1.Transformers in Medical Imaging: A Survey
������Transformers��ҽѧͼ��ָ��⡢���ࡢ�ؽ����ϳɡ������ٴ��������ɺ����������е�Ӧ�á�
Shamshad F, Khan S, Zamir S W, et al. Transformers in Medical Imaging: A Survey[J]. arXiv preprint arXiv:2201.09873, 2022. [Դ��]
2.Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey
Kaur N, Mittal A, Singh G. Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey[J]. Multimedia Tools and Applications, 2021: 1-31.
���ڱ�����-��������ܵ�ARRGϵͳʹ�ñ�����������ͼ������ȡ����,ʹ�ý�������������ȡ��������Ӧ������������ʹ����[������]-[������]�IJ�ͬ���,����[CNN]-[RNN]��[CNN]-[HRNN]��[CNN]-[HRNN��˫��LSTM]��[CNN��GLP����]-[HRNN������ƥ�����]�����ڱ�������������ܵ�ARRGϵͳ��������ͼ������������ͼ���г��ֵ��쳣�ľ��ӡ�Ȼ��,����ע����Ƶ�ARRGϵͳ��עͼ���һ������������һ�����ʡ���ָ��,ͬʱ�������ɱ�����Ӿ����������Կ������ϵͳ�����ܡ�������ARRGϵͳ����ע���ɾ��ӵĿɶ���,���������ǵ��ٴ�����ԡ�����ǿ��ѧϰ��ARRGϵͳʹ�ý������ɾ�������ٴ�����Եı��档�ݹ۲�,�����ٴ���Ч������������ǿģ�ͱȵ��������ṩ���õĽ����Ȼ��,���ɵı����з������ֵľ��ӡ�����ͼ��ARRGϵͳ�����������⡣�ڻ���ͼ�ε�ARRGϵͳ��,����ע�,�����ɱ���ʱ,����ģ������RNN;������˵,Ԥ��ѵ��������ģ�Ϳ����ṩ���õĽ����
3.Diagnostic captioning: a survey
Pavlopoulos J, Kougia V, Androutsopoulos I, et al. Diagnostic captioning: a survey[J]. arXiv preprint arXiv:2101.07299, 2021.
�����ṩ�������Ļ(DC)�������������ݼ���������ʩ�Ĺ㷺������
�ͷ�������,Ŀǰ�����DC����ʹ�ñ�����-���������ѧϰ����,����Ҫ����Ϊ������ͨ��(��ҽѧ)ͼ����Ļ����ȡ���˳ɹ���Ȼ��,�����Ѿ�ָ��,DC��Ŀ����ֻ����������ҽ����ϵ���Ϣ�������ʾ��ͻ������(������������)û���ٴ�����Ҫ�ı���,�������ἰ,����һ��ͼ����Ļ��ͬ,����ͻ������(�Լ������Ķ���)ͨ�����뱨�档����ͨͼ����Ļ����һ����Ҫ������,ҽѧͼ��IJ���С�ö�,���,��ͬ���ߵ���Ӧ����ı�ͨ���dz�����,������ȫ��ͬ������������ʹ�û��ڼ����ķ�����DC�б��ֵó���غ�,��Щ���������������Ծ�������ͼ���ѵ��ʾ��������ı���Ҳ����ʹ�ó��þ��ӻ����ģ��,�������������ǡ�
��������Ŀ��,DC����������Ҫ������Դ�Ի��������ժҪ�ĵ����ص�����,�����������ժҪͨ�������ٴ���ȷ��,��������Ҳʹ���˹�ʾ����֤�����������������˱Ƚϱ�ǩ(Ҳ����Ϊ��ǩ�����,��Ӧ��ҽѧ��������)�Ĵ�ʩ,��Щ��ǩ���ֶ���ȡ��,���߸���������,��ϵͳ���ɵĺ������д����ϱ������Զ���ȡ��,��Ϊ���õز��ٴ���ȷ�Ե��ֶΡ�Ȼ��,���Զ���ȡ��ǩ�Ĺ��߲�ȷ,������ע��ָ�ϲ����Ӧ�÷��������Щ��ǩ,�Լ�����ǩ������ȫ��������ı���Ҫ��������Ϣʱ,����Ҳ����ʧ�ܡ��˹�������DC���ټ�,��������Ϊ��Ӷ�����㹻ҽѧרҵ֪ʶ��������Ա���ѶȺͳɱ���
�����ݼ�����,����רע�ڽ��е�������������������Ĺ����������ݼ�(IU X-RAY��MIMIC-CXR),�������������������������ݼ�������ȱ��(����,���ǿ��ܲ�������ʵ����ҽѧͼ��)�����ǻ��ռ���������֮ǰ����������DC���ݼ�������������ָ��������������������ʹ�õ����ݼ���ָͬ,��Щ���ͨ����ֱ�ӽ��бȽ�,�������ṩ�˲�ͬ����DC����ִ�����������ָʾ�������ռ��Ľ��Ҳ���ܰ��������о���Ա�ó���֮ǰ�����Ľ����ֱ�ӿɱȵĽ����
������Ϊ,����ͷ��������ı��ı�����-��������������ڼ����ķ������ϵĻ�Ϸ���,�����ù�ȥ���ư����е��ı��ķ���,���п��ܳɹ���
4.Deep learning in generating radiology reports: A survey
Monshi M M A, Poon J, Chung V. Deep learning in generating radiology reports: A survey[J]. Artificial Intelligence in Medicine, 2020, 106: 101878.

���CNN+RNN�ṹ�������ɽ���������
5.A survey on deep learning and explainability for automatic image-based medical report generation
Messina P, Pino P, Parra D, et al. A survey on deep learning and explainability for automatic image-based medical report generation[J]. arXiv preprint arXiv:2010.10563, 2020.
6.Improving factual completeness and consistency of image-to-text radiology report generation
Miura Y, Zhang Y, Tsai E B, et al. Improving factual completeness and consistency of image-to-text radiology report generation[J]. arXiv preprint arXiv:2010.10042, 2020. [Դ��]
7.Hierarchical x-ray report generation via pathology tags and multi head attention
Srinivasan P, Thapar D, Bhavsar A, et al. Hierarchical x-ray report generation via pathology tags and multi head attention[C]//Proceedings of the Asian Conference on Computer Vision. 2020. [Դ��]
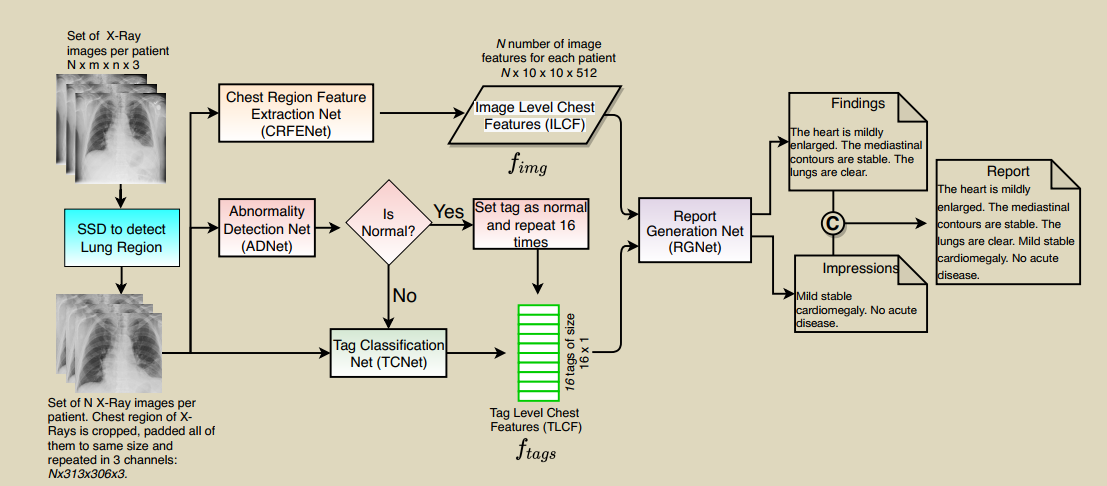
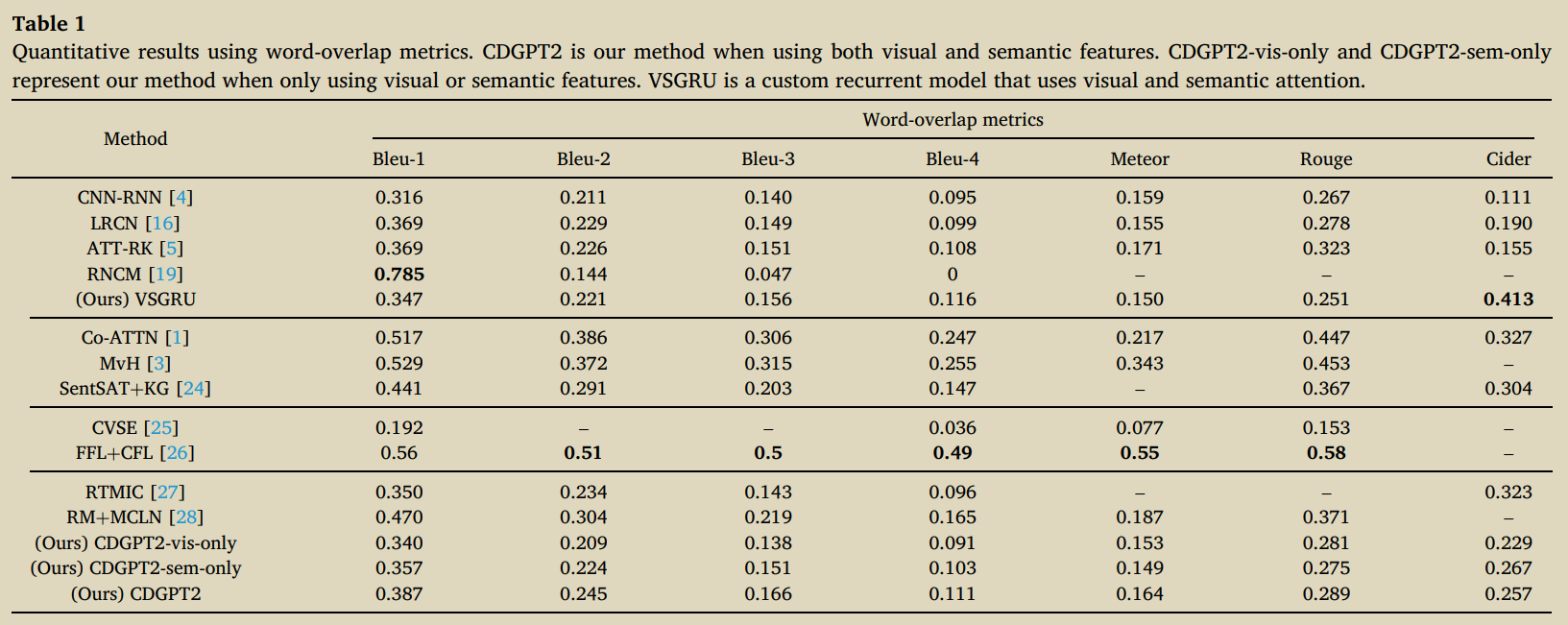
1.���÷��η���������,������������ʶ����쳣����,��������MTI��ǩǶ�롣Ȼ����ݱ�ǩ��������ѧϰ��2.Ϊ��Ԥ�ⱨ��ʹ��һ�ְ���������������������������Transformer��3.��ǩǶ���ͼ�������ֱ�ʹ���������������롣�����findings��impressionsͨ�������ѵ��Ľ�����ѧϰ,����ǰ�߸Ľ�������ɡ�
8.Exploring and distilling posterior and prior knowledge for radiology report generation
Liu F, Wu X, Ge S, et al. Exploring and distilling posterior and prior knowledge for radiology report generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13753-13762.
ģ��ҽ����ȷ���쳣����ͼ�������,����������֪ʶ���б�����д�Ĺ��̡���Ϊ: Posterior KnowledgeExplorer (PoKE), Prior Knowledge Explorer (PrKE) ��
Multi-domain Knowledge Distiller (MKD)��PoKE̽���˺���֪ʶ,�ṩ����ʽ���쳣�Ӿ������������Ӿ�����ƫ��;PrKE����ǰ��ҽѧ֪ʶͼ����(ҽѧ֪ʶ)�ͼ�����ǰ�ķ���ѧ����(��������)��̽����ǰ��֪ʶ,�Լ����ı����ݵ�ƫ����̽����֪ʶ��MKD���������������յı��档
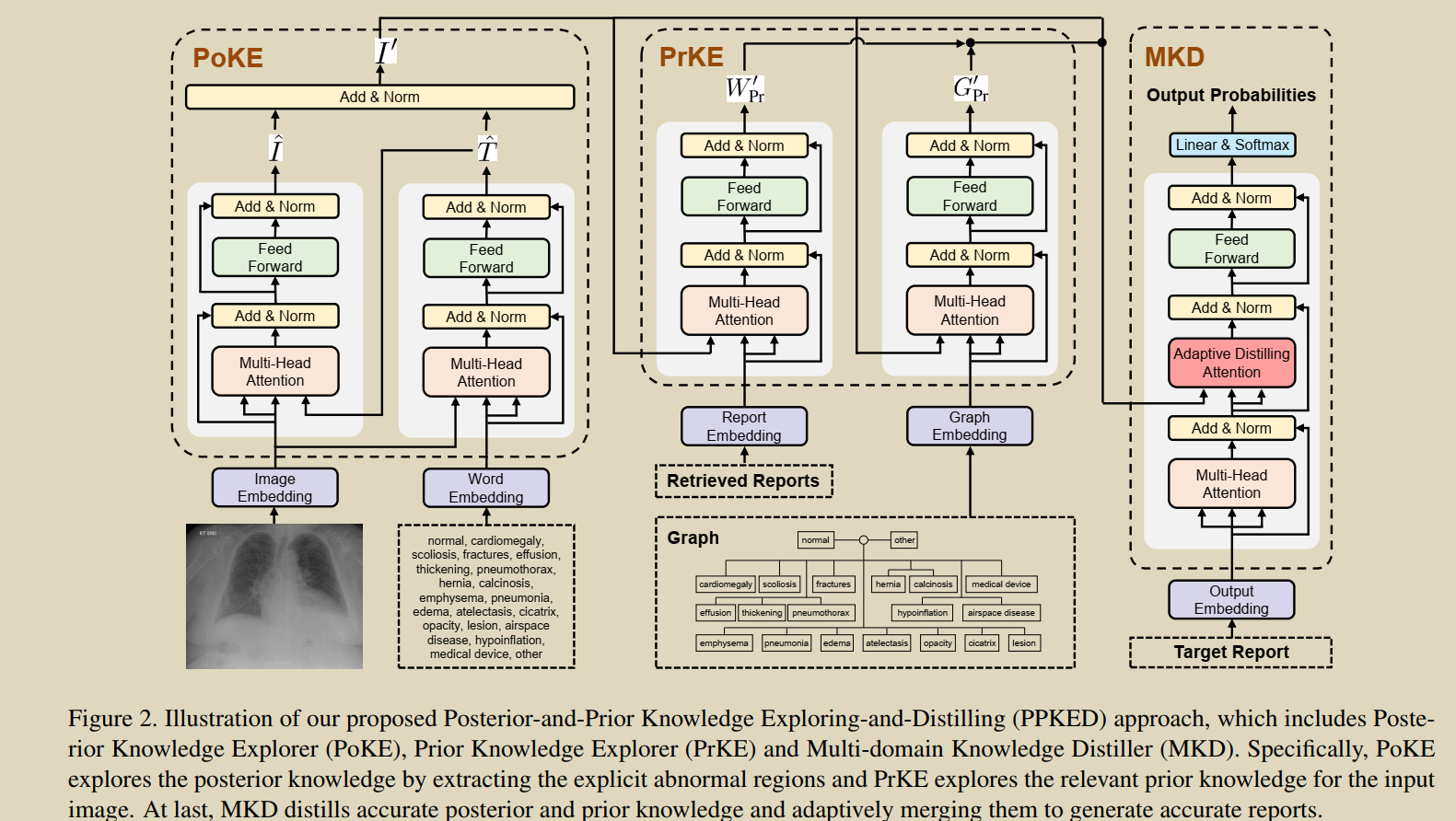

a. P o K E : { I , T } �� I �� PoKE : \{I, T\} \rightarrow I^{\prime} PoKE:{I,T}��I��;
����: T ^ = FFN ? ( MHA ? ( I , T ) ) ; I ^ = FFN ? ( MHA ? ( T ^ , I ) ) \hat{T}=\operatorname{FFN}(\operatorname{MHA}(I, T)) ; \hat{I}=\operatorname{FFN}(\operatorname{MHA}(\hat{T}, I)) T^=FFN(MHA(I,T));I^=FFN(MHA(T^,I))
I I I:����ͼ�� T T T:�̶����쳣����(20��)�ʴ�
b. PrKE ? : { I �� , W P r } �� W P r �� ; { I �� , G P r } �� G P r �� \operatorname{PrKE}:\left\{I^{\prime}, W_{\mathrm{Pr}}\right\} \rightarrow W_{\mathrm{Pr}}^{\prime} ; \quad\left\{I^{\prime}, G_{\mathrm{Pr}}\right\} \rightarrow G_{\mathrm{Pr}}^{\prime} PrKE:{I��,WPr?}��WPr��?;{I��,GPr?}��GPr��?
����:
W
Pr
?
��
W_{\operatorname{Pr}}^{\prime}
WPr��?and
G
Pr
?
��
G_{\operatorname{Pr}}^{\prime}
GPr��? which represent the prior knowledge relating to the abnormal regions of the input image .prior knowledge from existing radiology
report corpus and represent them as
W
Pr
?
W_{\operatorname{Pr}}
WPr?and
G
Pr
?
G_{\operatorname{Pr}}
GPr?respectively
c. W P r �� = F F N ( MHA ? ( I �� , W P r ) ) G P r �� = F F N ( MHA ? ( I �� , G P r ) ) \begin{aligned} W_{\mathrm{Pr}}^{\prime} &=\mathrm{FFN}\left(\operatorname{MHA}\left(I^{\prime}, W_{\mathrm{Pr}}\right)\right) \\ G_{\mathrm{Pr}}^{\prime} &=\mathrm{FFN}\left(\operatorname{MHA}\left(I^{\prime}, G_{\mathrm{Pr}}\right)\right) \end{aligned} WPr��?GPr��??=FFN(MHA(I��,WPr?))=FFN(MHA(I��,GPr?))?
d.MKD : { I �� , W P r �� , G P r �� } �� R \left\{I^{\prime}, W_{\mathrm{Pr}}^{\prime}, G_{\mathrm{Pr}}^{\prime}\right\} \rightarrow R {I��,WPr��?,GPr��?}��R.
e.Adaptive Distilling Attention (ADA)
ADA
?
