-
CBAM:论文地址
-
目的:
卷积操作是通过混合通道和空间两个维度的信息来特征提取的。在注意力方面,SE仅关注了通道注意力,没考虑空间方面的注意力。因此,本文提出了 CBAM――一种同时关注通道和空间注意力的卷积模块,可以用于CNNs架构中,以提升feature map的特征表达能力。 -
网络结构:
网络主结构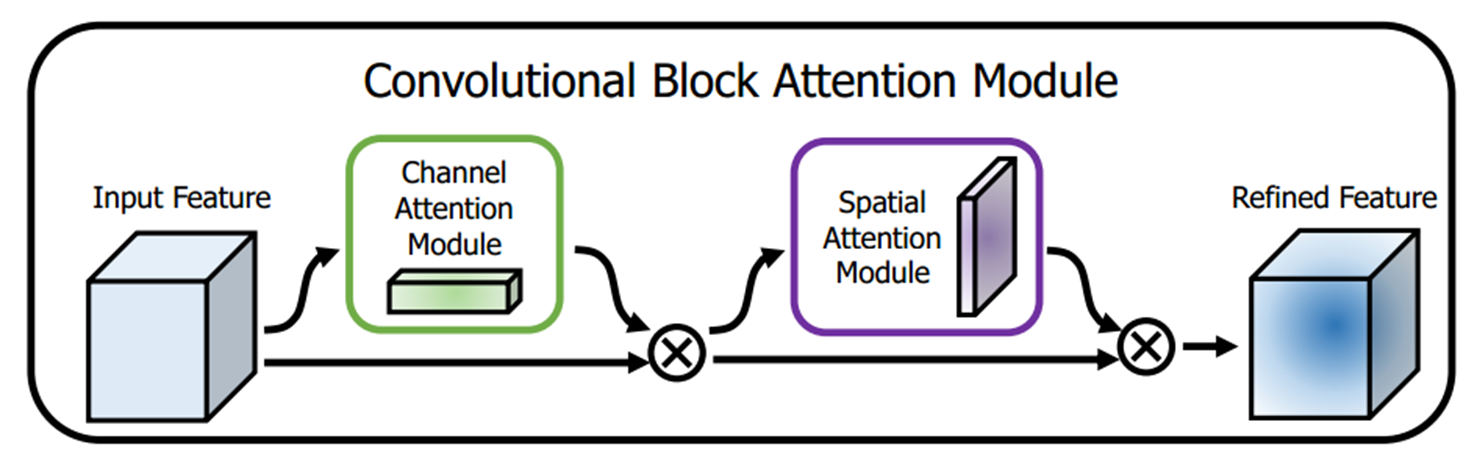
CAM和SAM的结构
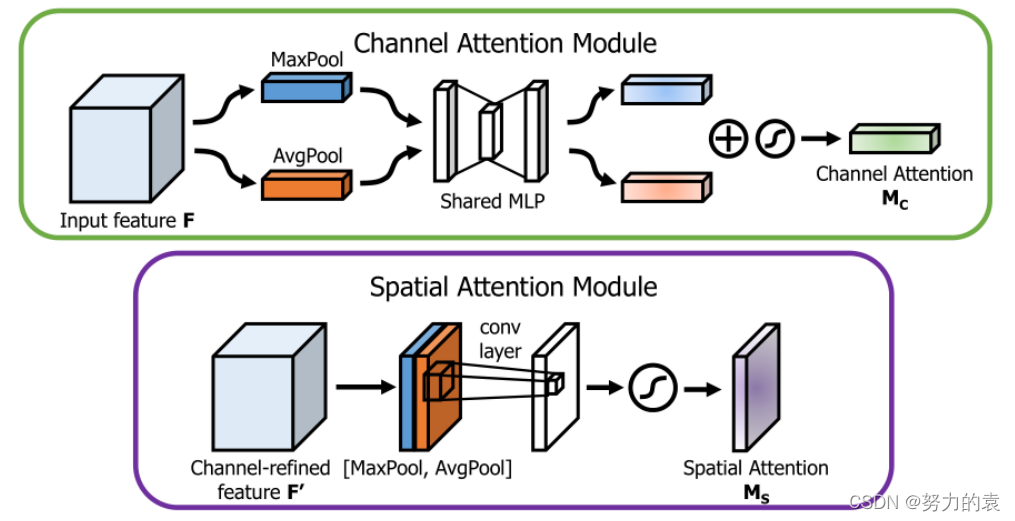
CAM:通道注意力机制就是学习一个不同通道的加权系数,同时考虑到了所有区域
SAM:空间注意力机制就是学习整个画面不同区域的系数,同时考虑到了所有通道。

-
Pytorch代码实现:
import torch from torch import nn class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() self.register_buffer() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x)