Abstract & Introduction & Related Work
- 研究任务
不连续NER - 已有方法和相关工作
- 基于组合的模型首先检测所有的重叠span,然后学习用单独的分类器来组合这些片段
- 基于过渡的模型通过一连串的移位-还原动作对不连续的span进行增量标记
- 面临挑战
- 现有的方法将其分为几个连续的阶段,在推理阶段模型输出依赖于前面的阶段,将会累计偏差
- exposure bias
- 创新思路
将不连续NER转化为寻找图中最大团的非参数化过程,避免了受到暴露偏差的问题 - 实验结论
sota,五倍的推理速度
回顾一下最大团
最大团 = 补图最大独立集 = 总点数 ? 补图最大匹配数
Methodology
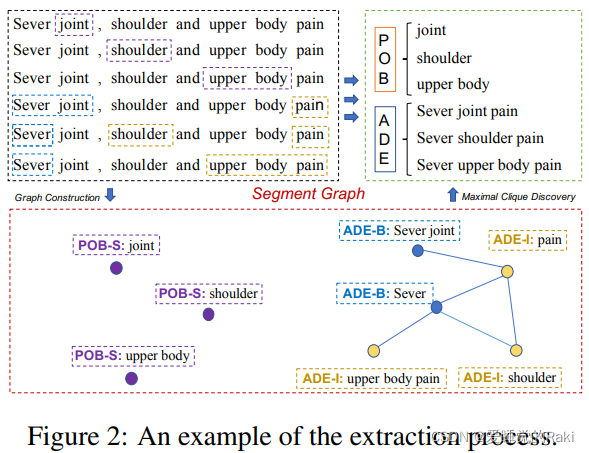
Grid Tagging Scheme
构建一个n*n的矩阵,来给每一对token之间一个标签,基于它们间的关系
注意,根据预先定义的标签集,一个标记对可能有多个标签
Segment Extraction
这个二维矩阵用来表示
s代表一个连续的实体,B和I代表beginning和inside

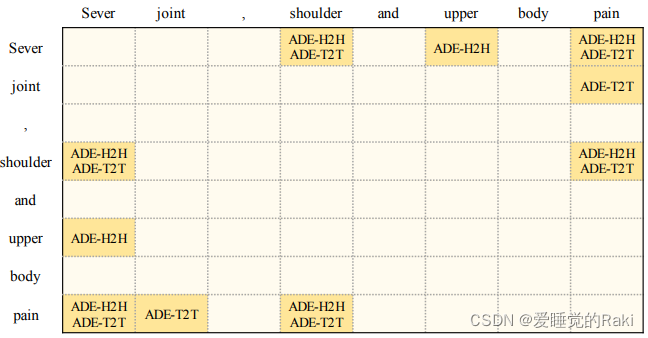
Edge Prediction
- 头到头(X-H2H)表示它定位在一个地方 ( t i , t j ) (t_i , t_j) (ti?,tj?),其中 t i t_i ti? 和 t j t_j tj? 分别是构成X类型的同一实体的两个片段的起始标记
- 尾对尾(X-T2T)与X-H2H相似,但重点在结束标记上
Sever shoulder pain
Decoding Workflow


Model Structure
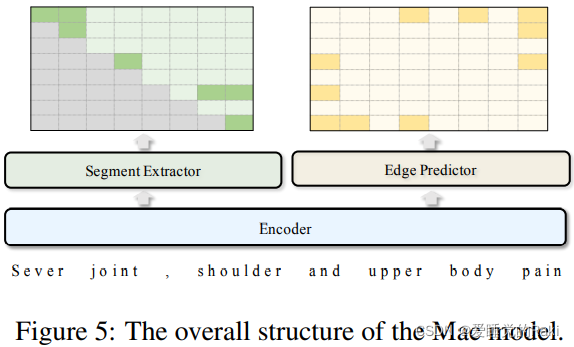
Token Representation
用一个线性层进行编码,但是我想问最初的
h
i
h_i
hi? 是从石头缝里面蹦出来的吗?我寻思你也没说啊?
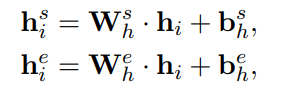
Segment Extractor
一对标记是一个片段的边界标记的概率可以表示为:
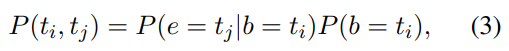
条件层归一化
一个条件向量被当做额外的上下文信息来生成增益参数,c和x分别是条件向量和输入向量
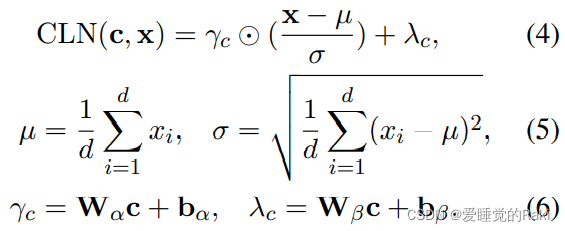
基于CLN机制,token对
(
t
i
,
t
j
)
(t_i , t_j)
(ti?,tj?) 作为一个片段的边界的表示可以定义为:
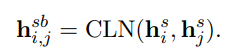
学习更好的片段表示
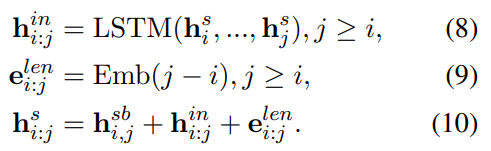
Edge Predictor
边缘预测与片段提取类似,因为它们都需要学习每个标记对的表示。关键的区别归纳为以下两个方面。
- 段落之间的距离通常是没有信息的,所以长度嵌入 e l e n i : j e_{len}^{i:j} eleni:j? 在边缘预测中是无价值的
- 对片段之间的标记进行编码可能会带来相关标记的噪声语义,并加重训练的负担,所以i:j中不需要
h
i
:
j
i
n
h_{i:j}^{in}
hi:jin?。在这样的考虑下,我们将每个用于边缘预测的标记对表示为
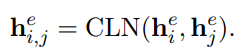
Training and Inference
全连接层,用来预测一对token的标签
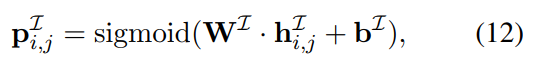
交叉熵损失
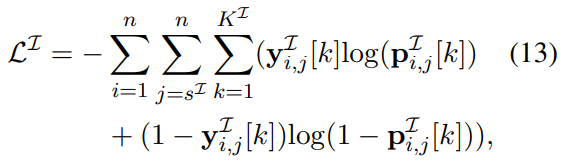
总损失
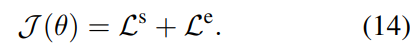
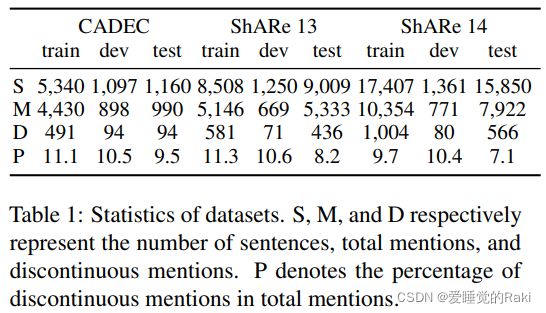
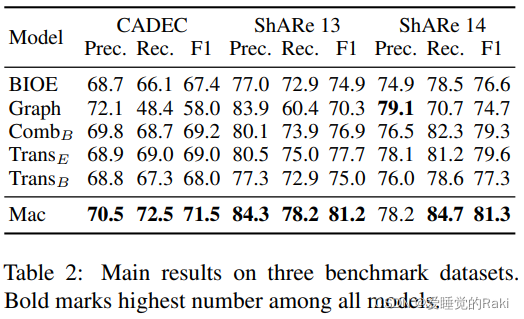
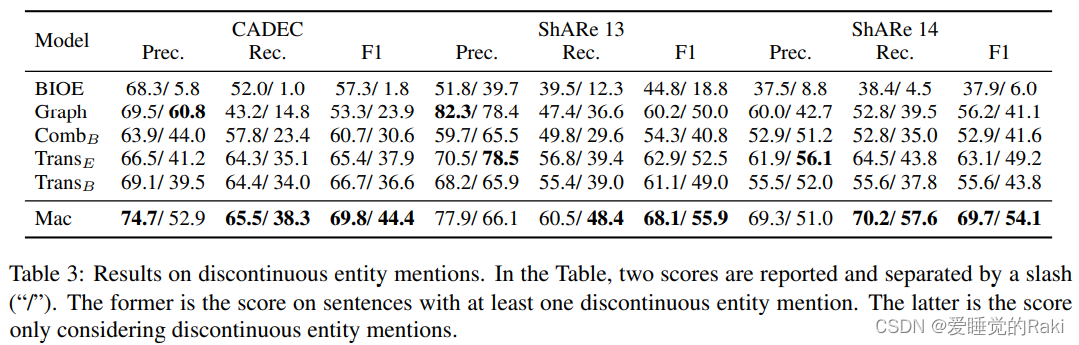
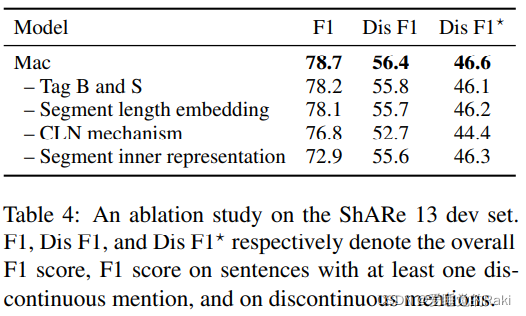
