本文发表于EMNLP2020。
本文提出了一个基于卷积模型的蒸馏方法,实现了一个轻量级的、快速的半监督文本分类框架FLiText,相比于Bert等大规模预训练模型,蒸馏模型更具备实际应用价值。

Method
模型总体的框架如下,大致分为激励网络和目标网络两部分:
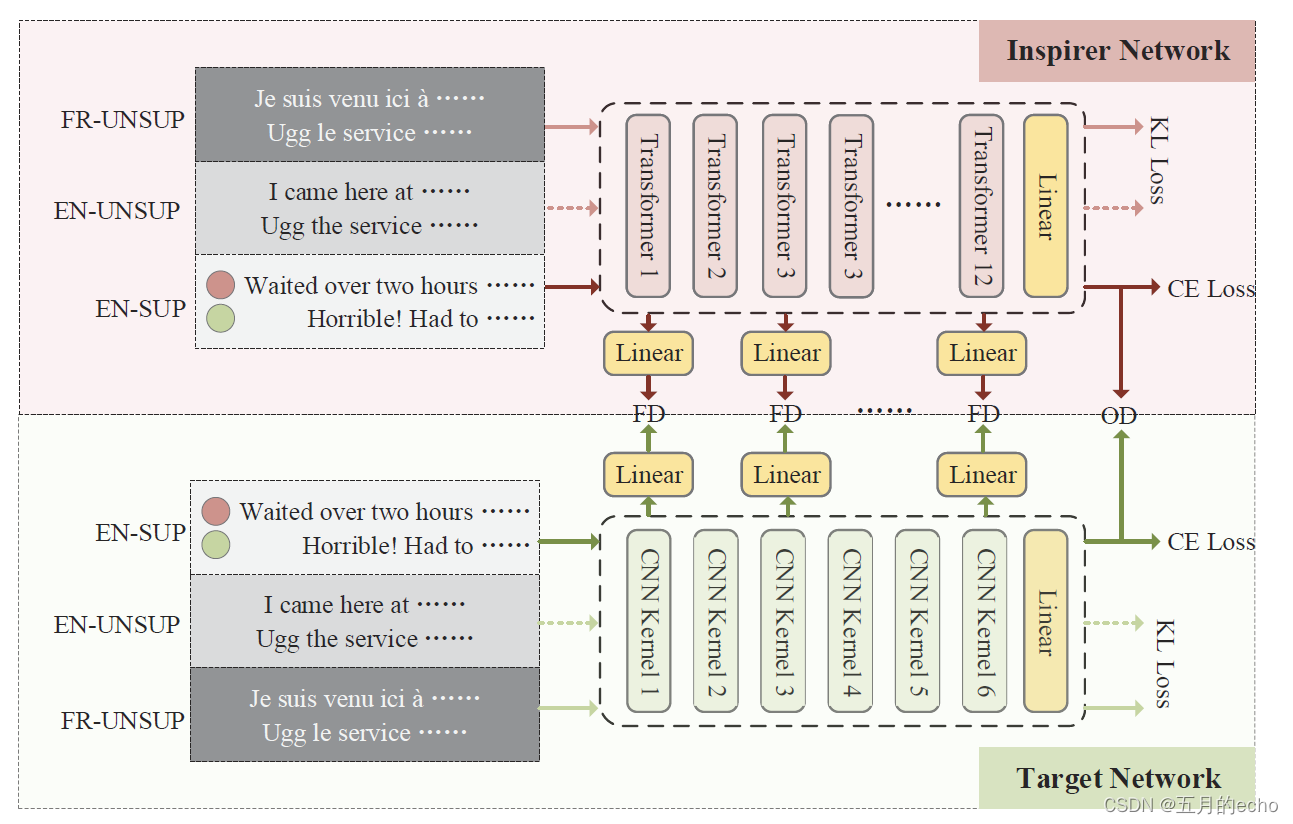
激励器网络(预训练语言模型)利用一致性正则化和数据增强技术,充分挖掘未标记数据和有限标记数据中的信息和特征。然后在输出和隐藏空间两层提供正则化约束,引导轻量级目标网络仅使用少量标记数据实现高效的半监督学习。
本文使用
X
=
(
x
i
,
y
i
)
,
i
∈
(
1
,
.
.
,
n
)
X=(x_i,y_i),i\in (1,..,n)
X=(xi?,yi?),i∈(1,..,n)表示有标签数据,
U
=
(
u
j
)
,
j
∈
(
1
,
.
.
,
n
)
U=(u_j), j\in (1,..,n)
U=(uj?),j∈(1,..,n)表示无标签数据。
Inspirer Network
激励网络,比如Bert使用 [CLS] 表示文本特征:

h
i
∈
R
d
h_i \in R^d
hi?∈Rd。接着使用两层MLP对下游任务进行预测:

为了对齐BERT和TextCNN的维度,我们将隐藏状态输入到特征投影
I
g
(
.
)
Ig(.)
Ig(.)中,输出的特征为
I
f
i
l
If_i^l
Ifil?,
l
l
l表示Bert的层:

这一步的目的是让Bert层与Text CNN层对齐并通过增加额外的一致性损失,让teacher(Bert)与student(Text CNN)学习到的中间层特征尽量一致。当然,公式(4)中并没有包含对齐的操作。
Target Network
目标网络是一个简单的带有最大池化的TextCNN,并在最后一层使用MLP进行概率预测:


然后使用一个简单的变换进行特征维度对齐,同激励网络类似:

Two-stage Learning
其实网络的结构很简单,接下来的学习才是重点。FLiText包括两个培训阶段:激励者预培训和目标网络培训。在第一阶段,我们引入各种先进的半监督思想来完成下游任务的激励者培训。在第二阶段,FLiText保持激励器参数不变,通过激励器网络提供的多级规则约束引导下游任务中目标网络的训练,最终实现高效的半监督蒸馏学习。
对于激励网络,需要包含两个损失:一个是有标签的损失,使用交叉熵即可;另一个是无标签的数据
u
i
u_i
ui?损失,通过引入其噪声版本
a
i
a_i
ai?,优化二者之间的差异(散度)从而保证模型的稳定性:

这里
(
T
)
(T)
(T)表示激励网络的标识。
Target Network Distillation
蒸馏的过程如框架图展示的那样,分为两部分。
Output-based Distillation。蒸馏的过程采用软硬两种损失。soft损失表示激励网络和目标网络的最终概率输出应该近似:

hard损失中则把激励网络的预测标签作为真实标签,然后使用交叉熵去估计:

Feature-based Distillation。基于特征的蒸馏则是关注于模型中间输出的特征,如图所示:
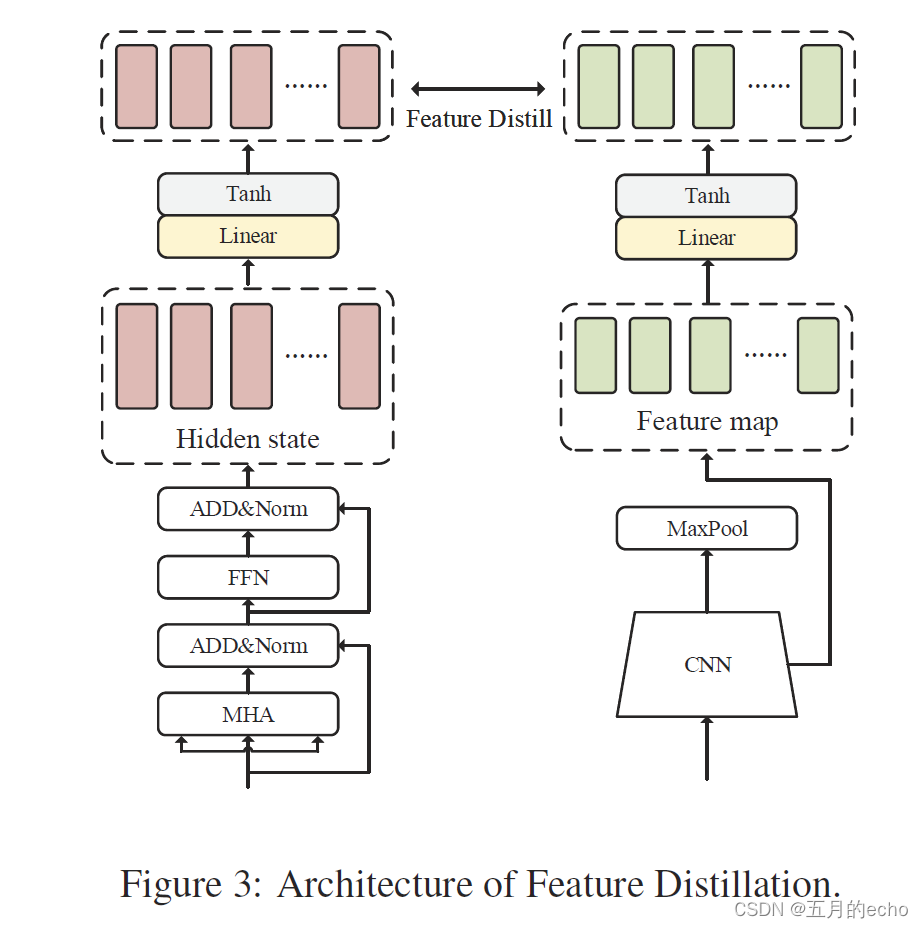
使用MSE进行评估,让两个网络的中间输出贴近:

Consistency Regularization。由于目标网络和激励网络的参数空间和网络结构的差异,在学习过程中存在知识丢失的问题。如果只采用KD方法,目标网络将无法学习激励网络的一些功能特征。因此,我们引入一致性正则化来约束目标网络,使其在函数空间中保持足够的平滑。因此,输入数据周围的网络应该是平坦的。即使输入数据发生了轻微的变化,或者它们的形式发生了变化,但语义没有改变,模型的输出也可以保持基本不变。这与对激励者网络的训练是一致的。其实也就是通过加入噪声进行平滑:

最终,模型的联合损失如下:

Experiments
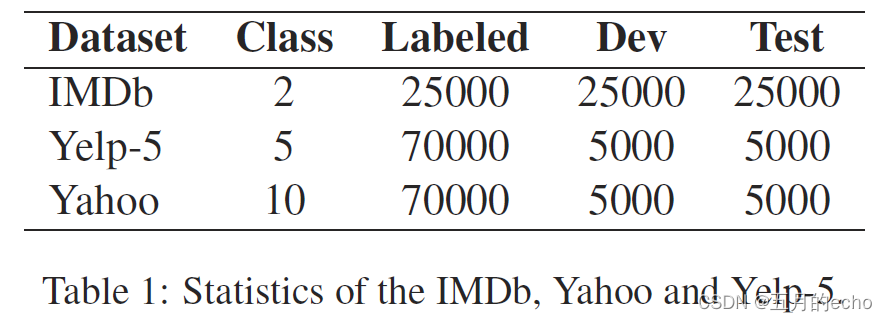
数据集:
结果:

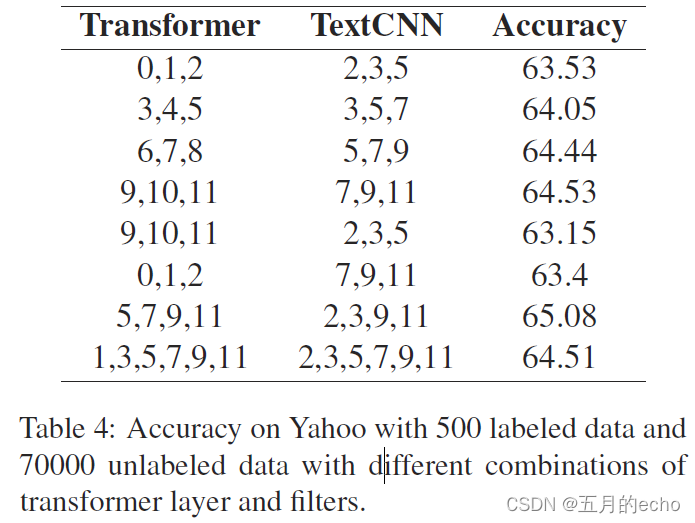
不同层的选择:
一致正则化的效果:

甚至不同的激活函数也进行了探究: