[�����Ķ��ʼ�]2019_IJCAI_Deep Adversarial Social Recommendation
�������ص�ַ: https://www.ijcai.org/Proceedings/2019/0187.pdf
�����ڿ�:IJCAI
Publish time: 2019
������λ:
- Wenqi Fan1, Tyler Derr2, Yao Ma2, Jianping Wang1, Jiliang Tang2and Qing Li3
- 1Department of Computer Science, City University of Hong Kong
- 2Data Science and Engineering Lab, Michigan State University
- 3Department of Computing,The Hong Kong Polytechnic University
- wenqifan03@gmail.com, {derrtyle, mayao4}@msu.edu, jianwang@cityu.edu.hk, tangjili@msu.edu, csqli@comp.polyu.edu.hk
���ݼ�: �����еĽ���
- Ciao http://www.cse.msu.edu/��tangjili/trust.html (�������߸�����)
- Epinions http://www.cse.msu.edu/��tangjili/trust.html (�������߸�����)
����:
����:
�����������
- �Կ����罻�Ƽ� (д���ص�)
��Ҫ�������µ�: 2018_NACAL_KBGAN: Adversarial Learning for Knowledge Graph Embeddings��GANs��Knowledge graph embeddings(KGE)����,�����KGE��Ч��,��Եľ���negative smaple�����ľͰ�Adversial Learning����SoRec��,�������negative sample
- (1) In this paper, we present a Deep Adversarial SOcial recommendation model (DASO), which learns separated user representations in item domain and social domain. (�ڱ�����,���������һ����ȶԿ�������Ƽ�ģ��(DASO),��ģ��ѧϰ��Ŀ����������������û���ʾ��)
- (2) Particularly, we propose to transfer users�� information from social domain to item domain by using a bidirectional mapping method. (�ر��,���ǽ���ʹ��˫��ӳ���������û�����Ϣ���罻����ת�Ƶ���Ŀ����)
- (3) In addition, we also introduce the adversarial learning to optimize our entire framework by generating informative negative samples. (����,���ǻ��������Կ�ʽѧϰ,ͨ��������Ϣ�ḻ�ĸ��������Ż����ǵ�������ܡ�)
- (4) �������������б���,��ͨ�õ�ģ�͵�������һ���ġ�
Abstract
- Recent years have witnessed rapid developments on social recommendation techniques for improving the performance of recommender systems due to the growing influence of social networks to our daily life. The majority of existing social recommendation methods unify user representation for the user-item interactions (item domain) and user-user connections (social domain). (������,�����罻����������ճ������Ӱ��Խ��Խ��,Ϊ������Ƽ�ϵͳ������,�罻�Ƽ������õ��˿��ٷ�չ�����еĴ�����罻�Ƽ�����ͳһ���û���Ŀ����(��Ŀ��)���û�����(�罻��)���û���ʾ��)
- However, it may restrain user representation learning in each respective domain, since users behave and interact differently in two domains, which makes their representations to be heterogeneous. (Ȼ��,�����û����������е���Ϊ�ͽ�����ͬ,��ʹ�����ǵı�ʾ�����칹��,��������ܻ�����ÿ�����е��û���ʾѧϰ)
- In addition, most of traditional recommender systems can not efficiently optimize these objectives, since they utilize negative sampling technique which is unable to provide enough informative guidance towards the training during the optimization process. (����,�������ͳ���Ƽ�ϵͳ������Ч���Ż���ЩĿ��,��Ϊ����ʹ������������,��Ϊ�Ż������е�ѵ���ṩ�㹻����Ϣָ����)
- In this paper, to address the aforementioned challenges, we propose a novel Deep Adversarial SOcial recommendation DASO. (���������һ���µ���ȶԿ�������Ƽ�DASO��)
- It adopts a bidirectional mapping method to transfer users�� information between social domain and item domain using adversarial learning. (������˫��ӳ������,ͨ���Կ�ʽѧϰ���罻�������Ŀ����֮�䴫���û���Ϣ��)
- Comprehensive experiments on two realworld datasets show the effectiveness of the proposed method.
1 Introduction
-
(1) In recent years, we have seen an increasing amount of attention on social recommendation, which harnesses social relations to boost the performance of recommender systems [Tang et al., 2016b; Fan et al., 2019; Wang et al., 2016]. Social recommendation is based on the intuitive ideas that people in the same social group are likely to have similar preferences, and that users will gather information from their experienced friends (e.g., classmates, relatives, and colleagues) when making decisions. Therefore, utilizing users�� social relations has been proven to greatly enhance the performance of many recommender systems [Ma et al., 2008; Fan et al., 2019; Tang et al., 2013b; 2016a]. (������,���ǿ�������Ƽ�Խ��Խ�ܵ���ע,����������ϵ�����Ƽ�ϵͳ������[Tang����,2016b;Fan����,2019;Wang����,2016]�� �罻�Ƽ�����һ��ֱ�۵��뷨,��ͬһ�罻Ⱥ���е��˿��������Ƶ�ƫ��,�û�����������ʱ��Ӿ���ḻ������(����ͬѧ�����ݺ�ͬ��)�����ռ���Ϣ�� ���,�����û�������ϵ�ѱ�֤���ܼ������������Ƽ�ϵͳ������[Ma����,2008��;Fan����,2019��;Tang����,2013b;2016a]��)

-
(2) In Figure 1, we observe that in social recommendation we have both the item and social domains, which represent the user-item interactions and user-user connections, respectively. Currently, the most effective way to incorporate the social information for improving recommendations is when learning user representations, which is commonly achieved in ways such as, (��ͼ1��,���ǹ۲쵽,���罻�Ƽ���,����ͬʱӵ����Ŀ���罻��,���Ƿֱ�����û���Ŀ�������û�-�û����ӡ�Ŀǰ,�����罻��Ϣ�ԸĽ��Ƽ�������Ч������ ѧϰ�û���ʾ,��ͨ��ͨ�����·�ʽʵ��:)
- using trust propagation [Jamali and Ester, 2010], (ʹ�����δ���)
- incorporating a user��s social neighborhood information [Fan et al., 2018], (�ϲ��û����罻������Ϣ)
- or sharing a common user representation for the user-item interactions and social relations with a co-factorization method [Ma et al., 2008]. (����ʹ��Э���ӷֽⷽ�������û����������ϵ�Ĺ����û���ʾ)
-
However, as shown in Figure 1, although users bridge the gap between these two domains, their representations should be heterogeneous. This is because users behave and interact differently in the two domains. Thus, using a unified user representation may restrain user representation learning in each respective domain and results in an inflexible/limited transferring of knowledge from the social relations to the item domain. Therefore, one challenge is to learn separated user representations in two domains while transferring the information from the social domain to the item domain for recommendation. (Ȼ��,��ͼ1��ʾ,�����û�����������֮�����������,�����ǵı�ʾӦ�����칹�ġ� ������Ϊ�û������������е���Ϊ�ͽ�����ʽ��ͬ�����,ʹ��ͳһ���û���ʾ���ܻ�����ÿ����Ӧ�����е��û���ʾѧϰ,������֪ʶ������ϵ����Ŀ����IJ����/����ת�ơ����,һ����ս���ڽ���Ϣ���罻����ת�Ƶ���Ŀ��������Ƽ���ͬʱ,ѧϰ���������з�����û���ʾ��)
-
(3) In this paper, we adopt a nonlinear mapping operation to transfer user��s information from the social domain to the item domain, while learning separated user representations in the two domains. (�ڱ�����,���Dz���������ӳ��������û�����Ϣ���罻����ת�Ƶ���Ŀ����,ͬʱ��������������ѧϰ������û���ʾ��)
-
Nevertheless, learning the representations is challenging due to the inherent data sparsity problem in both domains. Thus, to alleviate this problem, we propose to use a bidirectional mapping between the two domains, such that we can cycle information between them to progressively enhance the user��s representations in both domains. (Ȼ��,���������������ڹ��е�����ϡ��������,���ѧϰ��Щ��ʾ������ս�ԡ����,Ϊ�˻����������,���ǽ�����������֮��ʹ��˫��ӳ��,������������������֮��ѭ����Ϣ,������ǿ�û����������еı�ʾ��)
-
However, for optimizing the user representations and item representations, most existing methods utilize the negative sampling technique, which is quite ineffective [Wang et al., 2018b]. This is due to the fact that during the beginning of the training process, most of the negative user-item samples are still within the margin to the real user-item samples, but later during the optimization process, negative sampling is unable to provide ��difficult�� and informative samples to further improve the user representations and item representations [Wang et al., 2018b; Cai and Wang, 2018]. Thus, it is desired to have samples dynamically generated throughout the training process to better guide the learning of the user representations and item representations. (Ȼ��,Ϊ���Ż��û���ʾ����Ŀ��ʾ,��������з�����ʹ������������,���Ƿdz���Ч��[Wang����,2018b]��������Ϊ����ѵ���̿�ʼʱ,����������û���������������ʵ�û��������IJ����,�����Ż����̵ĺ���,���������ṩ�����ѡ�����Ϣ�ḻ������,�Խ�һ�������û���������Ŀ����[Wang����,2018b;Cai��Wang,2018]�����,ϣ��������ѵ�������� ��̬�������� ,�Ը��õ�ָ���û���ʾ����Ŀ��ʾ��ѧϰ��)
-
(4)Recently, Generative Adversarial Networks (GANs) [Goodfellow et al., 2014], which consists of two models to process adversarial learning, have shown great success across various domains due to their ability to learn an underlying data distribution and generate synthetic samples [Mao et al., 2017; 2018; Brock et al., 2019; Liu et al., 2018; Wang et al., 2017; 2018a; Derr et al., 2019]. (���,�����ԶԿ�����(GANs) [Goodfello et al.,2014]������ģ�����,���ڴ����Կ�ѧϰ,�������ܹ�ѧϰ�ײ����ݷֲ������ɺϳ�����,�ڸ�������ȡ���˾�ɹ�)
- This is performed through the use of a generator and a discriminator. (����ͨ��ʹ������������������ʵ�ֵ�)
- The generator tries to generate realistic fake data samples to fool the discriminator, which distinguishes whether a given data sample is produced by the generator or comes from the real data distribution. (��������ͼ������ʵ�ļ�������������ƭ������,�������������ָ��������������������������ɵĻ���������ʵ�����ݷֲ���)
- A minimax game is played between the generator and discriminator, where this adversarial learning can train these two models simultaneously for mutual promotion. (���������ͼ�����֮����һ������С����,���ֶԿ���ѧϰ����ͬʱѵ��������ģ��,�Ա���ٽ���)
- In [Wang et al., 2018b] adversarial learning had been used to address the limitation of typical negative sampling.
- This is performed through the use of a generator and a discriminator. (����ͨ��ʹ������������������ʵ�ֵ�)
-
(5)Thus, we propose to harness adversarial learning in social recommendation to generate ��difficult�� negative samples to guide our framework in learning better user and item representations while further utilizing it to optimize our entire framework. (���,���ǽ���������Ƽ��������Կ���ѧϰ�����ɡ����ѵġ���������,��ָ�����ǵĿ��ѧϰ���õ��û�����Ŀ��ʾ,ͬʱ��һ���������Ż����ǵ�������ܡ�)
-
Our major contributions can be summarized as follows:
- We introduce a principled way to transfer users�� information from social domain to item domain using a bidirectional mapping method where we cycle information between the two domains to progressively enhance the user representations; (���ǽ�����һ��ԭ���Եķ���,ʹ��˫��ӳ�䷽�����û���Ϣ���罻����ת�Ƶ���Ŀ����,������������֮��ѭ����Ϣ,������ǿ�û���ʾ;)
- We propose a Deep Adversarial SOcial recommender system DASO, which can harness the power of adversarial learning to dynamically generate ��difficult�� negative samples, learn the bidirectional mappings between the two domains, and ultimately optimize better user and item representations; (���������һ����ȶԿ�������Ƽ�ϵͳDASO,�����������Կ���ѧϰ��������̬����==�����ѡ��ĸ�������==,ѧϰ��������֮���˫��ӳ��,�����Ż����õ��û�����Ŀ��ʾ;) and
- We conduct comprehensive experiments on two real-world datasets to show the effectiveness of the proposed model. (������������ʵ���ݼ��Ͻ������ۺ�ʵ��,��֤����ģ�͵���Ч�ԡ�)
2 The Proposed Framework
- Let
U
=
{
u
1
,
u
2
,
.
.
.
,
u
N
}
\mathcal{U} = \{u_1, u_2, ..., u_N\}
U={u1?,u2?,...,uN?} and
V
=
{
v
1
,
v
2
,
.
.
.
,
v
M
}
\mathcal{V} = \{v_1, v_2, ..., v_M\}
V={v1?,v2?,...,vM?} denote the sets of users and items respectively,
- where N ( M ) N (M) N(M) is the number of users (items).
- We define user-item interactions matrix
R
��
R
N
��
M
R \in R^{N\times M}
R��RN��M from user��s implicit feedback,
- where the
i
i
i,
j
j
j-th element
r
i
,
j
r_{i,j}
ri,j? is 1 if there is an interaction (e.g., clicked/bought) between user
u
i
u_i
ui? and item
v
j
v_j
vj?, and 0 other- wise.
- However, r i , j = 1 r_{i,j} = 1 ri,j?=1 does not mean user uiactually likes item v j v_j vj?.
- Similarly, r i , j = 0 r_{i,j} = 0 ri,j?=0 does not mean u i u_i ui? does not like item v j v_j vj?, since it can be that the user u i u_i ui? is not aware of the item v j v_j vj?.
- where the
i
i
i,
j
j
j-th element
r
i
,
j
r_{i,j}
ri,j? is 1 if there is an interaction (e.g., clicked/bought) between user
u
i
u_i
ui? and item
v
j
v_j
vj?, and 0 other- wise.
- The social network between users can be described by a matrix
S
��
R
N
��
N
S \in R^{N\times N}
S��RN��N,
