

- https://rishabhmisra.gihub.io/publications/
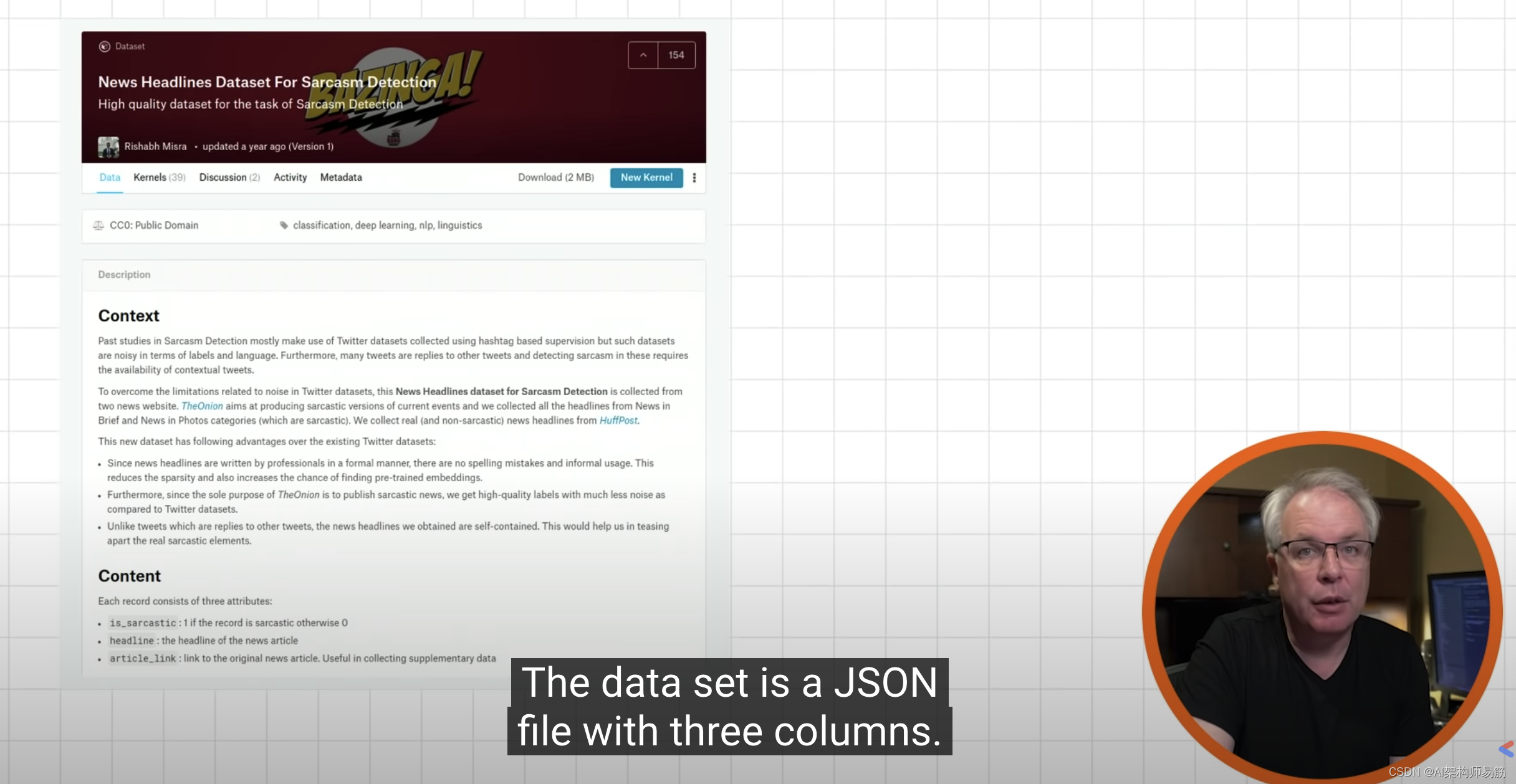
- ЖўЮЌТыЕФСДНг https://www.kaggle.com/rmisra/news-headlines-dataset-for-sarcasm-detection



СЗЯА1
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/sarcasm.json \
-O /tmp/sarcasm.json
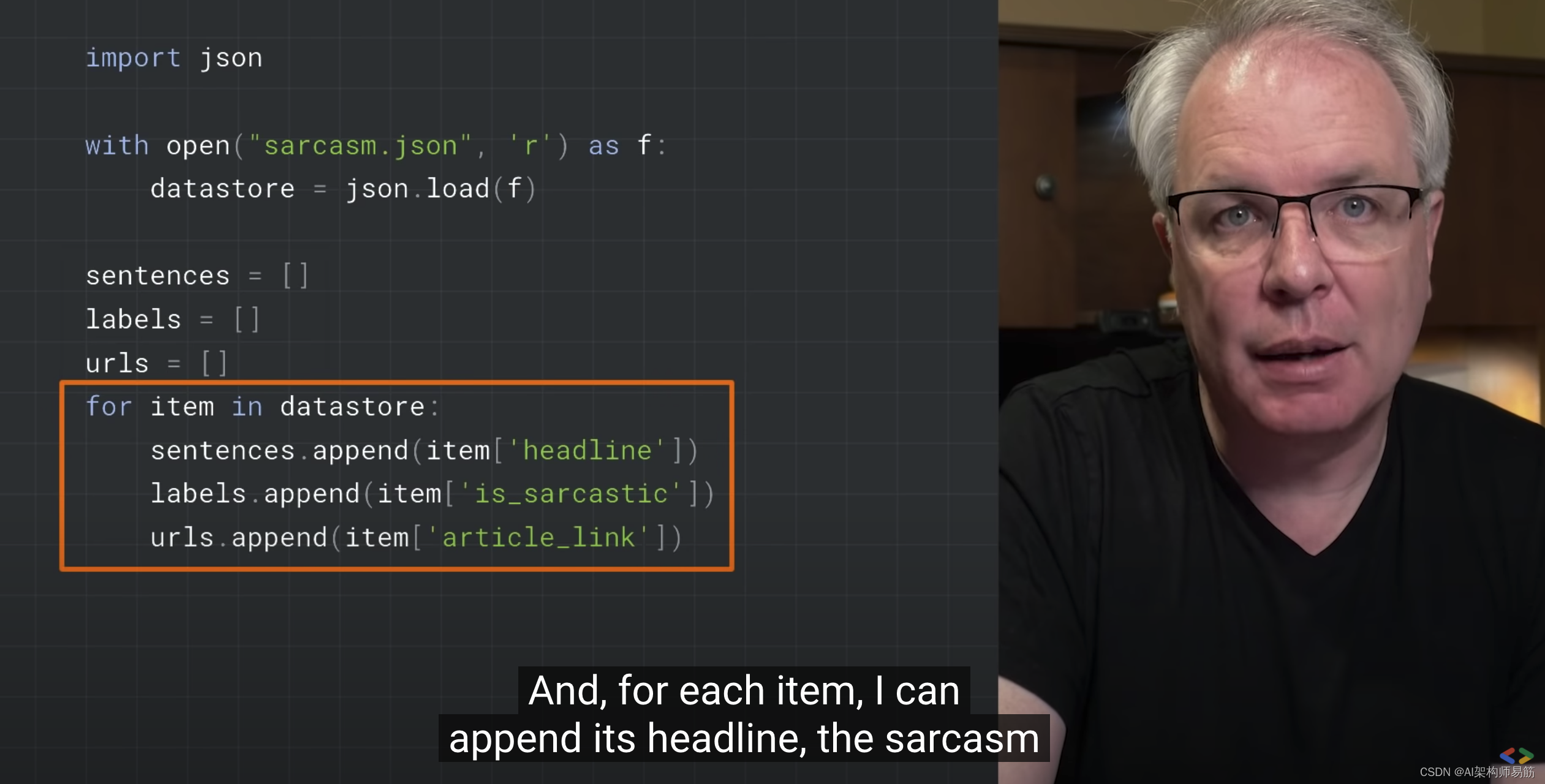
import json
with open("/tmp/sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
