目录
第4章 神经网络的学习
本章的主题是神经网络的学习,这里所说的“学习”是指从训练数据中自动获取最优权重参数的过程。本章中,为了使神经网络能进行学习,将导入损失函数这一指标,而学习的目的就是以该损失函数为基准,找出能使它的值达到最小的权重参数。为了找出尽可能小的损失函数的值,本章我们将介绍利用了函数斜率的梯度法。
4.1 从数据中学习
神经网络的特征就是可以从数据中学习。所谓“从数据中学习”,是指可以由数据自动决定权重参数的值。对于线性可分问题,感知机是可以利用数据自动学习的。根据“感知机收敛定理”,通过有限次数的学习,线性可分问题是可解的。但是,非线性可分问题则无法通过(自动)学习来解决。
4.1.1 数据驱动
如何实现数字“5”的识别?一种方案是,先从图像中提取特征量,再用机器学习技术学习这些特征量的模式。这里所说的“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。图像的特征量通常表示为向量的形式。在计算机视觉领域,常用的特征量包括SIFT、SURF和HOG等,使用这些特征量将图像数据转换为向量,然后对转换后的向量使用机器学习中的SVM、KNN等分类器进行学习。
机器学习的方法中,由机器从收集到的数据中找到规律性。与从零开始想出算法相比,这种方法可以更高效地解决问题,也能减轻人的负担。但是需要注意的是,将图像转换为向量时使用的特征量仍是由人设计的,对于不同的问题,必须使用合适的特征量(必须设计专门的特征量),才能得到好的结果。也就是说,即使使用特征量和机器学习的方法,也需要针对不同的问题人工考虑合适的特征量。
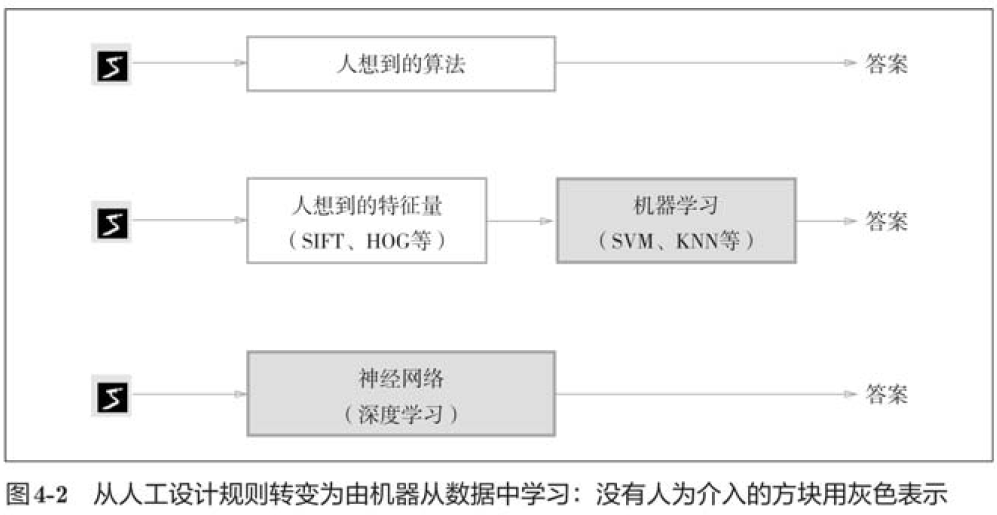
深度学习有时称为端到端机器学习。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思。
神经网络的优点是对所有的问题都可以用同样的流程来解决。比如,不管要求解的问题是识别5,还是识别狗,抑或是识别人脸,神经网络都是通过不断地学习所提供的数据,尝试发现待求解的问题的模式。也就是说,与待处理的问题无关,神经网络可以将数据直接作为原始数据,进行“端对端”的学习。
4.1.2 训练数据和测试数据?