(
h
t
,
I
��
,
G
P
r
��
,
W
P
r
��
)
=
MHA
?
(
h
t
,
I
��
+
��
1
G
P
r
��
+
��
2
W
P
r
��
)
\operatorname{ADA}\left(h_{t}, I^{\prime}, G_{\mathrm{Pr}}^{\prime}, W_{\mathrm{Pr}}^{\prime}\right)=\operatorname{MHA}\left(h_{t}, I^{\prime}+\lambda_{1} G_{\mathrm{Pr}}^{\prime}+\lambda_{2} W_{\mathrm{Pr}}^{\prime}\right)
ADA(ht?,I��,GPr��?,WPr��?)=MHA(ht?,I��+��1?GPr��?+��2?WPr��?)
��
1
,
��
2
=
��
(
h
t
?
W
h
��
(
I
��
W
I
+
G
P
r
��
W
G
+
W
P
r
��
W
W
)
)
\lambda_{1}, \lambda_{2}=\sigma\left(h_{t} \mathrm{~W}_{h} \oplus\left(I^{\prime} \mathrm{W}_{I}+G_{\mathrm{Pr}}^{\prime} \mathrm{W}_{G}+W_{\mathrm{Pr}}^{\prime} \mathrm{W}_{W}\right)\right)
��1?,��2?=��(ht??Wh?��(I��WI?+GPr��?WG?+WPr��?WW?))
����:�����������ͺ���
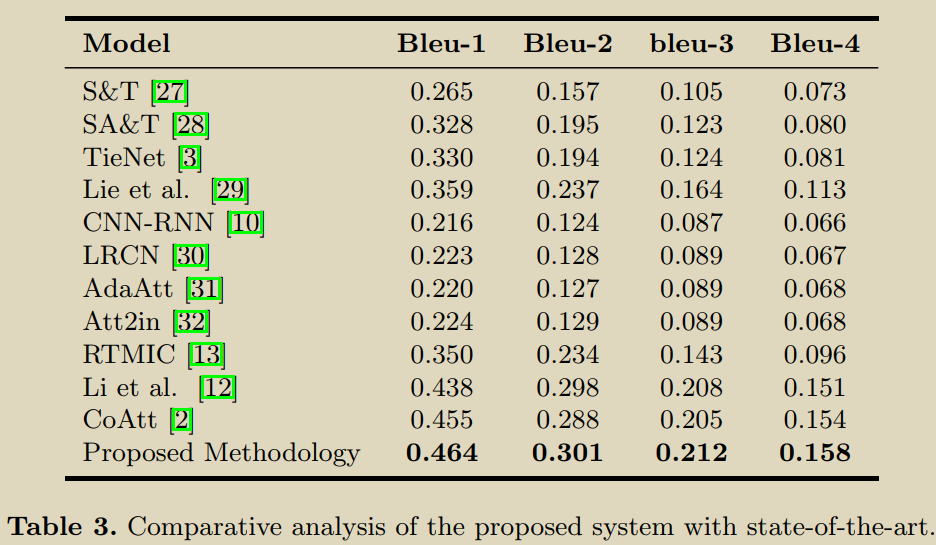
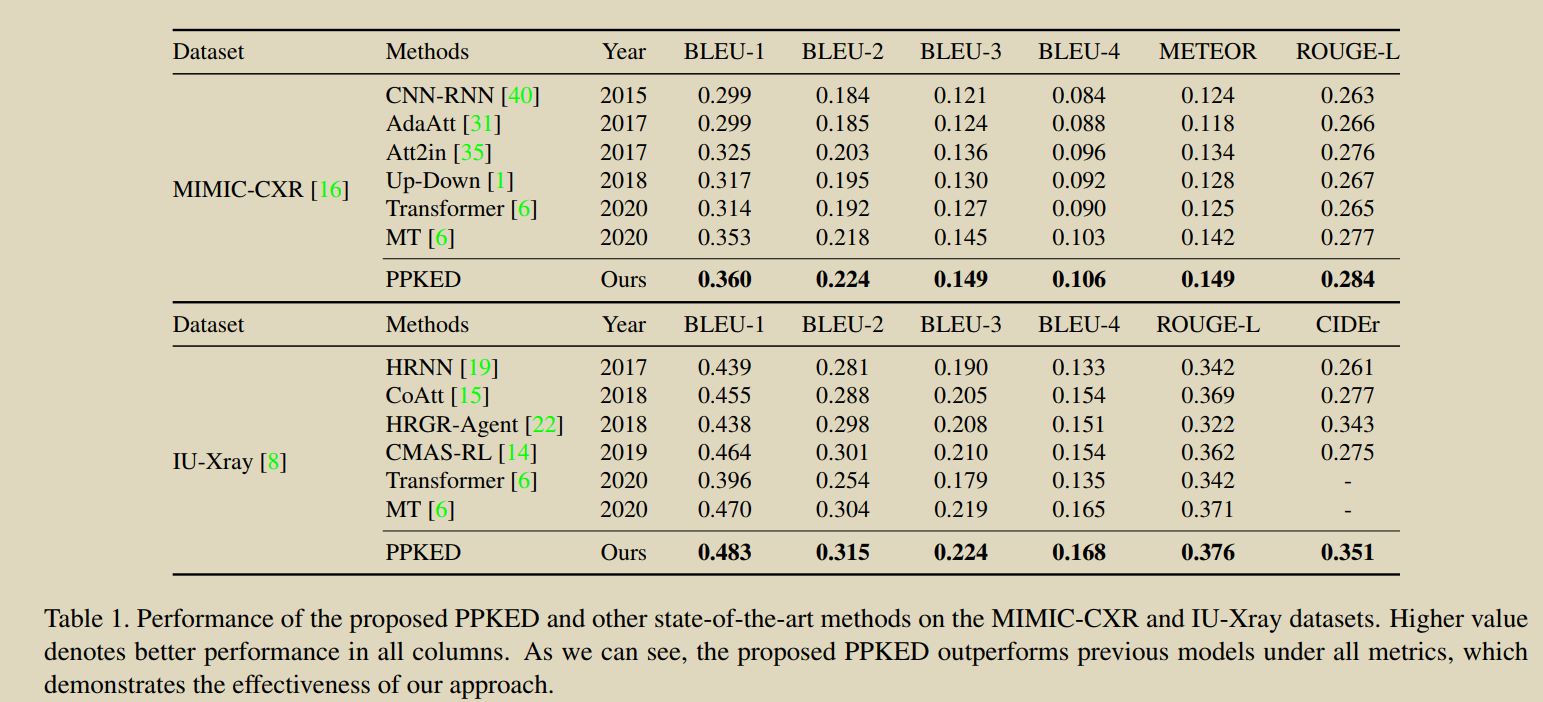
ȱ��:�������ݾ������������ݼ�IU-Xray��MIMIC-CXR
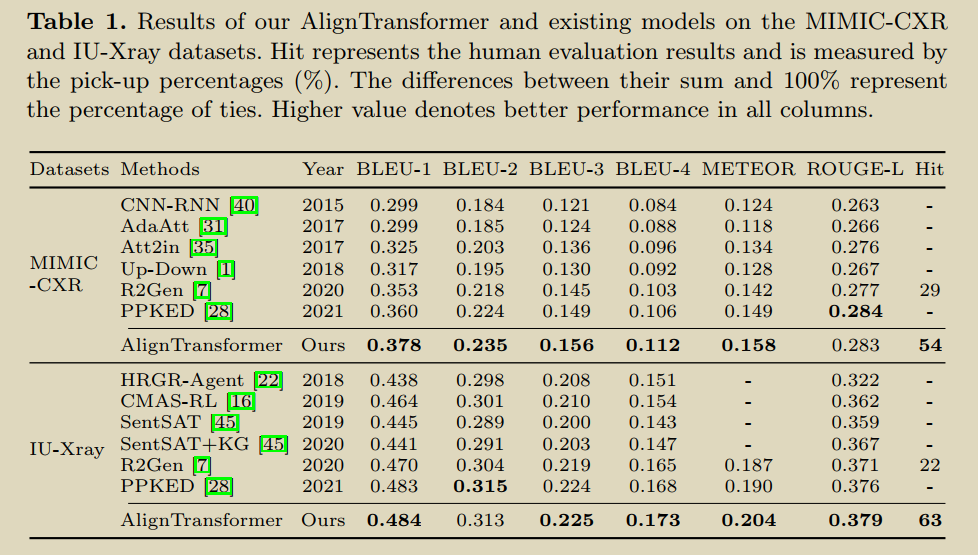
9.Aligntransformer: Hierarchical alignment of visual regions and disease tags for medical report generation
You D, Liu F, Ge S, et al. Aligntransformer: Hierarchical alignment of visual regions and disease tags for medical report generation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 72-82.
�����������8ƪ����
���AlignTransformer���ҽѧ���������е���������:(1)����data bias->Align Hierarchical Attention (AHA) (2)���ɳ�����->Multi-Grained
Transformer (MGT) modules
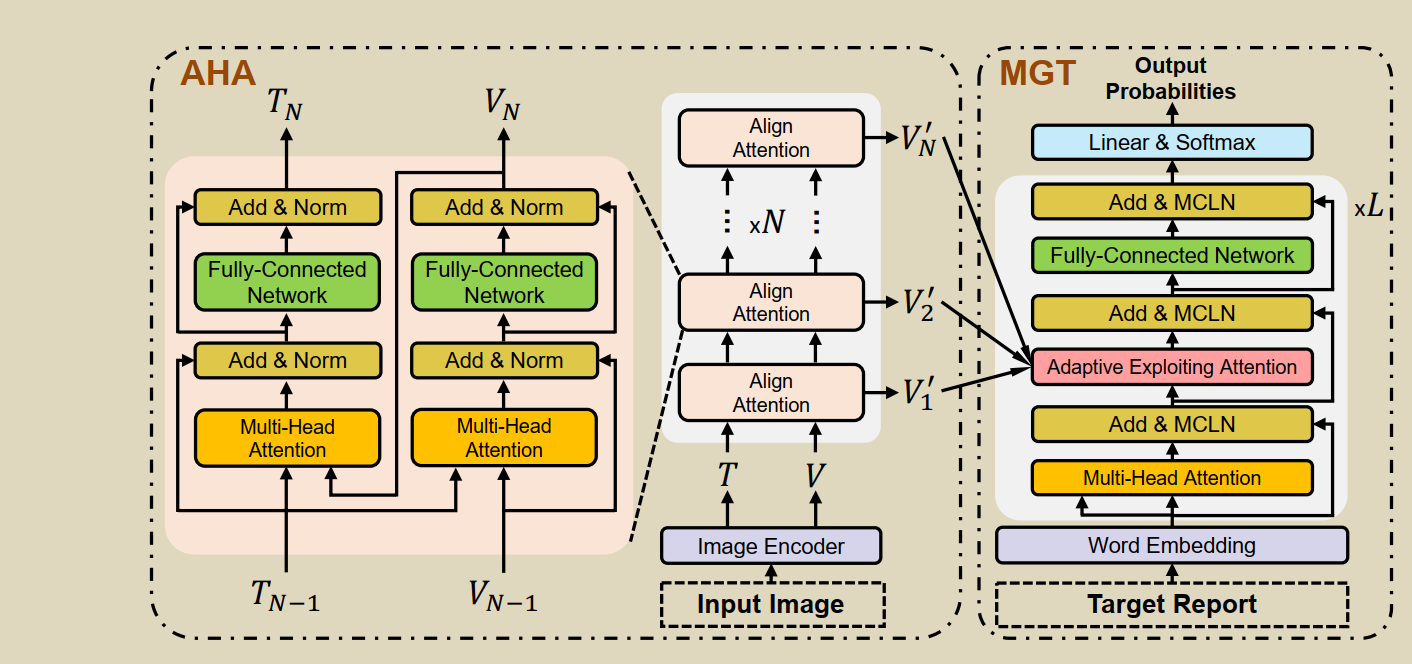
v i s u a l f e a t u r e s V visual features V visualfeaturesV :��ImageNETԤѵ��CheXpert����ResNet-50��ȡ
tags T :��multi-label classification����Tags
A H A : { V , T } �� V ^ \mathrm{AHA}:\{V, T\} \rightarrow \hat{V} AHA:{V,T}��V^:AHA���ȴ�����ͼ����Ԥ�⼲����ǩ,Ȼ��ͨ���ֲ�����Ӿ�����ͼ�����ǩѧϰ�����ȵ��Ӿ���������õĻ��ڼ������Ӿ��������Ը��õش�������ͼ����쳣����,���Ի�������ƫ�����⡣
V �� = F C N ( M H A ( T , V ) ) V^{\prime}=\mathrm{FCN}(\mathrm{MHA}(T, V)) V��=FCN(MHA(T,V)) T �� = F C N ( M H A ( V �� , T ) ) T^{\prime}=\mathrm{FCN}\left(\mathrm{MHA}\left(V^{\prime}, T\right)\right) T��=FCN(MHA(V��,T)) V ^ = LayerNorm ? ( V �� + T �� ) \hat{V}=\operatorname{LayerNorm}\left(V^{\prime}+T^{\prime}\right) V^=LayerNorm(V��+T��)
MGT : V ^ �� R : \hat{V} \rightarrow R :V^��R: MGTģ����Ч�������˶��������Ժ�Transformer���,�����˳�ʱ���ҽ�Ʊ��档
h
^
t
(
l
)
=
AEA
?
(
h
t
(
l
)
,
{
V
^
i
}
)
=
��
i
=
1
N
��
i
��
MHA
?
(
h
t
(
l
)
,
V
^
i
)
\hat{h}_{t}^{(l)}=\operatorname{AEA}\left(h_{t}^{(l)},\left\{\hat{V}_{i}\right\}\right)=\sum_{i=1}^{N} \lambda_{i} \odot \operatorname{MHA}\left(h_{t}^{(l)}, \hat{V}_{i}\right)
h^t(l)?=AEA(ht(l)?,{V^i?})=��i=1N?��i?��MHA(ht(l)?,V^i?)
��
i
=
��
(
[
h
t
(
l
)
;
MHA
?
(
h
t
(
l
)
,
V
^
i
)
]
W
i
+
b
i
)
\lambda_{i}=\sigma\left(\left[h_{t}^{(l)} ; \operatorname{MHA}\left(h_{t}^{(l)}, \hat{V}_{i}\right)\right] \mathrm{W}_{i}+b_{i}\right)
��i?=��([ht(l)?;MHA(ht(l)?,V^i?)]Wi?+bi?)
10.Meshed-memory transformer for image captioning
Cornia M, Stefanini M, Baraldi L, et al. Meshed-memory transformer for image captioning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10578-10587. [Դ��]
11.Cross-modal Memory Networks for Radiology Report Generation
Chen Z, Shen Y, Song Y, et al. Cross-modal Memory Networks for Radiology Report Generation[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 5904-5914. [Դ��] �����ķ��롿
�����һ�ֿ�ģ̬�洢������(CMN)����ǿ���ڷ���ѧ�������ɵı�����-���������,���������洢�������Ϊ��¼ͼ����ı�֮��Ķ���,�Ա��ڿ�ģ̬�Ľ��������������һ������cross-modal memory networks ����¼ͼ�ĵĶ��롣���ͼ�Ķ�ģ̬ӳ������ʹ������ӳ����и��õı������ɡ�
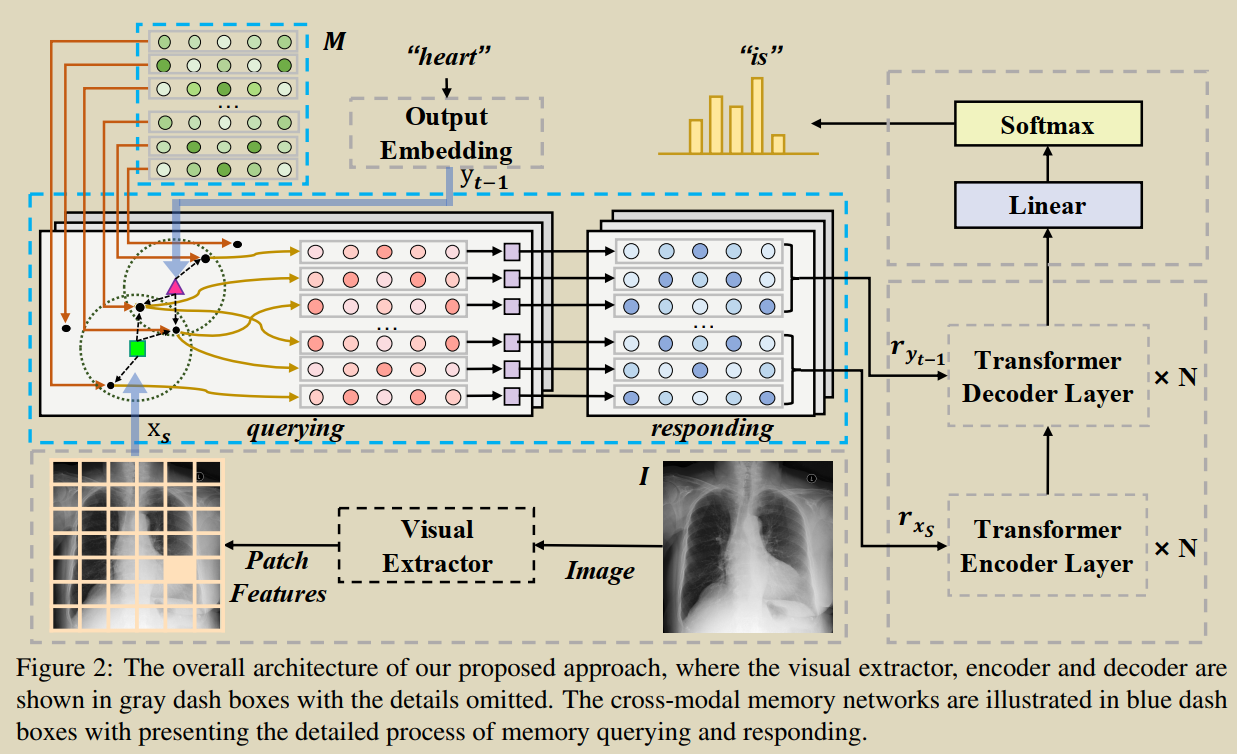
��ϸ��,ʹ�ô洢�������洢��ģ̬��Ϣ��ʹ������ִ�ж��Ӿ����ı������Ĵ洢��ѯ����Ӧ,���ж��ڴ洢��ѯ,�Ӿ�������ȡ����صĴ洢����������������Ӿ����ı�������������Ȩ��,Ȼ��ͨ����Ȩ��ѯ���Ĵ洢ʸ����������Ӧ��֮��,���������Ӿ����ı���������Ӧ�����͵��������ͽ�������,�Ա�ͨ����ʽ�Ŀ�ѧϰ�Ŀ�ģ̬��Ϣ������ǿ�ı��档�Ӿ����ı������Ĵ洢��Ӧ�������������ͽ�����������,����ǿ���ɹ��̡�
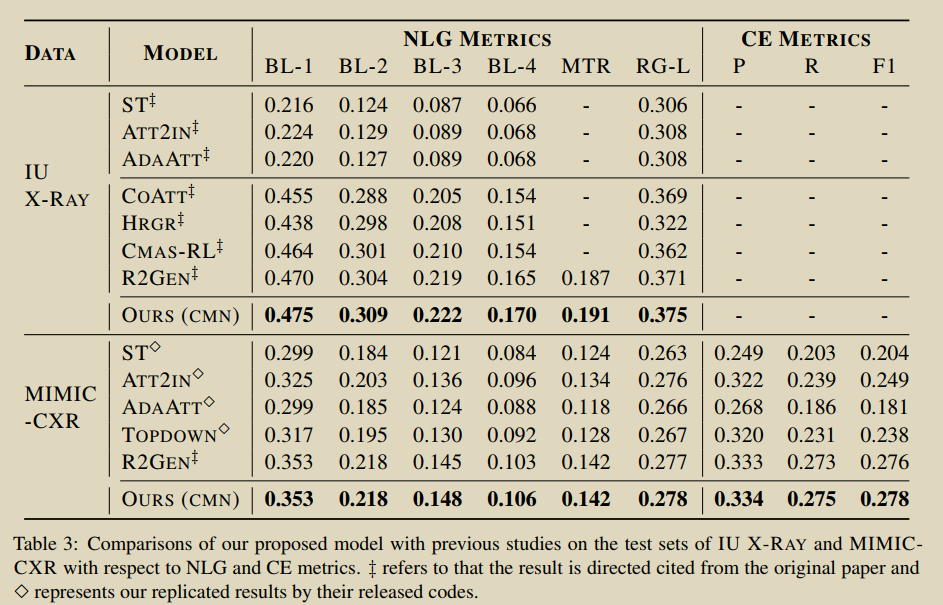
��������������ʹ��Transfomer���Ʒ�ʽ����ͼ������,�Ա�Ч������AlignTransfomer�������AlignTransfomerֻ����NLP metrics,����ʹ����CE Metrics
12.Knowledge-driven encode, retrieve, paraphrase for medical image report generation
Li C Y, Liang X, Hu Z, et al. Knowledge-driven encode, retrieve, paraphrase for medical image report generation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 6666-6673.