- where s i , j = 1 s_{i,j} = 1 si,j?=1 if there is a social relation between user u i u_i ui? and user u j u_j uj?, and 0 otherwise.
- Given interactions matrix R R R and social network S S S, we aim to predict the unobserved entries (i.e., those where r i , j = 0 ri,j= 0 ri,j=0) in R R R. (������������ R R R���罻���� S S S,���ǵ�Ŀ����Ԥ�� R R R��δ�۲쵽����Ŀ(�� r i , j = 0 r_{i,j}=0 ri,j?=0��)
2.1 An Overview of the Proposed Framework
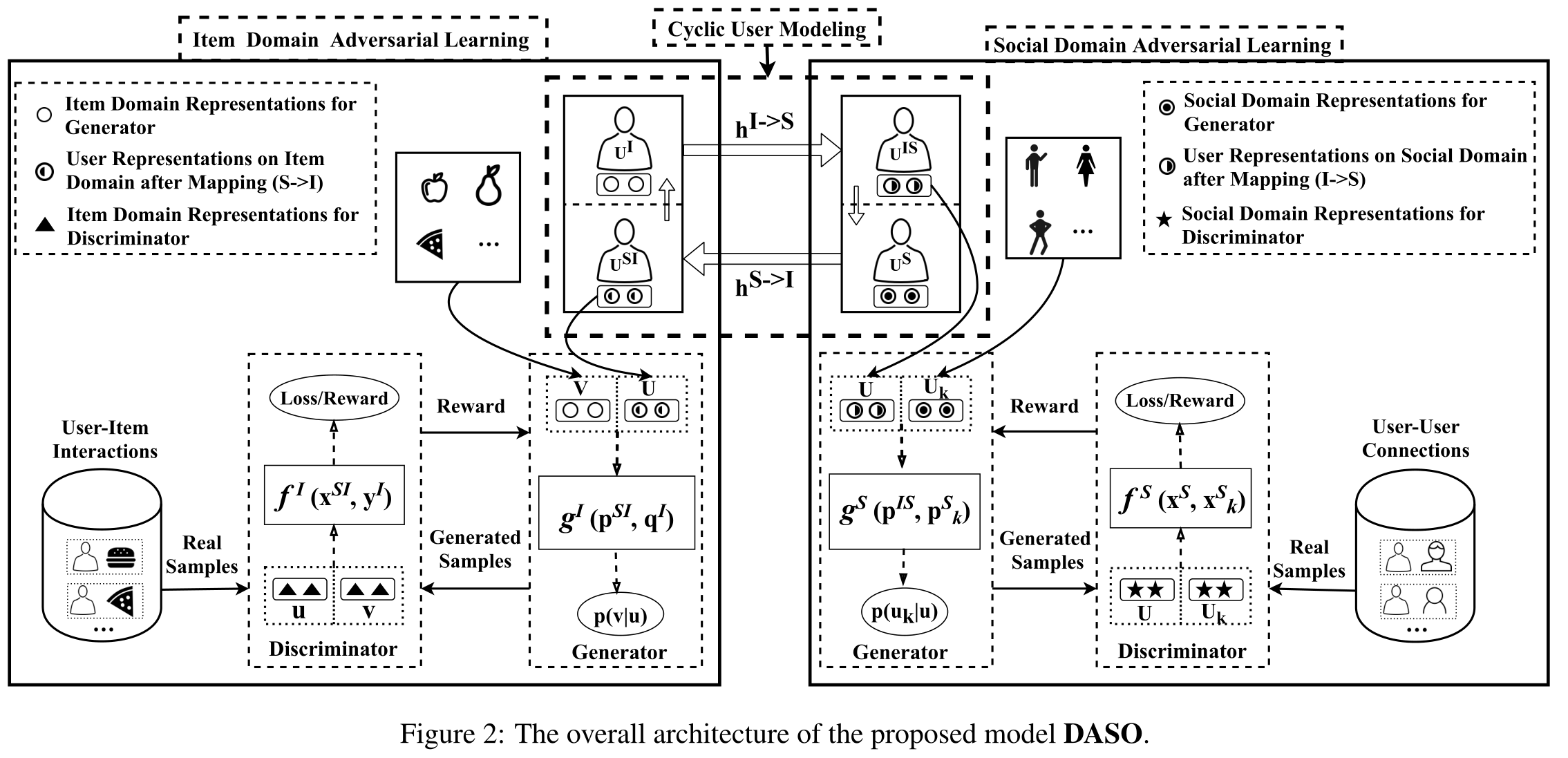
-
(1)The architecture of the proposed model is shown in Figure 2. The information is from two domains, which are the item domain I I I and the social domain S S S. (�����ģ�͵ļܹ���ͼ2��ʾ����Ϣ������������,����Ŀ��I���罻��S)
- The model consists of three components: (��ģ���������������)
- cyclic user modeling, (ѭ���û���ģ)
- item domain adversarial learning, (��Ŀ��Կ���ѧϰ)
- and social domain adversarial learning. (���罻��Կ���ѧϰ)
- The cyclic user modeling is to model user representations on two domains. (ѭ���û���ģ�����������϶��û���ʾ���н�ģ)
- The item domain adversarial learning is to adopt the adversarial learning for dynamically generating ��difficult�� and informative negative samples to guide the learning of user and item representations. (��Ŀ�� �Կ���ѧϰ �Dz��öԿ���ѧϰ ��̬ ���� �����ѡ� �� ��Ϣ�ḻ �� ������,��ָ���û�����Ŀ������ѧϰ)
- The generator is utilized to ��sample�� (recommend) items for each user and output user-item pairs as fake samples; (������ ����Ϊÿ���û���������(�Ƽ�)��Ŀ,�����û���Ŀ����Ϊ���������)
- the other is the discriminator, which distinguishes the user-item pair samples sampled from the real user-item interactions from the generated user-item pair samples. (��һ���� ������ ,��������ʵ�û�����в������û�����������������û�����������ֿ���)
- The social domain adversarial learning also similarly consists of a generator and a discriminator. (�罻����ĶԿ���ѧϰͬ����һ����������һ�����������)
- The model consists of three components: (��ģ���������������)
-
(2)There are four types of representations in the two domains.
- In the item domain
I
I
I, we have two types of representations including
- item domain representations of the generator ( p i I �� R d p^I_ i\in R^d piI?��Rd for user u i u_i ui? and q j I �� R d q^I_j \in R^d qjI?��Rd for item v j v_j vj?),
- and the item domain representations of the discriminator ( x i I �� R d x^I_i \in R^d xiI?��Rd for user u i u_i ui? and y j I �� R d y^I_j \in R^d yjI?��Rd for item v j v_j vj?).
- Social domains
S
S
S also contains two types of representations including
- the social domain representations of the generator ( p i S �� R d p^S_i \in R^d piS?��Rd for user u i u_i ui?),
- and the social domain representations of the discriminator ( x i S �� R d x^S_i \in R^d xiS?��Rd for user u i u_i ui?).
- In the item domain
I
I
I, we have two types of representations including
2.2 Cyclic User Modeling
- Cyclic user modeling aims to learn a relation between the user representations in the item domain
I
I
I and the social domain
S
S
S. As shown in the top part of Figure 2, ((ѭ���û���ģּ���˽���Ŀ��I���罻��S�е��û���ʾ֮��Ĺ�ϵ����ͼ2������ʾ)
- we first adopt a nonlinear mapping operation, denoted as h S �� I h^{S\to I} hS��I, to transfer user��s information from the social domain to the item domain, while learning separated user representations in the two domains. (�������Ȳ��÷�����ӳ�����,��ʾΪ h S �� I h^{S\to I} hS��I���û���Ϣ���罻����ת�Ƶ���Ŀ����,ͬʱѧϰ���������еĶ����û���ʾ)
- Then, a bidirectional mapping between these two domains (achieved by including another nonlinear mapping h I �� S h^{I��S} hI��S) is utilized to help cycle the information between them to progressively enhance the user representations in both domains. (Ȼ��,��������֮���˫��ӳ��(ͨ��������һ��������ӳ�� h I �� S h^{I\to S} hI��Sʵ��) ���ڰ���ѭ������֮�����Ϣ,������ǿ�������е��û���ʾ��)
2.2.1 Transferring Social Information to Item Domain
-
(1)In social networks, a person��s preferences can be influenced by their social interactions, suggested by sociologists [Fan et al., 2019; 2018; Wasserman and Faust, 1994]. Therefore, a user��s social relations from the social network should be incorporated into their user representation in the item domain. (���ѧ�ҽ���,���罻������,һ���˵�ƫ�ÿ��ܻ��ܵ����ǵ��罻������Ӱ��[Fan����,2019��;2018��;��ɪ����ʿ��,1994��]�����,�����罻������û��罻��ϵӦ�ñ�������������Ŀ���е��û���ʾ����)
-
(2)We propose to adopt nonlinear mapping operation to transfer user��s information from the social domain to the item domain. (���ǽ������������ӳ��������û���Ϣ���罻����ת�Ƶ���Ŀ����)
- More specifically, the user representation on social domain p i S p^S_i piS? is transferred to the item domain via a Multi-Layer Perceptron (MLP) denoted as h S �� I h^{S\to I} hS��I.
- The transferred user representation from social domain is denoted as p i S I p^{SI}_i piSI?. (���罻����ת�Ƶ��û���ʾ����ʾΪ)
- More formally, the nonlinear mapping is as follows:
p
i
S
I
=
h
S
��
I
(
p
i
S
)
=
W
L
?
(
?
?
?
a
(
W
2
?
a
(
W
1
?
p
i
S
+
b
1
)
+
b
2
)
.
.
.
)
+
b
L
p^{SI}_i = h^{S\to I}(p^S_i) = W_L��(�� �� ��a(W_2��a(W_1��p^S_i + b_1) + b_2). . .) + b_L
piSI?=hS��I(piS?)=WL??(???a(W2??a(W1??piS?+b1?)+b2?)...)+bL?,
- where the W s W_s Ws?, b s bs bs are the weights and biases for the layers of the neural network having L L L layers,
- and a a a is a nonlinear activation function.
2.2.2 Bidirectional Mapping with Cycle Reconstruction
-
(1)As user-item interactions and user-user connections are often very sparse, learning separated user representations is challenging. (�����û�������û�-�û�����ͨ���dz�ϡ��,���ѧϰ������û���ʾ��һ����ս��)
- Therefore, to partially alleviate this issue, we propose to utilize a bidirectional mapping between the two domains, such that we can cycle information between them to progressively enhance the user representations in both domains. (���,Ϊ�˲��ֻ����������,���ǽ�������������֮���˫��ӳ��,�������ǿ���������֮��ѭ����Ϣ,������ǿ�������е��û���ʾ��)
- To achieve this, another nonlinear apping operation, denoted as h I �� S h^{I\to S} hI��S, is adopted to transfer information from the item domain to the social domain: p i I S = h I �� S ( p i I ) p^{IS}_i = h^{I\to S}(p^I_i) piIS?=hI��S(piI?), which has the same network structure as the h S �� I h^{S\to I} hS��I.
-
(2)This Bidirectional Mapping allows knowledge to be transferred between item and social domains. To learn these mappings, we further introduce cycle reconstruction. Its intuition is that transferred knowledge in the target domain should be reconstructed to the original knowledge in the source domain. Next we will elaborate cycle reconstruction. (����˫��ӳ������֪ʶ����Ŀ���罻����֮��ת�ơ�Ϊ��ѧϰ��Щӳ��,���ǽ�һ������ѭ���ع�������ֱ����,Ŀ��������ת�Ƶ�֪ʶӦ���ؽ�ΪԴ�����е�ԭʼ֪ʶ�����������ǽ���ϸ����ѭ���ؽ���)
-
(3)For user u i u_i ui?��s item domain representation p i I p^I_i piI?, the user representation with cycle reconstruction should be able to map p i I p^I_i piI? back to the original domain, as follows, p i I ? h I �� S ( p i I ) ? h S �� I ( h I �� S ( p i I ) ) �� p i I p^I_i \longrightarrow h^{I\to S}(p^I_i) \longrightarrow h^{S\to I}(h^{I\to S}(p^I_i)) \approx p^I_i piI??hI��S(piI?)?hS��I(hI��S(piI?))��piI?.
- Likewise, for user u i u_i ui?��s social domain representation p i S p^S_i piS?, the user representation with cycle reconstruction can also bring p i S p^S_i piS? back to the original domain: p i S ? h S �� I ( p i I ) ? h I �� S ( h S �� I ( p i S ) ) �� p i S . p^S_i \longrightarrow h^{S\to I}(p^I_i) \longrightarrow h^{I\to S}(h^{S\to I}(p^S_i)) �� p^S_i. piS??hS��I(piI?)?hI��S(hS��I(piS?))��piS?.
-
(4)We can formulate this procedure using a cycle reconstruction loss, which needs to be minimized, as follows,

