基于RGB和LiDAR融合的自动驾驶3D语义分割
论文 RGB and LiDAR fusion based 3D Semantic Segmentationfor Autonomous Driving
摘要
激光雷达已经成为交通驾驶应用的标准传感器,因为他们提供了高度精确的三维点云。激光雷达对于夜间的低光场景或由于阴影而导致相机性能下降的场景也很健壮。激光雷达的感知算法逐渐成熟,包括目标检测和SLAM。然而,语义分割算法的研究相对较少。基于图像语义分割是一种成熟的图像分割算法,本文对基于传感器融合的三维图像分割进行了研究。我们的主要贡献是将RGB图像转换为用于激光雷达的极网格映射表示,并设计早期和中期的融合架构。
此外,我们设计了一种混合融合架构,结合了这两种融合算法。我们在KITTI数据集上对算法进行了评测,该数据集为汽车、行人和骑自行车者提供了分割标注。我们评估了两个最先进的体系结构,即SqueezeSeg和PointSeg,并在两种情况下提高mIoU分数,相对于仅使用LiDAR的基线,提高了10%。
introduction
自动驾驶是一项复杂的任务,机器人汽车需要在高度动态的环境中实现全自动驾驶。为了完成这一任务,自动驾驶汽车必须配备多个传感器和鲁棒算法,以实时的方式高精度地感知周围环境。感知pipeline的第一步是从背景中检测出目标。目标检测本身不足以让机器人导航,必须有鲁棒的分类来确定每个对象的类型,以规划交互,特别是对于复杂的场景,如停车[9][11]。这是一项至关重要的任务,因为与突然出现的车辆相比,自动驾驶汽车对行人的反应会完全不同。此外,算法必须估计外部对象的位置在随后的帧能够采取适当的行动。
从这个角度来看,三维语义分割是自动驾驶的关键任务,它同时对目标进行三维定位和分类,如图1所示。在[4][10][23]中对点云分割进行了研究。经典的方法使用管道,包括从前景对象分割地面,聚类对象的点和执行分类基于手工制作的特征。这种方法容易由于累积误差而导致性能低下
此外,它们不能很好地适用于不同的驾驶环境。由于深度学习具有强大的自动特征提取功能,它能够发现不同领域之间的模糊关系,而不是人类有时无法解释的模糊关系,因此近年来在包括语义分割在内的多个任务中获得了很大的关注。本文采用端到端卷积神经网络(CNN)进行三维语义分割。我们的方法利用了两种互补传感器的信息,即摄像头和激光雷达,这两种传感器正在最近的商用车上部署。相机传感器提供颜色,而激光雷达提供深度信息。[22][21]最近的工作提供了仅从LiDAR理解语义的算法。在此基础上,将颜色信息与激光雷达数据融合,进行三维语义分割。我们实现了两种融合算法来研究添加颜色信息对图像融合的影响。第一种方法是早期融合,即在特征提取之前将信息作为原始数据进行融合。第二种方法是中间融合,我们使用CNN从两种不同的模式中提取特征,然后执行融合特征级别。
本文的主要贡献如下:
1)构建了基于CNN的早期和中期融合架构,系统研究了颜色信息对三维语义分割的影响。
2)对目前最先进的两种算法SqueezeSeg和PointSeg进行评价,通过与摄像机数据融合,获得了显著改善。