Ҫ���ɳ�������һ�µı���������ҽѧͼ��,���ν��Ӿ�������ģʽ������ҽѧ����֪ʶ�Լ�������ʵȷ�������������پ���ս�����������һ���µ�֪ʶ�����ı��롢����������(KERP)����,�÷�������ͳ�Ļ���֪ʶ�ͼ����ķ������ִ��Ļ���ѧϰ�ķ�����Э��,��ʵ��ȷ���Ƚ���ҽѧ�������ɡ�������˵,KERP��ҽѧ�������ɷֽ�Ϊ��ȷ��ҽѧ�쳣ͼѧϰ��������Ȼ���Խ�ģ��KERP����ʹ��Encodeģ��,���Ӿ�����ת��Ϊ�ṹ�����쳣ͼ,�������ǰ��ҽѧ֪ʶ;Ȼ����Retrieveģ��,��ģ����ڼ����쳣�����ı�ģ��;���,һ������ģ��,�����ض��������дģ�塣KERP�ĺ����������ͨ��ʵ�ֵ�ԪGraph Transformer (GTR),��������֪ʶͼ��ͼ������еȶ�������ͼ�ṹ����֮�䶯̬ת�������塣ʵ�����,�÷������ɽṹ������׳�ı���,��֧��ȷ���쳣�����Ϳɽ��͵�ע������,������ҽ�Ʊ������ȡ�������Ƚ��Ľ����������ѵ�ҽѧ�쳣�ͼ������ྫ��,�����������������
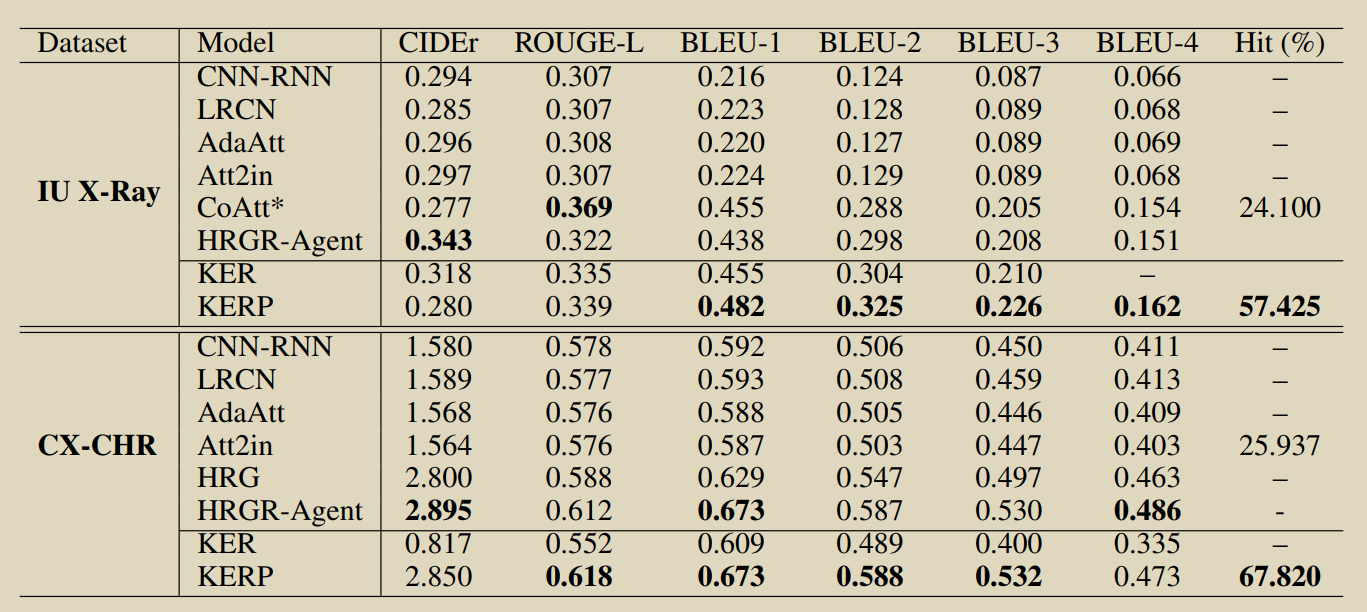
13.Generating radiology reports via memory-driven transformer
Chen Z, Song Y, Chang T H, et al. Generating radiology reports via memory-driven transformer[J]. arXiv preprint arXiv:2010.16056, 2020. [Դ��] �����ͷ��롿 �����ͽ��2��
���R2Genģ�͡�����ҽ��Ӱ����ص�,�� Transformer �Ľ���������������������(Relational Memory,RM),�Ӷ��ܹ�ʹ�� Transformer ��ģӰ�泤������Ϣ��ͬʱ,��ģ���е�ģʽ����Ϣ��
Ϊ�˽� Relational Memory ���뵽 Transformer ��,��������˻��ڼ���IJ��һ��(Memory-driven Conditional Layer Normalization,MCLN),ʹģ�ʹﵽ���õ�Ч����Ϊ�˽� Relational Memory ���뵽 Transformer ��,��������˻��ڼ���IJ��һ��(Memory-driven Conditional Layer Normalization,MCLN),ʹģ�ʹﵽ���õ�Ч����
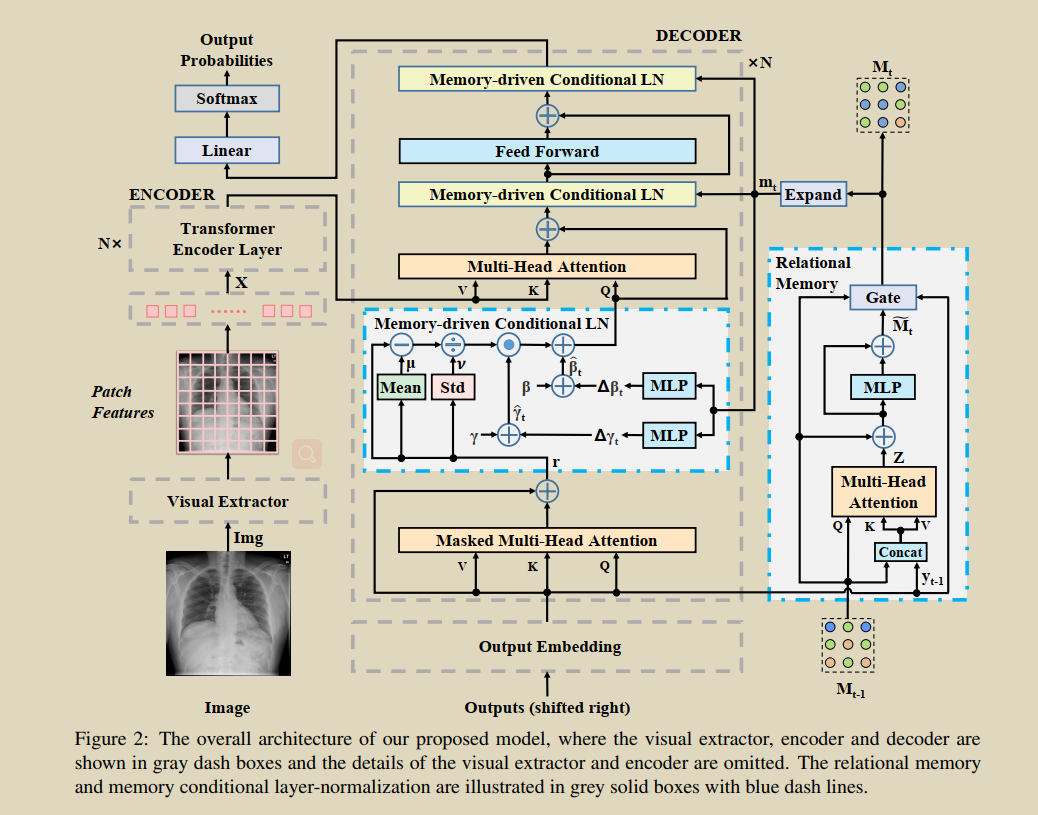
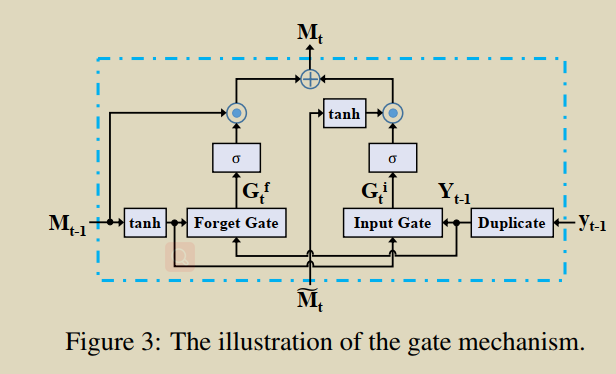
ģ�ͽṹ
ģ����ʹ�õ��DZ�����-���������,������ģ�鹹��,�ֱ����Ӿ���ȡ�����������ͽ��������Ӿ���ȡ��ʹ�õ���Ԥѵ���ľ���������,�������ͽ������ǻ��� Transformer �Ǽ�,��������Ĵ��µ��ע�ڽ���������,��������ʹ���DZ��� Transformer ��������
�Ӿ�������ʹ�õ���Ԥѵ���ľ��������硣ҽ��Ӱ���Ӿ���������õ�һ�� width x height x dim ������,����άͼ������ flatten ֮��õ�һ��(width x height) x dim������������Ϊ�����������롣֮��,��������������������������
���ڽ���������,����Ȼ���뷨��ֱ���ñ��� Transformer ������,���������߳��Ժ��ּ�ʹ�� Transformer ������ȫ������ɱ��泤�ȶ̺���������ȷ�Բ��������,���������� RelationalMemory ģ��,�Ľ��˲��һ��ģ�顣
Relational Memory ּ��ѧϰӰ���ģʽ����Ϣ,�� Relational Memory ������һ��,ʹ��Ӱ������ʱ,�� Memory ���� Transformer ��������ľ�ֵ�ͷ���,�Ӷ����������Ӱ���ģʽ����Ϣ��
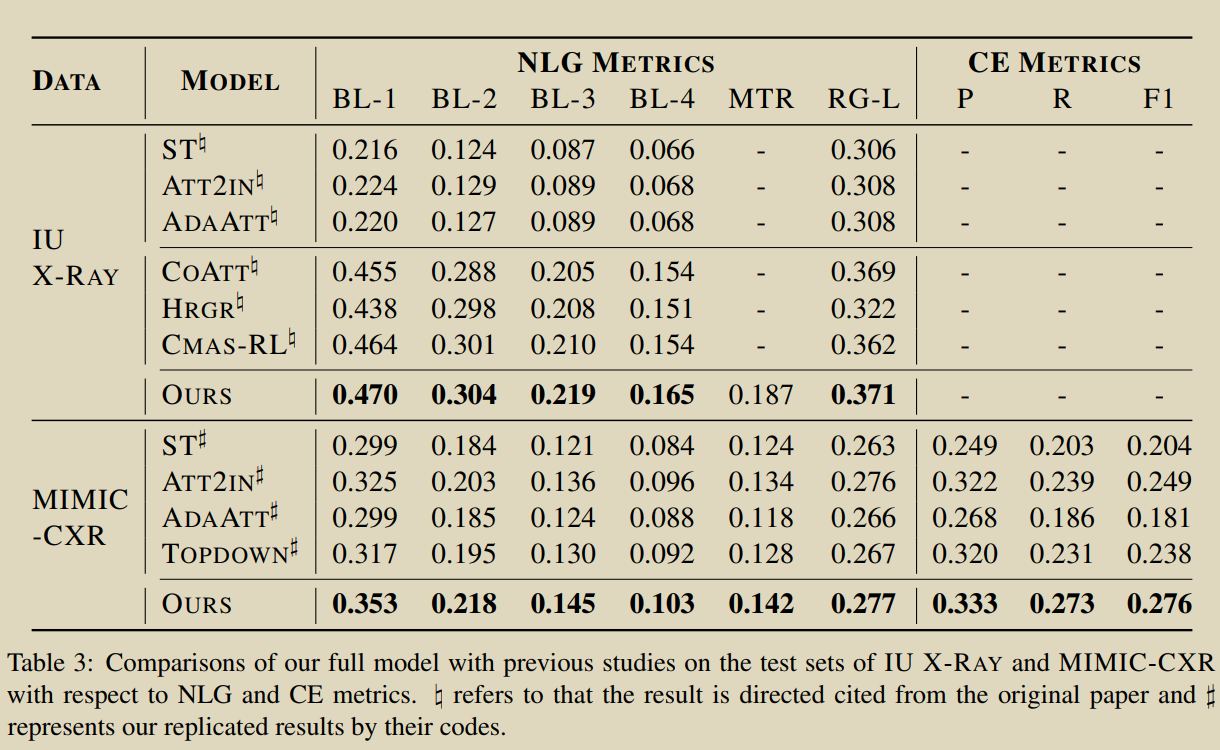
14.Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation
Yan A, He Z, Lu X, et al. Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation[J]. arXiv preprint arXiv:2109.12242, 2021.
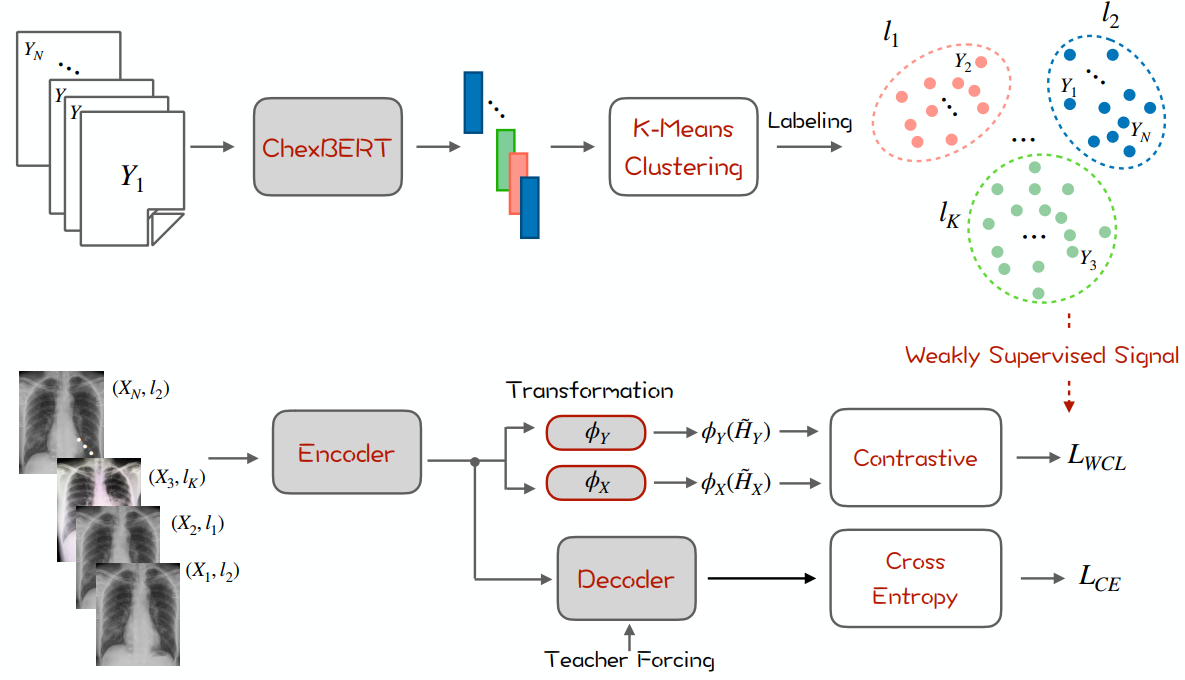
Ϊ�����������ʧ�������µ��ı���������г��ָ�Ƶ��ǻ���ӹ���Ƶ��,�ڽ�����֮������Ա�ѧϰ��ʧ,�����������ɵĶ����ԡ�
GroundTruth������ChexBERT���ɱ�ǩ,��ǩͨ�������Ϊ��,���ڶԱ���ʧ���������Ƶı������ijͷ��Ӷ����������ԡ� �� \alpha ��ȡֵΪ2��
L W C L = �� i = 1 N log ? exp ? ( s i , i ) �� l i �� l j exp ? ( s i , j ) + �� �� l i = l j exp ? ( s i , j ) \mathcal{L}_{W C L}=\sum_{i=1}^{N} \log \frac{\exp \left(s_{i, i}\right)}{\sum_{l_{i} \neq l_{j}} \exp \left(s_{i, j}\right)+\alpha \sum_{l_{i}=l_{j}} \exp \left(s_{i, j}\right)} LWCL?=��i=1N?log��li?��?=lj??exp(si,j?)+����li?=lj??exp(si,j?)exp(si,i?)?
