����Ŀ¼
��һƪ:������ѧϰ�㷨�����Իع��㷨
һ��Logistic�ع�
����֪��,�ع�������Ԥ��ֵ��������,������������Ԥ��ֵ����������,���߳�Ϊ����ɢ�ġ����ǻ�֪��,����ģ�͵�һ���ص���ǡ���ֱ��,��һ��������⡢��������·��ֱ�ߡ�ֱ����������,�����ܱ����ڻع�����,������ô���������ɢ�ķ���������?
��ô˵Ҳ��������������,���ܸо���ֱ̫��,����ͼ�ͺö��ˡ���ɢ�����ܴ��š���Ծ����ôһ������,��ν��Ծ,����˼�������̨��һ���͵�һ�±���ȥ,�����е����д����ĸ��S��,����ͼ��������ͼ4-1a,��ֱͼ��(��4-1b)���Ǿͼ��ö��ˡ�
����ģ�������ٵ����˵��Ҳ��,����������ͼ4-1a��aͼ���bͼ��
- ��������
- Logistic����
1. ��������
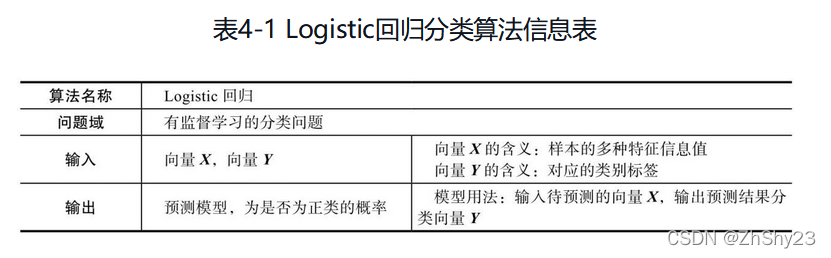
����������ع�����һ��,�������мලѧϰ,Ҳ������������Ҫ��:һ��Ҫ����Ԥ��,�����вο���,����Ϊ��������
���ȷ��������ȷ������Щ���,Ҳ���������Ԥ���趨��;Ȼ����ģ��ѵ����,�����ѵ��������ÿһ���������������Ϣ,Ҳ���Ǹ�����ʲô��������������һ��(��ͼ4-2)��
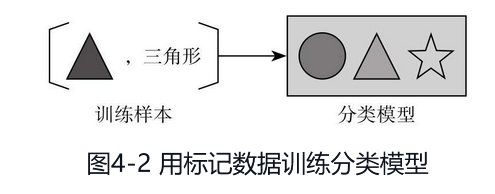
�����ǽ���Ԥ��,��Ҳ���о��������������Ŀ��,����һ��������ģ���Զ��жϾ���������һ��,��������յķ�����(��ͼ4-3)��
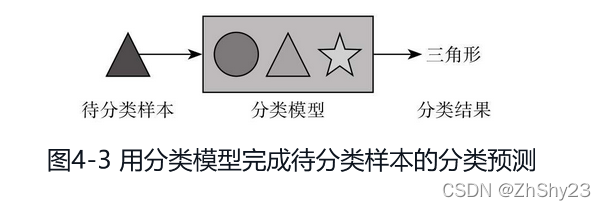
�����Է���������ӽǿ����������ࡣ����Ͱһ���Ԥ�����á��ɻ��ա��͡����ɻ��ա�����Ͷ���,���������Ԥ�����,Ȼ��ͨ�����ֻ����������ߴ����Щ�������ڿɻ���,��Щ���ڲ��ɻ���,�����ģ��ѵ���Ĺ��̡����������տ�ʼͶ������ʱ,����Ҫ�Ե�ǰ����������һ���ж�,��������������һ�ַ���,Ȼ��ŵ���Ӧ��Ͷ�ſ�,����Ǹ���ģ��ѵ���Ľ������Ԥ����������̡�
����������ҪԤ��IJ�����ֵ,�����������������ϵ����,����ѧϰ�㷨��Ҫ��ɵ���Ԥ�����������ĸ����
ѧ���϶Է����������˸�Ϊϸ�µ�����:
- ����������ֻ������,ͨ����֮Ϊ��Ԫ����(Binary Classification)����,�ڻ���ѧϰ�н϶�ʹ��Logistic�����������
- ���������������,���֮Ϊ�����(Multi-classClassification)����,�ڻ���ѧϰ�н϶�ʹ��Softmax�����������
����ѧϰ������ʵ����������,���������ֵ���һ�����,�����÷���������Է��������
Ʃ��˵���ڡ������Dz��Ǹ�˯���ˡ�,���ܵ�ѡ�����������������廨����,��������˯���ˡ��͡���û��˯����ʱ��,����������г���,�����Ի��롰�ǡ�����ߡ����ࡣ
���ǡ���͡������ڻ���ѧϰ�зdz�����,Ҳ�dz���Ҫ,���,����ѧϰר�Ź涨������,�����������Ϊ**�����ࡱ(Positive),�������������Ϊ�����ࡱ(Negative),��֮��Ӧ��ѵ������Ҳ�ɻ��ֳ�������������������������**
ͨ������ӽ�,�Ϳ��Ѷ�Ԫ��������Ͷ��������ͳһ����,���������ɺܶ����Ԫ������ɵķ�������,�γ����ݽṹ�еĶ�����������
���ڵ�����������Ҳ�����˶��������,Ʃ��ֳɳ����������ɻ����������к�������,��ô�ö�Ԫ����ķ���,���ȿ��Խ���һ���Dz��dz��������ķ���,���dz�������������Ҳ���Ǹ���,�������������һ���Dz��ǿɻ��������ķ���,��������ܲ��Ͻ�����ȥ,���������Ҳ�Ϳ����ö�Ԫ����������,��Ҳ��������Զ�Ԫ����������Ƶ��㷨���õ���������������һ����Ҫ��ʽ��
���,��Ԫ��������Ҳ�ͳ�Ϊ������ķ������⡣
2. Logistic����
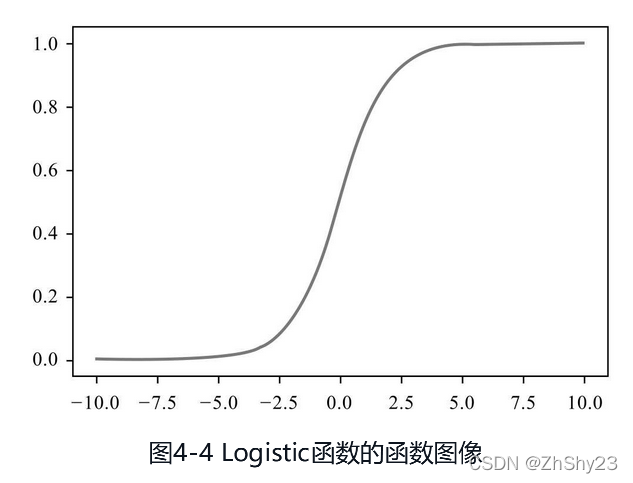
����ģ���ܹ�Ԥ����ɢ�ķ������������ȫ������Logistic�������档Logistic������ͳ��ѧ��Ƥ�������������ߡ�Τ���շ�����19����,���кܶ�����,�����������㷨�г���ΪSigmoid����,Ҳ���˳���ΪLogistic����,�ܵ���˵,����һ�������ġ��ܺõĺ�����Logistic�������������������������ӵ�����������������Ŀ�ꡪ�����۵�S������,����ͼ����ͼ4-4��ʾ��
(1) ��Ծ����(���ɵ�)
ǰ���������۷�������ʱ�ᵽ���������Ԥ��������ɢ��,����ֽ�Ծ������Ծ����������ر�����,ͼ���ʼҲ��һ��ƽ�������ֱ��,������ijһ����,Ʃ��˵�ں����ꡰ0����λ��,ͼ��ͻȻ�仯��,����һ����ֱ��Ծ,����һ���ܾ��˵��۾����͵ذ�����ͷ,�������������µؼ�������ֱ����ǰ�ߡ�
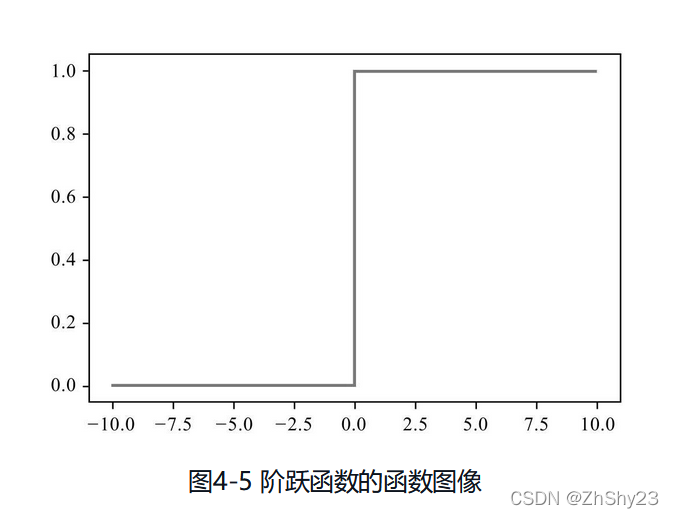
���ڹ���Ӧ��,��Ծ�������������ʾ����ر�ߵ�ʵ�ü�ֵ,Ʃ����������ء������á���,�����洦�ɼ���һ�����ͷ�������ડ�����Ŀ���,��˳������ź�ϵͳ������˵�������ء�,���Ͽ����뵽����Ƕ�Ԫ���������һ�ֵ���ʵ��,����,��Ծ���������ѧϰ�ƺ���ʼ���˽�����
��ϧҲ�͵���Ϊֹ��,��Ծ������ֱ�����ڻ���ѧϰ�����ѿ���,Logistic�����ͱ���Ծ�������Ǵ��������ԵIJ�ͬ����Ծ������������Ȼ�dz�Ӳ��,����λ��ȫ����Ӳ����ֱ��,�����ĺ��������ɵ��ġ�
��������,ʵ���Ͻ�Ծ������ȷͼ��Ӧ��������ֱ��һ����:
- ��x<0ʱ,ͼ��ʼ����ij��ֵ,
- ��x>0ʱ,ͼ����ʼ����ij��ֵ,
- ����x=0ʱ,������ֵֻ��Ϊһ��ȷ��,����0��
��Ծ�����ڲ������������ĵ�,���Ҳ��Ϊ���캯������Ծ������ͼ���Dz�������,�������ĺ���ͬ�����ɵ������ڻ���ѧϰ��,�ɵ��Էdz���Ҫ,�����������ʹ���ݶ��½����Ż��㷨,ʹ��ƫ����С�ˡ�
(2)�ɵ��Ľ�Ծ����
Logistic������һ�ֿɵ�����,����һ�ֽ�Ծ����,����˵�ܹ��������ƽ�Ծ�����Ľ�ɫ�������ĸ�����Logistic����ͼ���ѿ���,���ʼҲ��һ��ֱ��,Ȼ����ij��λ����Ȼ̧ͷ����,����������һ��ֱ�ߡ����, Logistic����Ҳ�������ء��Ĺ��ܡ�
�����Ǿͺܺ�����,Logistic����������ͬʱ���������ֳ�ͻҪ�����?���ܾ���������������Logistic������˵,�����ᡰ0����һ�������������������,Խ����0��ԽԶ��0,Ҳ��������0����С�ͷŴ�,����ͼ���ֽ�Ȼ��ͬ����״,���ơ�������ı��ν�ա���
���������Logistic����ͼ������(-10,10)�����Ŀ�������Ƶ�,���ֳ���Ư����S���ߡ����������ֵ����0����С,����Կ���S���߱��Խ��Խ��ֱ��,����(-1,1)������Сʱ,�����ͱ����һ��ֱ�ߡ������Logistic����Ϊʲô�ɵ�,��ͼ4-6��ʾ��
 ��������,ֻҪ���ֵ��������,Logistic����ͼ��Խ��Խ�ӽ���ԭ���Ľ�Ծ����,Խ�ܷ��ӳ������ء���Ч������ͼ4-7��ʾ��
��������,ֻҪ���ֵ��������,Logistic����ͼ��Խ��Խ�ӽ���ԭ���Ľ�Ծ����,Խ�ܷ��ӳ������ء���Ч������ͼ4-7��ʾ��

���ڿ��Կ�����,Logistic������Ϊ��Ծ������˵,�dz߶�Խ��,Ч��Խ���ԡ������������,���Ǿ��ܰ�Logistic������Ϊ������������ֵ�ͽ�Ծ��ɢֵ��������
����ģ�͵�Ԥ������һ����������ֵ,�����趨�������ĵġ���Logistic������һ���ܱ���������:
- X���ֵԽ��С��0,Y���ֵ��Խ�ǽӽ���0 ;
- X���ֵԽ�Ǵ���0,Y���ֵ��Խ�ǽӽ���1��
��ô,ͨ��Logistic�����Ϳ�������ģ�͵�Ԥ����ӳ��ɷ������������Ԥ������˼·����:
- ������ģ�͵������Logistic���������봮��������
- ������Ϊ����ʱ,������ģ�������Ԥ��ֵС��0,����ԽСԽ�á�
- ������Ϊ����ʱ,������ģ�������Ԥ��ֵ����0,����Խ��Խ�á�
����Logistic��������ӳ��,����ģ�Ͳ�����Ҫ���ij���ض���ֵ,��ֻҪ���㡰����������ܵؽӽ�0����1����һ��Ҫ�ɡ�����Ҫ��������ģ�Ϳ�������ġ�
����Logistic�ع���㷨ԭ��
1. ����˼·
���������Ԥ������ȻԤ��������,Ҳ�������ճ�������ϰ��������������Ϊ��ͬ��������,���ڻ���ѧϰ��,ʹ�õ�����ǰԼ������ֵ���������,���õ���ʽ����������:
- ������ʽ:������Ϊֱ�ӵ�һ����ʽ,Ʃ��ֱ���á�1����������,��-1����������,��ôԤ����������������1��,�Ǹ�������-1,�����ˡ���Ȼ,ָ�������ֲ���Ψһ��,ֻҪ��������Ӧ����,Ʃ����һ�ֳ���ϰ�����á�0����ָ�����ࡣ
- ������ʽ:���ǵ�ǰ���ѧϰ�ڷ���������ʹ������һ����ʽ,�ر����ڶ���������϶����������ʽ,��������Ԫ�ذ�˳��������,Ʃ����A��B��C����,�Ϳ�����[x1, x2, x3]����������Ԫ�����δ���,Ԥ����Ϊ��һ��,�Ͱ������еĶ�ӦԪ����1,������0����Ԥ��Ľ�����Ϊ��A��,�������Ԥ�����ͱ�ʾΪ[1,0,0];Ԥ����Ϊ��B��,���ʾΪ[0,1,0]��
- ����ֵ��ʽ:ǰ�����ֱ�ʾ��ʽ����1��0��ȷֵ����ʾԤ�����Ƿ�Ϊ�����,�������㷨������Ԥ�������Ǿ��Եġ���/��,����ÿ����Ŀ��ܸ��ʡ������Ķ�A��B��C�����Ԥ����,��������ʽ�ͱ�ʾΪ��[0.8435, 0.032, 0.000419],���Կ���,��Ȼ����Ԫ�ض�����һ������,����Ȼ��A���ĸ���Ҫ��������,ͬ���ܹ���Ԥ������Ч����
����ȷ����,����ҪԤ�����һ����Ԫ��������,�����ʽ��������ʽ,Ҳ����1����-1����0Ϊ��,������ֵ����һ��,���Ǿ͵õ�����Ҫ����ɢֵ��
if (����ģ�����������ֵ > 0):
return 1
else:
return -1
�ؼ������������Իع顣���Ǹ�������,ѧ�Ŵ�����ģ�͵��ӽǿ�,�ͻᷢ���������������ʲôԤ��ֵ����ɢ�ķ�������,����ҪԤ��õ�һ������ֵ��
��������һ��������ֵ,��Ȼ���Ǵ���0����С��0,Ϊ��ʹԤ���ȷ,Ψһ��Ҫ�����Ԥ��ֵ����0��ԽԶԽ��,Ʃ��˵���������ҪԤ��3756.2��3890��3910.7,�Ѹ���������ҪԤ��-2116.4��-2213��-2305.6����������ֵ���Ȼ���ǵ��͵Ļع�����,Ȼ��Ϳ����պ�«��ư�������Իع������ϰ취ȥ��ϡ�ֻҪ���Իع�Բ���������������,������Ȼ���ܱ�֤�����Ԥ��������0,������С��0��(��ͼ4-8)��

��������ƺ��ܼ��жϽṹ,����ʵ�Ǵ���������Sgn����,Ҳ��������ǰ��������Logistic������ҪЧ�µĽ�Ծ����,Sgn����������ʾ:
s
g
n
(
x
)
=
{
1
,
x
>
0
0
,
x
=
0
?
