Linguistic Regularities in Continuous Space Word Representations
语言规律在连续单词规律中的表示
第四周阅读材料
该论文检查了由输入层权重隐式学习的向量空间的单词表示
介绍
神经网络语言模型的一个特征是将单词表示为高维实值向量,单词通过一个训练过的查找表转换为实值向量,用作神经网络的输入,这些模型的主要优点之一是 分布式表示实现了经典 n-gram 语言模型无法实现的泛化水平,n-gram 模型其中相似的词可能具有相似的向量。因此,当模型参数根据特定单词或单词序列进行调整时,其相似单词和序列的出现也会相应变换。
在训练模型的过程中,作者发现训练过的单词表示 实际上以非常简单的方式捕获了有意义的句法和语义规律。具体来说,规则被观察为共享特定关系的词对之间的恒定向量偏移。
模型
基于递归神经网络,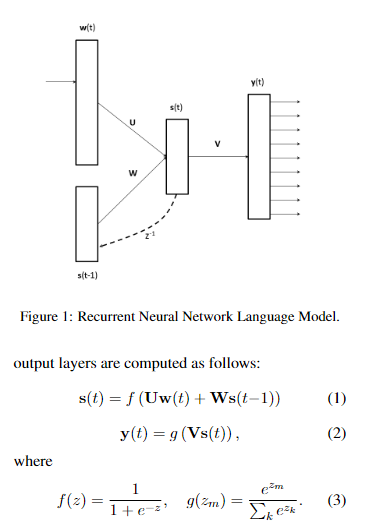
在这个框架中,单词表示存在于 U 的列中,每列代表一个单词。 RNN 通过反向传播进行训练,以最大化模型下的数据对数似然值。模型本身并不了解句法、形态或语义。
测量语言规律
句法测试集:
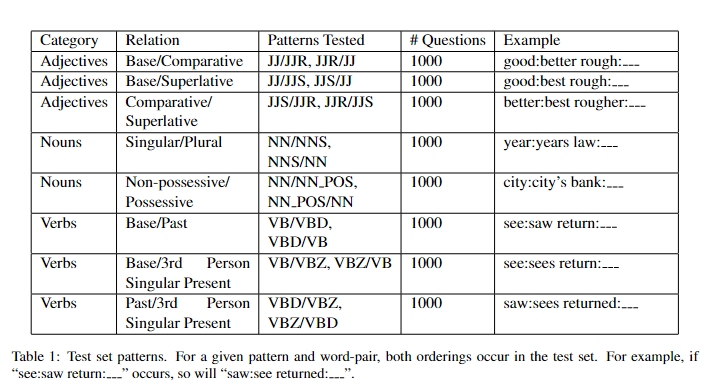
form “a is to b as c is to __ ”
选择了 100 个最常见的比较形容词(标记为 JJR 的词); 100 个最常见的复数名词 (NNS); 100 个最常见的所有格名词 (NN POS);和 100 个最常见的基本形式动词 (VB)。
语义测试集:
该数据集包含 79 个细粒度的词关系,其中 10 个用于训练,69 个用于测试。每个关系都以 3 或 4 个黄金词对为例。给定一组假定具有相同关系的词对,任务是根据这种关系保持的程度对目标词对进行排序。比如
For example, take the Class-Inclusion:Singular Collective relation with the pro-totypical word pair clothing:shirt. To measure the degree that a target word pair dish:bowl has the same relation, we form the analogy “clothing is to shirt as dish is to bowl,” and ask how valid it is
矢量偏移法:
句法和语义任务都被表述为类比问题。作者发现基于余弦距离的简单矢量偏移方法在解决这些问题方面非常有效。在这种方法中,我们假设关系以向量偏移量的形式存在,因此在嵌入空间中,共享特定关系的所有词对都通过相同的常量偏移量相关联。
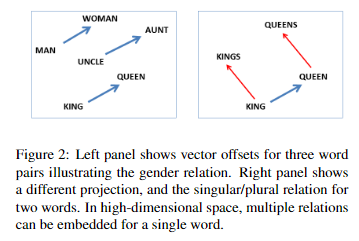
下图中左图显示了三个词对的向量偏移量,说明了性别关系。右图显示了不同的投影,以及两个单词的单数/复数关系。
在高维空间中,单个词可以嵌入多个关系。
在这个模型中,为了回答类比问题 a:b c:d 其中 d 未知,我们找到嵌入向量 xa、xb、xc(均归一化为单位范数),并计算 y = xb -xa + xc。 y 是期望成为最佳答案的单词的连续空间表示。当然,y可能不存在任何单词,然后搜索其嵌入向量与 y 具有最大余弦相似度的单词并将其输出:
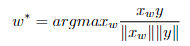
结论
作者提出了一种普遍适用的向量偏移方法,用于识别连续空间词表示中的语言规律。且已经证明,RNNLM 学习的单词表示在捕捉这些规律方面做得特别好。同时提出了一个用于测量句法性能的新数据集,并实现了近 40% 的正确率。。