1. 写在前面
做时空数据预测毕设的时候, 遇到的一个需求就是想用Transformer搭建一个特征提取器, 模型的输入是滑动窗口切分好的时空数据, 维度[batch, seq_len, observepoint_num] , 解释的话,就是一个表面有m个观测点, 每个观测点每天会测量一次温度, 那么如果是预测整个平面温度趋势的话,就是需要先用滑动窗口,采用过去几天的数据切割,所以就得到了这样的一个三维初始数据。
我的想法是先让这个数据集过一个Transformer特征提取器,这样就能获取全局信息, 得到各个观测点温度的相关性, 得到的输出再用时空模型进行训练和预测。 本来是想把Transformer块和后面时空模型搭建成序列模型的形式, 但又担心这样模型太复杂,训练不充分。 所以, 我就想先训练一个简单的Transformer网络,然后把最后面的Dense层去掉,只用它之前的特征提取模块。 这样,把原始数据过一下特征提取模块,就得到了整合全局信息的数据了。 下面的尝试就是基于这样的一个背景。
过程逻辑就是首先需要先自己搭建Transformer块以及简易网络, 然后原始数据训练到收敛,然后把这个网络保存起来, 然后在导入这个模型,拿到它的Transformer子模块,让原始数据过一下这个, 得到输出后保存起来,供后面时空模型训练使用。
这个过程中, 在模型保存和使用子模型部分遇到了小坑,这里把解决办法记录下, 这个花费了大约一下午的时间摸索。
2. 自定义模型导入与加载
首先, 我先导入数据, 最终得到的数据维度:
sst_data = load_data(sst_name, use_time)
# 数据预处理
print("数据预处理....")
ds = data_preprocess(sst_data, use_time)
print('数据预处理完成!')
# 划分数据集
print('划分数据集......')
x_train, y_train, x_valid, y_valid, x_test, y_test = split_data(ds=ds.values, seq_len=seq_len, output_len=output_len, test_num=test_num, out_dim=out_dim, use_time=use_time)
print('划分数据集完成!')
# 数据标准化
print('数据标准化....')
x_train, y_train, x_valid, y_valid, x_test, y_test = data_scaler(x_train, y_train, x_valid, y_valid, x_test, y_test, seq_len=seq_len, out_dim=out_dim)
print('数据标准化完成!')
print(x_train.shape, y_train.shape, x_valid.shape, y_valid.shape, x_test.shape, y_test.shape)
# (13927, 5, 64) (13927, 64) (365, 5, 64) (365, 64) (365, 5, 64) (365, 64)
这里的维度含义上面做了解释, 过去5天的这一个海表面64个观测点的数据预测未来1天64个观测点的数据, 这里由于是整个表面,所以是一种时空序列预测, 空间相关性和时间相关性同样重要。
由于我想先用Transformer块处理, 来获取64个观测点之间的空间信息, 所以这里的输入第二维和第三维需要换下,变成(-1, point, seq_len), 这样最后得到的才是point之间的关系, 而seq_len这个维度,其实就相当于embedding了,这里是过去n天的温度值。
# 交换维度
x_train, x_valid, x_test = tf.transpose(x_train, (0, 2, 1)), tf.transpose(x_valid, (0, 2, 1)), tf.transpose(x_test, (0, 2, 1))
这样, 就能直接作为Transformer的输入了。
接下来,搭建Transformer块以及简单网络:
class InteractingLayer(Layer):
"""A layer user in AutoInt that model the correction between different feature fields by multi-head self-att mechanism
input: 3维张量, (none, field_num, embedding_size)
output: 3维张量, (none, field_num, att_embedding_size * head_num)
"""
def __init__(self, att_embedding_size=8, head_num=2, use_res=True, seed=2021, **kwargs):
super(InteractingLayer, self).__init__()
self.att_embedding_size = att_embedding_size
self.head_num = head_num
self.use_res = use_res
self.seed = seed
def build(self, input_shape):
embedding_size = int(input_shape[-1])
# 定义三个矩阵Wq, Wk, Wv
self.W_query = self.add_weight(name="query", shape=[embedding_size, self.att_embedding_size * self.head_num],
dtype=tf.float32,
initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed))