urls = []
for item in datastore:
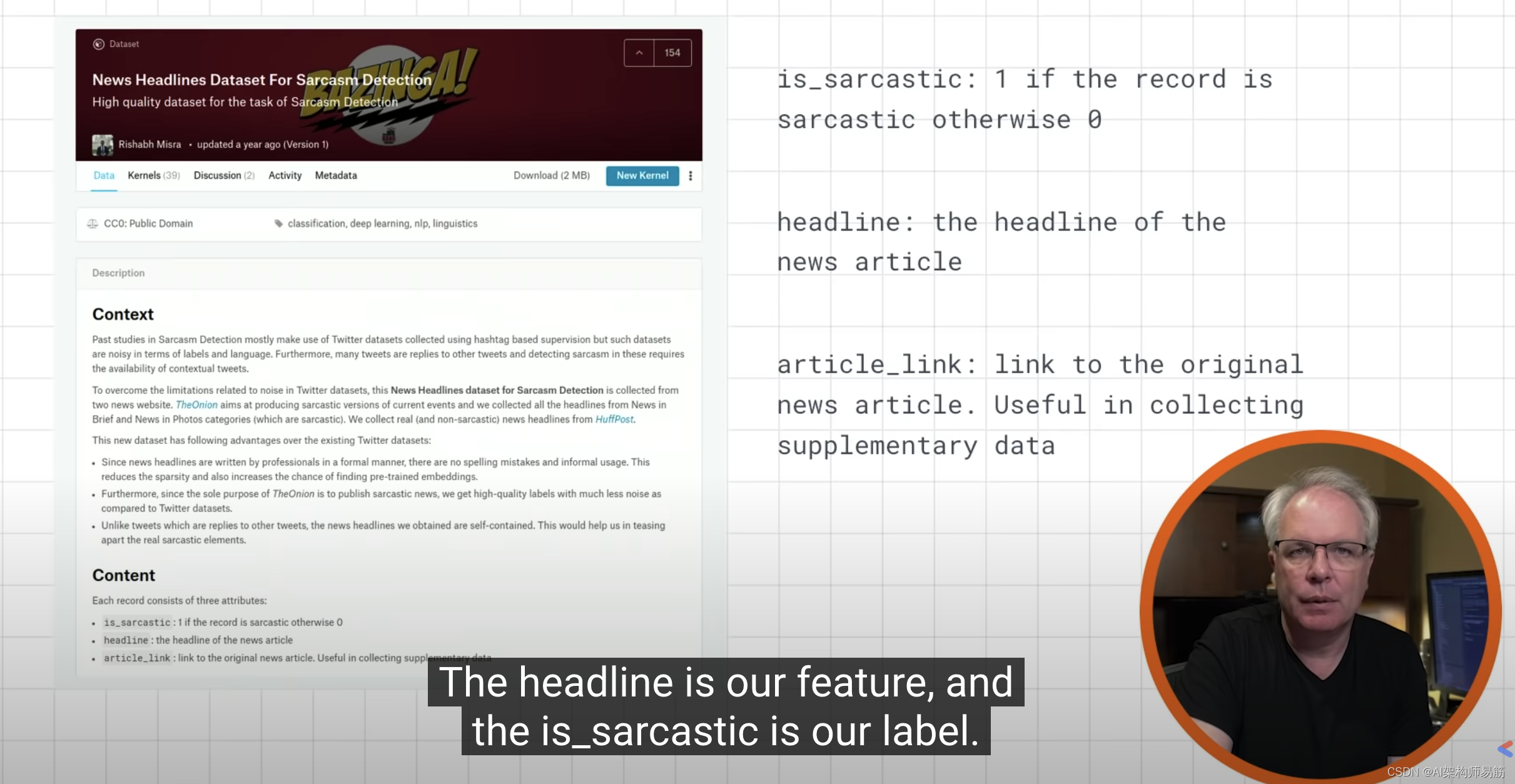
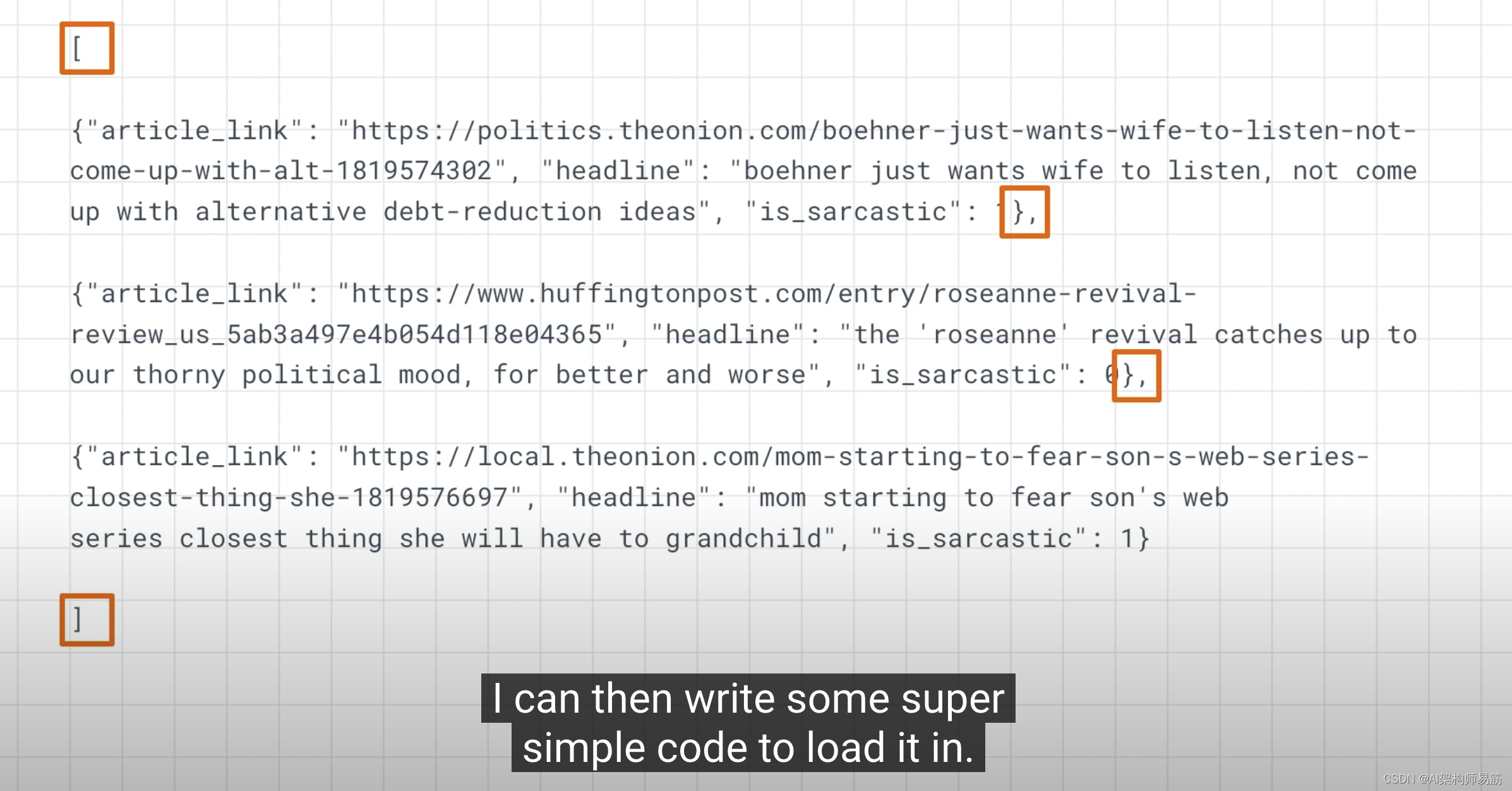