2.3 Item Domain Adversarial Learning
-
(1)To address the limitation of negative sampling for recommendation on the ranking task, we propose to harness adversarial learning to generate ��difficult�� and informative samples to guide the framework in learning better user and item representations in the item domain. As shown in the bottom left part of Figure 2, the adversarial learning on item domain consists of two components: (Ϊ�˽�������������������еľ�����,���ǽ������öԿ���ѧϰ���ɡ����ѡ�����Ϣ�ḻ������,��ָ����ܸ��õ�ѧϰ��Ŀ���е��û�����Ŀ��ʾ����ͼ2���½���ʾ,��Ŀ����ĶԿ���ѧϰ�������������:)
- Discriminator D I ( u i , v ; ? D I ) D^I(u_i, v; \phi^I_D) DI(ui?,v;?DI?), parameterized by ? D I \phi^I_D ?DI?, aims to distinguish the real user-item pairs ( u i , v ) (u_i, v) (ui?,v) and the user-item pairs generated by the generator. (ּ�������������û���� ( u i , v ) (u_i, v) (ui?,v)�Լ����������ɵ��û���ԡ�)
- Generator G I ( v �O u i ; �� G I ) G^I(v|u_i; \theta^I_G) GI(v�Oui?;��GI?), parameterized by �� G I \theta^I_G ��GI?, tries to fit the underlying real conditional distribution p r e a l I ( v �O u i ) p^I_{real}(v|u_i) prealI?(v�Oui?) as much as possible, and generates (or, to be more precise, selects) the most relevant items to a given user u i u_i ui?. (������ϵײ�ʵ�����ֲ� p r e a l I ( v �O u i ) p^I_{real}(v|u_i) prealI?(v�Oui?) ������(���߸�ȷ��˵,ѡ��)������û� u i u_i ui?����ص���? .)
-
(2)Formally, D I D^I DI and G I G^I GI are playing the following two-player minimax game with value function L a d v I ( G I , D I ) L^I_{adv}(G^I, D^I) LadvI?(GI,DI), (��ʽ��, D I D^I DI �� G I G^I GI��������������㼫С����ֵ��Ϸ)

