
- 这是AAAI2022的一篇低光照图像质量增强论文
- 文章的网络结构总体如下所示

流模型基础
- 首先对流模型理论做个简单的介绍。本文将低光图像质量增强建模为:
给定低光图片作为条件,正常光照的图像条件分布在以gt为均值的高斯分布上
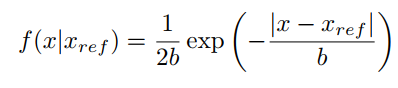
- 流模型就是一个可逆可导的函数映射,因此上述分布可以分解为,流模型(即
Θ
(
x
r
e
f
;
x
l
)
\Theta(x_{ref};x_l)
Θ(xref?;xl?),其中
x
r
e
f
x_{ref}
xref?和
x
l
x_{l}
xl?分别为GT和低光照图像。因此流模型有两个输入,而输出是一个隐变量)输出的分布乘以流模型输出对正常光照图像的雅克比:
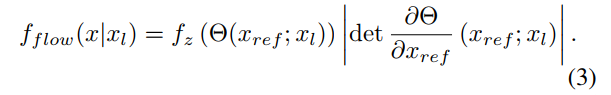
- 取负对数作为loss函数则变成以下形式:
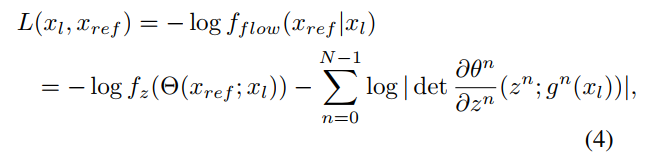
- 最后一项之所以变成求和是把流模型的各层分解出来了。
Encoder g
-
encoder g是一个RRDB网络,用来提取latent 来作为流模型中间各层的输入。g的输入由以下4部分组成:
-

-
(a)低光照图片
-
(b)对低光照图片进行直方图均衡化的结果
-
(c)color map:即对每个像素除以RGB通道的均值,因此消除掉亮度的影响而保留颜色特征,即用亮度去归一化整张图片。
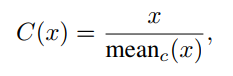
-
(d)Noise map:即 color map 的梯度图(用max来处理x y方向上的梯度)
-
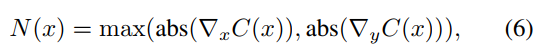
本文的流模型
- 如网络结构图所示,本文将RRDB网络的中间各层直至最后一层的输出作为流模型过程中的各层隐变量,并认为最后一层的输出作为隐变量对应着正常光照图像的color map,并且认为低光和正常光照的同一场景的图片(即paired 数据集)具有相同的color map(除了低光的color map有更多的噪声外),这类似retinex 理论中的反射分量。
- 因此,训练的时候,对于流模型网络以正常光照图像为输入进行反向传导的输出,随机选择以其对应低光照图像作为输入的RRDB网络的输出或者其自身的color map 来监督,loss函数如下:

- 而预测的时候,则只需要低光图像网络送进RRDB图像的同时进行流模型的正向传导即可预测正常光照的图像
对比实验
- 对比实验显示模型效果比Zero-DCE要好:
- 在LOL上训练和测试(这里Zero-DCE的方法效果很差,我怀疑是训练的时候没有按Zero-DCE的方式训练导致的,因为Zero-DCE需要多种光照条件的数据集进行自监督的训练,而LOL是成对图像数据集,只有高低两种光照条件,并且数据集太小了)

- 在LOL上训练在VE-LOL上测试(这里Zero-DCE反而表现很好,就很奇怪)

- 在VE-LOL上训练和测试(这个表格突然又不标EnlightenGAN的结果了?)

可调节的z
- 文章提到向RRDB最后一层的输出中加一个常数(-0.4到0.4,一次增加0.2)再送进流模型可以控制生成图片的亮度,并且是单调递增:

- 但文章不是说输出的是color map吗,为什么又和亮度有关呢。。我觉得这里不合理
自己的思考
- 文章前面提到现有方法的缺陷是低光照图像质量增强其实是一个ill-posed的问题,因为one-to-many,没有标准答案,但是本文其实好像并没有解决这个问题,这个可调节的参数也是实验结果,和模型的设计没什么关系,感觉只是碰巧这样而已。
- 而且对比实验中Zero-DCE和ElightenGAN都是无监督的模型,在paired的LOL数据集中不仅没有优势反而甚至会影响模型表现,在有监督的数据集中与无监督的方法比较指标好像并不是十分合适。。
- 但是整个框架看起来还是挺亮眼的,很有借鉴意义和改进的空间