2021��������ѧϰ(4):����������CNN
1 ǰ��
ͼƬһ���õ�����ά������,Ҳ����:

��ά���ǡ�����*�߶�*ͨ����,�ڳ�������ÿһ�����ȡ����ȶ�������һ������,���������������������(RGB������ͨ����),Ϊ���ܹ������������,�Ͱ�����ά��ֱ��һ��tensor:
2 �۲�1
��ͼƬ���Կ���,��������������ʵ�Ƿdz����,����������Ҫ����ô,��������ν���ͼƬʶ���?
��������ʶ��һ����,��ͨ�������ض�����(�������졢צ��)ʶ���,���,���ǿ��Զ�������Ϣ���м�,������ҪͼƬ���е���Ϣ,����ֻ��Ҫ�ض��IJ��֡�
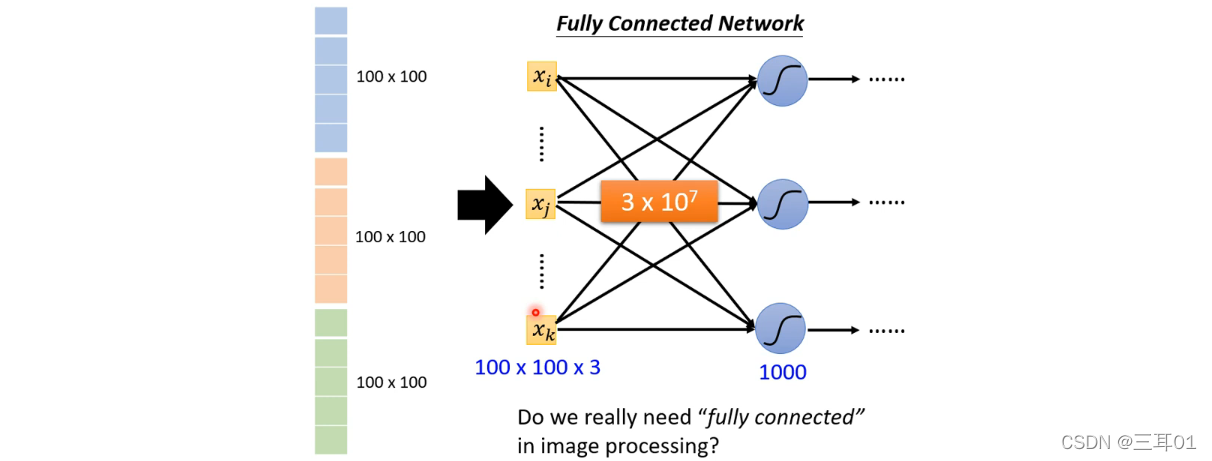
2.1 ����1:Receptive field(����Ұ)
���ǿ����Լ��趨Receptive field,ÿһ����Ԫ��ֻ�����Լ���Receptive field���淢������:
 ��Ԫ����ι����Լ���Receptive field���淢����������?
��Ԫ����ι����Լ���Receptive field���淢����������?
����ͼ����3*3*3������,�������������ֱ,��Ϊ27ά������,��ΪNeuron������,Neuron������������ÿ��ά��һ��weight,������27��weight,�ټ���bias�õ���Ԫ�����,������������һ����Ԫ��Ϊ���롣
- ��Ԫ�����ص�
- ͬһ������Ұ�����в�ͬ����Ԫ
- Receptive Field �����д���С
- Receptive Field ����ֻ����ijЩ Channel(����ֻ���Ǻ�ɫͨ��R)
- Receptive Field Ҳ�����dz����ε�
2.2 ���� Receptive Field �İ��ŷ�ʽ(Typical Setting)
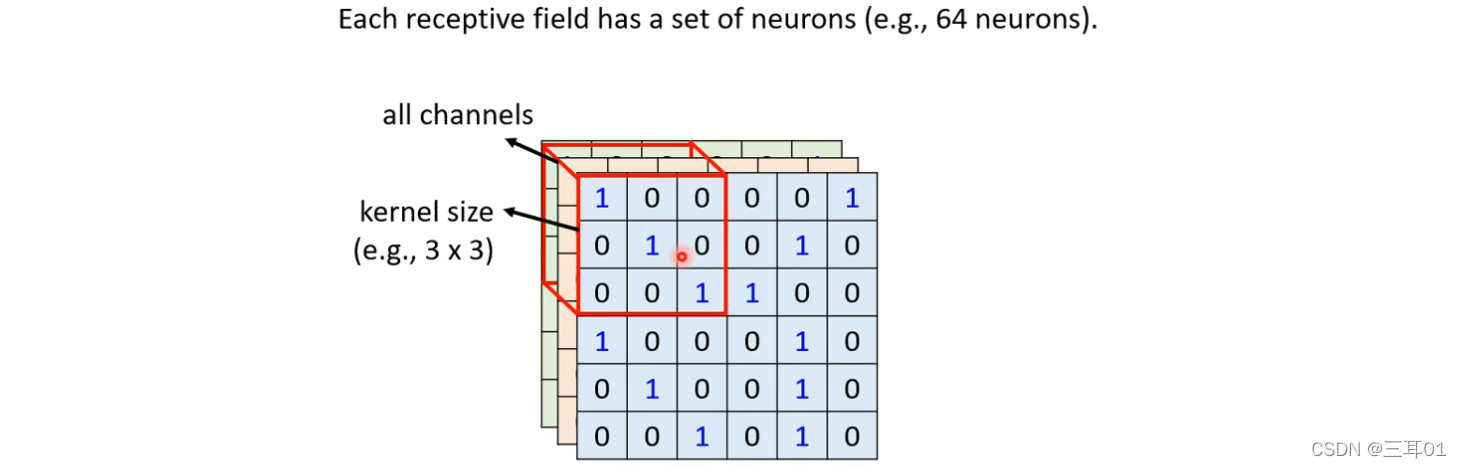
- ������ȫ���� Channel
��ʱ,��������һ�� Receptive Field ��ʱ��,ֻҪ�����ĸ߸����ͺ���,�Ͳ��ý��������,�������һ���ǿ���ȫ���� Channel,������߸������������� Kernel Size - ������ Receptive Field �趨��ʽ,���� Kernel Size 3��3
- һ��ͬһ�� Receptive Field,����ֻ��һ�� Neuron ȥ������,��������һ�顢һ�� Neuron ȥ�ر���,����˵ 64 �������� 128 �� Neuron ȥ�ر�һ�� Receptive Field �ķ�Χ
2.2.1 ����stride��padding
������ͬ Receptive Field ֮��Ĺ�ϵ,����ô����?
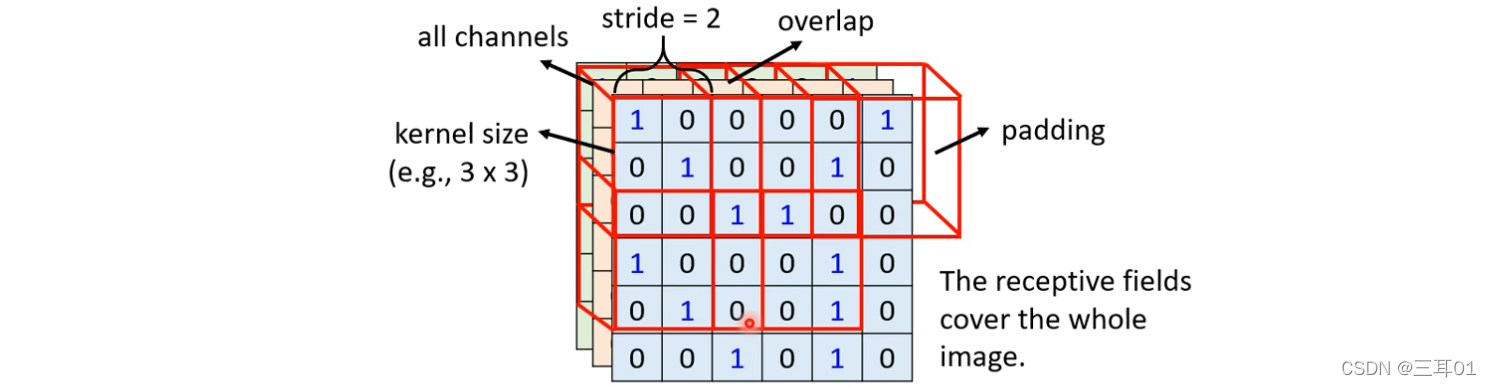
- �������Ͻǵ���� Receptive Field ������һ��,Ȼ����������һ�� Receptive Field,����ƶ��������� Stride;
- ��� Stride ������������̫��,������ 1 �� 2 �Ϳ�����
������������ͳ�����Ӱ��ķ�Χ:
- Padding ���Dz� 0
- Ҳ�б�IJ�ֵ�ķ���,Padding ���Dz�ֵ����˼,������ͼƬ�e������ Value ��ƽ��,���߰ѱ߱ߵ���Щ�����ó�����������
3 �۲�2
ͬ���� Pattern ���ܻ������ͼƬ�IJ�ͬ��������,����������ܳ�����ͼƬ�����Ͻ�,Ҳ���ܳ�����ͼƬ���м�,��Ȼ���ǵ���״����һ����,��������,�������ǿ��ܳ�����ͼƬ�IJ�ͬ��λ�á�
��ʵ�����������������,��û�й�ϵ,����һ������ijһ�� Receptive Field �ķ�Χ��,�Ǹ� Receptive Field,һ����һ�� Neuron ���չ�,����������һ�� Neuron�����������,�����첻�ܳ�����ͼƬ������,���ᱻ��������
��������,��Щ�������� Neuron,��������������ʵ��һ����,ֻ�������ر��ķ�Χ�Dz�һ���ĸ���Ұ,���������Ҫÿһ���ر���Χ,��ȥ��һ���������� Neuron ��?
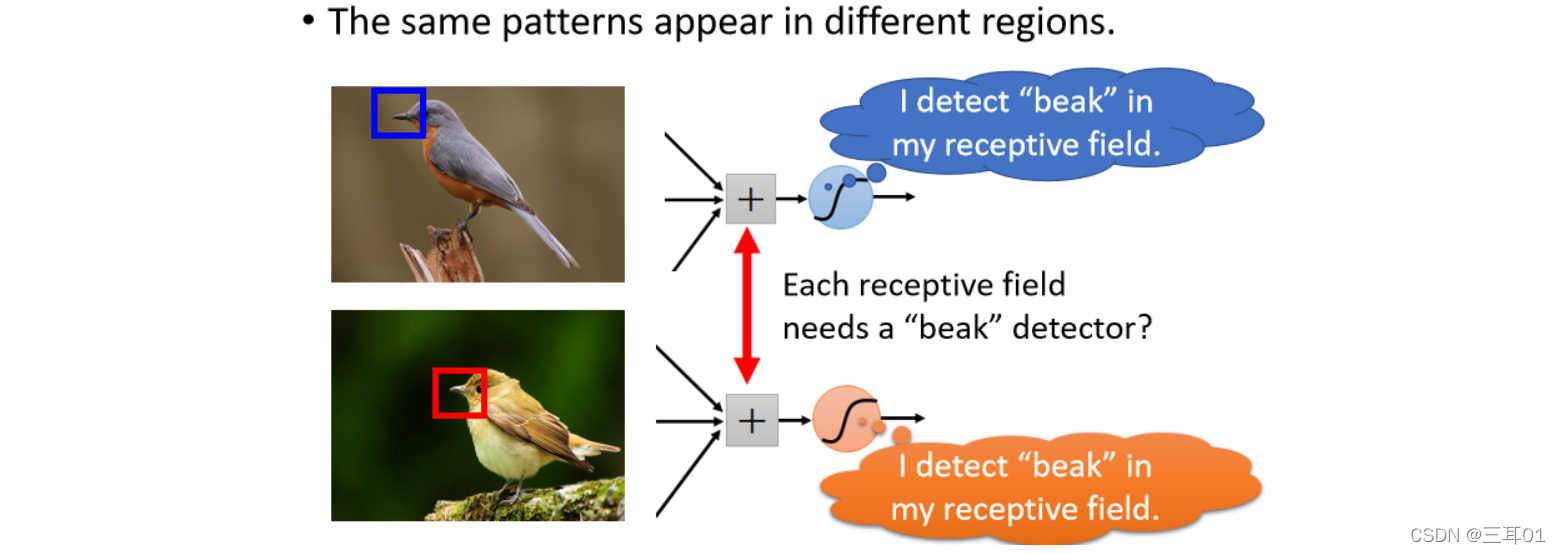
�����ͬ���ر���Χ,��Ҫ��һ���������� Neuron,����IJ���������̫������?
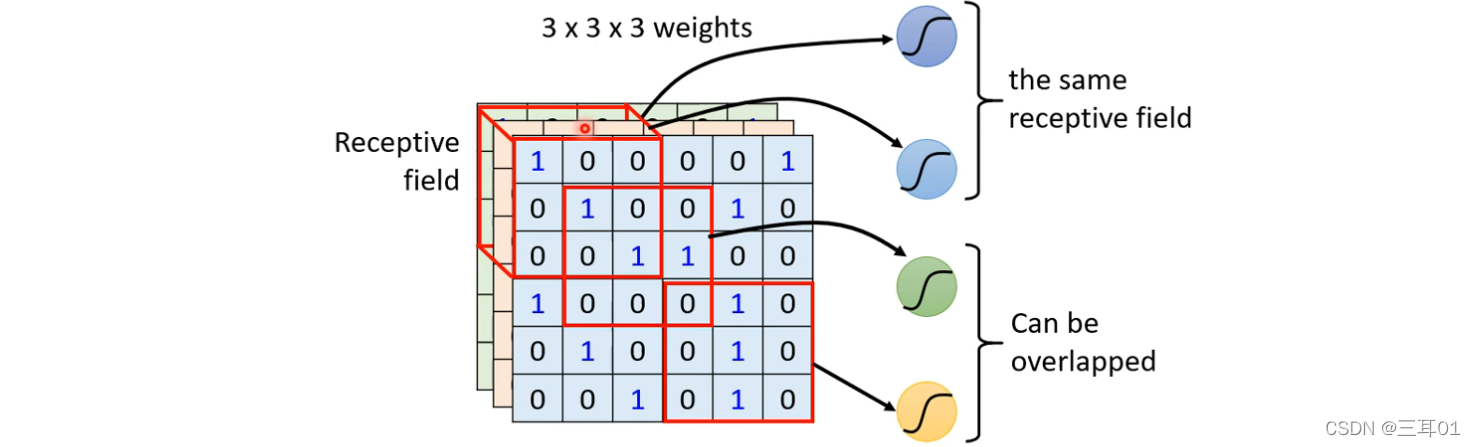
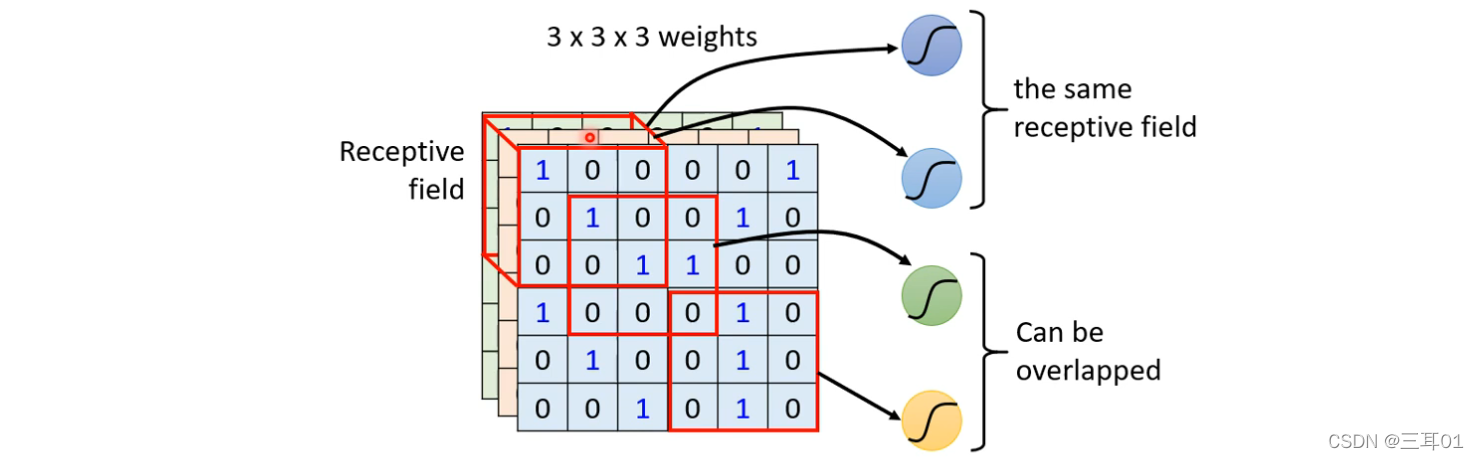
3.1 ����2:��������
�ò�ͬ Receptive Field �� Neuron��������,Ҳ������ Parameter SharingȨֵ������
��ν������������,������ Neuron ���ǵ� weights��ȫ��һ����:
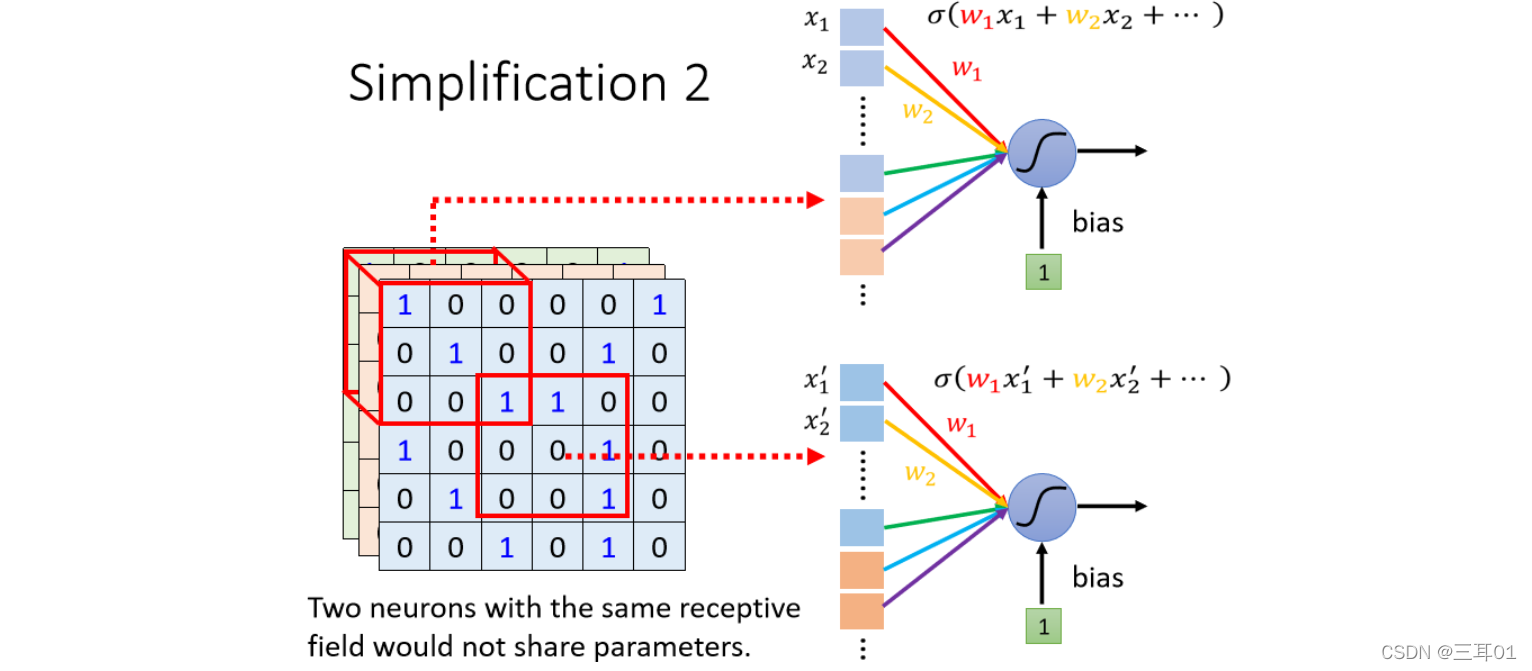

3.2 Typical Setting
�ղ��Ѿ�˵��,ÿһ�� Receptive Field,������һ�� Neuron �ڸ����ر�,����˵ 64 �� Neuron,�������Ͻ���� Receptive Field�� 64 �� Neuron,���½���� Receptive Field Ҳ�� 64 �� Neuron��
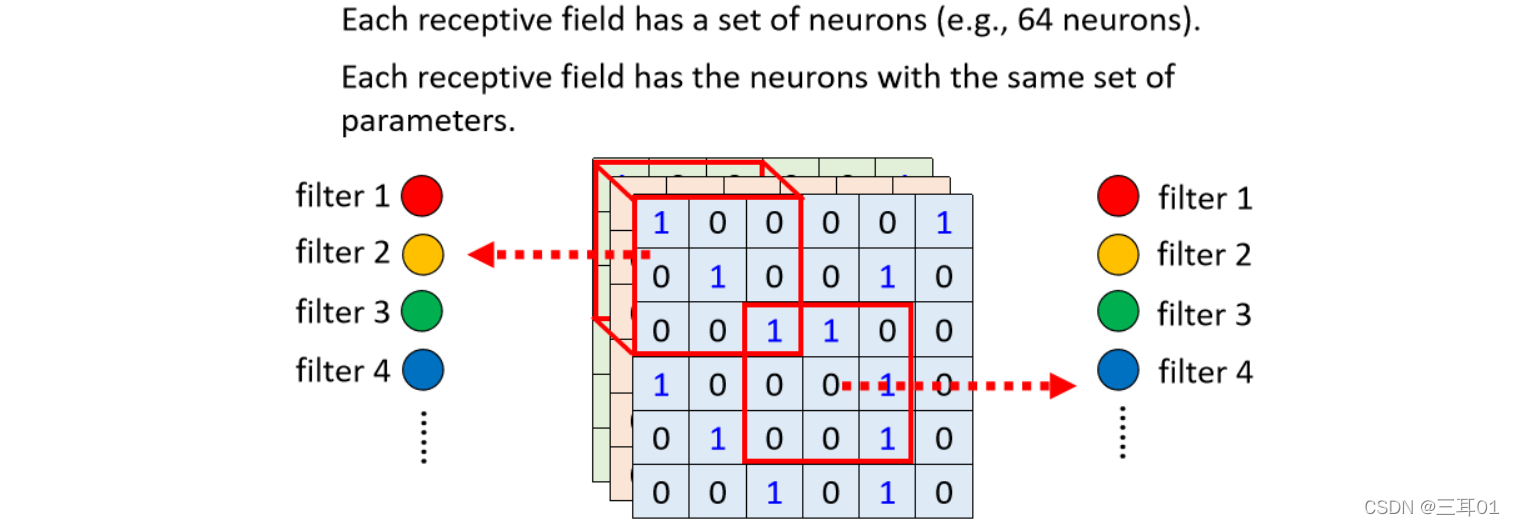
���������һ�����ɫ,�ʹ���˵������ Neuron,����һ���IJ���,������ʵÿһ�� Receptive Field��ֻ��һ��������ѡ�
��Щ������һ������,���� Filter,������������ɫ Neuron,���ǹ���ͬһ�����,��������ͽ� Filter1,��ɫ������ Neuron ���ǹ�ͬһ�����,��������ͽ� Filter2,�Դ�����,��64�� Filter��
4 �ܽ�:CNN�ĺô�
- Fully Connected �� Network �ǵ�������,�����Ծ���������ͼƬ,����ֻ��һ����Χ,�������ֻ�뿴һ����Χ,�Ѻܶ� Weight ��� 0���ɡ�
- ����ʱ����Ҫ������ͼƬ,Ҳ��ֻҪ��ͼƬ��һС���־Ϳ���������Ҫ�� Pattern,������������ Receptive Field �ĸ���,��ʱ���� Network �ĵ����DZ�С�ġ�
- ������Ȩֵ�����ָ���һ�������� Network �ĵ��ԡ������� Learning ��ʱ��,�����Ծ��������� Network �IJ�����ʲô,ÿһ�� Neuron �IJ���������ͬҲ���Բ�ͬ,���Ǽ�����������Ժ�,����ζ��ijһЩ Neuron����Ҫһģһ��,�������ָ������˶� Neuron �����ơ�
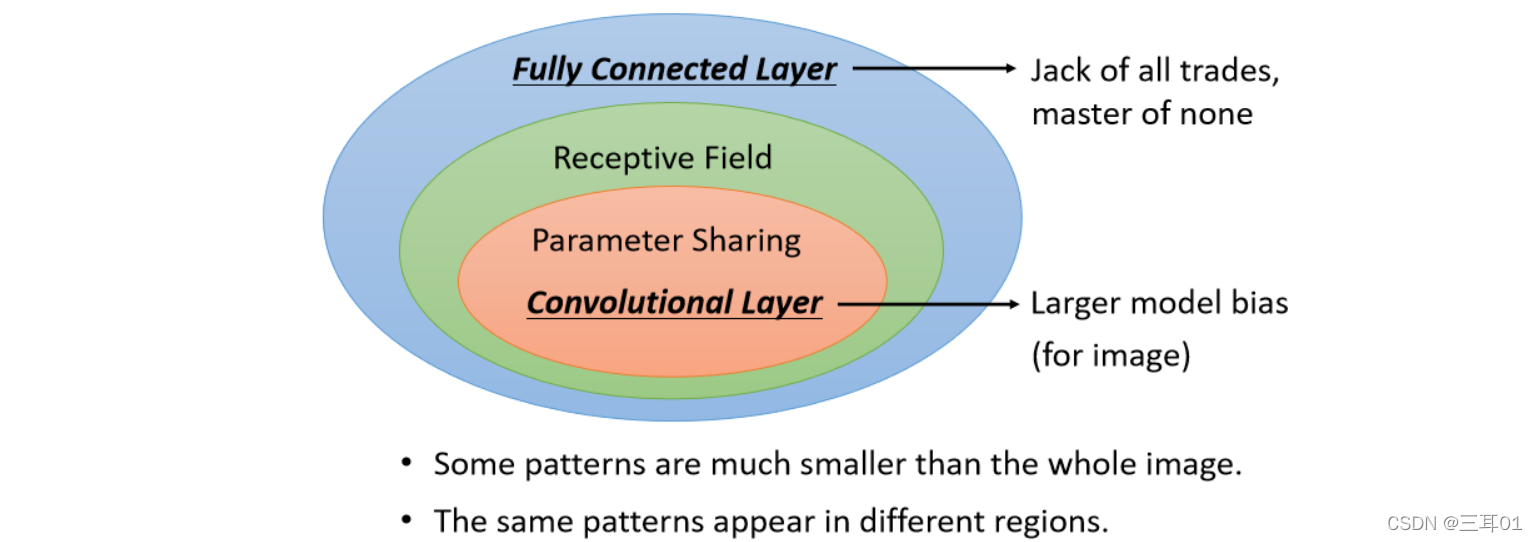
Receptive Field ���� Parameter Sharing,���� Convolutional Layer��
���õ� Convolutional Layer �� Network,�ͽ� Convolutional Neural Network,���� CNN��
����һ���˲���ȥһ����������
CNN �� Model �� Bias �Ƚϴ�,�ⲻһ����ʲô����:
- ��Ϊ�� Model Bias С,Model ������Ժܸߵ�ʱ��,���Ƚ��������,Fully Connected Layer��������ʽ����������,�������и�ʽ�����ı仯,����������û�а취��,�κ��ض�������������
- �� Convolutional Layer ��ר��ΪӰ����Ƶ�,�ղŽ��� Receptive Field ��������,��Щ�۲춼��ΪӰ����Ƶ�,��������Ӱ������Ȼ�������ú�,��Ȼ���� Model Bias �ܴ�,�������Ӱ���ϲ�������,�������������Ӱ��֮�������,���Ҫ��ϸ����,��Щ������û�����ǸղŽ���Ӱ���õ�����
5 �ڶ���CNN�Ľ���
���˲��������н���:Convolutional �� Layer �����кܶ�� Filter
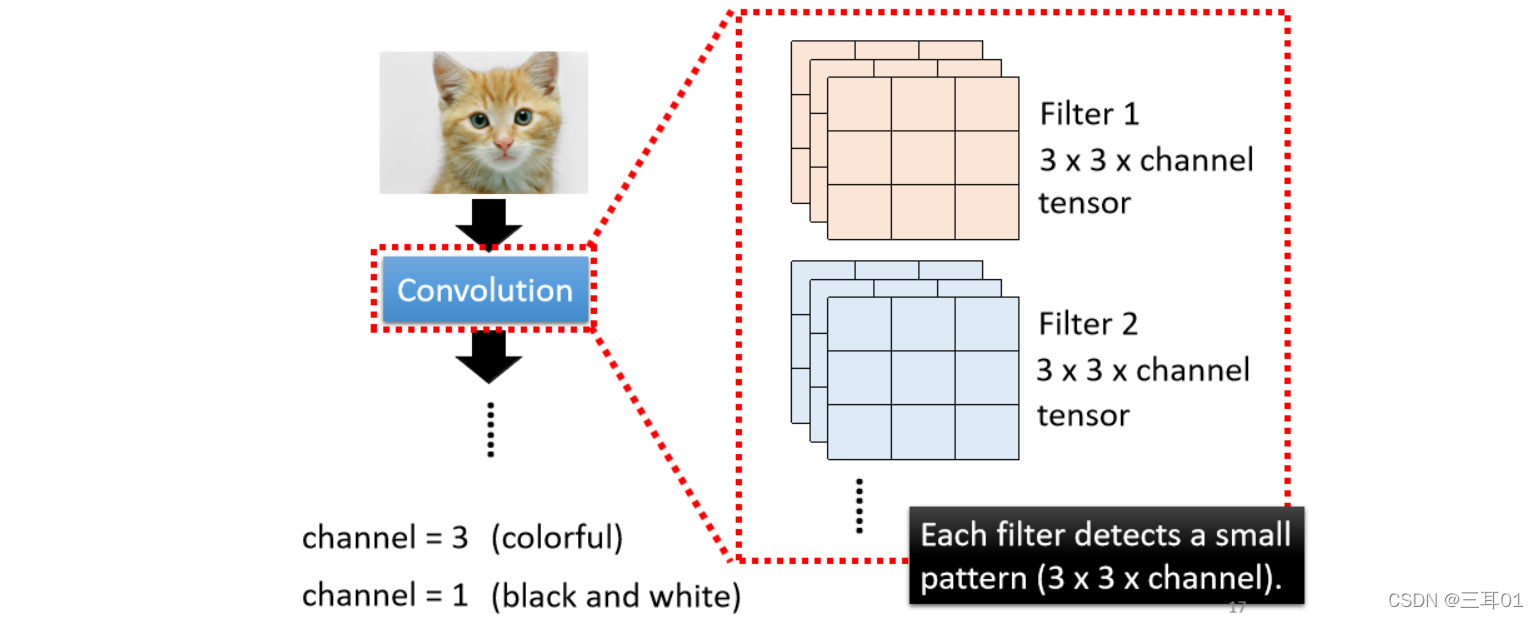
��Щ Filter �Ĵ�С��, 3 �� 3 �� Channel �� Size������Dz�ɫͼƬ�Ļ�,�Ǿ��� RGB ���� Channel;����Ǻڰ�ͼƬ�Ļ�,���� Channel ��Ϊ 1��
һ�� Convolutional �� Layer ������һ�ŵ� Filter,ÿһ�� Filter ����һ�� 3 �� 3 �� Channel ��ô��� Tensor��
ÿһ�� Filter �����þ���ץȡͼƬ����ijһ�� Pattern(Pattern�Ĵ�СҪ�� 3 �� 3 �� Channel�ķ�Χ��,���ܹ�����Щ Filter ץ����)
����Щ Filter,��ôȥͼƬ����ץ Pattern ��?