2.3.1 Item Domain Discriminator Model
- (1)Discriminator D I D^I DI aims to distinguish real user-item pairs (i.e., real samples) and the generated ��fake�� samples. (������ D I D^I DIּ��������ʵ�û���Ŀ��(����ʵ����)�����ɵġ��١�������)
- The discriminator
D
I
D^I
DI estimates the probability of item
v
j
v_j
vj? being relevant (bought or clicked) to a given user
u
i
u_i
ui? using the sigmoid function and a score function
f
��
D
I
I
f^I_{��^I_D}
f��DI?I? sa follows: (������
D
I
D^I
DIʹ��sigmoid������score����������Ŀ
v
j
v_j
vj?�ĸ���?������û�
u
i
u_i
ui?���(�������)�ĸ���?)

- (2)Given real samples and generated fake samples, the objective for the discriminator D I D^I DI is to maximize the log-likelihood of assigning the correct labels to both real and generated samples. The discriminator can be optimized by minimizing the objective in eq. (1) with the generator fixed using stochastic gradient methods. (������ʵ���������ɵļ�����,������ D I D^I DI��Ŀ�������Ϊ��ʵ��������������������ȷ��ǩ�Ķ��������ԡ���������ݶȷ�,���������̶��������,��ͨ����С����ʽ(1)�е�Ŀ�����Ż���������)
2.3.2 Item Domain Generator Model
-
(1) On the other hand, the purpose of the generator G I G^I GI is to approximate the underlying real conditional distribution p r e a l I ( v �O u i ) p^I_{real}(v|u_i) prealI?(v�Oui?), and generate the most relevant items for any given user u i u_i ui?. (��һ����,������ G I G^I GI��Ŀ���ǽ��Ƶײ�ʵ�����ֲ� p r e a l I ( v �O u i ) p^I_{real}(v|u_i) prealI?(v�Oui?), ��Ϊ�κθ����û� u i u_i ui?��������ص���?Ŀ.)
-
(2) We define the generator using the softmax function over all the items according to the transferred user representation p i S I p^{SI}_i piSI? from social domain to item domain: (���Ǹ��ݴ��罻����Ŀ������û���ʾ p i S I p^{SI}_i piSI?,����������ʹ��softmax��������������?)

- where g �� G I I g^I_{\theta^I_G} g��GI?I? is a score function reflecting the chance of v j v_j vj? being clicked/purchased by u i u_i ui?. Given a user u i u_i ui?, an item v j v_j vj? can be sampled from the distribution G I ( v j �O u i ; �� G I ) G^I(v_j | u_i; ��^I_G) GI(vj?�Oui?;��GI?).
-
(3) We note that the process of generating a relevant item for a given user is discrete. Thus, we cannot optimize the generator G I G^I GI via stochastic gradient descent methods [Wang et al., 2017]. Following [Sutton et al., 2000; Schulman et al., 2015], we adopt the policy gradient method usually adopted in reinforcement learning to optimize the generator. (����ע�,Ϊ�����û����������Ĺ�������ɢ�������,������ͨ������ݶ��½����Ż������� G I G^I GI[Wang����,2017]����[Sutton����,2000��;Schulman����,2015��]֮��,���Dz��� ǿ��ѧϰ ��ͨ�����õ������ݶȷ����Ż���������)
-
(4) To learn the parameters for the generator, we need to perform the following minimization problem: (Ϊ���˽��������IJ���,������Ҫִ��������С������:)

-
(5) Now, this problem can be viewed in a reinforcement learning setting, where K ( x i I , y j I ) = l o g ( 1 + e x p ( f ? D I I ( x i I , y j I ) ) ) K(x^I_i, y^I_j) = log(1 + exp(f^I_{\phi^I_D}(x^I_i, y^I_j))) K(xiI?,yjI?)=log(1+exp(f?DI?I?(xiI?,yjI?))) is the reward given to the action ��selecting v i v_i vi? given a user u i u_i ui?�� performed according to the policy probability G I ( v �O u i ) G^I(v|u_i) GI(v�Oui?). The policy gradient can be written as: (����,������������ǿ��ѧϰ�����в鿴)

