这篇文章主要整理kaiming大神所提出的MAE,和沿着MAE发展的几个代表性变体模型。
Masked Autoencoders Are Scalable Vision Learners
MAE的最突出的贡献是在iGPT和BEiT的基础上,化繁为简,让BERT式预训练能真正在CV上也能训到很好,即CV届的BERT/GPT-3!为了理解这句话,可以首先看看kaiming大神在一开头就提出的问题:为什么CV和NLP用的masked autoencoder不一样?(博主的理解是为什么CV非要改装之后才能用Transformer)。比如对于iGPT的做法是马赛克图像使其变成色块patch再输入Transformer;BEiT用dVAE离散化图像再用Decoder还原。主要是因为,
- 结构上(Architecture)。CV和NLP直到最近在结构上都是不一样的,CNN天然适合图像领域,要像Transformer运行需要mask,position token这些不够自然,因此也造成了这第一个困难。不过随着ViT的提出,相比iGPT的马赛克、dVAE的离散化来说,ViT这种patch形态是对信息损失最少且相对高效的。
- 信息密度上(Information density)。语言是由人类产生的信号,具有高度的语义性和信息密集性。相反,图像是具有大量空间冗余的自然信号,其实遮挡patch、word去预测的时候,图像要比文本容易很多,一般只需要通过周边的patch即可推理出来。所以这篇文章给的策略是:mask掉非常多的随机补丁,比如90%以上。这种策略可以在很大程度上减少冗余,增强模型的理解能力。
- Decoder上。语言中解码器预测包含丰富语义信息的缺失单词(语义级别高),而视觉中的解码器重建像素(语义级别低)。对于复原图像来说,如果太关注细节就会损失高维抽象能力,因此这篇文章的策略是非对称编码解码器(asymmetric encoder-decoder),即encoder只负责抽取高维表示且仅对没有掩码的信号进行操作,而轻量级的decoder则负责从隐表示和带掩码的token中进行图像信号还原。
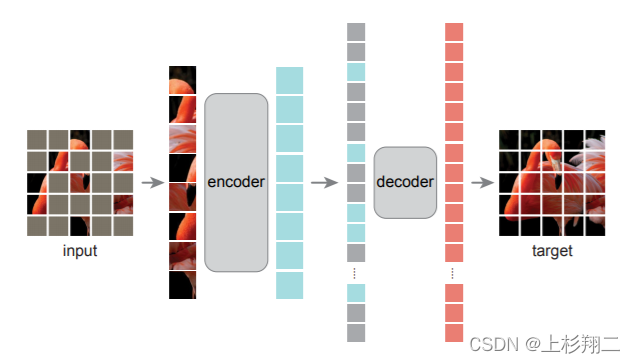
MAE的模型结构如上图,主要有一下几个部件:
- Input。MAE 和 ViT 的做法一致,将图像切成patches。然后采用的非常高的mask rate,以大大减小冗余信息,增加重建 images 的困难。
- MAE Encoder。主体和 ViT 的一样,但是这里的Encoder会只对整个图片 patches 小集合 (例如25%)进行操作,而删除掉有mask的patches,即这个小子集是unmasked patches组成。而不使用BERT那种特殊字符作为掩码标记。
- MAE Decoder。操作集合是整个图片 patches,仅用于预训练期间执行图像重建任务。在非对称的设计下,解码器可以很轻量来缩短预训练的时间。
- Reconstruction。Linear层,归一化的像素算MSE Loss。
从结果上看,MAE在ImageNet-1k过了所有在ImageNet-21k pre-training 的 ViT 变体模型们。证明了重建原图pixel的重要性,这种非常直观的MIM对比起MLM来看,开头的那句CV届的GPT-3应该真的不远了。
- paper:https://arxiv.org/abs/2111.06377
How to Understand Masked Autoencoder
补一篇MAE的理论证明。首先作者整理了MAE的主要贡献:
- 1K数据集训练就有很好效果,可以促使人们重新考虑ViT的研究。此外,性能超监督学习且展现出其强大的scaling能力。
- MAE作为一种生成式模型打败了对比式模型如MoCo。
- 搭起CV和NLP的桥梁。
然后作者提出了五大理论分析问题:
- 1MAE模型的表示空间(representation space)是如何形成的、优化的和传播的?A:MAE中的注意机制等价于一个可学习的积分核变换,其表示能力由巴伦空间Barron space动态更新,位置嵌入作为高维特征空间的坐标。
- 2图像的patch为什么有助于MAE模型的学习?A:在图像的低秩性质的常见假设下,我们证明了MAE的随机补丁选择保留了原始图像的信息,同时降低了计算成本。
- 3为什么MAE模型内部低层和高层输出的特征表示之间没有显著的差异?A:ViT主干中的缩放点积注意在跨层传播过程中提供了稳定的表示。
- 4decoder对于MAE模型不重要吗?A:解码器对于帮助编码器建立更好的表示是至关重要的,即使解码器在预训练后被丢弃。由于MAE解码器中的补丁维数更大,它允许编码器中的表示空间通过巴伦空间的函数更加丰富,以学习更好的基础。
- 5MAE对每一个masked patch的重建仅仅是依据其邻居patch进行推断的吗?A:masked patch的潜在表示是基于由注意机制学习的补丁间拓扑进行全局插值的。
详细数学证明请参看全文:
paper:https://arxiv.org/abs/2202.03670
iBOT:Image BERT Pre-training with Online Tokenizer
大多数 CV 的自监督学习关注的往往是图片的global view比如 MoCo,而没有认真研究 image,而MAE的出现使MIM变成现实。这篇iBOT的关注点主要在于,Online Tokenizer:
- NLP的lingual tokenizer 非常重要,其把词语变成富含语义的 tokens。
- CV的visual tokenizer非常重要,那么它也应该把图片变成富含语义的 tokens。
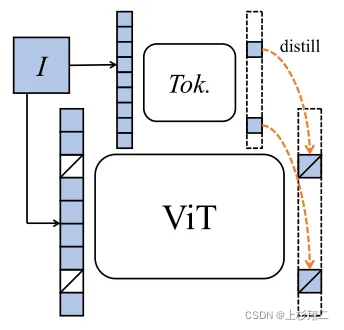
但由于图像连续分布且存在大量冗余的底层细节信息,visual semantic不容易被提取。因此,作者们提出先训练一个 off-the-shelf 的 tokenizer来学习带有丰富语义的 tokens。类似BEiT的dVAE ,但作者希望能学到更高级的语义,这种高级语义的定义为:1)具备完整表征连续图像内容的能力;2)像 NLP 中的 tokenizer 一样具备高层语义。具体方法如上图,主要使用知识蒸馏,待训练的ViT输入masked images,而Online tokenizer 接收原始图像,目标让ViT的重建masked patch token。与MAE的区别就在于,MAE是Decoder来重建,而IBOT让Encoder来输出重建以学习高维信息。
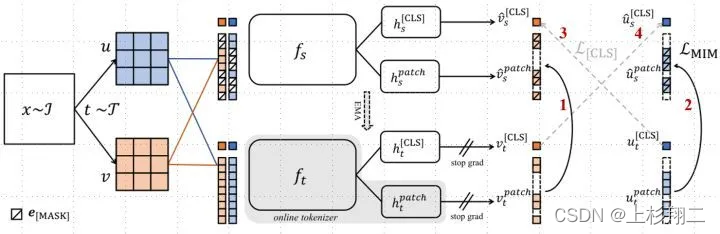
- Input。学生网络输入masked token,教师网络是全部,目标是让学生网络有能力重建。
- loss。损失函数1,2是 patch上的自蒸馏,让学生的输出和教师越接近越好。损失函数3,4是[CLS]上的自蒸馏,让online tokenizer 学习到高语义特征。都是做Contrastive Learning。
paper:https://arxiv.org/abs/2111.07832
Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
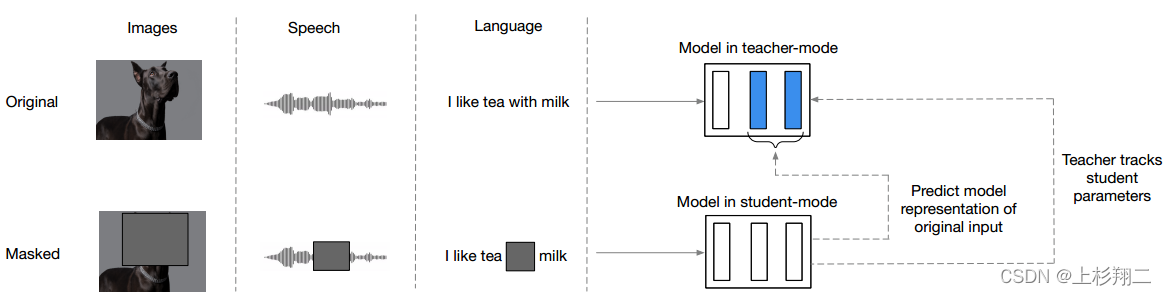
这篇文章扩展Tokenizer到多模态数据,是一个通用的自监督学习框架,同时适用于图像、语音和文本。主要模型架构如上图。其核心就在于对不同模态采用不同的编码方式以及掩码方式。
- 文本 : 常规token embedding和token masking。
- 图像:patch embedding和block-wise masking。
- 语音:多层一维卷积对waveform进行embedding和span masking。
Teacher-Student和iBOT较像,细节可以看原文。
- paper:https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
- project:https://github.com/pytorch/fairseq/tree/main/examples/data2vec