一、 摘要
CNN+static vector 在句子分类的任务中表现很好,而且基于具体task微调后的task-specific vectors 表现的更好
二、模型结构
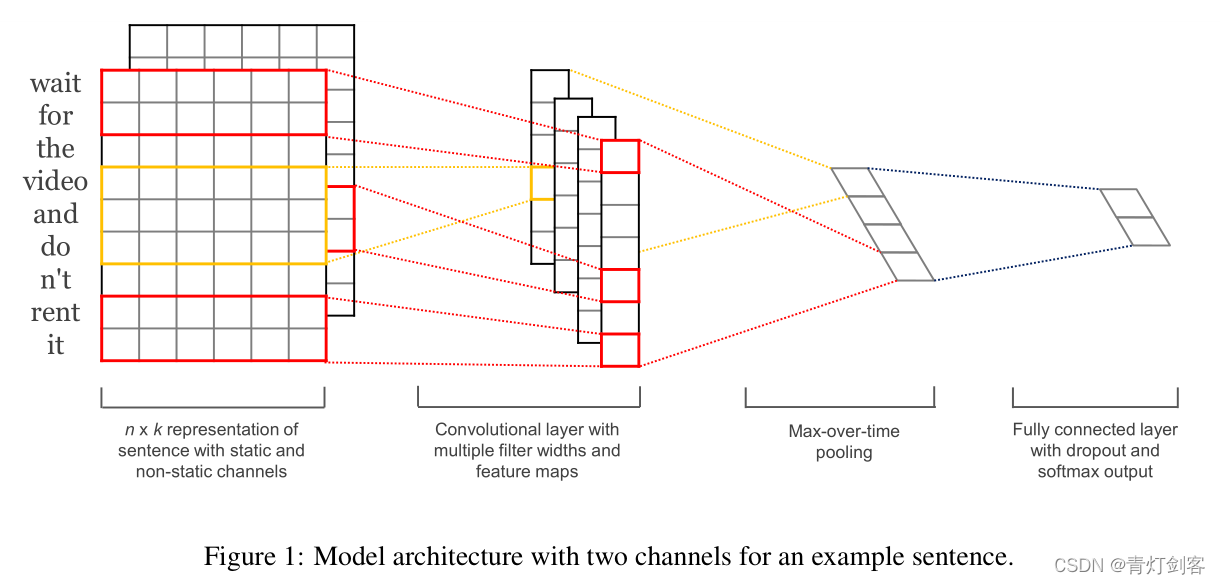
值得注意的是:我们的实验对象有2个channels。在第一个里面,词向量是训练过程中保持是static;在第二个里面,词向量在训练中根据backPropagation微调。
2.1 正则化
(1)倒数第二层增加dropout
(2)倒数第二层增加L2正则的权重限制。
三、数据和实验
3.1 调参和训练
(1)超参数,从网格搜索中得来
(2)在验证集上运用了early stopping
当没有验证集时,从训练集中随机选取10%来作为验证集。优化器是SGD.
3.2 预训练的词向量
当没有大量的训练数据时,使用公开可得到的 word2vec 向量 是一种流行的可提高表现的方法。未出现在 word2vec 中的词,其向量随机初始化。
3.3 模型变体们
CNN-rand: 所有单词的词向量随机初始化,在训练中微调。
CNN-static: 词向量来自于word2vec ,在训练中保持 static。
CNN-non-static: 词向量来自于word2vec ,在训练中微调
CNN-multichannel: 两套来自于word2vec 的词向量。一套static,一套在训练中微调。
四、结果和分析
CNN-rand 结果不好;CNN-static 很优秀,但CNN-non-static 表现更好。
4.1 多channel 还是单channel
我们原本以为多channel 能够防止 过拟合,可是结果表现却时mixup,需要更多的研究。例如,代替使用多channel,而是 增加向量的维度,这些增加的维度在训练中可以被修改。
4.2 静态和非静态的语义表征
使用非静态的语义表征的向量,其针对具体的任务更专业 specific。
4.3 进一步的观察
- 另外一哥们也用CNN做实验,结果差得多。我们对比发现:(1)他的结构和我们的单channel模型类似。(2)差异化在于 ,我们的模型有更大的capacity,即多种核宽和多种特征map
- dropout+比necessary更大的网络 贡献很大。
- 从分布U[-a,a]中为不在word2ec的词 采样 数值,也获得了一点提升。
- Adadelta、Adadelta的效果类似,不过需要的epoch要少。
五、结论
无监督训练出来的word2vec 真的很不错。