Evaluation
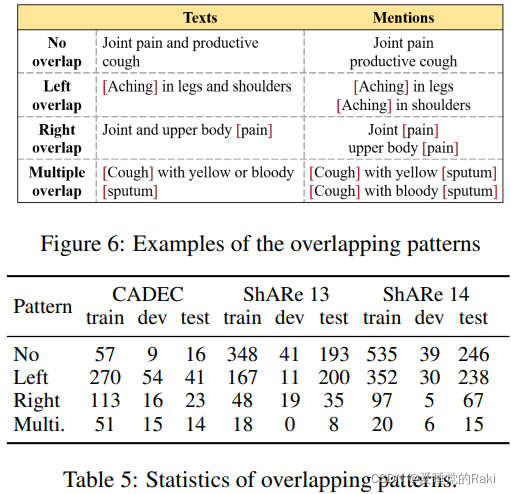
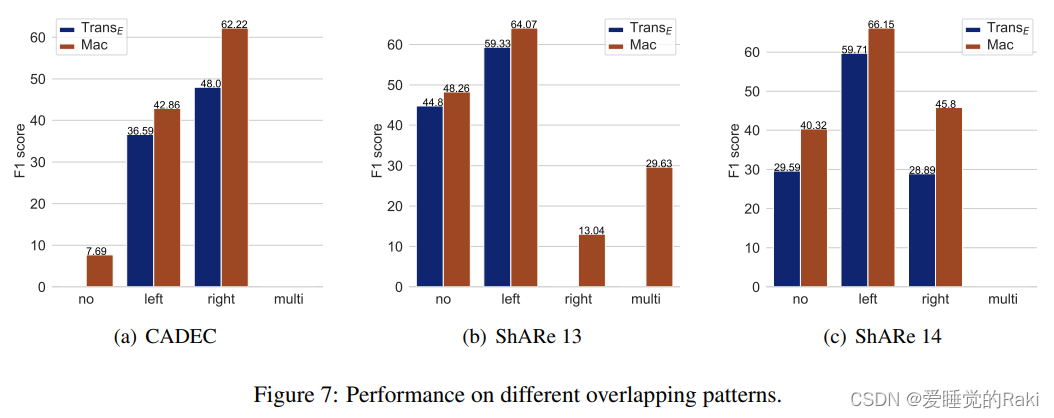
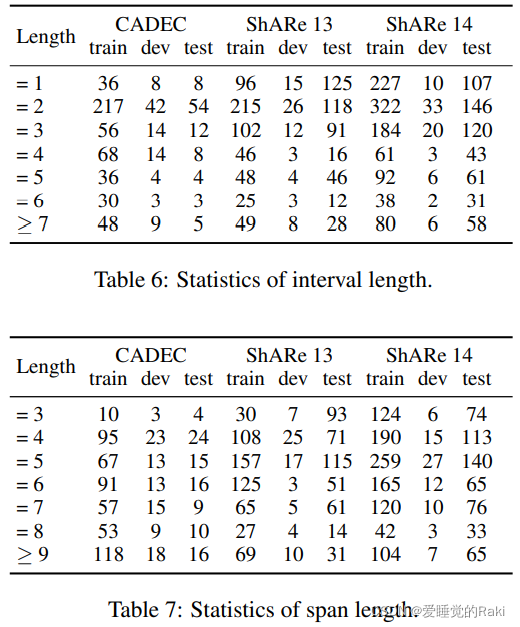
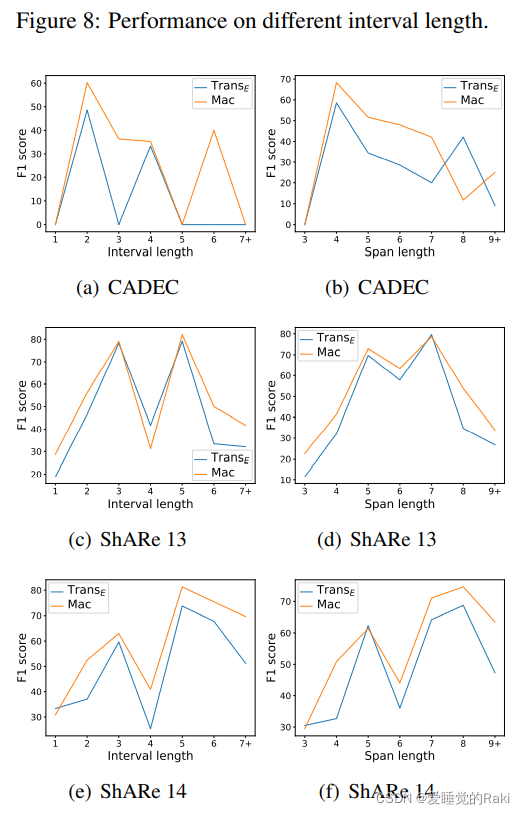
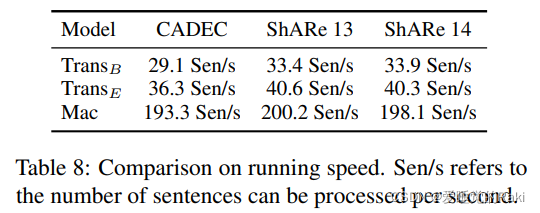
Conclusion
在本文中,我们将不连续的NER重新表述为发现片段图中最大团的任务,并提出了一个新颖的Mac架构。它将片段图的构建分解为两个独立的二维网格标记问题,并在一个阶段内共同解决,解决了以往研究中的暴露偏差问题。在三个基准数据集上进行的广泛实验表明,Mac在F1中比以前的SOTA方法高出3.5个百分点,同时速度快5倍。进一步的分析表明,我们的模型有能力识别不连续的和重叠的实体提及。在未来,我们希望在其他信息提取任务中探索类似的表述,如事件提取和嵌套的NER
Remark
novelty有的,但是实现起来感觉有点不优美,实验做的非常足,还行吧