1
,
x
<
0
(4-1)
sgn(x)= \begin{cases} 1,&x>0\\ 0,&x=0\\ -1,&x<0 \end{cases} \tag{4-1}
sgn(x)=??????1,0,?1,?x>0x=0x<0?(4-1)
����Ҳ����ǰ������,Sgn�������ڲ��ɵ�������,����ʵ��������ѡ����Logistic��������������λ�á�
2. ��ѧ����
(1) ��ѧ����ʽ
Logistic������ѧ����ʽ:
L
o
g
i
s
t
i
c
(
z
)
=
1
1
+
e
?
z
(4-2)
Logistic(z)=\frac{1}{1+e^{-z}} \tag{4-2}
Logistic(z)=1+e?z1?(4-2)
- e��Ϊ��Ȼ����,Ҳ����һ���̶�ֵ�ġ�������,
e
?
z
e^{-z}
e?z����eΪ�ס�zΪ������ָ������,��������д��Ϊ
e
?
x
e^{-x}
e?x����eΪ��ָ������
e
x
e^x
ex�ֿ���д��exp(x),������ʽ���ӽ��ڱ�̵ĺ���д��������ֻ����д�����IJ�ͬ,��ʱ���㿴����Logistic�ع���ܲ���������д��,������ʽ�����������һ����:
L o g i s t i c ( z ) = 1 1 + e x p ( ? z ) (4-3) Logistic(z)=\frac{1}{1+exp(-z)} \tag{4-3} Logistic(z)=1+exp(?z)1?(4-3)
Logistic�ع�ļ��躯����������Logistic���������Է���,Ҳ���ǰ����Է��̱���ʽ������ʽ��z,����ʽ����:
H
(
x
)
=
1
1
+
e
?
(
w
T
x
i
+
b
)
(4-4)
H(x)=\frac{1}{1+e^{-(w^Tx_i+b)}} \tag{4-4}
H(x)=1+e?(wTxi?+b)1?(4-4)
(2) ��ʧ����
����ʽ:
L
(
x
)
=
?
y
l
o
g
H
(
x
)
?
(
1
?
y
)
l
o
g
(
1
?
H
(
x
)
)
(4-5)
L(x)=-ylogH(x)-(1-y)log(1-H(x)) \tag{4-5}
L(x)=?ylogH(x)?(1?y)log(1?H(x))(4-5)
��ϸ�۲�Logistic�������������,ֵ���Ǵ�0��1��ʲô��Ԥ�����,ֵ�����Ǵ�0��1����?������Ժ���Ҳ������һ����ͷ,û��,����!�ⲻ��żȻ��ѡȡLogistic������Ϊ����,һ�ǿ�������S����,������Ϊ�������������ϸ��ʵ�Ҫ��
Logistic������ĸ���������ĸ���������������,������������ݻ���������ǩ(Class Label)��Ϣ�����������y�������,����������Ϣ��ֵ�����ó�0��1,���ֵ���������⸳���,�����������������Ϊ1,����Ϊ0��Ҳ����˵,����������ʱ,���Ѿ������൱����,Ԥ��ʱ����Ӧ��Ҳ�ð����൱������
��ʧ������Ҫ��Ԥ������ʵ�ʽ���������,�����Ԥ������������,�����д����һ����ʧ����:
L
(
x
)
=
?
H
(
x
i
)
y
i
(
1
?
H
(
x
i
)
)
1
?
