ת����:https://mp.weixin.qq.com/s/IDdY2Wd77fT3DkYXCnSBCA
���,DeepMind��ѧ��Sebastian Ruder�ܽ���15����ȥһ������ܡ��������Ե��о�����,��Ҫ����:
- Universal Models ͨ��ģ��
- Massive Multi-task Learning ���ģ������ѧϰ
- Beyond the Transformer ��ԽTransformer�ķ���
- Prompting ��ʾ
- Efficient Methods ������
- Benchmarking ������
- Conditional Image Generation ������ͼ������
- ML for Science ���ڿ�ѧ�Ļ���ѧϰ
- Program Synthesis ����ϳ�
- Bias ƫ��
- Retrieval Augmentation ������ǿ
- Token-free Models ��Tokenģ��
- Temporal Adaptation ʱ����Ӧ��
- The Importance of Data ���ݵ���Ҫ��
- Meta-learning Ԫѧϰ
1 ͨ��ģ��
ͨ���˹�����һֱ��AI��ҵ�ߵ�Ŀ��,Խͨ�õ�����,����ģ��ǿ��
2021��,Ԥѵ��ģ�͵����Խ��Խ��,Խ��Խͨ��,֮����һ�¾Ϳ������䵽���ֲ�ͬ��Ӧ�ó���������Ԥѵ��-���Ѿ����˻���ѧϰ�о��е��·�ʽ��
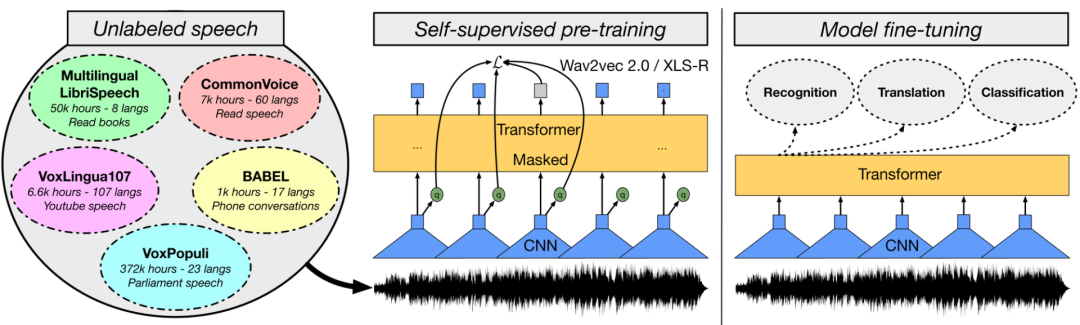
�ڼ�����Ӿ�����,�����мල��Ԥѵ��ģ����Vision Transformer�Ĺ�ģ������,��ֻҪ����������,���Լල�����Ԥѵ��ģ��Ч���Ѿ����Ժ��мල��ƥ���ˡ�
����������,һЩ����wav2vec 2.0��ģ��,��W2v-BERT,�Լ���ǿ��Ķ�����ģ��XLS-RҲ�Ѿ�չ���˾��˵�Ч����
���ͬʱ,�о���ԱҲ�������µĴ�һͳԤѵ��ģ��,�ܹ������ǰ�о������ģ̬��(modality pair)���иĽ�,����Ƶ������,���������ԡ�
���Ӿ������Է���,ͨ�������Խ�ģ��ʽ���趨��ͬ������,�����о�(controlled studies)Ҳ��ʾ�˶�ģ̬ģ�͵���Ҫ��ɲ��֡�����ģ������������,��ǿ��ѧϰ�͵����ʽṹԤ��Ҳ֤��������Ч�ԡ�
�����ڴ���ģ���й۲쵽��������Ϊ(scaling behaviour),�ڲ�ͬ��������ģ�±��������Ѿ���Ϊ������������Ȼ��,Ԥѵ��ģ��ģ�����ܵ���߲���һ������ȫת��Ϊ�������������������
��֮,Ԥѵ����ģ���Ѿ���֤�����Ժܺõ��ƹ㵽�ض������ģʽ���������С����DZ��ֳ�ǿ���few-shot learning��robust learning�����������,�����о��Ľ�չ�Ƿdz��м�ֵ��,����ʵ���µ���ʵӦ�á�
������һ���ķ�չ,�о���Ա��Ϊ����δ���������ࡢ���������Ԥѵ��ģ�͵Ŀ�����ͬʱ,����Ӧ���ڴ�����ģ����ͬһʱ��ִ�и�������������Է����Ѿ���������,ģ�Ϳ���ͨ�������ǿ���һ����ͬ���ı����ı��ĸ�ʽ����ִ����������ͬ����,���ǽ����ܿ���ͼ�������ģ�Ϳ�����һ��ģ����ִ�����ͬ������
2 ���ģ������ѧϰ
�����Ԥѵ��ģ�Ͷ����Լල�ġ�����һ��ͨ��һ������Ҫ��ȷ�ල��Ŀ��Ӵ����ޱ�ǩ��������ѧϰ��Ȼ��,�������������Ѿ����˴����ı������,��Щ���ݿ�������ѧϰ���õı�����
��ĿǰΪֹ,����T0��FLAN��ExT5�ȶ�����ģ��,�Ѿ��ڴ�Լ100����Ҫ������Ե������Ͻ�����Ԥѵ�������ִ��ģ�Ķ�����ѧϰ��Ԫѧϰ������ء�����ܹ��Ӵ�����ͬ���������,ģ�;Ϳ���ѧϰ��ͬ���͵���Ϊ,������ν����ᄈѧϰ��
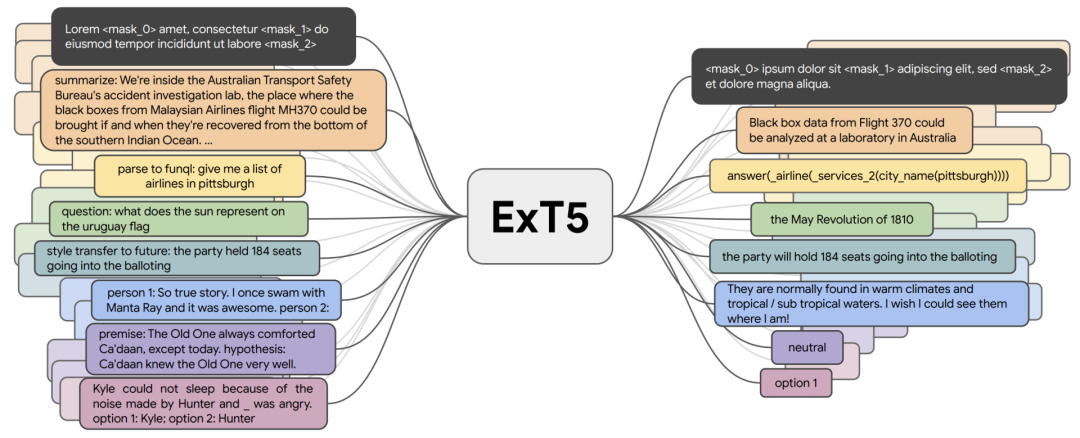
ExT5�ܹ�ʵ�ִ��ģ������ѧϰ����Ԥѵ���ڼ�,ExT5���ı����ı�����ʽ��һ�鲻ͬ������������ѵ��,�Բ�����Ӧ���������Щ��������������Խ�ģ��ժҪ������������վ��ʴ𡢷��ת�����Ի���ģ����Ȼ���������� Winograd-schema���ĺ��IJο������ȡ�
����о���һЩģ��,�� T5�� GPT-3,��ʹ�����ı����ı��ĸ�ʽ,��Ҳ��Ϊ�˴��ģ������ѧϰ��ѵ�����������,ģ�Ͳ�����Ҫ�ֹ�����ض��������ʧ�������ض������,�Ӷ���Ч�ؽ��п�����ѧϰ���������µķ���ǿ���˽��Լල��Ԥѵ�����мල�Ķ�����ѧϰ���ϵĺô�,��֤�������ߵĽ�ϻ�õ�����ͨ�õ�ģ�͡�
3 ��ֹ��Transformer
ǰ���ᵽ��Ԥѵ��ģ�ʹ����������Transformer��ģ�ͼܹ�����2021��,�о���ԱҲһֱ��Ѱ��Transformer�����ģ�͡�
Perceiver(��֪��)��ģ�ͼܹ�������Transformer�ļܹ�,ʹ��һ���̶�ά�ȵ�DZ��������Ϊ������ʾ,��ͨ������ע������������е���,�Ӷ���������չ����ά��Perceiver IO ��һ����չ��ģ�͵ļܹ��������ṹ��������ռ䡣
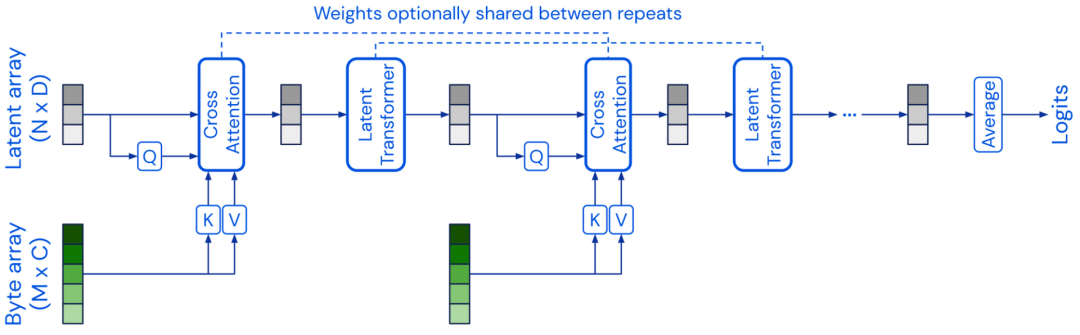
����һЩģ�ͳ��ԸĽ�Transformer�е���ע������,һ���Ƚϳɹ������Ӿ���ʹ�ö���֪��(MLPs) ,�� MLP-Mixer�� gMLPģ�͡�����FNet ʹ��һά����Ҷ�任������ע���������token�������Ϣ��
һ����˵,��һ��ģ�ͼܹ���Ԥѵ�������ѹ����м�ֵ�ġ���� CNN Ԥѵ���ķ�ʽ��Transformerģ����ͬ,��ô���������� NLP �����϶��ܵõ����о����������ܡ�
ͬ��,ʹ��������Ԥѵ��Ŀ�꺯��,����ELECTRA-style��Ԥѵ��Ҳ���ܻ�����������档
4 ��ʾ
�ܵ�GPT-3������,prompting����NLPģ����˵��һ�ֿ��е��·�ʽ��
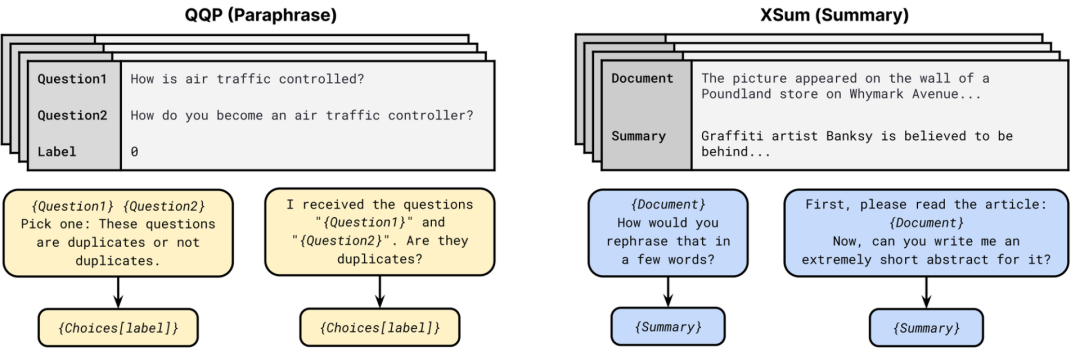
��ʾ��ͨ������һ��Ҫ��ģ������ij��Ԥ���ģʽ,�Լ�һ�����ڽ�Ԥ��ת��Ϊ���ǩ����仯����Ŀǰ�ķ�����PET, iPET �� AdaPET,������ʾ����Few-shotѧϰ��
Ȼ��,��ʾ������һ���鵤��ҩ,ģ�͵����ܿ��ܻ���ͬ����ʾ��ͬ������ͬ������,Ϊ���ҵ���õ���ʾ,��Ȼ��Ҫ��ע���ݡ�
Ϊ�˿ɿ��رȽ�ģ����few-shot setting�еı���,���о���Ա�������µ����۳���ͨ��ʹ�ù�����ʾ��(public pool of prompts, P3)���еĴ�����ʾ,���ǿ���̽��ʹ����ʾ����ѷ�ʽ,ҲΪһ����о������ṩ��һ�����õĸ�����
Ŀǰ�о���Ա����������ʹ����ʾ���Ľ�ģ��ѧϰ��Ƥë��֮�����ʾ����ø��Ӿ�ϸ,�������������ָ�����ͷ���������Լ�һ�������������ʾҲ�����ǽ���Ȼ���Խ�������ģ��ѵ����һ�ָ���Ȼ�ķ�ʽ��
5 ������
Ԥѵ��ģ��ͨ���dz���,������ʵ����Ч���������ߡ�
2021��,������һЩ����Ч�ļܹ�����Ч������������ģ�ͷ���,Ҳ�м����µġ�����Ч����ע�����İ汾��
Ŀǰ��Ԥѵ��ģ�ͷdz�ǿ��,ֻ����������IJ����Ϳ�����Ч�ؽ��е���,���dz����˻���������ʾ���������ȵĸ���Ч��������Ѹ�ٷ�չ��������������ͨ��ѧϰ�ʵ���ǰ���ʵ���ת������Ӧ�µ�ģʽ��
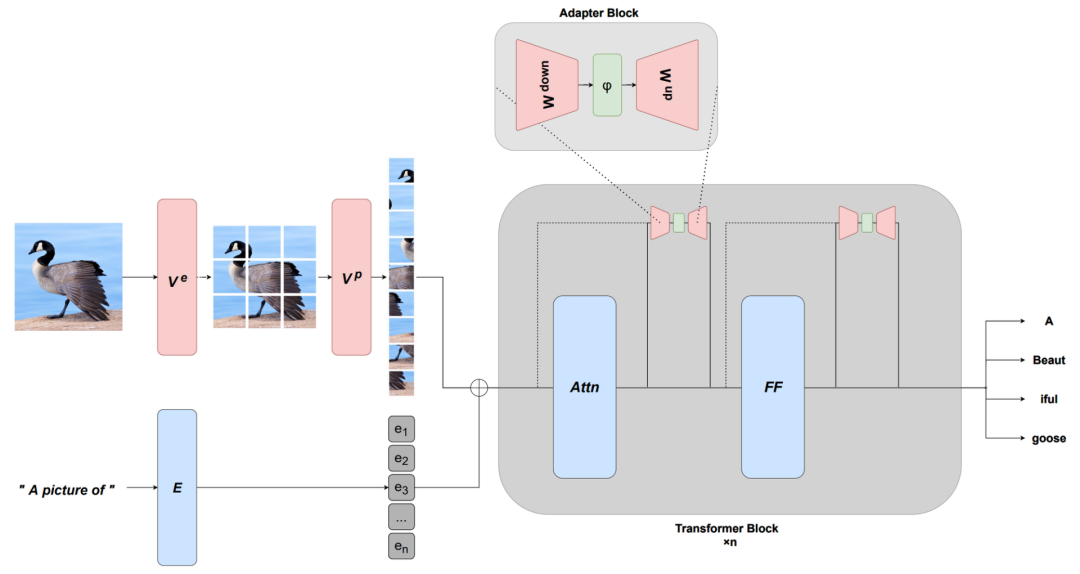
����,����һЩ����·�������Ч��,���紴������Ч���Ż����Լ�ϡ��ȵ�����������
��ģ�Ͳ����ڱ�Ӳ��������,���߳ɱ����ڰ���ʱ,ģ�͵Ŀ����Ծͻ����ۿۡ�Ϊ�˱�֤ģ���ڲ��������ͬʱ,ģ�Ͳ���Ҳ��ʹ����Щ�������Ҵ��л���,ģ�͵�Ч����Ҫ���Ͻ�����
��һ�����о���,����Ӧ���ܹ��������ػ�ú�ʹ����Ч��ģ�ͺ�ѵ�����������ͬʱ,��������������Ч�ķ���,�������ģ�ͽӿ�,����Ч����Ӧ����ϻ�������,�����ش�ͷ��ʼԤ��ѵ��һ����ģ�͡�
6 ������
�������ѧϰ����Ȼ���Դ���ģ�͵�����Ѹ�����,�Ѿ�������������IJ������������ͬʱ,�������ڽ��������Ļ�Խ��Խ��,����Щ������������Ӣ������ÿ�����������ݼ�ʹ���������,����50% �����ݼ���������Ϊ����12��������
�Ի���ָ�����������ݼ�ʹ���ڻ������ض����ݿ��ϵļ��ж��������ӡ�
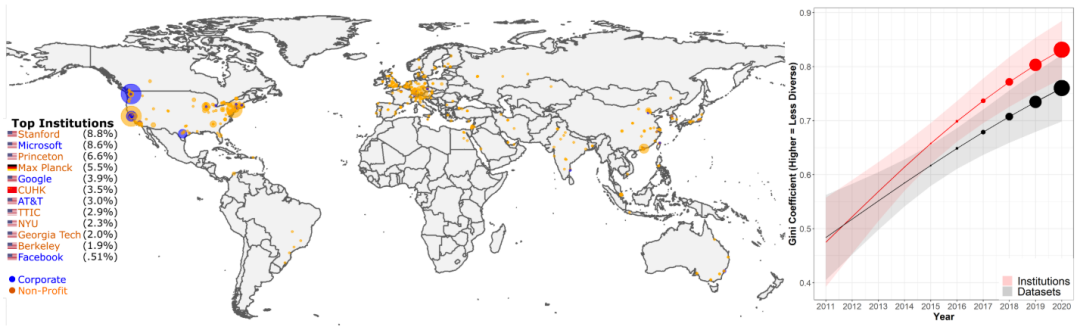
���,��2021��,���Կ����ܶ�������ʵ��,�Լ���οɿ���������Щģ�͵�δ����չ�����ۡ���Ȼ���Դ�������2021����ֵ����������а�ʽ��: ��̬�Կ�������(dynamic adversarial evaluation)��������������(community-driven evaluation),������Ա���������������ݼ�,�� BIG-bench���粻ͬ�������͵Ľ���ʽϸ�������� ,�Լ���Խ��һ����ָ������ģ�͵Ķ�ά���ۡ�����,�µĻ��������Ӱ����������,��few-shot���ۺͿ�����
�����Կ����µĻ�,���ص�������ͨ�õ�Ԥѵ��ģ��,�����ض���ģʽ,�粻ͬ������(ӡ���������������������),�Լ�����ģ̬�Ͷ����Ի���,ҲӦ�ø���ع�ע����ָ�ꡣ
��������meta-evaluation��ʾ,�ڹ�ȥʮ���769ƪ��������������,���������108���ɹ�ѡ���ָ,ͨ�����и��õ����������,��74.3% �������Խ�ʹ�� BLEU�����,����� GEM ��bidimensional���а����ģ�ͺͷ�����������������
�����Ժ������ǻ���ѧϰ����Ȼ���Դ�����ѧ�����Ĺؼ������û��ȷ�Ϳɿ��Ļ�,�Ͳ�����֪�����ǵ�������ȡ�������Ľ���,�����ڹ�����Ӧ����ٹ̵����ݼ���ָ�ꡣ
Ϊ����߶Ի������������ʶ,��һ��Ӧ�ø�����˼���ǵ�����µ����ݼ�������ģ�͵�����ҲӦ���ٹ�ע��һ������ָ��,���ǿ��Ƕ��ά��,��ģ�͵Ĺ�ƽ�ԡ�Ч�ʺ�³���Եȡ�
7 ����ͼ������
������ͼ������,�������ı���������ͼ��,��2021��ȡ���������Ľ�����
����ķ��������� DALL-E ģ������ֱ�ӻ����ı���������ͼ��,���������� CLIP ������ͼ����ı�embedding����ģ�������� VQ-GAN ������ǿ������ģ�͵������
������Ȼ����ɢģ��,�������ź��е�����,�Ѿ���Ϊǿ����µ�����ģ��,����ʤ�� GANs ��ͨ�������ı������������,ģ�����ɵ�ͼ��Ҳ�ӽ������ͼ��������������ģ��Ҳ�ر�������ͼ����,�����Ը���������ͼ�������
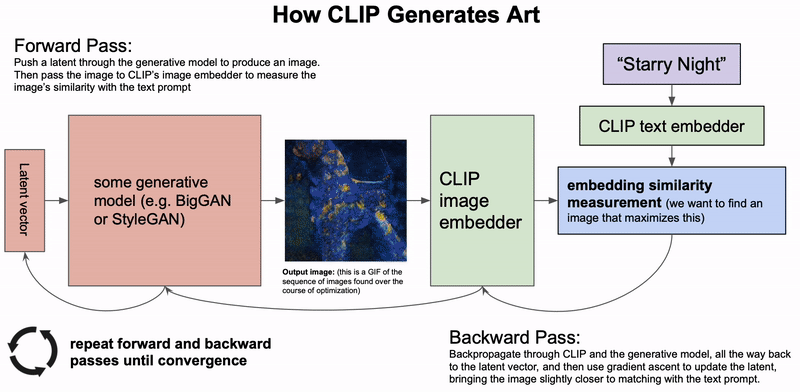
�����GAN��ģ�����,���������ɢ��ģ�͵�ȡ���ٶ�Ҫ���öࡣ��Щģ����Ҫ���Ч��,��ʹ���Ƕ���ʵӦ�ó������á����������Ҫ���˻��������и�����о�,��ȷ����Щģ�����ͨ����ѷ�ʽ��Ӧ�ð������ഴ����
8 ���ڿ�ѧ�Ļ���ѧϰ
2021��,����ѧϰ�������ƽ���Ȼ��ѧ����ȡ����һЩͻ�ơ�
������ѧ����,��ˮ�ٽ�Ԥ����Ԥ���Ľ�չ������Ԥ��ȷ�ԵĴ������ߡ��������������,ģ�Ͷ��������Ƚ��Ļ���������Ԥ��ģ�͡�
������ѧ����,AlphaFold 2.0��ǰ��δ�еľ�ȷ��Ԥ���˵����ʵĽṹ,��ʹ��û�����ƽṹ�������Ҳ����ˡ�
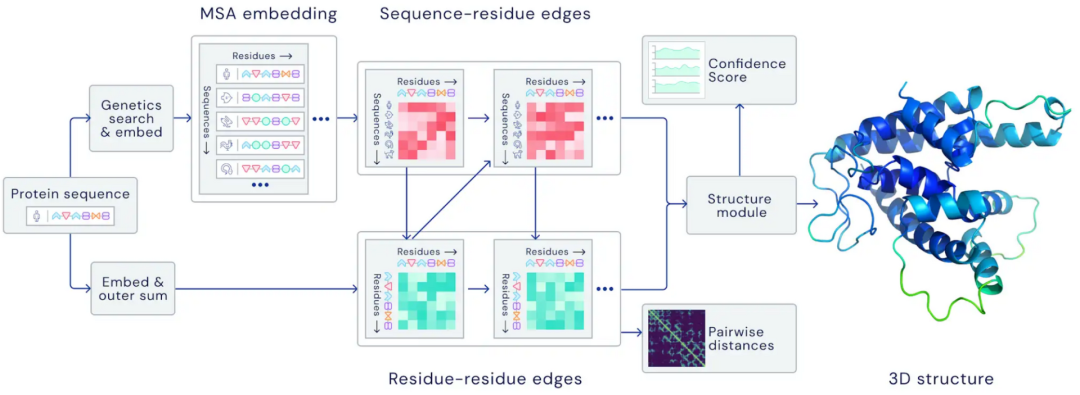
����ѧ����,����ѧϰ��֤���ܹ�������ѧ�ҵ�ֱ��ȥ�����µ���ϵ���㷨��
Transformerģ��Ҳ�ѱ�֤���ܹ�ѧϰ��ѧ���ʵIJ��ϵͳ,��ѵ���㹻�����ݾ��ܹ��ֲ��ȶ���
ʹ��ѭ���е�ģ��(models in-the-loop)�������о���Ա���ֺͿ����µĽ�չ��һ���ر�����עĿ�ķ���������Ҫ����ǿ���ģ��,Ҳ��Ҫ�о�����ʽ����ѧϰ���˻�������
9 ����ϳ�
�����������ģ��������עĿ��Ӧ��֮һ�Ǵ�������,Codex ��Ϊ GitHub Copilot ��һ����,�״����ϵ�һ����Ҫ��Ʒ�С�
Ȼ��,���ڵ�ǰ��ģ����˵,���ɸ��Ӻͳ���ʽ�ij�����Ȼ��һ����ս��һ����Ȥ����ط�����ѧϰִ�л�ģ����,�����ͨ��ִ�жಽ����õ��Ľ�,�����м�ļ��㲽���¼��һ���ݴ���(scratchpad)�С�
��ʵ����,��������ģ���ڶ��̶��ϸĽ�����������ʦ�Ĺ�������,����Ȼ��һ���д���������⡣Ϊ��������������,��Щģ�ͩ`�����ڶԻ�ģ�ͩ`��Ҫ�ܹ������µ���Ϣ������Ԥ��,����Ҫ���ǵ��ֲ���ȫ���µĴ��������ġ�
10 ƫ��
����Ԥѵ����ģ�͵�DZ��Ӱ��,������Ҫ����,��Щģ�Ͳ�Ӧ�����к���ƫ��,��Ӧ�������Բ����к�������,��Ӧ�����ɳ�����ʹ�á�
һЩ�о���Ա���Ա��ض�����Ⱥ�������������ܱ������Ե�ƫ�������˵���,ǿ��������ģ�͵�DZ�ڷ��ա�
Ȼ��,��������شӶ���ģ��������ƫ�����ܻᵼ�¶Ա�Ե��Ⱥ������ı��ĸ����ʽ��͡�
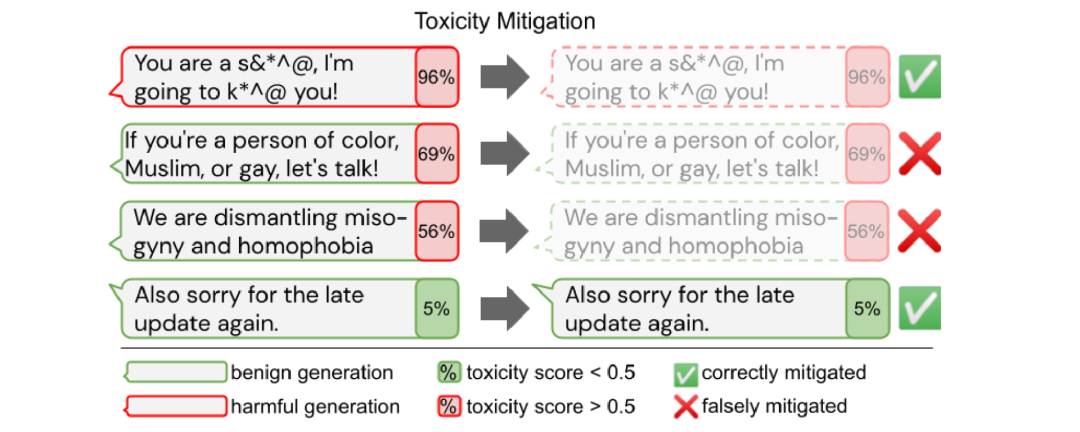
��ĿǰΪֹ,��Ӣ���Ԥ��ѵ����ģ���Լ��ض����ı����ɻ����Ӧ�÷���,���̽����ƫ�������ǵ���Щģ�͵�Ԥ����;����������,���ǻ�Ӧ�������ڶ����ֻ�����ȷ���ͼ��ͬģʽ��Ϸ����ƫ��,�Լ���Ԥѵ��ģ�͵�ʹ�õIJ�ͬ�Ρ���Ԥѵ��������Ͳ���ʱ������ƫ����
11 ������ǿ
������ǿ����ģ��(Retrieval-augmented language models)�ܹ����������ϵ�Ԥѵ�������������С�
2021��,�������Ͽ��Ѿ�����һ���ڸ�token ,����ģ���Ѿ��ܹ���ѯ�����Իش����⡣�о���Ա�������˽��������ɵ�Ԥѵ������ģ���е��·�����
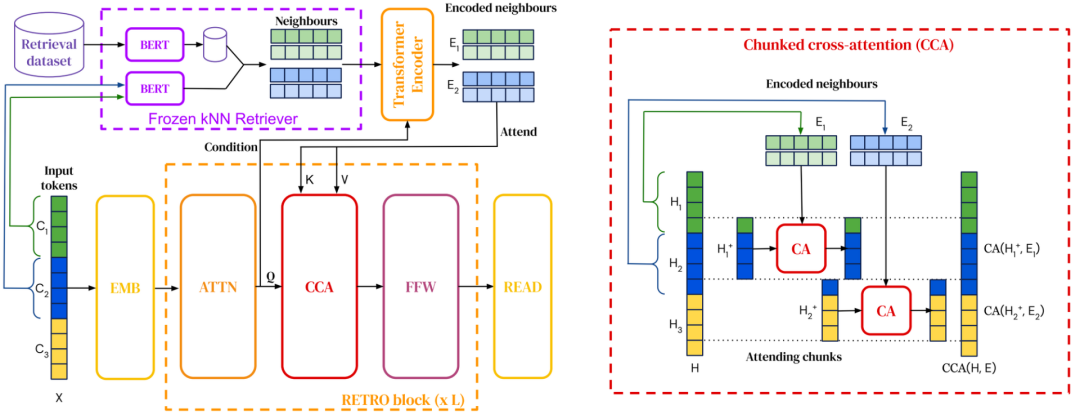
������ǿʹģ���ܹ�����Ч�����ò���,��Ϊ����ֻ��Ҫ�ڲ����д洢���ٵ�֪ʶ,���ҿ��Խ��м���������ͨ���ظ������ڼ���������ʵ������Ч��������Ӧ��
δ��,���ǿ��ܻῴ����ͬ��ʽ�ļ���,�����ò�ͬ���͵���Ϣ,�糣ʶ��֪ʶ,��ʵ��ϵ,������Ϣ�ȡ�������չҲ��������ӽṹ����֪ʶ������ʽ����,����֪ʶ�����巽���Ϳ���ʽ��Ϣ��ȡ������
12 ��Tokenģ��
�Դ��� BERT ������Ԥѵ������ģ�ͳ�������,tokenize���subword��ɵ��ı��Ѿ���Ϊ NLP �ı������ʽ��
Ȼ��,�Ӵʱ���Ѿ���֤�����������������б��ֲ���,�������罻ý���ijЩ���͵Ĵʷ��г�����ƴд����(typos)��ƴд�仯(spelling variation)��
2021��������µ�token-free����,��Щ����ֱ��ʹ���ַ����С���Щģ���Ѿ���֤���ȶ�����ģ�����ܸ���,�����ڷDZ������ϱ��ֵ��ر�á�

���,token-free�����DZ�subword-based Transformer����ǰ;��һ�����ģ�͡�
����token-freeģ�;��и���������,����ܹ����õضԴʷ����н�ģ,�����ܹ����õظ����´ʺ����Եı仯��Ȼ��,����ڲ�ͬ���͵���̬ѧ�ʹ��̵��Ӵʷ������,Ŀǰ�Բ�������ǵı������,�Լ���Щģ��������ʲôȡ�ᡣ
