬ��Ӳ��ƽ̨��һЩ���ƻ����Ż�,����˵���ǻ�ͨ������ڴ����Ż�����һЩ��������,ȥʵ��һЩ����Ż�,��֤��ָ��ƽ̨���ܴﵽһ����õ�����Ч�ܡ�ͨ������ӿ�Ҳ���Խ���һЩ���ƻ����Ż��趨������˵���ǿ���������ӿ�����ָ���ڶ��Ӳ��ƽ̨��ȥ����,�����ӿ���ʵ�ֶԶ���������֧�֡�ͬʱҲ����ʵ���칹��������һ��ģʽ,���Ի�ͬʱȥ���ɶ����������,Ȼ�����Щ�������ƽ�����䵽��ͬ�ļ��㵥Ԫ��,������������ͬʱ������һ������,��������������������
�����е�������Ҫ��������
1����һ�����Dz�ͬ����������,������Ҫ����WINDOWSϵͳ��Linuxϵͳ������,ƻ��ϵͳҲ�����á�
2���ڶ������ǶԷɽ�ѵ��ģ�͵����պ͵�����ת����
3��������������ν�������ģ�ͽ���ת����IRģ�Ͳ�����openVINO�ϡ�
(PS:�������Ӧ���Ѿ��������պ�,���Գ���ȥ���²�ͬģ�͵�����ת��,���Ƿdz��ײ��Ҳ�Ƿdz�ѵ���˻�������һ����ս,����˵PP-OPENVINO���ӵ�ת����)
ȫ���̵��ѵ���ص����������������ɵ�,�����Ǿ�һ����������������⡣
Paddlepaddle-PaddleX-openVINO��װ�뻷������
��������һ�·ɽ��ļܹ���ɰ�,����ο��ٶȹٷ���Ʒ�ġ����ѧϰ�����ʱ�䡱һ����һͼ,����ʮ�����������ڲ�ͬ�������ѧ�߶��ܹ��ҵ���Ӧ����ϵ,��������Ҫ˵��������ĵ���������,һ����paddle,һ����paddleX,ǰ��������ĵĿ��,ͨ��������Ŀ����ʹ�������Ŀ��,��paddleX�ǿ�����ȫ���̹���,���������Լ���AIģ�͡�

PaddleX����
����ο��ٶȷɽ��Ĺٷ������ĵ���������˽�
PaddleX���ӻ��ͻ��˻���PaddleX�����Ŀ��ӻ����ѧϰģ��ѵ����,Ŀǰ֧��ѵ���Ӿ������ͼ����ࡢĿ���⡢ʵ���ָ������ָ��Ĵ�����,ͬʱ֧��ģ�Ͳü���ģ���������ַ�ʽѹ��ģ�͡�
PaddleX�е�����ģ��ѵ���������ܽ�Ϊ����3������
����:���̡����ݼ���ģ��,�Ϳ��Եõ�һ��AI ģ��
������ô���չʾһ������������,�������ﲻ���������ǽ��г���,��Ϊ��ʱ���ѵĵ����л�û�а�װpaddlepaddle,���ǿ������������������̡�
���߲˷���Ϊ������ʾPaddleX����ȫ����
- ��װPaddleX
��װ����������ǻ��ڽ�������ϸ������
pip install paddlex -i https://mirror.baidu.com/pypi/simple
- ���߲˷������ݼ�
wget https://bj.bcebos.com/paddlex/datasets/vegetables_cls.tar.gz
tar xzvf vegetables_cls.tar.gz
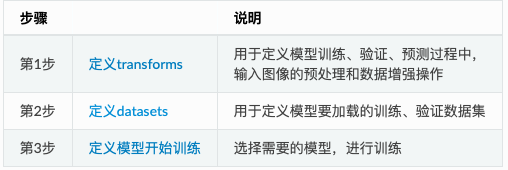
- ����ѵ��/��֤ͼ��������transforms
��Ϊѵ��ʱ������������ǿ����,�����ѵ������֤������,ģ�͵����ݴ���������Ҫ�ֱ���ж��塣������ʾ,������train_transforms�м�����RandomCrop��RandomHorizontalFlip����������ǿ��ʽ, ��������Բο��ٷ���������ǿ�ĵ���
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])
- ����dataset����ͼ��������ݼ�
�������ݼ�,pdx.datasets.ImageNet��ʾ��ȡImageNet��ʽ�ķ������ݼ�
train_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/val_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=eval_transforms)
- ʹ��MobileNetV3_small_ssldģ�Ϳ�ʼѵ��
����ʹ�ðٶȻ��������õ���MobileNetV3Ԥѵ��ģ��,ģ�ͽṹ��MobileNetV3һ��,�����ȸ��ߡ�PaddleX������20���ַ���ģ��
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small_ssld(num_classes=num_classes)
model.train(num_epochs=20,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small_ssld',
use_vdl=True)
- ѵ������ʹ��VisualDL�鿴ѵ��ָ��仯
ѵ��������,ģ����ѵ��������֤���ϵ�ָ������Ա��������ʽ����������նˡ����û��趨use_vdl=Trueʱ,Ҳ��ʹ��VisualDL��ʽ��ָ���㵽save_dirĿ¼�µ�vdl_log�ļ���,���ն�����������������visualdl���鿴���ӻ���ָ��仯�����
visualdl --logdir output/mobilenetv3_small_ssld --port 8001
����������,ͨ���������https://0.0.0.0:8001��https://localhost:8001���ɡ�
- ����ѵ�������ģ��Ԥ��
ģ����ѵ��������,��ÿ���һ����������һ��ģ��,����֤��������Ч����õ�һ�ֻᱣ����save_dirĿ¼�µ�best_model�ļ��С�ͨ�����·�ʽ�ɼ���ģ��,����Ԥ�⡣
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small_ssld/best_model')
result = model.predict('vegetables_cls/bocai/100.jpg')
print("Predict Result: ", result)
Ԥ�����������,
Predict Result: Predict Result: [{'score': 0.9999393, 'category': 'bocai', 'category_id': 0}]
��ô������,����Ѿ������һ��AIģ�͵Ŀ�����,��ʹ���ٸ��ӵĹ�ҵ����,���������������ϸ����
�ղ������ᵽ,��Ҫʹ��paddle X�û��ĵ����оͱ�����paddlepaddle�Ļ���(paddlepaddle-gpu��paddlepaddle(�汾���ڻ����1.8.1),��ô��������������һ�²�ͬ������paddle�İ�װ��
1����װpaddle paddle
����ÿ���û��ĵ��Ի�������һ����ͬ,���ٶȹٷ��ṩ������ҳ���ָ��,�����������,ѡ���������ڵĵ��Ի���,�Ϳ��Ի����ذ�װָ��,һ����ʮ����Ӻ�Ϳ���װ��ɡ�
������Թٷ���ָ��Ϊ���ˡ�
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/macos-pip.html

2.win/Mac/linux/anaconda/pip/pycocotools
��װpaddleX
pip��װ
������Windows��װ����
pip install paddlex -i https://mirror.baidu.com/pypi/simple
Anaconda��װ
Anaconda��һ����Դ��Python���а汾,�������conda��Python��180�����ѧ�����������ʹ��Anaconda����ͨ���������������Python����,�����û���Python������װ̫�ͬ�汾�������³�ͻ��
���밲װ
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
python setup.py install
pycocotools��װ����
PaddleX����pycocotools��,�簲װpycocotoolsʧ��,�ɲ������·�ʽ��װpycocotools
Windowsϵͳ
Windows��װʱ���ܻ���ʾMicrosoft Visual C++ 14.0 is required,�Ӷ����°�װ����,�����ʱ����Ҫ����VC build tools��װ��ִ������pip����
��������
https://go.microsoft.com/fwlink/?LinkId=691126
ע��:��װ���,��Ҫ���´��µ��ն������
pip install cython
pip install git+https://gitee.com/jiangjiajun/philferriere-cocoapi.git#subdirectory=PythonAPI
Linux/Macϵͳ
Linux/Macϵͳ��,ֱ��ʹ��pip��װ����������������
pip install cython
pip install pycocotools
Next Previous
3��openVINO��װ����ػ�������
�����ʹ��window����ϵͳ�Ļ���������ѿ��Բο�֮ǰд��һƪ����,������ÿ���Ľ�ͼ��
��������
����������ΪҪ�ͷɽ�����,�������صİ汾��һЩ�ض���Ҫ�������Ƽ�ʹ��OpenVINO 2020.4��2021.1�汾
ע��:
����PaddleX�ָ�ģ��ʹ����ReSize-11 Op,OpenVINO 2021.1�汾��ʼ֧��֧��Resize-11 ,CPU�����������OpenVINO 2021.1+�汾
����VPU��OpenVINO 2021.1�汾��ת���ķ���ģ�ͻ����Range layer��֧�ֵ����,VPU�����������OpenVINO 2020.4�汾
���Կ��¸�����Ӳ�豸��openVINO��֧��

Windows��װopenVINO
��������˵��һЩҪװ�Ļ���
��ʲô�������������Dz���,���Կ��¹ٷ������ĵ�
https://docs.openvino.ai/latest/openvino_docs_install_guides_installing_openvino_windows.html
ǰ������
Visual Studio 2019
OpenVINO 2020.4����2021.1+
CMake 3.0+
python3.6+
����������һ��:CPU��ʹ��OpenVINO 2021.1+�汾;VPU����ʹ��OpenVINO 2020.4�汾
��װ����
1����װ�ⲿ����������
2����װOpenVINOTM���߰���Ӣ�ض�?���а�
3�����û���
4������ģ���Ż���
��1��:��װ�ⲿ����������
1��Microsoft Visual Studio* 2019 with MSBuild
https://visualstudio.microsoft.com/vs/older-downloads/#visual-studio-2019-and-other-products
2��CMake 3.14 or higher 64-bit
https://cmake.org/download/
3��Python - 64-bit
https://www.python.org/downloads/windows/

��2��:��װOpenVINOTM���߰����������Ӣ�ض�?���а�
1����������Windows��OpenVINOTM���߰���Ӣ�ض�?�ַ�����OpenVINOTM���߰����ļ���Ӣ�ض�?�ַ����������˵���ѡ��������Windows��OpenVINOTM���߰���Ӣ�ض�?���а档
2��ת����Downloads���ļ���,˫����
w_openvino_toolkit_p_.exe,��һ������,������ѡ��װĿ¼�������

3��������Ļ�ϵ�˵��������ע��������Ϣ,�Է������������������:

4��Ĭ�������,Intel?Distribution of OpenVINO?��װ������Ŀ¼,���ĵ��������ط���Ϊ<INSTALL_DIR>: C:\Program Files (x86)\Intel\ openvino_��Ϊ�˼����,��������һ�����°�װ�Ŀ�ݷ�ʽ:C:\Program Files (x86)\Intel\ openvino_2021��
5����ѡ:����ѡ���Զ��������İ�װĿ¼��Ҫ��װ�������

��������ɡ��Թرհ�װ��
��������ɡ��Թرհ�װ��,����һ���µ����������,���а����������Ķ����ĵ�(�Է���û�а�װ),Ȼ����ת������������װ����IJ��֡�
����������Ѱ�װ��������һ����װ���������
��3��:���û���
������¶����������,Ȼ����ܱ��������OpenVINOTMӦ�ó���������ʾ��,Ȼ������setupvars.bat�������ļ�����ʱ���û�������:
C:\�����ļ� (x86)\Intel\openvino_2021\bin\setupvars.bat
ע��:�������������������Windows PowerShell,����������ʾ��(cmd),�������Թ���,ֻ�����ն�,���ǽ��顣
����:�ر�������ʾ����ʱ,OpenVINO���߰�������������ɾ������Ϊһ��ѡ��,�������ֶ��������û���������
��4��:����ģ���Ż���
Model Optimizer�ǻ���Python�������й���,���ڴ����е����ѧϰ���(��Caffe��TensorFlow*��Apache MXNet*��ONNX��Kaldi)����ѵ�����ص�ģ�͡�
ģ���Ż�����OpenVINO���߰�Ӣ�ض����еĹؼ��������ģ��ִ���ƶ�(ONNX��nGraphģ�ͳ���)��Ҫͨ��ģ���Ż�������ģ�͡���ͨ��ģ���Ż���ת��Ԥѵ����ģ��ʱ,�����������м��ʾ(IR)���м��ʾ��һ����������ģ�͵��ļ�:
.xml:������������
.bin:����Ȩ�غ�ƫ�ö���������
1�����������ڿ�������cmd��������ʾ��,Ȼ��Enter�����ڴĴ�������������:
2��ת��ģ���Ż����Ⱦ�����Ŀ¼��
cd C:\Program Files (x86)\Intel\openvino_2021\deployment_tools\model_optimizer\install_prerequisites
3�����д��������ļ�������Caffe��TensorFlow 2.x��MXNet��Kaldi*��ONNX��ģ���Ż���:
install_prerequisites.bat
ע��:��װ��OpenVINO����Ҫ�ֶ�����OpenVINOĿ¼��ϵͳ��������,���������г���ʱ������Ҳ���dll���������װOpenVINOʱ���ı�OpenVINO��װĿ¼�����Ϊʾ��,
��������
�ҵĵ���->����->��ϵͳ����->��������
��ϵͳ�������ҵ�Path(��û��,���д���),��˫���༭
�½�,�ֱ�OpenVINO����·�����벢����:
C:\Program File (x86)\IntelSWTools\openvino\inference_engine\bin\intel64\Release
C:\Program File (x86)\IntelSWTools\openvino\inference_engine\external\tbb\bin
C:\Program File (x86)\IntelSWTools\openvino\deployment_tools\ngraph\lib
��ȷ��ϵͳ�Ѿ���װ��������������,�����ú���Ӧ����,��������ʾ���Թ���Ŀ¼Ϊ D:\projects��ʾ��
window- paddle- openVINO����
����ʹ��c++��Ԥ�ⲿ��ķ���
Step1: ����PaddleXԤ�����
��win���ն�,����D������Ԥ�����
d:
mkdir projects
cd projects
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
˵��:����C++Ԥ�������PaddleX\deploy\openvino Ŀ¼,��Ŀ¼�������κ�PaddleX������Ŀ¼��
Step2 ��������
�ṩ����������Ԥ�����:
������opencv����Ҫ���û�������,����������ʾ- �ҵĵ���->����->��ϵͳ����->�������� - ��ϵͳ�������ҵ�Path(��û��,���д���),��˫���༭ - �½�,��opencv·�����벢����,��D:\projects\opencv\build\x64\vc14\bin
Step3: ʹ��Visual Studio 2019ֱ�ӱ���CMake
��Visual Studio 2019 Community,����������������
���: �ļ�->��->CMake ѡ��C++Ԥ���������·��(����D:\projects\PaddleX\deploy\openvino),����CMakeList.txt
���:��Ŀ->CMake����
������,�ֱ����ñ���ѡ��ָ��OpenVINO��Gflags��NGRAPH��OPENCV��·��

������ɺ�, ������沢����CMake�����Լ��ر����� 5. �������->ȫ������
Step4: Ԥ��
����Visual Studio 2019��������Ŀ�ִ���ļ���out\build\x64-ReleaseĿ¼��,��cmd,���л�����Ŀ¼:
D:
cd D:\projects\PaddleX\deploy\openvino\out\build\x64-Release
����ɹ���,ͼƬԤ��demo����ڳ���Ϊdetector.exe,classifier.exe,segmenter.exe,�û��ɸ����Լ���ģ������ѡ��,����Ҫ�������˵������:

����:
��CPU��������ͼƬ�ķ�������Ԥ�����ͼƬ /path/to/test_img.jpeg
ֱ�����ն��������д��뿴��Ԥ���Ƿ��ܳɹ�
./classifier.exe --model_dir=/path/to/openvino_model --image=/path/to/test_img.jpeg --cfg_file=/path/to/PadlleX_model.yml
����ɹ��Ļ�,��ϲ�����Ѿ�������windowϵͳ��ʹ�������ˡ�
Linux��װopenVINO
������������һЩ�����ĵط�,����ֱ�ӿ��¹ٷ��ļ����ĵ���
https://docs.openvino.ai/latest/openvino_docs_install_guides_installing_openvino_linux.html
������˵��Linux�İ�װ����,�����˵��windows���:
1����װOpenVINOTM���߰���Ӣ�ض�?���а�
2����װ�ⲿ����������
3�����û���
4������ģ���Ż���
��1��:��װOpenVINOTM���߰����������Ӣ�ض�?���а�
��������Linux��OpenVINOTM���߰���Ӣ�ض�?�ַ�*OpenVINOTM���߰����ذ��ļ���Ӣ�ض�?�ַ����������˵���ѡ��������Linux��������OpenVINOTM���߰���Ӣ�ض�?���а档
1����������ʾ�ն˴��ڡ�ʹ�ü��̿�ݼ�:Ctrl+Alt+T
2����Ŀ¼����Ϊ������Linux*�������ļ���OpenVINO���߰���Ӣ�ض��ַ���
3����������������ļ����ص���ǰ�û���DownloadsĿ¼:
cd ~/����/
Ĭ�������,���ļ�����Ϊl_openvino_toolkit_p_.tgz,����l_openvino_toolkit_p_2021.4.689.tgz��
4����ѹ.tgz�ļ�:
tar -xvzf l_openvino_toolkit_p_<version>.tgz
5��ת��l_openvino_toolkit_p_Ŀ¼:
cd l_openvino_toolkit_p_<�汾>
6��ѡ��װѡ��,������ؽű���Ϊ������,��ʹ��ͼ���û�����(GUI)��װ��������ָ��(CLI)��GUI�ṩ��ͼ,CLI���ṩ��ͼ���������ϢҲ������CLI,��װ���а���,���Կ�����ͬ��ѡ�������
ѡ��1:GUI��װ��:
sudo ./install_GUI.sh
ѡ��2:������˵��:
Sudo ./install.sh
ѡ��3:�����о���˵��:
sudo sed -i's/decline/accept/g' silent.cfg
sudo ./install.sh -s silent.cfg
7��ע��������Ϣ,�Է����������������,������û��ȱ����:

���ڸ������Ա:/opt/intel/openvino_/
������ͨ�û�:/home//intel/openvino_/
Ϊ�˼����,�����������°�װ�ķ�������:/opt/intel/openvino_2021/��/home//intel/openvino_2021/
8������ɡ���Ļ��ʾ��������Ѱ�װ:

��������ɡ��رհ�װ��,��ʹ�ô��ĵ���һ���µ���������ڡ�����ת������������װ����IJ��֡�
Ĭ�������,OpenVINOTM��Ӣ�ض�?���а氲װ������Ŀ¼��:
��2��:��װ�ⲿ����������
�����OpenVINOTM��Ӣ�ض�?���а氲װ����Ĭ��Ŀ¼,�뽫/opt/intel�滻Ϊ��װ������Ŀ¼��
�������������������������:
Ӣ�ض��Ż���OpenCV���
���ѧϰ��������
���ѧϰģ���Ż�������
1��ת��install_dependenciesĿ¼:
cd /opt/intel/openvino_2021/install_dependencies
2�����нű����غͰ�װ�ⲿ����������:
sudo -E ./install_openvino_dependencies.sh
��װ�������,������һ�����û���������
��3��:���û���
������¶����������,Ȼ����ܱ��������OpenVINOTMӦ�ó���ʹ��vi(����)����ѡ�༭���������³־û�������:
1����/home/�д�.bashrc�ļ�:
vi ~/.bashrc
2����i���л�������ģʽ��
3�������������ӵ��ļ�ĩβ:
��Դ/opt/intel/openvino_2021/bin/setupvars.sh
4�����沢�ر��ļ�:��Esc��������:wq��
5��Ҫ��֤����,���һ���µ��նˡ���������[setupvars.sh] OpenVINO�����ѳ�ʼ����
��Դ/opt/intel/openvino_2021/bin/setupvars.sh
�����˻���������������,������ģ���Ż�����
��4��:����ģ���Ż���
����CentOS����ʽ֧��TensorFlow���,������ڸò���ϵͳ�����ú�����TensorFlow��ģ���Ż�����
*
Model Optimizer�ǻ���Python�������й���,���ڴ����е����ѧϰ���(��Caffe��TensorFlow��Apache MXNet��ONNX��Kaldi)����ѵ�����ص�ģ�͡�
ģ���Ż�����OpenVINO���߰�Ӣ�ض����еĹؼ��������ģ��ִ���ƶ�(ONNX��nGraphģ�ͳ���)��Ҫͨ��ģ���Ż�������ģ�͡���ͨ��ģ���Ż�������Ԥѵ��ģ��ʱ,�����������м��ʾ(IR)���м��ʾ��һ����������ģ�͵��ļ�:
.xml:������������
.bin:����Ȩ�غ�ƫ�ö���������
1��ת��ģ���Ż����Ⱦ�����Ŀ¼:
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/install_prerequisites
2�����нű�ΪCaffe��TensorFlow 2.x��MXNet��Kaldi��ONNX����ģ���Ż���:
sudo ./install_prerequisites.sh
����Ѿ���װ��paddle��openVINO��,�����ú���Ӧ����,��������ʾ���Թ���Ŀ¼ /root/projects/��ʾ��
Ԥ�ⲿ�����
�ĵ��ṩ��c++��Ԥ�ⲿ��ķ���,�����Ҫ��python��Ԥ�ⲿ����ο�pythonԤ�ⲿ��
Step1 ����PaddleXԤ�����
mkdir -p /root/projects
cd /root/projects
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
˵��:����C++Ԥ�������PaddleX/deploy/openvino Ŀ¼,��Ŀ¼�������κ�PaddleX������Ŀ¼��
Step2 ��������
Step3�еı���ű���һ����װ����������������Ԥ�����,�û�����Ҫ�������ػ������Щ����������
Step3: ����
����cmake��������scripts/build.sh��,������ݮ��(Raspbian OS)�ϱ�������ARCH����x86Ϊarmv7,�����б���������������������Step1�б���������ʵ���������Ҫ����,����Ҫ����˵������:
#openvinoԤ������·��
OPENVINO_DIR=$INTEL_OPENVINO_DIR/inference_engine
#gflagsԤ������·��
GFLAGS_DIR=$(pwd)/deps/gflags
#ngraph libԤ������·��
NGRAPH_LIB=$INTEL_OPENVINO_DIR/deployment_tools/ngraph/lib
#opencvԤ������·��
OPENCV_DIR=$(pwd)/deps/opencv/
#cpu�ܹ�(x86��armv7)
ARCH=x86
ִ��build�ű�:
sh ./scripts/build.sh
Step4: Ԥ��
������һ�������������
linuxϵͳ��CPU��������ͼƬ�ķ�������Ԥ�����ͼƬ /path/to/test_img.jpeg
./build/classifier --model_dir=/path/to/openvino_model --image=/path/to/test_img.jpeg --cfg_file=/path/to/PadlleX_model.yml
����ɹ���,���������Ԥ���ִ�г���Ϊclassifier,��������Ԥ���ִ�г���Ϊdetector,�ָ������Ԥ���ִ�г���Ϊsegmenter,����Ҫ�������˵������:

��ʼѵ��
�����뱣�浽���غ�����(������������λ������ı�����),������Զ�����ѵ�����ݲ���ʼѵ�����籣��Ϊdeeplabv3p_mobilenetv2_x0.25.py,ִ����������ɿ�ʼѵ��:
python deeplabv3p_mobilenetv2_x0.25.py
OpenVINO��������
תģ�����г��֡�ModuleNotFoundError: No module named ��mo����
ԭ��:��������Ҫ����Ϊ�ڰ�װOpenVINO֮��δ��ʼ��OpenVINO�����������:�ҵ�OpenVINO��ʼ�������ű�,���к��Խ��������
Linuxϵͳ��ʼ��OpenVINO����
1)root�û���װ,��OpenVINO 2021.1�汾Ϊ��,������������ɳ�ʼ��
source /opt/intel/openvino_2021/bin/setupvars.sh
2)��root�û���װ,��OpenVINO 2021.1�汾���û���ΪpaddlexΪ��,������������ɳ�ʼ��
source /home/paddlex/intel/openvino_2021/bin/setupvar.sh
Windowϵͳ��ʼ��OpenVINO����
��OpenVINO 2021.1�汾Ϊ��,ִ����������ɳ�ʼ��OpenVINO����
cd C:\Program Files (x86)\Intel\openvino_2021\bin\
setupvars.bat
paddlepaddle��ѵ��
������(���ݱ�ע��ת��������)
ʹ��Labelme��ע
��������:
https://paddlex.readthedocs.io/zh_CN/release-1.3/data/annotation/labelme.html
LabelMe�İ�װ������
LabelMe�İ�װ������
LabelMe�����ڱ�עĿ���⡢ʵ���ָ����ָ����ݼ�,��һ�Դ�ı�ע���ߡ�
- ��װAnaconda
�Ƽ�ʹ��Anaconda��װpython����,�о���Ŀ����߿��������˲��衣��װAnaconda�ķ�ʽ���Բο��ĵ���
�ڰ�װAnaconda,����������֮��,�ٽ��н������IJ���
- ��װLabelMe
����Python������,ִ�����������
conda activate my_paddlex
conda install pyqt
pip install labelme
- ����LabelMe
���밲װ��LabelMe��Python����,ִ���������������LabelMe
conda activate my_paddlex
labelme
ͼ�����
ͼ������ע��һ�������,��ı�ע����,�û�ֻ�轫����ͬһ���ͼƬ����ͬһ���ļ����¼���,��������ʾĿ¼�ṹ,
MyDataset/ # ͼ��������ݼ���Ŀ¼
|--dog/ # ��ǰ�ļ�������ͼƬ����dog���
| |--d1.jpg
| |--d2.jpg
| |--...
| |--...
|
|--...
|
|--snake/ # ��ǰ�ļ�������ͼƬ����snake���
| |--s1.jpg
| |--s2.jpg
| |--...
| |--...
���ݻ���
��ģ�ͽ���ѵ��ʱ,������Ҫ����ѵ����,��֤���Ͳ��Լ�,�����Ҫ���������ݽ��л���,ֱ��ʹ��paddlex����ɽ����ݼ�������ֳ�70%ѵ����,20%��֤����10%���Լ�
paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
���ֺõ����ݼ����������labels.txt, train_list.txt, val_list.txt, test_list.txt�ĸ��ļ�,֮���ֱ�ӽ���ѵ����
Ŀ����
Ŀ�������ݵı�ע�Ƽ�ʹ��LabelMe��ע����,����ǰ���ް�װ,��ôLabelMe�İ�װ�ɲο�LabelMe��װ������
��������:
https://paddlex.readthedocs.io/zh_CN/release-1.3/data/annotation/labelme.html
ע��:LabelMe��Ҫ�����µ�·���Լ��ļ����г��������ַ�!
������
1�����ռ���ͼ������JPEGImages�ļ�����,����洢��D:\MyDataset\JPEGImages
2��������ͼ���ļ������Ӧ���ļ���Annotations,���ڴ洢��ע��json�ļ�,��D:MyDataset\Annotations
3����LabelMe,�����Open Dir����ť,ѡ����Ҫ��ע��ͼ�����ڵ��ļ��д�,��File List���Ի����л���ʾ����ͼ������Ӧ�ľ���·��,���ű���Կ�ʼ����ÿ��ͼ��,���б�ע����
Ŀ����ע
1�����ο��ע����(�Ҽ��˵�->Create Rectangle),��������ͼ��ʾ

2��ʹ�������ķ�ʽ��Ŀ��������б�ʶ,���ڵ����ĶԻ�����д����Ӧlabel(��label�Ѵ���ʱ�������, �˴���ע��label��ʹ������),��������ͼ��ʾ,�����ע����ʱ,�ɵ�����ġ�Edit Polygons���ٵ����ע��,ͨ������������,Ҳ���ٵ����Delete Polygon������ɾ����

3������ҲࡱSave��,����ע������浽�д������ļ���AnnotationsĿ¼��
��ʽת��
LabelMe��ע������ݻ���Ҫ����ת��ΪPascalVOC��MSCOCO��ʽ,�ſ�������Ŀ���������ѵ��,����D:\dataset_vocĿ¼,��python�����а�װpaddlex��,ʹ�����������
paddlex --data_conversion --source labelme --to PascalVOC \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_voc
���ݼ�����
ת�������ݺ�,Ϊ�˽���ѵ��,����Ҫ�����ݻ���Ϊѵ��������֤���Ͳ��Լ�,ͬ���ڰ�װpaddlex��,ʹ����������ɽ����ݻ���Ϊ70%ѵ����,20%��֤����10%�IJ��Լ�
paddlex --split_dataset --format VOC --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
ִ������������,����D:\MyDataset������labels.txt, train_list.txt, val_list.txt��test_list.txt,�ֱ�洢�����Ϣ,ѵ�������б�,��֤�����б�,���������б�
ʵ���ָ�
������
1�����ռ���ͼ������JPEGImages�ļ�����,����洢��D:\MyDataset\JPEGImages
2��������ͼ���ļ������Ӧ���ļ���Annotations,���ڴ洢��ע��json�ļ�,��D:MyDataset\Annotations
3����LabelMe,�����Open Dir����ť,ѡ����Ҫ��ע��ͼ�����ڵ��ļ��д�,��File List���Ի����л���ʾ����ͼ������Ӧ�ľ���·��,���ű���Կ�ʼ����ÿ��ͼ��,���б�ע����
Ŀ���Ե��ע
1������α�ע����(�Ҽ��˵�->Create Polygon)�Դ��ķ�ʽȦ��Ŀ�������,���ڵ����ĶԻ�����д����Ӧlabel(��label�Ѵ���ʱ�������,�˴���ע��label��ʹ������),������������ʾ,�����ע����ʱ,�ɵ�����ġ�Edit Polygons���ٵ����ע��,ͨ������������,Ҳ���ٵ����Delete Polygon������ɾ���� 
2������ҲࡱSave��,����ע������浽�д������ļ���AnnotationsĿ¼��
��ʽת��
LabelMe��ע������ݻ���Ҫ����ת��ΪMSCOCO��ʽ,�ſ�������ʵ���ָ������ѵ��,��������Ŀ¼D:\dataset_seg,��python�����а�װpaddlex��,ʹ�����������
paddlex --data_conversion --source labelme --to MSCOCO \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_coco
���ݼ�����
ת�������ݺ�,Ϊ�˽���ѵ��,����Ҫ�����ݻ���Ϊѵ��������֤���Ͳ��Լ�,ͬ���ڰ�װpaddlex��,ʹ����������ɽ����ݻ���Ϊ70%ѵ����,20%��֤����10%�IJ��Լ�
paddlex --split_dataset --format COCO --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
ִ������������,����D:\MyDataset������train.json, val.json, test.json,�ֱ�洢ѵ��������Ϣ,��֤������Ϣ,����������Ϣ
����ָ�
������
1�����ռ���ͼ������JPEGImages�ļ�����,����洢��D:\MyDataset\JPEGImages
2��������ͼ���ļ������Ӧ���ļ���Annotations,���ڴ洢��ע��json�ļ�,��D:MyDataset\Annotations
3����LabelMe,�����Open Dir����ť,ѡ����Ҫ��ע��ͼ�����ڵ��ļ��д�,��File List���Ի����л���ʾ����ͼ������Ӧ�ľ���·��,���ű���Կ�ʼ����ÿ��ͼ��,���б�ע����
Ŀ���Ե��ע
1������α�ע����(�Ҽ��˵�->Create Polygon)�Դ��ķ�ʽȦ��Ŀ�������,���ڵ����ĶԻ�����д����Ӧlabel(��label�Ѵ���ʱ�������,�˴���ע��label��ʹ������),������������ʾ,�����ע����ʱ,�ɵ�����ġ�Edit Polygons���ٵ����ע��,ͨ������������,Ҳ���ٵ����Delete Polygon������ɾ���� 
2������ҲࡱSave��,����ע������浽�д������ļ���AnnotationsĿ¼��
��ʽת��
LabelMe��ע������ݻ���Ҫ����ת��ΪSEG��ʽ,�ſ�����������ָ������ѵ��,��������Ŀ¼D:\dataset_seg,��python�����а�װpaddlex��,ʹ�����������
paddlex --data_conversion --source labelme --to SEG \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_seg
���ݼ�����
ת�������ݺ�,Ϊ�˽���ѵ��,����Ҫ�����ݻ���Ϊѵ��������֤���Ͳ��Լ�,ͬ���ڰ�װpaddlex��,ʹ����������ɽ����ݻ���Ϊ70%ѵ����,20%��֤����10%�IJ��Լ�
paddlex --split_dataset --format SEG --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
ִ������������,����D:\MyDataset������train_list.txt, val_list.txt, test_list.txt,�ֱ�洢ѵ��������Ϣ,��֤������Ϣ,����������Ϣ
���ݸ�ʽ
ͼ�����ImageNet
�����ļ��нṹ
��PaddleX��,ͼ�����֧��ImageNet���ݼ���ʽ�����ݼ�Ŀ¼data_dir�°�������ļ���,ÿ���ļ����е�ͼ�������ͬһ�����,�ļ��е�������Ϊ�����(ע��·���в�Ҫ��������,�ո�)�� ����Ϊʾ���ṹ
MyDataset/ # ͼ��������ݼ���Ŀ¼
|--dog/ # ��ǰ�ļ�������ͼƬ����dog���
| |--d1.jpg
| |--d2.jpg
| |--...
| |--...
|
|--...
|
|--snake/ # ��ǰ�ļ�������ͼƬ����snake���
| |--s1.jpg
| |--s2.jpg
| |--...
| |--...
����ѵ������֤��
Ϊ������ѵ��,������Ҫ��MyDatasetĿ¼����train_list.txt, val_list.txt��labels.txt�����ļ�,�ֱ����ڱ�ʾѵ�����б�,��֤���б�������ǩ�б����������ͼ�����ʾ�����ݼ�
ע:Ҳ��ʹ��PaddleX�Դ�����,�����ݼ������������,�����ݼ����������ʽ��֯��,ʹ����������ɿ���������ݼ��������,����val_value��ʾ��֤���ı���,test_value��ʾ���Լ��ı���(����Ϊ0),ʣ��ı�������ѵ������
paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
labels.txt
labels.txt�����г��������,����Ӧ�кű�ʾģ��ѵ������������id(�кŴ�0��ʼ����),����labels.txtΪ��������
dog
cat
snake
����ʾ�÷������ݼ��й���3�����,�ֱ�Ϊdog,cat��snake,��ģ��ѵ����dog��Ӧ�����idΪ0, cat��Ӧ1,�Դ�����
train_list.txt
train_list.txt�г�����ѵ��ʱ��ͼƬ����,�����Ӧ�����id,ʾ������
dog/d1.jpg 0
dog/d2.jpg 0
cat/c1.jpg 1
... ...
snake/s1.jpg 2
���е�һ��Ϊ��Զ�MyDataset�����·��,�ڶ���ΪͼƬ��Ӧ�������id
val_list.txt
val_list�г�������֤ʱ��ͼƬ����,�����Ӧ�����id,��ʽ��train_list.txtһ��
PaddleX���ݼ�����
ʾ����������,
import paddlex as pdx
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224), transforms.Normalize()
])
train_dataset = pdx.datasets.ImageNet(
data_dir='./MyDataset',
file_list='./MyDataset/train_list.txt',
label_list='./MyDataset/labels.txt',
transforms=train_transforms)
eval_dataset = pdx.datasets.ImageNet(
data_dir='./MyDataset',
file_list='./MyDataset/eval_list.txt',
label_list='./MyDataset/labels.txt',
transforms=eval_transforms)
Next Previous
Ŀ����PascalVOC
���ݼ��ļ��нṹ
��PaddleX��,Ŀ����֧��PascalVOC���ݼ���ʽ�������û������ݼ��������·�ʽ������֯,ԭͼ������ͬһĿ¼,��JPEGImages,��ע��ͬ��xml�ļ�������ͬһĿ¼,��Annotations,ʾ������
MyDataset/ # Ŀ�������ݼ���Ŀ¼
|--JPEGImages/ # ԭͼ�ļ�����Ŀ¼
| |--1.jpg
| |--2.jpg
| |--...
| |--...
|
|--Annotations/ # ��ע�ļ�����Ŀ¼
| |--1.xml
| |--2.xml
| |--...
| |--...
����ѵ������֤��
Ϊ������ѵ��,������Ҫ��MyDatasetĿ¼����train_list.txt, val_list.txt��labels.txt�����ļ�,�ֱ����ڱ�ʾѵ�����б�,��֤���б�������ǩ�б����������Ŀ����ʾ�����ݼ�
ע:Ҳ��ʹ��PaddleX�Դ�����,�����ݼ������������,�����ݼ����������ʽ��֯��,ʹ����������ɿ���������ݼ��������,����val_value��ʾ��֤���ı���,test_value��ʾ���Լ��ı���(����Ϊ0),ʣ��ı�������ѵ������
paddlex --split_dataset --format VOC --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
labels.txt
labels.txt�����г��������,����Ӧ�кű�ʾģ��ѵ������������id(�кŴ�0��ʼ����),����labels.txtΪ��������
dog
cat
snake
��ʾ�ü�����ݼ��й���3��Ŀ�����,�ֱ�Ϊdog,cat��snake,��ģ��ѵ����dog��Ӧ�����idΪ0, cat��Ӧ1,�Դ�����
train_list.txt
train_list.txt�г�����ѵ��ʱ��ͼƬ����,�����Ӧ�ı�ע�ļ�,ʾ������
JPEGImages/1.jpg Annotations/1.xml
JPEGImages/2.jpg Annotations/2.xml
... ...
���е�һ��Ϊԭͼ���MyDataset�����·��,�ڶ���Ϊ��ע�ļ����MyDataset�����·��
val_list.txt
val_list�г�������֤ʱ��ͼƬ����,�����Ӧ�ı�ע�ļ�,��ʽ��val_list.txtһ��
PaddleX���ݼ�����
ʾ����������,
import paddlex as pdx
from paddlex.det import transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32)
])
eval_transforms = transforms.Compose([
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32),
])
train_dataset = pdx.datasets.VOCDetection(
data_dir='./MyDataset',
file_list='./MyDataset/train_list.txt',
label_list='./MyDataset/labels.txt',
transforms=train_transforms)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='./MyDataset',
file_list='./MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms)
Next Previous
ʵ���ָ�MSCOCO
���ݼ��ļ��нṹ
��PaddleX��,ʵ���ָ�֧��MSCOCO���ݼ���ʽ(MSCOCO��ʽͬ��Ҳ��������Ŀ����)�������û������ݼ��������·�ʽ������֯,ԭͼ������ͬһĿ¼,��JPEGImages,��ע�ļ�(��annotations.json)������JPEGImages����Ŀ¼ͬ��Ŀ¼��,ʾ���ṹ����
MyDataset/ # ʵ���ָ����ݼ���Ŀ¼
|--JPEGImages/ # ԭͼ�ļ�����Ŀ¼
| |--1.jpg
| |--2.jpg
| |--...
| |--...
|
|--annotations.json # ��ע�ļ�����Ŀ¼
����ѵ������֤��
��PaddleX��,Ϊ������ѵ��������֤��,��MyDatasetͬ��Ŀ¼,ʹ�ò�ͬ��json��ʾ���ݵĻ���,����train.json��val.json���������ʵ���ָ�ʾ�����ݼ���
ע:Ҳ��ʹ��PaddleX�Դ�����,�����ݼ������������,�����ݼ����������ʽ��֯��,ʹ����������ɿ���������ݼ��������,����val_value��ʾ��֤���ı���,test_value��ʾ���Լ��ı���(����Ϊ0),ʣ��ı�������ѵ������
paddlex --split_dataset --format COCO --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
MSCOCO���ݵı�ע�ļ�����json��ʽ,�û���ʹ��Labelme, �����ע���ֻ�EasyData�ȱ�ע���߽��б�ע,�μ����ݱ�ע����
PaddleX�������ݼ�
ʾ����������,
import paddlex as pdx
from paddlex.det import transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32)
])
eval_transforms = transforms.Compose([
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32),
])
train_dataset = pdx.dataset.CocoDetection(
data_dir='./MyDataset/JPEGImages',
ann_file='./MyDataset/train.json',
transforms=train_transforms)
eval_dataset = pdx.dataset.CocoDetection(
data_dir='./MyDataset/JPEGImages',
ann_file='./MyDataset/val.json',
transforms=eval_transforms)
Next Previous
����ָ�Seg
���ݼ��ļ��нṹ
��PaddleX��,��ע�ļ�Ϊpng�ļ��������û������ݼ��������·�ʽ������֯,ԭͼ������ͬһĿ¼,��JPEGImages,��ע��ͬ��png�ļ�������ͬһĿ¼,��Annotations,ʾ������
MyDataset/ # ����ָ����ݼ���Ŀ¼
|--JPEGImages/ # ԭͼ�ļ�����Ŀ¼
| |--1.jpg
| |--2.jpg
| |--...
| |--...
|
|--Annotations/ # ��ע�ļ�����Ŀ¼
| |--1.png
| |--2.png
| |--...
| |--...
����ָ�ı�עͼ��,��1.png,Ϊ��ͨ��ͼ��,���ر�ע�����Ҫ��0��ʼ����(һ��0��ʾbackground����), ����0, 1, 2, 3��ʾ4�����,��ע������255�����(��������ֵ255������ѵ��������)��
����ѵ������֤��
Ϊ������ѵ��,������Ҫ��MyDatasetĿ¼����train_list.txt, val_list.txt��labels.txt�����ļ�,�ֱ����ڱ�ʾѵ�����б�,��֤���б�������ǩ�б��������������ָ�ʾ�����ݼ�
ע:Ҳ��ʹ��PaddleX�Դ�����,�����ݼ������������,�����ݼ����������ʽ��֯��,ʹ����������ɿ���������ݼ��������,����val_value��ʾ��֤���ı���,test_value��ʾ���Լ��ı���(����Ϊ0),ʣ��ı�������ѵ������
paddlex --split_dataset --format Seg --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
labels.txt
labels.txt�����г��������,����Ӧ�кű�ʾģ��ѵ������������id(�кŴ�0��ʼ����),����labels.txtΪ��������
background
human
car
��ʾ�ü�����ݼ��й���3���ָ����,�ֱ�Ϊbackground,human��car,��ģ��ѵ����background��Ӧ�����idΪ0, human��Ӧ1,�Դ�����,�粻֪��������ǩ,��ֱ����labels.txt����д0,1,2�����м��ɡ�
train_list.txt
train_list.txt�г�����ѵ��ʱ��ͼƬ����,�����Ӧ�ı�ע�ļ�,ʾ������
JPEGImages/1.jpg Annotations/1.png
JPEGImages/2.jpg Annotations/2.png
... ...
���е�һ��Ϊԭͼ���MyDataset�����·��,�ڶ���Ϊ��ע�ļ����MyDataset�����·��
val_list.txt
val_list�г�������֤ʱ��ͼƬ����,�����Ӧ�ı�ע�ļ�,��ʽ��val_list.txtһ��
PaddleX���ݼ�����
ʾ����������,
import paddlex as pdx
from paddlex.seg import transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ResizeRangeScaling(),
transforms.RandomPaddingCrop(crop_size=512),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByLong(long_size=512),
transforms.Padding(target_size=512),
transforms.Normalize()
])
train_dataset = pdx.datasets.SegDataset(
data_dir='./MyDataset',
file_list='./MyDataset/train_list.txt',
label_list='./MyDataset/labels.txt',
transforms=train_transforms)
eval_dataset = pdx.datasets.SegDataset(
data_dir='./MyDataset',
file_list='./MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms)
�ؿ���ChangeDet
���ݼ��ļ��нṹ
��PaddleX��,��ע�ļ�Ϊpng�ļ��������û������ݼ��������·�ʽ������֯,ͬһ�ؿ鲻ͬʱ�ڵĵ�òԭͼ������ͬһĿ¼,��JPEGImages,��ע��ͬ��png�ļ�������ͬһĿ¼,��Annotations,ʾ������
MyDataset/ # ����ָ����ݼ���Ŀ¼
|--JPEGImages/ # ԭͼ�ļ�����Ŀ¼,����ͬһ����ǰ�ںͺ��ڵ�ͼƬ
| |--1_1.jpg
| |--1_2.jpg
| |--2_1.jpg
| |--2_2.jpg
| |--...
| |--...
|
|--Annotations/ # ��ע�ļ�����Ŀ¼
| |--1.png
| |--2.png
| |--...
| |--...
ͬһ�ؿ鲻ͬʱ�ڵĵ�òԭͼ,��1_1.jpg��1_2.jpg,������RGB��ɫͼ�Ҷ�ͼ����tiff��ʽ�Ķ�ͨ��ͼ������ָ�ı�עͼ��,��1.png,Ϊ��ͨ��ͼ��,���ر�ע�����Ҫ��0��ʼ����(һ��0��ʾbackground����), ����0, 1, 2, 3��ʾ4�����,��ע������255�����(��������ֵ255������ѵ��������)��
����ѵ������֤��
Ϊ������ѵ��,������Ҫ��MyDatasetĿ¼����train_list.txt, val_list.txt��labels.txt�����ļ�,�ֱ����ڱ�ʾѵ�����б�,��֤���б�������ǩ�б���
labels.txt
labels.txt�����г��������,����Ӧ�кű�ʾģ��ѵ������������id(�кŴ�0��ʼ����),����labels.txtΪ��������
unchanged
changed
��ʾ�ü�����ݼ��й���2���ָ����,�ֱ�Ϊunchanged��changed,��ģ��ѵ����unchanged��Ӧ�����idΪ0, changed��Ӧ1,�Դ�����,�粻֪��������ǩ,��ֱ����labels.txt����д0,1,2�����м��ɡ�
train_list.txt
train_list.txt�г�����ѵ��ʱ��ͼƬ����,�����Ӧ�ı�ע�ļ�,ʾ������
JPEGImages/1_1.jpg JPEGImages/1_2.jpg Annotations/1.png
JPEGImages/2_1.jpg JPEGImages/2_2.jpg Annotations/2.png
... ...
���е�һ�к͵ڶ���Ϊԭͼ���MyDataset�����·��,��Ӧͬһ�ؿ鲻ͬʱ�ڵĵ�òͼ��,������Ϊ��ע�ļ����MyDataset�����·��
val_list.txt
val_list�г�������֤ʱ��ͼƬ����,�����Ӧ�ı�ע�ļ�,��ʽ��val_list.txtһ��
paddleģ��ѵ�����������
ģ��ѵ��
ͼ�����
PaddleX���ṩ��20+��ͼ�����ģ��,�����㿪���߲�ͬ�����������µ�ʹ�á�
-Top1����: ģ����ImageNet���ݼ��ϵIJ��Ծ���
-Ԥ���ٶ�:����ͼƬ��Ԥ����ʱ(������Ԥ�����ͺ���)
-��-����ʾָ����δ����

��ʼѵ��
�����뱣�浽���غ�����(������������λ������ı���),������Զ�����ѵ�����ݲ���ʼѵ�����籣��Ϊmobilenetv3_small_ssld.py,ִ����������ɿ�ʼѵ��:
python mobilenetv3_small_ssld.py
Ŀ����
PaddleXĿǰ�ṩ��FasterRCNN��YOLOv3���ּ��ṹ,����backboneģ��,�����㿪���߲�ͬ���������ܵ�����
-Box MMAP: ģ����COCO���ݼ��ϵIJ��Ծ���
-Ԥ���ٶ�:����ͼƬ��Ԥ����ʱ(������Ԥ�����ͺ���)
-��-����ʾָ����δ����

��ʼѵ��
�����뱣�浽���غ�����(������������λ������ı���),������Զ�����ѵ�����ݲ���ʼѵ�����籣��Ϊyolov3_mobilenetv1.py,ִ����������ɿ�ʼѵ��:
python yolov3_mobilenetv1.py
ʵ���ָ�
PaddleXĿǰ�ṩ��MaskRCNNʵ���ָ�ģ�ͽṹ,����backboneģ��,�����㿪���߲�ͬ���������ܵ�����
-Box MMAP/Seg MMAP: ģ����COCO���ݼ��ϵIJ��Ծ���
-Ԥ���ٶ�:����ͼƬ��Ԥ����ʱ(������Ԥ�����ͺ���)
-��-����ʾָ����δ����

��ʼѵ��
�����뱣�浽���غ�����(������������λ�����������),������Զ�����ѵ�����ݲ���ʼѵ�����籣��Ϊmask_rcnn_r50_fpn.py,ִ����������ɿ�ʼѵ��:
python mask_rcnn_r50_fpn.py
����ָ�
PaddleXĿǰ�ṩ��DeepLabv3p��UNet��HRNet��FastSCNN��������ָ�ṹ,����backboneģ��,�����㿪���߲�ͬ���������ܵ�����
-mIoU: ģ����CityScape���ݼ��ϵIJ��Ծ���
-Ԥ���ٶ�:����ͼƬ��Ԥ����ʱ(������Ԥ�����ͺ���)
-��-����ʾָ����δ����

��ʼѵ��
�����뱣�浽���غ�����(������������λ������ı�����),������Զ�����ѵ�����ݲ���ʼѵ�����籣��Ϊdeeplabv3p_mobilenetv2_x0.25.py,ִ����������ɿ�ʼѵ��:
python deeplabv3p_mobilenetv2_x0.25.py
����ģ��Ԥ��
ͼ�����
����ģ��Ԥ��
PaddleX����ʹ��paddlex.load_model�ӿڼ���ģ��(����ѵ�������б����ģ��,�����IJ���ģ��,����ģ���Լ��ü���ģ��)����Ԥ��,ͬʱPaddleX��Ҳ������һϵ�еĿ��ӻ����ߺ���,�����û�����ؼ��ģ�͵�Ч����
ע��:ʹ��paddlex.load_model�ӿڼ��ؽ�����ģ��Ԥ��,����Ҫ�ڴ�ģ�ͻ����ϼ���ѵ��,���Խ���ģ����ΪԤѵ��ģ�ͽ���ѵ��,������������ѵ��������,��train�����е�pretrain_weights����ָ��ΪԤѵ��ģ��·����
ͼ�����
�����������ʾ�������е�ģ��
import paddlex as pdx
test_jpg = 'mobilenetv3_small_ssld_imagenet/test.jpg'
model = pdx.load_model('mobilenetv3_small_ssld_imagenet')
result = model.predict(test_jpg)
print("Predict Result: ", result)
����������:
Predict Result: [{'category_id': 549, 'category': 'envelope', 'score': 0.29062933}]
����ͼƬ����:

Ŀ����
�����������ʾ��������ģ��
import paddlex as pdx
test_jpg = 'yolov3_mobilenetv1_coco/test.jpg'
model = pdx.load_model('yolov3_mobilenetv1_coco')
#predict�ӿڲ�δ���˵����Ŷ�ʶ����,�û���������scoreֵ���й���
result = model.predict(test_jpg)
#���ӻ�����洢��./visualized_test.jpg, ����ͼ
pdx.det.visualize(test_jpg, result, threshold=0.3, save_dir='./')

ʵ���ָ�
ʵ���ָ�
�����������ʾ��������ģ��
import paddlex as pdx
test_jpg = 'mask_r50_fpn_coco/test.jpg'
model = pdx.load_model('mask_r50_fpn_coco')
# predict�ӿڲ�δ���˵����Ŷ�ʶ����,�û���������scoreֵ���й���
result = model.predict(test_jpg)
# ���ӻ�����洢��./visualized_test.jpg, ����ͼ
pdx.det.visualize(test_jpg, result, threshold=0.5, save_dir='./')

����ָ�
����ָ�
�����������ʾ��������ģ��
import paddlex as pdx
test_jpg = './deeplabv3p_mobilenetv2_voc/test.jpg'
model = pdx.load_model('./deeplabv3p_mobilenetv2_voc')
result = model.predict(test_jpg)
# ���ӻ�����洢��./visualized_test.jpg,����ͼ��(��ͼΪԭͼ)
pdx.seg.visualize(test_jpg, result, weight=0.0, save_dir='./')
������ʾ��������,ͨ������paddlex.seg.visualize���Զ�����ָ��Ԥ�������п��ӻ�,���ӻ��Ľ��������save_dir��,����ͼ������weight�������ڵ���Ԥ������ԭͼ����ں�չ��ʱ��Ȩ��,0.0ʱֻչʾԤ����mask�Ŀ��ӻ�,1.0ʱֻչʾԭͼ���ӻ���
ѵ����������
PaddleX����ѵ���ӿ���,���õIJ�����Ϊ���ݵ�GPU����Ӧbatch_size�µĽ��Ų���,�û����Լ���������ѵ��ģ��,�漰����������ʱ,����̫��������ž���,��ɲο����·�ʽ
1.num_epochs�ĵ���
num_epochs��ģ��ѵ��������������(ģ�Ͷ�ѵ����ȫ��������һ�鼴Ϊһ��epoch),�û��������ýϴ����ֵ,����ģ�͵�����������֤���ϵ�ָ�����,���ж�ģ���Ƿ�����,������ǰ��ֹѵ��������Ҳ����ʹ��train�ӿ��е�early_stop����,ģ����ѵ�����̻��Զ��ж�ģ���Ƿ������Զ���ֹ��
2.batch_size��learning_rate
Batch Sizeָģ����ѵ��������,ǰ�����һ��(��Ϊһ��step)���õ�����������
����ʹ�öѵ��, batch_size����ֵ����ſ���(�����Ҫ��batch size��������)
Batch Size���������Դ�/�ڴ�߶����,batch_sizeԽ��,�����ĵ��Դ�/�ڴ��Խ��
PaddleX�ڸ���train�ӿ��о�������Ĭ�ϵ�batch size(Ĭ����Ե�GPU��),����ѵ��ʱ��ʾGPU�Դ治��,����Ӧ����BatchSize,����GPU�Դ��ʹ�ö���GPU��ʱ,����Ӧ����BatchSize��
�����û�����batch size,��Ҳע����Ҫ��Ӧ������������,�ر���train�ӿ���Ĭ�ϵ�learning_rateֵ������YOLOv3ģ����,Ĭ��train_batch_sizeΪ8,learning_rateΪ0.000125,���û���ģ����2��������ѵ��ʱ,���Խ�train_batch_size����Ϊ16, ��ôͬʱlearning_rateҲ���Զ�Ӧ����Ϊ0.000125 * 2 = 0.00025
3.warmup_steps��warmup_start_lr
��ѵ��ģ��ʱ,һ�㶼��ʹ��Ԥѵ��ģ��,������ģ����ѵ��ʱʹ��backbone��ImageNet���ݼ��ϵ�Ԥѵ��Ȩ�ء�������������ѵ��ʱ,�Լ���������ImageNet���ݼ����ڽϴ�IJ���,���ܻ�һ��ʼ�����ݶȹ���ʹ��ѵ����������,��������¿����ڸտ�ʼѵ��ʱ,��ѧϰ����һ����С��ֵ,�����������趨��ѧϰ�ʡ�warmup_steps��warmup_start_lr�������������,ģ�Ϳ�ʼѵ��ʱ,ѧϰ�ʻ��warmup_start_lr��ʼ,��warmup_steps��batch���ݵ����������������趨��ѧϰ�ʡ�
����YOLOv3��train�ӿ�,Ĭ��train_batch_sizeΪ8,learning_rateΪ0.000125, warmup_stepsΪ1000, warmup_start_lrΪ0.0;�ڴ˲��������±�ʾ,ģ��������ѵ����,��ǰ1000��step(ÿ��stepʹ��һ��batch������,��8������)��,ѧϰ�ʻ��0.0��ʼ�����������趨��0.000125��
4.lr_decay_epochs��lr_decay_gamma
lr_decay_epochs������ѧϰ����ģ��ѵ��������˥��,��һ����һ��list,��[6, 8, 10],��ʾѧϰ���ڵ�6��epochʱ˥��һ��,��8��epochʱ��˥��һ��,��10��epochʱ��˥��һ�Ρ�ÿ��ѧϰ��˥��Ϊ֮ǰ��ѧϰ��*lr_decay_gamma��
����YOLOv3��train�ӿ�,Ĭ��num_epochsΪ270,learning_rateΪ0.000125, lr_decay_epochsΪ[213, 240],lr_decay_gammaΪ0.1;�ڴ˲��������±�ʾ,ģ��������ѵ����,��ǰ213��epoch��,ѵ��ʱʹ�õ�ѧϰ��Ϊ0.000125,�ڵ�213��240��epoch֮��,ѵ��ʹ�õ�ѧϰ��Ϊ0.000125x0.1=0.0000125,��240��epoch֮��,ʹ�õ�ѧϰ��Ϊ0.000125x0.1x0.1=0.00000125
5.�����趨ʱ��Լ��
����������������,�����˽ѧϰ�ʵı仯��ΪWarmUp�����κ�Decay˥����,
Wamup������:����ѵ������,ѧϰ�ʴӽϵ͵�ֵ�������������趨��ֵ,��stepΪ��λ
Decay˥����:����ѵ������,ѧϰ����˥��,��ÿ��˥��Ϊ֮ǰ��0.1, ��epochΪ��λ
step��epoch�Ĺ�ϵ:1��epoch�ɶ��step���,����ѵ��������800��ͼ��,train_batch_sizeΪ8, ��ôÿ��epoch��Ҫ��������800��ͼƬѵһ��ģ��,��ÿ��epoch�ܹ�����800//8��100��step
��PaddleX��,Լ��warmup������Decay֮ǰ����,��˸�����������Ҫ������������
warmup_steps <= lr_decay_epochs[0] * num_steps_each_epoch
����num_steps_each_epoch���㷽ʽ����,
num_steps_each_eposh = num_samples_in_train_dataset // train_batch_size
���,������������ѵ��ʱ,����ʾwarmup_steps should be less than��ʱ,����ʾ��Ҫ����������ʽ������IJ�����,���Ե���lr_decay_epochs������warmup_steps��
6.���ʹ�ö�GPU������ѵ��
��import paddlexǰ���û�������,��������
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # ʹ��0��GPU������ѵ��
# ע��paddle��paddlex����Ҫ�����û�����������import
import paddlex as pdx
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '' # ��ʹ��GPU,ʹ��CPU����ѵ��
import paddlex as pdx
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,3' # ͬʱʹ�õ�0��1��3��GPU������ѵ��
import paddlex as pdx
ģ�ͱ���
ѵ�����̱���
PaddleX��ģ��ѵ��������,����train�����ӿ��е�save_interval_epoch��������,ÿ�����Ӧ��������һ��ģ��,ģ��Ŀ¼�а�����model.pdparams, model.yml���ļ���
��ѵ�������б����ģ��,��������Ϊpretrain_weights����ѵ��ģ��,Ҳ��ʹ��paddlex.load_model�ӿڼ��ز���ģ�͵�Ԥ��������ȡ�
����ģ�͵���
��ǰ���ᵽ��ѵ���б����ģ��,����Ҫ���ڲ���(����ɲ���PaddleX�ĵ��е�ģ�Ͷ�˲����½�),�赼��Ϊ�����ģ��ʽ,�����ģ��Ŀ¼�а���__model__,params__��model.yml�����ļ���
ģ�Ͳ�����Python����,����ʹ�û��ڸ�����Ԥ����python�ӿ�paddlex.deploy.Predictor,Ҳ��ʹ��paddlex.load_model�ӿڡ�
���ܽ����ģ��Ŀ¼�а���model.pdparams,��˵��ģ����ѵ�������б����,����ʱ��Ҫ���е���;�����ģ��Ŀ¼�������__model,__params__��model.yml�����ļ���
ģ�Ͳ����ļ�˵��
model:������ģ�͵�����ṹ��Ϣ
params: ������ģ�������еIJ���Ȩ��
model.yml:��PaddleX��,��ģ�͵�Ԥ����,����,�Լ���������Ϣ���洢�ڴ��ļ���
ģ�͵���ΪONNXģ��
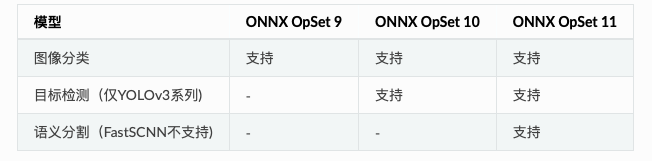
PaddleX��Ϊ���ſ�Դ����,���еĴ�ģ�;�֧�ֵ���ΪONNXЭ��,���㿪���߶����Ե�����
��Ҫע�����ONNX���ڶ��OpSet�汾,�±�ΪPaddleX��ģ��֧�ֵ�����ONNXЭ��汾��
ģ��ѹ���Ż�
ģ�Ͳü�
ģ�Ͳü����Ը��õ������ڶ˲ࡢ�ƶ����ϲ����µ���������,������Ч�ý���ģ�͵����,�Լ�������,����Ԥ�����ܡ�PaddleX������PaddleSlim�Ļ������жȵ�ͨ���ü��㷨,�û�������PaddleX��ѵ������������ʹ��������
�ڱ��ĵ���չʾ�˷���ģ�͵IJü�����,�ĵ��д����Լ���������ģ�͵ĵIJü��������Github�е�tutorials/slim/pruneĿ¼��ȡ��
ʹ�÷���
ģ�Ͳü���Ա�������ͨѵ��һ��ģ��,�����������
1.���������ķ�ʽѵ��һ��ģ��
2.��ģ�͵IJ����������жȷ���
3.���ݵ�2���õ������ж���Ϣ,��ģ�ͽ��вü�,���Ե�1��ѵ���õ�ģ����ΪԤѵ��Ȩ��,��������ѵ��
����������ͼ�����ģ��MobileNetV2Ϊ��,��ʾ�������д��������Github��[tutorials/slim/prune/image_classification]�л�á�
��һ�� ����ѵ��ģ��
�˲����в��������Ĵ������ģ��ѵ��,�ڻ�ȡ��ʾ�������,ֱ��ִ�����������
python mobilenetv2_train.py
��ѵ����ɺ�,������output/mobilenetv2/best_model�����ģ��,�����������IJ���
�ڶ��� �������жȷ���
�˲�����,������Ҫ���ص�һ��ѵ�������ģ��,��ͨ�����ϵر�������,�����������ü�������֤���ݼ��ϵľ�����ʧ,�Դ��жϸ����������жȡ����жȷ����Ĵ���ܼ�, �û���ֱ�Ӳ鿴params_analysis.py�����������ն�ִ���������ʼ����������
python params_analysis.py
�ڴ˲�����,���ǻ�õ������mobilenetv2.sensi.data�ļ�,����ļ�������ģ����ÿ�����������ж�,�ں����IJü�ѵ����,����ݴ��ļ��б������Ϣ,�Ը����������вü���ͬʱ,����Ҳ���Զ�����ļ����п��ӻ�����,�ж�eval_metric_loss�Ĵ�С������ģ�ͱ��ü������Ĺ�ϵ��(eval_metric_loss��˵����������)
ģ�Ͳü��������ӻ����������slim_visualize.py,ִ�����������
python slim_visualize.py
���ӻ��������,��ͼ����,�����ǽ�eval_metric_loss��Ϊ0.05ʱ,ģ�ͽ����ü���65%;��eval_metric_loss��Ϊ0.10,ģ�ͽ����ü���68.0%�������ʵ��ʹ��ʱ,���ǿ��Ը����Լ�������,ȥ����eval_metric_loss���Ʋü�������
������ ģ�Ͳü�ѵ��
��ǰ����,���ǵõ�������ѵ�������ģ��output/mobilenetv2/best_model�ͻ��ڸñ���ģ�͵õ��IJ������ж���Ϣ�ļ�mobilenetv2.sensi.data,���������ǽ���ģ�Ͳü�ѵ����ģ�Ͳü�ѵ���Ĵ���ڵ�һ������һ��,Ψһ����������train������,��������pretrain_weights,save_dir,sensitivities_file��eval_metric_loss�ĸ�����,������ʾ
model.train(
num_epoch=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4,6,8],
learning_rate=0.025,
pretrain_weights='output/mobilenetv2/best_model',
save_dir='output/mobilenetv2_prune',
sensitivities_file='./mobilenetv2.sensi.data',
eval_metric_loss=0.05,
use_vdl=True)
��������tutorials/slim/prune/image_classification/mobilenetv2_prune_train.py,ִ�����������
python mobilenetv2_prune_train.py
�����ĵ�4��������������
1��pretrain_weights: Ԥѵ��Ȩ��,�ڲü�ѵ����,����ָ��Ϊ��һ������ѵ���õ���ģ��·��
2��save_dir: �ü�ѵ��������,ģ�ͱ������·��
3��sensitivities_file: �ڶ����з����õ��ĸ��������ж���Ϣ�ļ�
4��
eval_metric_loss: �����ڿ���ģ�����ձ��ü��ı���,���ڶ����еĿ��ӻ�˵��
�ü�Ч��
�ڱ�ʾ�������ݼ���,�����ü�ѵ����,ģ�͵�Ч���Ա�����,����Ԥ���ٶȲ�����ͼ���Ԥ�����ͽ���ĺ������ӱ��п��Կ���,���ڱ�ʾ���еļ����ݼ�,ģ�Ͳü���68%��,ģ��ȷ��û�н���,��CPU�ĵ���ͼƬԤ����ʱ������37%
ģ������
ģ��������ģ�͵ļ���Ӹ�����תΪ����,�Ӷ�����ģ�͵�Ԥ������ٶ�,���ƶ���/��Ե���豸�Ͻ���ģ�͵������
ע:�������ģ��,ͨ��PaddleLiteת��ΪPaddleLite�����ģ��ʽ��,ģ�����������ѹ���������������ģ�������Է���˱��ز����ʽ(�ļ�����__model__��__params__),��ôģ�͵��ļ���С�������ֲ����仯����ġ�
ʹ�÷���
PaddleX���Ѿ�������������Ϊģ�͵�����һ��API,����ʹ�÷�ʽ����,��ʾ�������ģ�����ݾ���ͨ��GitHub��Ŀ�ϴ���tutorials/slim/quant/image_classification��ȡ�õ�
import paddlex as pdx
model = pdx.load_model('mobilenetv2_vegetables')
# �������ݼ���������
dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=model.test_transforms)
# ��ʼ����
pdx.slim.export_quant_model(model, dataset,
batch_size=4,
batch_num=5,
save_dir='./quant_mobilenet',
cache_dir='./tmp')
�ڻ�ȡ��ʾ�������,ִ��������������������PaddleLite��ģ�͵���
# ��mobilenetv2ģ����������
python mobilenetv2_quant.py
# ���������ģ�͵���ΪPaddleLite�����ʽ
python paddlelite_export.py
������
�ڱ�ʾ����,���ǿ��Կ���ģ��������ķ���˲���ģ��ʽserver_mobilenet��quant_mobilenet����Ŀ¼��,ģ�Ͳ�����С���ޱ仯�� ����ʹ��PaddleLite������,mobilenetv2.nb��mobilenetv2_quant.nb��С�ֱ�Ϊ8.8M, 2.7M,ѹ����ԭ����31%��
����ģ�͵���
�ڷ���˲���ģ��ʱ��Ҫ��ѵ�������б����ģ�͵���Ϊinference��ʽģ��,������inference��ʽģ�Ͱ���__model__��__params__��model.yml�����ļ�,�ֱ��ʾģ�͵�����ṹ��ģ��Ȩ�غ�ģ�͵������ļ�(��������Ԥ����������)��
������ģ���ļ���,���������model.pdparams, model.pdmodel��model.yml3���ļ�ʱ,��ô����Ҫ�����������̽���ģ�͵���
�ڰ�װ��PaddleX��,���������ն�ʹ���������ģ�͵�������ֱ������С���ּܷ�ģ�������Ա��ĵ�������xiaoduxiong_epoch_12.tar.gz��
paddlex --export_inference --model_dir=./xiaoduxiong_epoch_12 --save_dir=./inference_model

ʹ��TensorRTԤ��ʱ,��̶�ģ�͵������С,ͨ���Cfixed_input_shape���ƶ������С[w,h]��
ע��:
1������ģ�͵Ĺ̶������С�뱣����ѵ��ʱ�������Сһ��;
2�����ģ��ģ����YOLOϵ���뱣��w��hһ��,��Ϊ32�ı�����С;3��RCNN��������,�����趨����ָ��[w,h]ʱ,w��h�м䶺�Ÿ���,���������ڿո�������ַ���
4����Ҫע���,w,h���Խ��,ģ����Ԥ�����������Ҫ�ĺ�ʱ���ڴ�/�Դ�ռ��Խ��;���̫С,��Ӱ��ģ�;���
paddlex --export_inference --model_dir=./xiaoduxiong_epoch_12 --save_dir=./inference_model --fixed_input_shape=[640,960]
�ɽ�ʵ����ʾ
����ָ�ģ��
���̳̻���PaddleX���ķָ�ģ��ʵ������ָ�,����Ԥѵ��ģ�ͺͲ������ݡ�֧����Ƶ������ָ�ṩģ��Fine-tune��Paddle Lite�ƶ��˼�Nvidia JestonǶ��ʽ�豸�����ȫ����Ӧ��ָ�ϡ�
Ԥѵ��ģ�ͺͲ�������
Ԥѵ��ģ��
�����������������ڴ��ģ�������ݼ���ѵ���õ�ģ��,������������˳������ƶ��˳���������ʹ����Щģ�Ϳ��Կ���������Ƶ������ָ�,Ҳ���Բ����ƶ��˻�Ƕ��ʽ�豸����ʵʱ����ָ�,Ҳ�����������ģ��Fine-tuning��

1��Checkpoint ParameterΪģ��Ȩ��,����Fine-tuning����,����__params__ģ�Ͳ�����model.yaml������ģ��������Ϣ��
2��Inference Model��Quant Inference ModelΪԤ�ⲿ��ģ��,����__model__����ͼ�ṹ��__params__ģ�Ͳ�����model.yaml������ģ��������Ϣ��
����Inference Model�����ڷ���˵�CPU��GPUԤ�ⲿ��,Qunat 3��3��Inference ModelΪ�����汾,������ͨ��Paddle Lite�����ƶ��˵ȶ˲��豸����
����Ԥ��������
��ѵ����ģ�ͺ�,���ܻ�����Ԥ�����������ڡ���ݡ�������,������ܴ��ڵ�ԭ��������ģ����Ԥ�������,������ԭͼ�����ٷŴ�Ĺ���,����������ʾ,
ԭͼ���� -> Ԥ����transforms��ͼ��������Ŀ���С -> Paddleģ��Ԥ�� -> Ԥ�����Ŵ���ԭͼ��С
��������ԭ���µ�����,�����ֶ���ģ���е�model.yml�ļ�,��Ԥ�����е�Ŀ���С�����������Ż�������,���ڱ��ĵ����ṩ������ָ�server��ģ����model.yml�ļ�����,��target_size��1024*1024(����Ҳ�����ģ��Ԥ���������Դ����,Ԥ���ٶȸ���)
Model: DeepLabv3p
Transforms:
- Resize:
interp: LINEAR
target_size:
- 512
- 512
��Ϊ
Model: DeepLabv3p
Transforms:
- Resize:
interp: LINEAR
target_size:
- 1024
- 1024
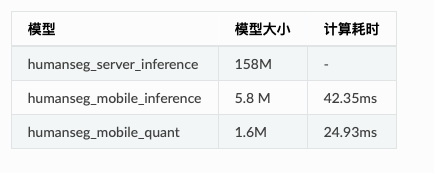
Ԥѵ��ģ�͵Ĵ洢��С������ʱ��������ʾ,�����ƶ���ģ�͵����л���Ϊcpu:����855,�ڴ�:6GB,ͼƬ��С:192*192
ִ�����½ű�����ȫ����Ԥѵ��ģ��:
~����PaddleXԴ��:
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
~����Ԥѵ��ģ�͵Ĵ���λ��PaddleX/examples/human_segmentation,�����Ŀ¼:
cd PaddleX/examples/human_segmentation
~ִ������
python pretrain_weights/download_pretrain_weights.py
��������
supervise.ly����������ָ����ݼ�Supervisely Persons, ���������������ȡһС�������ݲ�ת����PaddleX��ֱ�Ӽ��ص����ݸ�ʽ,�������´�������ظ����ݡ��Լ��ֻ�ǰ������ͷ��������������Ƶvideo_test.mp4.
���ز������ݵĴ���λ��PaddleX/xamples/human_segmentation,�����Ŀ¼��ִ������:
python data/download_data.py
����������Ƶ������ָ�
ǰ������
PaddlePaddle >= 1.8.0
Python >= 3.5
PaddleX >= 1.0.0
��װ���������ο�PaddleX��װ
����PaddleXԴ��:
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
��Ƶ������ָ�ͱ����滻��ִ���ļ���λ��PaddleX/examples/human_segmentation,�����Ŀ¼:
cd PaddleX/examples/human_segmentation
�������ٸ�������Ƶ������ָ�
��������DIS(Dense Inverse Search-basedmethod)���������㷨��Ԥ������PaddleX�ķָ��������ں�,�Դ˸�����Ƶ������ָ��Ч�����������´����������,���´���λ��PaddleX/xamples/human_segmentation:
ͨ����������ͷ����ʵʱ�ָ��
python video_infer.py --model_dir pretrain_weights/humanseg_mobile_inference
������������Ƶ���зָ��
python video_infer.py --model_dir pretrain_weights/humanseg_mobile_inference --video_path data/video_test.mp4
��Ƶ�ָ���������ʾ:

�����滻
��������ʵ���������滻����,������ѡ����������ı�����������滻,����������һ��ͼƬ,Ҳ������һ����Ƶ�������滻�Ĵ���λ��PaddleX/xamples/human_segmentation,�����Ŀ¼��ִ��:
ͨ����������ͷ����ʵʱ�����滻����, ͨ�����Cbackground_video_path�����뱳����Ƶ
python bg_replace.py --model_dir pretrain_weights/humanseg_mobile_inference --background_image_path data/background.jpg
��������Ƶ���б����滻����, ͨ�����Cbackground_video_path�����뱳����Ƶ
python bg_replace.py --model_dir pretrain_weights/humanseg_mobile_inference --video_path data/video_test.mp4 --background_image_path data/background.jpg
�Ե���ͼ����б����滻
python bg_replace.py --model_dir pretrain_weights/humanseg_mobile_inference --image_path data/human_image.jpg --background_image_path data/background.jpg
�����滻�������:

ע��:
��Ƶ�ָ��ʱ����Ҫ������,�����ĵȴ���
�ṩ��ģ���������ֻ�����ͷ�������㳡��,����Ч�����Բ�һЩ��
ģ��Fine-tune
ǰ������
PaddlePaddle >= 1.8.0
Python >= 3.5
PaddleX >= 1.0.0
��װ���������ο�PaddleX��װ
����PaddleXԴ��:
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
����ָ�ѵ����������Ԥ�⡢ģ�͵���������������ִ���ļ���λ��PaddleX/examples/human_segmentation,�����Ŀ¼:
cd PaddleX/examples/human_segmentation
ģ��ѵ��
ʹ������������л���Ԥѵ��ģ�͵�ģ��ѵ��,��ȷ��ѡ�õ�ģ�ͽṹmodel_type��ģ�Ͳ���pretrain_weightsƥ�䡣�������Ҫ�������ṩ�IJ�������,�ɸ������ݡ�ѡ����ʵ�ģ�Ͳ�����ѵ��������
# ָ��GPU����(��0�ſ�Ϊ��)
export CUDA_VISIBLE_DEVICES=0
# ����ʹ��GPU,��CUDA_VISIBLE_DEVICESָ��Ϊ��
# export CUDA_VISIBLE_DEVICES=
python train.py --model_type HumanSegMobile \
--save_dir output/ \
--data_dir data/mini_supervisely \
--train_list data/mini_supervisely/train.txt \
--val_list data/mini_supervisely/val.txt \
--pretrain_weights pretrain_weights/humanseg_mobile_params \
--batch_size 8 \
--learning_rate 0.001 \
--num_epochs 10 \
--image_shape 192 192
�������������:
�Cmodel_type: ģ������,��ѡ��Ϊ:HumanSegServer��HumanSegMobile
�Csave_dir: ģ�ͱ���·��
�Cdata_dir: ���ݼ�·��
�Ctrain_list: ѵ�����б�·��
�Cval_list: ��֤���б�·��
�Cpretrain_weights: Ԥѵ��ģ��·��
�Cbatch_size: ����С
�Clearning_rate: ��ʼѧϰ��
�Cnum_epochs: ѵ������
�Cimage_shape: ��������ͼ���С(w, h)
���������а�������������������в鿴:
python train.py --help
ע��:����ͨ�������Cmodel_type�������Ӧ�ĨCpretrain_weightsʹ�ò�ͬ��ģ�Ϳ��ٳ��ԡ�
����
ʹ�����������ģ������֤���ϵľ��Ƚ�������:
python eval.py --model_dir output/best_model \
--data_dir data/mini_supervisely \
--val_list data/mini_supervisely/val.txt \
--image_shape 192 192
�������������:
�Cmodel_dir: ģ��·��
�Cdata_dir: ���ݼ�·��
�Cval_list: ��֤���б�·��
�Cimage_shape: ��������ͼ���С(w, h)
Ԥ��
ʹ����������Բ��Լ�����Ԥ��,Ԥ����ӻ����Ĭ�ϱ�����./output/result/�ļ����С�
python infer.py --model_dir output/best_model \
--data_dir data/mini_supervisely \
--test_list data/mini_supervisely/test.txt \
--save_dir output/result \
--image_shape 192 192
�������������:
�Cmodel_dir: ģ��·��
�Cdata_dir: ���ݼ�·��
�Ctest_list: ���Լ��б�·��
�Cimage_shape: ��������ͼ���С(w, h)
ģ�͵���
�ڷ���˲����ģ����Ҫ���Ƚ�ģ�͵���Ϊinference��ʽģ��,������ģ�ͽ�����__model__��__params__��model.yml��������,�ֱ�Ϊģ�͵�����ṹ,ģ��Ȩ�غ�ģ�͵������ļ�(��������Ԥ���������ȵ�)���ڰ�װ��PaddleX��,���������ն�ʹ�������������ģ�͵���:
paddlex --export_inference --model_dir output/best_model \
--save_dir output/export
�������������:
�Cmodel_dir: ģ��·��
�Csave_dir: ����ģ�ͱ���·��
RGBң��Ӱ��ָ�
����������PaddleXʵ��ң��Ӱ��ָ�,�ṩ��������Ԥ�ⷽʽ,�Ա�����ֱ�ӶԴ�ߴ�ͼƬ����Ԥ��ʱ�Դ治��ķ���������,��������֮����ص��̶ȿ�����,�Դ���������Ԥ�����и�����ƴ�Ӵ����Ѻ۸С�
ǰ������
Paddle paddle >= 1.8.4
Python >= 3.5
PaddleX >= 1.1.4
��װ���������ο�PaddleX��װ
����PaddleXԴ��:
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
�ð������нű���λ��PaddleX/examples/remote_sensing/,�����Ŀ¼:
cd PaddleX/examples/remote_sensing/
������
������ʹ��2015 CCF�����ݱ����ṩ�ĸ���ң��Ӱ��,����5�Ŵ���ע��RGBͼ��,ͼ��ߴ������7969?��?7939����С��4011?��?2470�������ݼ�����ע��5������,�ֱ��DZ���(���Ϊ0)��ֲ��(���Ϊ1)����·(���Ϊ2)������(���Ϊ3)��ˮ��(���Ϊ4)��
��������ǰ4��ͼƬ������ѵ����,��5��ͼƬ��Ϊ��֤����Ϊ����ѵ��ʱ��������С,�Ի�������Ϊ(1024,1024)������Ϊ(512, 512)��ǰ4��ͼƬ�����з�,����ԭ����4�Ŵ�ߴ�ͼƬ,ѵ����һ����688��ͼƬ����ѵ��������ֱ�ӶԴ�ͼƬ������֤�ᵼ���Դ治��,Ϊ�����������ij���,�����֤���Ի�������Ϊ(769, 769)������Ϊ(769,769)�Ե�5��ͼƬ�����з�,�õ�40����ͼƬ��
�������½ű�,����ԭʼ���ݼ�,��������ݼ����з�:
python prepare_data.py
ģ��ѵ��
�ָ�ģ��ѡ��BackboneΪMobileNetv3_large_ssld��Deeplabv3ģ��,��ģ�ͼ汸�����ܸ߾��ȵ��ŵ㡣�������½ű�,����ģ��ѵ��:
python train.py
Ҳ��������ģ��ѵ������,ֱ������Ԥѵ��ģ�ͽ��к�����ģ��Ԥ�������:
wget https://bj.bcebos.com/paddlex/examples/remote_sensing/models/ccf_remote_model.tar.gz
tar -xvf ccf_remote_model.tar.gz
ģ��Ԥ��
ֱ�ӶԴ�ߴ�ͼƬ����Ԥ��ᵼ���Դ治��,Ϊ�����������ij���,�������ṩ�˻�������Ԥ��ӿ�,֧�����ص������ص����ַ�ʽ��
���ص��Ļ�������Ԥ��
������ͼƬ���Թ̶���С�Ĵ��ڻ���,�ֱ��ÿ�������µ�ͼ�����Ԥ��,������ڵ�Ԥ����ƴ�ӳ�����ͼƬ��Ԥ����������ÿ�����ڱ�Ե���ֵ�Ԥ��Ч������м䲿�ֵIJ�,���ÿ������ƴ�Ӵ����ܻ������Ե��Ѻ۸С�
��Ԥ�ⷽʽ��API�ӿ����overlap_tile_predict,ʹ��ʱ��Ҫ�Ѳ���pad_size����Ϊ[0, 0]��
���ص��Ļ�������Ԥ��
��Unet������,�������һ�����ص��Ļ�������Ԥ�����(Overlap-tile strategy)������ƴ�Ӵ����Ѻ۸С��Ը���������Ԥ��ʱ,����������չһ�������,����չ��Ĵ��ڽ���Ԥ��,������ͼ�е���ɫ��������,��ƴ��ʱֻȡ�������м䲿�ֵ�Ԥ����,������ͼ�еĻ�ɫ��������λ������ͼ���Ե���Ĵ���,����չ����µ�������ͨ������Ե�������ؾ�����õ���

������ص��Ļ�������Ԥ��,���ص��Ļ�������Ԥ����Խ���������ģ�;���miou��80.58%������81.52%,���ҽ�Ԥ����ӻ�������Ѻ۸���������,�ɼ���ͼ������Ԥ�ⷽʽ��Ч���Աȡ�

�������½ű�ʹ�����ص��Ļ������ڽ���Ԥ��:
python predict.py
ģ������
��ѵ��������,ÿ��10����������������һ��ģ������֤���ľ��ȡ����������Ƚ�ԭʼ��ߴ�ͼƬ�зֳ�С��,��ʱ�൱��ʹ�����ص��Ĵ�ͼ��СͼԤ�ⷽʽ,����ģ�;���miouΪ80.58%���������½ű�,���������ص��Ĵ�ͼ��Сͼ��Ԥ�ⷽʽ,��������ԭʼ��ߴ�ͼƬ��ģ�;���,��ʱmiouΪ81.52%��
python eval.py
��ͨ��ң��Ӱ��ָ�
ң��Ӱ��ָ���ͼ��ָ������е���ҪӦ�ó���,�㷺Ӧ�������ز�桢������⡢���н��������ң��Ӱ��ָ��Ŀ����ֶ���,�������ѩ��ũ�����·��������ˮԴ�ȵ���Ŀ��,Ҳ�������Ʋ�Ŀ���Ŀ�ꡣ
����������PaddleXʵ�ֶ�ͨ��ң��Ӱ��ָ�,�������ݷ�����ģ��ѵ����ģ��Ԥ�������,ּ�ڰ����û��������ѧϰ���������ͨ��ң��Ӱ��ָ����⡣
ǰ������
Paddle paddle >= 1.8.4
Python >= 3.5
PaddleX >= 1.1.4
��װ���������ο�PaddleX��װ
����谲װgdal, ʹ��pip��װgdal���ܳ���,�Ƽ�ʹ��conda���а�װ:
conda install gdal
����PaddleXԴ��:
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
�ð������нű���λ��PaddleX/examples/channel_remote_sensing/,�����Ŀ¼:
cd PaddleX/examples/channel_remote_sensing/
������
ң��Ӱ��ĸ�ʽ���ֶ���,��ͬ���������������ݸ�ʽҲ���ܲ�ͬ��PaddleX���Ѽ�������4�ָ�ʽͼƬ��ȡ:
tif
png
img
npy
��עͼҪ�����Ϊ��ͨ����png��ʽͼ��,����ֵ��Ϊ��Ӧ�����,���ر�ע�����Ҫ��0��ʼ����������0,1,2,3��ʾ��4�����,255����ָ��������ѵ��������������,��ע������Ϊ256�ࡣ
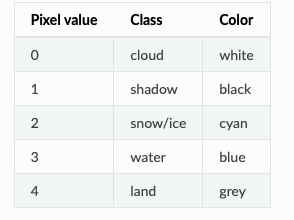
������ʹ��L8 SPARCS�������ݼ�������ѩ�ָ�,�����ݼ�����80������Ӱ��,����10�����Ρ�ԭʼ��עͼƬ����7�����,�ֱ���cloud, cloud shadow, shadow over water, snow/ice, water, land��flooded������flooded��shadow over water2�����ռ�Ƚ�Ϊ1.8%��0.24%,���ǽ�����кϲ�,flooded��Ϊland,shadow over water��Ϊshadow,�ϲ����ע����5�����
��ֵ�������ɫ��Ӧ��:


ִ�������������ز���ѹ�������ϲ�������ݼ�:
mkdir dataset && cd dataset
wget https://paddleseg.bj.bcebos.com/dataset/remote_sensing_seg.zip
unzip remote_sensing_seg.zip
cd ..
����dataĿ¼���ң��Ӱ��,data_visĿ¼��Ų�ɫ�ϳ�Ԥ��ͼ,maskĿ¼��ű�עͼ��
���ݷ���
ң��Ӱ�����������ನ�����,��ͬ�������ݷֲ����ܴ��ྶͥ,����ɼ��Ⲩ�κ��Ⱥ��Ⲩ�ηֲ�ʮ�ֲ�ͬ��Ϊ�˸������˽����ݵķֲ����Ż�ģ��ѵ��Ч��,��Ҫ�����ݽ��з�����
�ο��ĵ����ݷ�����ѵ��������ͳ�Ʒ���,ȷ��ͼ������ֵ�ĽضϷ�Χ,��ͳ�ƽضϺ�ľ�ֵ�ͷ��
ģ��ѵ��
������ѡ��UNet����ָ�ģ�������ѩ�ָ�,�������²������ģ��ѵ��,ģ�͵����ž���miouΪ78.38%��
����GPU����
export CUDA_VISIBLE_DEVICES=0
�������½ű���ʼѵ��
python train.py --data_dir dataset/remote_sensing_seg \
--train_file_list dataset/remote_sensing_seg/train.txt \
--eval_file_list dataset/remote_sensing_seg/val.txt \
--label_list dataset/remote_sensing_seg/labels.txt \
--save_dir saved_model/remote_sensing_unet \
--num_classes 5 \
--channel 10 \
--lr 0.01 \
--clip_min_value 7172 6561 5777 5103 4291 4000 4000 4232 6934 7199 \
--clip_max_value 50000 50000 50000 50000 50000 40000 30000 18000 40000 36000 \
--mean 0.15163569 0.15142828 0.15574491 0.1716084 0.2799778 0.27652043 0.28195933 0.07853807 0.56333154 0.5477584 \
--std 0.09301891 0.09818967 0.09831126 0.1057784 0.10842132 0.11062996 0.12791838 0.02637859 0.0675052 0.06168227 \
--num_epochs 500 \
--train_batch_size 3
Ҳ��������ģ��ѵ������,����Ԥѵ��ģ��ֱ�ӽ���ģ��Ԥ��:
wget https://bj.bcebos.com/paddlex/examples/multi-channel_remote_sensing/models/l8sparcs_remote_model.tar.gz
tar -xvf l8sparcs_remote_model.tar.gz
ģ��Ԥ��
�������½ű�,��ң��ͼ�����Ԥ�Ⲣ���ӻ�Ԥ����,��Ӧ��Ҳ����Ӧ�ı�ע�ļ����п��ӻ�,�ԱȽ�Ԥ��Ч����
export CUDA_VISIBLE_DEVICES=0
python predict.py
���ӻ�Ч��������ʾ:

��ֵ�������ɫ��Ӧ��:
�ؿ�仯���
����������PaddleXʵ�ֵؿ�仯���,��ͬһ�ؿ��ǰ�����������ͼƬ����ƴ��,�������������ָ�������б仯�����Ԥ�⡣��ѵ����,ʹ��������ųߴ硢��ת���ü�����ɫ�ռ��Ŷ���ˮƽ��ת����ֱ��ת����������ǿ���ԡ�����֤��Ԥ���,ʹ�û�������Ԥ�ⷽʽ,�Ա�����ֱ�ӶԴ�ߴ�ͼƬ����Ԥ��ʱ�Դ治��ķ�����
ǰ������
Paddle paddle >= 1.8.4
Python >= 3.5
PaddleX >= 1.2.2
��װ���������ο�PaddleX��װ
����PaddleXԴ��:
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
�ð������нű���λ��PaddleX/examples/change_detection/,�����Ŀ¼:
cd PaddleX/examples/change_detection/
������
������ʹ��Daifeng Peng���˿��ŵ�Google Dataset, �����ݼ������˹��ݲ���������2006����2019���ڼ�ķ��ݽ�����ı仯���,���ڷ������л����̡�һ����20�Ը���ͼƬ,ͼƬ�к졢�̡�����������,�ռ�ֱ���Ϊ0.55m,ͼƬ��С��1006x1168��4936x5224���ȡ�
����Google Dataset����ע�˷��ݽ������Ƿ����仯,��˱������Ƕ�����仯�������,�ɸ���ʵ���������������������չΪ�����仯��⡣
��������15��ͼƬ������ѵ����,5��ͼƬ��������֤��������ͼƬ�ߴ����,ֱ��ѵ���ᷢ���Դ治�������,����Ի�������Ϊ(1024,1024)������Ϊ(512, 512)��ѵ��ͼƬ�����з�,�зֺ��ѵ����һ����743��ͼƬ���Ի�������Ϊ(769, 769)������Ϊ(769,769)����֤ͼƬ�����з�,�õ�108����ͼƬ,����ѵ�������е���֤��
�������½ű�,����ԭʼ���ݼ�,��������ݼ����з�:
python prepare_data.py
�зֺ������ʾ������:

ע��:
tiff��ʽ��ͼƬPaddleXͳһʹ��gdal���ȡ,gdal��װ�ɲο�gdal�ĵ�����������tiff��ʽ����ͨ��RGBͼ��,������밲װgdal,������ת��jpeg��bmp��png��ʽͼƬ��
label�ļ���Ϊ��ͨ����png��ʽͼƬ,�ұ�ע��0��ʼ����,��ע255��ʾ���������㡣���籾������,0��ʾunchanged��,1��ʾchanged�ࡣ
ģ��ѵ��
������������С,�ָ�ģ��ѡ��Ϻü��dz��ϸ����Ϣ�����������Ϣ��UNetģ�͡��������½ű�,����ģ��ѵ��:
python train.py
������ʹ��0,1,2,3��GPU�����ѵ��,�ɸ���ʵ���Դ��С����ѵ���ű��е�GPU��������train_batch_size������ֵ,��train_batch_size�ĵ���������Ӧ�ص���ѧϰ��learning_rate,����train_batch_size��16������8ʱ,learning_rate����0.1������0.05������,��ͬ���ݼ����ܻ�����ž�������Ӧlearning_rate����������ͬ,���Գ��Ե�����
Ҳ��������ģ��ѵ������,ֱ������Ԥѵ��ģ�ͽ��к�����ģ��������Ԥ��:
wget https://bj.bcebos.com/paddlex/examples/change_detection/models/google_change_det_model.tar.gz
tar -xvf google_change_det_model.tar.gz
ģ������
��ѵ��������,ÿ��10����������������һ��ģ������֤���ľ��ȡ����������Ƚ�ԭʼ��ߴ�ͼƬ�зֳ�С��,�൱��ʹ�����ص��Ļ�������Ԥ�ⷽʽ,����ģ�;���:

category�ֱ��Ӧunchanged��changed���ࡣ
�������½ű�,���������ص��Ļ�������Ԥ�ⷽʽ,��������ԭʼ��ߴ�ͼƬ��ģ�;���,��ʱģ�;���Ϊ:

python eval.py
��������Ԥ��ӿ�˵�����API˵��,���е�ʹ�ó����ɲο�RGBң�зָ�����ɸ���ʵ���Դ��С�������ű���tile_size,pad_size��batch_size��
ģ��Ԥ��
ִ�����½ű�,ʹ�����ص��Ļ���Ԥ�ⴰ�ڶ���֤������Ԥ�⡣�ɸ���ʵ���Դ��С�������ű���tile_size,pad_size��batch_size��
python predict.py
Ԥ����ӻ��������ͼ��ʾ:

OpenVINOģ��ת��
��Paddleģ��ת��ΪOpenVINO��Inference Engine
1����������
Paddle2ONNX 0.4
ONNX 1.6.0+
PaddleX 1.3+
OpenVINO 2020.4+
˵��:PaddleX��װ��ο�PaddleX , OpenVINO��װ��ο�OpenVINO,ONNX�밲װ1.6.0���ϰ汾��������תģ�ʹ���, Paddle2ONNX�밲װ0.4�汾��
ע��:��װOpenVINOʱ����ذ�װ�����̳̳�ʼ��OpenVINO���л���,����װ�������,�������֡�No module named mo��������
��ȷ��ϵͳ�Ѿ���װ��������������,��������ʾ���Թ���Ŀ¼ /root/projects/��ʾ��
2������inferenceģ��
paddleģ��תopenvino֮ǰ��Ҫ�Ȱ�paddleģ�͵���Ϊinference��ʽģ��,������ģ�ͽ�����__model__��__params__��model.yml�����ļ���,������������
paddlex --export_inference --model_dir=/path/to/paddle_model --save_dir=./inference_model --fixed_input_shape=[w,h]
ע��:��ҪתOpenVINOģ��ʱ,����inferenceģ�������ָ���Cfixed_input_shape�������̶�ģ�͵������С,��ģ�͵������С��Ҫ��ѵ��ʱһ�¡� PaddleX�ͻ����ڷ���ģ��ʱû�й̶������С,��˶��ڿ��ӻ��ͻ���,���ҵ���������Ŀ¼,�������output�ļ����ҵ�best_modelģ��Ŀ¼,����Ŀ¼ʹ������������й̶�shape�������ɡ�
3������OpenVINOģ��
mkdir -p /root/projects
cd /root/projects
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
cd deploy/openvino/python
python converter.py --model_dir /path/to/inference_model --save_dir /path/to/openvino_model --fixed_input_shape [w,h]
ת���ɹ������save_dir�³��ֺ���Ϊ.xml��.bin��.mapping�����ļ�ת������˵������:

paddle- openVINO����ʵ��
openvino-yolo
������ʾ������
�����ʾ�������OpenVINO������PaddlePaddle YoloV3����㷨��
��������������Щ��һ�������������,���Կ��������������ӡ�
YOLOV3Model Configuration(ģ������):
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.1/configs/yolov3
PPYOLO Annotation Data(����):
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.2/docs/tutorials/config_annotation/ppyolo_r50vd_dcn_1x_coco_annotation.md
PPYOLO Model Configuration:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.1/configs/ppyolo
import os, sys, os.path
import numpy as np
import cv2
from openvino.inference_engine import IENetwork, IECore, ExecutableNetwork
from IPython import display
from PIL import Image, ImageDraw
import urllib, shutil, json
import yaml
from yaml.loader import SafeLoader
���غ͵����ٶ��ͺ�- YOLOV3��PPYOLO
�����ҪһЩʱ��,Ҫȷ�����չ�����read me�еİ�װ˵����PaddleDetection GitHub��װ��openvino-paddlepaddle-demoĿ¼�С�
�����ǹ���������
Reference on Baidu Model Exporting: https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.1/deploy/EXPORT_MODEL.md
#Get the YOLOV3
PADDLE_DET_PATH="../../PaddleDetection"
YML_CONFIG="configs/yolov3/yolov3_darknet53_270e_coco.yml"
PRETRAINED="yolov3_darknet53_270e_coco.pdparams"
OUTPUT_DIR="models"
if(not os.path.isfile("models/yolov3_darknet53_270e_coco/model.pdmodel")):
print("Download and Export Model... This may take a while...")
! python $PADDLE_DET_PATH/tools/export_model.py -c $PADDLE_DET_PATH/$YML_CONFIG -o use_gpu=false weights=https://paddledet.bj.bcebos.com/models/$PRETRAINED "TestReader.inputs_def.image_shape=[3,608,608]" --output_dir=$OUTPUT_DIR
else:
print("Model is already downloaded")
�����ʾģ���Ѿ�������
Model is already downloaded
#Get the PPYOLO (experimental)
PADDLE_DET_PATH="../../PaddleDetection"
YML_CONFIG="configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml"
PRETRAINED="ppyolo_r50vd_dcn_1x_coco.pdparams"
OUTPUT_DIR="models"
if(not os.path.isfile("models/ppyolo_r50vd_dcn_1x_coco/model.pdmodel")):
print("Download and Export Model... This may take a while...")
! python $PADDLE_DET_PATH/tools/export_model.py -c $PADDLE_DET_PATH/$YML_CONFIG -o use_gpu=false weights=https://paddledet.bj.bcebos.com/models/$PRETRAINED "TestReader.inputs_def.image_shape=[3,608,608]" --output_dir=$OUTPUT_DIR
else:
print("Model is already downloaded")
Model is already downloaded
#Helper functions
def image_preprocess(input_image, size):
img = cv2.resize(input_image, (size,size))
img = np.transpose(img, [2,0,1]) / 255
img = np.expand_dims(img, 0)
##NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
img_mean = np.array([0.485, 0.456,0.406]).reshape((3,1,1))
img_std = np.array([0.229, 0.224, 0.225]).reshape((3,1,1))
img -= img_mean
img /= img_std
return img.astype(np.float32)
def draw_box(img, results, label_text, scale_x, scale_y):
for i in range(len(results)):
#print(results[i])
bbox = results[i, 2:]
label_id = int(results[i, 0])
score = results[i, 1]
if(score>0.20):
xmin, ymin, xmax, ymax = [int(bbox[0]*scale_x), int(bbox[1]*scale_y),
int(bbox[2]*scale_x), int(bbox[3]*scale_y)]
cv2.rectangle(img,(xmin, ymin),(xmax, ymax),(0,255,0),3)
font = cv2.FONT_HERSHEY_SIMPLEX
label_text = label_list[label_id];
cv2.rectangle(img, (xmin, ymin), (xmax, ymin-70), (0,255,0), -1)
cv2.putText(img, "#"+label_text,(xmin,ymin-10), font, 1.2,(255,255,255), 2,cv2.LINE_AA)
cv2.putText(img, str(score),(xmin,ymin-40), font, 0.8,(255,255,255), 2,cv2.LINE_AA)
return img
����ģ��
������������ͬ��ģ��֮���л�-Ĭ����PPYolo���Ա�����ģ�͵�����
#PPYolo3
#pdmodel_path = "models/yolov3_darknet53_270e_coco"
#PPYolo (experimental)
pdmodel_path = "models/ppyolo_r50vd_dcn_1x_coco"
pdmodel_file = pdmodel_path + "/model.pdmodel"
pdmodel_config = pdmodel_path + "/infer_cfg.yml"
device = 'CPU'
#load the data from config, and setup the parameters
label_list=[]
with open(pdmodel_config) as f:
data = yaml.load(f, Loader=SafeLoader)
label_list = data['label_list'];
��PaddlePaddleԤѵ��ģ�ͼ��ص�OpenVINO��������(IE)��
ie = IECore()
net = ie.read_network(pdmodel_file)
net.reshape({'image': [1, 3, 608, 608], 'im_shape': [
1, 2], 'scale_factor': [1, 2]})
exec_net = ie.load_network(net, device)
assert isinstance(exec_net, ExecutableNetwork)
����ͼ��������������
input_image = cv2.imread("horse.jpg")
test_image = image_preprocess(input_image, 608)
test_im_shape = np.array([[608, 608]]).astype('float32')
test_scale_factor = np.array([[1, 2]]).astype('float32')
#print(test_image.shape)
inputs_dict = {'image': test_image, "im_shape": test_im_shape,
"scale_factor": test_scale_factor}
output = exec_net.infer(inputs_dict)
result_ie = list(output.values())
result_image = cv2.imread("horse.jpg")
scale_x = result_image.shape[1]/608*2
scale_y = result_image.shape[0]/608
result_image = draw_box(result_image, result_ie[0], label_list, scale_x, scale_y)
_,ret_array = cv2.imencode('.jpg', result_image)
i = display.Image(data=ret_array)
display.display(i)
cv2.imwrite("yolo-output.png",result_image)

ʵʱ����ͷ��ʾ
�����ʾ����ʾ��������ͷ������YoloV3�����ģ��ȷʵ������,��˿����ṩ���õ�mAP��Ҳ����������ģ��,��mobilenet,�������Ȩ�����ܺ�ȷ�ԡ�
Source: https://github.com/PaddlePaddle/PaddleDetection
def YoloVideo(VideoIndex=0, scale=0.5):
#PPYolo3
pdmodel_path = "models/yolov3_darknet53_270e_coco"
pdmodel_file = pdmodel_path + "/model.pdmodel"
pdmodel_config = pdmodel_path + "/infer_cfg.yml"
device = 'CPU'
#load the data from config, and setup the parameters
label_list=[]
with open(pdmodel_config) as f:
data = yaml.load(f, Loader=SafeLoader)
label_list = data['label_list'];
ie = IECore()
net = ie.read_network(pdmodel_file)
net.reshape({'image': [1, 3, 608, 608], 'im_shape': [
1, 2], 'scale_factor': [1, 2]})
exec_net = ie.load_network(net, device)
assert isinstance(exec_net, ExecutableNetwork)
try:
cap = cv2.VideoCapture(VideoIndex)
except:
print("Cannot Open Device")
del exec_net
try:
ret, frame = cap.read()
while(ret==True):
# Capture frame-by-frame
ret, frame = cap.read()
if not ret:
# Release the Video Device if ret is false
cap.release()
# Message to be displayed after releasing the device
print ("Released Video Resource")
break
#frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
half_frame = cv2.resize(frame, (0, 0), fx = scale, fy = scale)
#Processing the Frame
test_image = image_preprocess(half_frame, 608)
test_im_shape = np.array([[608, 608]]).astype('float32')
test_scale_factor = np.array([[1, 2]]).astype('float32')
#print(test_image.shape)
inputs_dict = {'image': test_image, "im_shape": test_im_shape,
"scale_factor": test_scale_factor}
output = exec_net.infer(inputs_dict)
result_ie = list(output.values())
result_image = half_frame.copy()
#result_image = cv2.resize(result_image, (int(608*1.0),int(608*1.0)))
scale_x = result_image.shape[1]/608*2
scale_y = result_image.shape[0]/608
result_image = draw_box(result_image, result_ie[0], label_list, scale_x, scale_y)
#convert to jpg for performance results
_,ret_array = cv2.imencode('.jpg', result_image)
i = display.Image(data=ret_array)
display.display(i)
display.clear_output(wait=True)
except KeyboardInterrupt:
# Release the Video Device
cap.release()
# Message to be displayed after releasing the device
print("Released Video Resource from KeyboardInterrupt")
del exec_net
pass
����Webcam Feed
�밴��ֹͣ��ť,����ȷ��ֹ��
YoloVideo(1, 0.75)
Released Video Resource from KeyboardInterrupt
openvino-PaddleOCR
��дʶ���ʫ
�����ʾ���Բ�ʿ��(OpenVINO Edge AI����������- Intel)
��һ����Դ��Ŀ,��ʾ�������OpenVINO������PaddleOCR (Lite)ģ�͡��������ڿ���ֱ�Ӵ�mobilenetv3ģ�Ͷ�ȡ������Ҫ�κ�ת��,�����ǽ�mobilenetv3ģ�͵�����ONNX,Ȼ��ͨ��OpenVINO�Ż��������м��ʾ(IR)��ʽ��
�����ʲô�����ĵط�,���Բο�����
ͨ��OpenVINO����Paddle Detection
import os, os.path
import sys
import json
import urllib.request
import cv2
import numpy as np
import paddle
import math
import time
from openvino.inference_engine import IENetwork, IECore, ExecutableNetwork
from IPython import display
from PIL import Image, ImageDraw
import copy
import logging
import imghdr
from shapely.geometry import Polygon
import pyclipper
from pre_post_processing import *
����ͼƬ
def image_preprocess(input_image, size):
img = cv2.resize(input_image, (size,size))
img = np.transpose(img, [2,0,1]) / 255
img = np.expand_dims(img, 0)
##NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
img_mean = np.array([0.485, 0.456,0.406]).reshape((3,1,1))
img_std = np.array([0.229, 0.224, 0.225]).reshape((3,1,1))
img -= img_mean
img /= img_std
return img.astype(np.float32)
# Test images provided include 1 handwritten Chinese image and 1 printed Chinese image
image_file = "handwritten_simplified_chinese_test.jpg"
ii = cv2.imread(image_file)
test_image = image_preprocess(ii,640)
Load the Network
model_dir = "./inference/ch_ppocr_mobile_v2.0_det_infer"
model_file_path = model_dir + "/inference.pdmodel"
params_file_path = model_dir + "/inference.pdiparams"
# initialize inference engine
ie = IECore()
# initialize inference engine
net = ie.read_network(model_file_path)
# pdmodel might be dynamic shape, this will reshape based on the input
input_key = list(net.input_info.items())[0][0] # 'inputs'
net.reshape({input_key: test_image.shape})
exec_net = ie.load_network(net, 'CPU')
assert isinstance(exec_net, ExecutableNetwork)
#perform the inference step
det_start_time = time.time()
output = exec_net.infer({input_key: test_image})
det_stop_time = time.time()
result_ie = list(output.values())
det_infer_time = det_stop_time - det_start_time
��PaddleDetection��������������
ori_im = ii.copy()
data = {'image': ii}
data_resize = DetResizeForTest(data)
data_norm = NormalizeImage(data_resize)
data_list = []
keep_keys = ['image', 'shape']
for key in keep_keys:
data_list.append(data[key])
img, shape_list = data_list
shape_list = np.expand_dims(shape_list, axis=0)
pred = result_ie[0]
if isinstance(pred, paddle.Tensor):
pred = pred.numpy()
pred = pred[:, 0, :, :]
segmentation = pred > 0.3
boxes_batch = []
for batch_index in range(pred.shape[0]):
src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
mask = segmentation[batch_index]
boxes, scores = boxes_from_bitmap(pred[batch_index], mask,src_w, src_h)
boxes_batch.append({'points': boxes})
post_result = boxes_batch
dt_boxes = post_result[0]['points']
dt_boxes = filter_tag_det_res(dt_boxes, ii.shape)
��openvino �����зɽ�ʶ��
# Processing detection results for Recognition
dt_boxes = sorted_boxes(dt_boxes)
img_crop_list = []
for bno in range(len(dt_boxes)):
tmp_box = copy.deepcopy(dt_boxes[bno])
img_crop = get_rotate_crop_image(ori_im, tmp_box)
img_crop_list.append(img_crop)
Ԥ��������Paddleʶ���ͼ��
def resize_norm_img(img, max_wh_ratio):
rec_image_shape = [3, 32, 320]
imgC, imgH, imgW = rec_image_shape
assert imgC == img.shape[2]
character_type = "ch"
if character_type == "ch":
imgW = int((32 * max_wh_ratio))
h, w = img.shape[:2]
ratio = w / float(h)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
else:
resized_w = int(math.ceil(imgH * ratio))
resized_image = cv2.resize(img, (resized_w, imgH))
resized_image = resized_image.astype('float32')
resized_image = resized_image.transpose((2, 0, 1)) / 255
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
Load the Network
model_dir = "./inference/ch_ppocr_mobile_v2.0_rec_infer"
model_file_path = model_dir + "/inference.pdmodel"
params_file_path = model_dir + "/inference.pdiparams"
ie = IECore()
net = ie.read_network(model_file_path)
��ʼʶ���ʫ��
img_num = len(img_crop_list)
# Calculate the aspect ratio of all text bars
width_list = []
for img in img_crop_list:
width_list.append(img.shape[1] / float(img.shape[0]))
# Sorting can speed up the recognition process
indices = np.argsort(np.array(width_list))
rec_res = [['', 0.0]] * img_num
rec_batch_num = 6
batch_num = rec_batch_num
rec_processing_times = 0
for beg_img_no in range(0, img_num, batch_num):
end_img_no = min(img_num, beg_img_no + batch_num)
norm_img_batch = []
max_wh_ratio = 0
for ino in range(beg_img_no, end_img_no):
h, w = img_crop_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
for ino in range(beg_img_no, end_img_no):
norm_img = resize_norm_img(img_crop_list[indices[ino]],max_wh_ratio)
norm_img = norm_img[np.newaxis, :]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
# pdmodel might be dynamic shape, this will reshape based on the input
input_key = list(net.input_info.items())[0][0] # 'inputs'
net.reshape({input_key: norm_img_batch.shape})
#load the network on CPU
start_time = time.time()
exec_net = ie.load_network(net, 'CPU')
stop_time = time.time()
assert isinstance(exec_net, ExecutableNetwork)
rec_processing_times += stop_time - start_time
for index in range(len(norm_img_batch)):
output = exec_net.infer({input_key: norm_img_batch})
result_ie = list(output.values())
preds = result_ie[0]
postprocess_op = build_post_process(postprocess_params)
rec_result = postprocess_op(preds)
for rno in range(len(rec_result)):
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
final_stop_time = time.time()
processing_time = final_stop_time - det_start_time
print("The total prediction and processing time is ", processing_time)
The total prediction and processing time is 0.3596353530883789
print("The total inference time for detection is ", det_infer_time)
print("The total inference time for recognition is ", rec_processing_times)
The total inference time for detection is 0.030055999755859375
The total inference time for recognition is 0.127180814743042
���ӻ�����ʶ����
src_im = draw_text_det_res(dt_boxes, image_file)
img_name_pure = os.path.split(image_file)[-1]
img_path = "det_res_{}".format(img_name_pure)
cv2.imwrite(img_path, src_im)
#Visualization Paddle Detection results
_,ret_array = cv2.imencode('.jpg', src_im)
i = display.Image(data=ret_array)
display.display(i)

#Visualization Paddle Recognition results, format
print(rec_res)
[(����®���˾�Ʒ��������, 0.7947357), (���ʾ����ܶ���Զ����ƫ��ǰ��, 0.78279454), (����������Ȼ����ɽɽ����Ϧ��, 0.8802729), (���ѷ������뻹��������������, 0.8675663), (���������ԡ�, 0.38597608)]