-
��������Ҫ����:
Fluid:�������ִ������
Program:���û���˵һ�������ij���
Executor:ִ����,ִ�г���
����:
����(Tensor):��ά���������,ͬ�����������ѧϰ���һ��,PaddlePaddleʹ����������������
Layer:
��ʾһ�������ļ�����,ͨ������һ������operator(����),��layers.relu��ʾReLU����;layers.pool2d��ʾpool������Layer����������ΪVariable��
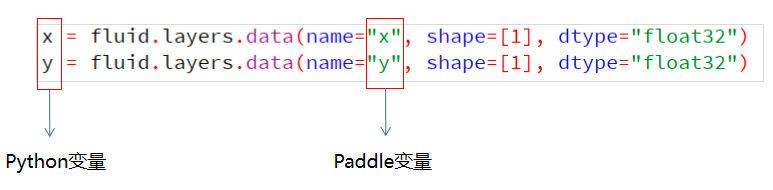
Variable:
��ʾһ������,������һ������(Tensor),Ҳ�������������͡�Variable����Layer����,Ȼ��Layer����Variable������������ʽ:
program:
Program����Variable����Ķ��������Layer����Ķ������,��һ�������ļ����������û��Ƕ�����,Program��˳������ִ�еġ�
Executor:
Executor�������ղ�ִ��Program,��һ��ִ��Program�ж�������м��㡣ͨ��feed���������,ͨ��fetch_list����ȡִ�н����

place:
PaddlePaddle����������lntel CPU,Nvidia GPU,ARM CPU����Ƕ��ʽ�豸��,����ͨ��Place����ָ��ִ�е��豸(CPU��GPU)��

optimizer:
�Ż���,�����Ż�����,һ����������ʧ�������ݶ��½��Ż�,�Ӷ������С��ʧֵ
�����ִ�й���:
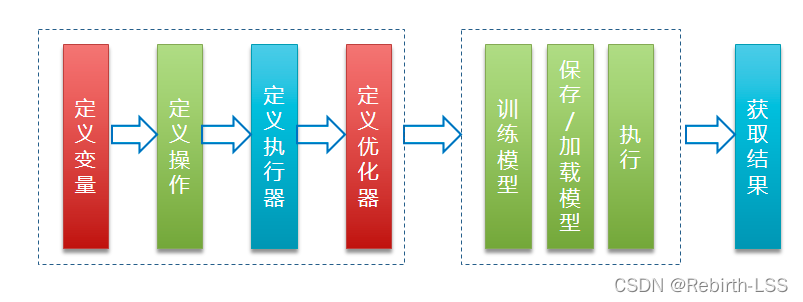
������
ʲô��������:
��������ָ���������ݴ��ⲿ(��Ҫָ�ļ�)����,���Ұ���һ
����ʽ(���������)���ݸ�������,����ѵ������ԵĹ���������������������:
��һ��:�Զ���Reader����ѵ��/Ԥ������
�ڶ���:�����������ж������ݲ����
������:�����������������ѵ��/Ԥ��
#�Զ�����ļ���ȡ,��pythonװ����
import numpy
import paddle
def reader_creator(file_path):
def reader():
with open(file_path, "r") as f:
lines = f.readlines()
for line in lines:
yield line.replace("\n","")
return reader
reader = reader_creator("test.txt")#ԭʼ˳��Ķ�ȡ��
shuffle_reader = paddle.reader.shuffle(reader,10)#10�ǻ������Ĵ�С,�����ȡ��
batch_reader = paddle.batch(shuffle_reader,3)#������ζ�ȡ��
# for data in reader():
# for data in shuffle_reader():
for data in batch_reader():
print(data, end="")
ģ�͵ļ����뱣��
Ԥ��ģ�͵ļ����뱣��:
����Ԥ��ģ��:
fluid.io.save_inference_model(dirname, feeded_var_names, target_vars, executor)
����˵��:
dirname(str):����Ԥ��model��·��
feeded_var_names(list[str]):Ԥ����Ҫfeed������
target_vars(list[Variable])�U����Ԥ������Variables
executor(Executor): executor����inference model
����Ԥ��ģ��:
fluid.io.load_inference_model(dirname, executor)
����˵��:
dirname (str)һ����Ԥ��model��·��
executor(Executor)-����ģ�͵�Executor
����ֵ˵��:
Program :����Ԥ���Program
feed_target_names(str�б�)�UԤ��Program���ṩ���ݵı���������fetch_targets(Variable�б�)�U���Ԥ����
����ģ�͵ı��������:
��������ģ��:
fluid.io.save_persistables(executor, dirname, main_program=None)
����˵��:
executor (Executor):���������executor
dirname (str):����ģ�͵�·��
main_program (ProgramNone):��Ҫ���������Program�����ΪNone,��ʹ��default_main_Program
��������ģ��:
fluid.io.load_persistables(executor, dirname, main_program=None)
����˵��:
executor (Executor): ���ر�����executor
dirname(str):��������ģ�͵�·��
main_ program (ProgramNone):��Ҫ���ر����� Program�����ΪNone,��ʹ��default_main_Program
fluid API�ṹͼ:
