Rethinking Atrous Convolution for Semantic Image Segmentation 论文解读
参考链接:https://zhuanlan.zhihu.com/p/61208558
https://blog.csdn.net/u010451780/article/details/109286262
https://blog.csdn.net/qq_37541097/article/details/121797301?spm=1001.2014.3001.5502
代码链接:https://github.com/dontLoveBugs/Deeplab_pytorch
V1链接:https://blog.csdn.net/weixin_44543648/article/details/122576853
V2链接:https://blog.csdn.net/weixin_44543648/article/details/122599976
摘要:
提出的框架是通用的,因为它可以应用于任何网络。具体地说,我们在ResNet中复制了原始的最后一个块的几个副本,并将它们排列为级联,并重新访问了ASPP模块,它包含几个并行的空洞卷积。
比较了多种捕获多尺度信息的方式:
如下图
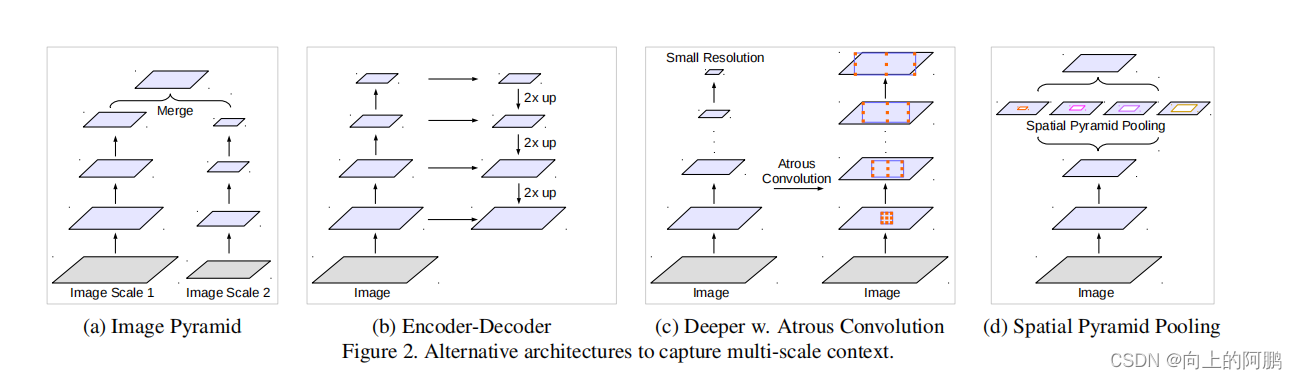
Image pyramid:将输入图片放缩成不同比例,分别应用在 DCNN 上,将预测结果融合得到最终输出。相同的模型,通常具有共享的权重,被应用于多尺度的输入。来自小尺度输入的特征响应编码了远程上下文,而大尺度输入保留了小对象的细节。
Encoder-decoder:利用 Encoder 阶段的多尺度特征,运用到 Decoder 阶段上恢复空间分辨率,代表工作有 FCN、SegNet、PSPNet 等工。
Context module:在原始模型的顶端增加额外的模块,例如 DenseCRF,捕捉像素间长距离信息。
Spatial pyramid pooling:使用空间金字塔池来捕获多个范围内的上下文。空间金字塔池化具有不同采样率和多种视野的卷积核,能够以多尺度捕捉对象。
主要贡献:
-
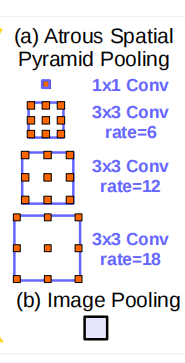
改进ASPP模块:相比于之前提出的ASPP模块,改进的模块含有5个并行分支,分别是一个1x1的卷积层,三个3x3的膨胀卷积层,以及一个全局平均池化层,其中最后一个全局池化分支作者说是为了增加一个全局上下文信息,然后通过Concat的方式将这5个分支的输出进行拼接(沿着channels方向),最后在通过一个1x1的卷积层进一步融合信息。结构如下图:
-
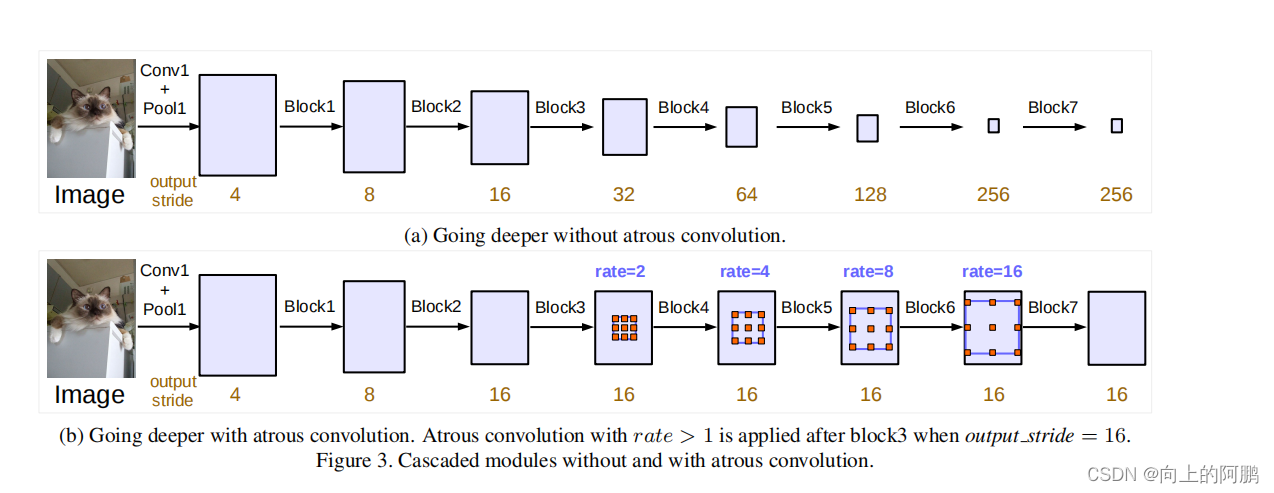
使用ResNet的块构成级联结构:其中Block1,Block2,Block3,Block4是原始ResNet网络中的层结构,Block5,Block6,Block7构建为联级模块,与ResNet相似,在这些块中有三个3×3的卷积,除了最后一个块,每个块的最后一个卷积操作步数为2。
-
Multi-grid:在DeepLab V3中作者有去做一些相关实验看空洞卷积的dilation设置何值更合理。针对block5-7(block5-7称为联级模块)进行实验,结果如下表,其中,blocks中真正采用的膨胀系数应该是图中的rate乘上这里的Multi-Grid参数。

代码
import torch.nn.functional as F
from torch.utils import model_zoo
from network.base.oprations import ASPP_module
from network.base.resnet import *
class DeeplabV3(ResNet):
def __init__(self, n_class, block, layers, pyramids, grids, output_stride=16):
self.inplanes = 64
super(DeeplabV3, self).__init__()
if output_stride == 16:
strides = [1, 2, 2, 1]
rates = [1, 1, 1, 2]
elif output_stride == 8:
strides = [1, 2, 1, 1]
rates = [1, 1, 2, 2]
else:
raise NotImplementedError
# Backbone Modules
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[0], rate=rates[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], rate=rates[1])
self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], rate=rates[2])
self.layer4 = self._make_MG_unit(block, 512, blocks=grids, stride=strides[3], rate=rates[3])
# Deeplab Modules
self.aspp1 = ASPP_module(2048, 256, rate=pyramids[0])
self.aspp2 = ASPP_module(2048, 256, rate=pyramids[1])
self.aspp3 = ASPP_module(2048, 256, rate=pyramids[2])
self.aspp4 = ASPP_module(2048, 256, rate=pyramids[3])
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(2048, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# get result features from the concat
self._conv1 = nn.Sequential(nn.Conv2d(1280, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# generate the final logits
self._conv2 = nn.Conv2d(256, n_class, kernel_size=1, bias=False)
self.init_weight()
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
# image-level features
x5 = self.global_avg_pool(x)
x5 = F.upsample(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self._conv1(x)
x = self._conv2(x)
x = F.upsample(x, size=input.size()[2:], mode='bilinear', align_corners=True)
return x
def get_1x_lr_params(self):
b = [self.conv1, self.bn1, self.layer1, self.layer2, self.layer3, self.layer4]
for i in range(len(b)):
for k in b[i].parameters():
if k.requires_grad:
yield k
def get_10x_lr_params(self):
b = [self.aspp1, self.aspp2, self.aspp3, self.aspp4, self.global_avg_pool, self._conv1, self._conv2]
for j in range(len(b)):
for k in b[j].parameters():
if k.requires_grad:
yield k
def freeze_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
def freeze_backbone_bn(self):
self.bn1.eval()
for m in self.layer1:
if isinstance(m, nn.BatchNorm2d):
m.eval()
for m in self.layer2:
if isinstance(m, nn.BatchNorm2d):
m.eval()
for m in self.layer3:
if isinstance(m, nn.BatchNorm2d):
m.eval()
for m in self.layer4:
if isinstance(m, nn.BatchNorm2d):
m.eval()
def resnet101(n_class, output_stride=16, pretrained=True):
if output_stride == 16:
pyramids = [1, 6, 12, 18]
grids = [1, 2, 4]
elif output_stride == 8:
pyramids = [1, 12, 24, 36]
grids = [1, 2, 1]
else:
raise NotImplementedError
model = DeeplabV3(n_class=n_class, block=Bottleneck, layers=[3, 4, 23, 3],
pyramids=pyramids, grids=grids, output_stride=output_stride)
if pretrained:
pretrain_dict = model_zoo.load_url(model_urls['resnet101'])
model_dict = {}
state_dict = model.state_dict()
for k, v in pretrain_dict.items():
if k in state_dict:
model_dict[k] = v
print(k)
state_dict.update(model_dict)
model.load_state_dict(state_dict)
return model
if __name__ == '__main__':
model = resnet101(n_class=21, output_stride=16, pretrained=True)
img = torch.randn(4, 3, 512, 512)
with torch.no_grad():
output = model.forward(img)
print(output.size())