�����:
https://zhuanlan.zhihu.com/p/68468520
һ��Ŀ��
��ʧ����������������ѧϰģ�͵ľ�ȷ�ȡ�һ����˵,��ʧ������ֵԽС,ģ�͵ľ�ȷ�Ⱦ�Խ�ߡ����Ҫ�����ѧϰģ�͵ľ�ȷ��,����Ҫ�����ܽ�����ʧ������ֵ����������ʧ������ֵ,����һ������ݶ��½��������������,�ݶ��½���Ŀ��,����Ϊ����С����ʧ������
����ʧ����MSE,����ʽ(1):
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-wq1b2Aiq-1645770279138)(https://www.zhihu.com/equation?tex=L%28w,b%29%20=%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi=1%7D%5E%7BN%7D%7B%28y_%7Bi%7D%20-%20f%28wx_%7Bi%7D%20%2b%20b%29%29%5E%7B2%7D%7D#pic_center)]](https://img-blog.csdnimg.cn/723bd71b81d3403e89ad8523fcda10b7.png)
����ԭ��
Ѱ����ʧ��������͵�,����������ɽ��������,ϣ��������ʽ�ҵ�ɽ������͵ĵط�������ʵ��,������Ѱ���½��ٶ�����һ����ʽ������Ȼ,�������һ�µ�ʱ��,����ͬ��ʱ��,������ķ������½��ٶ����ġ�
- ��͵ķ���>�ݶȷ���

һ��������Ӧ��һ���ݶ� d L d w \frac{d L}{dw} dwdL?,��ô���������Ӧ����ݶȡ����ƽ���ݶ� d L w �� \frac{dL}{\bar{w}} w��dL?���������������ݶȡ�(�ɿ�����������ġ����ߡ�ƽ���Ľ����)��ͼ��ʾΪֻ��һ��Ȩ�� w w w,Ȩ�� w w w�ķ����ֻ�����������֮�֡���������Aÿ��һ��ʱ��,�۲�һ����͵÷���,�������䷽��ǰ�����������A�ڲ��ٹ̶��������,��̶�ʱ�������s����ͬ�á���ôȨ�� w w w�øı���Ϊ �� w = s ? d L d w \Delta w=s* \frac{d L}{d w} ��w=s?dwdL?(����,��ͼ��ʾ d L d w = c o s �� \frac{dL}{dw}=cos \theta dwdL?=cos��)
- ��ͬ��ʱ��*��ͬ�IJ���==��ͬ��·�̡�>ѧϰ��
�����һ��ʱ�̵�Ȩ�صø���ֵΪ: w + �O �� w �O w+|\Delta w| w+�O��w�O.��Ӧ����ѧ��������˵,�� w i w_i wi? ��ʾȨ�صij�ʼֵ, w i + 1 w_{i+1} wi+1? ��ʾ���º��Ȩ��ֵ,�� �� \alpha �� ��ʾѧϰ��,���� ��ʽ(2)
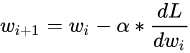
���ݶ��½���,���ǻ��ظ�ʽ��(2)���,ֱ����ʧ����ֵ�������䡣
���ѧϰ��
��
\alpha
�����õù���,�п������ǻ������ʧ��������Сֵ;������õù�С,��������Ҫ����ʽ��(2)�dz���β����ҵ���Сֵ,��ķѽ϶��ʱ�䡣���,��ʵ��Ӧ����,������ҪΪѧϰ��
a
l
p
h
a
alpha
alpha ����һ�����ʵ�ֵ��
���潲���˶�Ȩ��
w
w
w ֵ���Ż�����,����ƫ��
b
b
b,����Ҳ��������ͬ�ķ�ʽ���д���,����Ͳ���չ���ˡ�
�����ݶ��½�����

�ġ������ݶ��½��㷨
1. С���������ݶ��½�(Mini Batch GD)
����㷨��ÿ���ݶ��½��Ĺ�����,ֻѡȡһ���ֵ��������ݽ��м����ݶ�,������������1/100�����ݡ����������ϴ����Ŀ��,�������Եؼ����ݶȼ����ʱ�䡣
2. ����ݶ��½�(Stochastic GD)
����ݶ��½��㷨ֻ�����ȡһ�����������ݶȼ���,����ÿ���ݶ��½�����ֻ����һ���������ݶ�,�������ʱ���С���������ݶ��½��㷨��Ҫ�ٺܶ�,������ѵ����������̫С(ֻ��һ��),����½�·���������ܵ�ѵ����������������Ӱ��,����������������·һ��,�������бб��