1. д��ǰ��
���ϵ��Ҳ�кܳ�ʱ��û������, ���ʱ�侭����ʵϰ���ҹ���������,���Ѿ�������ȥ�Ķ������������ı���,������,һֱ���á������ڴ�����ź����ڼҵ�ʱ������ϵ�н��ϡ���Ȼ�������֪ʶ�Ƚ�ƫ����,���ܸ����ǵĸо��Dz�̫ʵ��,����д����Щʡ��,��ɬ�Ѷ�,�Գ�ѧ��Ҳ���Ǻ��Ѻ�, �������кܶ���Ҫ��˼�������ǽ��ʵ�������лῼ�ǵ���,����֮����������һ��,��ȫ����Ϊ��Ȥ����,���������,��Ҳ�ᾡ������������ο�����,���������֪ʶ������,ʹ������,������dz����ø��Ӱ������������֪ʶ����ع�,����ѧϰ����Ӧ�û����һЩ,��Ȼ,Ҳϣ���ܰ�������Ļ��,�ڻ���ѧϰ��·���ߵĸ�����Ȼ,��ν"ƮƮ������������,������" 😉

���츴ϰ����������, ��Ӧ����������µ�����, ��������Ȼ�ǻ���ѧϰ�����һ��,�������Ѿ��������ݻ�����һ���µ��ӷ���,Ҳ������������֪�����ѧϰ������,���������ϵ������,ֻ�Ƕ����ѧϰ������һ����,û����ϸչ��,������ͬ��Ҳ����չ��,�Ͼ��ⶫ���漰��֪ʶ����Щ��,��չ������,����ᵥ��д��ƪ����,�������ѧϰ�Ļ���֪ʶ��
����Ļ�,��Ȼ���������������Ϊ��,��Ҫ���������DNN����ѧϰ, ��Ȼ,Ҳ����������ο�������һЩ����,��֪ʶ������,��Ҫ����
- ��֪������,�Ჹ��һЩ����֤����ʽ�Ƶ�,����,��֪���㷨��ʵ��һ���dz�ΰ����㷨��, ����������̫���ڴ���,��û��д����֪��������(��֪��ʵ���϶��ڷ�������,�ҵ���һ��ͳһ�Ľ��ģ��);
- ���������ķ����㷨��ʽ�Ƶ�,�������ϸ��ҵĸо��Ƿ��Ŷ�,����ʡ��,����̫�ÿ�,��������������ǹ�˾����ϲ����������
- ���˷����㷨,�Ϳ�����numpyдһ�����������Լ�������Ϥ�Ŀ�ܸ���һ��(��Ҳ�ǹ�˾��������), �������ҲҪ����
- ������Ƕ�����˵����ǰ�������ܱƽ����⸴�Ӷ�����������˵����������Ӹ�����
- ������,��������һ�������һЩ��Ҫ����֪ʶ��,���������������ô��, ����ֲ���С��ô���
- ���,����һ�����Գ�������һ������: ������IJ�����ʼ��������0? why?
���, �����ʴ��һ������Ե�����, ���������Ƕ�֪����ģ����Ԫ��һ�ֲ���,���������Ӧһ�����, ����ν�Ķ��һ, ���һ���Ƿdz���Ϥ,�����ݽṹ�������, ��ѧ����ĺ������Ƕ��һ, ��ô��Ȼ���Ƕ��һ,����Ϊɶ������������? ���仰˵,������ij���Ӧ���Ǿ��л�ʱ�������, ����û�����, Ϊɶ������ʱ����?����������������?
��ƪ������Ȼ�Ǻܳ�,�����漰���Ĺ�ʽ�Ƶ�����ʱ��ԭ����Ȼ�����ư�(��ξ���д������Щ),���Ǹ�ȡ���輴�ɡ�
�������:
- ��Ԫģ�ͳ�ʶ
- ���������? �����ȴӸ�֪����ʼ
- �������ǰ��ͷ����㷨��ʽ�Ƶ�
- �������numpy���Լ�tf��pytorch��ܵļ�ʵ��
- ȫ����С�;ֲ���С
- ���ѧϰ��ʶ
- ��������������(��һ�ڲ����ص�,����ֱ������)
- ����֪ʶ: ������������ܳ�ʼ��0����������
Ok, let��s go!
2. ��Ԫģ�ͳ�ʶ
�������Ǿ�����Ӧ�Եļ�Ԫ��ɵĹ㷺���л���������,������֯��ģ������ϵͳ����ʵ�������������ķ�Ӧ�� ����ļ�Ԫ,ָ�ľ����������еĻ����ɷ���Ԫģ����
1943��, ����ѧ��W.S.McCulloch��������ѧ��W.Pitts������Ԫ����������, �����˵�����Ԫ����ѧģ��(MPģ��),�������������:
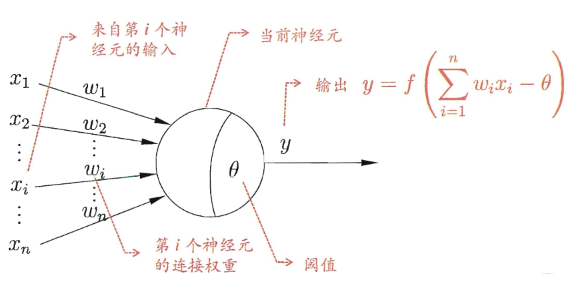
���ģ����,��Ԫ��������
n
n
n��������Ԫ���ݹ����������ź�, ��Щ�����ź�ͨ����Ȩ�ص����ӽ��д���, ��Ԫ���յ���������ֵ����Ԫ��ֵ���бȽ�, Ȼ��ͨ��"�����"����������Ԫ������������һ����Ԫ�ڸɵ�����, ��ʵ����ṹ�dz���,��һ�����͵Ķ��һ�ṹ,��������ѧ�ϵĸ��Ϻ�������˵�����һ,�����ֺ��������뵽���ݽṹ��������ṹ��
����,��������ṹ,������������:
- ÿ������ x i x_i xi?��,������һ��Ȩ��ֵ w i w_i wi?, ���Ǹ��� w i w_i wi?����ֵ���������жϳ�������ڵ�ǰ��Ԫ����Ҫ�Գ̶�
- ��Ԫ������м������, �������������Ԫ������,��ǿ���������,��Ȼ��һ����Ԫ���ܿ���������������̾ͷdz������ڶ�һ��"ֱ��"�����˸��ߵ����̡� ����ļ����ò��������sigmoid��
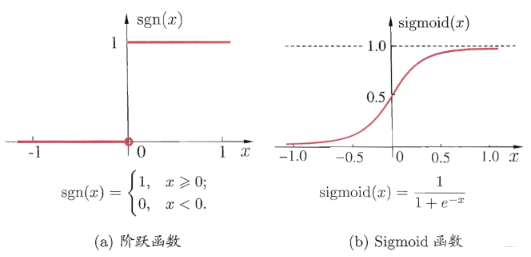
��������������Ԫ��һ���IJ�νṹ��������,�͵õ��������硣�����������Ԫ,��������һ������,���Ǹ�֪��, Ҫ��ѧϰ������, ����Ӧ�������ĸ�֪����
3. ���������? �����ȴӸ�֪����ʼ
3.1 ��֪���㷨(�Ҿ�������һ��ΰ����㷨)
��֪����������Ԫ���, ��һ�������������Է���ģ��, 1957����Rosenblatt���,����������SVM�Ļ�����
��֪��ģ�͵Ķ���Ҳ�Ƚϼ�, ��������ռ���
X
?
R
n
\mathcal{X} \subseteq \mathbf{R}^{n}
X?Rn, ����ռ���
Y
=
{
+
1
,
?
1
}
\mathcal{Y}=\{+1,-1\}
Y={+1,?1}, ����
x
��
X
x \in \mathcal{X}
x��X��ʾʵ������������, ��Ӧ������ռ��еĵ�, ���
y
��
Y
y \in \mathcal{Y}
y��Y��ʾʵ�������, ������ռ䵽����ռ�ĺ���:
f
(
x
)
=
sign
?
(
w
?
x
+
b
)
f(x)=\operatorname{sign}(w \cdot x+b)
f(x)=sign(w?x+b)
������֪���㷨������ķ��ź���,���õľ�������Ľ�Ծ������������ǴӼ�����ȥ����,���ܾ���Ȼ�ˡ� ��������֪�����Է���
w
?
x
+
b
=
0
w \cdot x+b=0
w?x+b=0
�ڶ�ά�ռ��о���һ��ֱ��, ��ά�ռ��ж�Ӧ�ڳ�ƽ��
S
S
S,
w
w
w��ʾ������,
b
b
b��ʾ�ؾࡣ �������ƽ����Ϸ�, ����
w
?
x
+
b
>
0
w \cdot x+b>0
w?x+b>0�ĵ�,�ڳ�ƽ����·�,����
w
?
x
+
b
<
0
w \cdot x+b<0
w?x+b<0, �൱��������,�ܰ����ͬ�ĵ�ֳ����������֡�
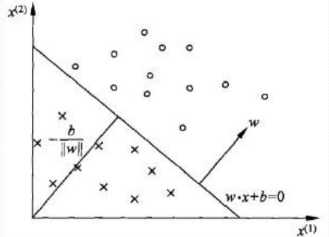
������? �����ǿ�����ô����, ������һ��ʼ��û������ֱ�ߵ�, �����
w
,
b
w, b
w,b�����Dz�֪����,��֪���㷨��ʵҪ��������,��������ͨ��һЩ�Ѿ���ѵ������(x,y), Ȼ��ȥѧϰ�������ֱ����, �����
w
,
b
w,b
w,b��,ԭ��,1957��Rosenblatt���о�������ѧϰ����ʶ�ˡ�
��ô,Ӧ����ôѧϰ���ָ�������? ����, �ȶ�����ʧ����, ��Ȼ����Ҫ������������,��ô��һ��Ӧ,����ϣ���õ��ij�ƽ������ȷ�İ������������ֿ�, ��ϣ��������ĸ���Խ��Խ��, ����������ʧ�������� w , b w,b w,b�����������ɵ���,�Ż������������⡣ ��������������һ��ѡ��,������������ƽ����ܾ�����
�����������ؼ���, �����Ǿ���, ����dz���,�������Ǹ�����ѧϰ�ĵ㵽ֱ�ߵľ��빫ʽ:
1
��
w
��
�O
w
?
x
i
+
b
�O
\frac{1}{\|w\|}\left|w \cdot x_i+b\right|
��w��1?�Ow?xi?+b�O
�ܾ���Ļ�,�Ǿ������е�ľ���֮�͡���ô��ôȷ�������
x
i
x_i
xi?����������? �������,���DZ���
y
i
=
1
y_i=1
yi?=1, ��λ����ֱ���·�(
w
?
x
i
+
b
<
0
w \cdot x_i+b<0
w?xi?+b<0)���߱���
y
i
=
?
1
y_i=-1
yi?=?1, ��ȴλ����ֱ���Ϸ�(
w
?
x
i
+
b
>
0
w \cdot x_i+b>0
w?xi?+b>0)�� ������ʵ�Ϳ����˹���, ������,�����������Ĺ�ʽ��:
?
y
i
(
w
?
x
i
+
b
)
>
0
-y_{i}\left(w \cdot x_{i}+b\right)>0
?yi?(w?xi?+b)>0
����,������������˵,��ֱ�ߵľ���,����������ʽ������ʾ:
?
1
��
w
��
y
i
(
w
?
x
i
+
b
)
-\frac{1}{\|w\|} y_{i}\left(w \cdot x_{i}+b\right)
?��w��1?yi?(w?xi?+b)
�������
�O
�O
w
�O
�O
||w||
�O�Ow�O�O,�Dz�Ӱ��������,ֻ�Ǹ�����,�൱�ں���ľ������������С���ٱ�,������û�й�ϵ�� ��������ݶ��½������ĵ�������, �����Ǿ����С�����Կ���ֱ��ȥ��,����ѡ�����ʧ��������:
L
(
w
,
b
)
=
?
��
x
i
��
M
y
i
(
w
?
x
i
+
b
)
L(w, b)=-\sum_{x_i \in M} y_{i}\left(w \cdot x_{i}+b\right)
L(w,b)=?xi?��M��?yi?(w?xi?+b)
MΪ�����㡣
��Ȼ,��ʧ����
L
(
w
,
b
)
L(w, b)
L(w,b)�ǷǸ���, ���û��������,��ʧ������ֵ��0, ����,������
Խ��,�������볬ƽ��Խ��, ��ʧ����ֵҲ��ԽС��
��ô,������ʧ����, ��֪������ν���ѧϰ����? ����һ��ѵ����
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
��
.
,
(
x
n
,
y
n
)
}
T=\{(x_1, y_1),(x_2, y_2), \ldots .,(x_n, y_n)\}
T={(x1?,y1?),(x2?,y2?),��.,(xn?,yn?)}
���ǵ����Ż�����:
min
?
w
,
b
L
(
w
,
b
)
=
?
��
x
i
��
M
y
i
(
w
?
x
i
+
b
)
\min _{w, b} L(w, b)=-\sum_{x_i \in M} y_{i}\left(w \cdot x_{i}+b\right)
w,bmin?L(w,b)=?xi?��M��?yi?(w?xi?+b)
��Ȼ������Ż�����,������ߵȴ����ϵĽ�����������,һ����λ�������
w
,
b
w,b
w,b, ������Ҫ�Ż�����, ������õ�������ݶ��½��㷨, ������������, ����ֱ����������ʦPPT�����һ��ͼ��:

����һ����������Ҫ˵��:
- ��С�������в���һ��ʹM��������������ݶ��½�,����һ�����ѡȡһ��������ʹ���ݶ��½�,��Ҳ�Ǻ�SVM���ﲻͬ�ĵط�, SVM��ֱ�ӿ�������������,��ȫ���Ͻ����Ż��ġ� ��Ȼ, SVM��199���������, ��Ȼ��Ҫ�ȸ�֪���㷨���ܶ�ġ�
- ����ݶ��½��㷨������w��b��ʱ��,��Ӧ�ü�һ��
��
\eta
����Ϊѧϰ������, ��ʾ��ƽ�����������ƶ��̶�, ���о����������ֱ��һЩ�� ���õ�д����ʵ������:
if.? y i ( w ? x i + b ) �� 0 w : = w + �� y i x i b : = b + �� y i \begin{aligned} \text {if. } y_{i}\left(w \cdot x_{i}+b\right) & \leq 0 \\ w &:=w+\eta y_{i} x_{i} \\ b &:=b+\eta y_{i} \end{aligned} if.?yi?(w?xi?+b)wb?��0:=w+��yi?xi?:=b+��yi??
ֱ����������������Ļ�:��һ��ʵ���㱻�������,��λ�ڷ��볬ƽ������һ��ʱ, ��һ������ w , b w,b w,b��ֵ, ʹ���볬ƽ�泯����������һ���ƶ�,�����ٸ÷�����볬ƽ��ľ���,ֱ����ƽ��Խ����������ʹ����ȷ���ࡣ ��Ȼ,������,���յij�ƽ����������Ψһ��,�ͳ�ֵ�Լ��ƶ������йء�
����о�������ƶ������Ǻ���ȷ, ���ǿ����ٽ�һ��, �����ƶ���֮����ʲô����, ����ֱ������һ�¡�

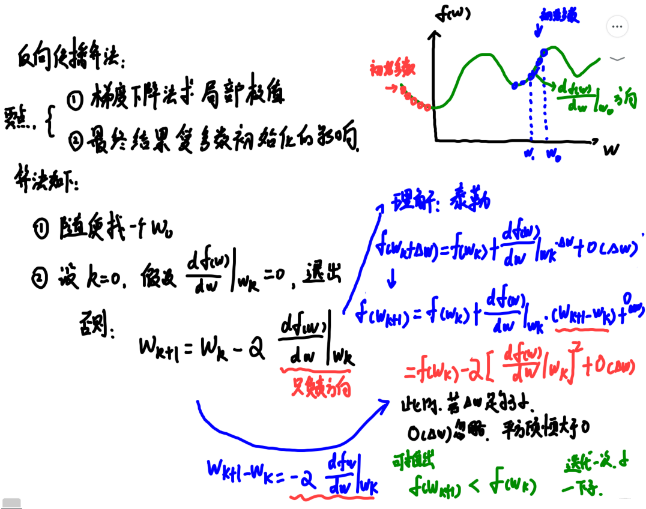
����,����ƶ��IJ����Ǻ�����, ����ʱ����и�����, ����ÿ��ѡ�������㶼�������,��ô����������������ȥ,��û�п��ܳ��ֲ�������������? ��֪���㷨֮������ôΰ��, ���к���Ҫ��һ��ԭ��,����Rosenblatt���������������һ���㷨, ������֤����,������������Կɷ�,���һ���ܵ������IJ���,�ҵ�һ����������ֿ��ij�ƽ���������Ҳ�Ǹ�֪���㷨�������Ͽɵ�һ���dz���Ҫ��ԭ���˰ɡ� ����,�����ȿ���������ô֤����,Ȼ����, ���Dz����ٻ����Ƕ�,�����¸�֪���㷨��ΰ��֮����
������Ȼ������һ��, ����,�����ȶԸ�֪���㷨���̽���һЩ��

д�������ķ�ʽ,��������Ϊ��������
��֪���㷨��������������:
���� [ X i �� ] i = 1 �� N \left[\overrightarrow{X_{i}}\right]_{i=1\sim N} [Xi??]i=1��N?, �����Կɷ�, �� ? W o p t \exists W_{opt} ?Wopt? ʹ��
W o p t ? X i �� > 0 ( i = 1 �� N ) W_{opt}^{\top} \overrightarrow{X_{i}}>0 \quad(i=1 \sim N) Wopt??Xi??>0(i=1��N)
�����������ĸ�֪���㷨, ��������֮��, �϶��ܵõ���һ�� W W W, ʹ�� W ? X i �� > 0 ( i = 1 �� N ) W^{\top} \overrightarrow{X_{i}}>0 \quad(i=1 \sim N) W?Xi??>0(i=1��N)������
ע��, ����� W W W����һ������ W o p t W_{opt} Wopt?, ��Ϊ���һ����ƽ���ܰ����������ֿ�,��ôһ�����������������ij�ƽ��, ����������ȵĸ��ʷdz�С�� ������ɷ�,һ�����ҵ�һ����ƽ��������������ֿ���
���濴����֤����

��Ȼ,�����Ƕ��Եķ���,������ж����ķ���,

Ҳ����˵,ֻҪһֱ���������ĵ�, Ҳ���ֻ��Ҫ����
D
2
D^2
D2,
W
W
W�ͻ�������
a
W
o
p
t
aW_{opt}
aWopt?, ��
W
o
p
t
W_{opt}
Wopt?���ܰ����������ֿ��ij�ƽ�档 ����,��������ɷ�, ���ø�֪���㷨,�ǿ϶������������������(��Ȼ��һ�������Ž�), �������ܽ�����Կɷ�������������������
�Ҿ��ø�֪���㷨Ҳ��һ��ΰ����㷨,��Ȼ��ѧ�Ͽ��ܲ���SVM��ôƯ��,��Rosenblatt���е����֤��˼·Ҳ�Ǻ�Ư����, ����֮���Գ�Ϊ����,�ɲ����������ij���㷨, ����ͨ����ѧ֤��ʹ���Լ��㷨����ϵ��Ǣ,����Ƿdz������ġ�
��ô,���ǿ����ٿ����Զ�,��һ�¸�֪���������������������? ��ν�ķ��೬ƽ��,�����Ǹ�������,��Ȼ���Ϻ���������,Ϊɶ�������������֪���ĸ���?
���೬ƽ��, ��Ȼ�Ǹ�����, ��һ�����ǽ�������,��Ϊ��������������,��ֵ��ֻ������(1��-1), ���Լ�ʹ�Ǻ���, �ǿ϶�Ҳ��һ���ֶκ���,��ͬ�Ķ�������,���ܶ�Ӧ��ͬ�ĺ������
����,��ʹ�Ǻ���,�����������û��һ��ͳһ�ı����, �Ƕ���һ���ֶκ������,�ͱȽ��鷳��, �����dz�ͷ�۵�����, �ֶ��ٶ�? ��ô�ֶ�? ÿһ����ô��?
�������һ������������, ����һ������������, �ֵ����¿��������������⡣
����, ������ν�ĺ�������ʽ, ��ʵ������ͳһ�����ʵ��������Ķ�����������
����,������Կɷֶ���������,����Ҫ������һ��ͳһģ��, ������������, ���ģ�嶼����Ч��, ����֪��, ������������˼�ֵ��
Rosenblatt��ү�Ӿ�˵, �����������㷨ֻ��ҪһЩ���������(x,y), Ȼ���㷨�����Լ�ѧϰ,���������ƽ��,����������,����ֻҪ�����Կɷֵ�����,һ�����ҵ������ij�ƽ�档
��ô,�ⲻ����������˵��ģ����? ֻҪ���ǵ�����������,���ֵ�, ���������Ÿ�֪����ģ���ʾ����,��֪������ȷ����������ģ�����,��ȷ����������ģ�峤ʲô����
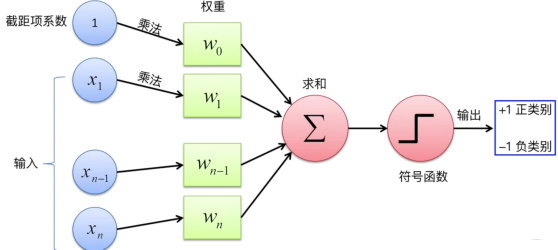
�����ֱ�ӷ���,��ô������������Dz�������,����ϡ��Źֵġ� ������? ֻҪͨ����֪��, ��������ͳһ�����һ�����Ժ���+������ķ�ʽ�� ���Ժ�����,�������,�����Ķ���,��ϸ�֪��ѧϰ�㷨,��Ȼ�ܰѷdz����ӵĶ�������������Ҿ���,����Ǹ�֪���������������ڡ�
�����˵,��֪��������ѧϰ�����dz�����, ò���������������ⶼ�������,����ɶ��?����,��������Ƿ����Կɷ�����, һ����֪�����������������, ��һ������, ���ǿ�����������֪��, ������֪������, ���������� ����,���γ���������˵�������硣
���ܱƽ�����:ֻ��Ҫһ�������㹻����Ԫ�����ز�, ��������������⾫�ȱƽ����⸴�Ӷȵ�����������
������ܱƽ�����, �ں����ʵ����������֮��,Ҳ��ٸ�����ֱ�۸�����, �����ǿ�����һ��, ���ܱƽ�, �����������ط��Dz���Ҳ��������? ֪ʶ����, ���Ժ��и��ֳ���̩�պ���Ҷ����Ӱ, ���Ǹ�����ѧϰ���ĺ�����̩��չ��, ����Ҷ����(һ�����ӵĺ������Բ���һ����Բ���˶��������Ҳ�), �Dz��Ƕ��ǻ�����Ϊ��˼·?
3.2 �Ӹ�֪����������
�ڸ�֪�����Ǹ����, ��ʵ��û�����Կɷֺ����Բ��ɷֵĸ���, ��������˹������("�˹�����"֮��)��1969���ʱ������������
- Minsky��Perceptron��һ��,�ճ������кܶ���������Ƿ����Կɷֵġ�
�������Ͼ���һ���������,Ҳ���Ǿ����������⡣
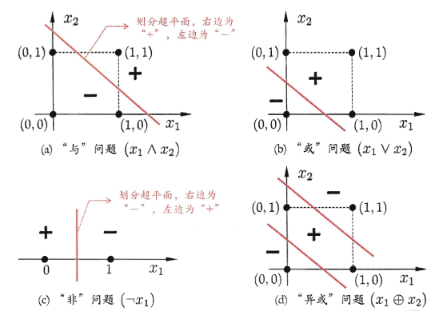
����������������ҵ�һ��ֱ��,�ܰ����������ȫ�ֿ��ġ�
��֪������ô�����ⶼ�������,���Խ�������һ��ʱ��,�����ֶԸ�֪��ʧȥ��ϣ��, ��Ҳӭ�����˹����ܵ�"��һ�κ���", ����19����80�����,��������˶����������㷨, ʹ��������������һ���Ļ���, �˹�����ӭ����һ�����졣
1986��, Hinton��ү�ӵ�������˷���(BP)�㷨,ʹ�ö���������ѵ����Ϊ��, ��������һ�λ���������
���������������,���ǾͿ�����������֪��

������
x
1
,
x
2
x_1,x_2
x1?,x2?�ȷֱ��������֪��, Ȼ����������֪�������,Ȼ���ٰ���������֪������������µ��������ٹ�һ����֪���õ����յķ�����,��������ʵ��������㡣��������,�൱�ڽ�ԭ��������
x
1
,
x
2
x_1,x_2
x1?,x2?�ȷֱ����������Ա任,�õ�
a
1
,
a
2
a_1,a_2
a1?,a2?, Ȼ���
a
1
,
a
2
a_1,a_2
a1?,a2?�ٵ���������һ�����Ա任�õ�
y
1
y_1
y1?��
����ʵ����һ�����2��������, �����м��һ��������ز�, ����һ��������, �������һ��������, ����һ��������������,��Ȼ���ж������:

�������Ԫ�����������,�������������Ԫ���źżӹ�,���ս���������Ԫ������������ѧϰ����, ���Ǹ���ѵ�����ݵ�����Ԫ֮���"����Ȩ��"�Լ�ÿ��������Ԫ֮�����ֵ��
������������������ǰ�һ�����ӵĺ���, ����һ�����ĸ�֪��(һ�����Ժ���+һ�������)
�������Ǿ��忴������������һЩϸ�ڡ�
4. ���������
4.1 ����������ʶ
���ڸ�֪����ȱ��,�Լ�Ϊɶ���õ���������������Ѿ�������һЩ�̵�, ��һ��Ļ�,��Ҫ�ǽ����������, ��һ�������Ƕ������������ļ����Ϊʲô�DZ����? �ڶ����������������ܱƽ�����������Ҫֱ�۸����¡�
���ڵ�һ������, �������������ļ�����DZ���Ҫ�е�,��Ϊ���û���˼����, ����������Ч����ʵ������һ����������Ч, ���ҹؼ�����,������������Ȼ�Ǹ�"ֱ��", ���ܽ��з�������ϡ� �������ǰ���ĽǶȽ���������,���Ը���һ��:
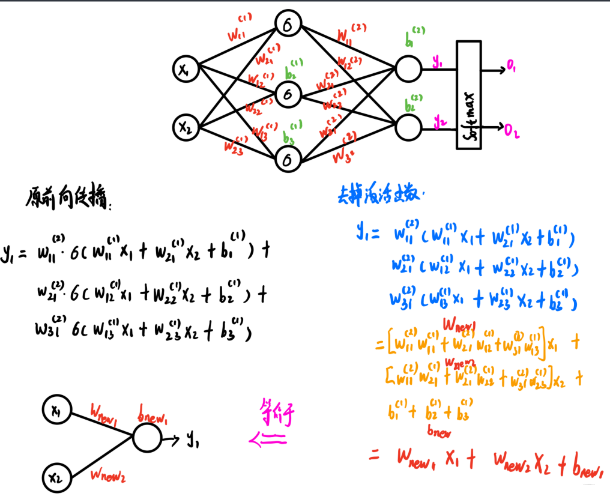
�����ҼĻ���һ�������������, ���Ҳ�Ǻ�����ǰ��ͷ����õ�����, �����������Ԫ,��������
x
1
,
x
2
x_1,x_2
x1?,x2?, ���Ź�һ�����ز�,������ز�3����Ԫ, �����ǽ�һ�������,���2����Ԫ, �õ�
y
1
,
y
2
y_1,y_2
y1?,y2?, �����
y
1
,
y
2
y_1,y_2
y1?,y2?��һ��sortmax����,�õ�������,���ת�����˸���,�����Ȳ��ùܡ� ������ǰ��ͷ�����ʽ��ʱ�����д��
�������� y 1 y_1 y1?�������, ��������������� y 1 y_1 y1?���㹫ʽ, �ұ���ȥ�������ز㼤���(����Ĭ������sigmoid)�ļ��㹫ʽ, ���Է������ȥ���˼����, ���ջ���֮��, ��Ȼ��һ��������������, �����������ϵ�ЧΪһ��һ��������硣
�ڶ�������,������������ܱƽ�����,���ĺ���ʦ��������ֱ�۵Ľ����˽���,����Ҳ�ֻ�����
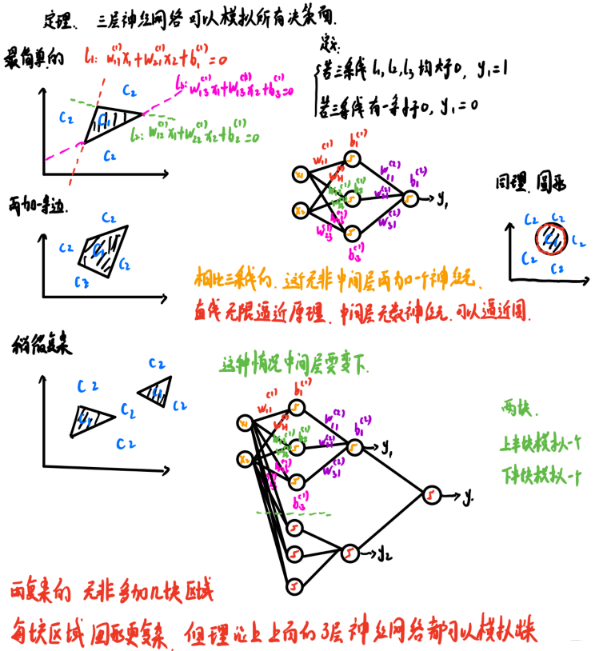
��ô�������һ��������,�����ϲ�������������Ϳ���ģ�����о�������? ��Ϊʲô���ǿ����Ķ�������������Ǻܶ����? ��ʵ, ��������ܱƽ�, ��Ȼ��һ������״̬, ��Ϊ������ʵ������IJ���,��������Ϊָ��, ����ͨ��������������ȥѧϰ�ġ���ʵ֤��, ����һ�����ӵĽ���, �ö���������ֿ����ģ��, Ҫ����һ��������(����������Ԫ)Ч��Ҫ�õĶ�, ������ѵ����Ҫ����, �Ͼ�ֻ��һ��,����������Ԫ, ������������, ��ô�������ѧϰ�����������ӡ� ��Ҳ��Ϊɶ���ܱƽ�����û����ʵ����ʹ�õ�ԭ��
��������Ҿ�����Ϊ�������Ǹ������������ǿ����, ����������綼��������ģ�����о�����, ������Ѹ��ӵľ�����ֿ�,Ȼ���ö��ļ�������ȥģ��, ��ô������
����о��е���ε���˼��, ����һ���������ӵ�����, ͨ���ֿ�, �����üĶ������ȥ���, �����������? ����ͨ���ٷֿ�,��һ�������ĸ�֪��ȥ���,����������,�㶨�˴����⡣
����֪���˶�������ѧϰ����Ҫ�ȵ����֪��ǿ�ö�,��ô,���ѵ�����"��Ȼ����"��? �ĸ�֪��ѧϰ�����ԶԶ������, ����, ��������˸�ǿ���ѧϰ�㷨����洫��(errorr BackPropagation, BP)�㷨, ���Ŀǰ��Ȼ��ʹ�á�
����ѧϰ���������ѧԭ��, ����Ҫ��һ��,������������㷨���Ƶ�, Ҳ���������羿�������ѧϰ��,����ͽ�������һ�¡�
4.2. ǰ��ͷ����㷨��ʽ�Ƶ�
�����ȳ�ʶ�·����㷨:
�������������104ҳ�����㷨��������, ����IJ���,�����dz�ʼ�����в���, Ȼ����������,�������������
y
y
y,�õ���ʧ������ ��ע��,��������Ҫ��ȷ������Ż�����, ��ͨ�������������ĸ��ֲ���,ʹ�����յ���ʧ������С, ���������
f
(
w
)
f(w)
f(w)ָ����������ʧ������
����� f ( w ) f(w) f(w)��, Ȼ����ͨ����ʽ�����Ƴ�ÿһ������ĵ��� d f ( w ) d w k \frac{df(w)}{dw^k} dwkdf(w)?, ����ͨ������ĸ��¹�ʽ,����ÿһ��IJ����ˡ�
�������������������������һ��, Ȼ����չ���������, ������������ϲ�һ���ĵط�,����ʧ�����ļ��������softmax, ��������ƽ������ʧ, ��Ϊ������ѧϰ��softmax������ʽ�Ƶ��ͼ���, ƽ������ʧ֮ǰ�Ƶ���,���ﻻ���µġ�
- ��Զ��������(softmax���,����������ʺ�Ϊ1)
H = ? �� i o i ? log ? ( o i ) H=-\sum_{i} o_{i}^{*} \log \left(o_{i}\right) H=?i��?oi??log(oi?) - ��Զ���������(sigmoid���,ÿ������ڵ�֮�以�����)
H = ? 1 N �� i = 1 N [ o i ? log ? o i + ( 1 ? o i ? ) log ? ( 1 ? o i ) ] H=-\frac{1}{N} \sum_{i=1}^{N}\left[o_{i}^{*} \log o_{i}+\left(1-o_{i}^{*}\right) \log \left(1-o_{i}\right)\right] H=?N1?i=1��N?[oi??logoi?+(1?oi??)log(1?oi?)]
�ټ�¼������������:�����softmax���, ��������������һ����Ϊ1�ķֲ��� ������Ƕ������sigmoid���, ����ķֲ���û��������
- �������һ��è������, �õ������Ҫô��è,Ҫô�ǹ�, ������������ʾ���һ����Ϊ1�ķֲ�����ʱ�����һ��softmax�����
- �������һ���ж��Dz������˵ķ�����, ��ô������п���������, �п���������, Ҳ����������ܲ������Ϊ1�ķֲ�,�����п��ܰ���������,��ʱ�����Ҫʹ��sigmoid�����
��������:
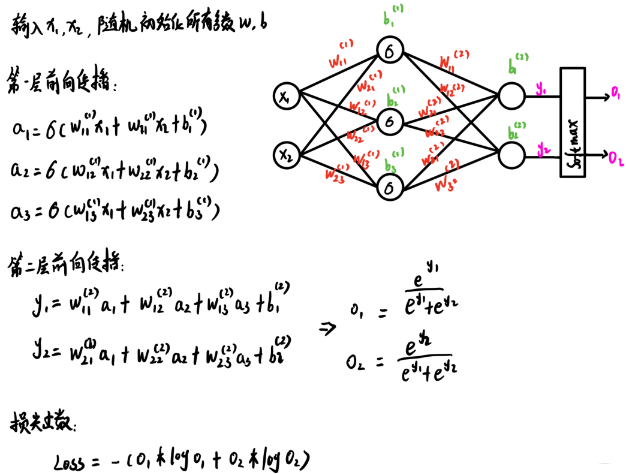
��������Ĺ�ʽ,����һ��ѵ������
{
(
x
1
,
x
2
)
,
l
a
b
e
l
(
o
1
?
,
o
2
?
)
}
\{(x_1,x_2),label(o_1^*,o_2^* )\}
{(x1?,x2?),label(o1??,o2??)}�����labelһ���Ǿ�����one-hot, ���ܵõ�һ����ʧֵ��������ʧ������*����Ӧ�������ϱ��Ǻ�,���dz�,����ͼ������д�˱顣
���濴ͨ���������֮��,��������θ��²���, ���ؼ��ķ���:
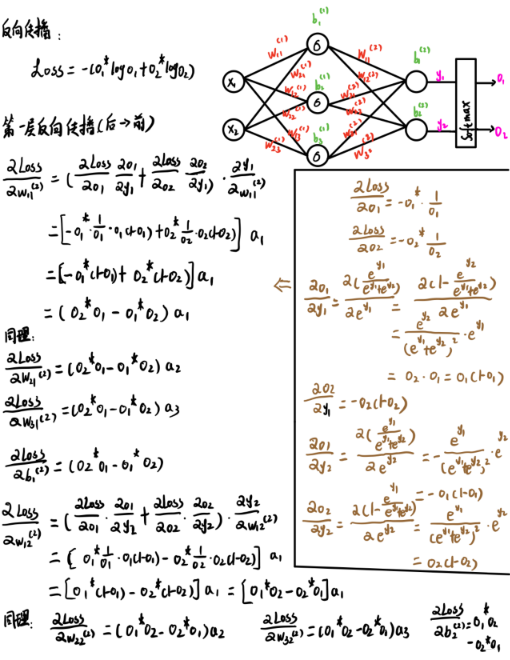
����ǰһ��:

�����������˼��, �����ݶȵ�ʱ��, �ǴӺ�����ǰ��һ����ͨ����ʽ������ġ������������,����������������ֹ�ʽ
y
=
f
(
g
(
h
(
l
(
m
(
x
)
)
)
)
)
y=f(g(h(l(m(x)))))
y=f(g(h(l(m(x)))))
�����ʱ��,������һ����������, �����㵼����ʱ��, ����Ҫ������һ�����������ˡ�
����һ����Ҫע�����, ��������������˵������"��BP�㷨", Ҳ����ÿ�����һ��ѵ���������еIJ�������,��ʵ�������, ��������С��ѵ�����ϵ��ۻ���ʧ���,�����"�ۻ�BP�㷨"
һ����˵,��BP�㷨ÿ�θ���ֻ��Ե�������, �������·dz�Ƶ��, ���Ҳ�ͬ�����������¿��ܻ����"����"���� ���,Ϊ�˴ﵽͬ�����ۻ���С��, ��BP�㷨������������������ �����ַ�����ѵ�����dz����ʱ��,�ٶȸ��졣
����������,������������ݶ��½�(SGD)���ݶ��½�������
�����һ������������ķ����㷨ϸ����, �ٶ������������Ҳ��һ������, ����������ﲻ������, ��ֱ���õ�ʱѧϰ�������ʦ���ѧϰʱ��γ̱ʼ���,�������ʦ�������ﲢû��������ôϸ, ����Щ,����ʹ�����������İ汾�� �������������ϸ�İ汾,�ٿ�����Լ��������汾�ľͷdz������ˡ�
����������ǰ����������:

��������練����������:
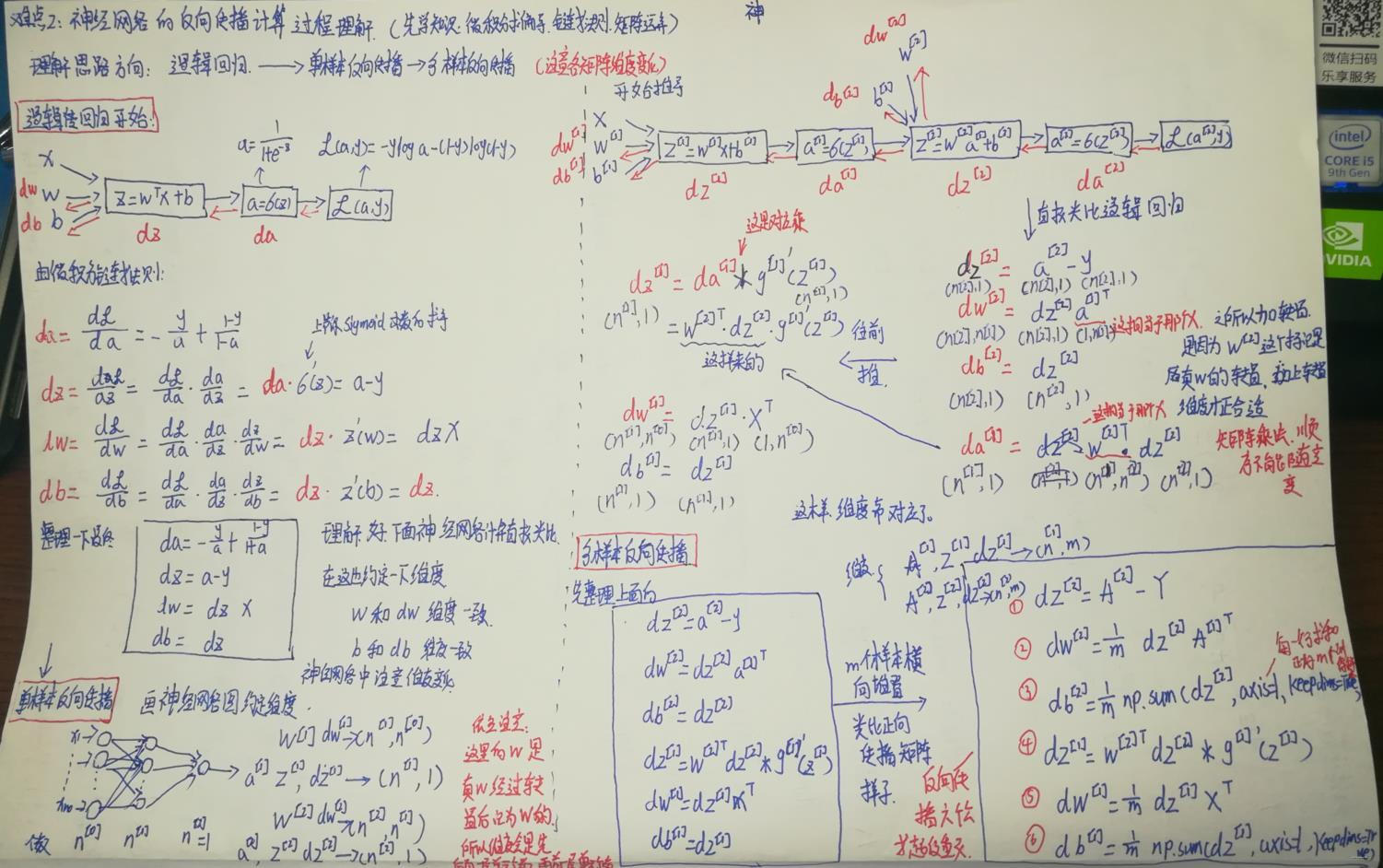
5. ������
����Ͷ���Сʵ����, ����numpyʵ��һ����С������,Ȼ������tf��Pytorch��ܶ����滻,��ѵ�����Ӹ�Ч�� ����, ����numpyʵ�ֵײ��ǰ���ͷ��������б�Ҫ��,�Ͼ����ǻ�������
���������Ǹ���������ݶ�̫�鷳��, ����ʹ�����һ������Щ������, ǰ���ͷ����Ҷ��Ѿ�������ˡ�
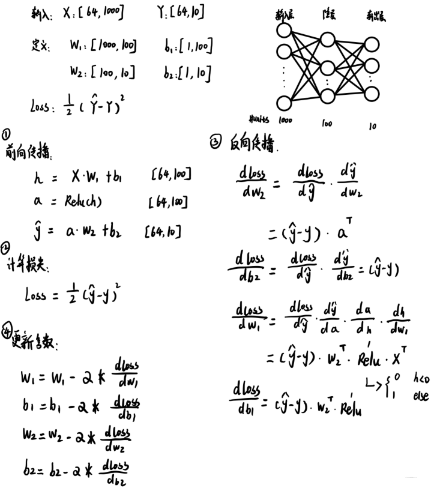
5.1 numpyʵ��������
�������,�����numpyд�Ļ�, ����д�����´���:
# ����������,�����,���ز�,�����IJ���
N, D_in, H, D_out = 64, 1000, 100, 10
# ����ѵ������x,y �����������
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
# �����ʼ������w1, w2
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
# �������ʵ��������ļ������
learning_rate = 1e-6
epochs = 500
for epoch in range(epochs):
# ǰ��
h = x.dot(w1)
h_relu = np.maximum(h, 0)
y_pred = h_relu.dot(w2)
# ������ʧ
loss = np.square(y_pred-y).sum()
print(epoch, loss)
# ����
# w2���ݶ�
grad_y_pred = * (y_pred-y)
grad_w2 = h_relu.T.dot(grad_y_pred)
# w1���ݶ�
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h<0] = 0
grad_w1 = x.T.dot(grad_h)
# ���²���
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
���ﱾ���볢����numpy��ߣһ�������Զ���ܶ�������������, ����ʵ�ֵ�ʱ��,��Ҫ�ò����ֵ䱣���������м�ֵ, ������ʱ����õ�,����һ��Ҫע����Ƿ���ʵ�ֵ�ʱ��, ÿһ��������ݶ�ҲҪ�����,����ǹؼ��ڵ�, ��Ҫ���������� �����������:
class DNN_Model:
def __init__(self, input_dim, layer_units=[1000, 100, 10], alpha=0.001):
self.input_dim = input_dim
self.layer_units = layer_units
self.layer_nums = len(layer_units)
self.alpha = alpha
# �����б�
self.params_dict = defaultdict(dict)
self.gradient_dict = defaultdict(dict)
self.init_params()
# ������ʼ��
def init_params(self):
# ������һ���ھӶ��б�,����[1000, 100, 10] -> [(1000, 100), (100, 10)]
self.neighbors = list(zip(self.layer_units[:-1], self.layer_units[1:]))
# �����������г�ʼ��
for layer_num, unit_num in enumerate(self.neighbors): # 0, 1
self.params_dict[layer_num+1][f'w_{layer_num+1}'] = np.random.rand(unit_num[0], unit_num[1])
self.params_dict[layer_num+1][f'b_{layer_num+1}'] = np.zeros((self.input_dim, unit_num[1]))
# ǰ��
def forward(self, X):
self.params_dict[1]['h_relu_0'] = X
for layer_num in range(self.layer_nums-1): # [(1000, 100), (100, 10)] 1, 2��
if layer_num < self.layer_nums - 2:
h = X.dot(self.params_dict[layer_num+1][f'w_{layer_num+1}'])
h_relu = np.maximum(h, 0)
self.params_dict[layer_num+2][f'h_relu_{layer_num+1}'] = h_relu # �ڶ���������ǵ�һ������
else:
y_pred = self.params_dict[layer_num+1][f'h_relu_{layer_num}'].dot(self.params_dict[layer_num+1][f'w_{layer_num+1}']) #+ self.params_dict[layer_num+1][f'b_{layer_num+1}']
return y_pred
# ������ʧ
def comput_loss(self, y_pred, y):
return np.square(y_pred, y).sum() * 1/2
# ����
def backward(self, y_pred, y):
grad_y_pred = y_pred - y # [64, 10]
for layer_num in range(self.layer_nums-1, 0, -1): # 2, 1
# ���һ��
if layer_num == self.layer_nums-1:
grad_h_relu = grad_y_pred.dot(self.params_dict[layer_num][f'w_{layer_num}'].T)
grad_w = self.params_dict[layer_num][f'h_relu_{layer_num-1}'].T.dot(grad_y_pred)
grad_b = grad_y_pred
self.gradient_dict[layer_num][f'grad_w_{layer_num}'] = grad_w
self.gradient_dict[layer_num][f'grad_b_{layer_num}'] = grad_b
self.gradient_dict[layer_num][f'grad_h_relu_{layer_num-1}'] = grad_h_relu
else:
grad_h_relu = self.gradient_dict[layer_num+1][f'grad_h_relu_{layer_num}']
grad_h = grad_h_relu.copy()
grad_h[grad_h<=0] = 0
grad_h[grad_h>0] = 1
grad_h_relu = grad_h.dot(self.params_dict[layer_num][f'w_{layer_num}'].T)
grad_w = self.params_dict[layer_num][f'h_relu_{layer_num-1}'].T.dot(grad_h)
grad_b = grad_h
self.gradient_dict[layer_num][f'grad_w_{layer_num}'] = grad_w
self.gradient_dict[layer_num][f'grad_b_{layer_num}'] = grad_b
self.gradient_dict[layer_num][f'grad_h_relu_{layer_num-1}'] = grad_h_relu
# �����ݶ�
def update_gradient(self):
for layer_num in range(self.layer_nums-1):
self.params_dict[layer_num+1][f'w_{layer_num+1}'] -= self.alpha * self.gradient_dict[layer_num+1][f'grad_w_{layer_num+1}']
self.params_dict[layer_num+1][f'b_{layer_num+1}'] -= self.alpha * self.gradient_dict[layer_num+1][f'grad_b_{layer_num+1}']
�����������, ֪����������ô����,��ʵ�õ�ʱ��,���ڶ������ֳɵ�����, �ô��Ƿ����dz���,�ݶȶ�������Ǽ���á� ��Ϊ�������ݶȵĹ��̷dz����׳����� ���������ò�ƾ��д���,debug�˰���Ҳû������������̵Ļ���������������̡�
���濴���ÿ��ʵ��������,Ȼ������������
5.2 tf��ܴ������
������Ӧ����model�ӿ�ʵ��, ������Ϊ�˼�,ֱ��keras���, ����ܼ�:
model = tf.keras.Sequential([
tf.keras.layers.Dense(1000, activation='relu', input_shape=(1000,)),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(10, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.mse,
metrics=['accuracy'])
history = model.fit(x, y, batch_size=64, epochs=100, verbose=1)
5.3 Pytorch���������
Pytorch�������Ҳͬ���Ƚϼ�:
# ���Ƕ���һ���������������,����̳���nn.Moduleģ��
class TwoLayerNet(torch.nn.Module):
# �����Ա��
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
# ����ǰ��
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
# �����Ͷ�����һ���������������
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# ����һ��ģ��
model = TwoLayerNet(D_in, H, D_out)
# ��ʼ����������
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
for it in range(1):
# ǰ��
y_pred = model(x)
# ������ʧ
loss = criterion(y_pred, y)
print(it, loss)
# ����, ���²���
optimizer.zero_grad()
loss.backward()
optimizer.step()
������,�������������ᵽ�IJ����Ե�֪ʶ,��������λ�������:
һ�ֲ�������ͣ: �����ݷֳ�ѵ��������֤��, ѵ�������������ݶ�, ����Ȩ��, ��֤�������������, ��ѵ�������͵���֤���������, ��ֹͣѵ��,���ؾ�����С��֤������Ȩ��
��һ�ֲ���������
��Ȼ,���ڻ���������һЩ������,����������, ����ѧϰ��˼·��
6. ȫ����С�;ֲ���С
���������������ֲ����Ž�,�������ֱ�۸���ȫ�ֺ;ֲ�����:
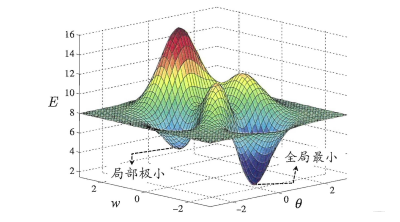
����ͳ�ʼ���IJ����кܴ��ϵ,��������Ҳ������һЩ����������"�ֲ���С":
- �ö��鲻ͬ����ֵ��ʼ�����������, ��������ѵ����, ���������С�Ľ���Ϊ���ղ���,�൱�ڴӲ�ͬ��ʼ�㿪ʼ����
- ģ���˻���
- ʹ������ݶ��½�, �ڼ����ݶ�ʱ�������������, ����dz��õ�
7. ���ѧϰ��ʶ
��һ���������ϲ�û��˵̫��, ������Ҳ����������̫��,��Ϊ�������ѧϰ����һ���Զ��������Ϊ�����Ĵ��֧��,���Ҹ�������ͬ, ������Ҳ��ö��ֶ���, ����CV����ľ���������, NLP�е�ѭ��������ȡ�����ܴ�,��Ҳ����ѧϰ��,���Ժ���ͷֿ����������������ѧϰ��֪ʶ�ˡ� ������Լ�cv,�Ƽ��Լ�nlp��ѧϰ�ʼ�ר���ɡ�
������ģ��, ���������һ�������������������Ŀ, ��������Ҳ�ᵽ,�������ز����Ŀ��Ȼ�����ӵ�����Ԫ������Ч, ��Ϊ����������Ŀ����������ӵ�м��������Ԫ��Ŀ,Ҳ������Ƕ�IJ�����
���滹�ᵽ���ල,Ǩ��ѧϰ, Ȩ����������, ��Щ����Ҳ���Ǻܻ��һЩ֪ʶ��,���滹����д�˵�����������֪ʶ, ����Щ�����������д��cvר��,��������������,����Ͳ����������ˡ�
8. ����֪ʶ: ������������ܳ�ʼ��0����������
���, ����һ������, ����������IJ���һ�㲻�ܳ�ʼ��Ϊ0, ����Ϊɶ? ������ʵ���ܸ���Ŀ�һ����
����, �����ȷ���������ع�, ��������������ǰ��ͷ���:

���ع�Ļ�,��������ʼ��Ϊ0��ʱ��, ��ʱȨ���ǿ��Եõ����µġ�
���濴������������:
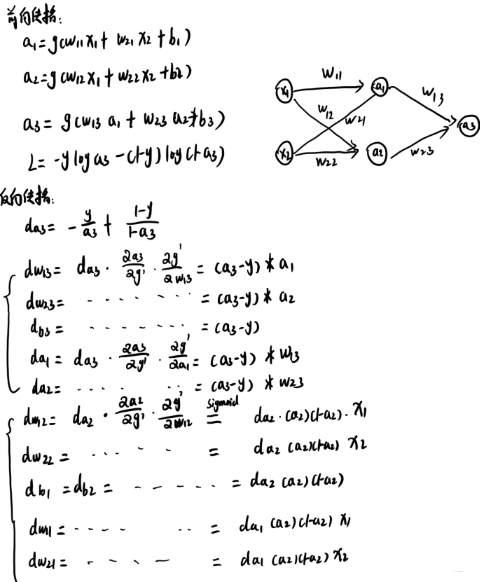
������Ĺ�ʽ
-
�� w w w��ʼ��0, b b b��ʼ��0
- ǰ��: a 1 = g ( 0 ) , a 2 = g ( 0 ) , a 3 = s i g m o i d ( 0 ) a_1=g(0), a_2=g(0), a_3=sigmoid(0) a1?=g(0),a2?=g(0),a3?=sigmoid(0)
- ����: a 1 = a 2 = > d w 13 = d w 23 a_1=a_2=>dw_{13}=dw_{23} a1?=a2?=>dw13?=dw23?, ����ʱ w 13 = w 23 w_{13}=w_{23} w13?=w23?, Ȩ�ضԳ���
���� w w w��ʶΪ0, �ڵ�һ��batch�����ǵ��� d a 1 = d a 2 = 0 da_1=da_2=0 da1?=da2?=0, ����һ��batch�� w 13 w_{13} w13?�� w 23 w_{23} w23?�Լ� b 3 b_3 b3?�ܵõ�����,����Ȩ�صò�������, �ڶ���batch����������,���� w 13 , w 23 w_{13},w_{23} w13?,w23?��Ȳ�Ϊ0, �ᵼ�� d a 1 , d a 2 da_1,da_2 da1?,da2?���,���� w 11 = w 12 , w 21 = w 22 w_{11}=w_{12}, w_{21}=w_{22} w11?=w12?,w21?=w22?�� ��������, ����ѵ�����ٴ�, �������ز���Ԫ���ٸ�, ����Ȩ�ضԳ���,ͬһ����������Ԫ���һ�¡�������������������Ԫ����Գ���, ������������Dz�ͬ��Ԫѧϰ��ͬ��Ϣ, ���������ʼ��Ϊ0, �����Ԫ����ͬһ����Ԫ��,��ע��,������˵�������ܸ����� -
w w w��ʼ��Ϊ0, b b b�����ʼ��
- ��һ��batchǰ��: a 1 = g ( b 1 ) , a 2 = g ( b 2 ) , a 3 = s i g m o i d ( b 3 ) a_1=g(b_1), a_2=g(b_2), a_3=sigmoid(b_3) a1?=g(b1?),a2?=g(b2?),a3?=sigmoid(b3?)
- ����: ���� d a 1 da_1 da1?�� d a 2 da_2 da2?��Ϊ0, ���� d w 11 , d w 12 , d w 21 , d w 22 dw_{11}, dw_{12}, dw_{21}, dw_{22} dw11?,dw12?,dw21?,dw22?Ϊ0, �� w 11 , w 12 , w 21 , w 22 w_{11},w_{12},w_{21},w_{22} w11?,w12?,w21?,w22?�ò�������, Ϊ0��
ģ���ܸ��µ�ֻ�� w 13 , w 23 , b 3 w_{13}, w_{23}, b_3 w13?,w23?,b3?, ͬ��,�ڶ���batch, ���� w 13 , w 23 w_{13},w_{23} w13?,w23?����0��,�������в������ܵõ�����, ���ַ�ʽ���½���, �ݶ���ʧ�ͱ�ը����,ʵ��������������, ��ע��, ��ʱ������������ѵ������
����, ������������ǻ��ڼ������sigmoid�������,�������tanh����relu, ���Ȩ�ض�Ϊ0, �������²�����ѵ���ˡ�
�������ս���:
- ������Ȩ�������ʼ��Ϊ0, �����ᵼ��ͬһ�������Ԫ���һ��, ��������ȫ��һ��, �Ӷ����ֶԳ���, ʹ�ö����Ԫ�����ú�һ����Ԫһ��,���Ӳ��������������
- ���������������������, ����IJ����ǿ��Ը��µ�, �������´���:
- ��һ��,���һ��Ȩ�ظ���, ǰ��Ȩ�ز�����(0)
- �ڶ���,���һ��͵����ڶ������, ǰ��Ϊ0��
- ������ǰ
- �������ع��ǿ��Գ�ʼ��ȫ0��
- ������������sigmoid, ���ɱ��,������۲�������,�����������ݶ���
���һ��, embedding��IJ����ǿ��Գ�ʼ��Ϊ0��, ������Ϊembedding��������õ�ʱ���Ǹ��ֲ�ͬ��
e
m
b
e
d
d
i
n
g
i
embedding_i
embeddingi?�Ľ������,����ͬ��
e
m
b
e
d
d
i
n
g
i
embedding_i
embeddingi?��
e
m
b
e
d
d
i
n
g
j
embedding_j
embeddingj?����ʱ�ߵIJ�ͬ�����絥Ԫ,��ʱ�����ܹ��������µġ�
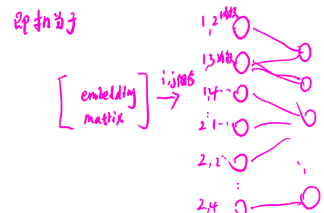
����ᷢ��,��ͬ��Ԫ��ϲ�ͬ, �����֮ǰ��������Ԫ�Գ��ԡ�
�����������ʼ�����,һ������ ( ? 1 d , 1 d ) (-\frac{1}{\sqrt{d}},\frac{1}{\sqrt{d}}) (?d?1?,d?1?)��ʼ��, d d d�Ǹò���Ԫ�ĸ�����
9. ��
��ƪ���µ��������ڽ�����, ����������д�˺ܳ�ʱ��, �����ⶫ��һ����;ͣ��, �Ͳ��Ǻ�Ը���ٻ���д,���Ժ�����Ľ�ѵ����,���Ҫ��ʼ,�ͱ��뾡��д����, ���ֹ����Ժ�ǿ������, �ʺ��������ʱ��д,�����Dz���,ÿ���õ�ʱ�伷���ࡣ ��Ȼ, �����黹����Щ���ӡ� ������
������ܽ��°�, ��ƪ�������˴�����ƪ����д������, �Ӹ�֪����ʼ�Ƶ�����,��֪���о���һ���dz�ΰ��Ľ���, �ѷdz����ӵ�����,�ü����۸�ͳһ����ˡ�
��֪�����ļ�ֵ,���Ǹ��˶��������һ����·, ����������������, ����ܱ���֪����ֳ�һ�����Ժ���+һ�����������ʽ��
�������Ǹ���֪������������, ������ʵ����:
- ���Ժ���:������Ƕ�ij�����������ģ�͵�����,��������ʶ��è��ʱ��,��è�ı�ģ����ô������? �������Ժ�����
- �����: �жϵı�, �ж������������,�����ϲ������������
����һ��ΰ��Ľ���,���Ƿ����㷨, ʹ�ö��������ʹ�ó�Ϊ�˿��ܡ�
������,�Ǿ��������������+�жϵĹ���, ÿ����һ����Ԫ,����Ҫ��������,Ȼ���ж�, Ȼ����жϵĽ��,���뵽��һ����Ԫ��
�������Ժ����ļ���,�����������ʶ������ı�ģ��(����ʶ��è)��һ������, �����м�����ļ���,�����ж����ݵ����ϲ���������������������ģ�͡����Ų��ı���, ���Ѷ������������������
�������֪����ij�̶ֳ��ϼ�ֵ��һ����,���ǰѸ��ӵ�, ���˵�������������������,����ܱ������ˡ����һ���ͨ��������Ԫ�ķ�ʽ,��������������ıƽ�����
���˵���Ժ���Ϊ�������ṩ���������������۵Ļ�, ��ô�������Ϊ�������ṩ����������ļ�ֵ��
���������˺ܶ�ͼƬ,�����ǰ���ͷ����Ĺ�ʽ, Ŀ���Ǹ���ϸ�µ�����������Ĺ���ԭ��, ʵ��ʹ����, �����ֳɵĿ��ʵ�ָ������硣���һ����ʼ��Ϊ0������,Ҳ������ϲ���ʵ�����, Ҳ������ϲ���ʵ����⡣
OK, ���ڰ����β�ͽ����,���波�Ը��µĿ�һЩ, ����͵��˱�Ҷ˹��,�漰������˼�ĸ�����, ��һ��Ҳ��һֱ��ѧ,����û��ѧϰ�Ķ���,ץ��ȥѧϰ���ܽ�,������
�ο�:
- ������ѧϰ�� - ��־��
- ��ͳ��ѧϰ������ - �
- �����ѧϰ�γ̡� - �����
- ����ѧϰ���㽭��ѧ�о����γ�
- ��2�� - ��֪���ʼ�
- ���ѧϰ�ʼ�-dz��������
- ʲô�Ǹ�֪��? ����ʲôȱ�����˹����������˵�һ�κ���