- RGB融合表示和混合融合设计提高结果的策略。
本文组织如下。第二节回顾了语义分割和点云分割的相关工作。第三节讨论了我们算法的各种提出的体系结构。第四部分详细介绍了所使用的数据集和实验设置,并讨论了得到的结果。第五部分是结束语和今后的工作。
II. RELATED WORK
在[19]中对自动驾驶的图像语义分割进行了详细的研究,在[2][20]中讨论了有效的设计技术。我们简要总结了像素级分类的主要方法。在[8]中使用patch-wise训练进行分类,在[6]中将输入图像送入拉普拉斯金字塔提取层次特征。在[8]中使用了深度网络,避免了进一步的后处理。采用端到端的方法对SegNet[1]进行语义分词。在[14]中,网络学习向上采样的热图,生成类化输出。在en编码器和解码器之间引入多个跳过连接,以避免失去分辨率。
与patch-wise方法不同,该方法使用完整的图像生成密集的语义分割输出。SegNet[1]提出了一种编码器-解码器网络,利用相应编码器层保留的索引信息对特征映射进行上采样。基于颜色的分割已经有了一些改进,但它们通常没有利用深度信息。
B。点云语义分割
相对于图像分割,关于点云语义分割的文献很少。大多数的三维物体检测文献关注的是三维包围盒的检测,但在很多情况下它并不是物体的最佳表示。这类似于二维分割,在图像中提供了比二维包围框更好的表示。一般来说,激光雷达感知的主要挑战是点云数据的稀疏性。它大大增加了外观的复杂性。因此,有许多不同的方法来简化这种表示,包括体素、鸟瞰和极网格地图。体素是聚类的点云数据,但仍然存在稀疏性问题。
鸟瞰图是最简单的表示,它将点云简化为一个平面。然而,这样就丢失了高度信息,从而丢失了探测物体所必需的重要外观特征。
在[5]中进行Bird-View Lidar语义分割,将Lidar点投影到网格xy平面上,并对每个网格进行语义分类。
其他方法用预先定义的分辨率将空间划分为体素[24],在这些体素中投影点云,并执行体素级分类。然而,体素化的主要问题是由于考虑了已占用和未占用的体素,需要内存资源和处理能力来表示被激光雷达传感器覆盖的巨大体积。在[18]中探索了使用高清地图进行运动目标分割的有效实现。另一方面,也有其他使用3D点云进行语义分割的方法,如PointNet[15]、PointNet++[15],它们将点云视为一组无序的点。该方法提供了对任意视角的不变性,但在自动驾驶中,特定视角是重要的。它也没有考虑激光雷达扫描的结构。
最近,Squeezeseg[22]利用极坐标网格地图解决了这一问题,在第三节a中详细讨论了这一问题。它使用了激光雷达点云的球面表示,明确地模拟了扫描过程,并提供了一个相对密集的2D平面。这为利用基于图像的语义分割体系结构提供了机会。
III. PROPOSED ALGORITHM
A激光雷达和相机的极网格地图表示
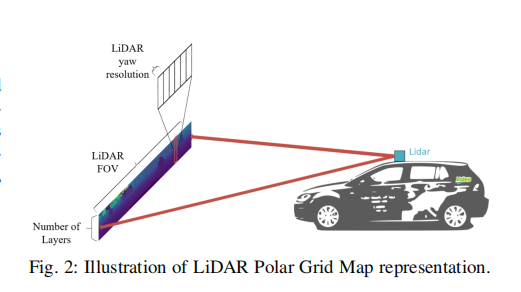
激光雷达传感器可以建模为一组排序的点,其中测量的射线在一个瞬间捕获,每条射线代表一个扫描点在一层。这是在一定的偏航角度执行,然后激光雷达旋转到下一个偏航角度,以进行另一个测量。
想象目前是搭载一个可以一个完整的360?感知周围的场景雷达的车辆。点云由大量点组成N =(层数)×(每层点数)其中每层点数= (Yaw FOV) (发射角度的Yaw分辨率)。
将稀疏的三维数据重构为二维极网格,高度为层数,宽度为每层检测到的点数,如图2所示。前视图是最重要的部分,为驾驶和全激光雷达扫描前视图的一个子集是为90?视场(FOV)与0.175?偏航分辨率,64层和5个特征(X, Y, Z, I, D)如图1所示。X, Y, Z为激光雷达传感器的笛卡尔坐标,I为扫描点的强度,D为扫描点的深度。这种表示被称为极网格图(PGM),这个张量的大小是64x512x5。
摄像机的二维图像是通过光线在图像平面上的投影得到的。通常,相机可能有一个不同的视场相比激光雷达。例如,激光雷达无法看到车辆的近场。照相机的理想针孔投影模型也被现代镜头所打破,这在鱼眼镜头的情况下是非常明显的。
LiDAR通常被投影到相机成像平面[13]上。然而,这导致了LiDAR的稀疏表示,可能导致模型的效果不好。在本文中,我们探索了另一种方法,重新投影像素到激光雷达的极网格地图平面是密集的。利用相对校正信息,将激光雷达点云投影到RGB图像上。这就建立了激光雷达扫描点和RGB像素之间的映射。利用该映射,我们在现有的点云特征张量XYZID的基础上增加三个额外的特征(RGB),创建一个大小为64x512x8的张量,如图3所示,大小为64x512x1的张量对应的ground truth如图3底部所示。这种表示也是可伸缩的,以映射汽车周围的多个摄像头,可以覆盖全360 ?。然而,它的缺点是不能利用没有映射到激光雷达点的彩色像素。
B. LiDAR baseline architecture
我们的基线架构是基于SqueezeSeg[22],这是一个轻量级架构,只使用LiDAR点云进行3D语义分割。网络架构如图4 (a)所示。它建立在SqueezeNet[12]上,使用编码器直到fire9层从输入点云中提取特征。fire单元包括1x1转换层,将输入张量压缩到原来深度的四分之一。两个并行卷积层之后是一个串联层来扩展压缩张量。输出被传递给fireDeconv模块进行上采样,在压缩层和扩展层之间插入反卷积层。
利用跳跃连接连接深浅层,以保持高分辨率的特征图,避免精度损失。最后,在最后的卷积层之后,再经过softmax层生成输出概率。该体系结构的输入是一个5通道张量,它包括X、Y、Z的三层,描述了点云中每个点的空间位置。第四层是深度图,它显示了激光雷达传感器和目标点之间的极距。最后,第五层编码激光雷达光束的反射强度。我们将这个输入称为XYZDI。我们还使用PointSeg[21]实现了另一个baseline架构,它改进了SqueezeSeg。
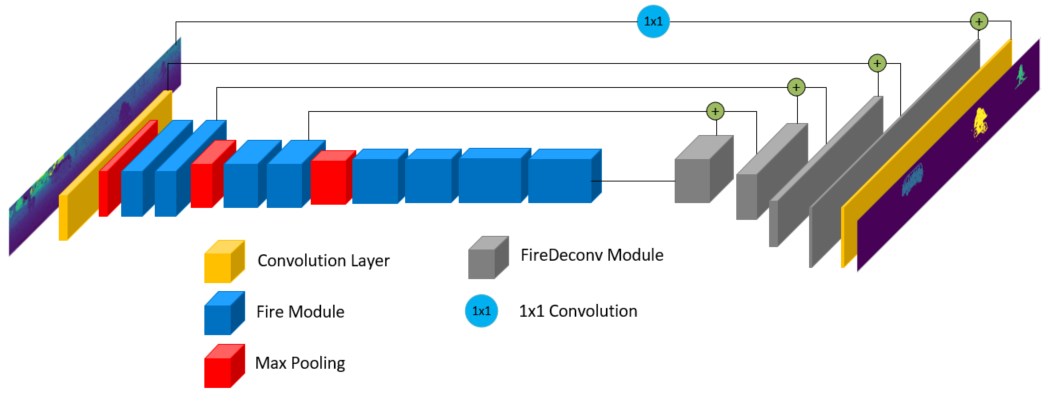
? (a) LiDAR baseline architecture based on SqueezeSeg [22].