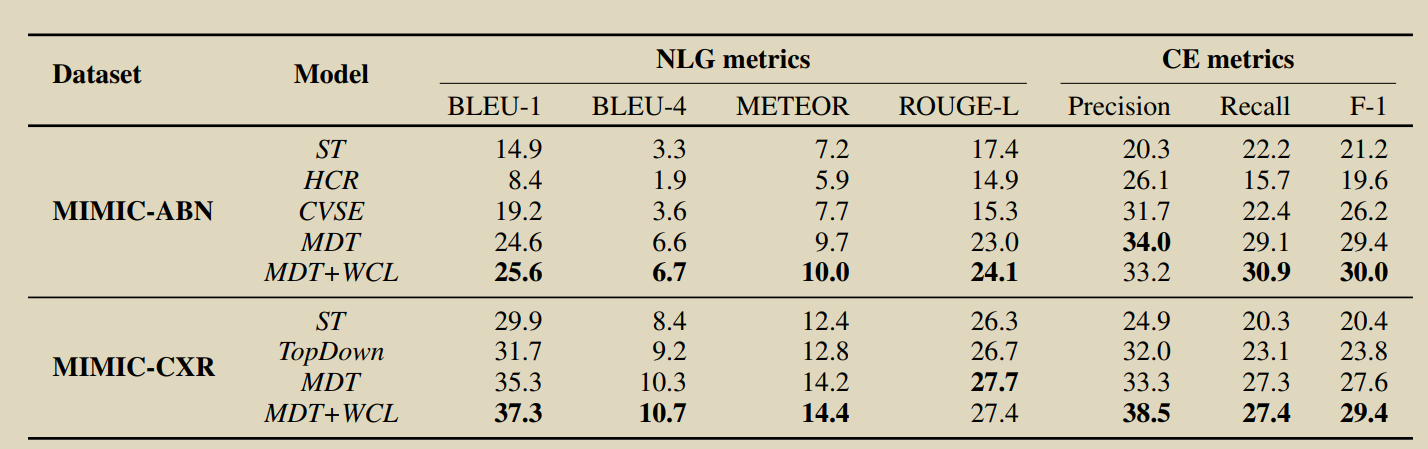
15.Automatic Generation of Chest X-ray Reports Using a Transformer-based Deep Learning Model
Amjoud A B, Amrouch M. Automatic Generation of Chest X-ray Reports Using a Transformer-based Deep Learning Model[C]//2021 Fifth International Conference On Intelligent Computing in Data Sciences (ICDS). IEEE, 2021: 1-5.
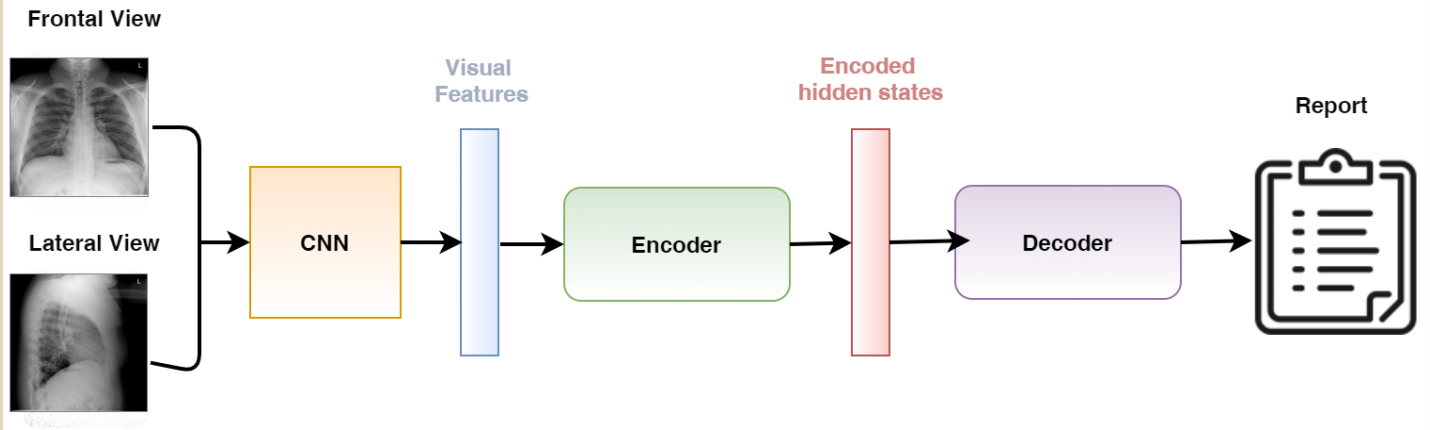
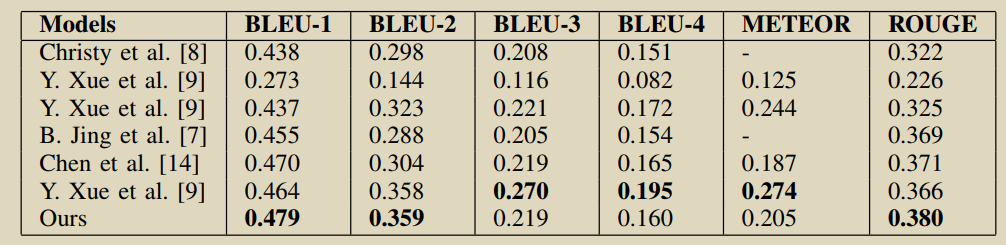
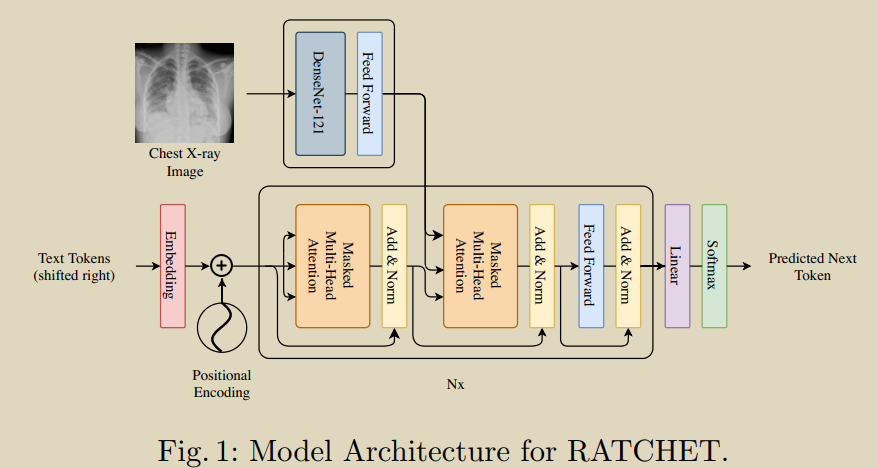
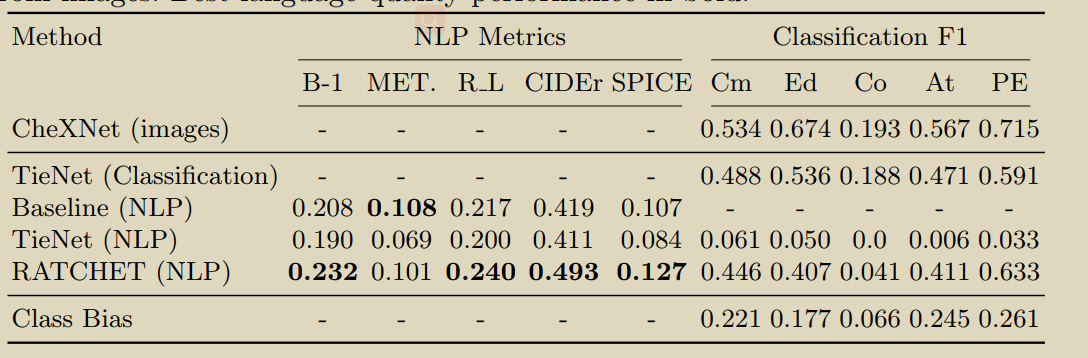
16.RATCHET: Medical Transformer for Chest X-ray Diagnosis and Reporting
Hou B, Kaissis G, Summers R M, et al. RATCHET: Medical Transformer for Chest X-ray Diagnosis and Reporting[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 293-303. [[Դ��]
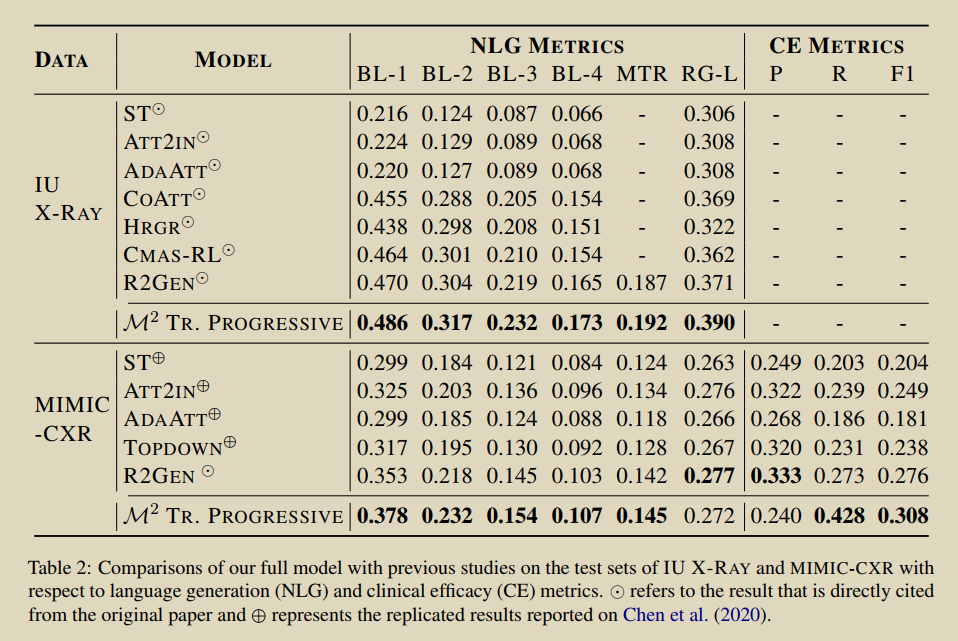
17.Progressive Transformer-Based Generation of Radiology Reports
Nooralahzadeh F, Gonzalez N P, Frauenfelder T, et al. Progressive Transformer-Based Generation of Radiology Reports[J]. arXiv preprint arXiv:2102.09777, 2021. [Դ��]
���ܿγ�ѧϰ������,�����һ��������(��,ͼ���ı����ı�)���ɿ��,����������,������ѧ��������������Ϊ�������衣��������ͼ�����������ķ���ѧ�����෴,��ģ���ڵ�һ���д�ͼ������ȫ�ָ���,Ȼ��ʹ��Transformer�ܹ�������ת��Ϊ����ϸ��һ�µ��ı���������ÿһ������ѭ����Transformer�����е����з�ʽ�����������������ݼ�(IU X-RAY ��MIMIC-CXR )�ϸĽ������µļ�����


19.Automated Generation of Accurate& Fluent Medical X-ray Reports
Nguyen H T N, Nie D, Badamdorj T, et al. Automated Generation of Accurate& Fluent Medical X-ray Reports[J]. arXiv preprint arXiv:2108.12126, 2021. [Դ��]
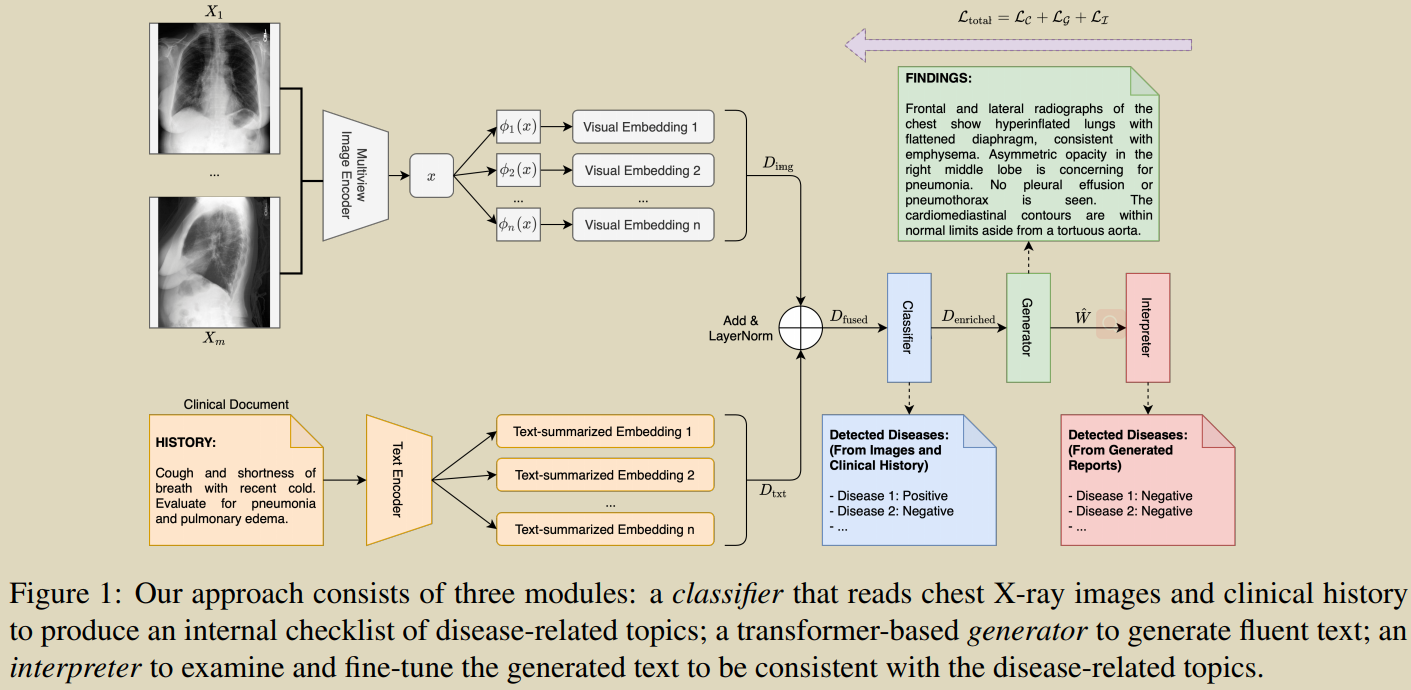
���һ������-����-���Ϳ��,�ر�ǿ���ٴ�ȷ��,ͬʱ�������ɱ�������������ԡ�
�����һ�ֿ��ֵĶ˵��˷���,��������ģ��(������������-������),���з�����ģ��ͨ�������Ľ�ģ(�ںͼ���״̬��֪����ѧϰ����������ʾ;����ģ�齫����Ƕ��ת��Ϊҽѧ����;������ģ����һ����ȫ��������ģ��,��������������������Ƽ������������嵥,�������ģ���ԭʼ������бȽ�,�Ӷ��γɷ�����·��ǿ���ɵı���ͷ����������һ���ԡ�
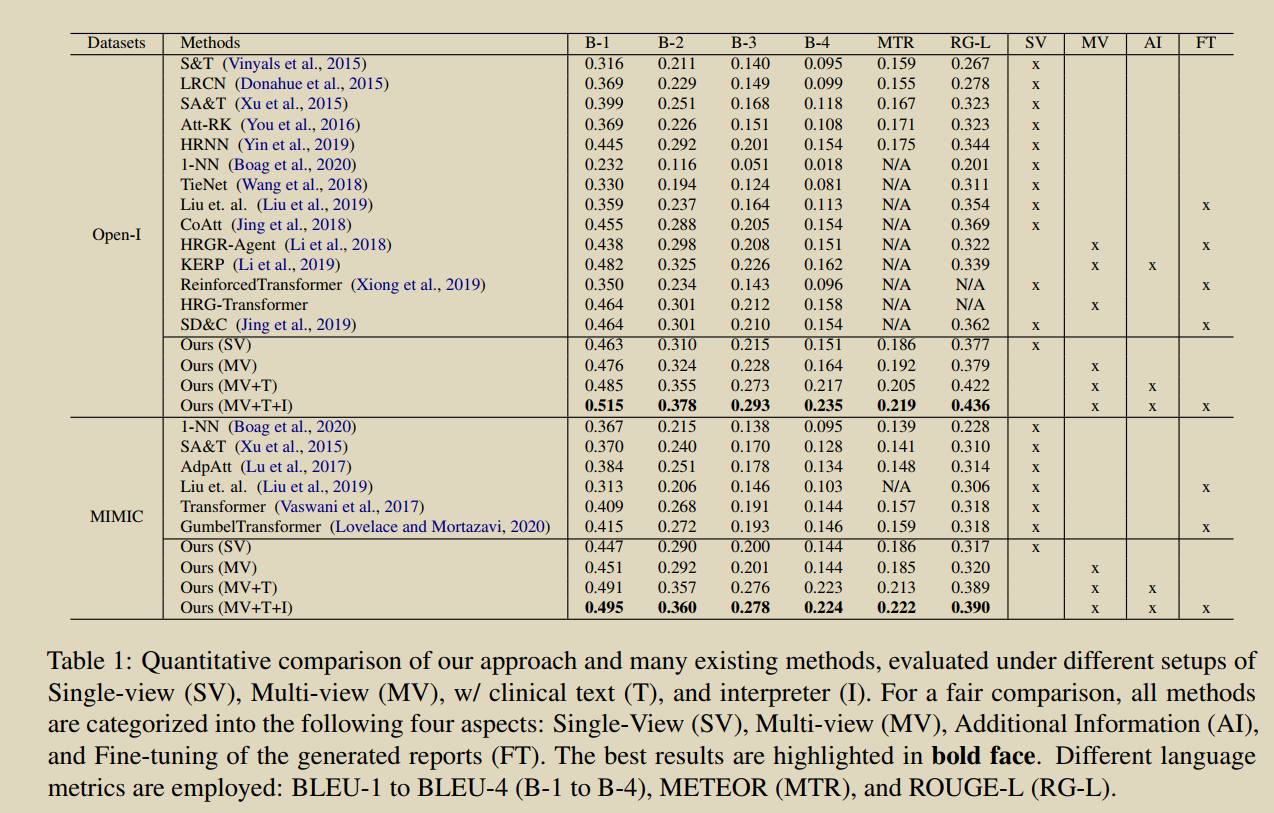
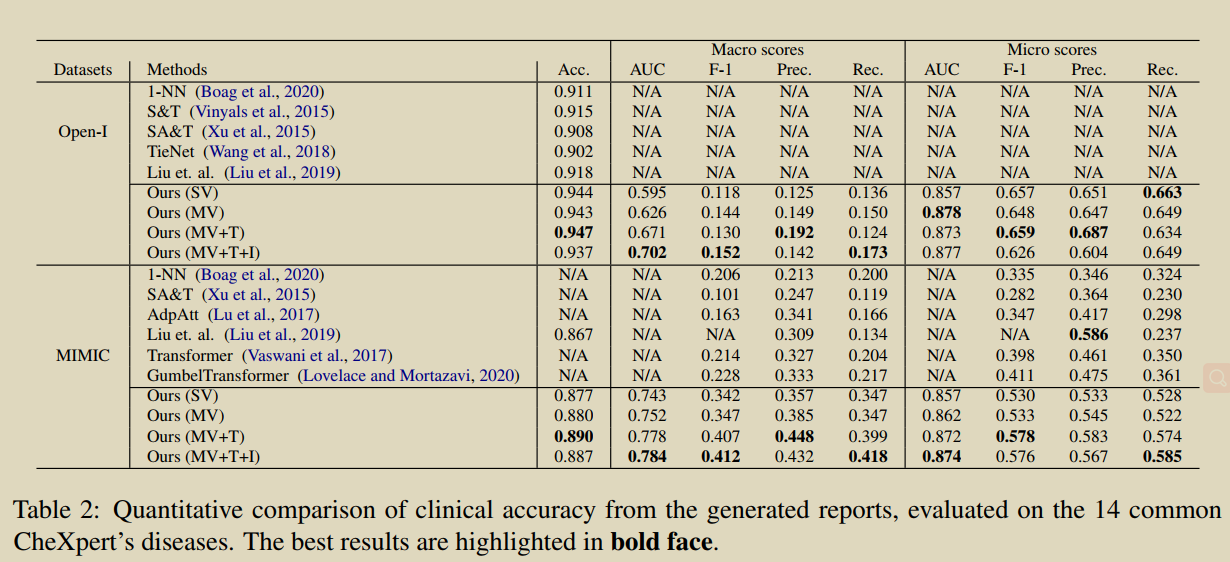
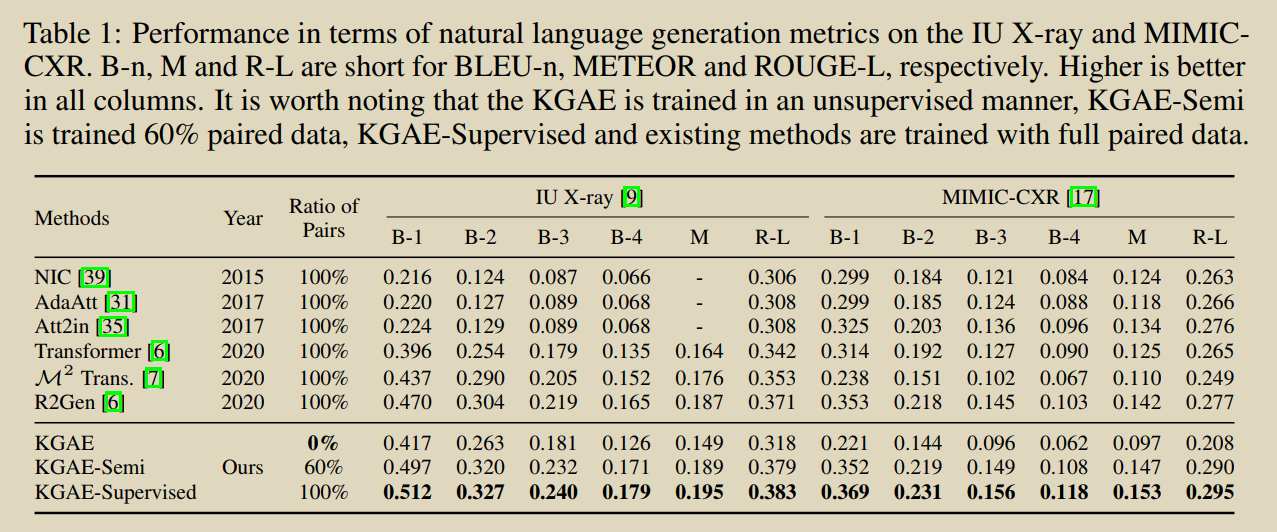
20.Auto-encoding knowledge graph for unsupervised medical report generation
Liu F, You C, Wu X, et al. Auto-encoding knowledge graph for unsupervised medical report generation[J]. Advances in Neural Information Processing Systems, 2021, 34.