- Specially, the gradient �� �� G I L a d v I ( G I , D I ) \bigtriangledown_{\theta^I_G}\mathcal{L}^I_{adv}(G^I, D^I) ����GI??LadvI?(GI,DI) is an expected summation over the gradients �� �� G I l o g G I ( v j �O u i ) \bigtriangledown_{\theta^I_G}logG^I(v_j | u_i) ����GI??logGI(vj?�Oui?) weighted by l o g ( 1 + e x p ( f ? D I I ( x i I , y j I ) ) ) log(1 + exp(f^I_{\phi^I_D}(x^I_i, y^I_j))) log(1+exp(f?DI?I?(xiI?,yjI?))).
-
(6) The optimal parameters of G I G^I GI and D I D^I DI can be learned by alternately minimizing and maximizing the value function L a d v I ( G I , D I ) L^I_{adv}(G^I, D^I) LadvI?(GI,DI). (ͨ��������С�������ֵ���� L a d v I ( G I , D I ) L^I_{adv}(G^I, D^I) LadvI?(GI,DI),����ѧϰ G I G^I GI�� D I D^I DI����Ѳ���. )
- In each iteration, discriminator D I D^I DI is trained with real samples from p r e a l I ( ? �O u i ) p^I_{real}(\cdot | u_i) prealI?(?�Oui?) and generated samples from generator G I G^I GI; (��ÿһ�ε�����,������ D I D^I DI���������� p r e a l I ( ? �O u i ) p^I_{real}(\cdot | u_i) prealI?(?�Oui?)����ʵ�����ʹ������� G I G^I GI���ɵ����� ѵ��)
- the generator G I G^I GI is updated with policy gradient under the guidance of D I D^I DI. (������ G I G^I GI�� D I D^I DI��ָ����ʹ�ò����ݶȽ��и���)
-
(7) Note that different from the way of optimizing user and item representations with the typical negative sampling on traditional recommender systems, the adversarial learning technique tries to generate ��difficult�� and high-quality negative samples to guide the learning of user and item representations. (��ע��,�봫ͳ�Ƽ�ϵͳ�ϵ��͵��������Ż��û�����Ŀ��ʾ��ͬ,�Կ�ѧϰ������ͼ���ɡ����ѡ��������ĸ�����,��ָ���û�����Ŀ��ʾ��ѧϰ��)
2.4 Social Domain Adversarial Learning
-
(1) In order to learn better user representations from the social perspective, another adversarial learning is harnessed in the social domain. Likewise, the adversarial learning in the social domain consists of two components, as shown in the bottom right part of Figure 2. (Ϊ�˴��罻�Ƕ�ѧϰ���õ��û���ʾ,���罻�����л���������һ�ֶԿ���ѧϰ��ͬ��,�罻�����еĶԿ���ѧϰ�����������,��ͼ2���²�����ʾ��)
-
Discriminator D S ( u i , u ; ? D S ) D^S(u_i, u; \phi^S_D) DS(ui?,u;?DS?), parameterized by ? D S \phi^S_D ?DS?, aims to distinguish the real connected user-user pairs ( u i , u ) (u_i, u) (ui?,u) and the fake user-user pairs generated by the generator G S G^S GS. (ּ�����������������û��� ( u i , u ) (u_i, u) (ui?,u)�Լ������� G S G^S GS���ɵļ��û��ԡ�)
-
Generator G S ( u �O u i ; �� G S ) G^S(u | u_i; \theta^S_G) GS(u�Oui?;��GS?), parameterized by �� G S \theta^S_G ��GS?, tries to fit the underlying real conditional distribution p r e a l S ( u �O u i ) p^S_{real}(u|ui) prealS?(u�Oui) as much as possible, and generates (or, to be more precise, selects) the most relevant users to the given user u i u_i ui?. (������ϵײ�ʵ�����ֲ�p^S_{real}(u|ui)p real S? (u)�O�û�����),������(���߸�ȷ��˵,ѡ��)������û�u_i����ص��û�? .)
-
-
(2) Formally, D S D^S DS and G S G^S GS are playing the following two-player minimax game with value function L a d v S ( G S , D S ) \mathcal{L}^S_{adv}(G^S, D^S) LadvS?(GS,DS), (���ڽ�����������㼫С����ֵ��Ϸ)

2.4.1 Social Domain Discriminator
- The discriminator
D
S
D^S
DS aims to distinguish the real user-user pairs and the generated ones. The discriminators
D
S
D^S
DS estimates the probability of user
u
k
u_k
uk? being connected to user
u
i
u_i
ui? with a sigmoid function and a score function
f
?
D
S
S
f^S_{\phi^S_D}
f?DS?S? as follows:

2.4.2 Social Domain Generator
-
(1) The purpose of the generator, G S G^S GS, is to approximate the underlying real conditional distribution p r e a l S ( u �O u i ) p^S_{real}(u | u_i) prealS?(u�Oui?), and generate (or, to be more precise, select) the most relevant users for any given user u i u_i ui?. (������ G S G^S GS��Ŀ���ǽ��ƻ�������ʵ�����ֲ� p r e a l S ( u �O u i ) p^S_{real}(u | u_i) prealS?(u�Oui?),��Ϊ�κθ����û� u i u_i ui?����(���߸�ȷ��˵,ѡ��)����ص��û�?)
-
(2) We model the distribution using a softmax function over all the other users with the transferred user representation p i I S p^{IS}_i piIS? (from the item to social domain), (����ʹ��softmax���������������û��ķֲ����н�ģ,��ʹ�ô�����û���ʾ p i I S p^{IS}_i piIS?(����Ŀ���罻��))

- where g �� G S S g^S_{\theta^S_G} g��GS?S?is a score function reflecting the chance of u k u_k uk? being related to u i u_i ui?. (��һ����������,��ӳ�� u k u_k uk?���� u i u_i ui?����ϵ�Ļ���)
-
(3) Likewise, policy gradient is utilized to optimize the generator G S G^S GS, (ͬ��,�����ݶȱ������Ż������� G S G^S GS)

-
where the details are omitted here, since it is defined similar to Eq.(5).
2.5 The Objective Function
-
(1) With all model components, the objective function of the proposed framework is: (��������ģ�����,����Ŀ�ܵ�Ŀ�꺯��Ϊ:)

