еЊвЊ
аЁбљБОбЇЯАЪЧвЛжжЭЈЙ§ЩйСПбљБОбЕСЗЗжРрЦїЕФЗНЗЈ,ФПЧАЪЧвЛЯюБШНЯРЇФбЕФШЮЮёЁЃФПЧАБШНЯгааЇЕФЗНЗЈЪЧЛљгкдЊбЇЯАЕФдЄбЕСЗЗНЗЈ,ЪзЯШдкбљБОБШНЯЗсИЛЕФЛљДЁРрБ№ЩЯбЕСЗвЛИіЬиеїЬсШЁЦї,ШЛКѓдкбљБОБШНЯЩйЕФаТРрБ№ЩЯНјааЮЂЕїЁЃШЛЖјЪЕбщБэУїЮЂЕїЖдЭјТчдкаТРрБ№ЩЯЕФЗжРрзМШЗТЪЕФИФНјБШНЯгаЯо,БОЮФЗЂЯж,дкгУгкдЄбЕСЗЕФЛљДЁРрБ№Ъ§ОнМЏжа,УПИіРрБ№жабљБОЕФЗжВМЖМБШНЯНєДе,ВЛЭЌРрБ№жЎМфуўЮМЗжУї,ЖјдкбљБОБШНЯЩйЕФаТРрБ№Ъ§ОнМЏжа,ИїИіРрБ№жаЕФбљБОЗжВМБШНЯЛьТв,ВЛЭЌРрБ№ЕФбљБОЛьдквЛЦ№,ВЛШнвзЗжПЊ,МДЗНВюБШНЯДѓЁЃеыЖдЩЯЪіЮЪЬт,ИУЮФЖдЫљгаРрБ№ЕФРрБ№ДЪЬѕНјааДІРэ,ЭЈЙ§WordNetЛёЕУЦфЪєадДЪЬѕ,НЋЫљгаРрБ№ДЪЬѕгыЪєадДЪЬѕОGloVeМЦЫуЕУЕНДЪЧЖШыЯђСП(МДЖдгЂЮФЕЅДЪНјааЪ§зжЛЏЕУЕНИпЮЌЯђСП),ВЙШЋЕЅДПЭЈЙ§бљБООљжЕМЦЫуЕУЕНЕФдаЭ,ЬсГівЛжжИќМгОпгаДњБэадЕФРрБ№даЭ,ШЛКѓНЋдЪМЕФдаЭгыВЙШЋЕФдаЭНјааИпЫЙШкКЯ,ЕУЕНзюжеЕФдаЭ,дкаТРрБ№Ъ§ОнМЏЩЯНјааN-way K-shotЗНЪНЕФдЊбЕСЗЁЃ5-way 1-shotбЕСЗКѓ,ФЃаЭдкMiniImageNetЕФВтЪдМЏЩЯДяЕНФПЧАзюИпЕФ73.13%ЗжРрзМШЗТЪЁЃ
ЗНЗЈ

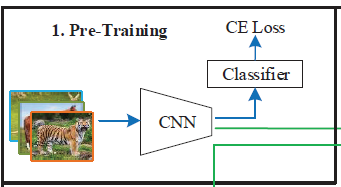
1. дЄбЕСЗ(Pre-Training)
дкЛљДЁРрБ№
C
b
a
s
e
C_{base}
Cbase?Ъ§ОнМЏЩЯ,ЪЙгУЫљгаЭМЯёбљБО,вдДЋЭГЕФЬнЖШЯТНЕбЕСЗЗНЗЈ,ЪЙгУБШНЯДѓЕФbatch_size(Шч128)ЁЂКЯЪЪЕФбЇЯАТЪ(Шч0.001)гыбЇЯАТЪЫЅМѕВпТдЁЂКЯЪЪЕФгХЛЏЦї(ШчЫцЛњЬнЖШЯТНЕ,SGD),КЯЪЪЕФЫ№ЪЇКЏЪ§(ШчНЛВцьиЫ№ЪЇКЏЪ§,CrossEntropyLoss,CE Loss),бЕСЗвЛИіОэЛ§ЩёОЭјТч(ШчResNet-12),МДЙЧИЩЭјТч(backbone),бЕСЗЭъГЩКѓ,ЩОГ§ЭјТчжаЕФЫљгаШЋСЌНгВу(МДЯТЭМжаЕФClassifier),аЮГЩЬиеїЬсШЁЦї
f
ІШ
f
f_{\theta_f}
fІШf??,
ІШ
f
\theta_f
ІШf?БэЪОЬиеїЬсШЁЦїЕФЫљгаВЮЪ§ЁЃЖдИУЭјТчЪфШывЛеХбЕСЗЭМЯёбљБО,МДПЩЪфГібљБОЕФЬиеїЭМ,УПИіbatchжаЕФЫљгаЭМЯёбљБОЕФЬиеїЭМЪЧЖрИіПеМфЗжБцТЪНЯЕЭ,ЭЈЕРЪ§КмЖрЕФШ§ЮЌеХСП, Р§ШчЩшжУbatch_sizeЮЊ128,дђЭјТчзюжеЪфГі128Иі7x7x512ЕФШ§ЮЌеХСП,ПЩвдаЮЯѓРэНтЮЊга512еХ7x7ЕФОиеѓбиЕкШ§ЮЌЖШЕўЦ№РДаЮГЩвЛИіГЄЗНЬх,етбљЕФГЄЗНЬхга128ИіЁЃ
2. бЇЯАШчКЮВЙШЋдаЭ(Learning to Complete Prototypes)
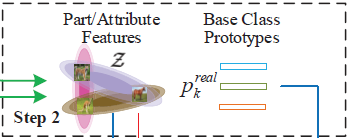
БОЮФЬсГівЛжждаЭВЙШЋЭјТч(ProtoComNet)зїЮЊдЊбЇЯАЦї,ВЙШЋЛљгкУПИіРрБ№бљБООљжЕЕФдЪМдаЭЁЃ
-
Step 1
евЕНЛљДЁРрБ№Ъ§ОнМЏ D b a s e D_{base} Dbase?жаЕк k k kИіРрБ№ДЪЬѕ c k c_k ck?ЕФЪєадДЪЬѕ a i a_i ai?,Р§ШчДќЪѓ(kangaroo)ОпгаГЄСГКЭАзЩЋИЙВП,дђЁАГЄСГ(long face)ЁБКЭЁААзЩЋИЙВП(white belly)ЁБОЭЪЧДќЪѓетИіРрБ№ДЪЬѕЕФЪєадДЪЬѕ,АпТэ(zebra)вВОпгаГЄСГ,ЫљвдАпТэЕФЪєадДЪЬѕвВАќРЈЁАГЄСГЁА,СэЭтАпТэЛЙгаЫФЬѕЭШ,ЫљвдЁАЫФЬѕЭШ(four-footed)ЁБвВЪЧАпТэЕФЪєадДЪЬѕЁЃ
ЭЈЙ§WordNetПЩвдЧсЫЩЛёЕУMiniImageNetЪ§ОнМЏжаЫљгаРрБ№ДЪЬѕЕФЪєадДЪЬѕЁЃ
МйЩшЛљДЁРрБ№Ъ§ОнМЏ D b a s e D_{base} Dbase?ЙВКЌ K K KИіЛљДЁРрБ№ c k c_k ck?,ЭЈЙ§WordNetЛёЕУСЫЫљга K K KИіЛљДЁРрБ№ЯТЕФ F F FИіЪєадДЪЬѕ a i a_i ai?ЁЃСюМЏКЯ A A AБэЪОЫљгаЪєадДЪЬѕ a i a_i ai?ЕФМЏКЯ,га A = { a i ЈO i = 1 , 2 , . . . , F } A=\{a_i|i=1,2,...,F\} A={ai?ЈOi=1,2,...,F}СюМЏКЯ C b a s e C_{base} Cbase?БэЪО K K KИіРрБ№ДЪЬѕ c k c_k ck?ЕФМЏКЯ,МД C b a s e = { c k ЈO k = 1 , 2 , . . . , K } C_{base}=\{c_k|k=1,2,...,K\} Cbase?={ck?ЈOk=1,2,...,K}Сю w j w_j wj?БэЪОЕк j j jИіДЪЬѕ,МЏКЯ W W WБэЪОЫљгаДЪЬѕ w j w_j wj?ЕФМЏКЯ,га W = { w j ЈO w j ЁЪ C b a s e ЁШ A , j = 1 , 2 , . . . , K , K + 1 , . . . , K + F } W=\{w_j|w_j\in C_{base}\cup A,j=1,2,...,K,K+1,...,K+F\} W={wj?ЈOwj?ЁЪCbase?ЁШA,j=1,2,...,K,K+1,...,K+F}Сю r k j r_{kj} rkj?БэЪОРрБ№ДЪЬѕ c k c_k ck?КЭДЪЬѕ w j w_j wj?жЎМфЕФЙиЯЕ,га r k j = { 1 if? w j ЪЧ c k ЕФ Ъє ад ДЪ Ьѕ 1 if? w j = c k 0 if?otherwise r_{kj}=\begin{cases}1&\text{if }w_jЪЧc_kЕФЪєадДЪЬѕ\\1&\text{if }w_j=c_k\\0&\text{if otherwise}\end{cases} rkj?=??????110?if?wj?ЪЧck?ЕФЪєадДЪЬѕif?wj?=ck?if?otherwise?Сю R R RЪЧЫљга r k j r_{kj} rkj?ЕФМЏКЯ,дђга r k j ЁЪ R , R ЁЪ R K ЁС ( K + F ) r_{kj}\in R,R\in \R^{K\times {(K+F)}} rkj?ЁЪR,RЁЪRKЁС(K+F)ЁЃ
ЪЙгУGloVeЫуЗЈЖдДЪЬѕМЏКЯ W W WжаЕФЫљгаДЪЬѕ w j w_j wj?Ъ§зжЛЏ,МД h ? j = GloVe ( w j ) , \vec{h}_j=\text{GloVe}(w_j), hj?=GloVe(wj?),зЊЛЏГЩЯрЭЌГЄЖШЕФДЪЧЖШыЯђСП h ? j ЁЪ R 1 ЁС d \vec{h}_j \in \R ^{1\times d} hj?ЁЪR1ЁСd, d d dЪЧЯђСПЭЈЕРЪ§ЁЃСю H H HБэЪОЫљга h ? j \vec{h}_j hj?ЕФМЏКЯ,га H = { h ? j ЈO j = 1 , 2 , . . . , K + F } , H ЁЪ R ( K + F ) ЁС d H=\{\vec{h}_j|j=1,2,...,K+F\},H\in \R^{(K+F)\times d} H={hj?ЈOj=1,2,...,K+F},HЁЪR(K+F)ЁСdЖдгкMiniImageNetЪ§ОнМЏ,ЙВ K = 100 K=100 K=100РрБ№, F = 71 F=71 F=71ИіЪєадДЪЬѕ,GloVeЫуЗЈЩњГЩ d = 300 d=300 d=300ЕФДЪЧЖШыЯђСП,дђ H H HЪЧ171x300ЕФОиеѓ, R R RЪЧ171x171ЕФЯЁЪшОиеѓЁЃдкОиеѓ R R Rжа,гЩгкЙВ K = 100 K=100 K=100ИіРрБ№,вђДЫДгЕк101ааПЊЪМ,КѓУцЕФЫљгадЊЫиЖМЪЧ0,Оиеѓжа0ЕФЪ§СПдЖДѓгк1ЕФЪ§СП,ДгЖј R R RЪЧвЛИіЯЁЪшОиеѓЁЃ

-
Step 2
дкдЄбЕСЗГіЕФЬиеїЬсШЁЦї f ІШ f f_{\theta_f} fІШf??КЭЪєадДЪЬѕМЏКЯ A A AЛљДЁЩЯ,МЦЫуУПИіЛљДЁРрБ№жаЫљгабљБОЬиеїЭМЕФЦНОљжЕ,ЕУЕНУПИіЛљДЁРрБ№ЕФдаЭЁЃОпЬхРДНВ,ЖдгкЕк k k kИіЛљДЁРрБ№ c k c_k ck?,НЋвЛеХЪєгк c k c_k ck?РрБ№ЕФбЕСЗЭМЯёбљБО x x xЪфШыдЄбЕСЗНзЖЮбЕСЗКУЕФЬиеїЬсШЁЦї f ІШ f f_{\theta_f} fІШf??,ЕУЕН x x xЕФЬиеїЯђСП f ? x = f ІШ f ( x ) ЁЪ R 1 ЁС s \vec{f}_x=f_{\theta_f}(x)\in \R^{1\times s} f?x?=fІШf??(x)ЁЪR1ЁСs, s s sЪЧЬиеїЭМЭЈЕРЪ§,Шє f ІШ f = ResNet-12 f_{\theta_f}=\text{ResNet-12} fІШf??=ResNet-12,дђ s = 512 s=512 s=512ЁЃвдетжжЗНЪНМЦЫуГі c k c_k ck?РрБ№ЯТбЕСЗЭМЯёбљБОМЏКЯ D b a s e k D^k_{base} Dbasek?жаЫљгаЭМЯёЕФЬиеїЯђСП,ЧѓЦНОљжЕ,ЕУЕНЛљДЁРрБ№ c k c_k ck?ЕФдаЭ p ? k r e a l \vec{p}_k^{real} p?kreal?,МД p ? k r e a l = 1 ЈO D b a s e k ЈO ЁЦ ( x , y ) ЁЪ D b a s e k f ІШ f ( x ) , p ? k r e a l ЁЪ R 1 ЁС s \vec{p}_k^{real}=\frac{1}{|D^k_{base}|}\sum_{(x,y)\in D^k_{base}}f_{\theta_f}(x),\vec{p}^{real}_k\in \R^{1\times s} p?kreal?=ЈODbasek?ЈO1?(x,y)ЁЪDbasek?ЁЦ?fІШf??(x),p?kreal?ЁЪR1ЁСsЦфжа ЈO D b a s e k ЈO |D^k_{base}| ЈODbasek?ЈOБэЪОЕк k k kИіРрБ№ЯТбЕСЗЭМЯёбљБОЕФЪ§СПЁЃ
ЖдгкWordNetЬсШЁГіЕФЪєадДЪЬѕ a i a_i ai?,ПЩвдЯыЕНетаЉЪєадДЪЬѕвВЭЌбљЪєгквЛаЉаТРрБ№,Р§ШчНЋТэзїЮЊЛљДЁРрБ№,АпТэзїЮЊаТРрБ№,дђТэЕФЪєадДЪЬѕжЎвЛЁАЫФЬѕЭШЁБвВЪЧАпТэЕФЪєадДЪЬѕ,МДетаЉЪєадДЪЬѕНЋЛљДЁРрБ№КЭаТРрБ№СЊЯЕСЫЦ№РДЁЃЖдгкЕк i i iИіЪєадДЪЬѕ a i a_i ai?,евЕНЦфЫљЪєЕФЫљгаЛљДЁРрБ№,Р§ШчЖдгкЁАЫФЬѕЭШЁБетвЛЪєадДЪЬѕ,ТэЁЂАпТэЁЂДѓЯѓЕШРрБ№ЖМОпгаЫФЬѕЭШ,МДЖМКЌгаЁАЫФЬѕЭШЁБетвЛЪєадДЪЬѕ,ШЛКѓевГіетаЉРрБ№ЫљАќКЌЕФЫљгабЕСЗЭМЯёбљБО x ЁЪ D b a s e a i x\in D_{base}^{a_i} xЁЪDbaseai??ЁЃ
НгЯТРДМЦЫуЫљгаЪєадДЪЬѕ a i a_i ai?ЕФЬиеїЯђСП z ? a i \vec{z}_{a_i} zai??(МДЯТЭМжаЕФPart/Attribute Features)ЁЃЪзЯШ,МЦЫуМЏКЯ D b a s e a i D_{base}^{a_i} Dbaseai??жаЫљгаЭМЯёбљБОЕФОљжЕЬиеїЯђСП ІЬ ? a i \vec{\mu}_{a_i} ІЬ?ai??КЭБъзМВюЯђСП Ів ? a i \vec{\sigma}_{a_i} Івai??,МД ІЬ ? a i = 1 ЈO D b a s e a i ЈO ЁЦ ( x , y ) ЁЪ D b a s e a i f ІШ f ( x ) , ІЬ ? a i ЁЪ R 1 ЁС s \vec{\mu}_{a_i}=\frac{1}{|D^{a_i}_{base}|}\sum_{(x,y)\in D^{a_i}_{base}}f_{\theta_f}(x),\vec{\mu}_{a_i}\in \R^{1\times s} ІЬ?ai??=ЈODbaseai??ЈO1?(x,y)ЁЪDbaseai??ЁЦ?fІШf??(x),ІЬ?ai??ЁЪR1ЁСs Ів ? a i = 1 ЈO D b a s e a i ЈO ЁЦ ( x , y ) ЁЪ D b a s e a i ( f ІШ f ( x ) ? ІЬ ? a i ) 2 , Ів ? a i ЁЪ R 1 ЁС s \vec{\sigma}_{a_i}=\sqrt{\frac{1}{|D^{a_i}_{base}|}\sum_{(x,y)\in D^{a_i}_{base}}{(f_{\theta_f}(x)-\vec{\mu}_{a_i})}^2},\vec{\sigma}_{a_i}\in \R^{1\times s} Івai??=ЈODbaseai??ЈO1?(x,y)ЁЪDbaseai??ЁЦ?(fІШf??(x)?ІЬ?ai??)2?,Івai??ЁЪR1ЁСs i = 1 , 2 , . . . , F i=1,2,...,F i=1,2,...,FЦфжа ЈO D b a s e a i ЈO |D^{a_i}_{base}| ЈODbaseai??ЈOБэЪО D b a s e a i D^{a_i}_{base} Dbaseai??жабљБОЕФЪ§СПЁЃЦфДЮ,вдОљжЕЬиеїЯђСП ІЬ ? a i \vec{\mu}_{a_i} ІЬ?ai??КЭБъзМВюЯђСП Ів ? a i \vec{\sigma}_{a_i} Івai??ЮЊВЮЪ§,ЙЙдь s s sЮЌе§ЬЌЗжВМ N ( ІЬ ? a i , Ів ? a i 2 ) N(\vec{\mu}_{a_i},\vec{\sigma}_{a_i}^2) N(ІЬ?ai??,Івai?2?)(МДЯТЭМжаВЛЭЌбеЩЋЕФЭждВаЮЧјгђЁЃЮЊКЮЪЙгУЭждВаЮ?вђЮЊИпЮЌе§ЬЌЗжВМИХТЪУмЖШКЏЪ§дкЖўЮЌЦНУцЩЯЕФЭЖгАЪЧвЛИіЭждВ),ДгИУЗжВМжаЫцЛњШЁжЕ,зїЮЊЪєадДЪЬѕ a i a_i ai?ЕФЬиеїЯђСП,МД z ? a i = ІЬ ? a i + Ів ? a i ? ? , z ? a i ЁЪ R 1 ЁС s \vec{z}_{a_i}=\vec{\mu}_{a_i}+\vec{\sigma}_{a_i}\vec{\epsilon},\vec{z}_{a_i} \in\R^{1\times s} zai??=ІЬ?ai??+Івai???,zai??ЁЪR1ЁСs ? ? \vec{\epsilon} ?Дг s s sЮЌБъзМе§ЬЌЗжВМжаЫцЛњШЁбљ, ? ? ЁЪ R 1 ЁС s \vec{\epsilon}\in \R^{1\times s} ?ЁЪR1ЁСsЁЃСю Z Z ZБэЪОЫљга z ? a i \vec{z}_{a_i} zai??ЕФМЏКЯ,га Z = { z ? a i ЈO a i ЁЪ A } Z=\{\vec{z}_{a_i}|a_i\in A\} Z={zai??ЈOai?ЁЪA}
-
Step 3
ЭЈЙ§Step 1КЭStep 2,ЕУЕНСЫЛљДЁРрБ№ c k c_k ck?ЕФдаЭ p ? k r e a l \vec{p}_k^{real} p?kreal?КЭЪєадДЪЬѕ a i a_i ai?ЕФЬиеїЯђСП z ? a i \vec{z}_{a_i} zai??,дкетвЛВНжа,ашвЊЭЈЙ§даЭВЙШЋЭјТч(ProtoComNet) f ІШ c f_{\theta_c} fІШc??,НЋМЏКЯ R R RЁЂМЏКЯ H H HЁЂМЏКЯ Z Z ZКЭЛљДЁРрБ№ c k c_k ck?ЕФдаЭ p k r e a l p_k^{real} pkreal?зїЮЊЪфШы,ЪфГіЛљДЁРрБ№ c k c_k ck?ВЙШЋКѓЕФдаЭ p ^ k \hat p_k p^?k?ЁЃОпЬхзіЗЈШчЯТ:
БрТыЦї(Encoder)
ДЫВНашвЊбЕСЗвЛИіЪфГіЭЈЕРМѕАыЕФШЋСЌНгВуМгReLUМЄЛюКЏЪ§зїЮЊБрТыЦї g ІШ e g_{\theta_e} gІШe??,МДself.encoder = nn.Sequential( nn.Linear(in_features=s, out_features=s//2), nn.ReLU(inplace=True), )дкЛљДЁРрБ№Ъ§ОнМЏ D b a s e D_{base} Dbase?жаЫцЛњбЁдёвЛИібЕСЗЭМЯёбљБО x x x,ЕУЕН x x xЕФБъЧЉ y y y,ЪфШыдЄбЕСЗНзЖЮбЕСЗКУЕФЬиеїЬсШЁЦї f ІШ f f_{\theta_{f}} fІШf??,МД f ? x = f ІШ f ( x ) \vec{f}_x=f_{\theta_f}(x) f?x?=fІШf??(x),ЕУЕН x x xЕФЬиеїЯђСП f ? x ЁЪ R 1 ЁС s \vec{f}_x\in \R^{1\times s} f?x?ЁЪR1ЁСsЁЃЖд f ? x = ( f 1 , f 2 , . . . , f s ) \vec{f}_x=(f_1,f_2,...,f_s) f?x?=(f1?,f2?,...,fs?)НјааЯпадБфЛЛВЂЗЧЯпадМЄЛю,ЕУЕН f ? x \vec{f}_x f?x?ЕФвўБрТы b ? x = ( b 1 , b 2 , . . . , b s / 2 ) \vec{b}_x=(b_1,b_2,...,b_{s/2}) bx?=(b1?,b2?,...,bs/2?),МД b j = ЁЦ i = 1 s ІТ i j f i + ІУ j b_j=\sum^s_{i=1} \beta_{ij}f_i+\gamma_j bj?=i=1ЁЦs?ІТij?fi?+ІУj? ReLUМЄЛю: b j = max ( 0 , b j ) \text{ReLUМЄЛю:}b_j=\text{max}(0,b_j) ReLUМЄЛю:bj?=max(0,bj?) j = 1 , 2 , . . . , s 2 j=1,2,...,\frac{s}{2} j=1,2,...,2s?ЭЌбљ,ЪфШыЪєадДЪЬѕ a i a_i ai?ЕФЬиеїЯђСП z ? a i = ( z 1 , z 2 , . . . , z s ) \vec{z}_{a_i}=(z_1,z_2,...,z_s) zai??=(z1?,z2?,...,zs?),ЬцЛЛЩЯЪіЪНзгЕФ f i f_i fi?,МЦЫуЕУЕНЪєадДЪЬѕ a i a_i ai?ЬиеїЯђСП z ? a i \vec{z}_{a_i} zai??ЕФвўБрТыЯђСП c ? a i ЁЪ R 1 ЁС s 2 \vec{c}_{a_i}\in \R^{1\times \frac{s}{2}} cai??ЁЪR1ЁС2s?
ОлКЯЦї(Aggregator)
ВЛЭЌЕФЪєадДЪЬѕЖдЭЌвЛРрБ№ОпгаВЛЭЌгАЯь,Р§ШчЪєадДЪЬѕЁАБЧзгЁБЖдгкЁАДѓЯѓЁБетвЛРрБ№БШЁАРЯЛЂЁБИќгаДњБэад,вђДЫашвЊЙЙдьвЛжжзЂвтСІЛњжЦДяЕНЪєадМгШЈФПЕФ,ДЫВНашвЊбЕСЗвЛИіЫЋВуШЋСЌНгЭјТчзїЮЊОлКЯЦї g ІШ a g_{\theta_a} gІШa??,МДself.aggregator = nn.Sequential( nn.Linear(in_features=d+d+s, out_features=d), nn.ReLU(inplace=True), nn.Linear(in_features=d, out_features=1)ЪзЯШ,НЋбЕСЗЭМЯёбљБО x x xЕФБъЧЉ y y yЖдгІЕФРрБ№ДЪЧЖШыЯђСП h ? y ЁЪ R 1 ЁС d \vec{h}_y\in \R^{1\times d} hy?ЁЪR1ЁСdЁЂДЪЬѕ w m ЁЪ W w_m\in W wm?ЁЪW( m = 1 , 2 , . . . , K + F m=1,2,...,K+F m=1,2,...,K+F)ЕФДЪЧЖШыЯђСП h ? m ЁЪ R 1 ЁС d \vec{h}_{m}\in \R^{1\times d} hm?ЁЪR1ЁСdКЭ x x xОЙ§ЬиеїЬсШЁЦї f ІШ f f_{\theta_{f}} fІШf??ЕУЕНЕФЬиеїЯђСП f ? x ЁЪ R 1 ЁС s \vec{f}_x\in \R^{1\times s} f?x?ЁЪR1ЁСsСЌНг,ЕУЕН [ h ? y ЈO ЈO h ? m ЈO ЈO f ? x ] ЁЪ R 1 ЁС ( d + d + s ) [\vec{h}_y||\vec{h}_{m}||\vec{f}_x]\in \R^{1\times (d+d+s)} [hy?ЈOЈOhm?ЈOЈOf?x?]ЁЪR1ЁС(d+d+s),Жд [ h ? y ЈO ЈO h ? m ЈO ЈO f ? x ] [\vec{h}_y||\vec{h}_{m}||\vec{f}_x] [hy?ЈOЈOhm?ЈOЈOf?x?]ОЙ§ЩЯЪіШЋСЌНгВу,ЕУЕНвўБрТыЯђСП c ? x = ( c 1 , c 2 , . . . , c K + F ) \vec{c}_x=(c_1,c_2,...,c_{K+F}) cx?=(c1?,c2?,...,cK+F?),МД t j m = ЁЦ i = 1 d + d + s ІФ i j [ h ? y ЈO ЈO h ? m ЈO ЈO f ? x ] i + ІЦ j , j = 1 , 2 , . . . , d t_{jm}=\sum_{i=1}^{d+d+s}\delta_{ij}[\vec{h}_y||\vec{h}_{m}||\vec{f}_x]_i+\zeta_j,\quad j=1,2,...,d tjm?=i=1ЁЦd+d+s?ІФij?[hy?ЈOЈOhm?ЈOЈOf?x?]i?+ІЦj?,j=1,2,...,d t j m = max ( 0 , t j m ) , j = 1 , 2 , . . . , d t_{jm}=\text{max}(0,t_{jm}),\quad j=1,2,...,d tjm?=max(0,tjm?),j=1,2,...,d c m = ЁЦ j = 1 d ІЧ j t j m + ІШ c_m=\sum_{j=1}^d\eta_{j}t_{jm}+\theta cm?=j=1ЁЦd?ІЧj?tjm?+ІШ m = 1 , 2 , . . . , K + F m=1,2,...,K+F m=1,2,...,K+FЦфДЮ,НЋвўБрТыЯђСП c x ? ЁЪ R 1 ЁС ( K + F ) \vec{c_x}\in \R^{1\times (K+F)} cx??ЁЪR1ЁС(K+F)гыБэЪОБъЧЉ y y yЖдгІРрБ№ c y c_y cy?ЖдЫљгаДЪЬѕЙиЯЕЕФЯђСП r ? y = ( r 1 , r 2 , . . . , r K + F ) \vec{r}_y=(r_1,r_2,...,r_{K+F}) ry?=(r1?,r2?,...,rK+F?)ж№дЊЫиЯрГЫ,МД ІС ? = c ? x ? r ? y , ІС ? ЁЪ R 1 ЁС ( K + F ) , m = 1 , 2 , . . . , K + F \vec{\alpha}=\vec{c}_x\cdot \vec{r}_y,\vec{\alpha}\in \R^{1\times (K+F)},m=1,2,...,K+F ІС=cx??ry?,ІСЁЪR1ЁС(K+F),m=1,2,...,K+FЕУЕНЪфШы x x xЪБ,ЫљгаДЪЬѕЕФзЂвтСІШЈжи ІС ? \vec{\alpha} ІСЁЃзюКѓ,НЋзЂвтСІШЈжи ІС ? = ( ІС 1 , ІС 2 , . . . , ІС K + F ) \vec{\alpha}=(\alpha_1,\alpha_2,...,\alpha_{K+F}) ІС=(ІС1?,ІС2?,...,ІСK+F?)ЁЂ x x xЕФЬиеїЯђСП f x ? \vec{f_x} fx??ОЙ§БрТыЦїЕУЕНЕФвўБрТыЯђСП b ? x = ( b 1 , b 2 , . . . , b s 2 ) \vec{b}_x=(b_1,b_2,...,b_{\frac{s}{2}}) bx?=(b1?,b2?,...,b2s??)ЁЂМЏКЯ Z Z ZжаЫљгаЪєадДЪЬѕЬиеїЯђСП z ? a i \vec{z}_{a_i} zai??ЕФвўБрТыЯђСП c ? i = ( c i 1 , c i 2 , . . . , c i s 2 ) \vec{c}_i=(c_{i1},c_{i2},...,c_{i\frac{s}{2}}) ci?=(ci1?,ci2?,...,ci2s??)ЯрГЫЧѓКЭ,ЕУЕНОлКЯНсЙћ g ? = ( g 1 , g 2 , . . . , g s 2 ) \vec{g}=(g_1,g_2,...,g_\frac{s}{2}) g?=(g1?,g2?,...,g2s??),МД g n = ІС y b n + ЁЦ i = 1 F ІС K + i c i n , n = 1 , 2 , . . . , s 2 g_n=\alpha_yb_n+\sum_{i=1}^{F}\alpha_{K+i}c_{in},\quad n=1,2,...,\frac{s}{2} gn?=ІСy?bn?+i=1ЁЦF?ІСK+i?cin?,n=1,2,...,2s?Цфжа,дкзЂвтСІШЈжиЯђСП ІС ? \vec{\alpha} ІСжа,гЩгкДцдк K K KИіЛљДЁРрБ№,ЫљвдЧА K K KИізЂвтСІШЈжи ІС 1 , ІС 2 , . . . , ІС K \alpha_1,\alpha_2,...,\alpha_K ІС1?,ІС2?,...,ІСK?ЪЧЛљДЁРрБ№ЕФзЂвтСІШЈжи,Кѓ F F FИізЂвтСІШЈжи ІС K + 1 , ІС K + 2 , . . . , ІС K + F \alpha_{K+1},\alpha_{K+2},...,\alpha_{K+F} ІСK+1?,ІСK+2?,...,ІСK+F?ЪЧ F F FИіЪєадДЪЬѕЕФзЂвтСІШЈжиЁЃ
НтТыЦї(Decoder)
НтТыЦї g ІШ d g_{\theta d} gІШd?ЕФзїгУБШНЯМђЕЅ,жЛЪЧАбЯђСПЕФЮЌЖШДг s / 2 s/2 s/2ЛжИДЕН s s s,МДself.decoder = nn.Sequential( nn.Linear(in_features=s//2, out_features=512), nn.ReLU(inplace=True), nn.Linear(in_features=512, out_features=s)ОпЬхЙЋЪНдкДЫЪЁТд,зюжеЕУЕН x x xЕФБъЧЉ y y yЖдгІЕФВЙШЋдаЭ p ^ y ЁЪ R 1 ЁС s \hat{p}_y\in \R^{1\times s} p^?y?ЁЪR1ЁСsЁЃзЂвт,дкбЕСЗдаЭВЙШЋЭјТчЙ§ГЬжа,ЪфШывЛИібЕСЗЭМЯёбљБО x x x,ЪфГівЛИі x x xЕФБъЧЉ y y yЕФВЙШЋдаЭ,МДдкЭЌвЛЛљДЁРрБ№ c y c_y cy?жа,ВЛЭЌбЕСЗЭМЯёбљБОЪфГіЕФВЙШЋдаЭ p ^ y \hat{p}_y p^?y?ВЛЭЌЁЃ
бЕСЗдаЭВЙШЋЭјТч
МЦЫуStep 2МЦЫуЕУЕНЕФЛљДЁРрБ№ c y c_y cy?ЕФдЪМдаЭ p ? y r e a l = ( p 1 r e a l , p 2 r e a l , . . . , p s r e a l ) \vec{p}_y^{real}=(p^{real}_1,p^{real}_2,...,p^{real}_s) p?yreal?=(p1real?,p2real?,...,psreal?)КЭЛљДЁРрБ№ c y c_y cy?ЕФВЙШЋдаЭ p ^ y = ( p 1 , p 2 , . . . , p s ) \hat{p}_y=(p_1,p_2,...,p_s) p^?y?=(p1?,p2?,...,ps?)жЎМфЕФОљЗНВюЫ№ЪЇ E E E,МД E = 1 s ЁЦ i = 1 s ( p i ? p i r e a l ) 2 E=\frac{1}{s}\sum_{i=1}^s(p_i-p^{real}_i)^2 E=s1?i=1ЁЦs?(pi??pireal?)2ЭЈЙ§ЬнЖШЯТНЕЗНЗЈ,вдКЯЪЪЕФбЇЯАТЪ,дкНЕЕЭОљЗНВюЫ№ЪЇ(MSE Loss) E E EЕФЙ§ГЬжа,бЕСЗБрТыЦї g ІШ e g_{\theta_e} gІШe??ЁЂОлКЯЦї g ІШ a g_{\theta_a} gІШa??ЁЂНтТыЦї g ІШ d g_{\theta_d} gІШd??ЭјТчЕФВЮЪ§КЭЦЋжУЁЃ

3. дЊбЕСЗ(Meta-Training)
ЮДЭъД§ај