自从bert提出后,nlp领域的预训练语言模型持续刷新各种任务榜单,各种预训练语言模型不断提出并更新迭代,最新的GPT3以千亿级的参数再次刷新了榜单任务。但是在工业界,bert的预训练+微调的任务模式还是在发挥一定的作用。因此本篇博客主要介绍在tf2.x的版本下使用bert模型进行命名实体识别任务。
bert模型的原理还是先简单介绍一下,主要从一下几个方面:
一、任务目标
bert的目标是学习大量的没有标注的语料数据,进而提取出语言模型,便于下游的微调任务。在训练的过程中主要有两个任务:其一是根据上下文预测当前词语;其二是判断当前句子是不是前一个句子的下一句。
二、输入数据
对于文本数据,一般处理步骤是先将文本分成一个个句子,再将句子分成词语列表或者字列表,然后进行后续的一系列任务。bert的输入也是如此,在预训练阶段,bert输入的是两个连续的句子。
(1)bert训练的输入数据有三个部分,第一个就是分词的word_ids,代表句子中每个词的编号;第二则是segment_ids,表示对两个输入句子的区分;第三是位置编码position,表示每个词在句子中所在的位置;最后将三者求和作为最终的结果输入到后续的transformer结构中。
(2)mask处理:为了进行第一个任务,需要随机对句子中的词进行mask操作,之后让模型去预测mask掉的词语,所以这个任务又被称为masked language model任务。
三、网络结构
bert的网络结构主要是由transformer的encoder部分堆叠而成,其中base版本模型为12层encoder结构,large版本模型为24层encoder构成。large版本的效果优于base版本,但是参数量多了一倍,训练成本比较高。工业界一般使用的都是base版本,large版本学术上使用的比较多,准确率上差的也不是太多。一个基本的transformer结构如下图所示:
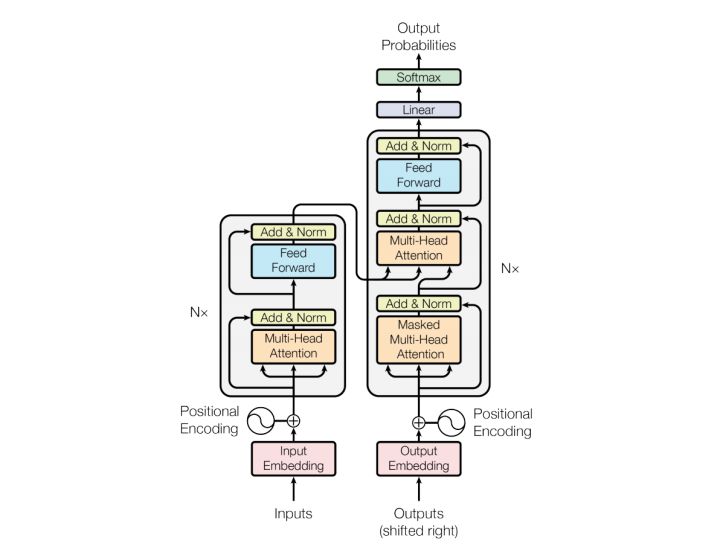
?完整的transformer是由encoder和decoder两个部分组成的,其中encoder部分也就是bert最基础的结构。是由multi-head attention, layer-normalization, feed-forward等组成,decoder结构大致相同,但是多了一个multi-head attention,并且输入不一样,key,value是encoder的输出,query是decoder的输入。
四、命名实体识别任务
命名实体就是以名称标识等实体。简单来说,如果我们听到一个名字,就知道这个东西是哪一个具体的事物,那么这个事物就是命名实体。
在生活和生产中,到处都有实体。实体店类型是根据需求,人为定义的一种概念,用来区分命名实体的类别,以便区别对待和使用,常用的实体类型有人名、地名、组织名、时间、产品名等等。
NER就是命名实体识别的一类技术,可以自动地从文本数据中识别出特定类型的命名实体。
ner任务的训练数据需要对文本数据中的实体进行标注,下面便是一条标注好的训练数据:
人 民 网 1 月 1 日 讯 据 《 纽 约 时 报 》 报 道 , 美 国 华 尔 街 股 市 在 2 0 1 3 年 的 最 后 一 天 继 续 上 涨 , 和 全 球 股 市 一 样 , 都 以 最 高 纪 录 或 接 近 最 高 纪 录 结 束 本 年 的 交 易 。
O O O B_T I_T I_T I_T O O O B_LOC I_LOC O O O O O O B_LOC I_LOC I_LOC I_LOC I_LOC O O O B_T I_T I_T I_T I_T O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
这条数据里B_T表示时间实体的起始值, I_T表示时间实体,B_LOC表示地名实体的起始值,I_LOC表示地名实体的其他值。
命名实体识别任务也就是一个多标签的分类任务,文本输入到模型中,按顺序输出预测的各种实体类别的标签。
数据处理代码如下:
def gen_data(self, input_idx, labels_idx):
'''
生成批次数据
:return:
'''
word_ids, segment_ids, word_mask, sequence_length = input_idx[0], input_idx[1], input_idx[2], input_idx[3]
batch_word_ids, batch_segment_ids, batch_word_mask, batch_sequence_length, batch_output_ids = [], [], [], [], []
for i in range(len(word_ids)):
word_id = word_ids[i]
segment_id = segment_ids[i]
mask = word_mask[i]
seq_len = sequence_length[i]
target_ids = labels_idx[i]
batch_word_ids.append(word_id)
batch_segment_ids.append(segment_id)
batch_word_mask.append(mask)
batch_sequence_length.append(seq_len)
batch_output_ids.append(target_ids)
if len(batch_word_ids) == self.batch_size:
yield dict(
input_word_ids=np.array(batch_word_ids, dtype="int64"),
input_mask=np.array(batch_word_mask, dtype="int64"),
input_type_ids=np.array(batch_segment_ids, dtype="int64"),
sequence_length=np.array(batch_sequence_length, dtype="int64"),
input_target_ids=np.array(batch_output_ids, dtype="float32")
)
batch_word_ids, batch_segment_ids, batch_word_mask, batch_sequence_length, batch_output_ids = [], [], [], [], []模型的loss计算与常用的分类也有一点差异:
def build_losses(self, labels, model_outputs, metrics, aux_losses=None) -> tf.Tensor:
'''
构建损失
'''
masked_labels, masked_weights = _masked_labels_and_weights(labels)
metrics = dict([(metric.name, metric) for metric in metrics])
losses = tf.keras.losses.sparse_categorical_crossentropy(masked_labels,
tf.cast(model_outputs, tf.float32),
from_logits=True)
# metrics['losses'].update_state(losses)
loss = losses
numerator_loss = tf.reduce_sum(loss * masked_weights)
denominator_loss = tf.reduce_sum(masked_weights)
loss = tf.math.divide_no_nan(numerator_loss, denominator_loss)
return loss考虑到过滤数据中一些不想放进训练的实体,所以对部分标签进行了掩盖,计算损失的时候不算进去。
对于预训练的bert模型的构建也有差异,使用的是tensorflow的开源包里的nlp模块:
def build_model(self):
'''
构建模型
'''
encoder_network = self.build_encoder()
model = BertTokenClassifier(network=encoder_network,
num_classes=self.config['tag_categories'],
dropout_rate=self.config['dropout_rate'],
output='logits')
return model
def build_encoder(self):
bert_config = bert_configs.BertConfig.from_json_file(self.config['bert_config_path'])
cfg = bert_config
bert_encoder = BertEncoder(
vocab_size=cfg.vocab_size,
hidden_size=cfg.hidden_size,
num_layers=cfg.num_hidden_layers,
num_attention_heads=cfg.num_attention_heads,
intermediate_size=cfg.intermediate_size,
activation=tf_utils.get_activation(cfg.hidden_act),
dropout_rate=cfg.hidden_dropout_prob,
attention_dropout_rate=cfg.attention_probs_dropout_prob,
max_sequence_length=cfg.max_position_embeddings,
type_vocab_size=cfg.type_vocab_size,
initializer=tf.keras.initializers.TruncatedNormal(
stddev=cfg.initializer_range),
embedding_width=cfg.embedding_size,
return_all_encoder_outputs=False)
return bert_encoder按时间步对数据进行训练,并进行梯度下降和反向传播更新模型参数:
def train_step(self,
inputs,
model:tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
metrics=None):
'''
进行训练,前向和后向计算
:param inputs:
:param model:
:param optimizer:
:param metrics:
:return:
'''
with tf.GradientTape() as tape:
outputs = model(inputs, training=True)
outputs = outputs[:, 1:self.config['seq_len'] + 1, :]
loss = self.build_losses(labels=inputs['labels'], model_outputs=outputs, metrics=metrics, aux_losses=None)
tvars = model.trainable_variables
grads = tape.gradient(loss, tvars)
grads, _ = tf.clip_by_global_norm(grads, clip_norm=5.0)
optimizer.apply_gradients(list(zip(grads, tvars)))
labels = inputs['labels']
logs = {self.loss: loss}
if metrics:
self.process_metrics(metrics, labels, outputs)
logs.update({m.name: m.result() for m in model.metrics})
if model.compiled_metrics:
self.process_compiled_metrics(model.compiled_metrics, labels, outputs)
logs.update({m.name: m.result() for m in metrics or []})
logs.update({m.name: m.result() for m in model.metrics})
return logs训练完成后,保存更新的模型,后续调用模型就可以进行预测了。
完整的代码在https://github.com/dextroushands/pretraind_model_for_nlp_tasks
五、后续
以上就是一个最简单的bert微调命名实体识别任务,一般还可以在bert后再加上crf层,取得更高地准确率。
实际的工业场景由于数据更加复杂,实体地类别更多,经常将命名实体识别任务与其他任务如分类或者相似度计算进行多目标的任务。或者网络结构设计更加复杂以针对具体场景的问题。