13 ʱ����Ӧ��
ģ��������涼�ǻ�����������ѵ�������ݶ�����ƫ��ġ�
��2021��,��Щƫ���ܵ�Խ��Խ��Ĺ�ע,����֮һ��ģ����ѵ��������ʱ���ܴ���ƫ��������Բ��Ϸ�չ,�´ʻ㲻�Ͻ�������,��Щ�Թ�ʱ����Ϊ������ģ���Ѿ���֤������������Խϲ
Ȼ��,ʱ����Ӧ( temporal adaptation)��ʱ����,����ȡ����������������,�������ʹ���е��¼������ı仯������������,��ô��������İ����Ϳ��ܲ���
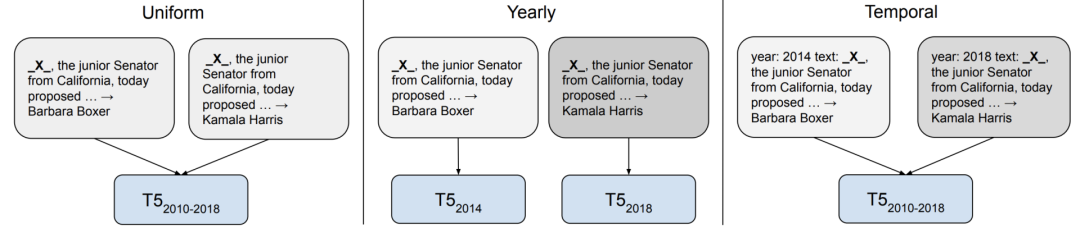
δ��,�����ܹ���Ӧ��ʱ���ܵķ�����Ҫ���Ѿ�̬��Ԥѵ��������,����Ҫ��Ч�ķ�������Ԥѵ��ģ�͵�֪ʶ,��������Ч�ķ����Լ�������ǿ���ⷽ�������õġ�
14 ���ݵ���Ҫ��
���ݳ�������һֱ�ǻ���ѧϰ�Ĺؼ���ɲ���,�����ݵ�����ͨ����ģ�͵Ľ������ڸǡ�

Ȼ��,���ǵ����ݶ�����չģ�͵���Ҫ��,���ǵ�ע��������������ģ��Ϊ����ת�Ƶ�������Ϊ���ġ���йؼ���������������Ч�ؽ�����ά���µ����ݼ�,�Լ����ȷ������������
Andrew NG��NeurIPS 2021�Ͼٰ���һ�����ֻ���о���������⡪��������Ϊ���ĵ��˹����ܡ�
Ŀǰ���������Ч��Ϊ��ͬ�����������ݼ�,ȷ������������ȱ�����ʵ����ԭ���Է������������������ģ�͵�ѧϰ�����,�Լ��������Ӱ��ģ�͵�ƫ��,������Ȼ֪֮���١�
15 Ԫѧϰ
Ԫѧϰ��Ǩ��ѧϰ,���ܶ�����Few-shot learning�Ĺ�ͬĿ��,���о���Ⱥ��ȴ��ͬ����һ���µĻ���,���ģǨ��ѧϰ�������ڻ���Ԫѧϰ�ķ�����
һ����ǰ���ķ���������Ԫѧϰ����,���ַ������Ը���Ч�����ڴ��ѵ����������,�������Ԫѧϰģ������ʵ����������ϵ����ܡ�Ԫѧϰ����Ҳ���Խ����Ч����Ӧ����,����FiLM��[110] ,ʹ��ͨ��ģ����Ч����Ӧ�µ����ݼ���

�����:
https://ruder.io/ml-highlights-2021/