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。为什么需要将数据分为训练数据和测试数据呢?因为我们追求的是模型的泛化能力。为了正确评价模型的泛化能力,就必须划分训练数据和测试数据。另外,训练数据也可以称为监督数据。
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力,获得泛化能力是机器学习的最终目标。因此,仅仅用一个数据集去学习和评价参数,是无法进行正确评价的,这样会导致可以顺利地处理某个数据集,但无法处理其他数据集的情况。只对某个数据集过度拟合的状态称为过拟合,避免过拟合也是机器学习的一个重要课题。
4.2 损失函数
神经网络的学习通过某个指标表示现在的状态,然后,以这个指标为基准,寻找最优权重参数。神经网的学习中所用的指标称为损失函数,这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
4.2.1 均方误差
可以用作损失函数的函数有很多,其中最有名的是均方误差。均方误差如下式所示:
![]()
?这里![]() 表示神经网络的输出,
表示神经网络的输出,![]() 表示监督数据,k表示数据的维数。将正确标签表示为1,其他标签表示为0的表示方法称为one-hot表示。
表示监督数据,k表示数据的维数。将正确标签表示为1,其他标签表示为0的表示方法称为one-hot表示。
如上式所示,均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。
import numpy as np
def mean_squard_error(y, t):
return 0.5 * np.sum((y-t)**2)
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(mean_squard_error(np.array(y), np.array(t)))
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(mean_squard_error(np.array(y), np.array(t)))
0.09750000000000003
0.5975?这里举了两个例子。第一个例子中,正确解是“2”, 神经网络的输出的最大值是“2”;第二个例子中,正确解是“2”, 神经网络的输出的最大值是“7”。如实验结果所示,我们发现第一个例子的损失函数的值更小,和监督数据之间的误差较小,也就是说,均方误差显示第一个例子的输出结果与监督数据更加吻合。
4.2.2 交叉熵误差
除了均方误差之外,交叉熵误差 也经常被用作损失函数。交叉熵误差如下式所示:
![]()
这里,![]() 表示以e为底数的自然对数
表示以e为底数的自然对数![]() 。
。![]() 是神经网络的输出,
是神经网络的输出,![]() 是正确解标签。并且,
是正确解标签。并且,![]() 中只有正确解标签的索引为1,其他均为0(one-hot表示)。交叉熵误差的值是由正确解标签所对应的输出结果决定的。
中只有正确解标签的索引为1,其他均为0(one-hot表示)。交叉熵误差的值是由正确解标签所对应的输出结果决定的。
import numpy as np
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t)))
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t)))0.510825457099338
2.302584092994546第一个例子中,正确解标签对应的输出为0.6,此时的交叉熵误差大约为0.51。第二个例子中,正确解标签对应的输出为0.1的低值,此时的交叉熵误差大约为2.3。
4.2.3 mini-batch学习
机器学习使用训练数据进行学习,使用训练数据进行学习,严格来说,就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数。因此,计算损失函数时必须将所有的训练数据作为对象,也就是说,如果训练数据有100个的话,我们就要把这100个损失函数的总和作为学习的指标。
如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下式:
![]()
这里,假设有N个数据,![]() 表示第n个数据的第k个元素的值(
表示第n个数据的第k个元素的值(![]() 是神经网络的输出,
是神经网络的输出,![]() 是监督数据)。
是监督数据)。
神经网络的学习是从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习。比如,从60000个训练数据中随机选择100笔,再用这100笔数据进行学习,这种学习方式称为mini-batch学习。
和收视率一样,mini-batch的损失函数也是利用一部分样本数据来近似地计算整体,也就是说,用随机选择的小批量数据作为全体训练数据的近似值。
4.2.4 mini-batch版交叉熵误差的实现
如何实现mini-batch的交叉熵误差呢?只要改良一下之前实现的对应单个数据的交叉熵误差就可以了。
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t*np.log(y + 1e-7)) / batch_sizedef cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size?4.2.5 为何要设定损失函数
假设有一个神经网络,现在我们来关注这个神经网络中的某一个权重参数。此时,对该权重参数的损失函数求导,表示的是“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数的值为0时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。
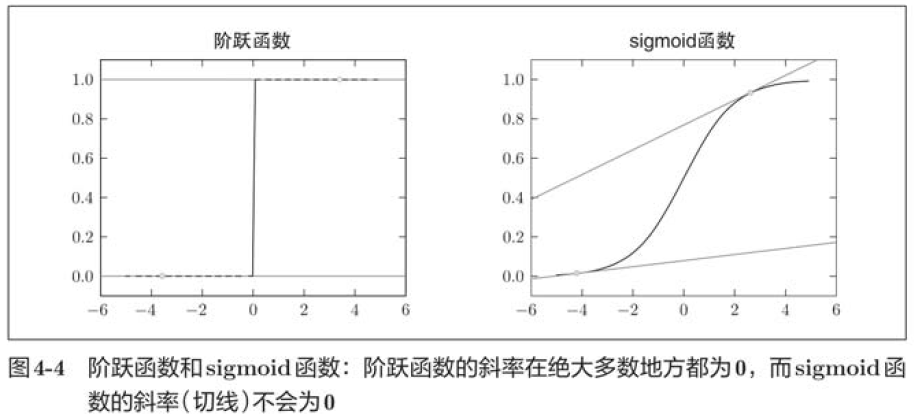
之所以不能用识别精度作为指标,是因为这样一来绝大多数地方的导数都会变为0,导致参数无法更新。
识别精度对微小的参数变化基本上没有什么反应,即便有反应,它的值也是不连续地、突然地变化。作为激活函数的阶跃函数也有同样的情况,出于相同的原因,如果使用阶跃函数作为激活函数,神经网络的学习将无法进行。阶跃函数只在某个瞬间产生变化,而sigmoid函数,不仅函数的输出是连续变化的,曲线的斜率也是连续变化的。也就是说,sigmoid函数的导数在任何地方都不为0,这对神经网络的学习非常重要。得益于这个斜率不会为0的性质,神经网络的学习得以正确进行。
4.3 数值微分
4.3.1 导数
 ?数值微分含有误差,为了减小这个误差,我们可以计算函数f在(x+h)和(x-h)之间的差分。因为这种计算方法以x为中心,计算它左右两边的差分,所以也称为中心差分(而(x+h)和x之间的差分称为前向差分)。下面,我们基于上述两个要点来实现数值微分(数值梯度)。
?数值微分含有误差,为了减小这个误差,我们可以计算函数f在(x+h)和(x-h)之间的差分。因为这种计算方法以x为中心,计算它左右两边的差分,所以也称为中心差分(而(x+h)和x之间的差分称为前向差分)。下面,我们基于上述两个要点来实现数值微分(数值梯度)。
利用微小的差分求导数的过程称为数值微分,而基于数学式的推导求导数的过程,则用“解析性”一词,称为“解析性求解”或者“解析性求导”,解析性求导得到的导数是不含误差的“真的导数”。
4.3.2 数值微分的例子
import numpy as np
import matplotlib.pylab as plt
def numerical_diff(f, x):
h = 1e-4
return (f(x+h)-f(x-h)) / (2*h)
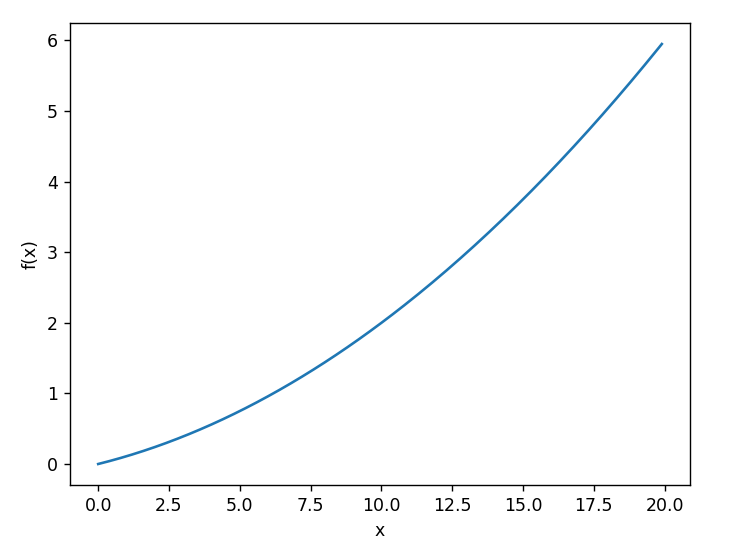
def function_1(x):
return 0.01*x**2 + 0.1*x
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.plot(x, y)
plt.show()
print(numerical_diff(function_1, 5))
print(numerical_diff(function_1, 10))
0.1999999999990898
0.2999999999986347这里计算的导数是f(x)相对于x的变化量,对应函数的斜率。另外,在x=5和x=10处,“真的导数”分比为0.2和0.3。和上面的结果相比,我们发现虽然严格意义上它们并不一致,但误差非常小。实际上,误差小到基本可以认为它们是相等的。
def tangent_line(f, x):
d = numerical_diff(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel('x')
plt.ylabel('f(x)')
tf = tangent_line(function_1, 5)
y2 = tf(x)
tf = tangent_line(function_1, 10)
y3 = tf(x)
plt.plot(x, y)
plt.plot(x, y2)
plt.plot(x, y3)
plt.show()
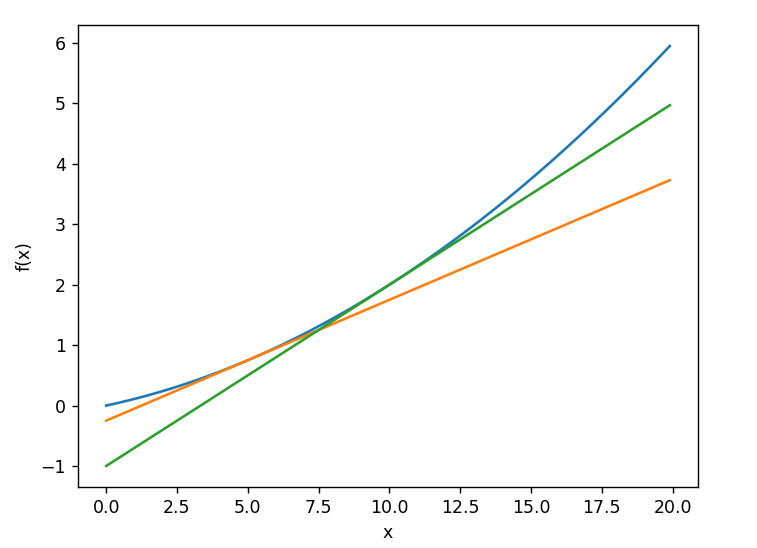
现在,我们用数值微分的值作为斜率,画一条直线,可以确认这些直线确实对应函数的切线。
4.3.3 偏导数
![]()
这个式子可以用Python来实现,如下所示。
def function_2(x):
return x[0]**2 + x[1]**2 # 或者return np.sum(x**2)import numpy as np
def numerical_diff(f, x):
h = 1e-4
return (f(x+h) - f(x-h)) / (2*h)
def function_tmp1(x0):
return x0*x0 + 4.0**2.0
def function_tmp2(x1):
return 3.0**2.0 + x1*x1
print(numerical_diff(function_tmp1, 3.0))
print(numerical_diff(function_tmp2, 4.0))6.00000000000378
7.999999999999119偏导数和单变量的导数一样,都是求某个地方的斜率。不过,偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。在上例的代码中,为了将目标变量以外的变脸固定到某些特定的值上,我们定义了新函数。然后,对新定义的函数应用了之前的求数值微分的函数,得到偏导数。
4.4 梯度
像![]() 这样的由全部变量的偏导数汇总而成的向量称为梯度。梯度可以像下面这样来实现:
这样的由全部变量的偏导数汇总而成的向量称为梯度。梯度可以像下面这样来实现:
import numpy as np
def function_2(x):
return np.sum(x**2)
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = tmp_val + h
fxh1 = f(x)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad
print(numerical_gradient(function_2, np.array([3.0, 4.0])))
print(numerical_gradient(function_2, np.array([0.0, 2.0])))
print(numerical_gradient(function_2, np.array([3.0, 0.0])))[6. 8.]
[0. 4.]
[6. 0.]
像这样,我们可以计算![]() 在各点处的梯度。为了更好地理解,我们把
在各点处的梯度。为了更好地理解,我们把![]() 的梯度画在图上。不过,这里我们画的是元素值为负梯度的向量。
的梯度画在图上。不过,这里我们画的是元素值为负梯度的向量。
import numpy as np
import matplotlib.pylab as plt
from mpl_toolkits.mplot3d import Axes3D
def _numerical_gradient_no_batch(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
def numerical_gradient(f, X):
if X.ndim == 1:
return _numerical_gradient_no_batch(f, X)
else:
grad = np.zeros_like(X)
for idx, x in enumerate(X):
grad[idx] = _numerical_gradient_no_batch(f, x)
return grad
def function_2(x):
if x.ndim == 1:
return np.sum(x**2)
else:
return np.sum(x**2, axis=1)
def tangent_line(f, x):
d = numerical_gradient(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
if __name__ == '__main__':
x0 = np.arange(-2, 2.5, 0.25)
x1 = np.arange(-2, 2.5, 0.25)
X, Y = np.meshgrid(x0, x1)
X = X.flatten()
Y = Y.flatten()
grad = numerical_gradient(function_2, np.array([X, Y]) )
plt.figure()
plt.quiver(X, Y, -grad[0], -grad[1], angles="xy",color="#666666")#,headwidth=10,scale=40,color="#444444")
plt.xlim([-2, 2])
plt.ylim([-2, 2])
plt.xlabel('x0')
plt.ylabel('x1')
plt.grid()
plt.legend()
plt.draw()
plt.show()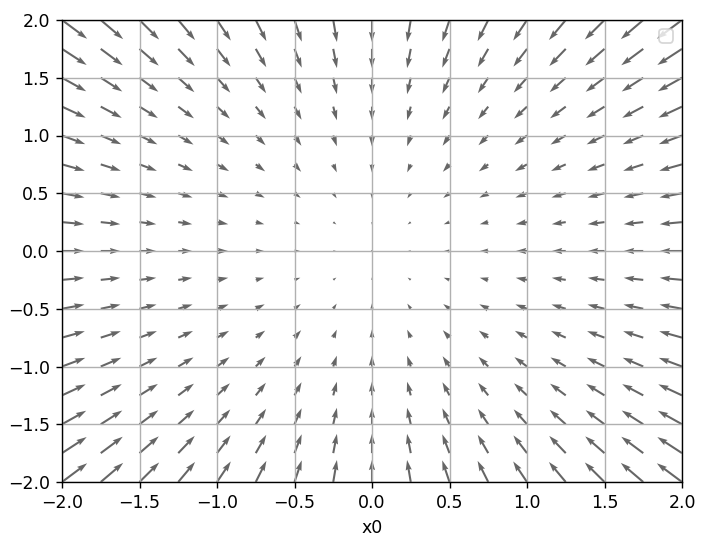
如图所示,函数的梯度呈现为有向向量(箭头)。我们发现梯度函数的“最低处”(最小值),就像指南针一样,所有的箭头都指向同一点。其次,我们发现离“最低处”越远,箭头越大。
虽然上图中的梯度指向了最低处,但并非任何时候都这样。实际上,梯度会指向各点处的函数值降低的方向。更严格地讲,梯度指示的方向是各点处的函数值减小最多的方向。
4.4.1 梯度法
机器学习的主要任务是在学习时寻找最优参数。同样的,神经网络也必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。但是,一般而言,损失函数很复杂,参数空间庞大,我们不知道它在何处能取得最小值,而通过巧妙地使用梯度来寻找函数最小值(或者尽可能小的值)的方法就是梯度法。
梯度表示的是各点处的函数值减小最多的方向,因此,无法保证梯度所指的方向就是函数的最小值或者真正应该前进的方向。实际上,在复杂的函数中,梯度指示的方向基本上都不是函数值最小处。
虽然梯度的方向并不一定指向最小值,但沿着它的方向能够最大限度地减小函数的值。因此,在寻找函数的最小值(或者尽可能小的值)的位置的任务中,要以梯度的信息为线索,决定前进的方向。
在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿着梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法。梯度法是解决机器学习中最优化问题的常用方法,特别是在神经网络的学习中经常被使用。
