本小节通过Fp-growth算法挖掘僵尸网络的主机。
目前互联网中有大量僵尸主机进行探测扫描行为,这些僵尸主机为了避免被安全设备检测到,通常会频繁更换IP地址,故而很难仅仅只通过ip地址就确定僵尸主机。本小节通过使用FP-growth算法,分析防火墙的拦截日志,挖掘出浏览器的user-agent字段和被攻击的目标url之间的关联关系,来初步确定潜在的僵尸主机。
1、数据集
本小节使用防火墙的拦截日志来做挖掘,位于KnowledgeGraph/sample7.txt文件中,如下所示
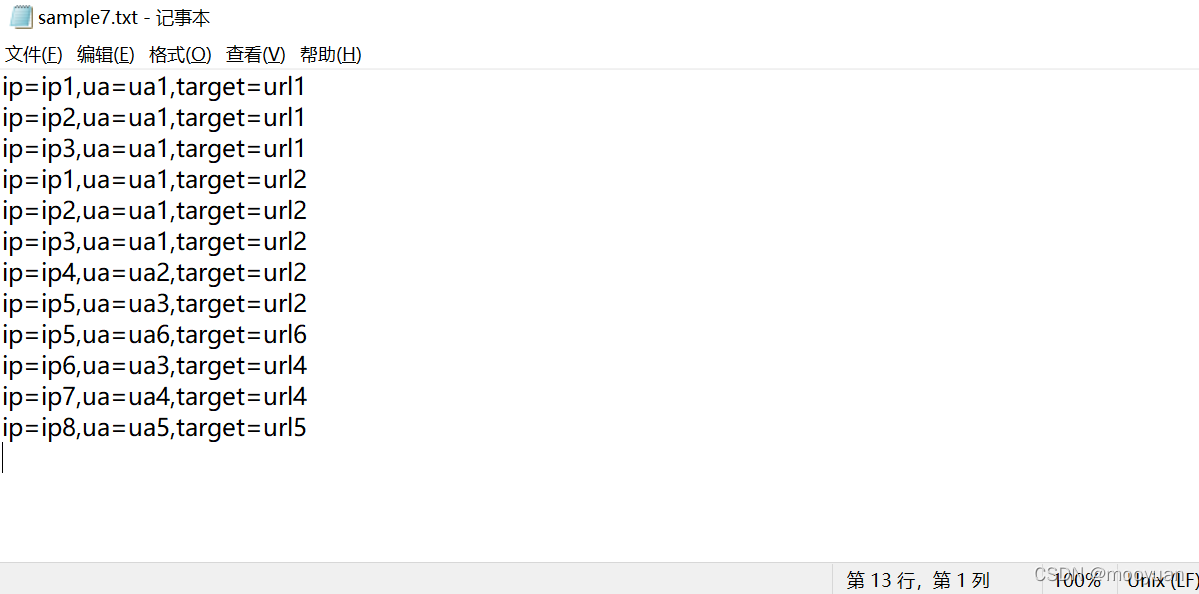
对于数据集处理则是使用逗号分隔,具体代码如下所示
transactions=[]
with open("../data/KnowledgeGraph/sample7.txt") as f:
for line in f:
line=line.strip('\n')
ip,ua,target=line.split(',')
print("Add (%s %s %s)" % (ip,ua,target))
transactions.append([ip,ua,target])
print(transactions)运行结果如下所示
Add (ip=ip1 ua=ua1 target=url1)
Add (ip=ip2 ua=ua1 target=url1)
Add (ip=ip3 ua=ua1 target=url1)
Add (ip=ip1 ua=ua1 target=url2)
Add (ip=ip2 ua=ua1 target=url2)
Add (ip=ip3 ua=ua1 target=url2)
Add (ip=ip4 ua=ua2 target=url2)
Add (ip=ip5 ua=ua3 target=url2)
Add (ip=ip5 ua=ua6 target=url6)
Add (ip=ip6 ua=ua3 target=url4)
Add (ip=ip7 ua=ua4 target=url4)
Add (ip=ip8 ua=ua5 target=url5)
[['ip=ip1', 'ua=ua1', 'target=url1'], ['ip=ip2', 'ua=ua1', 'target=url1'], ['ip=ip3', 'ua=ua1', 'target=url1'], ['ip=ip1', 'ua=ua1', 'target=url2'], ['ip=ip2', 'ua=ua1', 'target=url2'], ['ip=ip3', 'ua=ua1', 'target=url2'], ['ip=ip4', 'ua=ua2', 'target=url2'], ['ip=ip5', 'ua=ua3', 'target=url2'], ['ip=ip5', 'ua=ua6', 'target=url6'], ['ip=ip6', 'ua=ua3', 'target=url4'], ['ip=ip7', 'ua=ua4', 'target=url4'], ['ip=ip8', 'ua=ua5', 'target=url5']]
?
2、使用FP-growth算法挖掘僵尸主机
本小节将条件设置为支持度=3,而置信度=0.9,满足这样条件我们就认为它是僵尸主机。
patterns = pyfpgrowth.find_frequent_patterns(transactions, 3)
rules = pyfpgrowth.generate_association_rules(patterns, 0.9)?3、运行结果
经过FP-growth挖掘,满足条件的结果为
{('target=url1',): (('ua=ua1',), 1.0)}