5.1 ����˵��
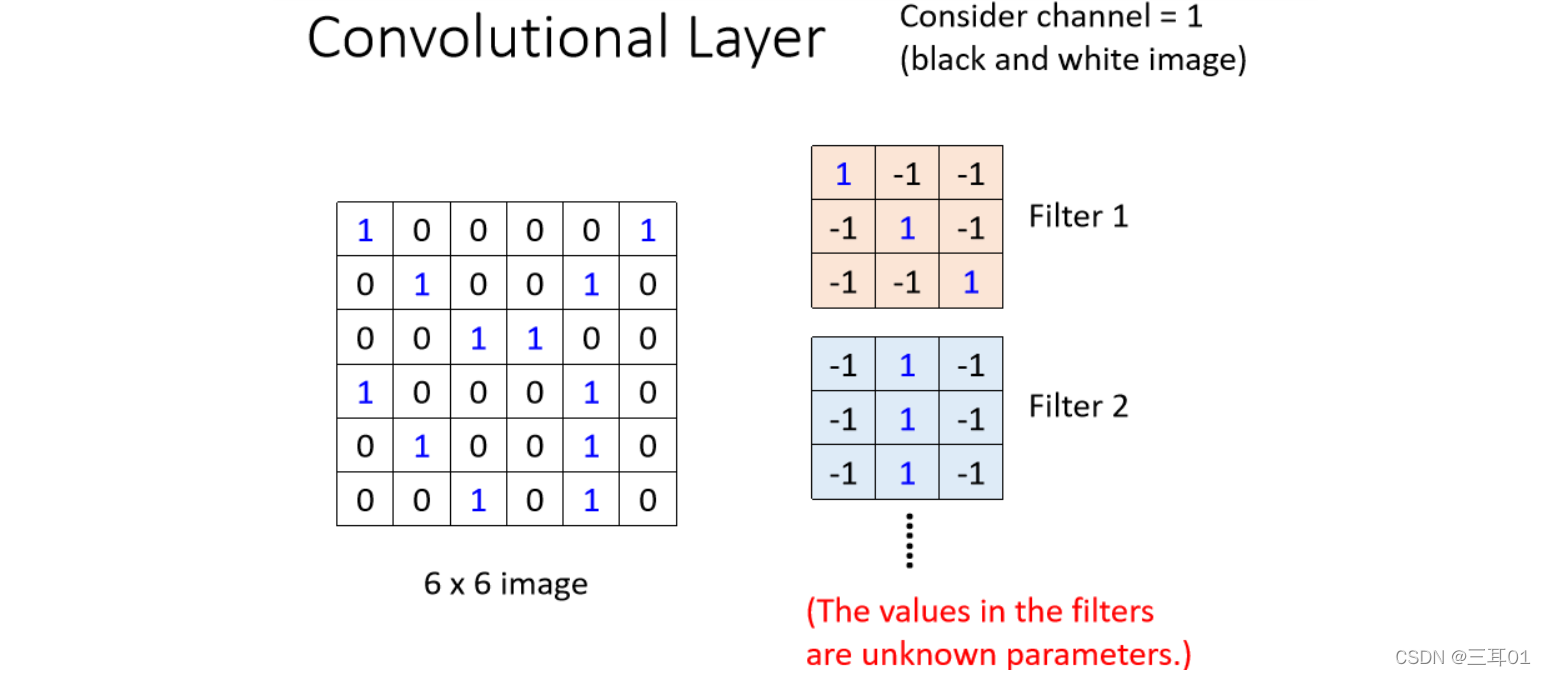
- ����channel=1,�Ǻڰ�ͼƬ��
- ������Щ Filter �IJ�������֪��,Filter ����һ��һ���� Tensor,��� Tensor �������ֵ,���Ƕ��Ѿ�֪����
(ʵ������Щ Tensor �������ֵ���� Model ����� Parameter,��Щ Filter �������ֵ��ʵ��δ֪��,����Ҫ��gradient decentȥ�ҳ�����,�������Ǽ�����֪)
����Filter1:
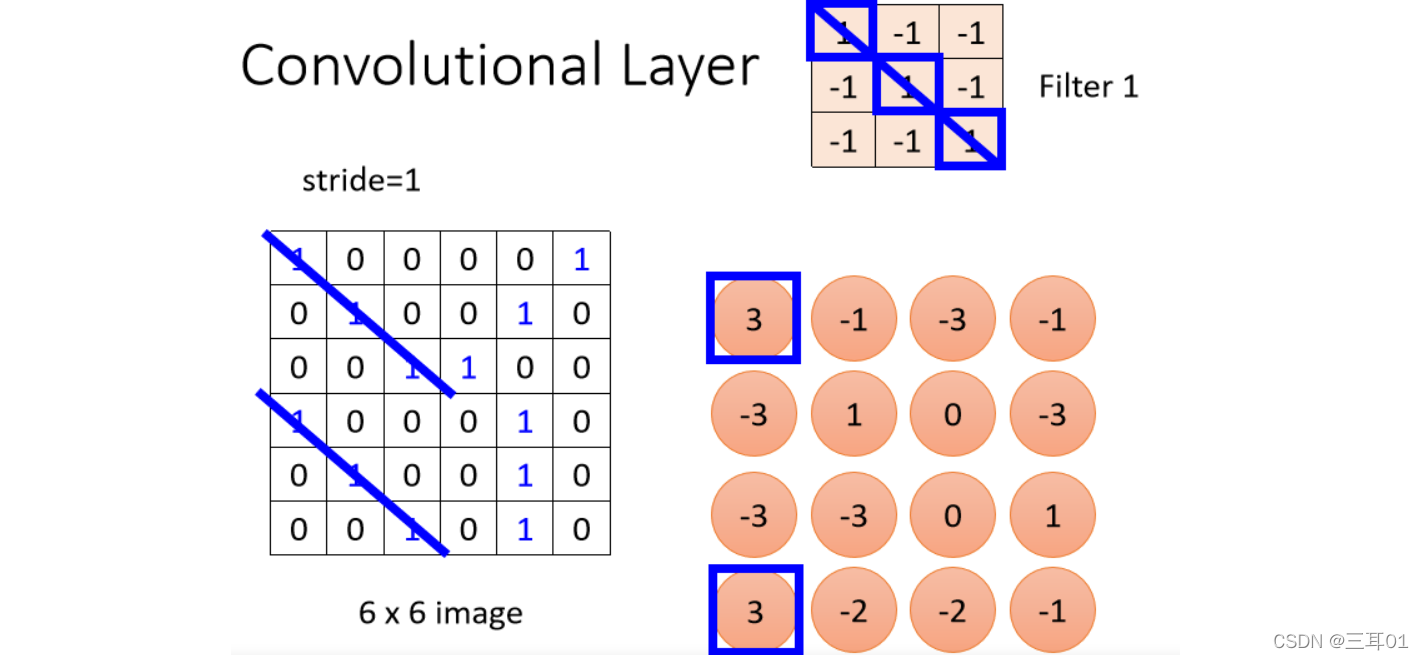
��� Filter ����,���Խ��ߵĵط�����1,���������� Image ����Ҳ���������� 1 ��ʱ��,������ֵ�����
���Իᷢ�����Ͻǡ����½ǵ�ֵ���,�����������ͼƬ���Ͻǡ����½��г���������� 1 ����һ��� Pattern��
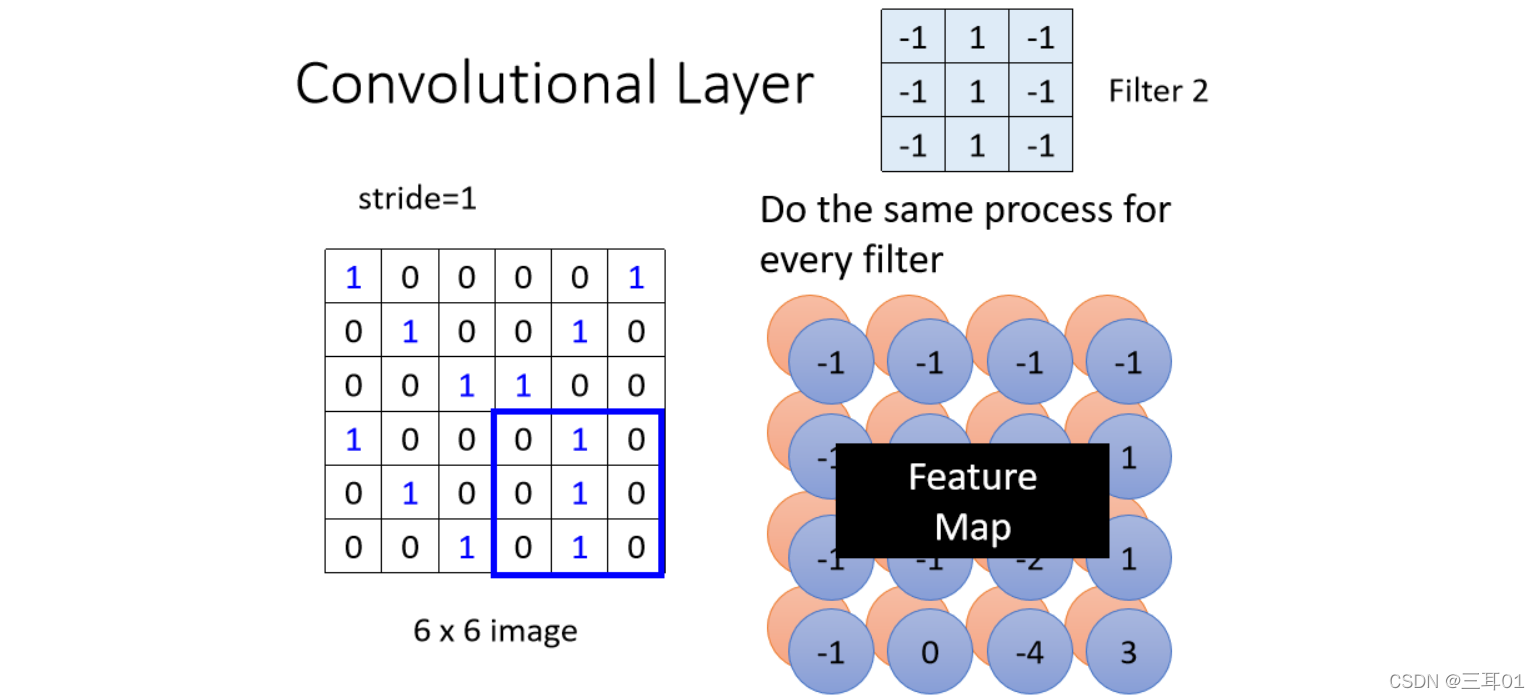
����ÿһ�� Filter,��������Dz���һȺ����,��������� 64 �� Filter,���Ǿ͵õ� 64 Ⱥ��������,��һȺ���ֽ��� Feature Map��
���Ե����ǰ�һ��ͼƬ,ͨ��һ�� Convolutional Layer,������һ�� Filter ��ʱ��,���Dz���������һ�� Feature Map��
5.2 ���ؾ�����
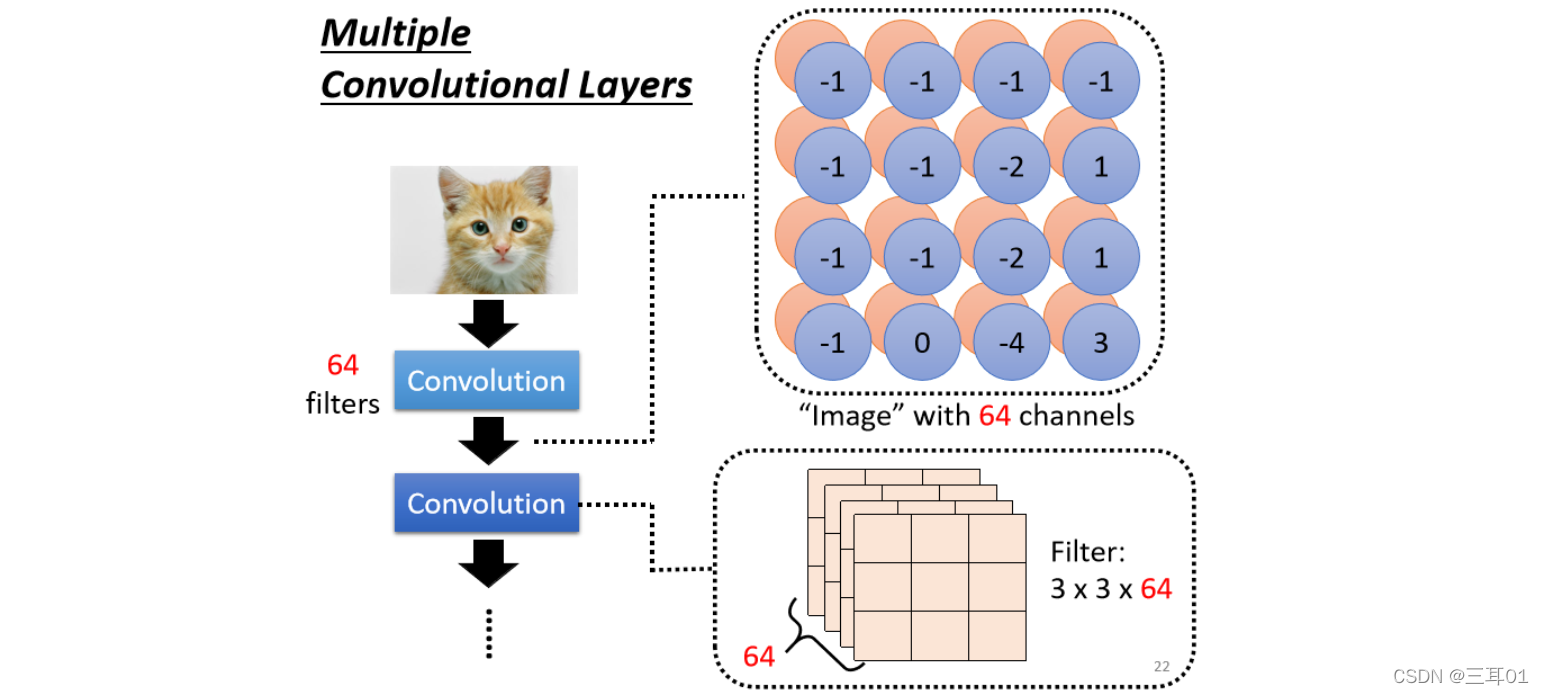
�Ǽ������ Convolutional Layer�e��,���� 64 �� Filter,�Ͳ�����64�� Feature Map,ÿһ��Feature Map�Ĵ�С����������e���� 4 �� 4,��� Feature Map����Կ���������һ���µ�ͼƬ��
ֻ�����ͼƬ�� Channel ���� 64 ��,�����Ⲣ���� RGB ԭͼ�� Channel��������ÿһ�� Channel ��Ӧһ�� Filter,ԭͼ������ Channel,ͨ��һ�� Convolution,�����һ���µ�ͼƬ,�� 64 �� Channel��
��� Convolutional Layer �ǿ��Ե��ܶ���,�ղ��ǵ��˵�һ�㡣������ӵڶ���,�ڶ���� Convolution �e��,Ҳ��һ�ѵ� Filter,��ÿһ�� Filter ��,���Ĵ�С�������Ҳ�� 3 �� 3,�����ĸ߶ȱ�����Ϊ 64(����߶Ⱦ�����Ҫ������Ӱ��� Channel)��
ֻҪnetwork����,�Ϳ�����쵽�㹻��С�ķ�Χ:
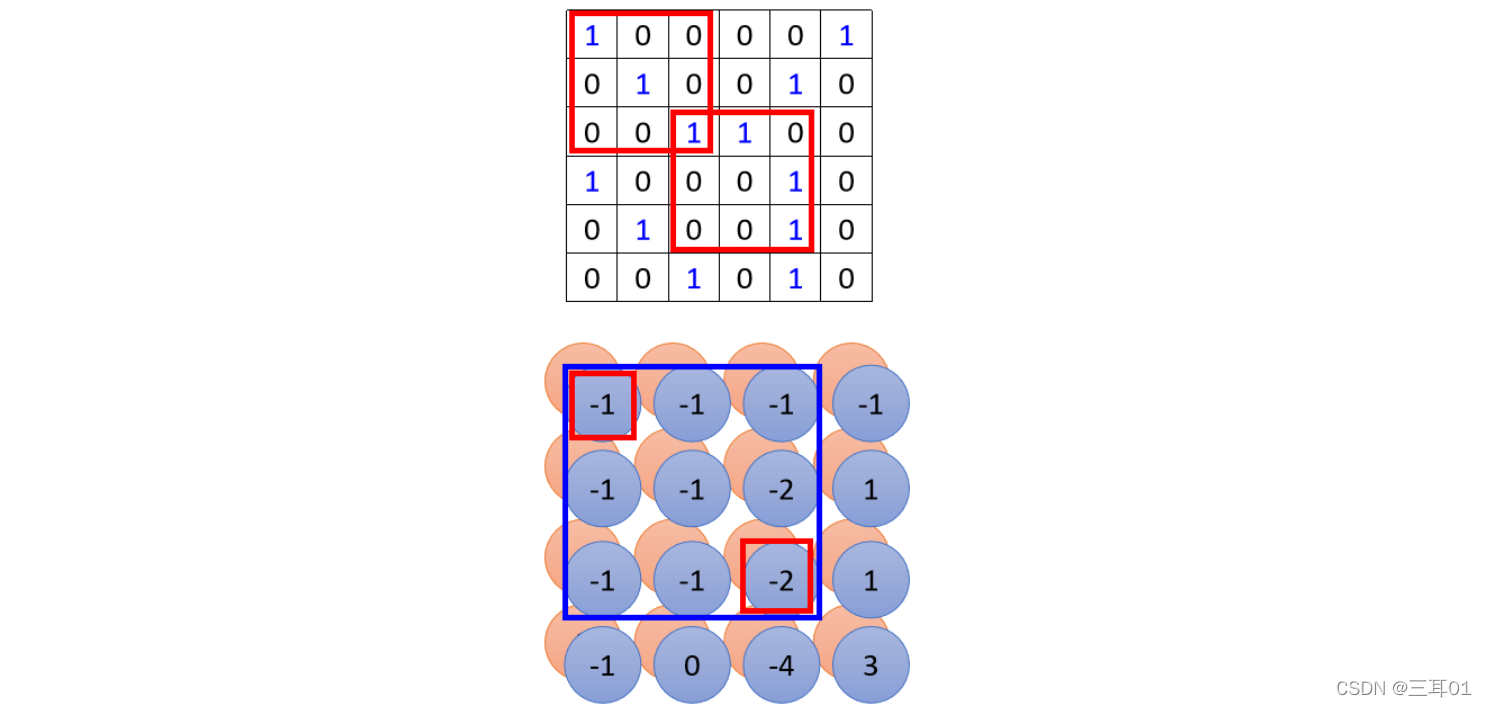
��ͼ��,�ڶ����3��3��Filter��̽��ʱ,���ϽǺ����½ǵ�-1��-2�ֱ��Ӧ����ԭͼ������3 �� 3�ĺ�ɫ���ӡ�
���Ե����ǿ��ǵ�һ�� Convolutional Layer ����� Feature Map �� 3 �� 3 �ķ�Χ��ʱ��,������ԭ����Ӱ����,��ʵ�ǿ�����һ�� 5 �� 5 �ķ�Χ��
���� Network ����Խ��,ͬ���� 3 �� 3 �Ĵ�С�� Filter,�����ķ�Χ�ͻ�Խ��Խ��
���� Network ����,�Ͳ�������ⲻ���Ƚϴ�� Pattern��
5.3 �ܽ�
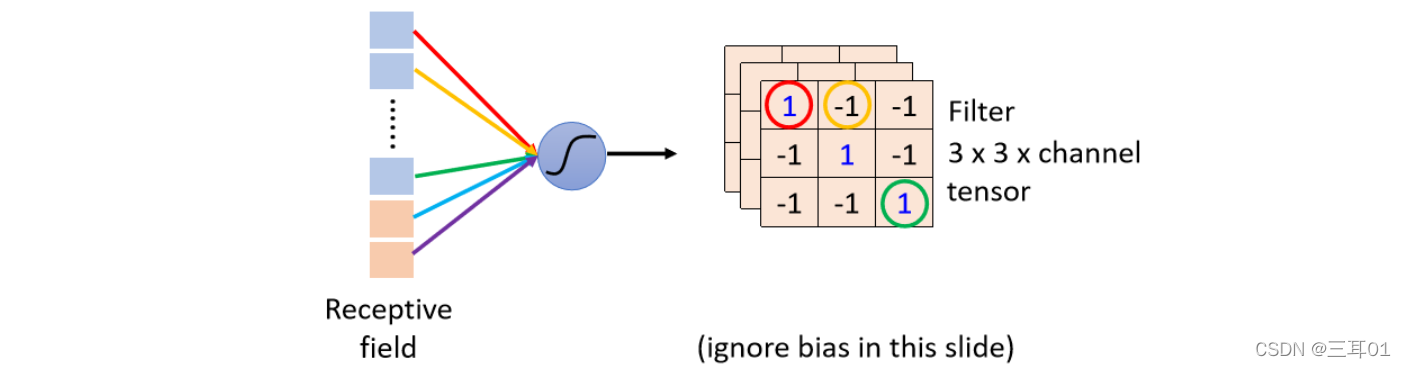
��һ���汾������Ԫ���õIJ���,���ǵڶ����汾�Ĺ�������� Filter,��ͼ����ɫ��Ȩ�ض�Ӧ��
�ڸղŵ�һ���汾�Ĺ�������,����˵��ͬ�� Neuron ���� Share Weight,Ȼ��ȥ�ر���ͬ�ķ�Χ,�� Share Weight �����,��ʵ�������ǰ� Filter ɨ��һ��ͼƬ:
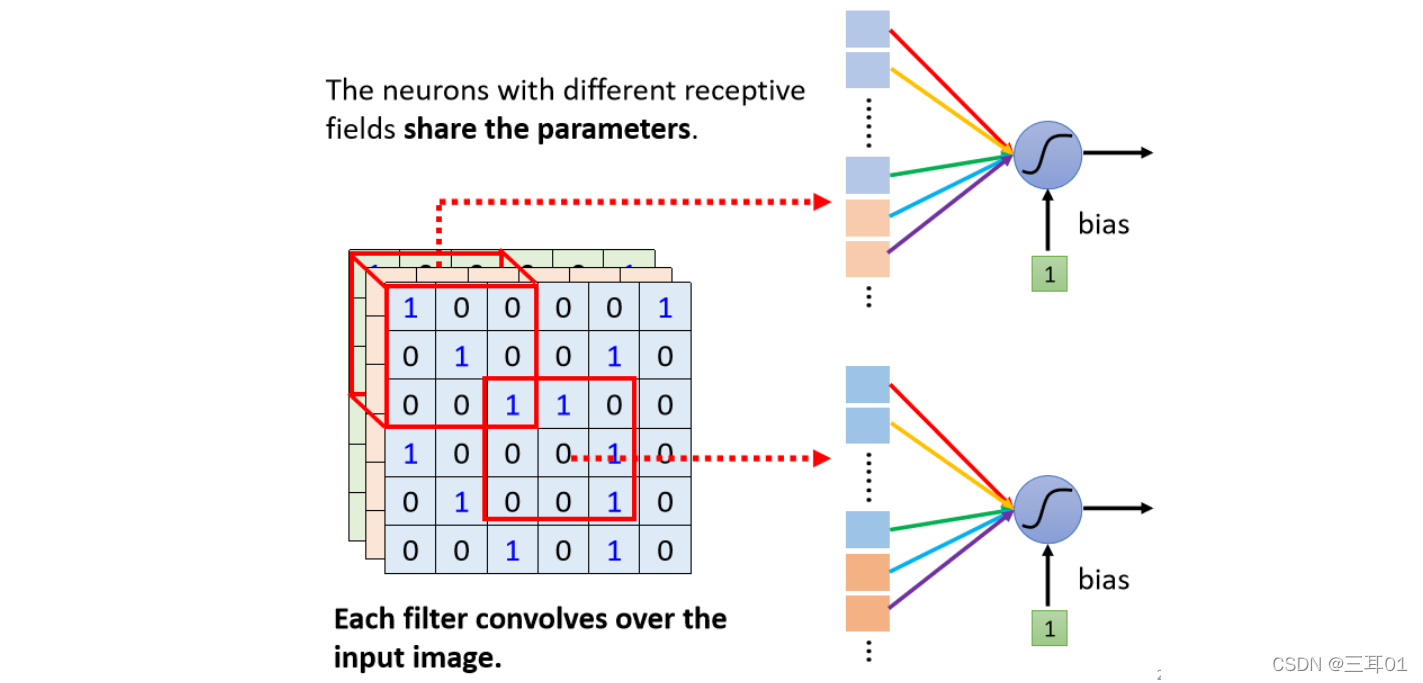
Filter ɨ��һ��ͼƬ�����,��ʵ���� Convolution�����Ƕ��ڲ�ͬ�� Receptive Field, Neuron ���Թ��ò���,�����鹲�õIJ���,�ͽ���һ�� Filter��
6 �۲�3����Pooling

���ǰ�һ�űȽϴ��ͼƬ�����γ�����������˵��ż�����ж��õ�,�������ж��õ�,ͼƬ���ԭ����1/4,���Dz���Ӱ���e����ʲ�N����,��ʵ���ǰ�һ�Ŵ��ͼƬ��С��
Pooling ����û�в���,����������һ�� Layer,���e��û�� Weight,��û��Ҫ Learn �Ķ���,���� Pooling �Ƚ�����һ�������,�Ƚ����� Sigmoid , ReLU ��Щ,������e����û��Ҫ Learn �Ķ�����,������һ�������,������Ϊ���ǹ̶��õ�,����Ҫ���� Data ѧ�κζ�����
ÿһ�� Filter ������һ������,Ҫ�� Pooling ��ʱ��,���ǾͰ���Щ���ּ�������һ��,Ȼ�� Pooling��
6.1 Convolutional Layers + Pooling
������������ Convolution �Ժ�,�������滹����� Pooling, Pooling ����������ǰ�ͼƬ��С,���� Convolution �Ժ����ǻ�õ�һ��ͼƬ,��һ��ͼƬ�e���кܶ�� Channel, ������ Pooling �Ժ�,���Ǿ��ǰ�����ͼƬ�� Channel ����,���� 64 �� Channel ���� 64 �� Channel,�������ǻ��ͼƬ��ñȽ�����һ�㡣
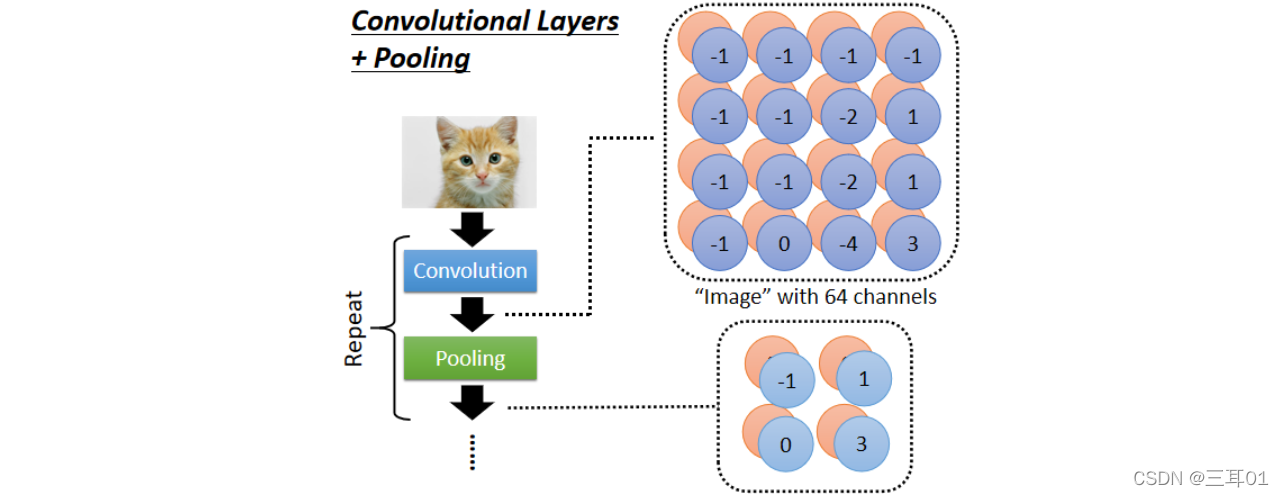
���� 4��4 ��ͼƬ��� 2��2 ��ͼƬ��
һ����ʵ����,�������� Convolution �� Pooling ����ʹ�á�
����Poolingʼ�ջ������˺�,���ڼ�����������,�ܶ�Ӱ����ӵ� Network �����,����Ҳ��ʼ�� Pooling ����,������ Full Convolution �� Neural Network,Ҳ�������� Network ����ͳͳ���� Convolution,��ȫ������ Pooling��
7 The whole CNN
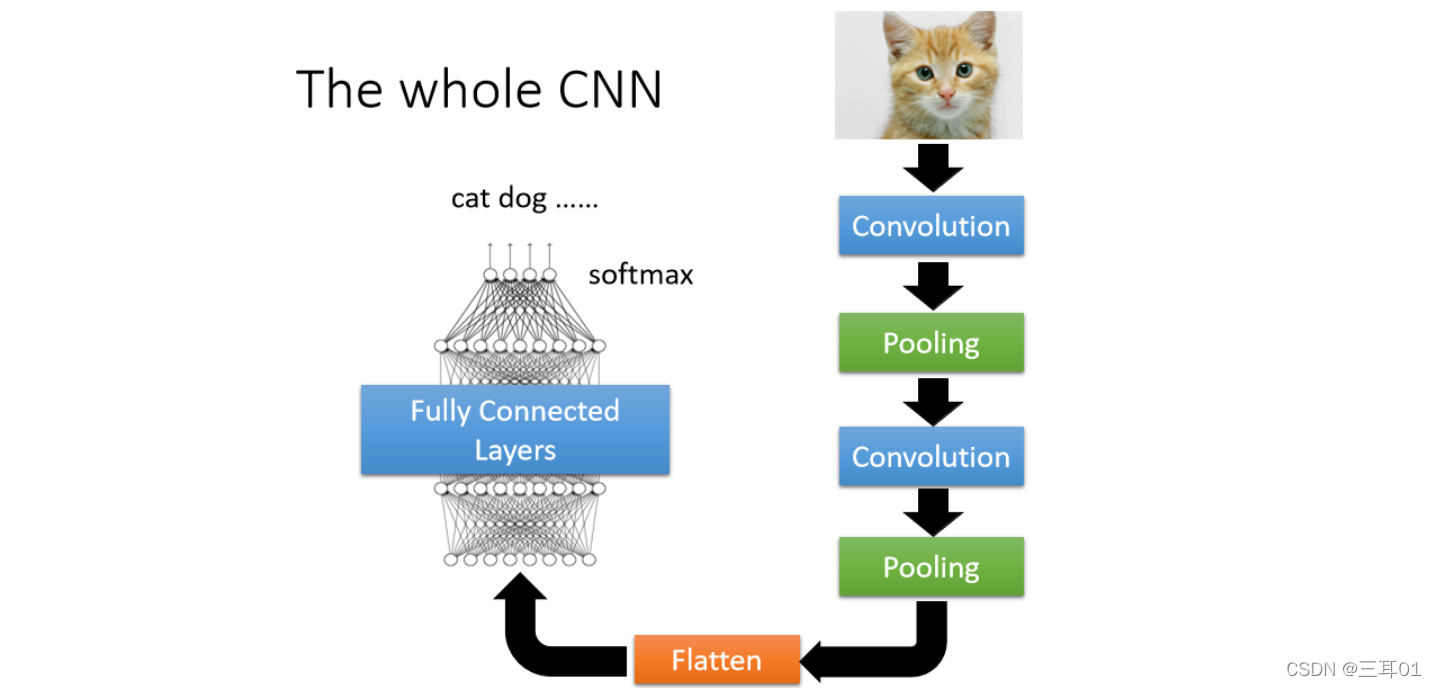
���꼸�� Convolution �Ժ�,��������� Output �� Flatten(��Ӱ�����汾���ųɾ�������ӵĶ�����ֱ,�����е���ֵ��ֱ���һ������),�ٰ��������,���� Fully Connected �� Layer ���档��������ܻ�Ҫ���� Softmax,Ȼ�����յõ�Ӱ���ʶ�Ľ����
�����һ�������Ӱ���ʶ��Network,�e���� Convolution,�� Pooling �� Flatten,�����ͨ������,Fully Connected �� Layer �� Softmax,���յõ�Ӱ���ʶ�Ľ����
8 ����һ��CNN�����Ӧ�á�����Χ��
����һ������ķ������⡣
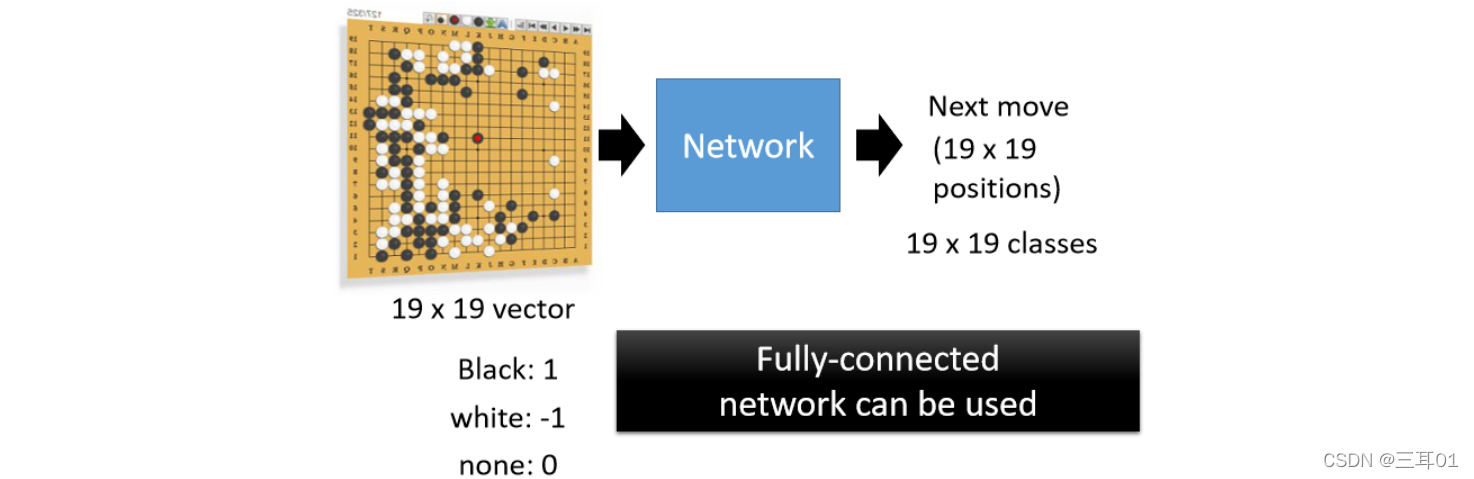
Network ��������һ������,���ǰ�һ�����̱�ʾ��һ�� 19 �� 19 ά������,��������������ʾ���ӵ�λ��(��������� 1 ,������ -1,û������ 0)��
����������䵽һ�� Network ����,Ȼ��Ϳ�����Χ�嵱��һ�����������,�� Network ȥԤ����һ��Ӧ�����ӵ�λ���������e��á�
������Χ��,����һ���� 19 �� 19 �����ķ��������,Network �� Output ����19 �� 19 ������e��,��һ���������õ�,Ӧ��Ҫѡ����һ�����ӵ�λ��Ӧ��������������������ȫ������һ�� Fully Connected �� Network �����,������ CNN ��Ч��������
��Ϊ�������̿������� 19 �� 19 ��ͼƬ(��С),����ÿһ�����ؾʹ���������һ���������ӵ�λ�á�
�� AlphaGo ��ԭʼ������,ÿһ�����̵�λ��,���� 48 �� Channel ��������,Ҳ����˵�����ϵ�ÿһ��λ��,������ 48 �������������Ǹ�λ�÷�����ʲô�¡�
7.1 Why CNN for Go playing?
- ���Ǹղ���Ӱ���ϵĵ�һ���۲���,�ܶ���Ҫ�� Pattern,��ֻ��Ҫ��С��Χ��֪��,��Χ���Dz���Ҳ��һ����
����Χ��,���㲻�ÿ��������̵�����,������֪����߷�����ʲô�¡��� AlphaGo �e�氡,���ĵ�һ��� Layer,���� Filter �Ĵ�С���� 5 �� 5,������Ȼ������ Network ��������,�����Ϻܶ���Ҫ�� Pattern,Ҳ���� 5 �� 5 �ķ�Χ�Ϳ���֪���ˡ� - Ӱ���ϵĵڶ����۲���,ͬ���� Pattern ���ܻ�����ڲ�ͬ��λ��,����Χ���e����ȻҲ��������
Χ����û����Pooling,��Ϊ���ܾ�ϸ,��������Pooling��
8 ����
8.1 ����Ӧ��
CNN ������Χ�廹��Ӱ������, ������Ҳ����������,Ҳ�������ִ����ϡ�
��������������� CNN ��������������������ִ�����,Ҫ��ϸ��һ�������ϵķ�������������������, Receptive Field ����ơ�������������ƺ�Ӱ���ϲ���һ���ġ�
����Ҫ���������Щ Receptive Field ��������,���������ϵ���Ƹ�Ӱ���ϲ���һ��,�ǿ��������������ֵ������Ժ�����Ƶġ�
�����㲻Ҫ�Ԟ���Ӱ���ϵ� CNN,ֱ������������Ҳ Work,�����Dz� Work ��,��Ҫ�����˵Ӱ��,������ʲ�N��������,����Ҫ���N��ƺ��ʵ� Receptive Field��
8.2 CNN���ܴ���Ӱ��Ŵ���С����ת������

����,�� CNN ���Ĺ��������������С,�����Ա�ʶ˵����һֻ��,��������ͼƬ�Ŵ��ʱ��,�����Ա�ʶ˵������һֻ����,�����Dz��еġ�
������˵��Ȼ������ͼƬ����״��һģһ����,�����������������������Ļ�,���e�����ֵ���Dz�һ����,���Զ� CNN ��˵,��Ȼ������һ����������״����,���� CNN �� Network ��˵���Ƿdz���һ����
������ʵ��,CNN �����ܹ�����Ӱ��Ŵ���С,��������ת������,����������ij�ִ�С��Ӱ����,�����������������DZȽ�С��,��������ѧ����Ӱ���ʶ,�������Ŵ����ͻ������ҵ���
���� CNN ��û������������Nǿ,�Ǿ���Ϊʲô����Ӱ���ʶ��ʱ��,������Ҫ�� Data Augmentation(������ǿ),��ν Data Augmentation ����˼����˵,������ѵ������,ÿ��ͼƬ���e���һС������Ŵ�,�� CNN �п�����ͬ��С�� Pattern,Ȼ���ͼƬ��ת,�����п���˵,ijһ�������ת�Ժ�ʲ�N����,CNN �Ż������õĽ����

CNN ������ܹ��������ź���ת������,��һ���ܹ��� Special Transformer Layer,���Դ����������(¼������ͼ)��
Pooling�Ƕ��Ѿ���fiter������������ݽ�����С���ġ�����˵����CNN���ܴ���ԭͼƬ��������С�ͷŴ