1 简介
论文题目:Improving Event Detection via Open-domain Trigger Knowledge
论文来源:ACL 2020
论文链接:https://aclanthology.org/2020.acl-main.522.pdf
代码链接:https://github.com/shuaiwa16/ekd
1.1 动机
- 由于标记数据的长尾问题(大量的类别仅有少量的样本)和生成数据的同质性,以前的方法在未见过或者稀疏的数据上表现不佳,在密集的数据上过拟合。
1.2 创新
- 第一个利用开放域的触发词知识提高事件检测的性能。
- 提出了一个新的teacher-student模型,从标记和未标记的数据中学习,减少标记中的内置偏差。
2 方法
2.1 知识收集
从WordNet中收集开放域触发词知识,分为下面两个步骤:
- 消除单词的歧义:使用IMS消岐,然后使用Stanford CoreNLP获得特征(词性标注、句法分析)。
- 判断是否触发事件:利用一个查表的方法,判断是否触发事件。
2.2 模型

模型的整体框架如上图,主要包括下面几部分:
- 特征抽取:使用BERT对句子进行编码。
- 事件预测:对于带标注的数据,预测每个词的事件类型。公式如下:

|

|
- 知识蒸馏:知识蒸馏的目标是使teacher模型的概率等于student模型的概率(公式如下),两个模型共享参数,teacher模型的输入为 S + S^+ S+(Knowledge-attending Sentences),通过开放域触发词知识,使用B-TRI和E-TRI标注触发词的开始和结束边界。如原始句子为 S = { w 1 , w 2 , . . . , w i , . . . , w n } S=\{w_1,w_2,...,w_i,...,w_n\} S={w1?,w2?,...,wi?,...,wn?}, w i w_i wi?为开放域触发词知识定义的触发词, S + = { w 1 , w 2 , . . . , B ? T R I , w i , E ? T R I , . . . , w n } S^+=\{w_1,w_2,...,B-TRI,w_i,E-TRI,...,w_n\} S+={w1?,w2?,...,B?TRI,wi?,E?TRI,...,wn?}。B-TRI和E-TRI在知识收集的句子上微调(mask的概率为15%)。student模型的输入为 S ? S^- S?(Knowledge-absent Sentences),随机mask由开放域触发词知识定义的触发词,如 S ? = { w 1 , w 2 , . . . , [ M A S K ] , . . . , w n } S^-=\{w_1,w_2,...,[MASK],...,w_n\} S?={w1?,w2?,...,[MASK],...,wn?}。使用KL散度最小化概率分布之间的差异,公式如下:

|
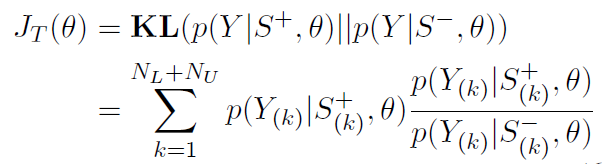
|
- 联合训练:优化的目标为带标注数据的监督loss和未标注数据的KL散度loss,公式如下:

3 实验
在ACE 2005数据集上的实验结果如下图:

为了评测是否将知识蒸馏到模型中,在测试集上观察带和不带开放域触发词知识的实验效果,结果如下图:

在领域迁移情形下的实验结果:

不同频率触发词的实验结果:

使用三种不同的知识,验证模型是否可以蒸馏其他的知识类型,实验结果如下图:

Case Study:
