ǰ����˵��,seq2seq model�����ֳ�����,һ����encoder,,����һ����decoder����inputһ��sequence,��encoder�������sequence,�ٰѴ����õ�sequence����decoder,��decoder������Ҫ���ʲô����sequence����ǰ��� Why transformer(һ)����,��������ϸ������transformer encoder�ļܹ���������,��������һ��transformer decoder�����������ġ�

����decoder
��decoder����ʵ������,һ����Autoregressive��decoder,��һ����Non-Autoregressive��decoder�����dz��õ���Autoregressive��decoder�������Autoregressive��decoder����ô��������?������������ʶ������������˵����
������ʶ������������?�ᵽ������ʶ,��������һ���������һ�����֡�������һ�����������encoder,�����һ��vector�������� Why transformer(һ)����ϸ�ᵽencoder������������,����Ͳ��ن����ˡ��ǽ������ؾ��ֵ�decoder������,decoderҪ����������Dz������,��decoder����������ʶ�Ľ������decoder��ô�������������ʶ�Ľ����?decoderҪ������������Ȱ�encoder���������ȥ,������ô����ȥ,��������ڽ�������д����

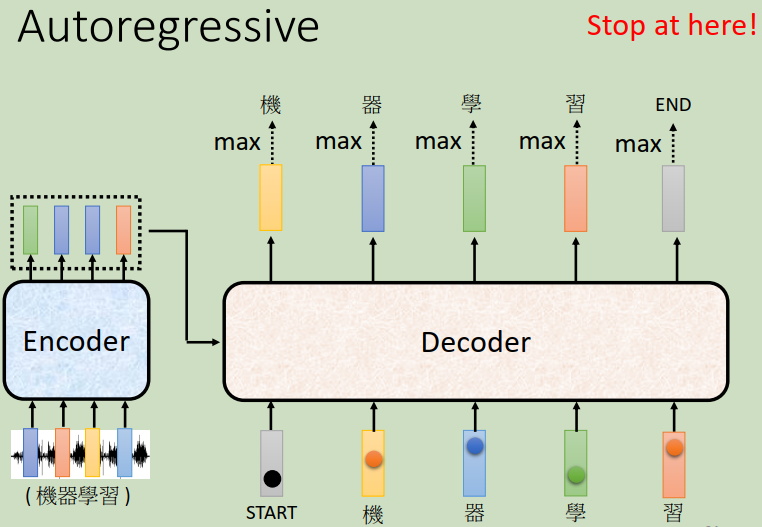
�����ȼ���encoder���������ij�ַ�������decoder,�ⲽ���ǵ����ڴ�������decoder��ô��������ʶ�в���һ��������?����������Ҫ�ȸ�decoderһ������ķ���,�������ķ��Ŵ�������ʼ(beginning)��?��beginning��Ҳ����one-hot vactor����ʾ:����һά��1,������0���ڳԽ�ȥ"beginning"֮��,decoder���³�һ������,�����vector������ʲô��?���vector�ij��ȸ����vocabulary��size��һ���ġ�vocabularyָ����ʲô��˼��?�����������decoder����ĵ�λ��ʲô�����仰˵,��������������������ĵ�������ʶ,���ǵ�decoder�����������,�����vocabulary��size�������ĵķ����ֵ���Ŀ����Ҫ�����decoder�����Щ���ܵķ�����,��Ͱ���������ߡ�
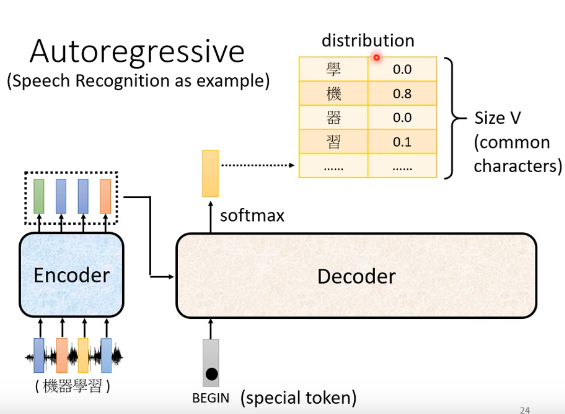
??��������֪��,��decoder�Խ�ȥ"beginning"֮��,decoder�³����������Ⱦ���ϣ��������������ֵ���Ŀ��һ�����ġ���decoder�³�������������������յ�������,ֻ�з�����ߵķ����ֲ������յ���������
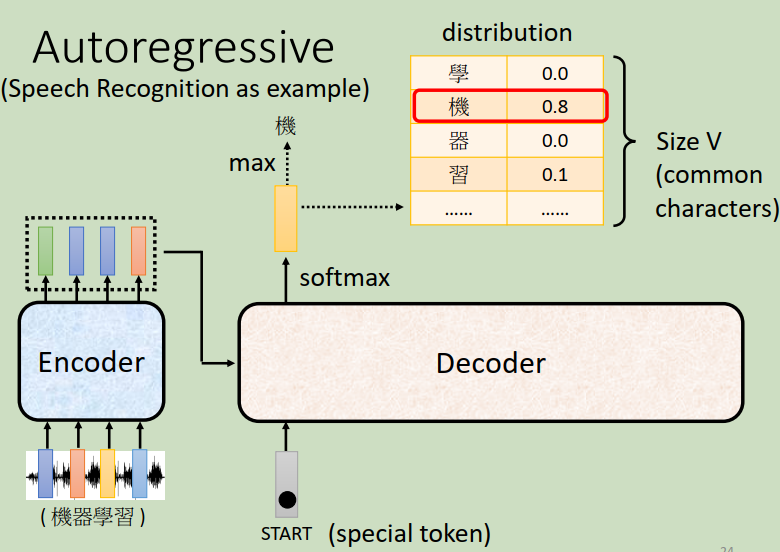