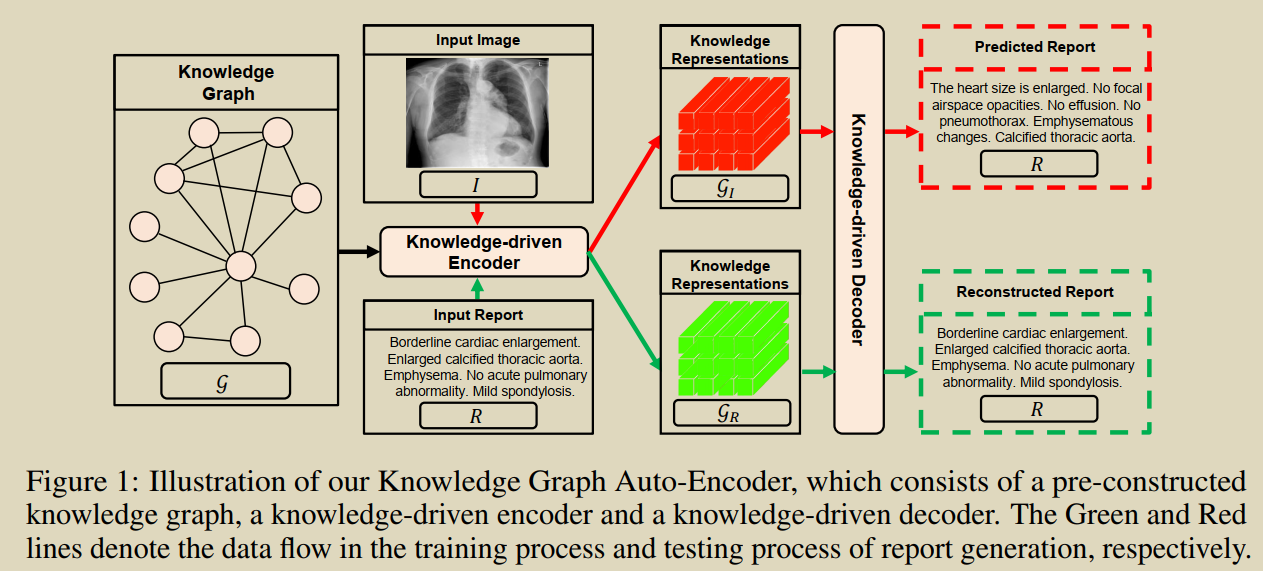
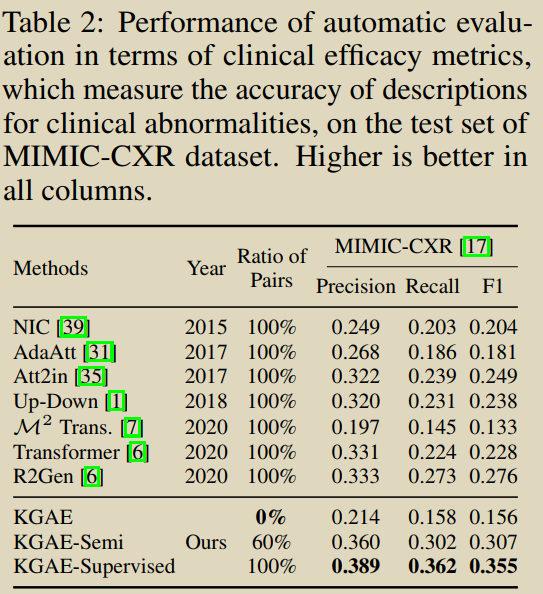
���������һ���ලģ��֪ʶͼ���Զ�������(KGAE),�����ö�����ͼ�ͱ��漯(ͼ��ͱ��漯�Ƕ�����,û���ص�)ѵ����KGAE��Ԥ�ȹ����֪ʶͼ�ס�֪ʶ�����ı�������֪ʶ�����Ľ�������ɡ���ͼ��ʾ,֪ʶͼ����Ϊͼ��ͱ���Ĺ���DZ�ڿռ䡣֪ʶ�������������Խ�ͼ�� I I I�� R R R��Ϊ��ѯ,������ͶӰ��DZ�ռ�����Ӧ������GI��GR�ϡ�����,���� G I \mathcal{G}_{I} GI?�� G R \mathcal{G}_{R} GR?��ͬһ��DZ�ռ�,��������DZ�ռ��е�λ��������ͼ��ͱ���֮��Ĺ�ϵ,�Ӷ���С���Ӿ�����ı���֮��IJ�ࡣ��֮,Ϊ����û�гɶԵ�ͼ��ͱ���ǰ����,Ϊ��С�Ӿ�������֮��IJ��,����֪ʶͼ�״���һ��DZ�ڵĿռ䡣������������ȡͼ��ͱ���֪ʶ��ʾ��ʽ,��֪ʶ��ص�ͼ��ͱ���,(ͼƬ,����֪ʶ)������ͬ��DZ�ڿռ�,��������û��ͼ�ĶԵ��������С�Ӿ�����������IJ�ࡣ������,��������֪ʶ����������,���� G I \mathcal{G}_{I} GI?�� G R \mathcal{G}_{R} GR?���ɱ��档��ѵ����,����ͨ������ G R \mathcal{G}_{R} GR?�ع����뱨�� R R R�����ƽ������IJ���,�� R �� G R �� R R \rightarrow \mathcal{G}_{R} \rightarrow R R��GR?��R;��Ԥ���,����ֱ�ӽ� G I \mathcal{G}_{I} GI?����ѵ���õĽ�����,���ɱ��档ͨ�����ַ�ʽ,���ǵķ��������ڲ�ʹ���κα�ǵ�ͼ��-����Ե��������������ı��档
�����ලģʽ��,KGAE��������ල��ල�ķ�ʽӦ�á��ڰ�ල������,KGAE��ʹ��60%��������ݼ�,���ܻ���뵱ǰ���Ƚ�ģ�;����Ľ��;�ڼල������,ͨ�������й����е�ȫ������ݼ�����ѵ��,KGAE���Էֱ���IU x���ߺ�MIMIC-CXR�������µ����Ƚ������ܡ�
21.Learning to generate clinically coherent chest X-ray reports
Lovelace J, Mortazavi B. Learning to generate clinically coherent chest X-ray reports[C]//Findings of the Association for Computational Linguistics: EMNLP 2020. 2020: 1235-1243. [Դ��]
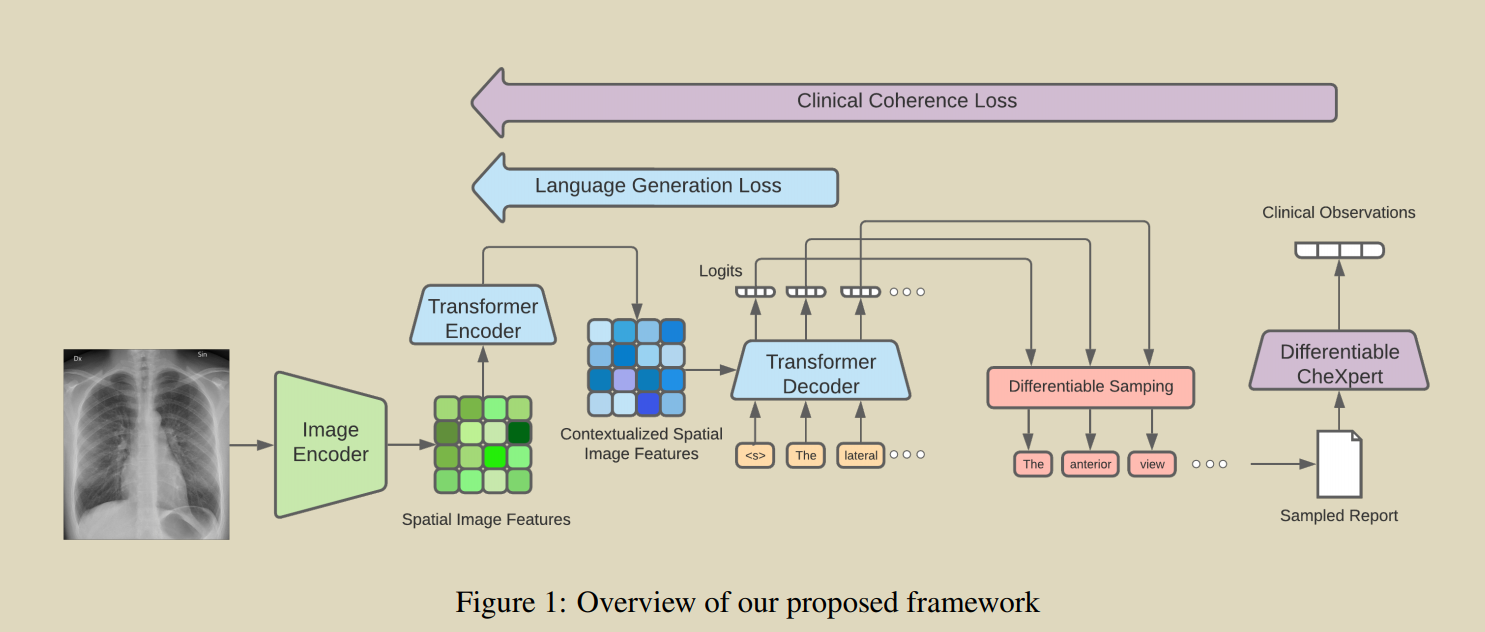
����Transfomer�ܹ��ķ���ѧ��������ģ��,��֤�����Ⱦ����Ļ��߸��������ٴ�һ�¡����ǻ�������һ�ֳ���,�����ɵı����п����ֵ���ȡ�ٴ���Ϣ,���������ֿ������Խ�һ���������ǵ��ٴ�һ����ģ��
(1)��transformerģ��Ӧ����CXR���������,��ͨ����������ָ������ɱ�����ٴ�һ������֤�������ھ����Ի��ߡ�(2)�����һ��,���ֵش����ɵı�������ȡ�ٴ���Ϣ,���������ֿ�����������һ������������ģ��,�Բ�����һ�µ��ٴ����档
Image-Encode: Pretrained DenseNet-121
Word: Word2Vec
Differentiable CheXpert :Ϊ��ֱ��ѵ��ģ�������ٴ�ȷ�ı���,�����ܹ������ɵķ���ѧ���������ֵ���ȡ�ٴ��۲�����Ȼ��,������ǩͨ����ʹ�ò������ֵĻ��ڹ���ı�ǩ���ӷ���Ʊ�������ȡ�ġ�ͨ��ѵ��һ����ģ����Ԥ������ǵ�ѵ�����еı�������CheXpert����ı�ǩ,�Ӷ�������һ��CheXpert��ǩ�Ŀ����ơ�����CNN��˫��LSTM����Ԥ�⡣
Differentiable Language Generation :utilize the Gumbel-Softmax trick[�μ����ͽ���],����Softmax��������,�ֽ���argmax��
Fine-Tuning Procedure :����NLGָ�����ɱ���,Ȼ��Gumbel-Softmax����Ӧ���ڽ������Ŀ�����������,Ȼ����CheXpertӦ���ڲ�������,�Ӷ�����ڶ���ѵ��Ŀ��,������ʵCheXpert��ǩ��ͨ�������ǵĿ�CheXpertӦ���ڲ����������õı�ǩ֮���һ���ԡ����յ�Ŀ�꺯��Ϊ���ַ�ʽ��ʧ�����ļ�Ȩ�͡�
22.Automated radiology report generation using conditioned transformers
Alfarghaly O, Khaled R, Elkorany A, et al. Automated radiology report generation using conditioned transformers[J]. Informatics in Medicine Unlocked, 2021, 24: 100557. ��Դ�롿
���IU-Xray dataset. :(1)��Ԥ��ѵ����Chexnet������,��ͼ����Ԥ���ض��ı�ǩ��(2)��Ԥ���ǩ��Ԥѵ��Ƕ���м����Ȩ����������(3)���Ӿ�������������ʹ��Ԥ��ѵ����GPT2ģ������������ҽѧ����
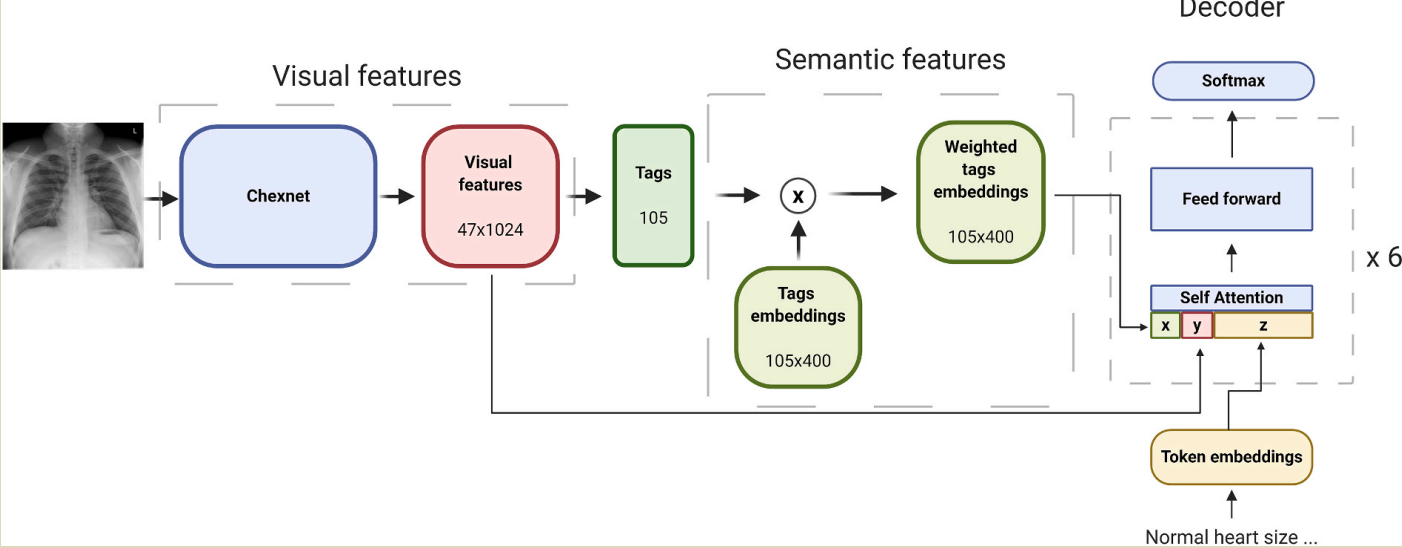
ģ����ϵ�ṹ��������Ҫ������:���ӻ�ģ�͡������������ɺͽ��������Ӿ�ģ����Ϊ������,����Ԥ����ͼ����صı�ǩ,�������Ӿ�����������������ͨ������ǩ���Ŷȷ�������Ӧ��Ԥѵ��Ƕ��ֵ���������õ����������ǻ����Ӿ������������Ļ���Transfomer(distilGPT2 )��Ԥѵ��ģ�͡�
condition Transformer: C S A ( X , Y , Z ) = softmax ? ( ( Z W q ) [ X U k Y H k Z W k ] T ) [ X U v Y H v Z W v ] C S A(X, Y, Z)=\operatorname{softmax}\left(\left(Z W_{q}\right)\left[\begin{array}{c}X U_{k} \\ Y H_{k} \\ Z W_{k}\end{array}\right]^{T}\right)\left[\begin{array}{l}X U_{v} \\ Y H_{v} \\ Z W_{v}\end{array}\right] CSA(X,Y,Z)=softmax????(ZWq?)???XUk?YHk?ZWk?????T???????XUv?YHv?ZWv?????