根据目的是寻找最小值还是最大值,梯度法的叫法有所不同。严格地讲,寻找最小值的梯度法称为梯度下降法,寻找最大值的梯度法称为梯度上升法。但是通过反转损失函数的符号,求最小值的问题和求最大值的问题会变成相同的问题,因此“下降”还是“上升”的差异本质上并不重要。一般来说,神经网络(深度学习)中,梯度法主要是是指梯度下降法。
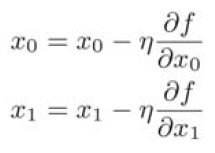
在上式中,![]() 表示更新量,在神经网络的学习中,称为学习率。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。通过反复执行此步骤,逐渐减小函数值。虽然这里只展示了有两个变量时的更新过程,但是即便增加变量的数量,也可以通过类似的式子(各个变量的偏导数)进行更新。
表示更新量,在神经网络的学习中,称为学习率。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。通过反复执行此步骤,逐渐减小函数值。虽然这里只展示了有两个变量时的更新过程,但是即便增加变量的数量,也可以通过类似的式子(各个变量的偏导数)进行更新。
import numpy as np
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = tmp_val + h
fxh1 = f(x)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
问题:请用梯度法求![]() 的最小值。
的最小值。
import numpy as np
import matplotlib.pylab as plt
from gradient_2d import numerical_gradient
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
x_history = []
for i in range(step_num):
x_history.append(x.copy())
grad = numerical_gradient(f, x)
x -= lr * grad
return x, np.array(x_history)
def function_2(x):
return x[0]**2 + x[1]**2
init_x = np.array([-3.0, 4.0])
lr = 0.1
step_num = 20
x, x_history = gradient_descent(function_2, init_x, lr=lr, step_num=step_num)
plt.plot([-5, 5], [0, 0], '--b')
plt.plot([0, 0], [-5, 5], '--b')
plt.plot(x_history[:, 0], x_history[:, 1], 'o')
plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel('X0')
plt.ylabel('X1')
plt.show()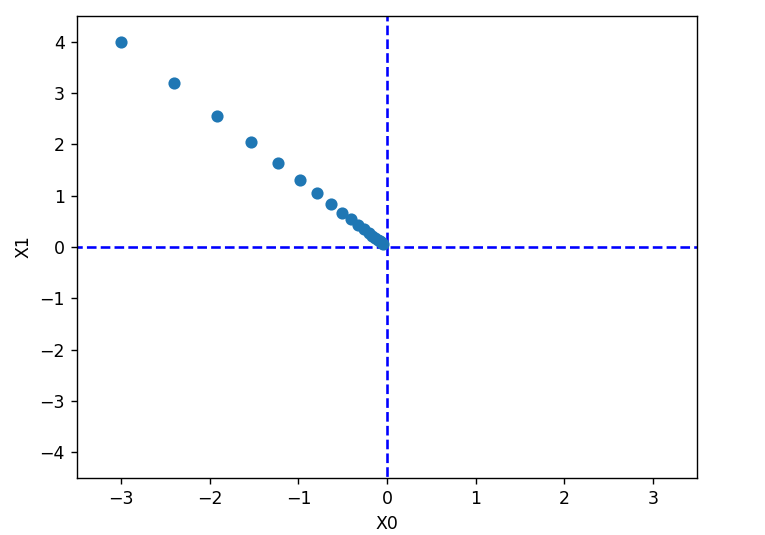
这里,设置初始值为![]() ,开始使用梯度法寻找最小值。最终的结果是
,开始使用梯度法寻找最小值。最终的结果是![]() ,非常接近(0,0)。实际上,真的最小值就是(0,0)。所以说通过梯度法我们基本得到了正确结果。
,非常接近(0,0)。实际上,真的最小值就是(0,0)。所以说通过梯度法我们基本得到了正确结果。
学习率过大或者过小都无法得到好的结果,学习率过大的话,会发散成成一个很大的值;反过来,学习率过小的话,基本上没怎么更新就结束了。也就是说,设定合适的学习率是一个很重要的问题。
像学习率这样的参数称为超参数。这是一种和神经网络的参数(权重和偏置)性质不同的参数。相对于神经网络的权重参数是通过训练数据和学习算法自动获得的,学习率这样的超参数则是人工设定的。一般来说,超参数需要尝试多个值,以便找到一种可以使学习顺利进行的设定。
4.4.2 神经网络的梯度
神经网络的学习也要求梯度,这里所说的梯度是指损失函数关于权重参数的梯度。
?
import sys
import os
sys.path.append(os.pardir)
import numpy as np
from functions import softmax, cross_entropy_error
from gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randn(2, 3)
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)
print(dW)
[[ 0.13329925 0.30577733 -0.43907658]
[ 0.19994888 0.45866599 -0.65861487]]
4.5 学习算法的实现
神经网络的学习步骤如下所示:
前提:神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为“学习”。
神经网络的学习分成下面4个步骤:
步骤1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为mini-batch。我们的目标是减小mini-batch的损失函数的值。
步骤2(计算梯度)
为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
步骤3(更新参数)
将权重参数沿梯度方向进行微小更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
神经网络的学习按照上面4个步骤进行,这个方法通过梯度下降法更新参数,不过因为这里使用的数据是随机选择的mini batch数据,所以又称为随机梯度下降法。“随机”指的是“随机选择的”的意思。因此,随机梯度下降是“对随机选择的数据进行的梯度下降法”。深度学习的很多框架中,随机梯度下降法一般由一个名为SGD的函数来实现。SGD来源于随机梯度下降法的英文名称的首字母。
4.5.1 2层神经网络的类
import sys
import os
sys.path.append(os.pardir)
from functions import *
from gradient import numerical_gradient
class TwolayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = sigmoid(a2)
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
numerical_gradient(self, x, t)基于数值微分计算参数的梯度。
4.5.2 mini-batch的实现
神经网络的学习的实现使用的是前面介绍过的mini-batch学习。所谓mini-batch学习,就是从训练数据中随机选择一部分数据(称为mini-batch),再以这些mini-batch为对象,使用梯度法更新参数的过程。
import sys
import os
import matplotlib.pyplot as plt
sys.path.append(os.pardir)
import numpy as np
from mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grad = network.gradient(x_batch, t_batch)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print('train acc, test ass | ' + str(train_acc) + ', ' + str(test_acc))
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