��ͼ�С������ֵķ������,�������������?���ǽ�����,��ѡ���������decoder�µ�input��ԭ��decoder��inputֻ�С�beginning������ر�ķ���,���ڳ��ˡ�beginning������С�������Ϊ����input���ǡ�������Ҳ�DZ�ʾΪһ��one-hot��vector������������������decoder��Ҫ�ó�һ�����,���һ����ɫ������(����ͼ),����softmax���ǿ������յõ������ɫ����������ǡ��������ǽ�����decoder���á�������������input,����decoder�����ˡ�beginning��,�����ˡ�����,�����ˡ�����,�ǽ������Ϳ��������ѧ��...������̾ͷ����ij�����ȥ��decoder�����ѧ���Ժ�,��ѧ�����ٱ�����decoder����,����decoder��������beginning��,�����ˡ�����,�����ˡ�����,�����ˡ�ѧ��(��encoder���Ҳ��������,ֻ�����ǵȻ���д),���������ϰ��
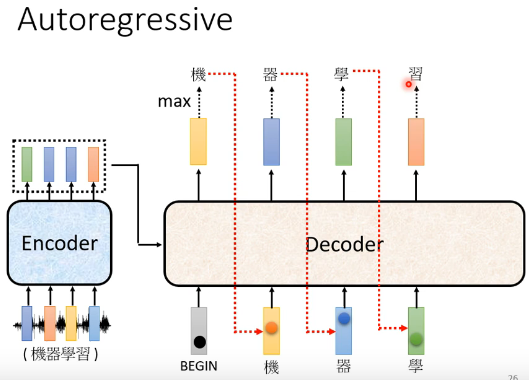
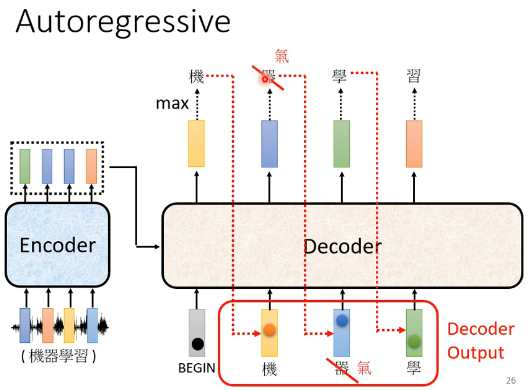
�����һ���ؼ��ĵط����������ú�ɫ�����߸��������,Ҳ����˵decoder������������ʵ������ǰһ��ʱ������������仰˵,decoder����Լ���������������������롣���Ե�decoder�ڲ���һ�����ӵ�ʱ��,����ʵ�п��ܿ�������Ķ���,��Ϊ���ǿ����Լ�ǰһ��������?����˵decoder�ѻ����ġ�������ʶ���������ġ�����,�ǽ�����decoder�ͻῴ������ı�ʶ���,��decoder���ǻ���ݴ���ı�ʶ���������һ����ȷ�����,����˵��ѧ������decoder��ᷢ����һ�����������������ʹ�������Ӷ��������?������һ�����,��˵��װ�����ȡ�
�ǽ�����,��������һ��decoder�ڲ��Ľṹ��ʲô���ӡ���transformer����,decoder�dz�������ӵ�
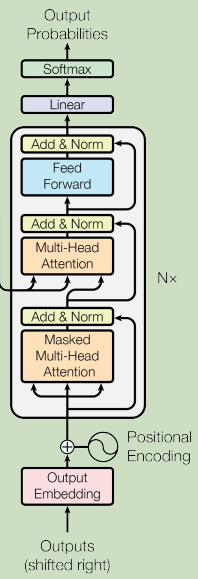
decoder��������encoder��Ҫ����һ�� �������ǰ�encoder��decoder����һ��,���Ƚ�һ������֮��IJ��졣

���ǿ��Է���,�����decoder�м���һ���ָ�����(����ͼ��ʾ),��ʵ��û����ô��IJ��ֻ������decoder������ǻ�����һ��softmax,ʹ��decoder�������Ϊһ��probabilities��
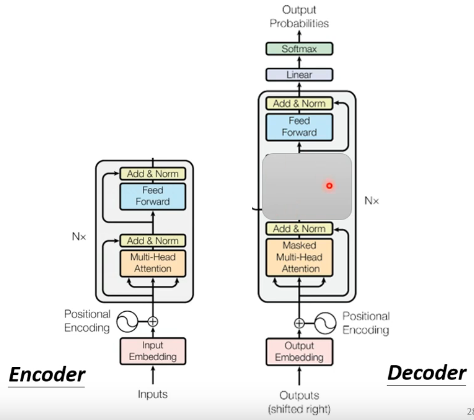
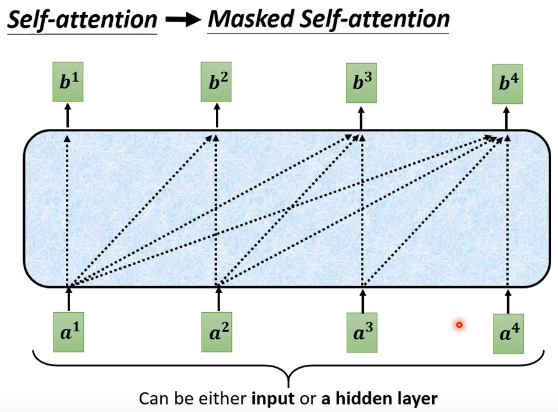
���˱��ڵ������IJ�����,��decoder�����һ����encoder��һ����:��Multi-Head Attention���滹����һ��Masked�����Masked��ʲô��˼��??���Masked��˼��������:�����ع�һ��֮ǰ����self-attention,����˵���b1��ʱ��,��ʵ�Ǹ���a1~a4���е���Ѷȥ���b1�������ǰ�self-attentionת��Masked self-attention��ʱ��,��ͬ����������?���IJ�ͬ����:�������ܿ����ұߵIJ�����Ҳ���Dz���b1��ʱ������ֻ�ܿ���a1����Ѷ,�����ٿ���a2~a4����Ѷ;����b2��ʱ��ֻ�ܿ���a1,a2����Ѷ,�����ٿ���a3,a4����Ѷ;����b3��ʱ��ֻ�ܿ���a1~a3����Ѷ,�����ܿ���a4����Ѷ;����b4��ʱ�������������sequence����Ѷ���������Masked self-attention
