2.5. 自动微分
作者 github链接: github链接
练习
- 证明一个矩阵 A \mathbf{A} A的转置的转置是 A \mathbf{A} A,即 ( A ? ) ? = A (\mathbf{A}^\top)^\top = \mathbf{A} (A?)?=A。
- 给出两个矩阵 A \mathbf{A} A和 B \mathbf{B} B,证明“它们转置的和”等于“它们和的转置”,即 A ? + B ? = ( A + B ) ? \mathbf{A}^\top + \mathbf{B}^\top = (\mathbf{A} + \mathbf{B})^\top A?+B?=(A+B)?。
- 给定任意方阵 A \mathbf{A} A, A + A ? \mathbf{A} + \mathbf{A}^\top A+A?总是对称的吗?为什么?
- 我们在本节中定义了形状
(
2
,
3
,
4
)
(2,3,4)
(2,3,4)的张量
X。len(X)的输出结果是什么? - 对于任意形状的张量
X,len(X)是否总是对应于X特定轴的长度?这个轴是什么? - 运行
A/A.sum(axis=1),看看会发生什么。你能分析原因吗? - 考虑一个具有形状 ( 2 , 3 , 4 ) (2,3,4) (2,3,4)的张量,在轴0、1、2上的求和输出是什么形状?
- 为
linalg.norm函数提供3个或更多轴的张量,并观察其输出。对于任意形状的张量这个函数计算得到什么?
练习参考答案
- 为什么计算二阶导数比一阶导数的开销要更大?
因为二阶导数是在一阶导数运算过的基础上进行的,所以计算二阶导数必然比一阶导数的开销要更大 - 在运行反向传播函数之后,立即再次运行它,看看会发生什么。
会报错的,对于Pytorch来说,前向过程建立计算图,反向传播后释放。因为计算图的中间结果已经被释放了,所以第二次运行反向传播就会出错。这时在 backward 函数中加上参数 retain_graph=True,就能两次运行反向传播了。 - 在控制流的例子中,我们计算
d关于a的导数,如果我们将变量a更改为随机向量或矩阵,会发生什么?
发生运行时错误,在Pytorch中,不让张量对张量求导,只允许标量对张量求导。如果想对一个非标量调用backward(),则需要传入一个gradient参数。 - 重新设计一个求控制流梯度的例子,运行并分析结果。
#当 a 的范数大于10时,梯度为所有元素为 1 的向量;当 a 的梯度不大于 10 时,梯度为所有元素为 2 的向量。
def f(a):
if a.norm() > 10:
b = a
else:
b = 2 * a
return b.sum()
a = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0], requires_grad=True)
d = f(a)
d.backward()
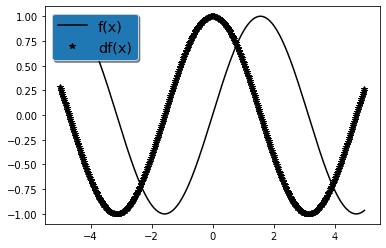
- 使 f ( x ) = sin ? ( x ) f(x)=\sin(x) f(x)=sin(x),绘制 f ( x ) f(x) f(x)和 d f ( x ) d x \frac{df(x)}{dx} dxdf(x)?的图像,其中后者不使用 f ′ ( x ) = cos ? ( x ) f'(x)=\cos(x) f′(x)=cos(x)。
其中后者不使用
f
′
(
x
)
=
cos
?
(
x
)
f'(x)=\cos(x)
f′(x)=cos(x),说明这个题的本意是让我们把函数求导得到的导数值都存下来,根据这些存下来的df值,画出
f
′
(
x
)
f'(x)
f′(x)
#导入相应的库
import numpy as np
import torch
import matplotlib.pyplot as plt
#做一些定义
x = np.arange(-5, 5, 0.02)#定义自变量在[5,5]之间,每个数间隔0.02
f = np.sin(x)
df = []
for i in x:
#对x的每一个值都去求一下导数
v = torch.tensor(i,requires_grad=True)
y = torch.sin(v)
y.backward()
df.append(v.grad)
#绘图部分
# Create plots with pre-defined labels.
fig, ax = plt.subplots()
ax.plot(x, f, 'k', label='f(x)')
ax.plot(x, df, 'k*', label='df(x)')
legend = ax.legend(loc='upper left', shadow=True, fontsize='x-large')
# Put a nicer background color on the legend.
legend.get_frame().set_facecolor('C0')
plt.show()