ԭ������:https://arxiv.org/pdf/2008.08294.pdf
Abstract
TNT��Ϊ3��stage:
- Ԥ��agentδ���ĵ�target point
- ����ָ����Щtarget point��trajectory
- ����Щtrajectory���,ѡ�����ʸߵ�
�������������һ����ģ̬��Ԥ��(��ֱ��,��ת,��ת,��ͬ����ɶ��)��
Introduction
TNT��Ҫ��Ϊ�˽��agent��δ���켣Ԥ��(֧�ֶ�ģ̬)��
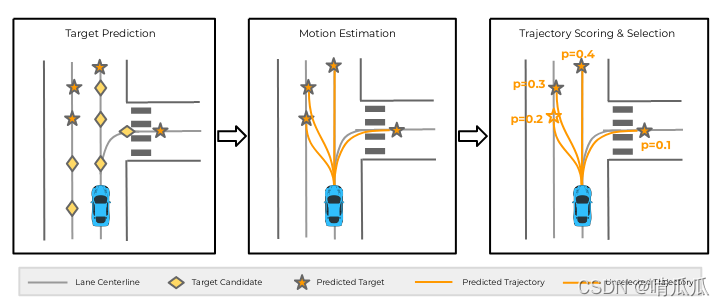
- target prediction:ʹ�ó���ͼԤ����targets�ķֲ�
- target-conditioned motion estimation:Ԥ���˶���ÿһ��target��ʱ������
- scoring and selection:�ۺϿ������й켣��,������ÿһ���켣��likelihood��ѡ�����ʸߵĹ켣�����
Formulation
��ʷT֡��agent��states:
s
P
=
[
s
?
T
��
+
1
,
s
?
T
��
+
2
,
.
.
.
,
s
0
]
s_P=[s_{-T'+1}, s_{-T'+2},...,s_0]
sP?=[s?T��+1?,s?T��+2?,...,s0?]
δ��T֡��agent��states:
s
F
=
[
s
1
,
s
2
,
.
.
.
,
s
T
]
s_F=[s_1,s_2,...,s_T]
sF?=[s1?,s2?,...,sT?]
��ʷT֡�Ļ�������(�������agents�ͳ���Ԫ��):
c
P
=
[
c
?
T
��
+
1
,
c
?
T
��
+
2
,
.
.
.
,
c
0
]
c_P=[c_{-T'+1},c_{-T'+2},...,c_0]
cP?=[c?T��+1?,c?T��+2?,...,c0?]
������
x
=
(
s
P
,
c
P
)
x=(s_P,c_P)
x=(sP?,cP?)����ʾ��ʷ�����б���,��ô������ʷ���δ��Ԥ��ĸ��ʷֲ�Ϊ
p
(
s
F
�O
x
)
p(s_F|x)
p(sF?�Ox).
��
��
(
c
P
)
\tau(c_P)
��(cP?)��ʾ����
c
P
c_P
cP?��õĴ�ŵ�target�ռ�,��
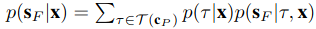
�ܵ�����,��һ��target prediction������
p
(
��
�O
x
)
p(\tau|x)
p(���Ox),��������ʷ��Ϣ���target���ڶ���target-conditioned motion estimation������ʷ��Ϣ��target������δ�����˶�״̬����������������ʵ�ģ�͡����һ��scoring and selection��ѧϰ�˴�ֵĺ���
?
(
s
F
)
\phi(s_F)
?(sF?),��Ԥ��Ĺ켣���д��.
Target-driveN Trajectory Prediction
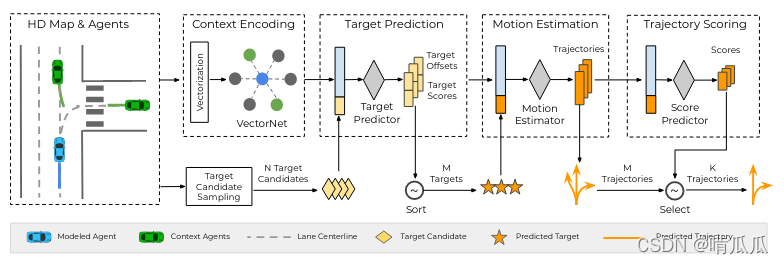
Overview:ģ��������encode���ij���,Ȼ��������,Ԥ��M��target,��ÿ��targetԤ��켣,��ֺ�ѡȡ������ߵ�K���켣��
����target��states,���Ǿ�ʹ�ö�ά������������ʾ
(
x
t
,
y
t
)
.
(x_t,y_t).
(xt?,yt?).
Scene context encoding
����и߾���ͼ�Ļ�,ʹ��VectorNet��encode,����ʹ��polyline��ʾlanes,agent��trajectory,����Ϊ
c
P
c_P
cP?��
s
P
s_P
sP?. ���������Ƕ���ÿ��agent��feature
x
x
x.
���û�и߾���ͼ,ʹ��ConvNet������Ҳ���ԡ�
Target prediction
������N��target��������N��target,���Ƕ�ҪԤ��һ��offset��
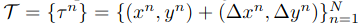
����target�ķֲ�Ϊ:
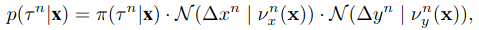
����
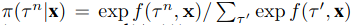
������softmax�е��㷨,f��õ�������target�е�����һ���ķ���,Ϊ�˻��ÿһ��target������target�еĸ���,������
��
\pi
��.
N ( . �O v ( . ) ) N(.|v(.)) N(.�Ov(.))��һ����̬�ֲ�,v��ƽ��ֵ,unit variance��������ƽ��ֵ�͵�λ����,offset��һ����̬�ֲ������������mean��distance���õ���Huber(����0�Ķ��κ���,Զ��һ�κ���)��
�������f��v���ǿ�ѧ��,����2��MLP�Ľ�������붼�Ǵ�ŵ�Ŀ��� ( x k , y k ) (x^k,y^k) (xk,yk)�ͳ�����feature x x x.
Loss��������
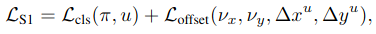
���з�Ϊ��ͬtarget��cross entropy loss��offset��Huber loss��
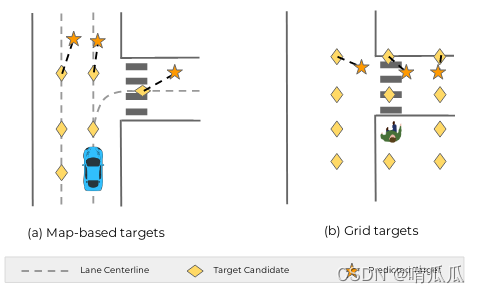
����car��˵,target candidate�Ǵ�lane�ϵȼ����sample�ġ�����pedestrian,����������ȡ�㡣��Ӧͼ�е����Ρ�
Ȼ��Ԥ�����
(
��
,
��
x
,
��
y
)
(\pi, \Delta x,\Delta y)
(��,��x,��y),��ÿ��target�ĸ��ʺ�offset����Ӧͼ�е�����ǡ�
ʵ����,���IJ����˷dz����target candidate����,N=1000,����ģ�ͺ�ӵ���ѡ����M=50����߸��ʵĽ����
Target-conditioned motion estimation
��һ��ҪԤ��δ����states�����δ����states��likelihood���Ա�ʾΪ
p
(
s
F
�O
��
,
x
)
=
��
t
=
1
T
(
p
(
s
t
�O
��
,
x
)
)
p(s_F|\tau,x)=\Pi_{t=1}^T(p(s_t|\tau,x))
p(sF?�O��,x)=��t=1T?(p(st?�O��,x))
�����ʽ�ij�����������������
- ÿһ��time step���Ƕ�����,����Դ������������ٶȡ��кܶ����Ķ���ô����
- ����target���Ԥ���ǵ�ģ̬�ġ��������Ϊ���ǵ�Ԥ����һ���Ƚ϶̵�ʱ��T�ڡ�
ʹ������MLP,�ѳ���feature
x
x
x��target
��
\tau
����Ϊ����,���һ��������ߵ�δ���켣
[
s
^
1
,
.
.
.
,
s
^
T
]
[\hat{s}_1,...,\hat{s}_T]
[s^1?,...,s^T?].�˴���ȡ��teacher forcing�ļ���(��RNN��,һ��ѵ�������ǰ���һ�������state��Ϊ��һ��������,�Դ����ơ���teacher forcing����ÿ���������ground truth)��ѵ����ʱ��ÿһ�������target���õ���ground truth������һ���ó��Ľ����
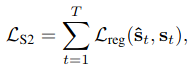
Loss��ÿһ��ʱ�̵�ground truth��Ԥ�����ľ���(Huber loss)֮�͡�
Trajectory scoring and selection
��һ���Ƕ���һ����Ԥ��Ĺ켣���д�֡�����
g
(
.
)
g(.)
g(.)��һ��2���MLP��
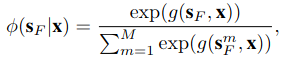
Loss�ļ����ȡ��Ԥ�������ground truth�����Ľ����ء�
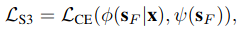
ÿһ��Ԥ��Ĺ켣��ground truth�ķ���������ground truth�ľ���������ġ�
��
(
s
F
)
=
e
x
p
(
?
D
(
s
,
s
G
T
)
/
��
)
��
s
��
e
x
p
(
?
D
(
s
��
,
S
G
T
)
/
��
)
\psi(s_F)=\frac{exp(-D(s,s_{GT})/\alpha)}{\sum_{s'}exp(-D(s',S_{GT})/\alpha)}
��(sF?)=��s��?exp(?D(s��,SGT?)/��)exp(?D(s,sGT?)/��)?
ֱ���ϵĻ����Ƕ��ڶ��ģ̬��Ԥ����,�ֱ����ÿһ����gt(gtֻ��һ��ģ̬)�ľ���,����Щ���������(����softmax�ķ���)�����о���ļ����������켣��ͬʱ�̵���������롣
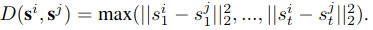
Ϊ�˱���̫���ӽ������,����NMS���Ƶ��������ȸ��ݷ�������,�Ӹߵ��ͷ���ѡ�еĹ켣,���̫�ӽ��Ѿ�ѡ�����Ĺ켣��
Training and inference details
����һ���˶�ѵ����ģ��,loss��������loss�ĺ͡�
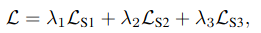
��inference�еIJ���Ϊ:
- ����encode
- ���ݵ�ͼ�ҳ�N��target candidate��Ϊ����,������ �� ( �� �O x ) \pi(\tau|x) ��(���Ox)ѡ��������ߵ�M��target
- Ԥ����M��target�Ĺ켣,��� p ( s F �O �� , x ) p(s_F|\tau,x) p(sF?�O��,x)
- ����M���켣��� ? ( s F �O �� , x ) \phi(s_F|\tau,x) ?(sF?�O��,x),ѡ�����ʸߵ�K���켣
Metrics
Average Displacement Error (ADE):�켣��ÿ�����gt��ÿ����ľ����ƽ��
Final Displacement Error (FDE):target�ľ���
Miss rate (MR):����target����gt��target��2m���ϵı���