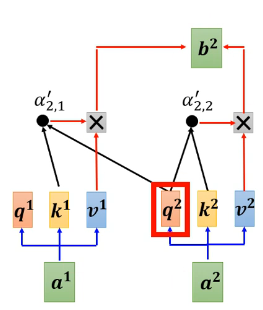
������һ��,?Masked self-attention��������������:����Ҫ����b2��ʱ��,����ֻ��a2��q��a1��k�Լ�������k��attention score,��ȥ��a2�ұߵĵط�,��:,
;Ȼ���ٷֱ����
,
�ͼ������õ�b2��
��Ȼ��Ȼ��,ΪʲôҪ��Masked��? ���������ʵ�dz���ֱ���������뿴����decoderһ��ʼ��������ʽ,���������һ��һ��������,����������a1,����a2,����a3,����a4��������ǵ�self-attention��һ��,ԭ����self-attention��һ������������model�����,encoder��һ��������a1~a4������ȥ�����Ƕ�decoder����,����a1,����a2,����a3,����a4������ʵ���ϵ�����a2����b2��ʱ��,����û��a3,a4��,�����������û�취��a3��a4���ǽ���,���Ծ���Ϊʲô��transformer���ĵ�ͼ�����ر�ǿ��˵�ⲻ��һ��һ���attention,����Masked self-attention,��˼�����������˵,decoder�������һ��һ��������,������ֻ�ܿ�������ߵĶ���,��û�취�������ұߵĶ���
������,������һ���ؼ������û���ἰ,�Ǿ���decoder�����Լ��������sequence�ij���,���仰˵,decoder����ѧ���Լ��Ͼ�,����û�а취�������sequence�ij�������֪�����sequence�ij����Ƕ���,������˵�������ĸ�����,�����һ�����ĸ�����,decoderҪѧ���Լ�ͣ����������˵�����ꡱϰ���Ժ�,decoder�����ֻ��������������,����������һֱ����������ȥ,������ϣ��decoder�ڲ�����ϰ��֮���ͣ������ ����ô��decoderͣ������?����Ҫ����������ʵ����Ҫ��decoder���һ���������������ǡ�������Ҫ�ر���һ������,������žͽ�����END��

�������ڴ�˵��decoder�����ꡰϰ��,�ٰѡ�ϰ������decoder�������Ժ�,decoder��Ҫ�ܹ������END����Ҳ����˵���ѡ�ϰ�����������Ժ�,decoder������encoder�����embedding,�����ˡ�beginning��,�����ˡ�����,�����ˡ�����,�����ˡ�ѧ��,�����ˡ�ϰ��,decoder��Ҫ֪�����������ʶ�Ľ���Ѿ�������,����Ҫ�ٲ�������Ĵʻ���,��������������������,�����END����probabilities����Ҫ������,Ȼ��������END���������,����decoder����sequence�Ĺ��̾ͽ�����������������Autoregressive��decoder�����ķ�ʽ��
��,�ǽ�����,���Ǿ�Ҫ�ش�encoder��decoder֮������ô������Ѷ����
����...