Chapter 1 МђНщ
- етИіЯюФПвРРЕгк
CNN_Mobilenet_TrainingетИіЯюФП,дквбЭъГЩЯюФПСаБэРяУцПЩвдбАеветИіУћзжВЂдФЖСЯрЙиЮФЕЕЁЃ
етИіЯюФПдкCSDNЕФСЌНгдкДЫ
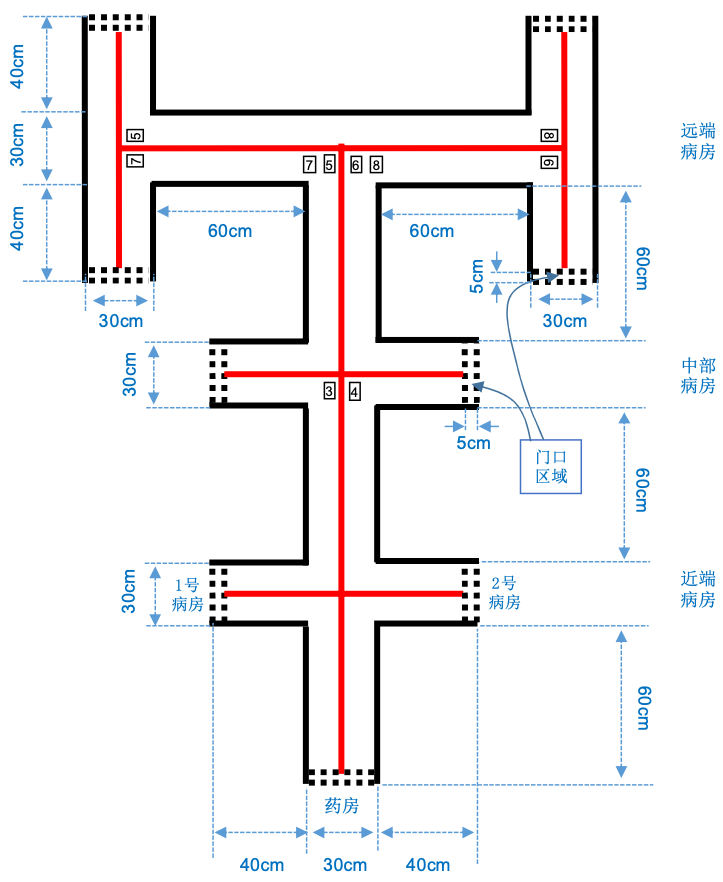
етИіЮФЕЕжївЊНВЪіЕФЪЧ2021ФъШЋЙњДѓбЇЩњЕчзгЩшМЦОКШќFЬтжаЕФЪ§зжЪЖБ№етвЛММЪѕЗжжЇ,ЛњаЕПижЦЕШЯрЙиЕФВПЗжВЂВЛЩцМАЁЃ
етИіММЪѕЗжжЇашвЊгавЛИіЪфШыКЭвЛИіЪфГі,ЪфШыЕФЪЧвЛИіАќКЌЪ§зжзжФЃЁЂГЁЕиБпЯпКЭв§ЕМЯпЕФвЛеХЭМЦЌ,ЪфГідђЪЧНЋЪЖБ№ГіЕФЪ§зжЭЈЙ§Ъ§зщЕФЗНЪНЯдЪОГіРДЁЃ
ЯТУцетеХЭМЪЧОКШќзщЮЏЛсИјЬсЙЉЕФЪ§зжзжФЃ,ЮЊСЫНЕЕЭФбЖШ,вђДЫжЛЬсЙЉСЫ8ИіЪ§зжЁЃ

Chapter 2 жЦзїЫМТЗ
Section 1 ЛЗОГгыГЩЯёаЇЙћМАЫМТЗ
БШШќГЁЕиЛљЕзЕзЩЋЮЊАзЩЋ,ЛЗОГЮЊЮобєЙтжБЩфЕФздШЛЙтееУїМАЖЅжУЖрЕЦееУїЛЗОГ,дке§ЪНБШШќЪБВЛЕУгаЬиЪтееУїЬѕМўвЊЧѓ,ЕЋЪЧПЩвддкЩуЯёЭЗЧААВзАвЛИіВЙЙтЕЦРДЯћГ§ЛЗОГЖдЩуЯёЭЗГЩЯёжЪСПЕФгАЯьЁЃ
ГЁЕиЕФЪЕМЪХФЩуаЇЙћШчЯТЭМЫљЪО:

аЁГЕГЕдиЩуЯёЭЗЮЊЪїнЎХЩзЈгУЕФ 3 Million Pixel ЩуЯёЭЗ,гЩгкДЋИаЦїжЪСПвдМАОЕЭЗжЪСП,ЛсГіЯжВаШБ(ОЕЭЗНЙЖЮдвђ)ЁЂЦЋЩЋЁЂФЃК§ЕШЧщПіЁЃОпЬхЕФЪОвтШчЯТЭМЫљЪО:

вђДЫ,ЮвЯыГіСЫШчЯТЕФЫМТЗгыЗНЗЈ:
- ВЩМЏЪ§ОнМЏЪБ,ЪЙгУЪїнЎХЩзЊгУЩуЯёЭЗНјааВЩМЏ;
- НЋдЪМЪ§ОнРћгУЖўжЕЛЏЕФЗНЗЈзЊЛЏЮЊКкАзЭМЦЌ;
- бЕСЗЪБЪЙгУОЙ§ЖўжЕЛЏДІРэЙ§КѓЕФЪ§ОнМЏ;
- дкЪЖБ№ЕФЪБКђ,НЋХФЩуЕНЕФееЦЌНјааЖўжЕЛЏДІРэ;
- ЖдЭМЦЌНјааresizeВйзї;
- ЭЈЙ§ЩшЖЈЕФБпПђжЕЖдЭМЦЌНјааЗжИю;
- НЋВЛЗћКЯЩшЖЈвЊЧѓЕФЭМЦЌЩОГ§;
- ЪЖБ№ЪЃЯТРДЕФЭМЦЌ;
Section 2 жЦзїВЂбЕСЗЪ§ОнМЏ
ЪзЯШЯШСЫНтЪВУДНазіЖўжЕЭМЯё
-
ВЪЩЋЭМЯёгаШ§ИіЭЈЕР,RGB,УПвЛИіЭЈЕРЖМга0~255,змЙВга2^24ЮЛПеМф;
-
ЛвЖШЭМЯёгавЛИіЭЈЕР,0~255,Ыљвдга256жжЛвЖШ;
-
ЖўжЕЭМЯёжЛгаСНжжбеЩЋ,КкКЭАз;
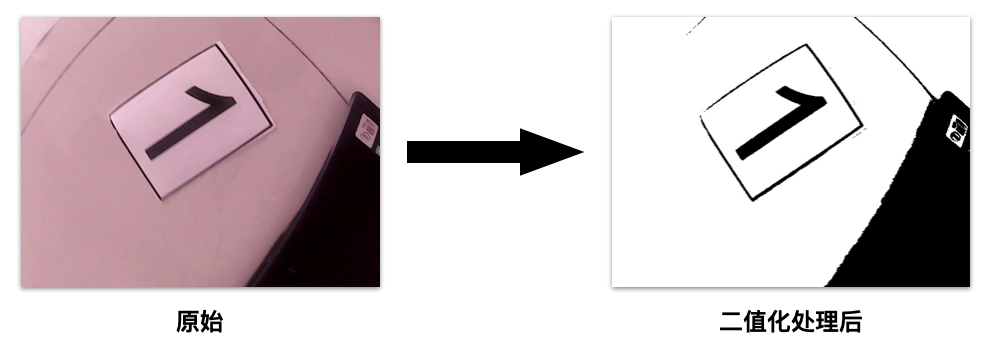
РћгУOpenCVжаЕФКЏЪ§МДПЩЭъГЩетаЉВйзї,гЩгкетВПЗжВЂВЛЪЧЮвДІРэЕФ,вђДЫЮвУЛгадЪМЕФДњТы;ЮвДгЭјЩЯевЕНСЫвЛаЉФмЙЛдЫааЕУЭЈЕФДњТыЗХдкЯТУцСЫ:
import cv2 as cv
import numpy as np
#ШЋОжуажЕ
def threshold_demo(image):
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY) #АбЪфШыЭМЯёЛвЖШЛЏ
#жБНгуажЕЛЏЪЧЖдЪфШыЕФЕЅЭЈЕРОиеѓж№ЯёЫиНјаауажЕЗжИюЁЃ
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_TRIANGLE)
print("threshold value %s"%ret)
cv.namedWindow("binary0", cv.WINDOW_NORMAL)
cv.imshow("binary0", binary)
#ОжВПуажЕ
def local_threshold(image):
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY) #АбЪфШыЭМЯёЛвЖШЛЏ
#здЪЪгІуажЕЛЏФмЙЛИљОнЭМЯёВЛЭЌЧјгђССЖШЗжВМ,ИФБфуажЕ
binary = cv.adaptiveThreshold(gray, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY, 25, 10)
cv.namedWindow("binary1", cv.WINDOW_NORMAL)
cv.imshow("binary1", binary)
#гУЛЇздМКМЦЫууажЕ
def custom_threshold(image):
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY) #АбЪфШыЭМЯёЛвЖШЛЏ
h, w =gray.shape[:2]
m = np.reshape(gray, [1,w*h])
mean = m.sum()/(w*h)
print("mean:",mean)
ret, binary = cv.threshold(gray, mean, 255, cv.THRESH_BINARY)
cv.namedWindow("binary2", cv.WINDOW_NORMAL)
cv.imshow("binary2", binary)
src = cv.imread('E:/imageload/kobe.jpg')
cv.namedWindow('input_image', cv.WINDOW_NORMAL) #ЩшжУЮЊWINDOW_NORMALПЩвдШЮвтЫѕЗХ
cv.imshow('input_image', src)
threshold_demo(src)
local_threshold(src)
custom_threshold(src)
cv.waitKey(0)
cv.destroyAllWindows()
ЖдгІДњТыЕФдЫаааЇЙћШчЯТЫљЪО:

бЕСЗЕФНсЙћЕФШШСІЭМКЭелЯпШчЯТ:

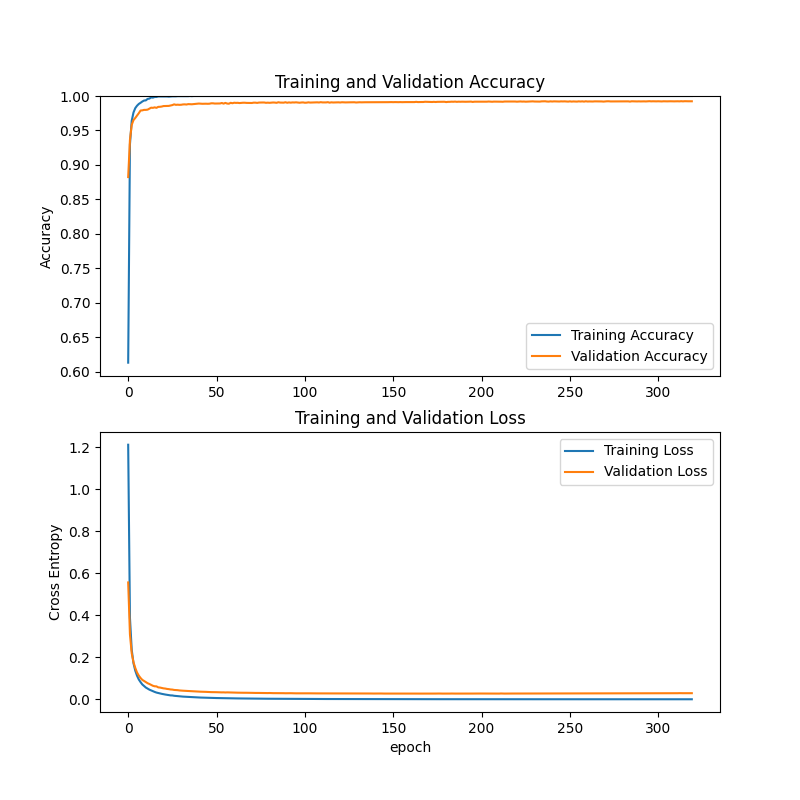
етИіЪЧЕквЛДЮбЕСЗЕФНсЙћ,5ЧЇеХ320ДЮбЕСЗ,вђЮЊЪБМфЪЧдкРДВЛМА,бЕСЗЕФДЮЪ§ЬЋЩй,ЕМжТвЛаЉЪ§зжЕФЪЖБ№ТЪвРШЛВЛааЁЃ
Section 3 ЕчФдЛЗОГХфжУ
гЩгкетвЛВПЗжЖМКЭCNN_Mobilenet_Training вЛжТ,гкЪЧЮвОЭИДжЦЙ§РДСЫ,ЕБШЛСЫ,гаЙиCUDAВПЗжПЩвджБНгТдЙ§ЁЃ
ЪзЯШЕчФдЩЯашвЊАВзАPython 3.8 вдМА conda ЛЗОГ,ПЩвдЭЈЙ§ anaconda НјааАВзА
ВЂДДНЈвЛИіаТЕФcondaЛЗОГЁЃyourEnvNameДњБэзХФуЕФаТcondaЛЗОГЕФУћзжЁЃ
conda create --name yourEnvName python=3.8
МЄЛюИеВХДДНЈЕФcondaЛЗОГ
windows ==> activate yourEnvName
linux/mac ==> source activate yourEnvName
ГЃгУЕФcondaжИСю
conda info --envs:ЪфГіжаДјгаЁО*ЁПКХЕФЕФОЭЪЧЕБЧАЫљДІЕФЛЗОГ
conda list: ПДетИіЛЗОГЯТАВзАЕФАќКЭАцБО
conda install numpy scikit-learn: АВзАnumpy sklearnАќ
conda env remove -n yourEnv: ЩОГ§ФуЕФЛЗОГ
conda env list: ВщПДЫљгаЕФЛЗОГ
жСгкШчКЮАВзАcondaЛЗОГ,ПЩвдЕЅЖРАВзАвВПЩвдЭЈЙ§anacondaвЛЦ№АВзАЁЃ
WindowsЩЯЕФПЊЗЂЛЗОГБШНЯЬиЪт,ашвЊЯШДгPythonЙйЭјЯТдиPythonАВзААќРДАВзАPython,ОпЬхЕФАВзААцБОЮЊ3.8,ЕЋЪЕМЪВтЪд3.7КЭ3.9АцБОУВЫЦвВУЛЪВУДЬЋДѓЮЪЬт,ЕЋЮвЛЙЪЧЭЦМіАВзА3.8АцБОЕФЁЃ
MacгУЛЇКЭUbuntuгУЛЇдђАДеее§ГЃЕФЗНЪНАВзАОЭаа,гаЩЖЮЪЬтПЩвдздааАйЖШЛђепGoogleЁЃ
жСгкЫЕTensorFlowЪЧАВзАCPUАцБОЕФЛЙЪЧGPUАцБОЕФ,етИіУВЫЦЪЧдк2.0АцБОжЎКѓЖМећКЯЕНвЛИіАВзААќРяШЅСЫ,ГЬађЛсЯШМьВтФуЕФЕчФдгаЮое§ШЗАВзАЯдПЈвдМАЖдгІЕФCUDAКЭCUDNN,ШчЙћФмааОЭЛсЪЙгУGPUНјаабЕСЗ,УЛгаЕФЛАОЭЛсЪЙгУCPUНјаабЕСЗЁЃ
ЮЊСЫБЃжЄбЕСЗЕФЫйЖШ,ФуЕФCPUзюКУжЇГжAVX-2жИСюМЏЛђепAVXжИСюМЏЁЃетбљГЬађФме§ГЃдЫаа,ШчЙћУЛгаAVXжИСюМЏЕФЛА,вЊУДЛЛИіЕчФдХмвЊУДДгTensorFlowЙйЭјЯТдивЛИіжЇГжВЛАќКЌAVXжИСюМЏДІРэЦїЕФTensorFlowАВзААќНјааАВзАЁЃЮввЊЪЧУЛМЧДэЕФЛА,УВЫЦБОДЮЪЙгУЕФTensorFlow2.3.1УЛгаетИіЬиЪтЕФАВзААќЁЃШчЙћФуЫЕвЊЛЛвЛИіАцБОЕФTensorFlowФи?вВВЛаа,етИіГЬађОЭжЇГж2.3.1АцБОЕФTensorFlow,вђЮЊвЊЪЙгУЕНЕБжаЕФвЛаЉЬиЪтЕФAPI,ИпвЛИіЛђепЕЭвЛИіАцБОЖМУЛгаетИіAPI,ГЬађОЭУЛгаАьЗЈХм,ЫљвджЛФметбљЁЃ
ЕБЪБХфетИіЛЗОГХфСЫВюВЛЖргавЛжмВХГЩЙІЕиШУTensorFlowХмЦ№РД,гжЛЈСЫвЛжмЪБМфШУTensorFlowдкGPUЩЯХмЦ№РДЁЃАВзАЙ§ГЬМђжБЭДПржСМЋЁЃОЭЯёЪЧБЛФГИіШЫЧПааАДЕНДВЩЯвЛбљФбЪмЁЃ

жСгкЫЕCUDAЛЙгаCUDNNЕФзАЗЈ,етИіЛЙЧыздааАйЖШЁЂCSDNЛђепдФЖСNVIDIAКЭTensorFlowЕФЙйЗНЮФЕЕ,УПвЛИізщМўЕФАцБОБиаыЖМвЊЖдгІЩЯ,етОЭЗЧГЃЗЧГЃЕиФбЪм,ОЭЫуЪЧШЋВПЖМАДееЮФЕЕНјааВйзї,вВЮДБиФмХмЦ№РД,ИњФуЕФЯдПЈЧ§ЖЏЪВУДЕФЖМгаЙиЯЕ,ЮвЩЯДЮОЭЪЧвђЮЊЧ§ЖЏАцБОЬЋИпСЫ,ВЛаа,НЕСЫЧ§ЖЏАцБОВХдЫааЦ№РДЕФЁЃУПДЮПДЕНБЈДэЮвЕФаФЧщФмгУЯТЭМНјааНтЪЭ:

ГЖдЖСЫ,змжЎ,ИњNVIDIAГЖЩЯЙиЯЕОЭЛсБфЕУВЛав,ЮоТлЪЧАВзАЙ§ГЬ,ЪЙгУЬхбщЛЙЪЧЧЎАќЁЃЛиЙще§ЬтЁЃ
ашвЊЪЙгУЕНЕФПтЮФМўСаБэвбОжЦзїЕН requirement.txt жа,ЗНБудкЛЛЕчФджЎКѓНјааАВзАЁЃ
етРяашвЊЧПЕївЛЯТ,етИіЮФМўжаЕФ TensorFlow АцБОКЭ Panda вдМА Numpy АцБОдкЪїнЎХЩЩЯДцдкГхЭЛ,АВзАВЛЩЯ,ашвЊЪжЖЏЯШАВзА TensorFlow ,етИіЪБКђЛсЖдСэЭтСНИіПтНјааНЕМЖ,ЕШАВзАЭъжЎКѓдйЪжЖЏНЋФЧСНИіПтЩ§МЖЛиШЅ,Зёдђ Keras ОЭгУВЛСЫЁЃЪЕВтвВУЛЗЂЩњЪВУДДэЮѓЁЃ
АВзАПтЮФМўЕФЪБКђ,дкЫљДДНЈЕФcondaЛЗОГЯТ,ПЩвдЭЈЙ§ШчЯТЕФУќСюНјааАВзА
pip install -r requirement.txt

АВзАЭъГЩжЎКѓЛсГіЯжШчЩЯЕФЬсЪОЁЃетИіЪБКђЪЙгУ
pip list
МьВщвЛЯТПтЮФМўЪЧЗёЖМАВзАГЩЙІЁЃ
ШчЙћrequirement.txtЖЊЪЇ,ПЩвдЭЈЙ§ЯТУцЕФДњТыжиНЈrequirement.txtЮФМў
absl-py==0.11.0
aliyun-iot-linkkit==1.2.3
astunparse==1.6.3
cachetools==4.1.1
certifi==2021.10.8
charset-normalizer==2.0.4
crcmod==1.7
cycler==0.10.0
docopt==0.6.2
gast==0.3.3
google-auth==1.23.0
google-auth-oauthlib==0.4.2
google-pasta==0.2.0
grpcio==1.34.0
h2==2.6.2
h5py==2.10.0
hpack==3.0.0
hyper==0.7.0
hyperframe==3.2.0
idna==3.2
imutils==0.5.4
keras==2.7.0
Keras-Preprocessing==1.1.2
kiwisolver==1.3.2
labelImg==1.8.6
lxml==4.6.4
Markdown==3.3.3
matplotlib==3.4.3
numpy==1.18.5
oauthlib==3.1.0
opencv-python==4.5.3.56
opt-einsum==3.3.0
paho-mqtt==1.5.1
pandas==1.3.2
Pillow==8.3.2
protobuf==3.14.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pyparsing==2.4.7
PyQt5==5.15.4
PyQt5-Qt5==5.15.2
PyQt5-sip==12.9.0
python-dateutil==2.8.2
pytz==2021.1
requests==2.26.0
requests-oauthlib==1.3.0
rsa==4.6
schedule==1.1.0
scipy==1.7.1
seaborn==0.11.2
six==1.16.0
stomp.py==7.0.0
tensorboard==2.4.0
tensorboard-plugin-wit==1.7.0
tensorflow==2.3.1
tensorflow-estimator==2.3.0
termcolor==1.1.0
tqdm==4.62.2
urllib3==1.26.6
Werkzeug==2.0.1
wrapt==1.12.1
Section 4 ГЬађНВНт
Part 1 ДгЩуЯёЭЗЛёШЁееЦЌ
def take_pic(path,cam_v):
cap = cv2.VideoCapture(cam_v)
ret, frame = cap.read()
cv2.imwrite(path, frame)
- @path :ХФЩуКѓЕФЭМЦЌБЃДцЕижЗ;
- @cam_v :бЁдёвЊЕїгУЕкМИИіЩуЯёЭЗ ЭЈГЃРДНВЩшжУЮЊ ЁБ0ЁА МДПЩ;
Part 2 АДееуажЕВУМєееЦЌ
ic.images_cut_img_input(PATH,BIN_LOW,BIN_HIGH)
PATH = './images/IMG_9281.JPG' #вЊДІРэЕФЭМЦЌТЗОЖ
BIN_LOW = 27 #ЩшЖЈЖўжЕЛЏ
BIN_HIGH = 255
ВЮЪ§ДЋШыЕНЯТУцЕФетИіКЏЪ§ЕБжа
def images_cut_img_input(IMG_PATH,BIN_LOW,BIN_HIGH):
img = cv.imread(IMG_PATH)
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) # КЏЪ§ЕФЗЕЛижЕЮЊзЊЛЛжЎКѓЕФЭМЯё
# ЭЈГЃЮЊ25,255
ret, th1 = cv.threshold(img_gray, BIN_LOW, BIN_HIGH, cv.THRESH_BINARY)
# ЖўжЕЛЏДІРэжЎКѓЕФЭМЦЌжЛга 0 КЭ 255 0ЮЊКк 255 ЮЊАз
img_list = cut_image_by_projection(th1)
count = 1
file_operate.custom_rmdir('./predict/data/')
#time.sleep(10)
for i in img_list:
# етРяПЩвдЖдЧаИюЕНЕФЭМЦЌНјааВйзї,ЯдЪОГіРДЛђепБЃДцЯТРД
cv.imwrite('./predict/data/'+str(count) + '.jpg', i)
count += 1
ЭЈЙ§ЦфжаЕФthresholdНЋЭМЦЌзЊЛЏЮЊЖўжЕЭМЦЌЁЃЕБжаЕФimg_grayВЮЪ§ЖдгІЕФЪЧcv.cvtColor(img, cv.COLOR_BGR2GRAY)
cvtColorЕФЙІФмЪЧЪЕЯжЖдЭМЦЌЩЋВЪПеМфЕФзЊЛЛ,КЏЪ§аЮЪНШчЯТ
void cvCvtColor( const CvArr* src, CvArr* dst, int code );
#УПвЛВПЗжВЮЪ§ЕФНтЪЭШчЯТ
src:дДЭМЯё(ЪфШыЕФ 8-bit , 16-bit Лђ 32-bit ЕЅБЖОЋЖШИЁЕуЪ§гАЯё)
dst:ФПБъЭМЯё(ЪфШыЕФ 8-bit , 16-bit Лђ 32-bit ЕЅБЖОЋЖШИЁЕуЪ§гАЯё)
code:
RGB <--> BGR:CV_BGR2BGRAЁЂCV_RGB2BGRAЁЂCV_BGRA2RGBAЁЂCV_BGR2BGRAЁЂCV_BGRA2BGR
RGB <--> 5X5:CV_BGR5652RGBAЁЂCV_BGR2RGB555ЁЂ(вдДЫРрЭЦ,ВЛвЛвЛСаОй)
RGB <---> Gray:CV_RGB2GRAYЁЂCV_GRAY2RGBЁЂCV_RGBA2GRAYЁЂCV_GRAY2RGBA
RGB <--> CIE XYZ:CV_BGR2XYZЁЂCV_RGB2XYZЁЂCV_XYZ2BGRЁЂCV_XYZ2RGB
RGB <--> YCrCb(YUV) JPEG:CV_RGB2YCrCbЁЂCV_RGB2YCrCbЁЂCV_YCrCb2BGRЁЂCV_YCrCb2RGBЁЂCV_RGB2YUV(НЋYCrCbгУYUVЬцДњЖМПЩвд)
RGB <--> HSV:CV_BGR2HSVЁЂCV_RGB2HSVЁЂCV_HSV2BGRЁЂCV_HSV2RGB
RGB <--> HLS:CV_BGR2HLSЁЂCV_RGB2HLSЁЂCV_HLS2BGRЁЂCV_HLS2RGB
RGB <--> CIE L*a*b*:CV_BGR2LabЁЂCV_RGB2LabЁЂCV_Lab2BGRЁЂCV_Lab2RGB
RGB <--> CIE L*u*v:CV_BGR2LuvЁЂCV_RGB2LuvЁЂCV_Luv2BGRЁЂCV_Luv2RGB
RGB <--> Bayer:CV_BayerBG2BGRЁЂCV_BayerGB2BGRЁЂCV_BayerRG2BGRЁЂCV_BayerGR2BGRЁЂCV_BayerBG2RGBЁЂCV_BayerGB2RGBЁЂ CV_BayerRG2RGBЁЂCV_BayerGR2RGB(дкCCDКЭCMOSЩЯГЃгУЕФBayerФЃЪН)
YUV420 <--> RGB:CV_YUV420sp2BGRЁЂCV_YUV420sp2RGBЁЂCV_YUV420i2BGRЁЂCV_YUV420i2RGB
ЮветРяжЛгУЕНСЫСНИіВЮЪ§,МД:src КЭ codeЁЃ
ЛЙашвЊзЂвтвЛЕу,OpenCVЕФФЌШЯЭМЦЌЭЈЕРЫГађЪЧBGRВЛЪЧRGB!!!
НгЯТРДОЭЪЧЖдЭМЦЌНјааЭЖгАЧаИю
img_list = cut_image_by_projection(th1)
етИіКЏЪ§гаШ§жжЧаИюФЃЪН,ЮвЮЊСЫФмЙЛИќМгзМШЗЕиНЋзжФЃЧаИюГіРД,ЮвбЁдёСЫЫЎЦНКЭЪњжБСНДЮЧаИюЁЃ
def cut_image_by_projection(img, cvalue=255, patern=2):
"""
ДЋШыЖўжЕЛЏДІРэжЎКѓЕФЭМЦЌ ЭЈЙ§ЭЖгАЧаИюЛёШЁУПИіЕЅЖРЕФЪ§зж
ДІРэЗНЗЈФЌШЯЮЊЯШЫЎЦНЧаИюдйЪњжБЧаИю
:param cvalue: ИљОнЧаИіЪ§жЕ,ФЌШЯЮЊ255(ИљОнАзЩЋЧаИю),ПЩбЁдё0(ИљОнКкЩЋЧаИю)
:param img:ДЋШыЕФЖўжЕЛЏЭМЦЌ
:param patern: 2 ЮЊЫЎЦНЪњжБСНДЮЧаИю,0 ЮЊЫЎЦНЧаИю, 1 ЮЊЪњжБЧаИю
:return: ЗЕЛиЧаИюЭъГЩКѓЕФЭМЦЌЪ§зщ
"""
if patern == 2:
return cut_vertical(cut_level(img, cvalue=cvalue), cvalue=cvalue)
elif patern == 1:
return cut_vertical(img, cvalue=cvalue)
else:
return cut_level(img, cvalue=cvalue)
етРяИљОнАзЩЋНјааЧаИю,вВОЭЪЧЫЕ,АбКкЩЋБпЯпЛђепКкЩЋБпПђНјааБЃСєЁЃЕБШЛвВАќРЈСЫФЧаЉГЁЕиБпЯпКЭв§ЕМЯпЁЃ
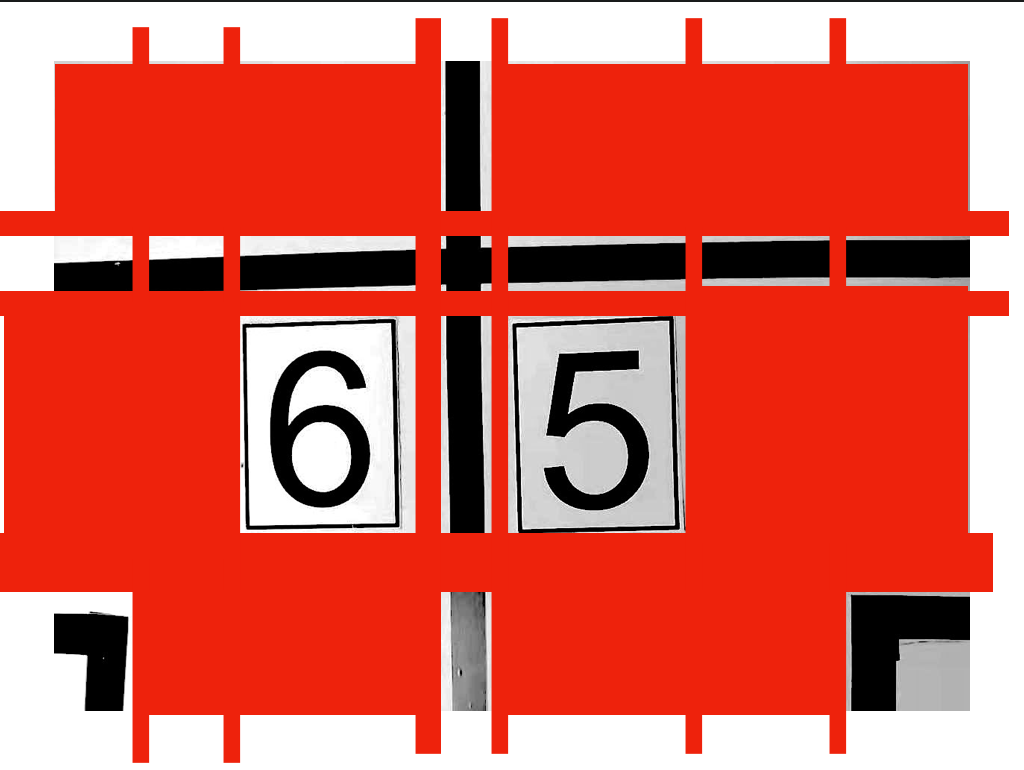
етеХЪОвтЭМ(ЮвжЛЪЧгУЭМЦЌБрМШэМўНјааЛвЖШДІРэСЫ,ЮДзіЖўжЕЛЏДІРэ)жаЕФКьЩЋЩЋПщВПЗжБэЪОЕФЪЧЧаИюВПЗж,ЧаИюГіРДЕФаЁЕФВПЗжжа,КЌгаКкЩЋЕФОЭНјааБЃСє,ВЛКЌЕФжБНгremoveЁЃвђДЫетеХЪОвтЭМСєЯТРДЕФВПЗжОЭЪЧжаМфЕФЁБ6ЁА,ЁА5ЁБЪ§зжзжФЃЁЂГЁЕиБпЯпКЭв§ЕМЯпЁЃ
ЧаИюКУЕФееЦЌЗХдкСЫpredict/dataФПТМжЎЯТЁЃАДееДгЩЯЕНЯТ,ДгзѓЕНгвЕФЫГађЖдЭМЦЌНјааБрКХЁЃ
Part 3 ЩИбЁееЦЌ
ЩИбЁееЦЌЕФЪ§жЕКЭдЪМееЦЌДѓаЁКЭЩуЯёЭЗАВзАЮЛжУгаЙиЯЕ,етРяЕФееЦЌЪЧгЩ 3 Million Pixel ЩуЯёЭЗХФЩуЕФ,ГпДчЮЊ 640 x 480,вђДЫЮвЩшЖЈЪ§зжзжФЃЕФЩИбЁГпДчЮЊ 70 x 80,ЩИбЁГіРДЕФНсЙћКЭзМШЗЖШЖМЛЙПЩвд,дкЫљгаЕФЧщПіЯТ(ЭЃЭсСЫ,ВаШБ,ФЃК§)ЖМФмзМШЗЕиНЋЪ§зжзжФЃЕФЧјгђВУМєГіРДЁЃ
import os
from PIL import Image
import glob
dir1 = './predict/data' # ЭМЦЌЮФМўДцЗХЕижЗ
def images_select(MAX_WIDTH,MAX_HEIGHT):
paths = glob.glob(os.path.join(dir1, '*.jpg'))
# ЪфГіЫљгаЮФМўКЭЮФМўМа
for file in paths:
fp = open(file, 'rb')
img = Image.open(fp)
fp.close()
width = img.size[0]
height = img.size[1]
if (width <= MAX_WIDTH) or (height <= MAX_HEIGHT):
os.remove(file)
НЋИУТЗОЖЯТЕФШЋВПееЦЌНјааБщРњ,ХаЖЯЪЧЗёЗћКЯЩшЖЈЕФГпДч,ВЛЗћКЯЕФжБНгremoveЕєЁЃ
Part 4 ЪЖБ№ееЦЌ
етИіЪЧзюЮЊЙиМќЕФвЛИіВНжш
ЯШдкmain.pyЬсЧАдЄМгдиФЃаЭ,етбљФмМѕЩй5~6УыЕФФЃаЭМгдиЪБМфЁЃ
model = tf.keras.models.load_model("models/number_rcog_mobilenet.h5")
ФЃаЭЭЈЙ§ВЛЖЯДЋВЮЕФЗНЪНДЋШыЕНdef start_recognize(model)КЏЪ§ЕБжаЁЃ
class_names = ['1','2','3','4','5','6','7','8'] # етИіЪ§зщдкФЃаЭбЕСЗЕФПЊЪМЛсЪфГі
етИіРрУћЕФОпЬхРДдДКЭЪЙгУЗНЗЈЧыВЮее CNN_Mobilenet_Training ЯюФПЕФЮФЕЕЁЃ
гЩгкЮвЪЙгУЕФЪЧmacOSЯЕЭГ,ЯЕЭГЛсздЖЏЩњГЩвЛИіУћЮЊ.DS_StoreЕФЮФМў,вђДЫгІЕБЯШМьВтетИіЮФМўЪЧЗёДцдкгкФПБъТЗОЖЕБжа,ДцдкЕФЛАЩОГ§ЕєМДПЩЁЃ
predict_dir = './predict/'
test = os.listdir(predict_dir)
if '.DS_Store' in test:
test.remove('.DS_Store')
ЩОГ§ЕєжЎКѓ,НЋУПвЛеХЭМЦЌЕФТЗОЖБЃДцЕНimagesетИіЪ§зщЕБжа
#аТНЈвЛИіСаБэБЃДцдЄВтЭМЦЌЕФЕижЗ
images = []
#ЛёШЁУПеХЭМЦЌЕФЕижЗ,ВЂБЃДцдкСаБэimagesжа
for testpath in test: #бЛЗЛёШЁВтЪдТЗОЖЕзЯТашвЊВтЪдЕФЭМЦЌ
for fn in os.listdir(os.path.join(predict_dir, testpath)):
if fn.endswith('JPG'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
elif fn.endswith('jpg'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
elif fn.endswith('png'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
ЭЈГЃРДНВ,етИіЫГађЮЪЬтВЛгУБЛПМТЧЕН,вђДЫдкЧаИюЕФЪБКђОЭвбОАДееЙцдђНјааХХађСЫ,Г§ЗЧЪЧаЁГЕВЂУЛгаАДееЙцЖЈЕФЗНЪНЭЃГЕЛђепаазп,ФЧЮввВУЛгаАьЗЈ,БЯОЙЫФЬьШ§вЙУЛгаЪБМфПМТЧФЧУДЖрЮЪЬтЁЃ
НгЯТРДОЭНјШыЕНСЫЪЖБ№ЕФГЬађПщСЫЁЃ
result_list = []
for img in images:
imgpath = img
img_init = cv2.imread(img)
img_init = cv2.resize(img_init, (224, 224)) # НЋЭМЦЌДѓаЁЕїећЕН224*224гУгкФЃаЭЭЦРэ
cv2.imwrite(img, img_init)
img = Image.open(img) # ЖСШЁЭМЦЌ
img = np.asarray(img) # НЋЭМЦЌзЊЛЏЮЊnumpyЕФЪ§зщ
outputs = model.predict(img.reshape(1, 224, 224, 3)) # НЋЭМЦЌЪфШыФЃаЭЕУЕННсЙћ
result_index = int(np.argmax(outputs))
result = class_names[result_index]
#result.setText(result)
#return img,result #ЗЕЛиЭМЦЌЕижЗКЭЪЖБ№ГіЕФЪ§зж
imgf = imgpath.split('/')[3]
imgb = imgf.split('.')[0]
#print(result)
result_list.append([imgb,result])
result_list = sorted(result_list, key=(lambda x:x[0]))
етРяашвЊЖдГЬађНјааНтЪЭ,ЪзЯШЮЊКЮвЊЖдЭМЦЌНјааresizeВйзї,вђЮЊЮвдкбЕСЗФЃаЭЕФЪБКђ,бЁдёЕФОЭЪЧ224x224,ШчЙћЮвдкЕїгУФЃаЭНјааЪЖБ№ЕФЪБКђЭМЦЌЗжБцТЪВЛЪЧ224x224,ГЬађОЭЛсБЈДэЁЃШчЙћвЊЪЙгУЦфЫћГпДчЕФЭМЦЌНјааЪЖБ№,ФЧУДдкбЕСЗЕФЪБКђОЭвЊЩшжУКУЁЃ
зюжеЪЖБ№ЭъжЎКѓЗЕЛиЕФИёЪНОЭЪЧ [[ађКХ,ЪЖБ№НсЙћ],[ађКХ,ЪЖБ№НсЙћ],[ађКХ,ЪЖБ№НсЙћ],[ађКХ,ЪЖБ№НсЙћ]]ЁЃ
ОпЬхЕФаЇЙћШчЯТЭМЫљЪО,НсЙћЮЊ ЁБ5523ЁА НсЙћЭъШЋУЛгаЮЪЬтЁЃ
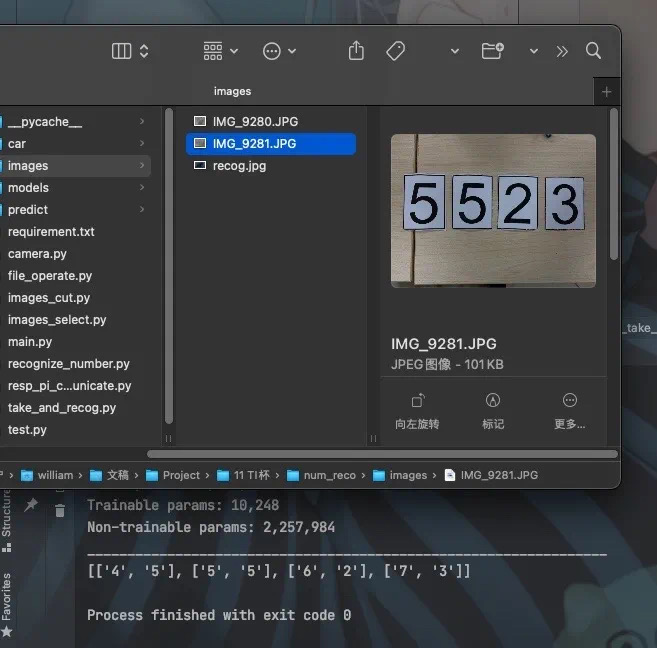
Chapter 3 аЁНс
гЩгкЖдгкгІгУГЁОАЗжЮіЪЇЮѓ,ЕМжТетЬзГЬађдкЪїнЎХЩЩЯдЫааЗЧГЃЛКТ§,ЮвКѓРДОЭПДСЫКмОУЯрЙиЕФНтОіЗНЗЈ,ОЭЪЧдкЖдГЬађНјаабЕСЗЕФЪБКђ,гІЕБЪЙгУINT8ФЃаЭСПЛЏ,вВОЭЪЧ8 Bit,ЖјЗЧФПЧАЪЙгУЕФfloat 32(ЮвЭќМЧЪЧfloat32 ЛЙЪЧ float 64СЫ,ЗДе§ЭІДѓЕФ),етОЭашвЊЖдбЕСЗЕФГЬађНјааДѓИЁЖЏИФЖЏСЫ,ЮвУЛгаетИіФмСІИФГЬађ,вђДЫвВОЭУЛгаАьЗЈНјаабщжЄЁЃШЛКѓбЕСЗЪЙгУЕФЪ§ОнМЏЕФЭМЦЌГпДчвВгІЪЪЕБНЕЕЭ,640x480ЕФЗжБцТЪЬЋИпСЫ,гІЕБНЕЕЭЕН64x48ЕФЗжБцТЪМДПЩЁЃЖјЪЖБ№гУЕФееЦЌЗжБцТЪвВгІИУЪЧ64x48ЛђепИќЕЭ,етбљВХФмдкЪїнЎХЩетжжЕЭадФмЕФЛњЦїЩЯдЫааЦ№РДЁЃ
змжЎ,етЦЊЮФЕЕЩцМАЕНСЫTensorFlowЕФгІгУ,здМКбЕСЗЕФЪ§ОнМЏЕФгІгУвдМАаЁВПЗжЕФOpenCVЕФгІгУЁЃ
ЯЃЭћВПЗжДњТы,ЫМТЗФмЙЛгаЫљАяжњЁЃ
ЯогкБОШЫЫЎЦН,ШчЙћЮФЕЕКЭДњТыгаБэЪіВЛЕБжЎДІ,ЛЙЧыВЛСпДЭНЬЁЃ
Chapter 4 ЭъећГЬађ
ГЬађЕФЭъГЩФПТМШчЯТ
ЦфжаЕФmodelsРяЕФФЃаЭашвЊИљОн CNN_Mobilenet_Training ЯюФПНјаабЕСЗЁЃ
imagesРяЕФееЦЌЮёБиЪЙЗжБцТЪЮЊ640x480ШЛКѓУќУћвЛжТМДПЩЁЃ
етбљОЭПЩвддкЖЊЪЇГЬађЕФЧщПіЯТЖдЯюФПНјаажиНЈЁЃ
Section 1 main.py
import take_and_recog
import tensorflow as tf
def TwoDConverToOneD(List):
new_list = []
for line in List:
new_list.append(line[1])
return new_list
if __name__ == '__main__':
model = tf.keras.models.load_model("models/number_rcog_mobilenet.h5")
print(TwoDConverToOneD(take_and_recog.photo_take_and_recog(model)))
Section 2 camera.py
import cv2
def take_pic(path,cam_v):
cap = cv2.VideoCapture(cam_v)
ret, frame = cap.read()
cv2.imwrite(path, frame)
Section 3 take_and_recog.py
import images_cut as ic
import images_select
import recognize_number
import camera
def photo_take_and_recog(model):
# вЊВУМєЕФееЦЌЕФБЃДцЕижЗКЭуажЕЩшжУВЮЪ§
PATH = './images/IMG_9281.JPG'
BIN_LOW = 27
BIN_HIGH = 255
# ЩИбЁееЦЌЕФГЄПэВЮЪ§
MAX_WIDTH = 70 #70,80
MAX_HEIGHT = 80
#camera.take_pic(PATH,0) #ХФееБЃДцТЗОЖКЭЯрЛњЮЛ
#АДееуажЕЩшжУВУМєееЦЌ
ic.images_cut_img_input(PATH,BIN_LOW,BIN_HIGH)
#ЩИбЁГіЪ§зжХЦЕФЧјгђ
images_select.images_select(MAX_WIDTH,MAX_HEIGHT)
return recognize_number.start_recognize(model)
Section 4 images_cut.py
import cv2 as cv
import numpy as np
import file_operate
import time
def count_number(num_list, num):
"""
ЭГМЦвЛЮЌЪ§зщжаФГИіЪ§зжЕФИіЪ§
:param num_list:
:param num:
:return: numЕФЪ§СП
"""
t = 0
for i in num_list:
if i == num:
t += 1
return t
def cut_level(img, cvalue=255):
"""
ЭЖгАЗЈЫЎЦНЧаИювЛеХЭМЦЌ жївЊДІРэЖрааЮФБО
:param cvalue: ЧаИюЯпЕФбеЩЋ
:param img: ДЋШыЮЊвЛеХЭМЦЌ
:return: ЫЎЦНЧаИюжЎКѓЕФЭМЦЌЪ§зщ
"""
r_list = []
end = 0
for i in range(len(img)):
if count_number(img[i], cvalue) >= img.shape[1]:
star = end
end = i
if end - star > 1:
# ШчЙћЯрВюжЕДѓгквЛЕФЪБКђОЭЫЕУїПчЙ§Д§ЧаИюЕФЧјгђ,
# ИљОн star КЭend ЕФжЕОЭПЩвдЛёШЁЧјгђ
r_list.append(img[star:end, :])
return r_list
def cut_vertical(img_list, cvalue=255):
"""
ЭЖгАЗЈЪњжБЧаИюЭМЦЌЕФЪ§зщ
:param img_list: ДЋШыЕФЪ§ОнЮЊвЛИігЩ(ЖўЮЌ)ЭМЦЌЙЙГЩЕФЪ§зщ,ВЛЪЧЕЅДПЕФЭМЦЌ
:param cvalue: ЧаИюЕФжЕ ЭЌcut_levelжаЕФcvalue
:return: ЧаИюжЎКѓЕФЭМЦЌЕФЪ§зщ
"""
# ШчЙћДЋШыЕФЪЧвЛИіЦеЭЈЕФЖўжЕЛЏЕФЭМЦЌ,дђашвЊЪзЯШНЋетИіЖўжЕЛЏЕФЭМЦЌЩ§ЮЌЮЊЭМЦЌЕФЪ§зщ
if len(np.array(img_list).shape) == 2:
img_list = img_list[None]
r_list = []
for img_i in img_list:
end = 0
for i in range(len(img_i.T)):
if count_number(img_i.T[i], cvalue) >= img_i.shape[0]:
star = end
end = i
if end - star > 1:
r_list.append(img_i[:, star:end])
return r_list
def cut_image_by_projection(img, cvalue=255, patern=2):
"""
ДЋШыЖўжЕЛЏДІРэжЎКѓЕФЭМЦЌ ЭЈЙ§ЭЖгАЧаИюЛёШЁУПИіЕЅЖРЕФЪ§зж
ДІРэЗНЗЈФЌШЯЮЊЯШЫЎЦНЧаИюдйЪњжБЧаИю
:param cvalue: ИљОнЧаИіЪ§жЕ,ФЌШЯЮЊ255(ИљОнАзЩЋЧаИю),ПЩбЁдё0(ИљОнКкЩЋЧаИю)
:param img:ДЋШыЕФЖўжЕЛЏЭМЦЌ
:param patern: 2 ЮЊЫЎЦНЪњжБСНДЮЧаИю,0 ЮЊЫЎЦНЧаИю, 1 ЮЊЪњжБЧаИю
:return: ЗЕЛиЧаИюЭъГЩКѓЕФЭМЦЌЪ§зщ
"""
if patern == 2:
return cut_vertical(cut_level(img, cvalue=cvalue), cvalue=cvalue)
elif patern == 1:
return cut_vertical(img, cvalue=cvalue)
else:
return cut_level(img, cvalue=cvalue)
def images_cut_img_input(IMG_PATH,BIN_LOW,BIN_HIGH):
img = cv.imread(IMG_PATH)
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) # КЏЪ§ЕФЗЕЛижЕЮЊзЊЛЛжЎКѓЕФЭМЯё
# ЭЈГЃЮЊ25,255
ret, th1 = cv.threshold(img_gray, BIN_LOW, BIN_HIGH, cv.THRESH_BINARY)
# ЖўжЕЛЏДІРэжЎКѓЕФЭМЦЌжЛга 0 КЭ 255 0ЮЊКк 255 ЮЊАз
img_list = cut_image_by_projection(th1)
count = 1
file_operate.custom_rmdir('./predict/data/')
#time.sleep(10)
for i in img_list:
# етРяПЩвдЖдЧаИюЕНЕФЭМЦЌНјааВйзї,ЯдЪОГіРДЛђепБЃДцЯТРД
cv.imwrite('./predict/data/'+str(count) + '.jpg', i)
count += 1
Section 5 file_operate.py
import os
import shutil
def custom_rmdir(rootdir):
filelist=os.listdir(rootdir)
for f in filelist:
filepath = os.path.join( rootdir, f )
if os.path.isfile(filepath):
os.remove(filepath)
#print(filepath+" removed!")
elif os.path.isdir(filepath):
shutil.rmtree(filepath,True)
#print("dir "+filepath+" removed!")
Section 6 images_select.py
import os
from PIL import Image
import glob
dir1 = './predict/data' # ЭМЦЌЮФМўДцЗХЕижЗ
def images_select(MAX_WIDTH,MAX_HEIGHT):
paths = glob.glob(os.path.join(dir1, '*.jpg'))
# ЪфГіЫљгаЮФМўКЭЮФМўМа
for file in paths:
fp = open(file, 'rb')
img = Image.open(fp)
fp.close()
width = img.size[0]
height = img.size[1]
if (width <= MAX_WIDTH) or (height <= MAX_HEIGHT):
os.remove(file)
Section 7 recognize_number.py
import os
import numpy as np
import cv2
from PIL import Image
def start_recognize(model):
model.summary() #ЪфГіФЃаЭИїВуЕФВЮЪ§зДПі
class_names = ['1','2','3','4','5','6','7','8'] # етИіЪ§зщдкФЃаЭбЕСЗЕФПЊЪМЛсЪфГі
#вЊдЄВтЕФЭМЦЌБЃДцдкетРя
predict_dir = './predict/'
test = os.listdir(predict_dir)
if '.DS_Store' in test:
test.remove('.DS_Store')
#аТНЈвЛИіСаБэБЃДцдЄВтЭМЦЌЕФЕижЗ
images = []
#ЛёШЁУПеХЭМЦЌЕФЕижЗ,ВЂБЃДцдкСаБэimagesжа
for testpath in test: #бЛЗЛёШЁВтЪдТЗОЖЕзЯТашвЊВтЪдЕФЭМЦЌ
for fn in os.listdir(os.path.join(predict_dir, testpath)):
if fn.endswith('JPG'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
elif fn.endswith('jpg'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
elif fn.endswith('png'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
result_list = []
for img in images:
imgpath = img
#print(img)
img_init = cv2.imread(img)
img_init = cv2.resize(img_init, (224, 224)) # НЋЭМЦЌДѓаЁЕїећЕН224*224гУгкФЃаЭЭЦРэ
cv2.imwrite(img, img_init)
img = Image.open(img) # ЖСШЁЭМЦЌ
img = np.asarray(img) # НЋЭМЦЌзЊЛЏЮЊnumpyЕФЪ§зщ
outputs = model.predict(img.reshape(1, 224, 224, 3)) # НЋЭМЦЌЪфШыФЃаЭЕУЕННсЙћ
result_index = int(np.argmax(outputs))
result = class_names[result_index]
#result.setText(result)
#return img,result #ЗЕЛиЭМЦЌЕижЗКЭЪЖБ№ГіЕФЪ§зж
imgf = imgpath.split('/')[3]
imgb = imgf.split('.')[0]
#print(result)
result_list.append([imgb,result])
result_list = sorted(result_list, key=(lambda x:x[0]))
return result_list #ЗЕЛиЖўЮЌСаБэ,ЕквЛЯюЪЧееЦЌЫГађДѓаЁ,ЕкЖўЯюЪЧЪЖБ№ГіКѓЕФЪ§зж