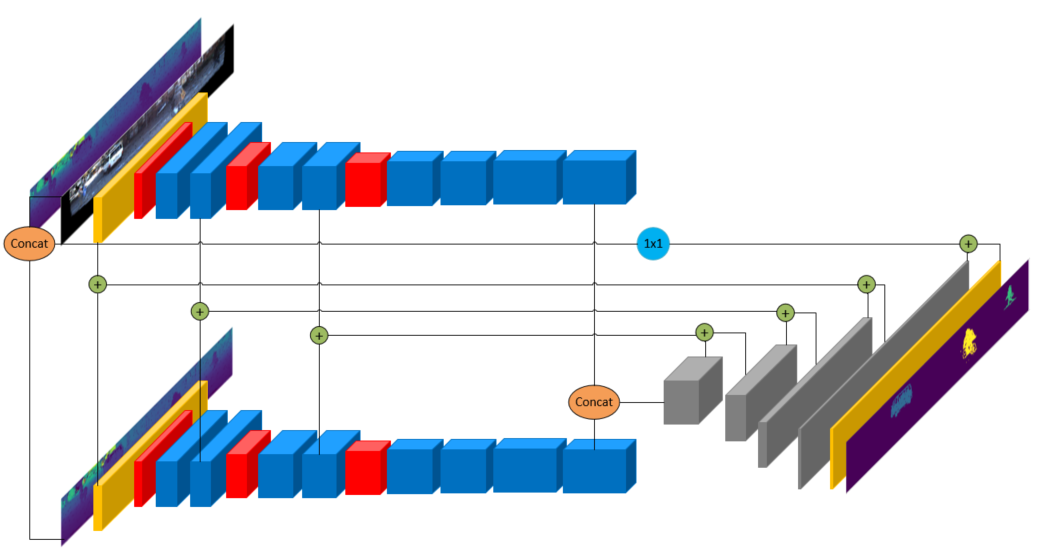
? (b) Proposed RGB+LiDAR mid-fusion architecture
C. Early-fusion architecture*
在框架中,我们的目标是融合输入数据的原始值,利用CNN进行联合特征提取这些输入数据。使用与基线网络架构中描述的方法相同,但本例中的输入张量由8个通道组成,这8个通道是原始的XYZDI,另外还有3个RGB层。这种体系结构的优点是,网络具有学习数据之间的关系并有效组合它们的潜力。然而,由于输入层的数量不同,这种体系结构不能直接利用大型单模态数据集(如ImageNet[3])的预训练。我们将这个体系结构称为XYZDIRGB,并且我们获得了比基线体系结构更好的结果,计算复杂度的增加可以忽略不计。
D. Mid-Fusion architecture
我们构建了一个中间融合架构,其中融合发生在CNN编码器特征级,如图4 (b)所示。在这种情况下,为每个输入模态构造了两个独立的编码器。对每个输入分别进行特征提取,然后使用连接层将处理后的特征图融合在一起。该模型比早期的融合模型计算更为复杂,因为编码参数的数量增加了一倍。但是,当从系统级别来看,单独的编码器可以在各自的模式中用于其他任务。与早期融合[17][16]相比,该模型具有更好的性能。我们将这种架构称为XYZDI + DIRGB。实验发现,这种结构不能有效地融合模式,在准确度上的增加微乎其微。我们构建了一个融合早期和融合中期的混合网络,将RGB通道连接到激光雷达的深度和强度通道。
使用这种方法,我们获得了对baseline的显著改进。
experiments
在这一节中,我们将详细介绍所使用的数据集和我们的实验设置。
A.dataset
我们使用KITTI原始[7]数据集,其中包含12919帧,其中选择10128帧作为训练数据,2791帧作为验证数据。我们选择这个数据集有多个原因。首先,它是基于自动驾驶场景的,这是我们工作的重点。此外,它还为多个类提供了3D边界框注释。在[22]之后,我们将我们的类分为三个组,即“汽车”,“行人”,“骑自行车的人”和“背景”。“汽车”类包括轿车、面包车和卡车。我们关注这些类别是因为它们对自动驾驶汽车来说具有主要的碰撞风险。用数据集提供的类对每个三维包围框内的点进行标注,可以作为三维语义分割的标注。我们利用[22]提供的数据分割,以便对其进行有效的比较。
B experimental setup
我们使用PGM数据表示水平前视场90?,创建一个64×512×nc的3D张量,其中nc表示输入通道的数量取决于手头的实验。在基线实验中,nc仅编码5个LiDAR数据,在early fusion中nc编码8个连接到LiDAR通道的RGB层。
在Mid-Fusion中,DIRGB分支为5,LiDAR分支为5。输出是一个64x512x1张量,表示每个极网格的分类。我们通过在y轴上随机翻转帧来使用数据扩充。在所有的实验中,我们将学习速率设置为0.01,优化器动量设置为0.9。联合上的类交叉(IoU)被用作性能度量,在所有类上计算一个平均IoU。我们的模型是使用TensorFlow库实现的。我们在1080 ti的GPU上运行我们的训练和推理。
C. Results
表I(上)显示了使用SqueezeSeg体系结构[22]对我们的方法进行的定量评估。XYZDI结果是通过使用KITTI-raw数据集对公开可用的网络[22]进行训练而得到的。
为了便于比较,这些结果可以作为我们实验的基准。XYZDIRGB的结果显示,与基线相比,性能增强,平均IoU绝对增加3%。XYZDI + DIRGB是我们提出的算法,其性能最好,平均IoU绝对增长3.7%。平均欠条的相对增幅约为10%。使用PointSeg[21]架构的结果报告在表I(下)。早期和中期融合显著优于仅使用激光雷达数据的结果。然而早期融合的结果优于中期融合的结果。这一结果与之前的SqueezeSeg实验和我们之前在融合架构[17]上的经验不一致。经过仔细的重复实验交叉验证结果,我们假设这可能是由于PointSeg网络中的非典型放大层与规则卷积层特征连接所致。
结果表明,非融合方法在推理小体积类时存在困难。我们认为有三个原因。第一个是不平衡数据集,特别是由[22]提供的建议分割,其中只有35%的行人类用于训练,65%用于测试。在自行车课程中,63%用于训练,37%用于测试。另一方面,Car类被分成78%用于训练,22%用于测试。
第二个原因是不平衡的类,其中Car类代表了96%的注释数据集,而Cyclist类只代表了1.4%的注释数据,而pedestrian类也代表了大约1.6%的注释数据。第三个原因是,与Car类相比,这两个类的实例数量较少,这最大限度地减少了特定于这些类的强大特性。我们相信这些原因在检测问题中发挥了重要作用。然而,无论是早期或中期的融合实验提供了增强性能的结果与激光雷达。在行人组中,早期和中期融合分别获得3.3%和5.8%。在骑行组中,两种融合方法的mIoU分别提高了2.3%和2.5%。使用PointSeg架构,我们获得了3%和2.8%的改进。
图5显示了使用SqueezeSeg体系结构获得的结果之间的定性比较。结果表明,我们的方法利用早期和中期融合改进了汽车、行人和骑自行车者的检测,如第二和第三列所示。在图5的第一和第二行中,未融合方法将骑行者分类为行人,早期融合的准确率更高,但头部部分分类不正确。在融合过程中,我们对骑行者进行了正确的分类,但是我们注意到骑行者的边缘出现了一些误报,我们认为这是由于卷积滤波器的平滑效果。
在第三排,早期融合和中期融合实现了汽车的最佳分类。
由于轻量级的架构,我们的算法的性能是实时的,每次扫描大约需要10毫秒。
早期融合所花费的执行时间与非融合方法几乎相同,而在两个架构中,中期融合所花费的时间要多3 ms。运行时详细信息列于表I的最后一列。
结论
在本文中,我们探讨了在利用激光雷达点云的基础上利用颜色信息进行自动驾驶3D semantic分割任务的问题。我们将RGB图像映射到激光雷达的极网格映射表示法,并构建了早期和中期的融合架构。
我们在KITTI数据集上给出了实验结果,并对目前最先进的两种算法SqueezeSeg和PointSeg在两种情况下都进行了10%的改进。在未来的工作中,我们计划利用网络架构搜索技术探索更复杂的融合架构,并利用所有可用的颜色像素。