- where �� \lambda �� is to control the relative importance of cyclereconstruction strategy and further influences the two mapping operation. (���� �� \lambda �����ڿ���ʩ�����Ե������Ҫ��,����һ��Ӱ������ӳ�������)
- h S ? I h^{S\longrightarrow I} hS?I and h I ? S h^{I\longrightarrow S} hI?S are implemented as MLP with three hidden layers. (ʵ��Ϊ�����������ز��MLP)
- To optimize the objective, the RMSprop [Tieleman and Hinton, 2012] is adopted as the optimizer in our implementation. (Ϊ���Ż�Ŀ��,���ǵ�ʵ�ֲ�����RMSprop[Tieleman and Hinton,2012]��Ϊ�Ż�����)
- To train our model, at each training epoch, we iterate over the training set in mini-batch to train each model (e.g., GI) while the parameters of other models (e.g., D I D^I DI, G S G^S GS, D S D^S DS) are fixed. (Ϊ��ѵ�����ǵ�ģ��,��ÿ��ѵ����,������С��������ѵ������ѵ��ÿ��ģ��(����GI),������ģ��(���� D I D^I DI, G S G^S GS, D S D^S DS)�IJ����ǹ̶��ġ�)
- When the training is finished, we take the representations learned by the generator G I G^I GI and G S G^S GS as our final representations of item and user for performing recommendation. ( ��ѵ������,���ǽ������� G I G^I GI�� G S G^S GSѧϰ���ı�ʾ��Ϊ��Ŀ���û������ձ�ʾ,��ִ���Ƽ���)
-
(2) There are six representations in our model, including p i I p^I_i piI?, q j I q^I_j qjI?, x i I x^I_i xiI?, y j I y^I_j yjI?, p i S p^S_i piS?, x i S x^S_i xiS?. They are randomly initialized and jointly learned during the training stage. (�����ǵ�ģ������������ʾ,���� p i I p^I_i piI?, q j I q^I_j qjI?, x i I x^I_i xiI?, y j I y^I_j yjI?, p i S p^S_i piS?, x i S x^S_i xiS?������ѵ�����������ʼ��������ѧϰ��)
-
(3) Following the setting of IRGAN [Wang et al., 2017], we adopt the inner product as the score function f �� D I I f^I_{��^I_D} f��DI?I? and g �� G I I g^I_{\theta^I_G} g��GI?I? in the item domain as follows: f ? D I I ( x i I , y j I ) = ( x i I ) T y j I + a j f^I_{\phi^I_D}(x^I_i,y^I_j) = {(x^I_i)}^Ty^I_j+ a_j f?DI?I?(xiI?,yjI?)=(xiI?)TyjI?+aj?, g �� G I I ( p i S I , q j I ) = ( p i S I ) T q j I + b j g^I_{\theta^I_G}(p^{SI}_i, q^I_j) = {(p^{SI}_i)}^Tq^I_j+ b_j g��GI?I?(piSI?,qjI?)=(piSI?)TqjI?+bj?, (����IRGAN[Wang����,2017]������,���Dz����ڻ���Ϊ��Ŀ���еĵ÷ֺ��� f �� D I I f^I_{��^I_D} f��DI?I?�� g �� G I I g^I_{\theta^I_G} g��GI?I?,������ʾ)
- where a j a_j aj? and b j b_j bj? are the bias term for item j j j.
- We define the score function f ? D S S f^S_{\phi^S_D} f?DS?S? and g �� G S S g^S_{\theta^S_G} g��GS?S? in the social domain in a similar way. (���罻����,�����Ƶķ�ʽ�����˷������� f ? D S S f^S_{\phi^S_D} f?DS?S? and g �� G S S g^S_{\theta^S_G} g��GS?S?)
- Note that the above score functions can be also implemented using deep neural networks, but leave this investigation as one future work. (��ע��,�������ֺ���Ҳ����ʹ�����������ʵ��,�������о�����δ��������)
3 Experiments
3.1 Experimental Settings
- (1) We conduct our experiments on two representative datesets Ciao and Epinions1 for the Top-K recommendation. (�������������д����Ե����ݼ�Ciao��Epinions1�Ͻ���ʵ��,�Ի��Top-K�Ƽ���)
- As these two datasets provide users�� explicit ratings on items, we convert them into 1(Both Ciao and Epinions datasets are available at: http://www.cse.msu.edu/��tangjili/trust.html) as the implicit feedback. This processing method is widely used in previous works on recommendation with implicit feedback [Rendle et al., 2009]. (�������������ݼ��ṩ���û�����Ŀ����ʽ����,���ǽ���ת��Ϊ1��Ϊ��ʽ���������ִ����������㷺Ӧ����֮ǰ�������Է����Ƽ��Ĺ�����[Rendle����,2009]��)

- We randomly split the user-item interactions of each dataset into training set (80%) to learn the parameters, validation set (10%) to tune hyper-parameters, and testing set (10%) for the final performance comparison. We implemented our method with tensorflow and tuned all the hyper-parameters with grid-search [Fan et al., 2019]. The statistics of these two datasets are presented in Table 1. (���ǽ�ÿ�����ݼ����û���������Ϊѵ����(80%)ѧϰ����,��֤��(10%)����������,���Լ�(10%)�����������ܱȽϡ�����ʹ��tensorflowʵ�������ǵķ���,��ʹ�������������������г�����[Fan����,2019]�����������ݼ���ͳ���������1��ʾ��)
- We use two popular performance metrics for Top-K recommendation [Wang et al., 2017]: (������Top-K�Ƽ���ʹ�����������е�����ָ��[Wang����,2017]:Precision@K�Լ���һ�������ۻ�����(NDCG@K))
- Precision@K
- and Normalized Discounted Cumulative Gain (NDCG@K).
- We set K as 3, 5, and 10. Higher values of the Precision@K and NDCG@K indicate better predictive performance. (.���ǽ�K��Ϊ3��5��10�����ߵ�Precision@K��NDCG@K��ʾ���õ�Ԥ�����ܡ�)
Baselines
- (2) To evaluate the performance, we compared our proposed model DASO with four groups of representative baselines, including (Ϊ����������,���ǽ����������DASOģ����������д����ԵĻ��߽����˱Ƚ�,����)
- traditional recommender system without social network information (BPR [Rendle et al., 2009]),
- tradition social recommender systems (SBPR [Zhao et al., 2014] and SocialMF [Jamali and Ester, 2010]),
- deep neural networks based social recommender systems (DeepSoR [Fan et al., 2018] and GraphRec [Fan et al., 2019]),
- and adversarial learning based recommender system (IRGAN [Wang et al., 2017]).
- Some of the original baseline implementations (SocialMF, DeepSoR, and GraphRec) are for rating prediction on recommendations. Therefore we adjust their objectives to point-wise prediction with sigmoid cross entropy loss using negative sampling. (һЩԭʼ�Ļ���ʵ��(SocialMF��DeepSoR��GraphRec)���ڶԽ����������Ԥ�⡣���,���ǵ��������ǵ�Ŀ��,����==��������sigmoid��������ʧ==�������Ԥ����)
3.2 Performance Comparison of Recommender Systems
Table 2 presents the performance of all recommendation methods. We have the following findings: (��2�����������Ƽ����������ܡ����������·���:)
- SBPR and SocialMF outperform BPR. SBPR and SocialMF utilize both user-item interactions and social relations; while BPR only uses the user-item interactions. These improvements show the effectiveness of incorporating social relations for recommender systems. (SBPR��Socialf�ı�������BPR��SBPR��SocialMFͬʱ�����û����������ϵ;��BPRֻʹ���û��������Щ�Ľ���ʾ��������ϵ�����Ƽ�ϵͳ����Ч�ԡ�)
- In most cases, the two deep models, DeepSoR and GraphRec, obtain better performance than SBPR and SocialMF, which are odeled with shallow architectures. These improvements reflect the power of deep architectures on the task of recommendations. (�ڴ���������,DeepSoR��GraphRec���������ģ�ͱ�SBPR��SocialMF(��������dz��ܹ���ģ��)��ø��õ����ܡ���Щ�Ľ���ӳ�����ܹ��Խ��������ǿ�����á�)
- IRGAN achieves much better performance than BPR, while both of them utilize the user-item interactions only. IRGAN adopts the adversarial learning to optimize user and item representations; while BPR is a pair-wise ranking framework for Top-K traditional recommender systems. This suggests that adopting adversarial learning can provide more informative negative samples and thus improve the performance of the model. (IRGANʵ���˱�BPR���õ�����,�����߶�ֻ�����û������IRGAN���öԿ�ʽѧϰ���Ż��û�����Ŀ��ʾ;��BPR��Top-K��ͳ�Ƽ�ϵͳ�ijɶ������ܡ���������öԿ���ѧϰ�����ṩ������Ϣ���ĸ�������,�Ӷ����ģ�͵�������)
- Our model DASO consistently outperforms all the baselines. Compared with DeepSoR and GraphRec, our model proposes advanced model components to model user representations in both item domain and social domain. (���ǵ�DASOģ��ʼ���������л��ߡ���DeepSoR��GraphRec���,���ǵ�ģ������˸�ģ�����������Ŀ����罻���е��û���ʾ���н�ģ��)
- In addition, our model harnesses the power of adversarial learning to generate more informative negative samples, which can help learn better user and item representations. (����,���ǵ�ģ�����öԿ���ѧϰ���������ɸ�����Ϣ���ĸ�������,��������ѧϰ���õ��û�����Ŀ��ʾ��)

