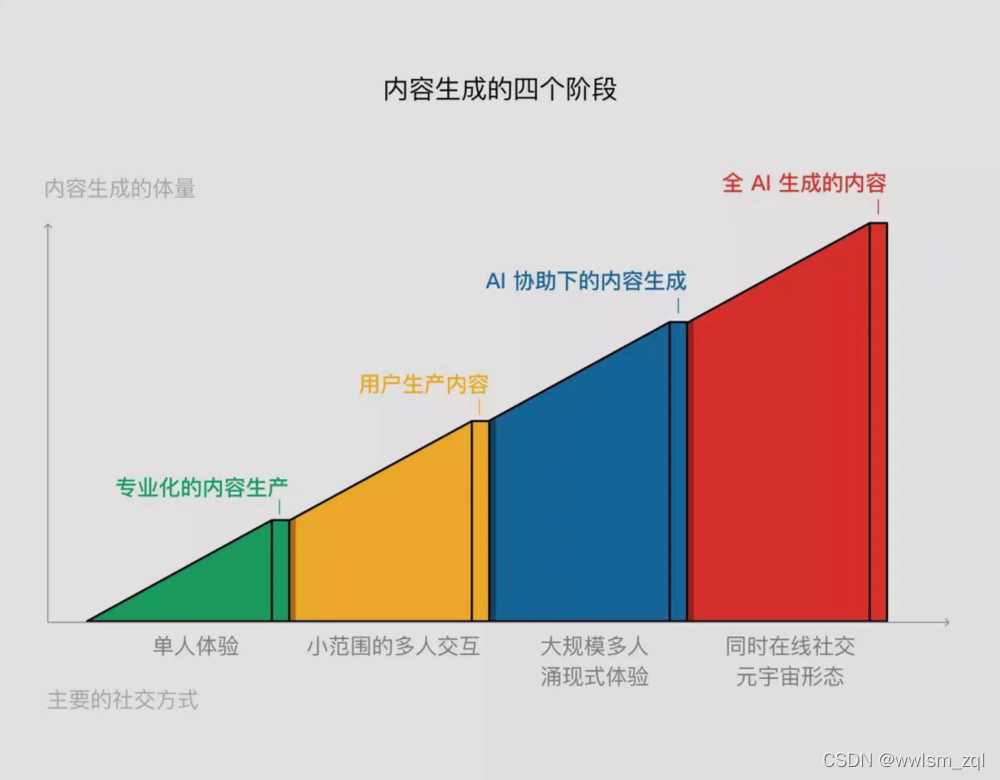
内容,已经成了我们生活中必不可少的成分,无论是小红书、抖音、爱奇艺等文本、短视频以及视频内容还是腾讯、网易的游戏内容。每天有不可计数的内容被生成,同时又被无数人的消费着,通过手机、电脑沉浸在一个个的 APP 中,用自己的时间、精力、金钱为各种内容买单。
内容的生产方式也是随着时代的变化在变化的,从最早的 PGC(Professionally Generated Content)到后来的 UGC(User Generated Content),以及现在逐渐火热的 AIGC(AI Generate Content),面对庞大的内容消费市场,我们如何通过 AIGC 的方式来进行内容生产呢?本文以文本内容为例,提供了一种思路,详情见正文,其他方法见后续文章。
keywords: AIGC、摘要生成、文本生成、NLP、内容创作、AI创作
一、概述
一篇文本内容,一般有标题+正文的方式,正文通常是图文或者纯文本的形式。本文以纯文本为例。
生成思路:通过已有的原文数据,通过一定的手段,生成新的标题和正文数据
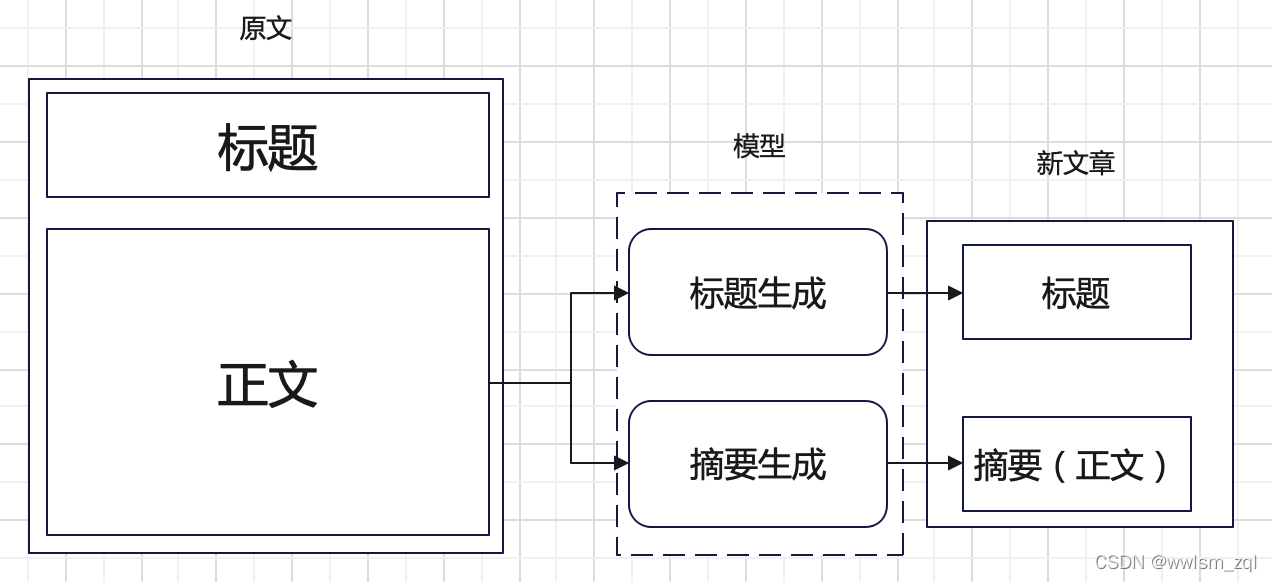
巧妇难为无米之炊,创业还需要启动资金呢,我们至少有一批种子数据,而新内容是在已有的原文基础上进行的生成,
新内容的标题和正文,可以通过 NLP 中文本生成的方法获取,即标题生成和摘要生成。
摘要生成,一般包括抽取式和生成式,抽取式是从原文中抽取关键的句子组成摘要;生成式则是在理解原文的基础上进行语言的重新组织表达。很明显后者的难度要远大于前者。
二、过程
从上面我们知道,新内容我们拆分为了标题和正文的分别生成,那么,新内容的创作问题转换为了标题生成和正文生成的 NLP 生成问题了,
而这两个问题在 NLP 领域已经进行了深刻的研究并取得了不错的成果。
标题生成
标题生成可以看做是摘要生成的一个特例,相比摘要需要一定的长度和前后连贯性的要求,标题则需要新颖性、简短性的要求。两者的模型一般来说结构相同,训练数据格式也经常相同。
目前标题生成开源模型有:
- tensorflow GPT2: https://github.com/liucongg/GPT2-NewsTitle
- paddle Bert: https://aistudio.baidu.com/aistudio/projectdetail/3463042
- paddle GPT2: https://aistudio.baidu.com/aistudio/projectdetail/2340166
基于公开的开源模型能够在通用数据集上得到一个较好的效果,但如果迁移到自己的领域,可能效果就不尽如人意,需要通过一定的微调实现领域知识的学习。
正文生成
新内容的正文,或者说摘要也是通过 NLP 生成模型来实现,但目前公开的模型,在中文数据集上,实验效果和实际效果存在一定的差异,或者说是数据集有效性,
目前效果比较好的几个摘要生成开源模型如下:
- 科学空间: https://kexue.fm/archives/8046/comment-page-1
- GPT2: https://zhuanlan.zhihu.com/p/113869509
- GPT2: https://github.com/qingkongzhiqian/GPT2-Summary
- bert: https://github.com/dmmiller612/bert-extractive-summarizer
- bert: https://geek.digiasset.org/pages/nlp/nlpinfo/bert-text-summarizer-chinese/
- tianma: https://github.com/google-research/pegasus
- https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/106893673
利用开源模型,或者进行微调后的开源模型,将原文转换为一定长度和描述的摘要,生成的摘要就可以当做新内容的正文啦。
三、分析
从上面的过程中,我们可以看出,生成的结果是两个模型结果的组合,并且两个模型都是压缩型的模型,将长文本转换为短文本,那么,相应的
- 新内容的篇幅一定小于原文的长度,因为无论是标题还是摘要都是从原文中进行的概括总描述
- 理论上,新内容的质量不高于原文,上限是原文的质量等级。
在做 NLP 生成模型中,标注数据的缺失是普遍遇到的问题。这需要一定的人力。
好啦,AIGC 方式进行内容生成的第一个方法就是这样啦,其他的方法,详见后续文章啦~
元宵节快乐~