CSA��ʾ��������ע��,Z��ʾǶ�����������,X��ʾ��������,Y��ʾ�Ӿ�����,Uk��Hk��Uv��Hv�ֱ��ʾ�����������Ӿ��������ӵ��¼���ֵ�� �����е�condition Transformer���������Encoder-agnostic adaptation for conditional language generation
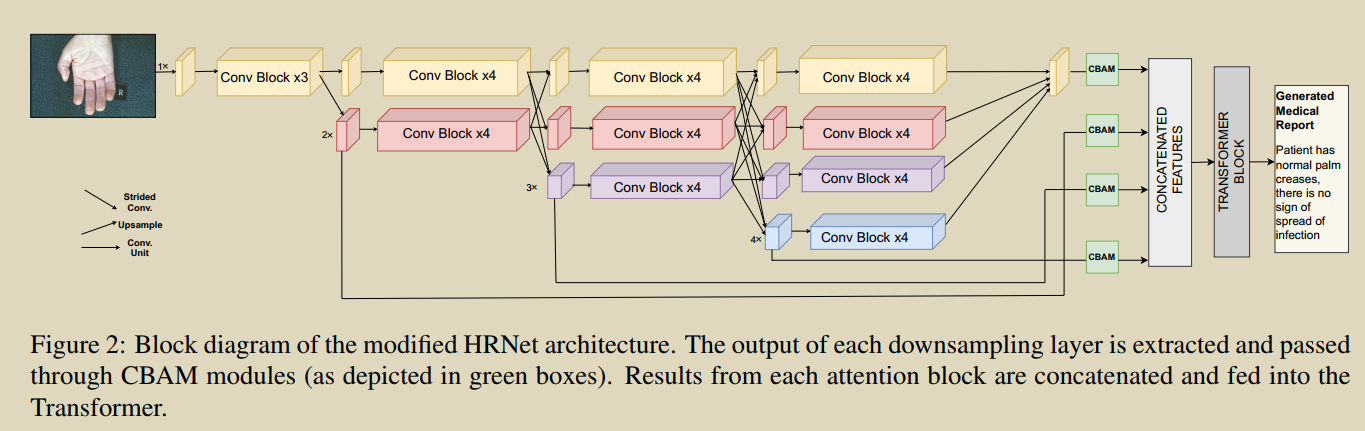
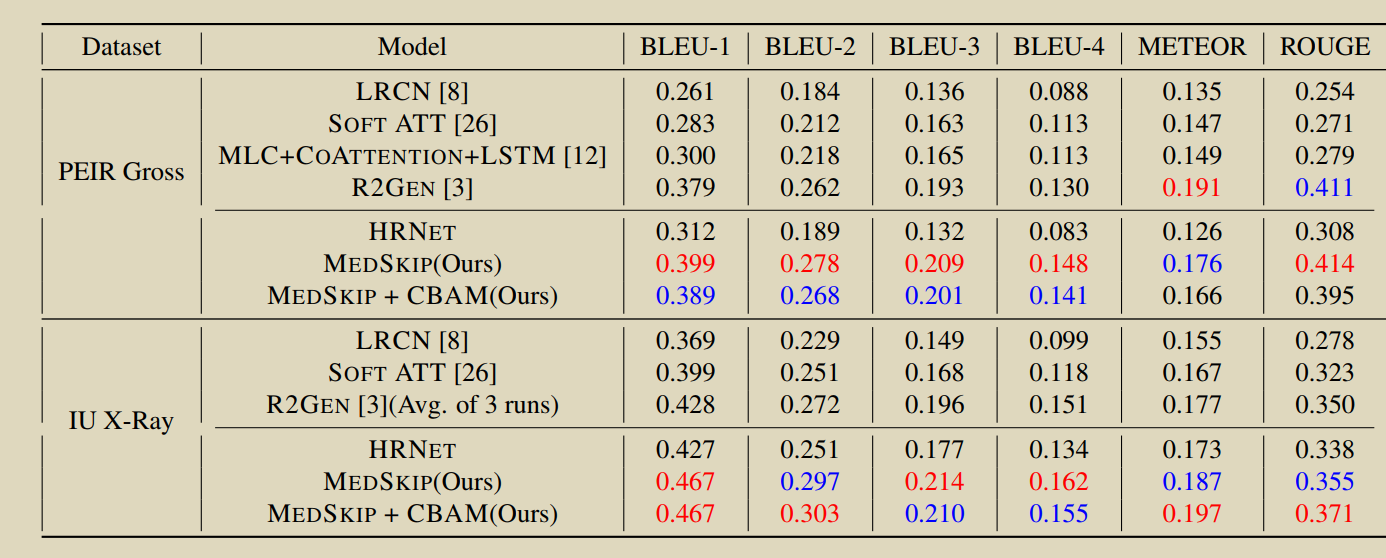
23. Medskip: Medical report generation using skip connections and integrated attention
Pahwa E, Mehta D, Kapadia S, et al. Medskip: Medical report generation using skip connections and integrated attention[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3409-3415.
�����ӱ���Ӿ���ȡ��MEDSKIP,��skip���Ӻ;�����ע��ģ����HRNet�������,�����Memory Transformer������ҽ�Ʊ��档
24.Big self-supervised models advance medical image classification
Azizi S, Mustafa B, Ryan F, et al. Big self-supervised models advance medical image classification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3478-3488.

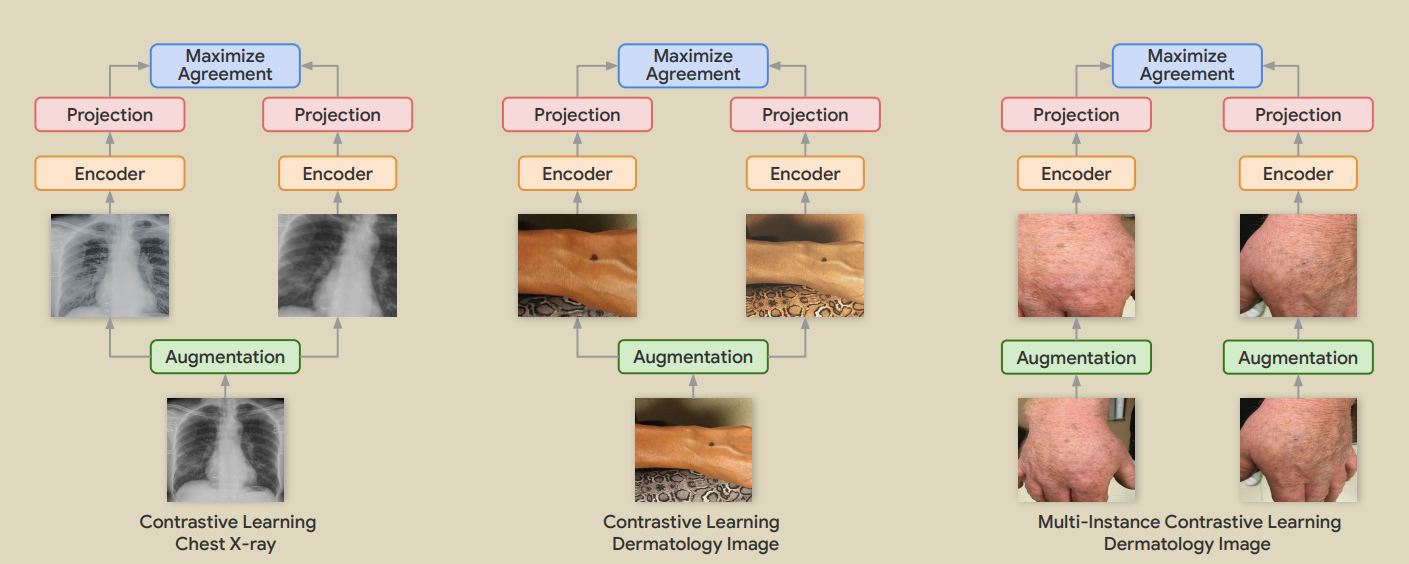
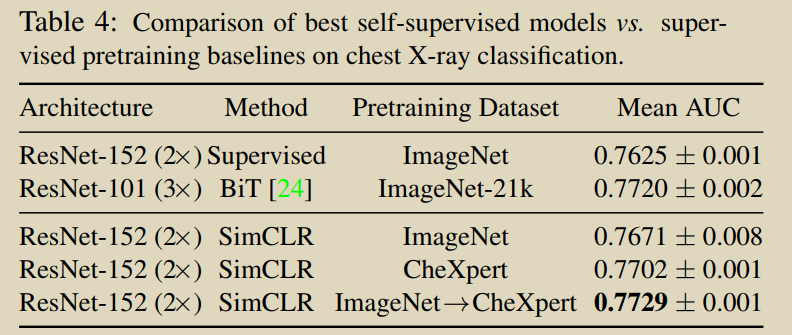
���ޱ�ǩҽѧͼ���Ͻ��е��ԼලԤѵ���������ڱ�ImageNetԤѵ���������ʼ��ѵ��������˶�ʵ���Ա�ѧϰ(MICLe)��Ϊ���жԱ�ѧϰ������һ������,������ÿ��ҽ�������Ķ��ͼ��MICLe������Լලģ�͵�����,���������Ƚ��Ľ��������Ƭ������,�Լලѧϰ��ƽ��AUC����ImageNet��Ԥѵ����ǿ�ල���ߵ�ƽ��AUCҪ�߳�1.1%����ImageNet ��CheXpert������Ԥѵ����Ч���ȵ��������������ݼ���Ԥѵ��Ҫ�á�
25.Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation
Vu Y N T, Wang R, Balachandar N, et al. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation[C]//Machine Learning for Healthcare Conference. PMLR, 2021: 755-769.
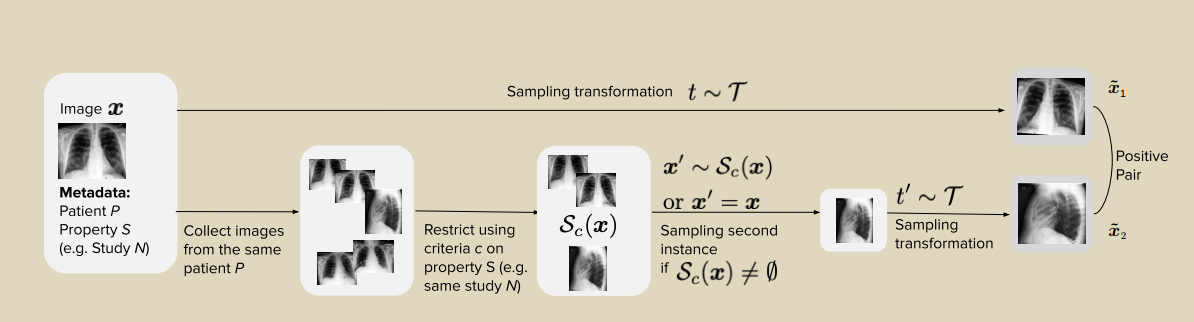
(1)������һ�ַ���MedAug,ʹ�û���Ԫ����(���ڻ��ߡ��о���ͼ��IJ��Եľ�����Ϣ)�ڶԱ�ѧϰ��ѡ��positive pair,�����÷���Ӧ�����ز�x��Ƭ,������ǻ��Һ�������������,ʹ��������ͬ��ͼ����Ϊ�Ա�ѧϰ������,��ֻʹ��ͬһͼ���������ǿ���ṩ���õ�Ԥѵ�����������,����ҽѧӰ��ĶԱ�ѧϰ��������ͨ��ʹ�û���Ԫ��������չ���ԵĹ��������档(2)��ImageNetԤѵ���Ļ������,��������Ԥѵ��������ƽ��AUC��������������14.4%,�����ʹ�û���Ԫ���ݴӶ��ͼ����ѡ��positive pair�����������Ʊ�����(3)�Ա�ǩ��Ϣ�����˱Ƚ�ʵ֤����,�������:(A)ʹ��������ͬ���ߵ����Բ�ͬͼ��,��Щͼ�������ͬ��DZ�ڲ���,������Ԥ��ѵ���ı���,(2)����ÿ��ͼ���ѯ��ѡ���γ����ԵIJ�ͬͼ�������,�����Ԥѵ����ʾ������.(4)��ʹ�û���Ԫ����ѡ�������ԵIJ��Խ�����̽���Է���,û�з����벻ʹ��Ԫ���ݵ�Ĭ�ϲ��������ʲô�Ľ�
26.Learning visual-semantic embeddings for reporting abnormal findings on chest x-rays
Ni J, Hsu C N, Gentili A, et al. Learning visual-semantic embeddings for reporting abnormal findings on chest x-rays[J]. arXiv preprint arXiv:2010.02467, 2020. [Դ��]
�Զ�����ҽѧͼ�������������ҽ������������DZ�����ܵ�Խ��Խ��Ĺ�ע�����еı������ɹ�������ѵ��������-�������������������ı��档Ȼ��,��Щģ���ܵ�����ƫ��(���ǩ��ƽ��)��Ӱ��,�������ı�����ģ���еĹ�ͬ����(���ظ�)�����������,���ǵ��ص��DZ����쳣���ֵķ���ͼ��;���������һ�ַ���,�������ල�ľ������С����Ա�����з�����,�����Դӱ�����ʶ���쳣���,�����Ƕ������ķ���ѧ���������ѵ�����ǽ���������Ϊ��ģ̬����,����������Ӿ�����Ƕ�뷽��,��������Ƕ��ռ��ж���ͼ���ϸ�����쳣���֡�����֤�������ǵķ����ܹ������쳣���,�������ٴ���ȷ�Ժ��ı����ɶ������������е�����ģ�͡�
27.Chexbert: combining automatic labelers and expert
annotations for accurate radiology report labeling using bert
Smit A, Jain S, Rajpurkar P, et al. CheXbert: combining automatic labelers and expert annotations for accurate radiology report labeling using BERT[J]. arXiv preprint arXiv:2004.09167, 2020.��Դ�롿
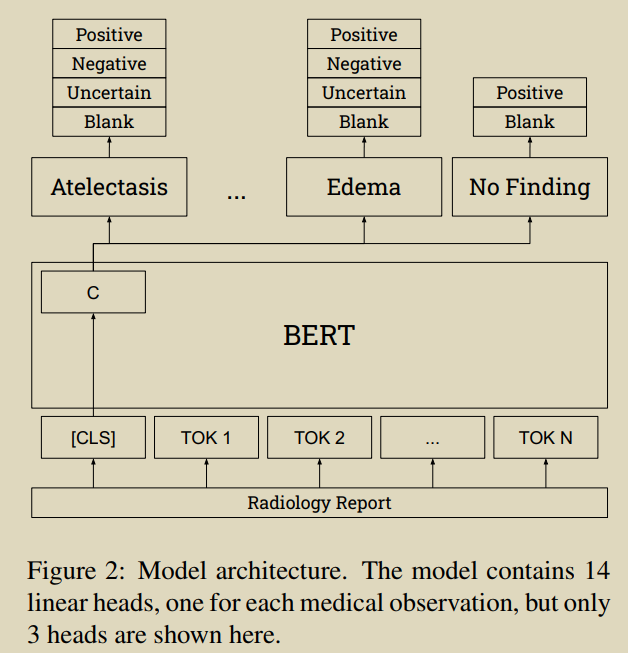
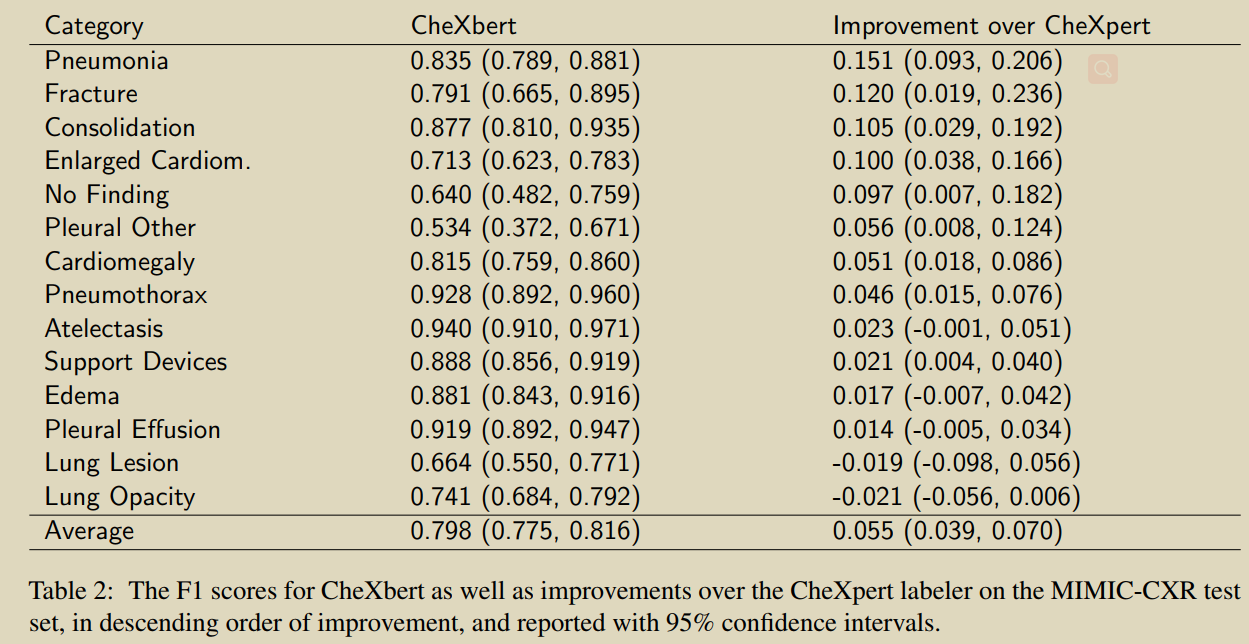
������һ�ֻ���BERT�ķ��������ҽѧͼ��,�÷��������˿��õĻ��ڹ����ϵͳ��ר�ұ�ע����������MIMIC-CXR ����˱�ע��
�ȴ�����ҽѧ��Ԥ��ѵ����BERTģ�Ϳ�ʼ(Devlin����,2019;Peng����,2019��)�����б�ע�������������ѵ,����ʹ���Զ���������ǿ��ר�ұ�ע��С���Ͽ���н�һ�������������ַ���Ӧ�����ز�x��
28.Encoder-agnostic adaptation for conditional language generation
Ziegler Z M, Melas-Kyriazi L, Gehrmann S, et al. Encoder-agnostic adaptation for conditional language generation[J]. arXiv preprint arXiv:1908.06938, 2019. [Դ��]
̽���˸���Ԥѵ������ģ��ʹ�����ܹ���������encoder����ķ���

��ɫ��ʾ������ʼ��ʹ��Ԥѵ����Ȩֵ,��ɫ��ʾ�����ʼ������ɫ������ʾÿһ���Ŀ�꼤��,��ɫ������ʾ�������������Դ��������������IMAGE PARAGRAPH CAPTIONING ����(Caption�ǵ�������Ƭ��,��Ҫģ��������������)
29.Self-supervised learning for cardiac MR image segmentation by anatomical position prediction
Bai W, Chen C, Tarroni G, et al. Self-supervised learning for cardiac mr image segmentation by anatomical position prediction[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2019: 541-549.
