Disentangled Person Image Generation(解构的人物形象生成文献总结)
1.介绍
由于前景、背景和姿势信息等不同图像因素之间的复杂相互作用,生成一个新颖但逼真的人物图像是很具有挑战性的。在该文中,首先,提出了一种多分支重建网络,将三种因素分解并编码为嵌入特征,然后将这些特征组合起来重新合成输入图像本身,其次,以对抗的方式学习三个相应的映射函数。
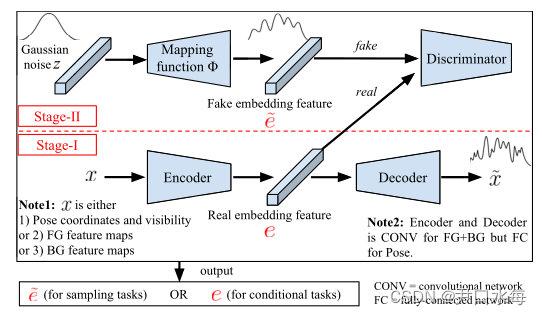
总之:我们的整个管道分两个阶段进行,如下图所示。在第一阶段,我们使用一个人的图像作为输入,并将信息分解为三个主要因素,即前景、背景和姿势。通过重建网络嵌入特征,对每个分离因子进行建模。在第二阶段,学习映射函数,将高斯分布映射到特征嵌入分布。
本文的主要贡献:
- 通过将人分解为弱相关因素,即前景、背景和姿势,生成自然人图像
- 一个两阶段框架:第一阶段,多分支重建网络的编码器用于图像生成任务,第二阶段,通过对抗训练学习的映射函数用于采样任务。
- 一种通过对抗性训练匹配真实和虚假嵌入特征分布的技术
2.相关工作
2.1条件图像生成
为了提取位置变化的外观特征,我们根据由姿势关键点获得的感兴趣区域(ROI)边界框来安排身体部位特征嵌入。然后,我们明确地利用这些姿势关键点作为结构信息,为每个身体部位选择必要的外观特征,并生成整个人物图像。
2.2 非纠缠图像生成
该文中采用三种变化轴(前景、背景、姿势)的显式表示。
3.方法
3.1第一阶段:非纠缠图像重建
第一阶段中,提出了一种多分支重建结构,以分离前景、背景和姿势因素,如下图所示。
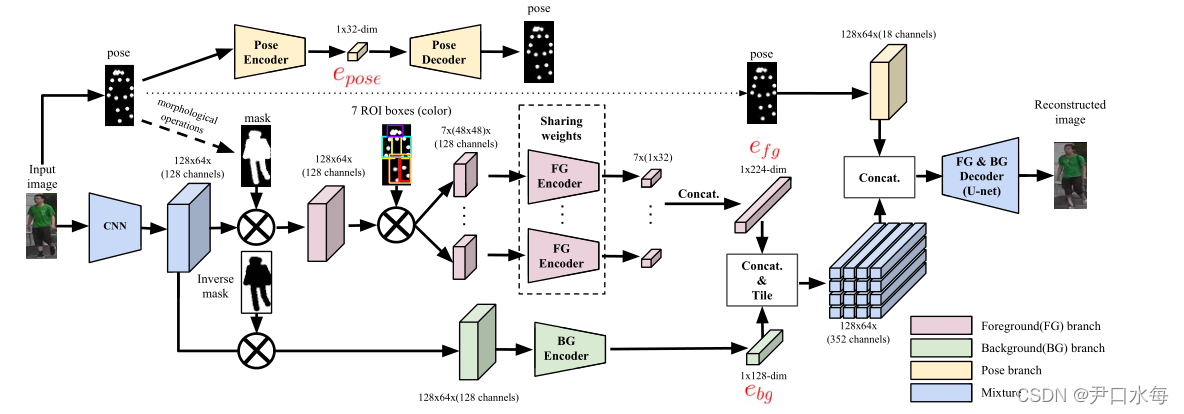
3.1.1前景分支
为了分离前景和背景信息,我们将粗姿态掩膜应用于特征地图,而不是直接应用于输入图像。这样可以减少粗糙姿势掩膜的不精确性。然后通过7个身体ROI来编码姿势不变的特征。对于每个ROI而言,提取的大小为48*48的特征映射,并将其传递给权重共享前景编码器,以提高学习效率。最后,将编码后的7个ROI嵌入特征串联成224D特征向量。
3.1.2 背景分支
通过应用逆姿势掩膜获得背景特征映射,并将其传递到背景编码器中,以获得128维的嵌入特征,然后将背景和前景特征拼接成128* 64 *352个外观特征图。
3.1.3 姿势分支
通过将18通道热图与外观特征图连接起来,并将其传递到基于U-net的构架中,以生成PG2(G1+D)之后的最终人物图像。因为外观和姿势的组合施加了一个强大的显式分离约束,迫使网络学习如何使用姿势结构信息为每个像素选择有用的外观信息。对于姿势采样,采用一个额外的全连接网络来重建姿势信息,以便对嵌入的姿势特征进行解码以获得热图。由于某些身体部位可能因遮挡而看不见,引入可见变量αi∈{0,1},i=1…18表示每个姿势关键点的可观性状态。
3.2 第二阶段:嵌入特征映射
两步映射技术:先学习一个映射函数Φ,该函数将高斯空间Z映射到一个连续的特征嵌入空间E,然后使用预训练的解码器将特征嵌入空间E映射到真实的图像空间X。
在第一阶段学习的编码器对FG进行编码,BG和姿势因子x转化为低维嵌入特征e,然后,我们将高斯噪声z映射的特征作为伪嵌入e~,并对映射函数Φ进行学习。通过这种方式,可以从噪声中提取假嵌入特征,然后使用在第一阶段学习的解码器将其映射回图像。提出的两步映射技术易于分段训练,最重要的是,它可以用于其他图像生成应用。