self.W_key = self.add_weight(name="key", shape=[embedding_size, self.att_embedding_size * self.head_num],
dtype=tf.float32,
initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed + 1))
self.W_value = self.add_weight(name="value", shape=[embedding_size, self.att_embedding_size * self.head_num],
dtype=tf.float32,
initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed + 2))
if self.use_res:
self.W_res = self.add_weight(name="res", shape=[embedding_size, self.att_embedding_size * self.head_num],
dtype=tf.float32,
initializer=tf.keras.initializers.TruncatedNormal(seed=self.seed + 3))
super(InteractingLayer, self).build(input_shape)
def call(self, inputs, **kwargs):
# inputs (none, field_nums, embed_num)
querys = tf.tensordot(inputs, self.W_query, axes=(-1, 0)) # (None, field_nums, att_emb_size*head_num)
keys = tf.tensordot(inputs, self.W_key, axes=(-1, 0))
values = tf.tensordot(inputs, self.W_value, axes=(-1, 0))
# 多头注意力计算 按照头分开 (head_num, None, field_nums, att_embed_size)
querys = tf.stack(tf.split(querys, self.head_num, axis=2))
keys = tf.stack(tf.split(keys, self.head_num, axis=2))
values = tf.stack(tf.split(values, self.head_num, axis=2))
# Q * K, key的后两维转置,然后再矩阵乘法
inner_product = tf.matmul(querys, keys, transpose_b=True) # (head_num, None, field_nums, field_nums)
normal_att_scores = tf.nn.softmax(inner_product, axis=-1)
result = tf.matmul(normal_att_scores, values) # (head_num, None, field_nums, att_embed_size)
result = tf.concat(tf.split(result, self.head_num, ), axis=-1) # (1, None, field_nums, att_emb_size*head_num)
result = tf.squeeze(result, axis=0) # (None, field_num, att_emb_size*head_num)
if self.use_res:
result += tf.tensordot(inputs, self.W_res, axes=(-1, 0))
result = tf.nn.relu(result)
return result
def get_config(self):
# 自定义层里面的属性
config = {
'att_embedding_size': self.att_embedding_size,
'head_num': self.head_num,
'use_res': self.use_res,
'seed': self.seed
}
base_config = super(InteractingLayer, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
用这个Transformer块搭建简单网络,其实就是后面加一个全连接即可, 因为我是想先训练下这个网络到收敛,然后取这个特征交互层的输出。
# 模型配置参数设置
loss = 'mean_squared_error'
optimizer = 'adam'
def Transformer(X_train, output_len, output_dim):
X = Input(shape=[X_train.shape[1], X_train.shape[2]])
transformer_out = InteractingLayer()(X)
flat = Flatten()(transformer_out)
out = Dense(output_len*output_dim)(flat)
model = Model(X, out)
model.compile(loss=loss, optimizer=optimizer)
return model
model = Transformer(x_train,output_len, out_dim)
这样模型搭建完,接下来进行训练:
history = model.fit(
x_train,
y_train,
validation_data=(x_valid, y_valid),
epochs=50,
batch_size=64,
verbose=1,
#callbacks=callbacks
)
这个模型其实非常简单,训练完之后,保存模型,
model.save('saved_model/Transformer.h5')
