ЬтФП
Bib
@inproceedings{Anh:2018:22812285,
author={Anh T Pham and Raviv Raich and Xiaoli Z Fern and Weng-Keen Wong and Xinze Guan},
title={Discriminative Probabilistic Framework for Generalized Multi-Instance Learning},
booktitle={2018 {IEEE} International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={2281--2285},
year={2018},
organization={IEEE}
}
еЊвЊ
ЖрЪЕР§бЇЯАЪЧвЛИіПђМм,гУгкДггЩАќМЖБ№БъМЧЕФЪЕР§АќзщГЩЕФЪ§ОнжабЇЯАЁЃЖрЪЕР§бЇЯАжаЕФвЛИіГЃМћМйЩшЪЧ,ЕБЧвНіЕБАќжажСЩйвЛИіЪЕР§ЮЊе§ЪБ,АќБъЧЉЮЊе§ЁЃдкЪЕМљжа,етИіМйЩшПЩФмЛсБЛЮЅЗДЁЃР§Шч,зЈМвПЩФмЛсЮЊАќКЌаэЖрЪЕР§ЕФАќЬсЙЉрадгЕФБъЧЉ,вдМѕЩйБъМЧЪБМфЁЃ
дкетРя,ЮвУЧПМТЧЙувхЕФЖрЪЕР§бЇЯА,ЫќМйЩшАќБъЧЉЪЧЛљгкАќжае§ЪЕР§ЕФЪ§СПЗЧШЗЖЈадШЗЖЈЕФЁЃетжжЩшжУЕФЬєеНЪЧЭЌЪБбЇЯАЪЕР§ЗжРрЦїКЭЮДжЊЕФАќБъЧЉИХТЪЙцдђЁЃБОЮФЪЙгУОпгаОЋШЗКЭгааЇЭЦРэЕФХаБ№ИХТЪЭМФЃаЭНтОіСЫЙувхЖрЪЕР§бЇЯАЁЃЖдКЯГЩЪ§ОнКЭецЪЕЪ§ОнЕФЪЕбщЫЕУїСЫЫљЬсГіЕФЗНЗЈЯрЖдгкЦфЫћЗНЗЈЕФгааЇад,АќРЈФЧаЉзёбДЋЭГЖрЪЕР§бЇЯАМйЩшЕФЗНЗЈЁЃ
ЗНЗЈИХЪі
БГОА
дкЪЕМЪжа,БъМЧАќБъЧЉЕФЙ§ГЬЭЈГЃЪЧрадгЧвВЛОЋШЗЕФ,ЮЅЗДСЫЛљгкДцдкЕФМйЩшЁЃ
ЯрЙиИХФю
ЙувхЖрЪЕР§бЇЯА: ШчЙћзЈМвШЯЮЊАќжаДцдкзуЙЛЪ§СПЕФбєадЪЕР§,ЫћУЧПЩФмжЛЛсНЋДќзгБъМЧЮЊбєадЁЃР§Шч,вЛИіЭМЯёБЛБъМЧЮЊЁАЩСжЁБЕБЧвНіЕБЫќАќКЌГЌЙ§ЪЎИіЁАЪїЁБЖЮЁЃ
ВНжш

БОЮФЬсГіСЫвЛжжгУгкЙувхЖрЪЕР§бЇЯАЕФХаБ№ИХТЪЭМФЃаЭЁЃНЋАќБъЧЉгыАќжае§Р§ЕФЪ§СПЯрЙиСЊЁЃ
ФПБъ:ЕУЕНЪЕР§МЖЗжРрЦїЁЂАќБъЧЉЗжРрЦї
вЛЁЂЪЕР§МЖЗжРрЦї:НЋЪЕР§ЬиеїЯђСПгыЯргІЕФЪЕР§БъЧЉЯрЙиСЊ(ТпМЛиЙщКЏЪ§НЈФЃ)
ЪЕР§ЕФБъЧЉЭЈЙ§ЭЈЙ§АќжаИУЪЕР§ЖдгІЕФЬиеїЯђСПЕУЕН;
w
w
wЪЧТпМЛиЙщВЮЪ§
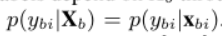
ЖўЁЂАќБъЧЉЦї:АќБъЧЉЭЈЙ§е§ЪЕР§ЕФЪ§СПгыЪЕР§БъЧЉЯрЙиСЊ;
N
b
N_b
Nb?ЪЧАќжае§ЪЕР§Ъ§СП;
v
v
vЪЧАќБъЧЉЦїВЮЪ§ЯђСП
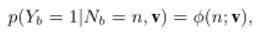
Ш§жждЄВтАќБъЧЉИХТЪЕФЗНЪН:
ЗНЪНвЛ:
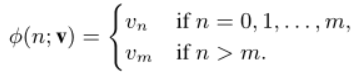
v
=
[
v
0
,
v
1
,
Ё
,
v
m
]
\textbf{v}=[v_0,v_1,\dots,v_m]
v=[v0?,v1?,Ё,vm?]ИУФЃаЭвдЖРСЂЕФЗНЪНЮЊе§ЪЕР§Ъ§ЕФУПИіПЩФмжЕЗжХфДќБъЧЉИХТЪ
ЗНЪНЖў:
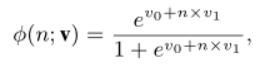
v
=
[
v
0
,
v
1
]
\textbf{v}=[v_0,v_1]
v=[v0?,v1?],ЕБ
v
1
\textbf{v}_1
v1?>0ЪБ,е§УцБъМЧДќзгЕФИХТЪЫцзХе§УцЪЕР§БъЧЉЕФЪ§СПЖјдіМгЁЃ
ЗНЪНШ§:
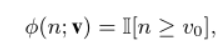
v
=
[
v
0
]
\textbf{v}=[v_0]
v=[v0?],ШчЙћДќзгжаЕФе§УцЪЕР§ЕФЪ§СПДѓгкЛђЕШгкv0,дђИУФЃаЭЬсЙЉЖдДќзгЕФе§УцБъЧЉЕФШЗЖЈадЗжХф
ФПБъ:бЇЯАЪЕР§ЗжРрЦїВЮЪ§wЯђСПКЭbagБъМЧВЮЪ§ЯђСПv
ЪЕбщ
HJA bird songЁЂMSCV2 image annotation
НЋМИИіРрЪгЮЊе§Рр,ЦфгрРрЪгзїИКРрРДаЮГЩСНРрЪ§ОнМЏ