Reference:
Neural Network and Learning Machines: International Edition, 3/e (Author: Haykin, ISBN:9780131293762)
������ר�ü����,ͨ����Ԫ�е����ӶԾ�����д洢;�����������ͨ�ü����,ͨ��������㷨ʵ�ֳ�����˽ṹ��ͬ,�����������ܹ�����ʵ�� ����ʶ��,�������ȵ� ����ͨ������ʵ�ֵ���,���ͨ�ü����Ϊ���ܹ��ﵽ��������Ƶ�Ч��,��Ҫ�Դ���ģ�ͽ���ģ��,�Ӷ�ʵ�����ƵĹ��ܡ�
���ԵĻ����ṹ
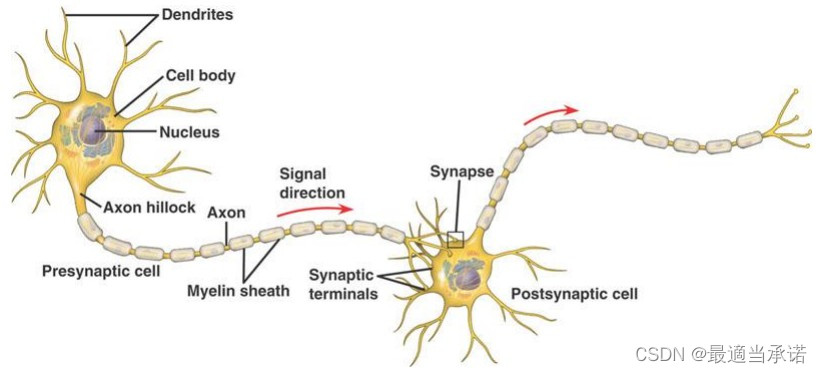
��������Ԫ���,ÿ����Ԫ�� ϸ������,��ͻ����ͻ����������ɡ� ��ͬ��Ԫ֮����ź�����ͻ������Ԫ,����ϸ������,Ȼ��ͨ����ͻȻ�ݵ���һ��ϸ���С�(��ѧ�ź�-���ź�-��ѧ�ź�)
��Ԫ����Ļ�������
- һ����Ԫͬʱ�� �����Ԫ������,Ҳ���Խ��źŴ��ݸ����������ϸ����(����ϸ��Ҳ���ǵ���)
- ��Ԫ���ź��Ƕ��ϸ����Ϣ����ĵ���(��Ϣ�����и�,Ҳ�����м���Ҳ������)(��Ϊͻ�����м�������,Ҳ����������)
- ��Ԫ���ź��������������������Թ�ϵ�����ȴ���һ������ֵ,���źų���һ������ֵ֮��ͻ���������� ���������Կ��� sign ����,����֮�ͳ���һ����ֵ֮��ͻἤ����Ԫ��
- ��Ԫ����ǿ�ȵ��˷ܲ����и��ߵ�������ɵ�,�����ɸ���Ƶ�ʵ���Ч�̼���ɵġ�
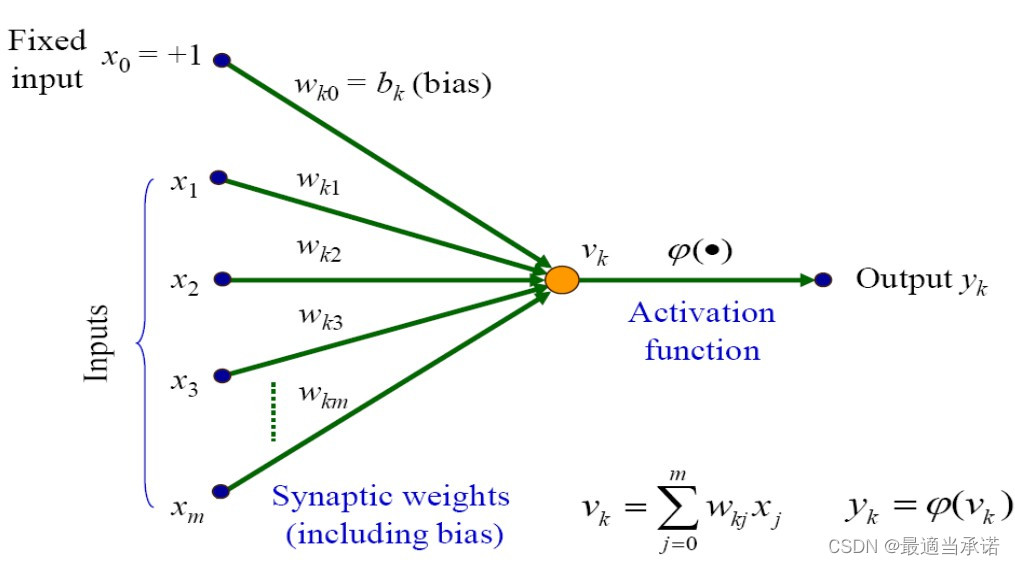
ͨ�����Խṹ����������Ԫģ��
- һ����Ԫ�ж������,Ȼ����һ�������
- �����ź������ڲ�ͬ����Ԫ,�в�ͬ��Ȩ��,�����ɸ�(�����ͺ�������)��
- ��Ԫ������������Լ����������: ����״̬ �� δ������״̬��(0��1)
��˿��Խ���Ԫ������������:
����һ: v ( x ? ) = w ? T x ? + b v(\vec x) =\vec w^T \vec x + b v(x)=wTx+b
����, i n p u t : x ? = [ x 1 , x 2 , �� , x n ] T , w e i g h t s : w ? = [ w 1 , w 2 , �� , w n ] , b : t h r e s h o l d { input: \vec x = [x_1,x_2, \dots, x_n]^T, weights: \vec w =[ w_1,w_2, \dots, w_n], b: threshold } input:x=[x1?,x2?,��,xn?]T,weights:w=[w1?,w2?,��,wn?],b:threshold
���̶�: y = �� ( v ) y = \varphi(v) y=��(v)
����, �� = s i g n { \varphi = sign} ��=sign, ���ڼ����,�� v > = 0 , y = 1 ; v < 0 , y = 0 { v>=0, y =1; v<0, y=0 } v>=0,y=1;v<0,y=0
������յĺ������Ա�ʾΪ:
y = �� ( w ? T x ? + b ) y = \varphi( \vec w^T \vec x +b ) y=��(wTx+b)
��Ϊ ��Ծ����������������,������յĺ���Ҳ������������,���ǵ�������ֵ�������
�����ǽ���������������ĺ���,����
sigmoid function: �� ( v ) = 1 1 + e ? a v {\varphi (v) = \frac{1}{1+e^{-av}}} ��(v)=1+e?av1?
tanh function: �� ( v ) = e x ? e ? x e x + e ? x { \varphi(v) = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}} ��(v)=ex+e?xex?e?x?
�������ҿɵ�,��ô����Ԫ��������������ҿɵ��ġ�
Perceptron
һ����Ԫ�ڳ��ڱ���Ϊ������perceptron,�Ը������������Ƕ���Ԫ��·����Ļ�����
����������
��Ϊ�����������Ϊ0��1,��˿�����Ϊ������,ʵ�ֱ�ǩ�ķ��ࡣ �� w ? T x ? > = 0 {\vec w^T \vec x >=0} wTx>=0,��ǩ���Ϊһ��; �� w ? T x ? < 0 { \vec w^T \vec x <0 } wTx<0,��ǩ���Ϊ����һ�ࡣ������ǿ��Կ��� ������ʵ������һ�����Զ���������ͨ�������һ��ֱ����һ����ƽ��,ʵ�ֲ�ͬ��ǩ�ķ��ࡣ ���Կɷֵ�����(linearly separable)�����ø�����ʵ��,����ֻҪ�����Կɷ�,������һ���ܹ�ʵ�֡�
��εõ���Ҫ��Ȩ��
- ���ڵ�ά�ȵĵ���˵,���ǿ���ֱ�����۹۲�,Ȼ��õ��߽��ߺ�Ȩ�ء�
- ���ڸ�ά�ȵķ�������,����ֻ��ͨ��learning��ʵ�֡�
���ⶨ��
������m����,����ÿһ����
x
?
i
=
[
1
,
x
1
,
x
2
,
��
,
x
n
?
1
]
{\vec x_i = [1, x_1,x_2, \dots, x_{n-1}]}
xi?=[1,x1?,x2?,��,xn?1?],Ȼ������Ҫ�ı�ǩ
d
i
{ d_i }
di?��
�������������Ȩ��
w
?
=
[
b
,
w
1
,
w
2
,
��
,
w
n
?
1
]
{\vec w = [b,w_1,w_2, \dots, w_{n-1}]}
w=[b,w1?,w2?,��,wn?1?]��
������Ҫʵ��, ����ÿһ����,����ʵ��
��
(
w
?
T
x
?
i
)
=
d
i
{ \varphi(\vec w^T \vec x_i) = d_i }
��(wTxi?)=di?.
�������
����m����,�������һ��
w
?
{\vec w}
w�ܹ�ʵ�����е����ȷ���֡�
����
d
i
=
1
{d_i = 1}
di?=1�ĵ���˵,������ִ���,ʹ��
w
?
T
x
?
<
0
{\vec w^T \vec x <0}
wTx<0,����Ӧ�ø���Ȩ��
w
?
n
=
w
?
n
?
1
+
��
w
?
{\vec w_n = \vec w_{n-1} + \Delta \vec w}
wn?=wn?1?+��w��
��
w
\Delta w
��w Ӧ����ʹ��
w
?
t
x
?
{\vec w^t \vec x}
wtx ����ֵ��� ����
��
w
?
=
��
x
?
(
��
>
0
)
{ \Delta \vec w = \eta \vec x (\eta>0) }
��w=��x(��>0)
����
d
i
=
0
{d_i=0}
di?=0�ĵ���˵,������ִ���,����Ӧ�ø���Ȩ��,ʹ�ý������
w
?
T
x
?
{ \vec w^T \vec x }
wTx��������
��
w
?
=
?
��
x
{\Delta \vec w = - \eta x}
��w=?��x
���Ƕ��� ���error:
e
=
d
i
?
w
?
T
x
?
i
{e = d_i - \vec w^T \vec x_i}
e=di??wTxi?
��ô���ǽ�����������������:
��
w
?
=
��
e
x
?
{\Delta \vec w = \eta e \vec x}
��w=��ex
��
{\eta}
����ΪȨ��,�ܹ��ı�ÿһ���ĸ������ʡ�
�㷨
ȷ��ѧϰ����
��
{\eta}
��
�������Ȩ��
w
?
{\vec w}
w
for
x
i
,
d
i
{x_i, d_i}
xi?,di? in all points
����
e
=
d
i
?
w
?
T
x
?
{ e = d_i - \vec w^T \vec x }
e=di??wTx
Ȼ�����Ȩ��:
w
n
=
w
n
?
1
+
��
e
x
?
{ w_n = w_{n-1} + \eta e \vec x }
wn?=wn?1?+��ex
�������Կɷֵ�����,���ǿ��Եȵ������(���б�ǩȫ����ȷ),��ֹͣ����� �������Բ��ɷֵ�����,���ǿ��Լ���һ����ѭ������,Ȼ��ֹͣ��
��������Ȼ�ܹ�ʵ�� ���Կɷ������ԭ��
Perceptron Convergence Theorem: (Rosenblatt, 1962)
������֤���˸������������Կɷֵ������Ȼ��������
�ع�����
�ع���������ʵ�ֶ������е����ȷ���,�������ͨ��������Ϊ�Ż�����,���е�����֮������:
E
(
w
?
)
=
1
2
��
n
i
=
1
e
(
i
)
2
=
1
2
��
i
=
1
n
[
d
(
i
)
?
y
(
i
)
]
2
{E(\vec w) =\frac{1}{2} \sum_n^{i=1}e(i)^2 =\frac{1}{2} \sum^n_{i=1}[d(i)-y(i)]^2 }
E(w)=21?��ni=1?e(i)2=21?��i=1n?[d(i)?y(i)]2
��������
�������Ƕ��弸����ر���:
- d ? = [ d 1 , d 2 , �� , d n ] T \vec d = [d_1,d_2, \dots,d_n]^T d=[d1?,d2?,��,dn?]T
- X = [ x ? 1 , x ? 2 , �� , x ? n ] X=[\vec x_1, \vec x_2, \dots, \vec x_n] X=[x1?,x2?,��,xn?]
- e ? = d ? ? X T ? w ? \vec e = \vec d - X^T \cdot \vec w e=d?XT?w
-
E
(
w
?
)
=
1
2
e
?
T
e
?
E(\vec w) =\frac{1}{2} \vec e^T \vec e
E(w)=21?eTe
���� X ��ά���� (m,n),���� m�DZ�����ά��, n�����ݵ��������
Ȼ��,����Ϊ�˵õ����Ž�,���DZ������cost function�ݶ�Ϊ��ĵ�:
�� ( E ( w ? ) ) = 0 �� w ? ( E ( w ? ) ) = e ? T ? ( ? X T ) ( d ? T ? w ? T X ) X T = 0 w ? T X X T = d ? X T X X T w ? = X d ? T w ? = ( X X T ) ? 1 X d ? T \begin{aligned} \bigtriangledown ( E(\vec w) ) &= 0 \\ \bigtriangledown_{\vec w} ( E(\vec w) ) &= \vec e^T \cdot (-X^T) \\ (\vec d^T - \vec w^T X) X^T &= 0 \\ \vec w^T X X^T &= \vec d X^T \\ X X^T \vec w &=X \vec d^T \\ \vec w &= (X X^T)^{-1}X \vec d^T \\ \end{aligned} ��(E(w))��w?(E(w))(dT?wTX)XTwTXXTXXTww?=0=eT?(?XT)=0=dXT=XdT=(XXT)?1XdT?
���� ( X X T ) ? 1 (X X^T)^{-1} (XXT)?1 Ҳ���� X��α�档�÷��̶���ά�Ƚϵ�ʱ��Ϊ����,���Ƕ��ڽ϶������ʱ,���ڴ�Ҫ��Ƚϸߡ����,���ڽ϶������,����ʹ�����µķ�ʽ: learning��
Learning
���ǽ�
E
(
w
?
)
E(\vec w)
E(w)�����������ֵĺ���,��ô����ÿ�θ���
w
?
\vec w
w������ ʹ��
E
(
w
?
)
E(\vec w)
E(w)�½����ķ���仯,�����ҵ��ֲ����ŵ㡣
���,����ÿ�θ���
w
?
\vec w
w�Ĺ�ʽ����:
w
?
n
=
w
?
n
?
1
?
��
��
w
?
E
(
w
?
)
w
?
n
=
w
?
n
?
1
+
��
e
(
n
)
x
?
(
n
)
\begin{aligned} \vec w_n &= \vec w_{n-1} - \eta \bigtriangledown_{\vec w}E(\vec w) \\ \vec w_n &= \vec w_{n-1} + \eta e(n) \vec x(n) \end{aligned}
wn?wn??=wn?1??����w?E(w)=wn?1?+��e(n)x(n)?
����,
e
(
n
)
=
d
(
n
)
?
w
?
T
x
?
(
n
)
e(n)=d(n)-\vec w^T \vec x(n)
e(n)=d(n)?wTx(n)
Multi-layer Perceptron
���ڵ���������ֻ��ʵ����һ��ֱ�ߵ�ģ��,ֻ����ɶ������Կɷֵ�����Ľ��,���߶������Թ�ϵ�������,������ɸ��Ӹ��ӵ��������,������XOR������ģ�⡣���,�����˶����Ԫ���������Ԫ���硣
XOR��������
����XOR����,������������������ģ��ġ�
| input 1 | input 2 | output |
|---|---|---|
| x 1 x_1 x1? | x 2 x_2 x2? | y y y |
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
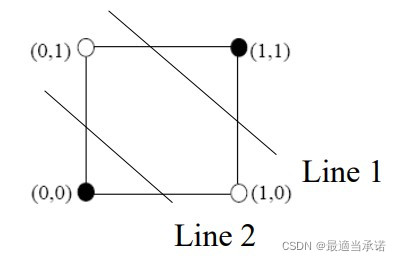
��Ϊ������ֻ������һ���߽���,������������
�������ʹ���������,�����ǵ������:
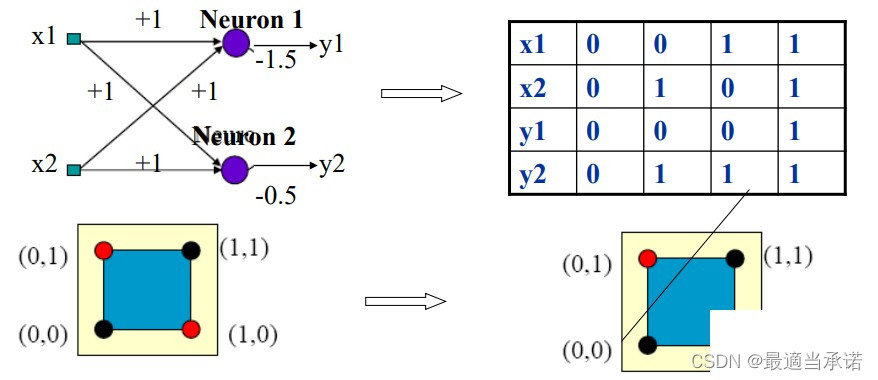
��ʱ���Ƿ���XOR������ (0,1) �� (1,0 )�����һ����,ʵ�����ռ�λ�õ�ת��,����˿������Կɷֵ����⡣ ��ʱ,�������������Ϊ����,������һ��������(��Ԫ)��,�Ϳ���ʵ��XOR�����ģ�⡣
���������
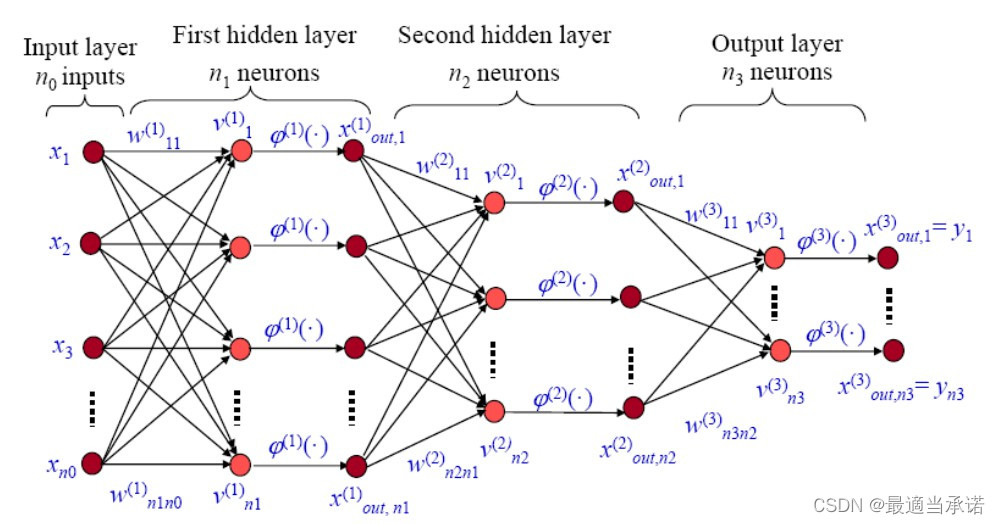
�����ڿ���������IJ���ʱ,�����������,ֻ�������ز������㡣һ��ȫ���Ӳ��һ������������һ��������㡣 ����ÿһ���ȫ���Ӳ�,����
w
?
x
?
+
b
\vec w \vec x+b
wx+b�����ڼ����,��������Ը������ǵ���Ҫ������,����RELU,sigmoid function, atanh�����ȵȡ�
LMS ����
������Ȼ���俴��һ���Ż�����:
��Ҫ���������: ����Ŀǰ�������е�Ȩ�ض���������ɵ�,������Ҫͨ�������������ǵ�label( d )֮������e,��Ȩ�ؽ��и���,��С���ɵ���
����ÿһ�����ݵ������������:
E
(
i
)
=
1
2
��
j
=
1
n
3
e
j
(
i
)
2
=
1
2
��
j
=
1
n
3
[
d
j
(
i
)
?
x
o
u
t
,
j
(
3
)
(
i
)
]
2
E(i) = \frac{1}{2}\sum_{j=1}^{n_3} e_j(i)^2=\frac{1}{2}\sum_{j=1}^{n_3}[d_j(i)- x_{out,j}^{(3)}(i)]^2
E(i)=21?j=1��n3??ej?(i)2=21?j=1��n3??[dj?(i)?xout,j(3)?(i)]2
����ͬʱ��һ�����ݵ���д���:
E
=
1
2
��
i
m
��
j
=
1
n
3
e
j
(
i
)
2
E =\frac{1}{2} \sum_{i}^{m} \sum_{j=1}^{n_3} e_j(i)^2
E=21?i��m?j=1��n3??ej?(i)2
���Ƕ�ÿ������зֱ���,������ȡ������,��Ϊ��������������ֲ�����;�����ݽ��зֱ���,������������noise,�ܹ������ֲ�����,��˶�ÿ���㵥�����д�����ȽϺá�
������ʹ���ݶ��½���:
��
w
j
i
(
s
)
(
n
)
=
?
��
[
?
E
(
n
)
?
w
j
i
(
s
)
(
n
)
]
T
\Delta w_{ji}^{(s)}(n) = - \eta [ \frac{\partial E(n)}{\partial w_{ji}^{(s)}(n)}]^T
��wji(s)?(n)=?��[?wji(s)?(n)?E(n)?]T
����,s��Ӧ��һ,��,����;j��i����һ�㡣
Back Propagation
������Ȩ�ظ���
v
j
(
3
)
=
��
i
n
2
w
j
i
(
3
)
x
o
u
t
,
i
(
2
)
x
o
u
t
,
j
(
3
)
=
��
(
3
)
[
v
j
(
3
)
]
e
r
r
o
r
:
e
j
(
n
)
=
d
j
(
n
)
?
x
o
u
t
,
j
(
3
)
\begin{aligned} v^{(3)}_j &=\sum_i^{n_2}w^{(3)}_{ji} x_{out,i}^{(2)} \\ x_{out,j}^{(3)} &=\varphi^{(3)}[ v_{j}^{(3)} ] \\ error: e_j(n) &= d_j(n)-x_{out,j}^{(3)} \end{aligned}
vj(3)?xout,j(3)?error:ej?(n)?=i��n2??wji(3)?xout,i(2)?=��(3)[vj(3)?]=dj?(n)?xout,j(3)??
���Ǹ�����ʽ����,���ԶԵ�����Ȩ�ؽ��и���:
?
E
?
w
j
i
(
3
)
=
?
E
?
e
j
(
n
)
?
e
j
(
n
)
?
x
o
u
t
,
j
(
3
)
?
x
o
u
t
,
j
(
3
)
?
v
j
(
3
)
?
v
j
3
(
)
?
w
j
i
(
3
)
=
e
j
(
n
)
?
(
?
1
)
?
��
(
3
)
��
[
v
j
(
3
)
]
?
x
o
u
t
,
i
(
2
)
=
?
e
j
(
n
)
��
(
3
)
��
[
v
j
(
3
)
]
x
o
u
t
,
i
(
2
)
\begin{aligned} \frac{\partial E}{\partial w^{(3)}_{ji}} &= \frac{\partial E}{\partial e_j(n)} \frac{\partial e_j(n)}{\partial x^{(3)}_{out,j}} \frac{\partial x^{(3)}_{out,j}}{\partial v_j^{(3)}}\frac{\partial v_j^{3()}}{\partial w^{(3)}_{ji}} \\ &=e_j(n) \cdot (-1)\cdot \varphi^{(3)'}[v_j^{(3)}] \cdot x^{(2)}_{out,i} \\ &= -e_j(n)\varphi^{(3)'}[v^{(3)}_j]x^{(2)}_{out,i} \end{aligned}
?wji(3)??E??=?ej?(n)?E??xout,j(3)??ej?(n)??vj(3)??xout,j(3)???wji(3)??vj3()??=ej?(n)?(?1)?��(3)��[vj(3)?]?xout,i(2)?=?ej?(n)��(3)��[vj(3)?]xout,i(2)??
����,���ǿ��Զ���
��
j
(
3
)
(
n
)
=
e
j
(
n
)
��
(
3
)
��
[
v
j
(
3
)
]
\delta^{(3)}_j(n)=e_j(n)\varphi^{(3)'}[v_j^{(3)}]
��j(3)?(n)=ej?(n)��(3)��[vj(3)?],����ʽ����д��
?
E
?
w
j
i
(
3
)
=
?
��
j
(
3
)
(
n
)
x
o
u
t
,
i
(
2
)
(
n
)
\frac{\partial E}{\partial w^{(3)}_{ji}}=-\delta_j^{(3)}(n)x^{(2)}_{out,i}(n)
?wji(3)??E?=?��j(3)?(n)xout,i(2)?(n)
������ǿ��Եõ�������Ȩ�صĸ��¹�ʽ:
w
j
i
(
3
)
(
n
+
1
)
=
w
j
i
(
3
)
(
n
)
+
��
��
j
(
3
)
(
n
)
x
o
u
t
,
i
(
2
)
(
n
)
w_{ji}^{(3)}(n+1) = w_{ji}^{(3)}(n)+ \eta \delta_j^{(3)}(n)x_{out,i}^{(2)}(n)
wji(3)?(n+1)=wji(3)?(n)+����j(3)?(n)xout,i(2)?(n)
����
��
j
(
3
)
\delta_j^{(3)}
��j(3)?���Կ���������,
x
o
u
t
,
i
(
2
)
(
n
)
x_{out,i}^{(2)}(n)
xout,i(2)?(n)���Կ��������źš�
�ڶ���Ȩ�ظ���
���Dz��ú�����ͬ���ķ�ʽ,������ʽ������⡣
?
E
?
w
j
,
k
(
2
)
=
?
E
?
x
o
u
t
,
i
(
3
)
?
x
o
u
t
,
i
(
3
)
?
v
i
(
3
)
?
v
i
(
3
)
?
x
o
u
t
,
j
(
2
)
?
x
o
u
t
,
j
(
2
)
?
v
j
(
2
)
?
v
j
(
2
)
?
w
j
,
k
(
2
)
=
?
e
i
(
n
)
��
(
3
)
��
[
v
i
(
3
)
]
w
i
,
j
(
2
)
��
(
2
)
��
[
v
j
(
2
)
]
x
o
u
t
,
k
(
1
)
=
?
��
i
(
3
)
w
i
,
j
(
2
)
��
(
2
)
��
[
v
j
(
2
)
]
x
o
u
t
,
k
(
1
)
\begin{aligned} \frac{\partial E}{\partial w_{j,k}^{(2)}} &=\frac{\partial E}{\partial x^{(3)}_{out,i}} \frac{\partial x^{(3)}_{out,i}}{ \partial v_i^{(3)}} \frac{ \partial v_i^{(3)}}{\partial x_{out,j}^{(2)}}\frac{ \partial x_{out,j}^{(2)} }{ \partial v_{j}^{(2)} } \frac{\partial v_{j}^{(2)}}{\partial w_{j,k}^{(2)} } \\ &=-e_{i}(n) \varphi^{(3)'}[ v_i^{(3)} ]w^{(2)}_{i,j} \varphi^{(2)'}[ v_j^{(2)}] x^{(1)}_{out,k} \\ &= -\delta_i^{(3)}w^{(2)}_{i,j}\varphi^{(2)'}[v_j^{(2)}]x_{out,k}^{(1)} \end{aligned}
?wj,k(2)??E??=?xout,i(3)??E??vi(3)??xout,i(3)???xout,j(2)??vi(3)???vj(2)??xout,j(2)???wj,k(2)??vj(2)??=?ei?(n)��(3)��[vi(3)?]wi,j(2)?��(2)��[vj(2)?]xout,k(1)?=?��i(3)?wi,j(2)?��(2)��[vj(2)?]xout,k(1)??
�������ǿ��Կ�����ʽ��i��һ��������,��Ϊ�����ڶ�
w
j
,
k
(
2
)
w_{j,k}^{(2)}
wj,k(2)?������ʱ��,����û�а���i����Ϣ������
w
j
,
k
(
2
)
w_{j,k}^{(2)}
wj,k(2)?���ڵ������е��������������Ӱ��,���ʵ�����������ʽ����Ӧ�ö�i�������!
?
E
?
w
j
,
k
(
2
)
=
?
��
i
n
3
[
��
i
(
3
)
w
i
,
j
(
3
)
]
��
(
2
)
��
[
v
j
(
2
)
]
x
o
u
t
,
k
(
1
)
\begin{aligned} \frac{\partial E}{\partial w_{j,k}^{(2)}} =- \sum_i^{n_3} [ \delta_i^{(3)}w^{(3)}_{i,j}]\varphi^{(2)'}[v_j^{(2)}]x_{out,k}^{(1)} \end{aligned}
?wj,k(2)??E?=?i��n3??[��i(3)?wi,j(3)?]��(2)��[vj(2)?]xout,k(1)??
��ʱ,���Ƕ���һ������:
��
j
(
2
)
=
��
i
n
3
[
��
i
(
3
)
w
i
,
j
(
3
)
]
��
(
2
)
��
[
v
j
(
2
)
]
\delta_j^{(2)}=\sum_i^{n_3} [ \delta_i^{(3)}w^{(3)}_{i,j}]\varphi^{(2)'}[v_j^{(2)}]
��j(2)?=��in3??[��i(3)?wi,j(3)?]��(2)��[vj(2)?]
��ô�ڶ����Ȩ�ؿ���д��:
��
w
j
,
k
(
2
)
=
?
��
j
(
2
)
x
o
u
t
,
k
(
1
)
\Delta w_{j,k}^{(2)} = - \delta_{j}^{(2)}x_{out,k}^{(1)}
��wj,k(2)?=?��j(2)?xout,k(1)?
��һ��Ȩ��
ͬ������ʽ,���ǿ���д��:
��
k
(
1
)
=
��
j
n
2
[
��
j
(
2
)
w
j
k
(
2
)
]
��
(
1
)
��
[
v
k
(
1
)
]
��
w
k
,
l
(
1
)
=
?
��
k
(
1
)
x
l
\begin{aligned} \delta_k^{(1)} &=\sum_j^{n_2}[\delta^{(2)}_j w^{(2)}_{jk}] \varphi^{(1)'}[v^{(1)}_k]\\ \Delta w^{(1)}_{k,l} &= -\delta_k^{(1)}x_{l} \\ \end{aligned}
��k(1)?��wk,l(1)??=j��n2??[��j(2)?wjk(2)?]��(1)��[vk(1)?]=?��k(1)?xl??
Back Propagation
���ǿ��Կ���,����ÿһ�����ݵ�
[
x
1
(
n
)
,
x
2
(
n
)
,
��
,
x
m
(
n
)
]
T
[x_1(n), x_2(n), \dots, x_m(n)]^T
[x1?(n),x2?(n),��,xm?(n)]T,���ǿ������ݵõ����Ľ��,Ȼ���������õ���
��
i
(
3
)
\delta_i^{(3)}
��i(3)?����ȥ���
��
j
(
2
)
\delta_j^{(2)}
��j(2)?,����
��
j
(
2
)
\delta_j^{(2)}
��j(2)?���֮ǰ��
��
k
(
1
)
\delta_k^{(1)}
��k(1)?,���ݲ�ͬ���
��
\delta
���Բ�ͬ���Ȩ�ؽ��и��¡�
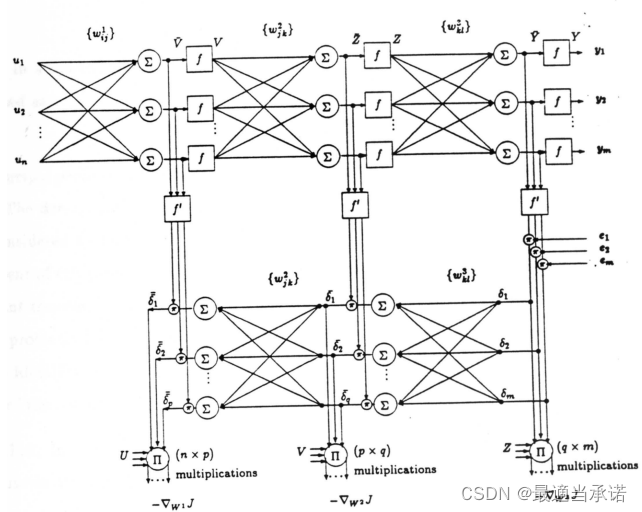
������Ȩ�ظ���
��
w
j
i
(
s
)
(
k
)
=
��
��
w
j
i
(
s
)
(
k
?
1
)
+
��
(
s
)
��
j
(
s
)
(
k
)
x
o
u
t
,
i
(
s
?
1
)
(
k
)
=
��
2
��
w
j
i
(
s
)
(
k
?
2
)
+
��
(
s
)
[
��
��
j
(
s
)
(
k
?
1
)
x
o
u
t
,
i
(
s
?
1
)
(
k
?
1
)
+
��
j
(
s
)
(
k
)
x
o
u
t
,
i
(
s
?
1
)
(
k
)
]
=
��
(
s
)
��
t
=
0
k
��
k
?
t
��
j
(
s
)
(
t
)
x
o
u
t
,
i
(
s
?
1
)
(
t
)
\begin{aligned} \Delta w_{ji}^{(s)}(k) &= \alpha \Delta w_{ji}^{(s)}(k-1)+ \eta^{(s)}\delta_j^{(s)}(k)x^{(s-1)}_{out,i}(k) \\ &= \alpha^2 \Delta w_{ji}^{(s)}(k-2) + \eta^{(s)}[ \alpha \delta_j^{(s)}(k-1)x^{(s-1)}_{out,i}(k-1) +\delta_j^{(s)}(k)x^{(s-1)}_{out,i}(k) ] \\ &=\eta^{(s)}\sum_{t=0}^{k} \alpha^{k-t}\delta_j^{(s)}(t) x_{out,i}^{(s-1)}(t) \end{aligned}
��wji(s)?(k)?=����wji(s)?(k?1)+��(s)��j(s)?(k)xout,i(s?1)?(k)=��2��wji(s)?(k?2)+��(s)[����j(s)?(k?1)xout,i(s?1)?(k?1)+��j(s)?(k)xout,i(s?1)?(k)]=��(s)t=0��k?��k?t��j(s)?(t)xout,i(s?1)?(t)?
����ÿ��Ȩ�صĸ��� ����֮ǰ���������ļ�Ȩƽ���� Խ����������,Ȩ��Խ�ߡ������ĸ����൱�������˹���� ͬʱȨ�صĸ��²���ֻ��һ�������ݵ�Ӱ��,����֮ǰ���е����ݵ�Ӱ��:�������ݶȷ����൱���ܹ�ʹ��֮ǰ���еĵ�����С,����ܹ�ʹ�ý�����ӵ��ȶ���
����ֹͣ�ļ��ַ�ʽ:
- �����С����ֵ
- �ܵĵ�����������һ��ֵ
- ����ƽ��ֵ�ı仯����0
- Ȩ�صı仯����0