3.2.1 Parameter Analysis
Next, we investigate how the value of �� \lambda �� affects the performance of the proposed framework. (������,�����о� �� \lambda ����ֵ���Ӱ���������ܵ����ܡ�)
- The value of �� \lambda �� is to control the importance of cycle reconstruction. Figure 3 shows the performance with varied values of �� \lambda �� using Precision@3 as the measurement. The performance first increases as the value of �� \lambda �� gets larger and then starts to decrease once �� goes beyond 100. ( �� \lambda ����ֵ���ڿ���ѭ���ؽ�����Ҫ�ԡ�ͼ3��ʾ��ʹ�ò�ͬ�� �� \lambda ��ֵʱ������Precision@3��Ϊ�������������������� �� \lambda ����ֵ��������,Ȼ���� �� \lambda ������100ʱ��ʼ���͡�)
- The performance weakly depends on the parameter controlling the bidirectional influence, which suggests that transferring user��s information from the social domain to the item domain already significantly boosts the performance. (������������������˫��Ӱ��IJ���,��������û���Ϣ���罻��ת�Ƶ���Ŀ���Ѿ�������������ܡ�)
- However, the user-item interactions and user-user connections are often very sparse, so the bidirectional mapping (Cycle Reconstruction) is proposed to help alleviate this data sparsity problem. Although the performance weakly depends on the bidirectional influence, we still observe that we can learn better user��s representation in both domains. (Ȼ��,�û�������û�����ͨ���dz�ϡ��,��������˫��ӳ��(ѭ���ع�)������������������ϡ����������Ȼ��������������˫��Ӱ��,��������Ȼ�۲쵽,���ǿ���������������ѧϰ���õ��û���ʾ��)

4 Related Work
-
(1) As suggested by the social theories [Marsden and Friedkin, 1993], people��s behaviours tend to be influenced by their social connections and interactions. Many existing social recommendation methods [Fan et al., 2018; Tang et al., 2013a; 2016b; Du et al., 2017; Ma et al., 2008] have shown that incorporating social relations can enhance the performance of the recommendations. (�����������[Marsden and Friedkin,1993]��ָ��������,���ǵ���Ϊ�������ܵ�����ϵ�ͻ�����Ӱ�졣�������е�����Ƽ�����[Fan et al.,2018;Tang et al.,2013a;2016b;Du et al.,2017;Ma et al.,2008]����,��������ϵ��������Ƽ��ļ�Ч��)
-
In addition, deep neural networks have been adopted to enhance social recommender systems. (����,����������ѱ�������ǿ����Ƽ�ϵͳ)
- DLMF [Deng et al., 2017] utilizes deep auto-encoder to initialize vectors for matrix factorization. (DLMF[Deng����,2017]��������Զ���������ʼ������ֽ��������)
- DeepSoR [Fan et al., 2018] utilizes deep neural networks to capture nonlinear user representations in social relations and integrate them into ((probabilistic matrix factorization** for prediction. (DeepSoR[Fan et al.,2018]�������������������ϵ�еķ������û���ʾ,�����伯�ɵ����ʾ���ֽ�������Ԥ�⡣)
- GraphRec [Fan et al., 2019] proposes a graph neural net-works framework for social recommendation, which aggregates both user-item interactions information and social interaction information when performing prediction. (GraphRec[Fan et al.,2019]�����һ����������Ƽ���ͼ��������,�ÿ���ڽ���Ԥ��ʱ�ۺ����û������Ϣ����ύ����Ϣ��)
-
(2) Some recent works have investigated adversarial learning for recommendation.
- IRGAN [Wang et al., 2017] proposes to unify the discriminative model and generative model with adversarial learning strategy for item recommendation. (IRGAN[Wang����,2017]������б�ģ�ͺ�����ģ������Ŀ�Ƽ��ĶԿ���ѧϰ������ͳһ��)
- NMRN-GAN [Wang et al., 2018b] introduces the adversarial learning with negative sampling for streaming recommendation. (NMRN-GAN[Wang����,2018b]Ϊ��ý���Ƽ������˴��и������ĶԿ�ʽѧϰ��)
-
Despite the compelling success achieved by many works, little attention has been paid to social recommendation with adversarial learning. Therefore, we propose a deep adversarial social recommender system to fill this gap. (����������Ʒȡ���������ŷ��ijɹ�,���������˹�ע���жԿ���ѧϰ������Ƽ������,���������һ����ȶԿ�������Ƽ�ϵͳ�����һ�հס�)
5 Conclusion and Future Work
- (1) In this paper, we present a Deep Adversarial SOcial recommendation model (DASO), which learns separated user representations in item domain and social domain. (�ڱ�����,���������һ����ȶԿ�������Ƽ�ģ��(DASO),��ģ��ѧϰ��Ŀ����������������û���ʾ��)
- (2) Particularly, we propose to transfer users�� information from social domain to item domain by using a bidirectional mapping method. (�ر��,���ǽ���ʹ��˫��ӳ���������û�����Ϣ���罻����ת�Ƶ���Ŀ����)
- (3) In addition, we also introduce the adversarial learning to optimize our entire framework by generating informative negative samples. (����,���ǻ��������Կ�ʽѧϰ,ͨ��������Ϣ�ḻ�ĸ��������Ż����ǵ�������ܡ�)
- Comprehensive experiments on two real-world datasets show the effectiveness of our model. The calculation of softmax function in item/social domain generator involves all items/users, which is time-consuming and computationally inefficient. (��������ʵ���ݼ��ϵ��ۺ�ʵ������˸�ģ�͵���Ч�ԡ���item/social domain generator��,softmax�����ļ����漰����item/users,��Ⱥ�ʱ�ּ���Ч�ʵ��¡�)
- Therefore, hierarchical softmax [Morin and Bengio, 2005; Mikolov et al., 2013; Wang et al., 2018a], which is a replacement for softmax, would be considered to speed up the calculation in both generators in the future direction. (���,���softmax�ķֲ�softmax[Morin and Bengio,2005;Mikolov et al.,2013;Wang et al.,2018a]������Ϊ��δ���ķ����ϼӿ���̨�������ļ����ٶȡ�)