����ѧϰ-XGBoost
XGBoost����Ҫ�ŵ�:
�����á������������ѧϰ��,�û���������ʹ��XGBoost������൱������Ч����
��Ч����չ���ڴ������ģ���ݼ�ʱ�ٶȿ�Ч����,���ڴ��Ӳ����ԴҪ�ߡ�
³����ǿ����������ѧϰģ�Ͳ���Ҫ��ϸ���α���ȡ�ýӽ���Ч����
XGBoost�ڲ�ʵ��������ģ��,�����Զ�����ȱʧֵ��
XGBoost����Ҫȱ��:
��������ѧϰģ������ʱ��λ�ý�ģ,���ܺܺõز���ͼ���������ı��ȸ�ά���ݡ�
��ӵ�к���ѵ������,�����ҵ����ʵ����ѧϰģ��ʱ,���ѧϰ�ľ��ȿ���ңң����XGBoost��
��������
Part1 �����������ݼ���XGBoost����ʵ��
Step1: �⺯������
Step2: ���ݶ�ȡ/����
Step3: ������Ϣ�鿴
Step4: ���ӻ�����
Step5: ����ɢ�������б���
Step6: ���� XGBoost ����ѵ����Ԥ��
Step7: ���� XGBoost ��������ѡ��
Step8: ͨ������������ø��õ�Ч��
�㷨ʵ��
�����������ݼ���XGBoost����ʵս
��ʵ�����ʼ,����������Ҫ����һЩ�����ĺ��������:numpy (Python���п�ѧ����Ļ���������),pandas(pandas��һ�ֿ���,ǿ��,���������ʹ�õĿ�Դ���ݷ����ʹ�������),matplotlib��seaborn��ͼ��
#������Ҫ�õ������ݼ�
!wget https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/7XGBoost/train.csv
step1;�⺯������
## ����������
import numpy as np
import pandas as pd
## ��ͼ������
import matplotlib.pyplot as plt
import seaborn as sns
,������һЩ������վ�ṩ��ÿ�ս�������,������Ҫ������ʷ����������Ԥ�����������ĸ��ʡ������漰���IJ��Լ�����test.csv��train.csv�ĸ�ʽ��ȫ��ͬ,����RainTomorrowδ����,ΪԤ�������
���ݵĸ���������������:
�������� ���� ȡֵ��Χ
Date ���� �ַ���
Location ����վ�ĵ�ַ �ַ���
MinTemp ����¶� ʵ��
MaxTemp ����¶� ʵ��
Rainfall ������ ʵ��
Evaporation ������ ʵ��
Sunshine ����ʱ�� ʵ��
WindGustDir ��ǿ�ķ�ķ��� �ַ���
WindGustSpeed ��ǿ�ķ���ٶ� ʵ��
WindDir9am ����9��ķ��� �ַ���
WindDir3pm ����3��ķ��� �ַ���
WindSpeed9am ����9��ķ��� ʵ��
WindSpeed3pm ����3��ķ��� ʵ��
Humidity9am ����9���ʪ�� ʵ��
Humidity3pm ����3���ʪ�� ʵ��
Pressure9am ����9��Ĵ���ѹ ʵ��
Pressure3pm ����3��Ĵ���ѹ ʵ��
Cloud9am ����9�����ָ�� ʵ��
Cloud3pm ����3�����ָ�� ʵ��
Temp9am ����9����¶� ʵ��
Temp3pm ����3����¶� ʵ��
RainToday �����Ƿ����� No,Yes
RainTomorrow �����Ƿ����� No,Yes
Step2:���ݶ�ȡ/����
## ��������Pandas�Դ���read_csv������ȡ��ת��ΪDataFrame��ʽ
data = pd.read_csv('train.csv')
Step3:������Ϣ�鿴
## ����.info()�鿴���ݵ�������Ϣ
data.info()
## ���м����ݲ鿴,���ǿ������� .head() ͷ��.tail()β��
data.head()
�������Ƿ������ݼ��д���NaN,һ���������ΪNaN�����ݼ��д�����ȱʧֵ,���������ݲɼ�����ʱ������һ�ִ����������Dz���-1��ȱʧֵ�����,�����������硰��λ�����ƽ���������ȱʧֵ������������Ȥ��ͬѧҲ���Գ��ԡ�
data = data.fillna(-1)
data.tail()
Date Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir WindGustSpeed WindDir9am ... Humidity9am Humidity3pm Pressure9am Pressure3pm Cloud9am Cloud3pm Temp9am Temp3pm RainToday RainTomorrow
106639 2011/5/23 Launceston 10.1 16.1 15.8 -1.0 -1.0 SE 31.0 NNW ... 99.0 86.0 999.2 995.2 -1.0 -1.0 13.0 15.6 Yes Yes
106640 2014/12/9 GoldCoast 19.3 31.7 36.0 -1.0 -1.0 SE 80.0 NNW ... 75.0 76.0 1013.8 1010.0 -1.0 -1.0 26.0 25.8 Yes Yes
106641 2014/10/7 Wollongong 17.5 22.2 1.2 -1.0 -1.0 WNW 65.0 WNW ... 61.0 56.0 1008.2 1008.2 -1.0 -1.0 17.8 21.4 Yes No
106642 2012/1/16 Newcastle 17.6 27.0 3.0 -1.0 -1.0 -1 -1.0 NE ... 68.0 88.0 -1.0 -1.0 6.0 5.0 22.6 26.4 Yes No
106643 2014/10/21 AliceSprings 16.3 37.9 0.0 14.2 12.2 ESE 41.0 NNE ... 8.0 6.0 1017.9 1014.0 0.0 1.0 32.2 35.7 No No
## ����value_counts�����鿴ѵ������ǩ������
pd.Series(data['RainTomorrow']).value_counts()
No 82786
,Yes 23858
,Name: RainTomorrow, dtype: int64
���Ƿ������ݼ��еĸ���������Զ��������������,���ֳ�����������������ݲ�ƽ�⡱����,��ijЩ�������Ҫ����һЩ�������
## ������������һЩͳ������
data.describe()
Step4:���ӻ�����
Ϊ�˷���,�����ȼ�¼�������������������:
numerical_features = [x for x in data.columns if data[x].dtype == np.float]
category_features = [x for x in data.columns if data[x].dtype != np.float and x != 'RainTomorrow']
## ѡȡ�����������ǩ��ϵ�ɢ����ӻ�
sns.pairplot(data=data[['Rainfall',
'Evaporation',
'Sunshine'] + ['RainTomorrow']], diag_kind='hist', hue= 'RainTomorrow')
plt.show()
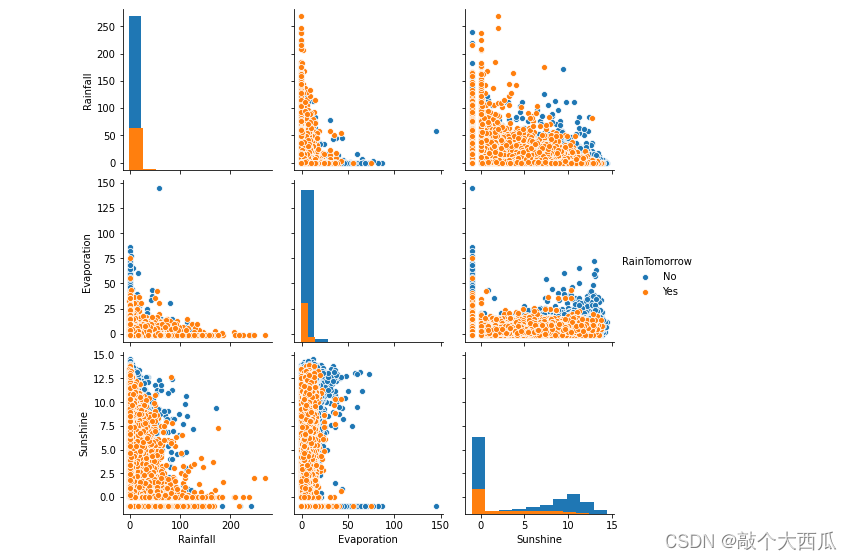
����ͼ���Է���,��2D����²�ͬ��������϶��ڵڶ��������벻�����ɢ��ֲ�,�Լ���ŵ�������������Ե�Sunshine��������������ϸ�������������
for col in data[numerical_features].columns:
if col != 'RainTomorrow':
sns.boxplot(x='RainTomorrow', y=col, saturation=0.5, palette='pastel', data=data)
plt.title(col)
plt.show()
��������ͼ����Ҳ���Եõ���ͬ����ڲ�ͬ�����ϵķֲ�������������ǿ��Է���Sunshine,Humidity3pm,Cloud9am,Cloud3pm������������ǿ
tlog = {}
for i in category_features:
tlog[i] = data[data['RainTomorrow'] == 'Yes'][i].value_counts()
flog = {}
for i in category_features:
flog[i] = data[data['RainTomorrow'] == 'No'][i].value_counts(
```
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.title(��RainTomorrow��)
sns.barplot(x = pd.DataFrame(tlog[��Location��]).sort_index()[��Location��], y = pd.DataFrame(tlog[��Location��]).sort_index().index, color = ��red��)
plt.subplot(1,2,2)
plt.title(��Not RainTomorrow��)
sns.barplot(x = pd.DataFrame(flog[��Location��]).sort_index()[��Location��], y = pd.DataFrame(flog[��Location��]).sort_index().index, color = ��blue��)
plt.show()
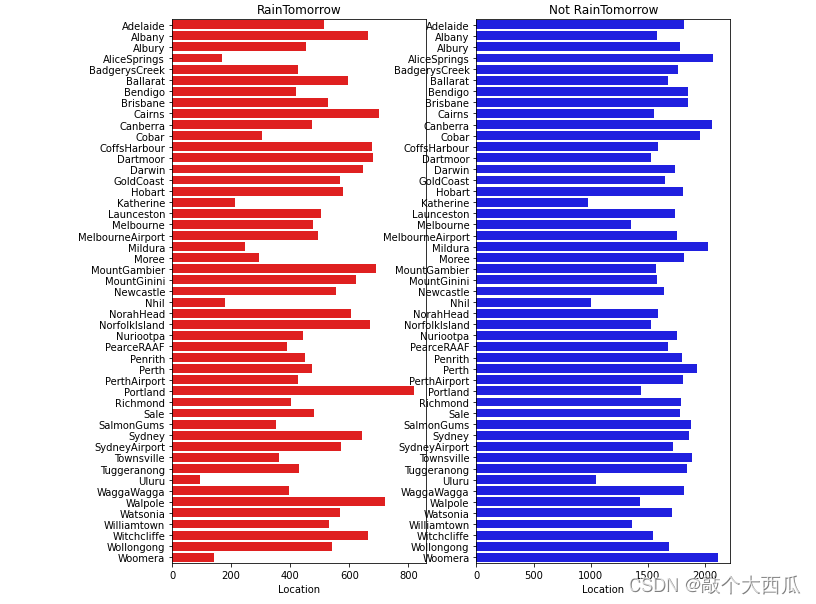
����ͼ���Է��ֲ�ͬ��������������ܴ�,��Щ�ط����Ը�������
plt.figure(figsize=(10,2))
plt.subplot(1,2,1)
plt.title(��RainTomorrow��)
sns.barplot(x = pd.DataFrame(tlog[��RainToday��][:2]).sort_index()[��RainToday��], y = pd.DataFrame(tlog[��RainToday��][:2]).sort_index().index, color = ��red��)
plt.subplot(1,2,2)
plt.title(��Not RainTomorrow��)
sns.barplot(x = pd.DataFrame(flog[��RainToday��][:2]).sort_index()[��RainToday��], y = pd.DataFrame(flog[��RainToday��][:2]).sort_index().index, color = ��blue��)
plt.show()
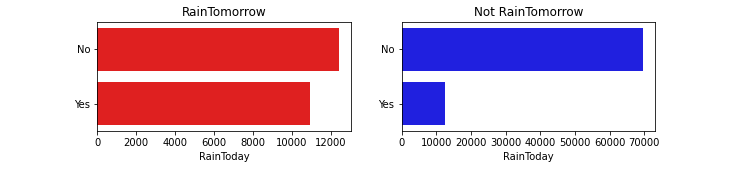
Step5:����ɢ�������б���
����XGBoost�������ַ������͵�����,������ҪһЩ�������ַ�������ת��Ϊ���ݡ�һ����ķ����ǰ����е���ͬ�������������ͬһ��ֵ,����Ů=0,��=1,����=2,���������������ֵ���� [0,��������?1]֮�������������֮��,���ж��ȱ��롢��ͱ��롢��һ������ȵȷ������Ի�ø��õ�Ч��
�C�����е���ͬ������������Ϊͬһ��ֵ
def get_mapfunction(x):
mapp = dict(zip(x.unique().tolist(),
range(len(x.unique().tolist()))))
def mapfunction(y):
if y in mapp:
return mapp[y]
else:
return -1
return mapfunction
for i in category_features:
data[i] = data[i].apply(get_mapfunction(data[i]))
�C �������ַ����������������
data[��Location��].unique()
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48])
Step6:���� XGBoost ����ѵ����Ԥ��
Ϊ����ȷ����ģ������,�����ݻ���Ϊѵ�����Ͳ��Լ�,����ѵ������ѵ��ģ��,�ڲ��Լ�����֤ģ�����ܡ�
from sklearn.model_selection import train_test_split
�Cѡ�������Ϊ0��1������ (���������Ϊ2������)
data_target_part = data[��RainTomorrow��]
data_features_part = data[[x for x in data.columns if x != ��RainTomorrow��]]
�C���Լ���СΪ20%, 80%/20%��
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
�C ����XGBoostģ��
from xgboost.sklearn import XGBClassifier
�C���� XGBoostģ��
clf = XGBClassifier()
�C��ѵ������ѵ��XGBoostģ��
clf.fit(x_train, y_train)
�C ��ѵ�����Ͳ��Լ��Ϸֲ�����ѵ���õ�ģ�ͽ���Ԥ��
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
�C����accuracy(ȷ��)��Ԥ����ȷ��������Ŀռ��Ԥ��������Ŀ�ı���������ģ��Ч��
print(��The accuracy of the Logistic Regression is:��,metrics.accuracy_score(y_train,train_predict))
print(��The accuracy of the Logistic Regression is:��,metrics.accuracy_score(y_test,test_predict))
�C�鿴�������� (Ԥ��ֵ����ʵֵ�ĸ������ͳ�ƾ���)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print(��The confusion matrix result:\n��,confusion_matrix_result)
�C��������ͼ���ڽ�����п��ӻ�
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap=��Blues��)
plt.xlabel(��Predicted labels��)
plt.ylabel(��True labels��)
plt.show()
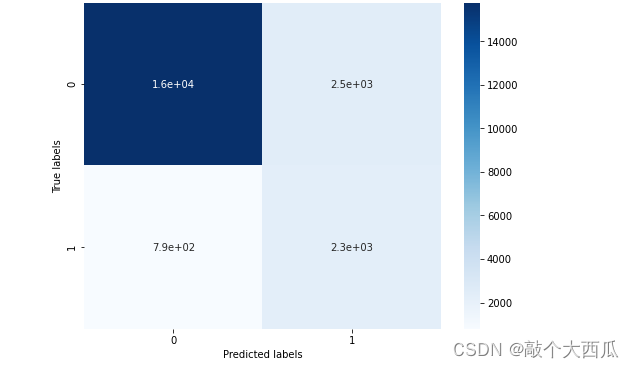
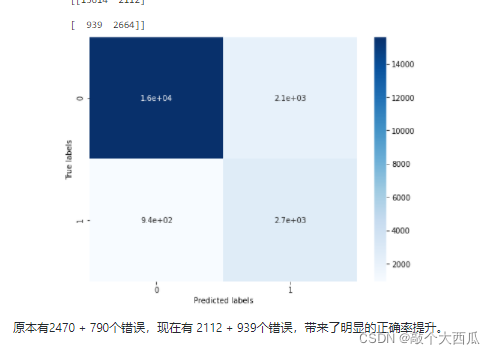
���ǿ��Է��ֹ���15759 + 2306������Ԥ����ȷ,2470 + 794������Ԥ�����
Step7: ���� XGBoost ��������ѡ��
XGBoost������ѡ����������ѡ���е�Ƕ��ʽ����,��XGboost�п���������feature_importances_ȥ�鿴��������Ҫ�ȡ�
? sns.barplot
sns.barplot(y=data_features_part.columns, x=clf.feature_importances_)
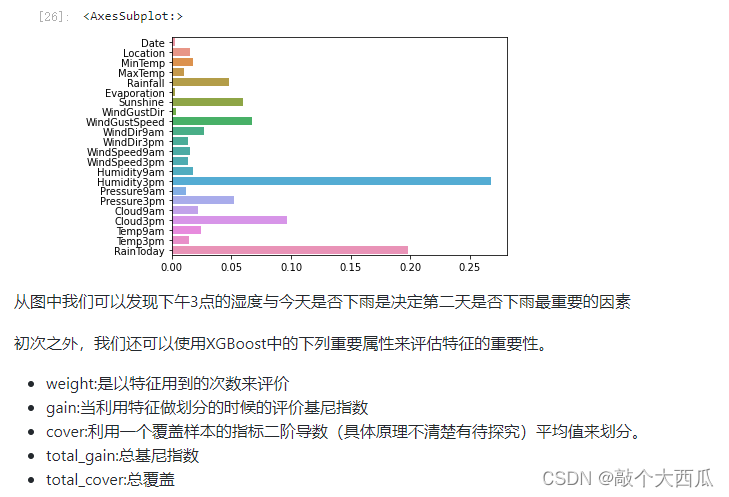
from sklearn.metrics import accuracy_score
from xgboost import plot_importance
def estimate(model,data):
#sns.barplot(data.columns,model.feature_importances_)
ax1=plot_importance(model,importance_type="gain")
ax1.set_title('gain')
ax2=plot_importance(model, importance_type="weight")
ax2.set_title('weight')
ax3 = plot_importance(model, importance_type="cover")
ax3.set_title('cover')
plt.show()
def classes(data,label,test):
model=XGBClassifier()
model.fit(data,label)
ans=model.predict(test)
estimate(model, data)
return ans
ans=classes(x_train,y_train,x_test)
pre=accuracy_score(y_test, ans)
print(��acc=��,accuracy_score(y_test,ans))
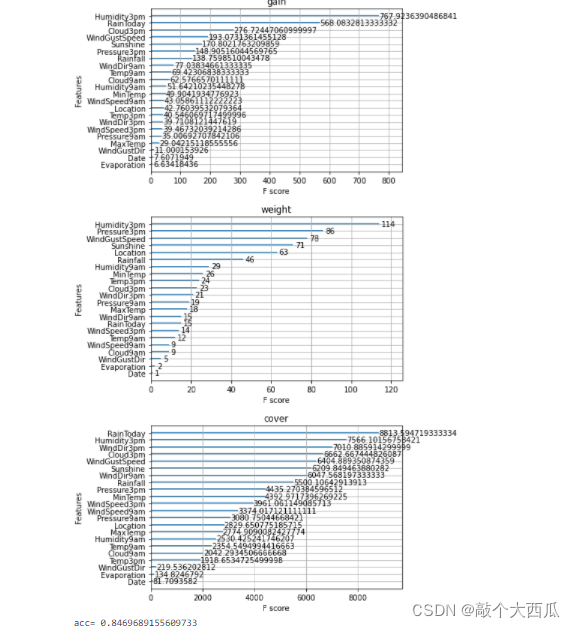
Step8: ͨ������������ø��õ�Ч��
XGBoost�а��������������ж�ģ��Ӱ��ϴ�IJ���:
learning_rate: ��ʱҲ����eta,ϵͳĬ��ֵΪ0.3��ÿһ�������IJ���,����Ҫ��̫��������ȷ�ʲ���,̫С�������ٶ�����
subsample:ϵͳĬ��Ϊ1������������ƶ���ÿ����,��������ı�������С���������ֵ,�㷨����ӱ���,��������, ȡֵ��Χ�㵽һ��
colsample_bytree:ϵͳĬ��ֵΪ1������һ�����ó�0.8���ҡ���������ÿ�����������������ռ��(ÿһ����һ������)��
max_depth: ϵͳĬ��ֵΪ6,���dz���3-10֮������֡����ֵΪ���������ȡ����ֵ���������ƹ���ϵġ�max_depthԽ��,ģ��ѧϰ�ĸ��Ӿ��塣
����ģ�Ͳ����ķ�����̰���㷨��������Ρ���Ҷ˹���εȡ��������Dz����������,���Ļ���˼�����������:�����к�ѡ�IJ���ѡ����,ͨ��ѭ������,����ÿһ�ֿ�����,������õIJ����������յĽ��
�C ��sklearn���е���������κ���
from sklearn.model_selection import GridSearchCV
�C�������ȡֵ��Χ
learning_rate = [0.1, 0.3, 0.6]
subsample = [0.8, 0.9]
colsample_bytree = [0.6, 0.8]
max_depth = [3,5,8]
parameters = { ��learning_rate��: learning_rate,
��subsample��: subsample,
��colsample_bytree��:colsample_bytree,
��max_depth��: max_depth}
model = XGBClassifier(n_estimators = 50)
�C ������������
clf = GridSearchCV(model, parameters, cv=3, scoring=��accuracy��,verbose=1,n_jobs=-1)
clf = clf.fit(x_train, y_train)
�C�������������ò���Ϊ
clf.best_params_
����ѵ�����Ͳ��Լ��Ϸֲ�������õ�ģ�Ͳ�������Ԥ��
������������� XGBoostģ��
clf = XGBClassifier(colsample_bytree = 0.6, learning_rate = 0.3, max_depth= 8, subsample = 0.9)
����ѵ������ѵ��XGBoostģ��
clf.fit(x_train, y_train)
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
������accuracy(ȷ��)��Ԥ����ȷ��������Ŀռ��Ԥ��������Ŀ�ı���������ģ��Ч��
print(��The accuracy of the Logistic Regression is:��,metrics.accuracy_score(y_train,train_predict))
print(��The accuracy of the Logistic Regression is:��,metrics.accuracy_score(y_test,test_predict))
���鿴�������� (Ԥ��ֵ����ʵֵ�ĸ������ͳ�ƾ���)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print(��The confusion matrix result:\n��,confusion_matrix_result)
�C��������ͼ���ڽ�����п��ӻ�
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap=��Blues��)
plt.xlabel(��Predicted labels��)
plt.ylabel(��True labels��)
plt.show()



end