train acc, test ass | 0.09871666666666666, 0.098
train acc, test ass | 0.78625, 0.7898
train acc, test ass | 0.8773333333333333, 0.8799
train acc, test ass | 0.8982, 0.9021
train acc, test ass | 0.9082166666666667, 0.9116
train acc, test ass | 0.9150833333333334, 0.9167
train acc, test ass | 0.9193833333333333, 0.9203
train acc, test ass | 0.9243, 0.9258
train acc, test ass | 0.9277666666666666, 0.9277
train acc, test ass | 0.9316333333333333, 0.9329
train acc, test ass | 0.93485, 0.9345
train acc, test ass | 0.9379666666666666, 0.9373
train acc, test ass | 0.94, 0.9395
train acc, test ass | 0.9417166666666666, 0.9409
train acc, test ass | 0.9444166666666667, 0.9419
train acc, test ass | 0.9458, 0.9441
train acc, test ass | 0.947, 0.9449
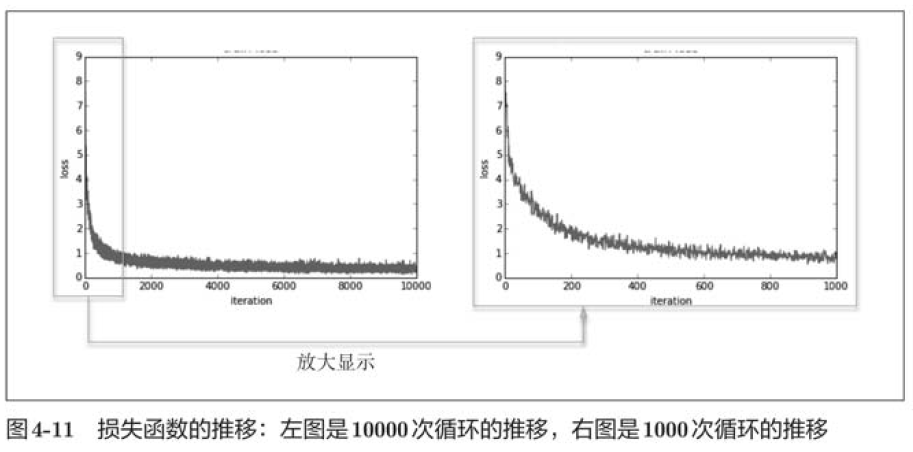
?随着学习的进行,损失函数的值在不断减少。这是学习正常进行的信号,表示神经网络的权重参数再逐渐拟合数据。也就是说,神经网络的确在学习!通过反复地向它浇灌(输入)数据,神经网络正在逐渐向最优参数靠近。
4.5.3 基于测试数据的评价
训练数据的损失函数值减小,虽说是神经网络的学习正常进行的一个信号,但光看这个结果还不能说明神经网络在其他数据集上也一定能有同等程度的表现。
神经网络的学习中,必须确认是否能够正确识别训练数据以外的其他数据,即确认是否会发生过拟合。过拟合是指,虽然训练数据中的数字图像能被正确辨认,但是不在训练数据中的数字图像却无法被识别的现象。
神经网络学习的最初目标是掌握泛化能力,因此,要评价神经网络的泛化能力,就必须使用不包含在训练数据中的数据。
epoch是一个单位。一个epoch表示学习中所有训练数据均被使用过一次时的更新次数。
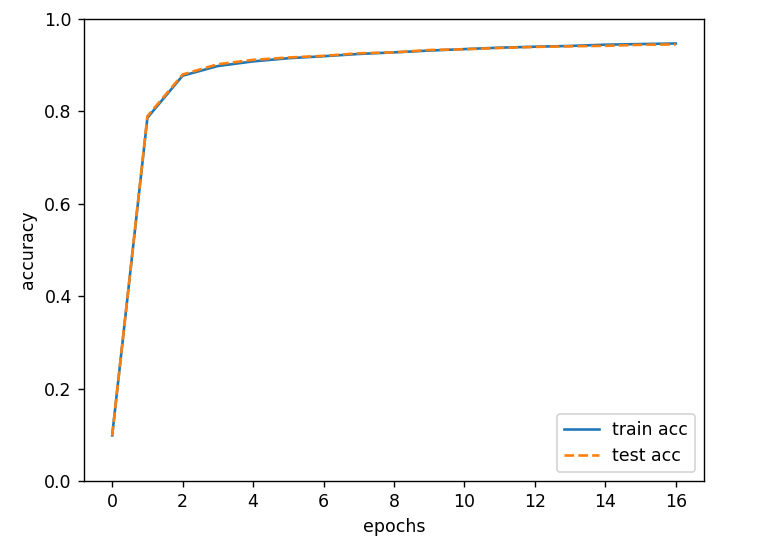
如图所示,随着epoch的前进(学习的进行),我们发现使用训练数据和测试数据评价的识别精度都提高了,并且,这两个识别精度基本上没有差异(两条线基本重叠在一起)。因此,可以说这次的学习中没有发生过拟合的现象。
4.6 小结
本章中,我们介绍了神经网络的学习。首先,为了能顺利进行神经网络的学习,我们导入了损失函数这个指标。以这个损失函数为基准,找出使它的值达到最小的权重参数,就是神经网络学习的目标。为了找到尽可能小的损失函数值,我们介绍了使用函数斜率的梯度法。
1.机器学习中使用的数据集分为训练数据和测试数据;
2.神经网络用训练数据进行学习,并用测试数据评价学习到的模型的泛化能力;
3.神经网络的学习以损失函数为指标,更新权重参数,以使损失函数的值减小;
4.利用某个给定的微小值的差分求导数的过程,称为数值微分;
5.利用数值微分,可以计算权重参数的梯度;
6.数值微分虽然费时间,但是实现起来很简单。下一章中要实现的稍微复杂一些的误差反向传播法可以高速地计算梯度。