遇到了第一个报错:NotImplementedError: Layers with arguments in __init__ must override get_config, 当然我上面那个是最终版本,没有这个错误了
这个报错的原因是保存的模型里面有自定义的层,比如我这里的InteractingLayer, 这时候,直接保存模型并不知道你这里面究竟有哪些属性或者参数, 所以解决办法,就是在这个类里面加一个get_config函数,我上面加好了。
def get_config(self):
# 自定义层里面的属性, 需要根据自己层里面的属性进行替换
config = {
'att_embedding_size': self.att_embedding_size,
'head_num': self.head_num,
'use_res': self.use_res,
'seed': self.seed
}
base_config = super(InteractingLayer, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
这个基本上是模板,就是config这里,需要根据自己层里面的属性替换掉。这样就能保存了。
接下来,关掉上面训练的jupyter, 重新打开一个jupyter, 然后导入模型。
# 导入之前训练好的Transformer模型
model = tf.keras.models.load_model('saved_model/Transformer.h5')
遇到了第二个报错:ValueError: Unknown Layer:InteractingLayer, 因为这个是自定义的层, 直接这样搞不行,需要告诉程序才行。 所有正确的方式是:
# 导入之前训练好的Transformer模型
model = tf.keras.models.load_model('saved_model/Transformer.h5', custom_objects={'InteractingLayer': InteractingLayer})
有自己定义的层的时候,要在导入的时候通过custom_objects指定出来。
然后运行, 遇到了一个非常奇葩的错误, 也是一下午主要卡着的问题TypeError: __init__() got an unexpected keyword argument name, 这个问题我可是百度了好久,最后发现解决方案是下面这样,在自定义layer的__init__方法里加入**kwargs这个参数
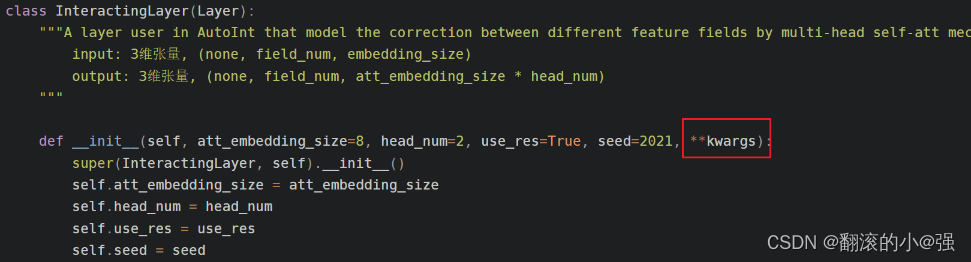
当然我上面这个自定义的层里面,这些错误都改过来了, 保存和导入的时候,可以直接使用了。
这样,自定义层模型保存与加载的坑就填完了,关键三个点:
- 自定义层里面的
__init__里面一定要加上**kwargs参数。 - 自定义层里面要加一个
git_config()函数模板 - 模型导入的时候, 要通过
custom_objects指定出自己定义的层。
3. 获取网络中间某一层的输出
导入Transformer网络之后,我接下来的需求是想单独把上面InteractingLayer这个块取出来, 然后让原始数据过这个东西,拿到提取好的特征,但是我保存模型的时候,是整个保存的,带着后面的Dense层了, 那么我怎么实现这个需求呢?
这就需要建立一个子模型来获取中间层的输出, 做法如下:
首先, 我先看看模型各个层的名称:

然后我建立子模型, 这里一行代码就行:
# 建立模型的子网络
InteractingLayerModel = Model(inputs = model.input, outputs = model.get_layer('interacting_layer').output)
这里的输出,变成中间层的输出即可。
这样就能实现我的需求了。
new_x_train = InteractingLayerModel(x_train)
new_x_valid = InteractingLayerModel(x_valid)
new_x_test = InteractingLayerModel(x_test)
维度如下:

这里Transformer块我由于用了2个头, 每个头embedding维度是8,所以最终输出第三个从原来的5变成了16, 可以理解成这个输出已经综合了全局观测点的空间相关性以及时序时间的非线性。
当然, 到这里还不行, 还需要再交换下维度,这样才能给后面的时空模型做输入,所以交换保存就完事啦。
# 维度转换
new_x_train = tf.transpose(new_x_train, (0, 2, 1))
new_x_valid = tf.transpose(new_x_valid, (0, 2, 1))
new_x_test = tf.transpose(new_x_test, (0, 2, 1))
# 保存新的数据
np.save('TransformerOutput/x_train.npy', new_x_train.numpy())
np.save('TransformerOutput/y_train.npy', y_train)
np.save('TransformerOutput/x_valid.npy', new_x_valid.numpy())
np.save('TransformerOutput/y_valid.npy', y_valid)
np.save('TransformerOutput/x_test.npy', new_x_test.numpy())
np.save('TransformerOutput/y_test.npy', y_test)
这样, 我时空模型训练的时候,就直接导入这些数据就好啦。
通过我实验证明, 在时空模型的预测上, 这种预先用Transformer块处理的效果要比直接用原始数据的效果要好。
终于没让我白采坑,哈哈, 主要是这次的方法, 在其他应用上也是一样的道理, 属于共通的东西,所以写一篇笔记记录下 😉