���һ������Ԥ����ʽṹΪ����������Լල����ѧϰ������������MR�ָ
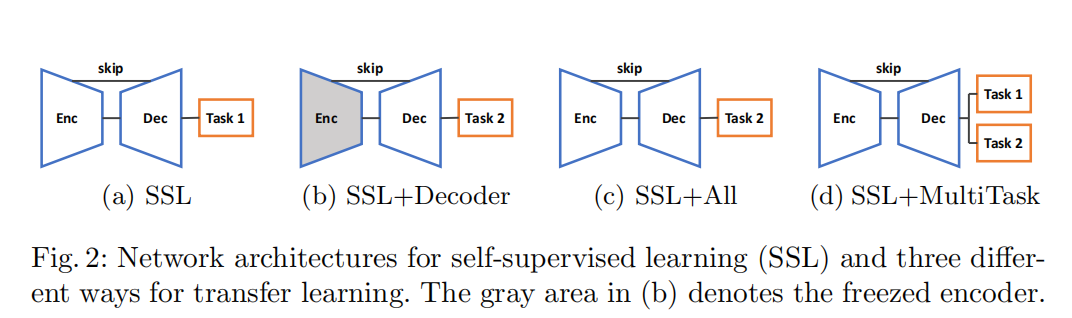
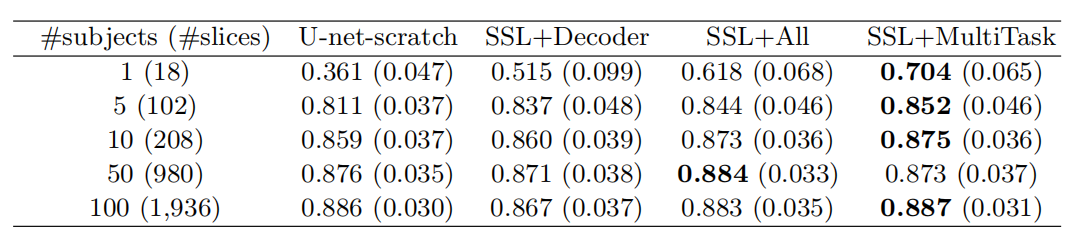
31.Rubik��s cube+: A self-supervised feature learning framework for 3d medical image analysis
Zhu J, Li Y, Hu Y, et al. Rubik��s cube+: A self-supervised feature learning framework for 3d medical image analysis[J]. Medical image analysis, 2020, 64: 101746.
32.Contrastive learning of global and local features for medical image segmentation with limited annotations
Chaitanya K, Erdil E, Karani N, et al. Contrastive learning of global and local features for medical image segmentation with limited annotations[J]. Advances in Neural Information Processing Systems, 2020, 33: 12546-12558. [Դ��] ��CSDN���ͷ��롿
��������IJ���ͨ����չ�Ա�ѧϰ�������������Ϊ����(��ע������)��ҽѧ��ע������,���ð�ලѧϰ������άҽѧͼ��ָ������˵:�������һ��ȫ�µĶԱ�ѧϰ����,ͨ��������άҽѧͼ��(�ض�����)�Ľṹ������;�������һ�־ֲ��Ա���ʧ��ѧϰ���صľֲ���������,�������ؼ�ͼ��ָ�(�ض�����)��������������������Ӧ�ø÷���������ҽѧ���ݼ��Ͻ�����ʵ����֤,ʵ���趨ʹ�ý�Ϊ���ı�ע�����Ͻ���ѵ��(��ѵ�����Ĵ�С),����������Լල�Ͱ�ලѧϰ�������,�÷����Էָ������д����������
introduction
���ܶԱ�ѧϰ��ȡ�ò����ijɼ�,���������е��������߷�����������Ҫ����δ���������̽�����о�������,�������о������۽�����ģ����ȡȫ����������,����������ȷ��ѧϰÿ���ֲ�����Ķ������������Ҳ��������Ϊ���ܶ����ؼ�ͼ��ָ�����ĵط������,�Ա�ѧϰ�IJ���������ʹ��������ǿ,(��ǰ���ᵽ��ͬһͼ����в�ͬͼ��任Ҳ���Dz�ͬ��������ǿ����,ͬһԭʼͼ�任���֮���������������,��ͬͼ��֮����������ﲻͬ),��û���õ���ͬ����֮���������(ע��:����ΪʲôҪ��ǰ��ժҪ�о�������ض�����domain-specific cue ���ض����� problem-specific cues����ΪMRI/CT����ά����,ÿ������֮���Ǵ��������Ե�,����Ȼ������ͼ��һ���Dz���������������)�����������������ض��������ݽṹ(��ά����,�����Ͼ��Ƕ����ά����������ά���ϵĶѵ�),ͨ�����ݽṹ֮���������ϵ,�Ի�ȡ��ȴ�ͳ��������Դ����������ǿ��ʽ���������������
Method
ʹ�ñ�������ȡȫ�ֱ�ʾ,ʹ�ý���������ȡ�����ľֲ���ʾ
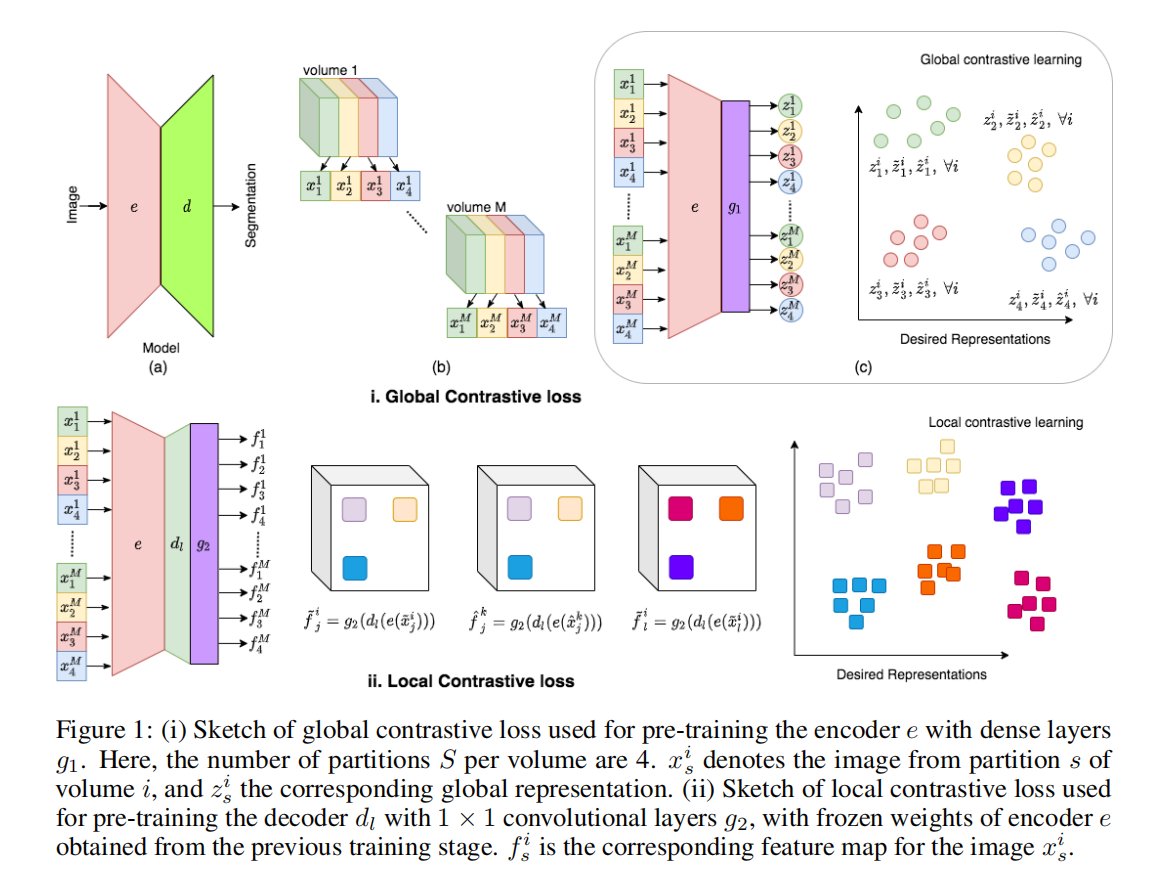
1.ȫ�ֶԱ���ʧ
���ڸ�����һ�����Ƶ�ͼ��
l ( x ~ , x ^ ) = ? log ? e sim ? ( z ~ , z ^ ) / �� e sim ? ( z ~ , z ^ ) / �� + �� x �� �� �� ? e sim ? ( z ~ , g 1 ( e ( x �� ) ) ) / �� , z ~ = g 1 ( e ( x ~ ) ) , z ^ = g 1 ( e ( x ^ ) ) l(\tilde{x}, \hat{x})=-\log \frac{e^{\operatorname{sim}(\tilde{z}, \hat{z}) / \tau}}{e^{\operatorname{sim}(\tilde{z}, \hat{z}) / \tau}+\sum_{\bar{x} \in \Lambda^{-}} e^{\operatorname{sim}\left(\tilde{z}, g_{1}(e(\bar{x}))\right) / \tau}}, \tilde{z}=g_{1}(e(\tilde{x})), \hat{z}=g_{1}(e(\hat{x})) l(x~,x^)=?logesim(z~,z^)/��+��x������??esim(z~,g1?(e(x��)))/��esim(z~,z^)/��?,z~=g1?(e(x~)),z^=g1?(e(x^))
ȫ�ֶԱ���ʧ: L g = 1 �O �� + �O �� ? ( x ~ , x ^ ) �� �� + [ l ( x ~ , x ^ ) + l ( x ^ , x ~ ) ] L_{g}=\frac{1}{\left|\Lambda^{+}\right|} \sum_{\forall(\tilde{x}, \hat{x}) \in \Lambda^{+}}[l(\tilde{x}, \hat{x})+l(\hat{x}, \tilde{x})] Lg?=�O��+�O1?��?(x~,x^)����+?[l(x~,x^)+l(x^,x~)]
2.�ֲ��Ա���ʧ
l ( x ~ , x ^ , u , v ) = ? log ? e sim ? ( f ~ ( u , v ) , f ^ ( u , v ) ) / �� e sim ? ( f ~ ( u , v ) , f ^ ( u , v ) ) / �� + �� ( u �� , v �� ) �� �� ? e sim ? ( f ~ ( u , v ) , f ^ ( u �� , v �� ) ) / �� l(\tilde{x}, \hat{x}, u, v)=-\log \frac{e^{\operatorname{sim}(\tilde{f}(u, v), \hat{f}(u, v)) / \tau}}{e^{\operatorname{sim}(\tilde{f}(u, v), \hat{f}(u, v)) / \tau}+\sum_{\left(u^{\prime}, v^{\prime}\right) \in \Omega^{-}} e^{\operatorname{sim}\left(\tilde{f}(u, v), \hat{f}\left(u^{\prime}, v^{\prime}\right)\right) / \tau}} l(x~,x^,u,v)=?logesim(f~?(u,v),f^?(u,v))/��+��(u��,v��)����??esim(f~?(u,v),f^?(u��,v��))/��esim(f~?(u,v),f^?(u,v))/��?
3.ѵ��
����ʹ��ȫ�ֶԱ���ʧѵ��Encoder(��Ҫ����һ��ȫ���Ӳ� g 1 g1 g1),Ȼ��̻� E n c o d e r Encoder Encoder����,���þֲ��Ա���ʧѵ�� D e o c d e r Deocder Deocder�ĵ�1������L��(��Ҫ����һ��ȫ���Ӳ� g 2 g2 g2)�����ȫ D e c o d e r Decoder Decoder��������,�ò��ֲ�������������г�ʼ��,�����ñ�ע���ݽ�����,�������ģ�͵�ѵ����
33.Sample-efficient deep learning for COVID-19 diagnosis based on CT scans
He X. Sample-efficient deep learning for COVID-19 diagnosis based on CT scans[J]. IEEE transactions on medical imaging, 2020. ��Դ�롿
1.����һ�����������ݼ�,���а������ٴ�Covid-19���Ե�CTɨ��(��216��covid-19������,�����ٴ����ֵ�349��CTͼ��)
2.����˲�ͬ��Ǩ��ѧϰ����,���������ۺ��о�,�Ե���Ǩ��ѧϰ��covid-19��ϵ�Ӱ�졣
domain difference in data:ImageNet�� Lung Nodule Maligancy
neural architectures:VGG16 ,ResNet18, ResNet50, DenseNet-121 , DenseNet-169 , EffificientNet-b0 , and EffificientNet-b1 .
light-weight architecture: CRNet
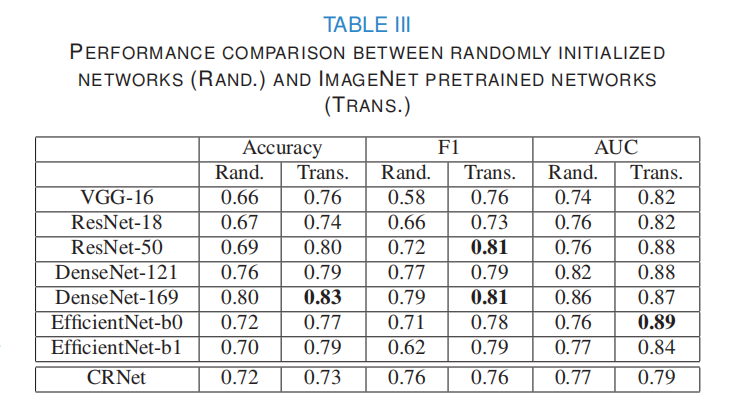
3.Ϊ�˴����ı��������ѧϰ,����� Self-Trans����,�����罫�Ա��Լලѧϰ��Ǩ��ѧϰЭͬ����,��ѧϰǿ�����ƫ������ʾ,�Լ��ٹ���ϵķ��ա�
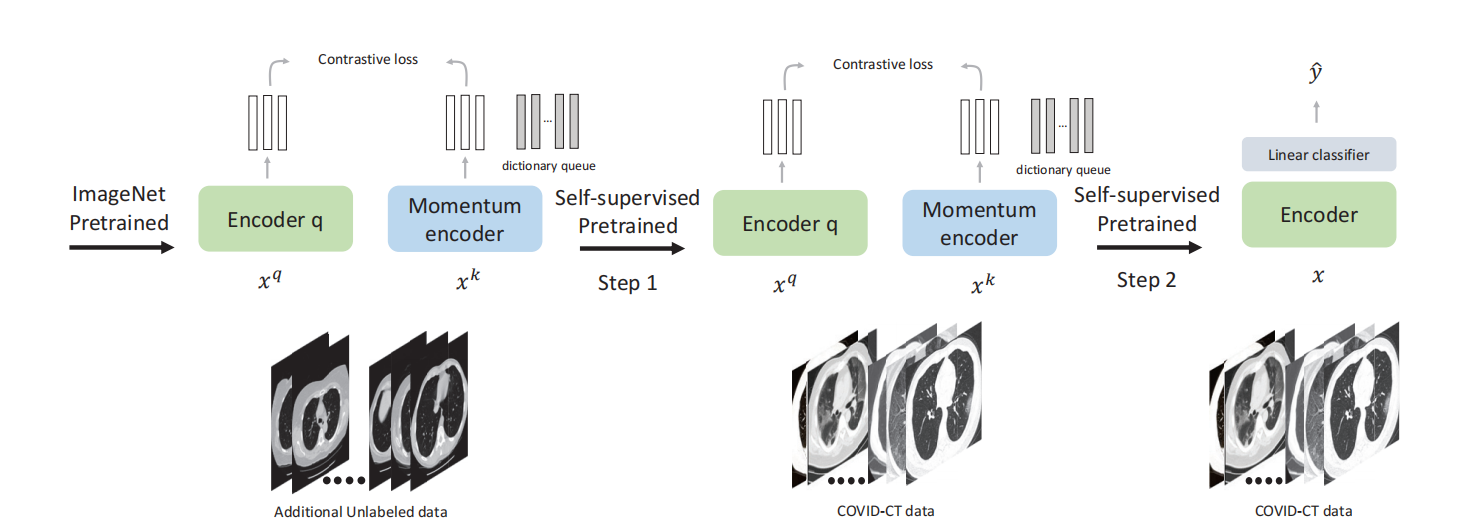
4.��COVID19-CT���ݼ���,F1�÷�Ϊ0.85,AUCΪ0.94,ȷ��Ϊ0.86��
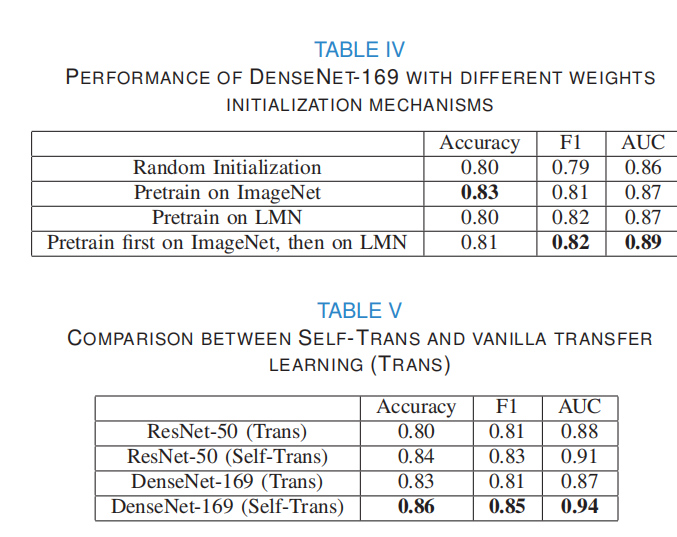
34.Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations
Zhou H Y, Yu S, Bian C, et al. Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2020: 398-407. [֪�����] ��Դ�롿
�����һ��ȫ�µĻ��ڶ�����teacher-student�ԼලԤѵ������C2L(Compare to Learn)���˷���ּ�����ô���(70��X������ ChestX-ray14��MIMIC-CXR��CheXpert�� MURA)��δ��ע��X��ͼ��Ԥѵ��һ��2D���ѧϰģ��,���Batch mixup �� feature mixup�ʹ洢��ǰepoch����ȡ��feature��memory queue,ʹ��ģ���ܹ����мල��Ϣ��������,ͨ���ԱȲ�ͬͼ�������IJ���,��ȡͨ�õ�ͼ����
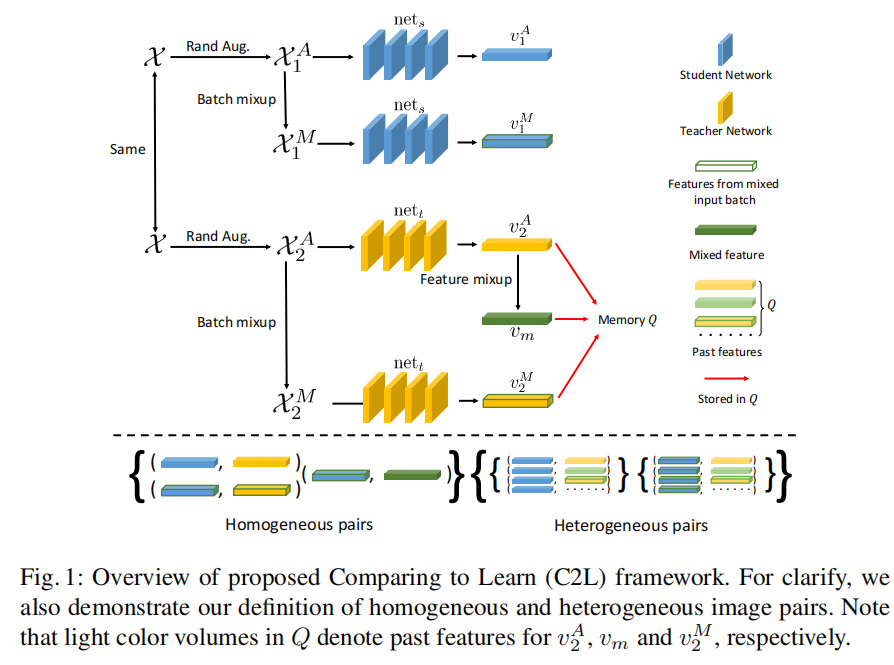

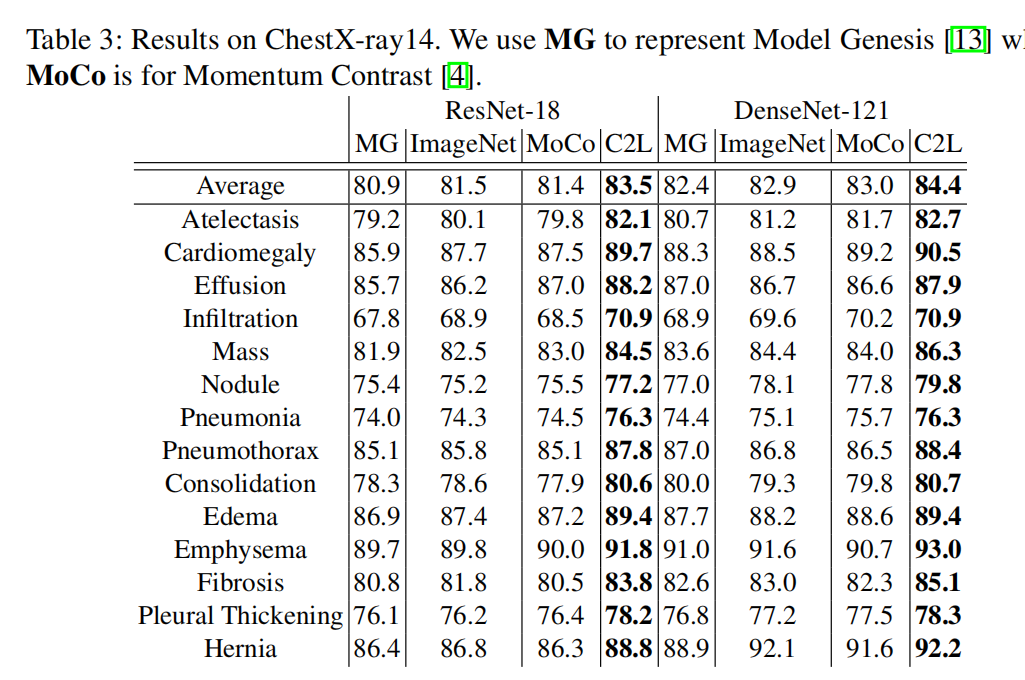
35.Moco pretraining improves representation and transferability of chest x-ray models
Sowrirajan H, Yang J, Ng A Y, et al. Moco pretraining improves representation and transferability of chest x-ray models[C]//Medical Imaging with Deep Learning. PMLR, 2021: 728-744. [Դ��]
�������MoCo��MoCo-CXR��

37.Semi-supervised medical image classification with relation-driven self-ensembling mode
Liu Q, Yu L, Luo L, et al. Semi-supervised medical image classification with relation-driven self-ensembling model[J]. IEEE transactions on medical imaging, 2020, 39(11): 3429-3440.
��ල,��ʵ��,��Ǩ��ѧϰ��ҽѧ����,��������ϻ�ָ������Ͻ�������( 2018��ǰ)��
38.Focalmix: Semi-supervised learning for 3d medical image detection
Wang D, Zhang Y, Zhang K, et al. Focalmix: Semi-supervised learning for 3d medical image detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 3951-3960. [���ͽ��]
39.Contrastive learning of medical visual representations from paired images and text
Zhang Y, Jiang H, Miura Y, et al. Contrastive learning of medical visual representations from paired images and text[J]. arXiv preprint arXiv:2010.00747, 2020.
���Contrastive VIsual Representation Learning from Text (ConVIRT):ͨ����ͼ����ı�ģʽ֮���˫��Ա�Ŀ��,����ȵ������ʵͼ��-�ı����������֮���һ����,�Ӷ������Ӿ���ʾ����ҽѧͼ����ࡢͼ���ȡ�����϶Ա�ѧϰ��úܺõ����ܡ� [Pytorch����] [Connected Papers]
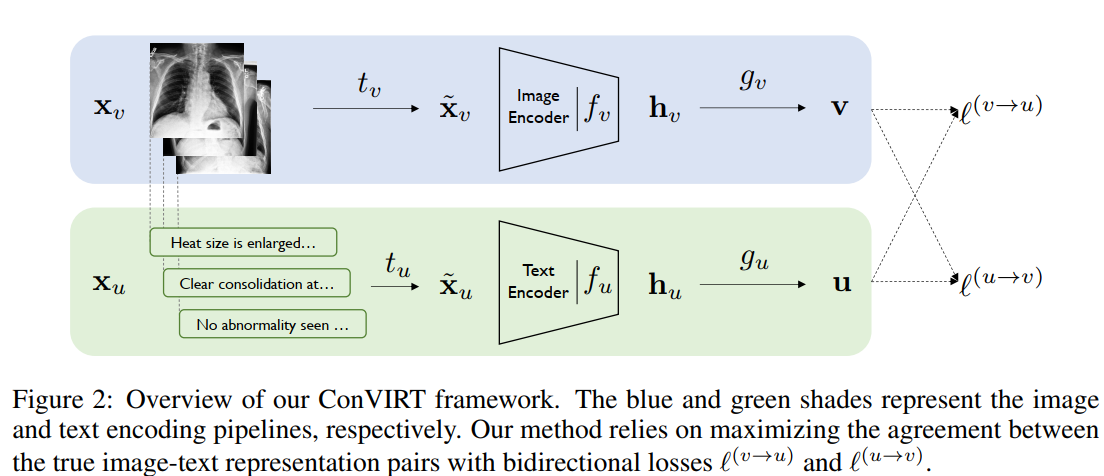
41.Trust It or Not: Confidence-Guided Automatic Radiology Report Generation
Wang Y, Lin Z, Tian J, et al. Confidence-Guided Radiology Report Generation[J]. arXiv preprint arXiv:2106.10887, 2021.
���һ�������������ɵ����߱��治ȷ���ŵĿ��Ŷȶ���������
��Ʒ���,���Ӿ����ı�����,��ȷ��������Ʊ��������ģ�͵IJ�ȷ���ԡ����ֶ�ģ̬��ȷ���Զ������Գ�ֲ���;��Ӽ����ģ�����ŷ���,��һ��������Щ������������ʧ,��ʵ�ָ�ȫ���ģ���Ż���
ҽѧ�������ɵIJ�ȷ���Ե���ԭ��:����,�Ӳ���ֵ�������ѧϰ���ܵ��²��ɿ���ģ��,�Ӷ��������ɲ�ȷ�ı��档���,���е�����ָ���������������NLP������Ƶ�,�Ѿ���֤�����ʺϴ�ҽѧͼ�����ɷ���ѧ���������һЩ��ͳ������,��ͼ�����������ѡ�����ٴ�����ȱ��������ͼ��������ơ�ȱ���ȶ�����ϱ���,���ܻ�Ӱ����ϱ���IJ�ȷ����,�Ӷ�Ӱ���ٴ������
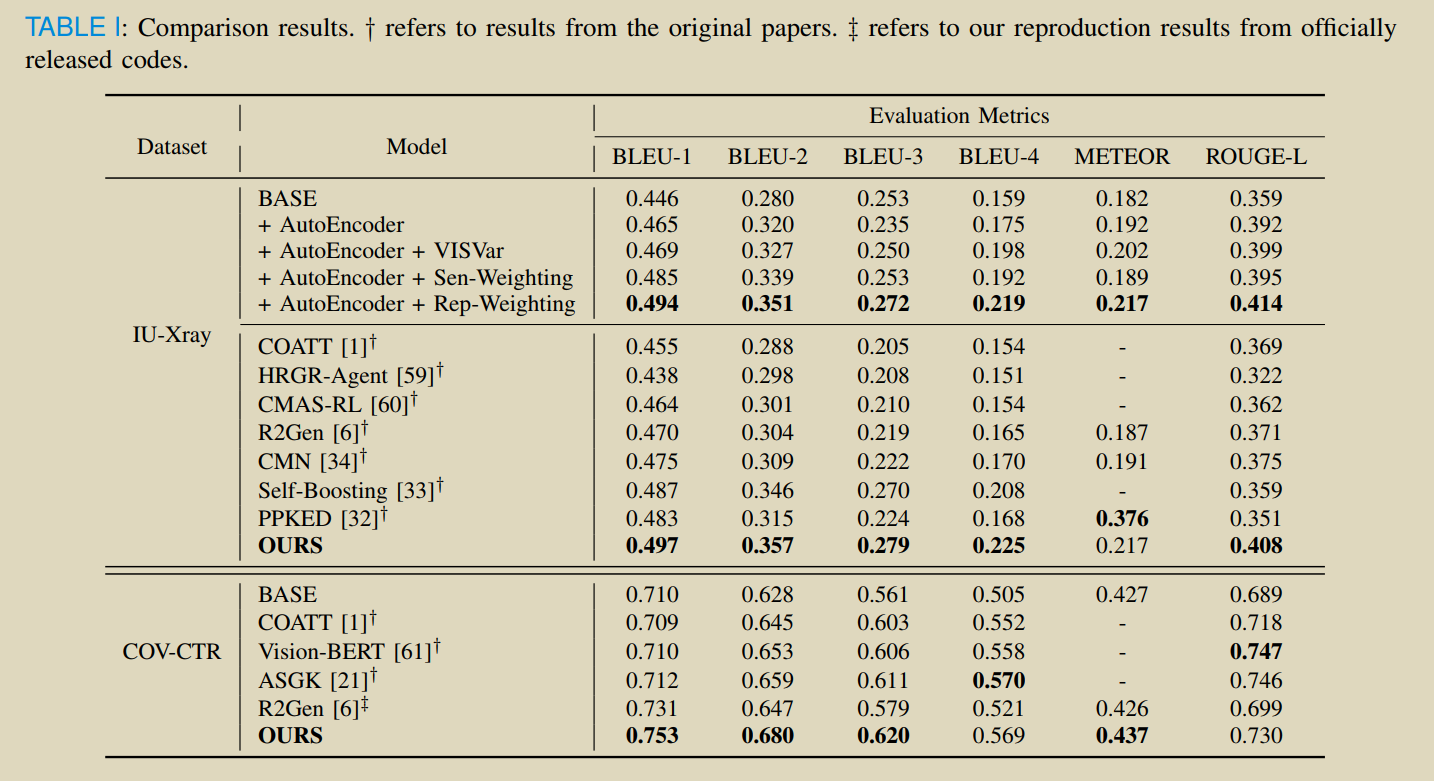
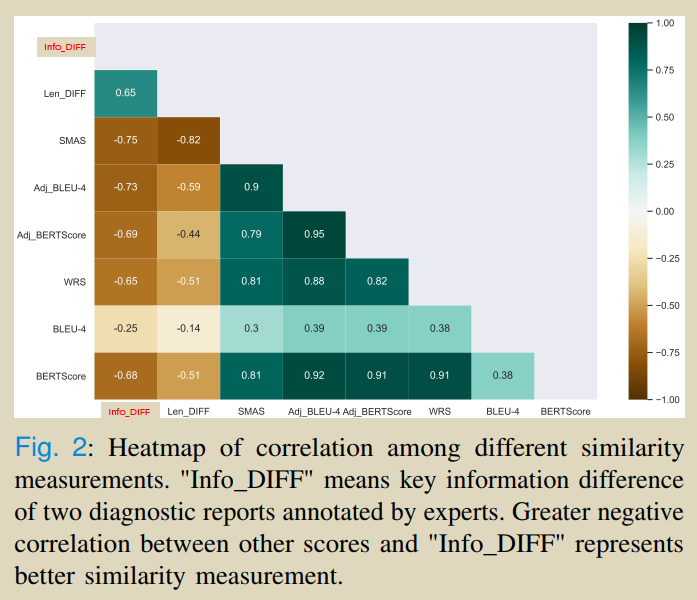
���¹���:֤ʵ�Ӿ���ȡ����image-caption�ṹ�е���Ҫ��,��������һ��������AutoEncoder��֧�������ض�������,����һ������Ӿ���ȷ���ԡ������һ���µĶ�������ҽѧ�����������ƶȵķ���SMAS(Sentence Matched Adjusted Semantic Similarity),�÷����ܹ����õز������Ϣ������������SMAS��һ�������ı��IJ�ȷ���ԡ��õ��IJ�ȷ���Կ������ϵ�ģ����,ƽ�ⱨ��/���ӵ���ʧ����,�����������Ż����̡�
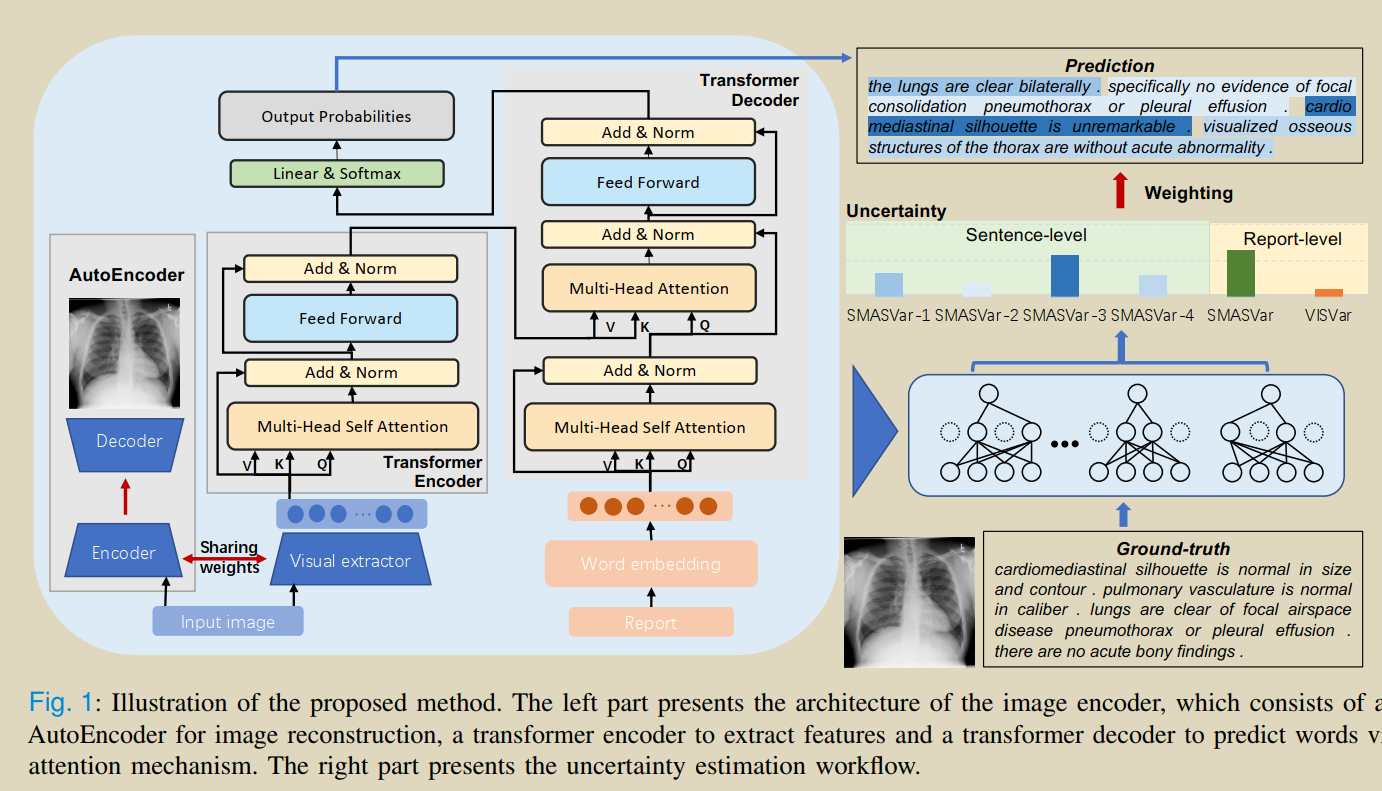
visual uncertainty measured by variance VISVar and textual SMAS uncertainty measured by variance SMASVar.
visual uncertainty�C>Monte Carlo (MC) dropout variational inference method
Textual Uncertainty: ->the variance of semantic similarity scores among generated diagnostic reports
42.Medical transformer: Gated axial-attention for medical image segmentation
Valanarasu J M J, Oza P, Hacihaliloglu I, et al. Medical transformer: Gated axial-attention for medical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 36-46. ��Դ�롿