FNLP lecture 7
问题:
提前做好reading预习,课后quiz预习巩固,完善笔记
lecture前准备好PPT
solving none-zero problem: G-T(Good Turing)
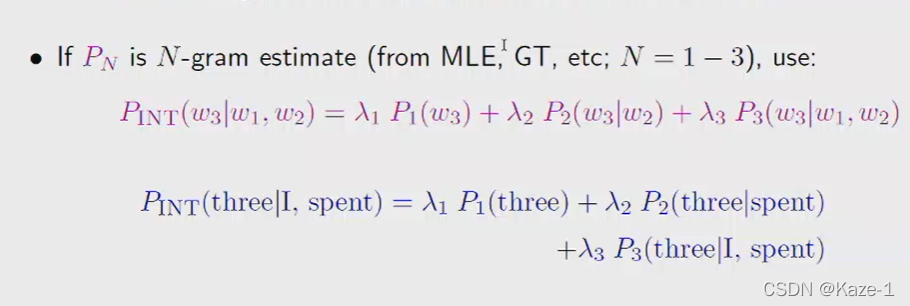
权重相加是1:
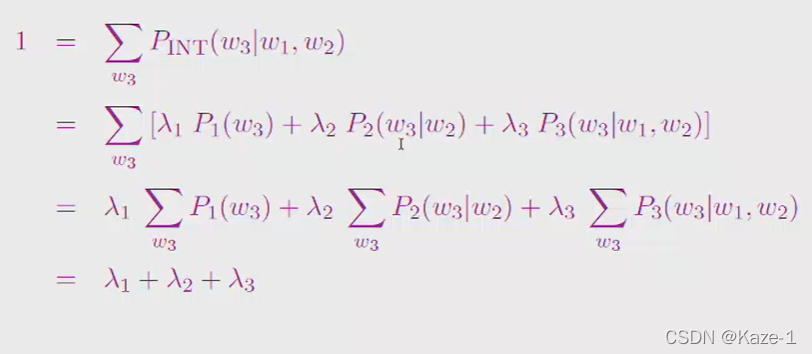
Kneser-Ney smoothing: 优势
1、take into account: diversity of history
例子:new york: york总是出现在new后面,用unigram/bigram除非前面是new,否则york出现概率低(但事实是york单独出现概率也不少)
2、
用一个向量来表示一个单词,向量每个元素代表该单词在某个context下的出现频率

错过了4分钟(30~35左右)
Noisy Channel Model
信息传输会经过errorful encoding,最后得到输出是有错误的
但是Noise的是服从概率分布的(What I am likely to say to you,具体应用中也就是Language Model (LM))
Noise Channel Model的数学本质:给出一个被拼错的单词X,找出最可能正确的原单词Y,也就是使得P(Y|X)最大的Y

Noisy Channel Model典型应用就是拼写纠错(Spelling Correction)
思考:平时在word,IDE等软件里看到的拼写预测是不是就是LM+Noisy Channel的应用呢,预测的列表可能是用有限copora当场计算出的可能单词Y,按P(Y|X)逆序排序,随着用户使用可以不断更新copora来迎合用户输入习惯
用depth set确定N(N-gram model)
没听懂的/确定的词:
back-off
和smoothing有关的某种方法?
interpolation:插值,插补文字
depth set
parallel corpora
类似的文本?