y
i
(4-6)
L(x)=-H(x_i)^{y_i}(1-H(x_i))^{1-y_i}\tag{4-6}
L(x)=?H(xi?)yi?(1?H(xi?))1?yi?(4-6)
����һ��������ĺ���,�Ǹ��ݸ�����Ƴ����ġ�������ֵ�� H ( x i ) y i H(x_i)^{y_i} H(xi?)yi?�� ( 1 ? H ( x i ) ) 1 ? y i (1-H(x_i))^{1-y_i} (1?H(xi?))1?yi?���������,������y��ֵֻ��Ϊ0��1,����ʵ����ÿ��ֻ����һ�������ܹ����ֵ��
- ��y=1ʱ,1-y��Ϊ0,���Եڶ����ֵ�ֵΪ1,��˺�Ժ�����ֵ����Ӱ��,����ֵΪ H ( x i ) y i H(x_i)^{y_i} H(xi?)yi?��
- ͬ��,��y=0ʱ,����ֵΪ ( 1 ? H ( x i ) ) 1 ? y i (1-H(x_i))^{1-y_i} (1?H(xi?))1?yi?��
����ȷ��һ����ʧ�����Ƿ�����������
��y=1ʱ,���Ԥ����ȷ,Ԥ��ֵ�����ӽ�1,Ҳ��
H
(
x
i
)
y
i
H(x_i)^{y_i}
H(xi?)yi?��ֵΪ1,��ʧֵ��Ϊ-1�����Ԥ�����,
H
(
x
i
)
y
i
H(x_i)^{y_i}
H(xi?)yi?��ֵΪ0,��ʧֵҲΪ0��Ԥ��������ʧֵȷʵ��Ԥ����ȷ�Ĵ�,����Ҫ��
Ҳ���ٸ�����������,ΪʲôҪ��ǰ��Ӹ�����,�ѵ�ֻ��һ��Ӳ���趨?��ʵǰ���Ѿ��ṩ��,��ʧ�����Ǹ��ݸ�������Ƶ�,������˵�Ǹ�����Ȼ����
P
(
Y
�O
X
;
w
)
P(Y|X; w)
P(Y�OX;w)��ָ���ġ�����Ȼ���������Ƚϸ���,���ǽ��ں�������,���������Ԥ��ֵ��ʵ�ʽ��Խ����,��Ȼ������ֵԽ����������ϣ������Ԥ��ֵ��ʵ�ʽ�����Խ��,������ֵԽ��,��ֻҪ����Ȼ����ȡ��,���ܴﵽ���Ŀ�ġ�
��һ�����ʧ������Ȼ�ܹ�����Ԥ��ֵ��ʵ��ֵ֮���ƫ��,������һ������������:������һ������,�⽫������ʹ���ݶ��½����Ż�����ʹ����ʧֵ��С�����ڻ���ѧϰ�����������Ӧ������״���Ľ������:��������,Ҳ��ȡlog��
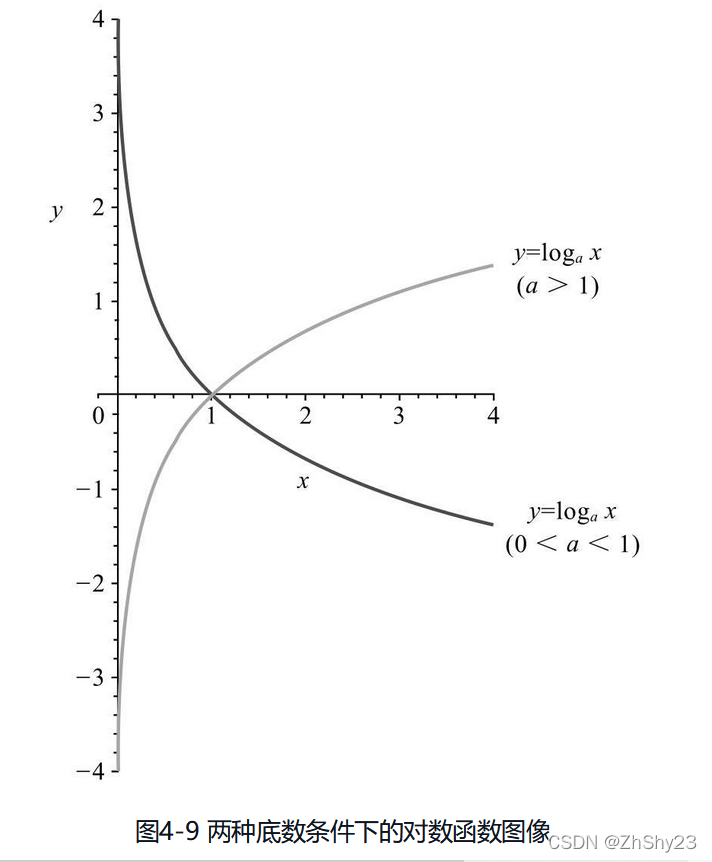
���ڶ���������֪ʶ,����ֻ��Ҫ֪������,���ȶ������ǵ�������,��Ҫô����,Ҫô�ݼ�;Ȼ������˽�һ�²�ͬ��������Ӧ�ĺ���ͼ��,һ��Ҳ������,����������1ʱ,������������,��������С��1������0ʱ,���������ݼ�������������Ҳ�е㸴�ӵĻ�,��ôֻ��Ҫ֪��,����ѧϰ�д���ʹ����log,������������1,�����ھ����������¶�ȡ��Ȼ����e,Ҳ���ǵ�������1�����,����ͼ���ǵ���������(��ͼ4-9)��
3. ���岽��
Logistic�ع�����Իع�IJ�������,���ȴ��һ����ɢ��ֵ���������4-1��ʾ��
���岽��ͬ��������:
- Ϊ���躯���趨����w,ͨ�����躯�������һ��Ԥ��ֵ��
- ��Ԥ��ֵ������ʧ����,�����һ����ʧֵ��
- ͨ���õ�����ʧֵ,�����ݶ��½����Ż�������������w�������ظ��������,ʹ����ʧֵ��С��
������Python��ʹ��Logistic�ع��㷨
1. LinearRegression��
��Ӧ���Իع��㷨,Ҳ��Ϊ��ͨ��С���˷�,����Ԥ��ع�����,��ʧ��������ѧ����ʽ:
L
(
x
)
=
m
i
n
w
��
X
w
?