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(len(word_index))
print(word_index)
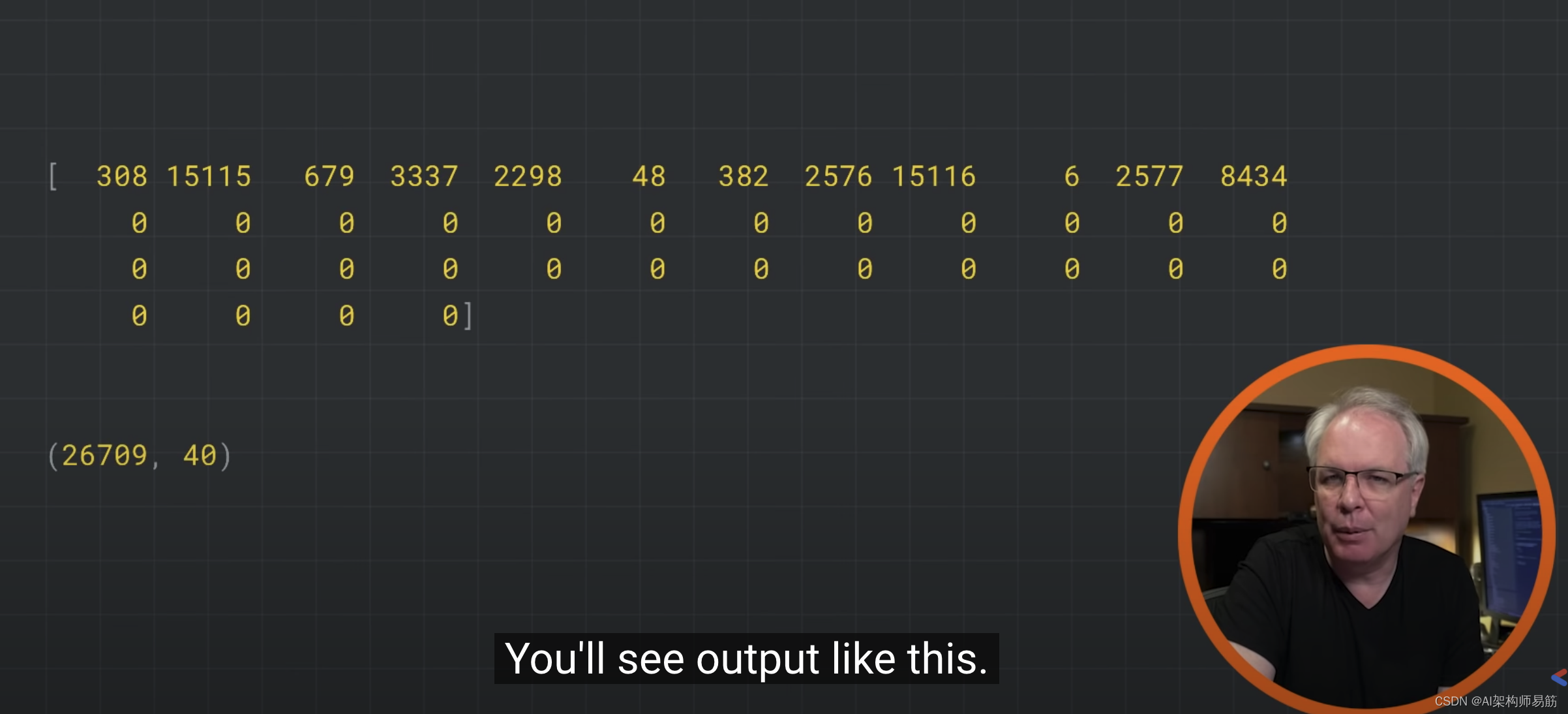
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape)

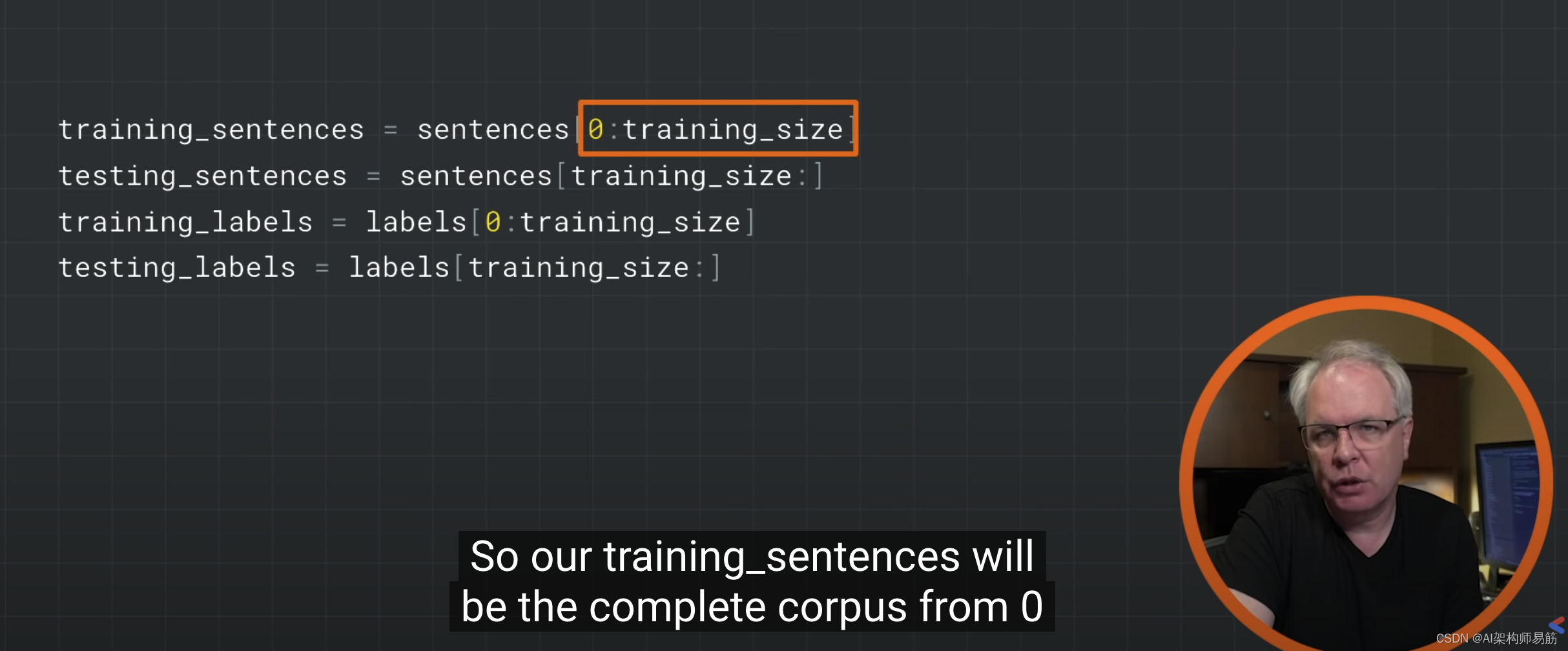
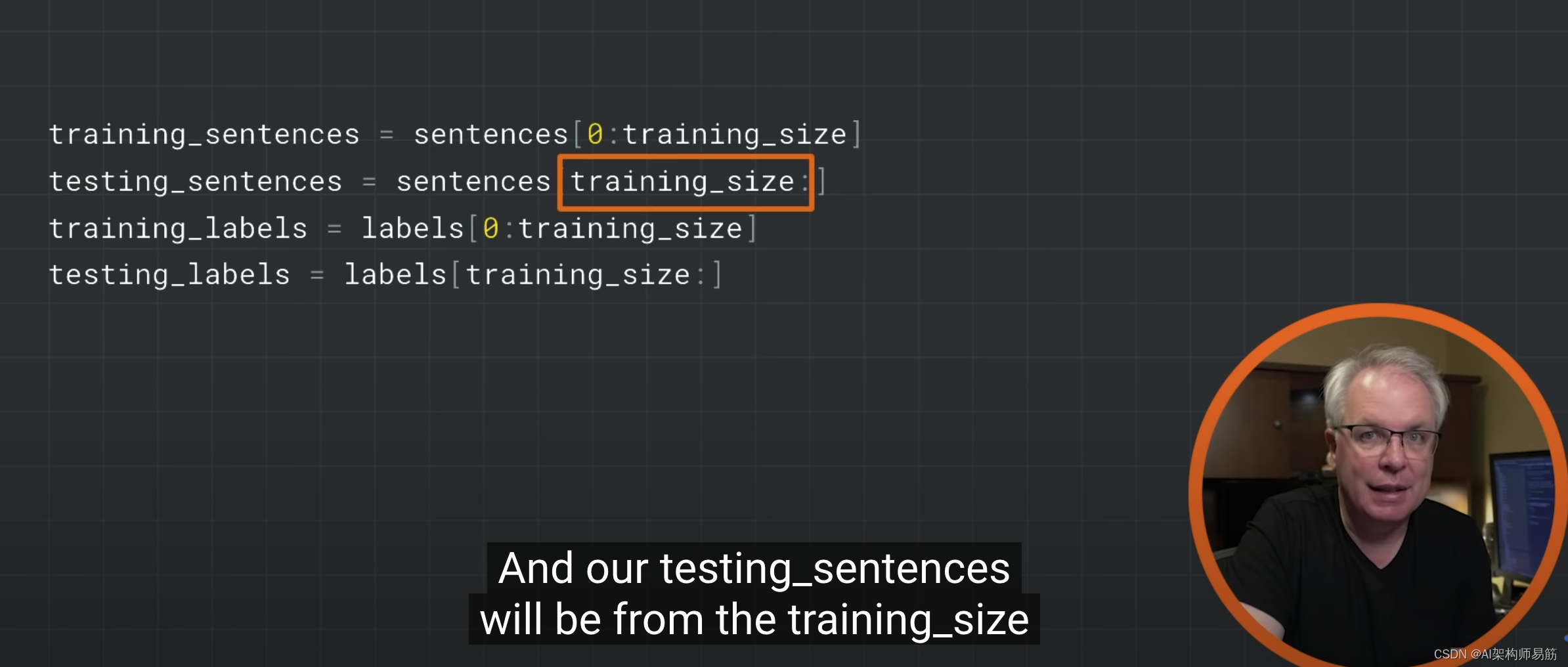

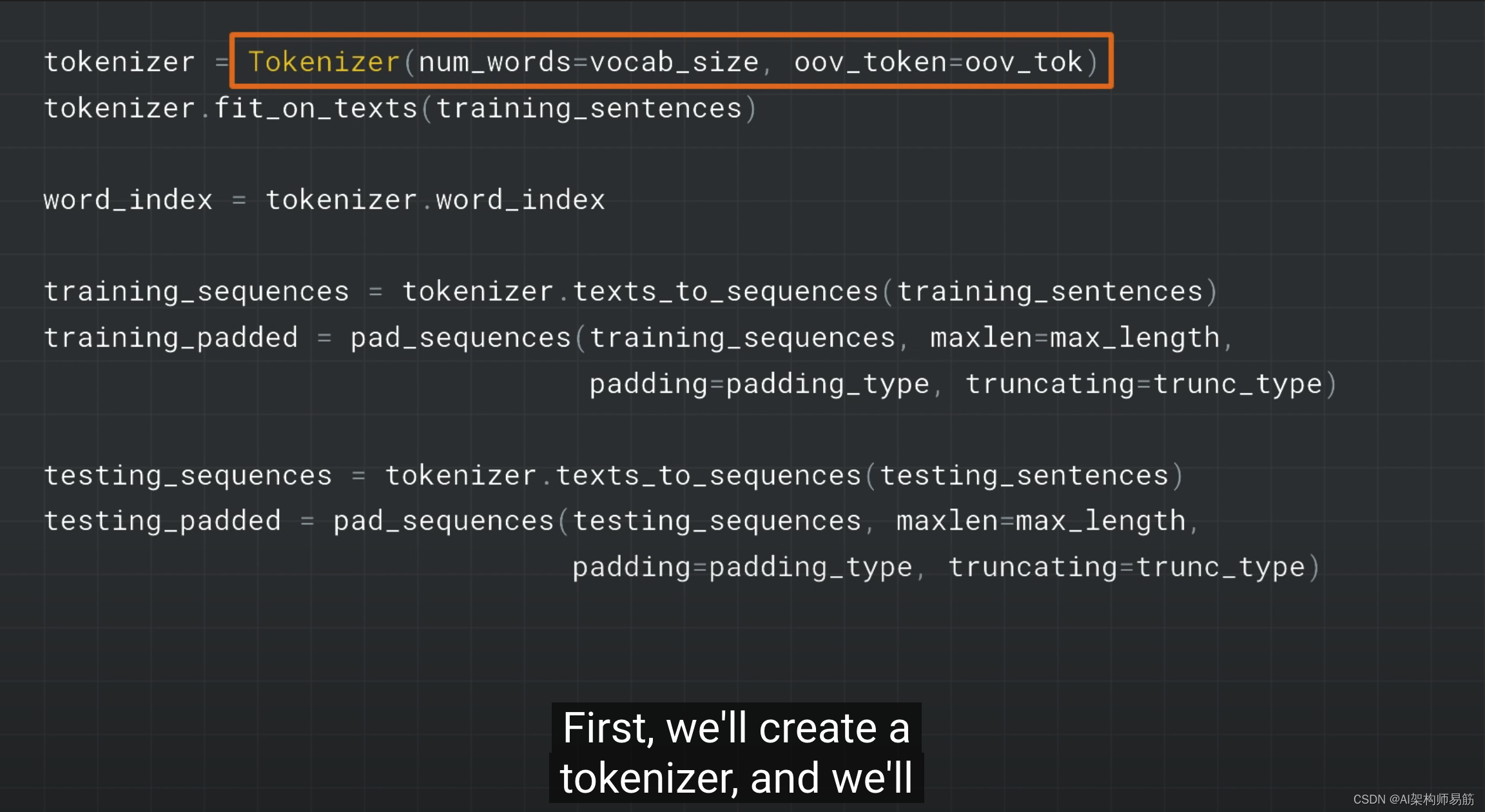








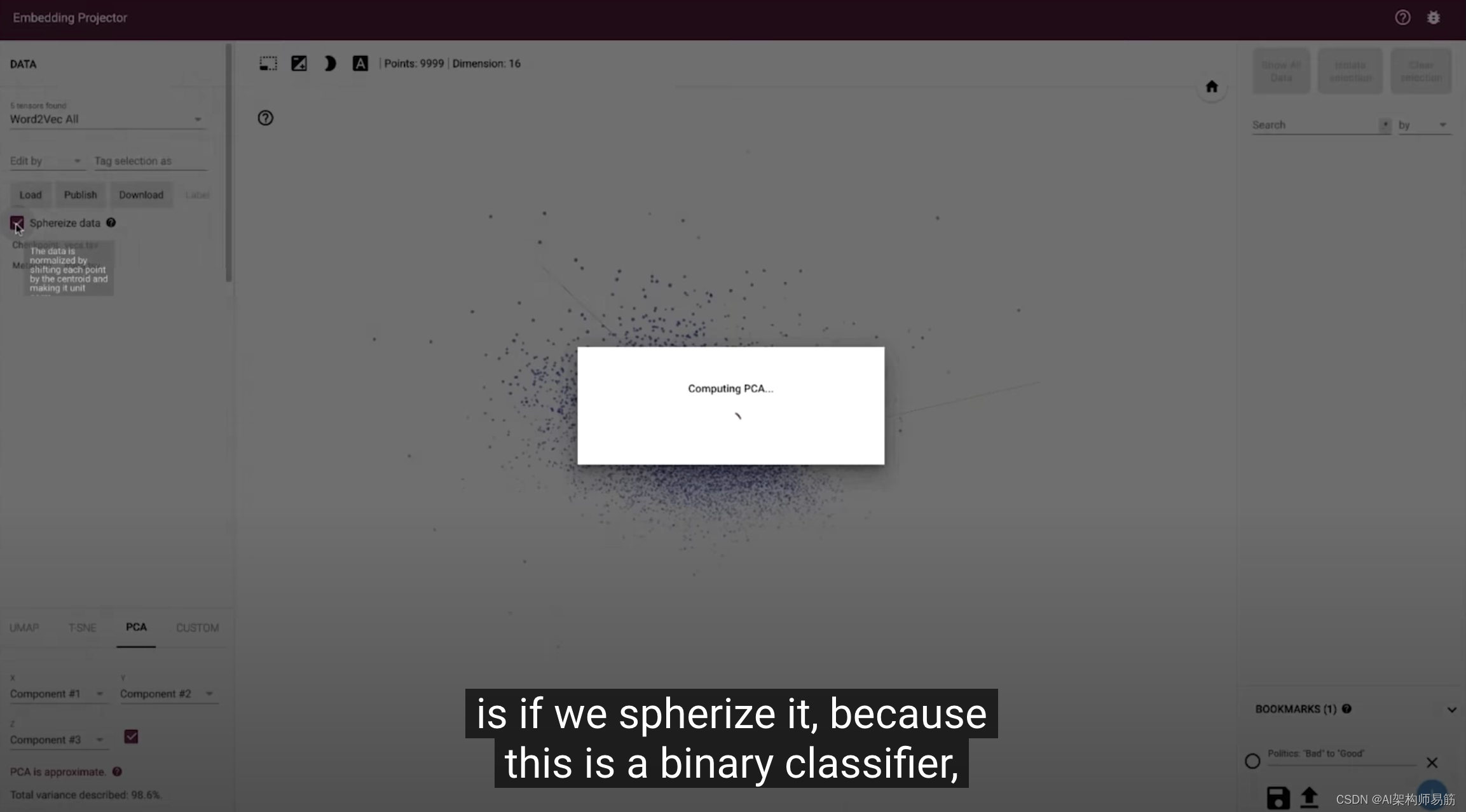
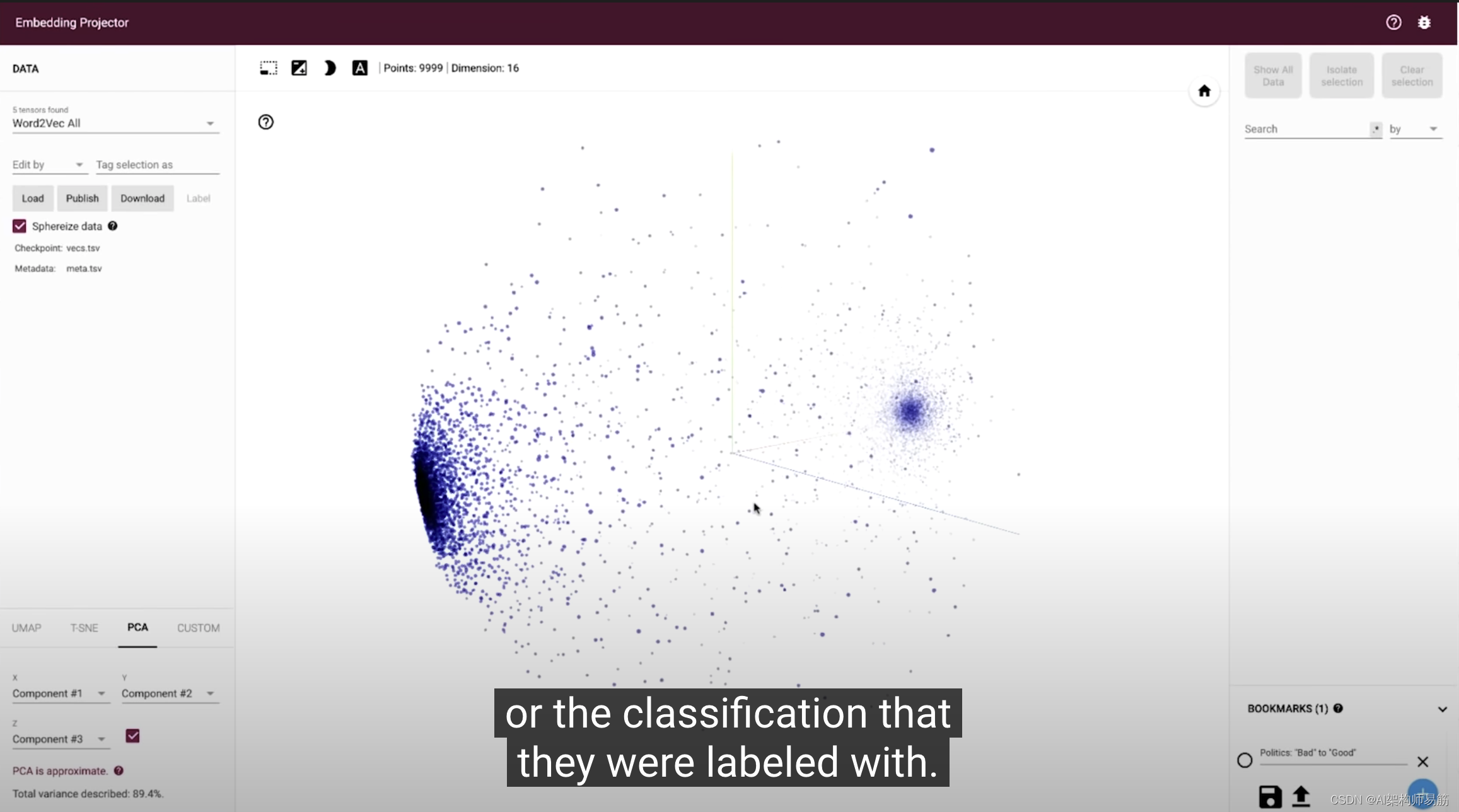

СЗЯА2
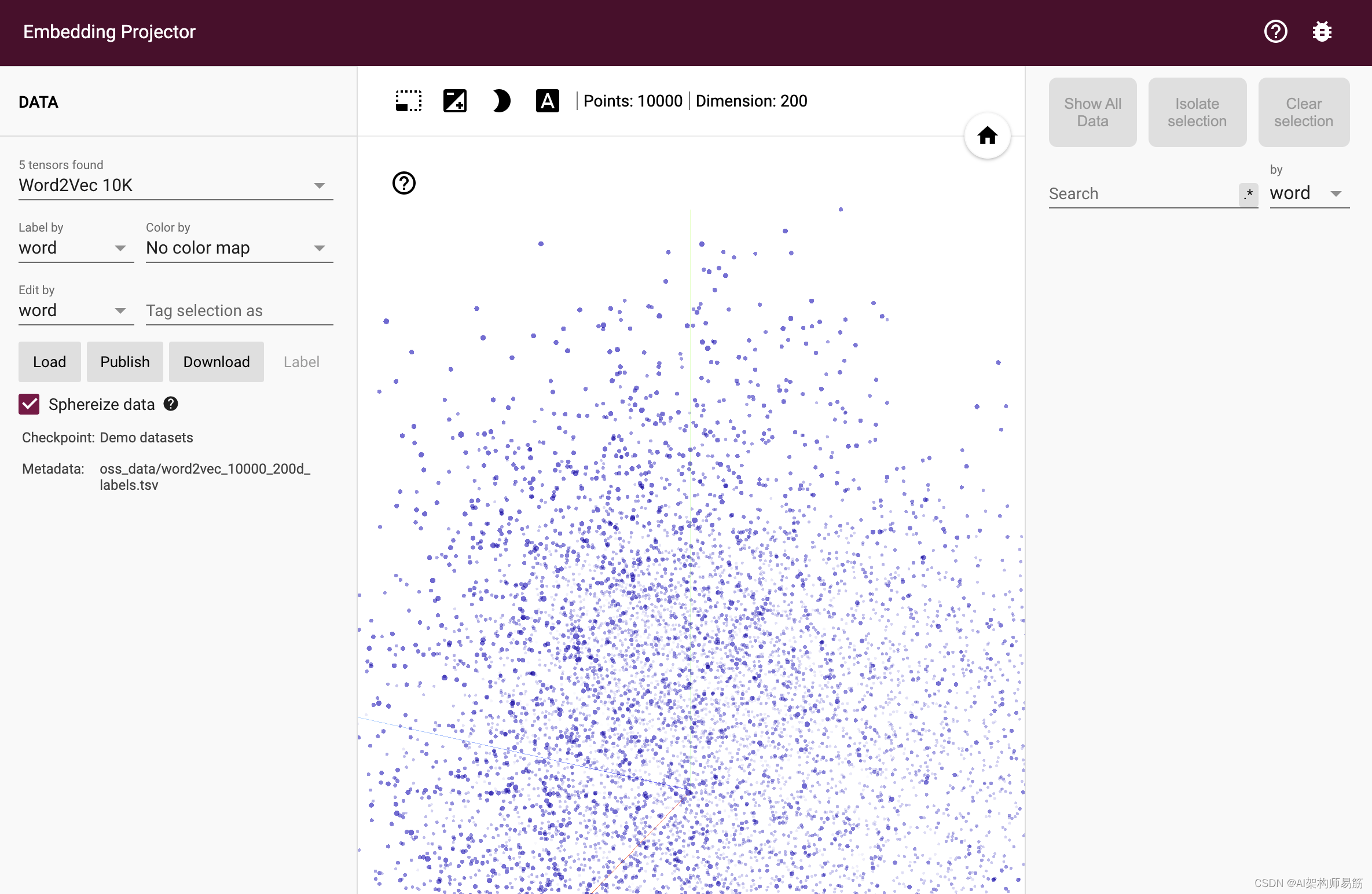
ВЮПМ
https://youtu.be/-8XmD2zsFBI