y
��
2
2
(4-8)
L(x)=\underset{w}{min}\|Xw-y\|^2_2 \tag{4-8}
L(x)=wmin?��Xw?y��22?(4-8)
LinearRegression�����fit�������������X��y,���ҽ�����ģ�͵�ϵ���洢�����Ա����coef_�С�
2. Ridge��
��ӦRidge�ع��㷨,�ֳ�Ϊ��ع�,����Ԥ��ع�����,�������Իع�Ļ�����������L2������,ʹ��Ȩ��weight�ķֲ���Ϊƽ��,����ʧ��������ѧ����ʽ����:
L
(
x
)
=
m
i
n
w
��
X
w
?
y
��
2
2
+
a
��
w
��
2
2
(4-9)
L(x)=\underset{w}{min}\|Xw-y\|^2_2+a\|w\|^2_2 \tag{4-9}
L(x)=wmin?��Xw?y��22?+a��w��22?(4-9)
����ʽ����������Իع��㷨����ʧ����һ��,ֻ�Ƕ����������Ҳ��L2�������ʽ,����a��һ������,���ݾ������á�
3. Lasso��
��ӦLasso�ع��㷨������֪��,���õ���������L1��L2,����L2����������Իع���Ridge�ع�,����L1����������Իع���ʲô��?����Lasso�ع�,ͬ������Ԥ��ع����⡣����ʧ��������ѧ����ʽ����:
L
(
x
)
=
m
i
n
w
1
2
n
��
X
w
?
y
��
2
2
+
a
��
w
��
1
(4-10)
L(x)=\underset{w}{min}\frac{1}{2n}\|Xw-y\|^2_2+a\|w\|_1 \tag{4-10}
L(x)=wmin?2n1?��Xw?y��22?+a��w��1?(4-10)
����ʽ�������Ridge�ع��㷨����ʧ��������һ��,ֻ�ǽ��Ҳ��L2�������ʽ�滻����L1�������ʽ������ܹ�ע�����ʽ��������Իع�,����һ��
1
2
n
\frac{1}{2n}
2n1?,����n����������,���Ż����̵������в��ᷢ���仯,��һ������,�������Ȩ��w�ĵ�������Ӱ��,���Ա��ʻ���һ���ġ�
4. LogisticRegression��
# ��������ģ���е�Logistic�ع��㷨
from sklearn.linear_model import LogisticRegression
# Scikit-Learn���д���֪�����β���������ݼ�,��һ��������������ݼ�
from sklearn.datasets import load_iris
# �����β�����ݼ�
X, y = load_iris(return_X_y=True)
# ѵ��ģ��
clf = LogisticRegression().fit(X, y)
# ʹ��ģ�ͽ��з���Ԥ��
clf.predict(X)
print("array({})".format(clf.predict(X)))
===================================================
array([0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 2 1 1 1
1 1 1 1 1 1 1 1 1 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2])
ģ���Դ�Ĭ�ϵ�����������,ʹ�÷�������:
print("{}".format(clf.score(X, y)))
=============================
0.96
�ġ�Logistic�ع��㷨��ʹ�ó���
