еЊвЊ
ЕудЦбЇЯАзюНќвђЦфдкМЦЫуЛњЪгОѕЁЂздЖЏМнЪЛКЭЛњЦїШЫММЪѕЕШаэЖрСьгђЕФЙуЗКгІгУЖјЪмЕНдНРДдНЖрЕФЙизЂЁЃзїЮЊШЫЙЄжЧФмЕФжїЕМММЪѕ,ЩюЖШбЇЯАвбГЩЙІгУгкНтОіИїжжЖўЮЌЪгОѕЮЪЬтЁЃШЛЖј,гЩгкЪЙгУЩюЖШЩёОЭјТчДІРэЕудЦЫљУцСйЕФЖРЬиЬєеН,ЕудЦЕФЩюЖШбЇЯАШдДІгкЦ№ВННзЖЮЁЃзюНќ,ЕудЦЕФЩюЖШбЇЯАБфЕУИќМгХюВЊЗЂеЙ,ЬсГіСЫаэЖрЗНЗЈРДНтОіИУСьгђЕФВЛЭЌЮЪЬтЁЃЮЊСЫМЄЗЂЮДРДЕФбаОП,БОЮФШЋУцЛиЙЫСЫЕудЦЩюЖШбЇЯАЗНЗЈЕФзюаТНјеЙЁЃЫќКИЧСЫШ§ИіжївЊШЮЮё,АќРЈ3DаЮзДЗжРрЁЂ3DФПБъМьВтКЭИњзйвдМА3DЕудЦЗжИюЁЃЫќЛЙеЙЪОСЫМИИіЙЋПЊПЩгУЕФЪ§ОнМЏЕФБШНЯНсЙћ,вдМАгаМћЕиЕФЙлВьКЭЦєЗЂЮДРДЕФбаОПЗНЯђЁЃ
ЙиМќДЪ:ЩюЖШбЇЯАЁЂЕудЦЁЂ3DЪ§ОнЁЂаЮзДЗжРрЁЂаЮзДМьЫїЁЂФПБъМьВтЁЂФПБъИњзйЁЂГЁОАСїЁЂЪЕР§ЗжИюЁЂгявхЗжИюЁЂВПЗжЗжИюЁЃ
1 НщЩм
ЫцзХ3DВЩМЏММЪѕЕФПьЫйЗЂеЙ,3DДЋИаЦїдНРДдНЖр,МлИёвВдНРДдНБувЫ,АќРЈИїжжРраЭЕФ3DЩЈУшвЧЁЂLiDARКЭRGB-DЯрЛњ(ШчKinectЁЂRealSenseКЭAppleЩюЖШЯрЛњ)[1]ЁЃетаЉДЋИаЦїЛёШЁЕФ3DЪ§ОнПЩвдЬсЙЉЗсИЛЕФМИКЮЁЂаЮзДКЭБШР§аХЯЂ[2]ЁЂ[3]ЁЃгы2DЭМЯёЯрИЈЯрГЩ,3DЪ§ОнЮЊИќКУЕиСЫНтЛњЦїжмЮЇЛЗОГЬсЙЉСЫЛњЛсЁЃ3DЪ§ОндкВЛЭЌСьгђгааэЖргІгУ,АќРЈздЖЏМнЪЛЁЂЛњЦїШЫЁЂвЃИаКЭвНСЦ[4]ЁЃ
3DЪ§ОнЭЈГЃПЩвдгУВЛЭЌЕФИёЪНБэЪО,АќРЈЩюЖШЭМЯёЁЂЕудЦЁЂЭјИёКЭЬхЛ§ЭјИёЁЃзїЮЊвЛжжГЃгУЕФИёЪН,ЕудЦБэЪОНЋдЪММИКЮаХЯЂБЃСєдк3DПеМфжа,ЮоашШЮКЮРыЩЂЛЏЁЃвђДЫ,ЫќЪЧаэЖрГЁОАРэНтЯрЙигІгУ(Р§ШчздЖЏМнЪЛКЭЛњЦїШЫММЪѕ)ЕФЪзбЁЁЃзюНќ,ЩюЖШбЇЯАММЪѕжїЕМСЫаэЖрбаОПСьгђ,Р§ШчМЦЫуЛњЪгОѕЁЂгявєЪЖБ№КЭздШЛгябдДІРэЁЃШЛЖј,3DЕудЦЕФЩюЖШбЇЯАШдШЛУцСйМИИіжиДѓЬєеН[5],Р§ШчЪ§ОнМЏЙцФЃаЁЁЂ3D ЕудЦЕФИпЮЌЖШКЭЗЧНсЙЙЛЏаджЪЁЃдкДЫЛљДЁЩЯ,БОЮФжиЕуЗжЮіСЫвбОгУгкДІРэ3DЕудЦЕФЩюЖШбЇЯАЗНЗЈЁЃЕудЦЩЯЕФЩюЖШбЇЯАдНРДдНЪмЕНЙизЂ,гШЦфЪЧдкЙ§ШЅЮхФъжаЁЃЛЙЗЂВМСЫМИИіЙЋПЊПЩгУЕФЪ§ОнМЏ,Р§ШчModelNet[6]ЁЂScanObjectNN[7]ЁЂShapeNet[8]ЁЂPartNet[9]ЁЂS3DIS[10]ЁЂScanNet[11]ЁЂSemantic3D[12]ЁЂApolloCar3D[13]ЁЂКЭ KITTI Vision Benchmark Suite[14]ЁЂ[15]ЁЃетаЉЪ§ОнМЏНјвЛВНЭЦЖЏСЫЖд3DЕудЦЩюЖШбЇЯАЕФбаОП,ЬсГіСЫдНРДдНЖрЕФЗНЗЈРДНтОігыЕудЦДІРэЯрЙиЕФИїжжЮЪЬт,АќРЈ3DаЮзДЗжРрЁЂ3DЖдЯѓМьВтКЭИњзйЁЂ3DЕудЦЗжИюЁЂ3DЕудЦХфзМЁЂ6-DOFЮЛзЫЙРМЦКЭ3DжиНЈ[16]ЁЂ[17]ЁЂ[18]ЁЃвВКмЩйгаЙигк3DЪ§ОнЕФЩюЖШбЇЯАЕїВщ,Р§Шч[19]ЁЂ[20]ЁЂ[21]ЁЂ[22]ЁЃШЛЖј,ЮвУЧЕФТлЮФЪЧЕквЛЦЊзЈУХЙизЂЕудЦРэНтЕФЩюЖШбЇЯАЗНЗЈЁЃЯжгаЕФ3DЕудЦЩюЖШбЇЯАЗНЗЈЕФЗжРрШчЭМ1ЫљЪОЁЃ
гыЯжгаЮФЯзЯрБШ,етЯюЙЄзїЕФжївЊЙБЯзПЩвдзмНсШчЯТ:
1)ОнЮвУЧЫљжЊ,етЪЧЕквЛЦЊШЋУцКИЧЩюЖШбЇЯАЗНЗЈЕФЕїВщТлЮФ,гУгкМИИіживЊЕФЕудЦРэНтШЮЮё,АќРЈ3DаЮзДЗжРрЁЂ3DФПБъМьВтКЭИњзйвдМА3DЕудЦЗжИюЁЃ
2)гыЯжгаЕФзлЪі[19]ЁЂ[20]ВЛЭЌ,ЮвУЧЬиБ№ЙизЂ3DЕудЦЕФЩюЖШбЇЯАЗНЗЈ,ЖјВЛЪЧЫљгаРраЭЕФ3DЪ§ОнЁЃ
3)БОЮФКИЧСЫЕудЦЩюЖШбЇЯАЕФзюаТНјеЙЁЃвђДЫ,ЫќЮЊЖСепЬсЙЉСЫзюЯШНјЕФЗНЗЈЁЃ
4)ЖдМИжжЙЋПЊЪ§ОнМЏЕФЯжгаЗНЗЈНјааСЫзлКЯБШНЯ(ШчБэ2ЁЂ3ЁЂ4ЁЂ5),ВЂИјГіСЫМђвЊзмНсКЭЩюШыЬжТлЁЃ
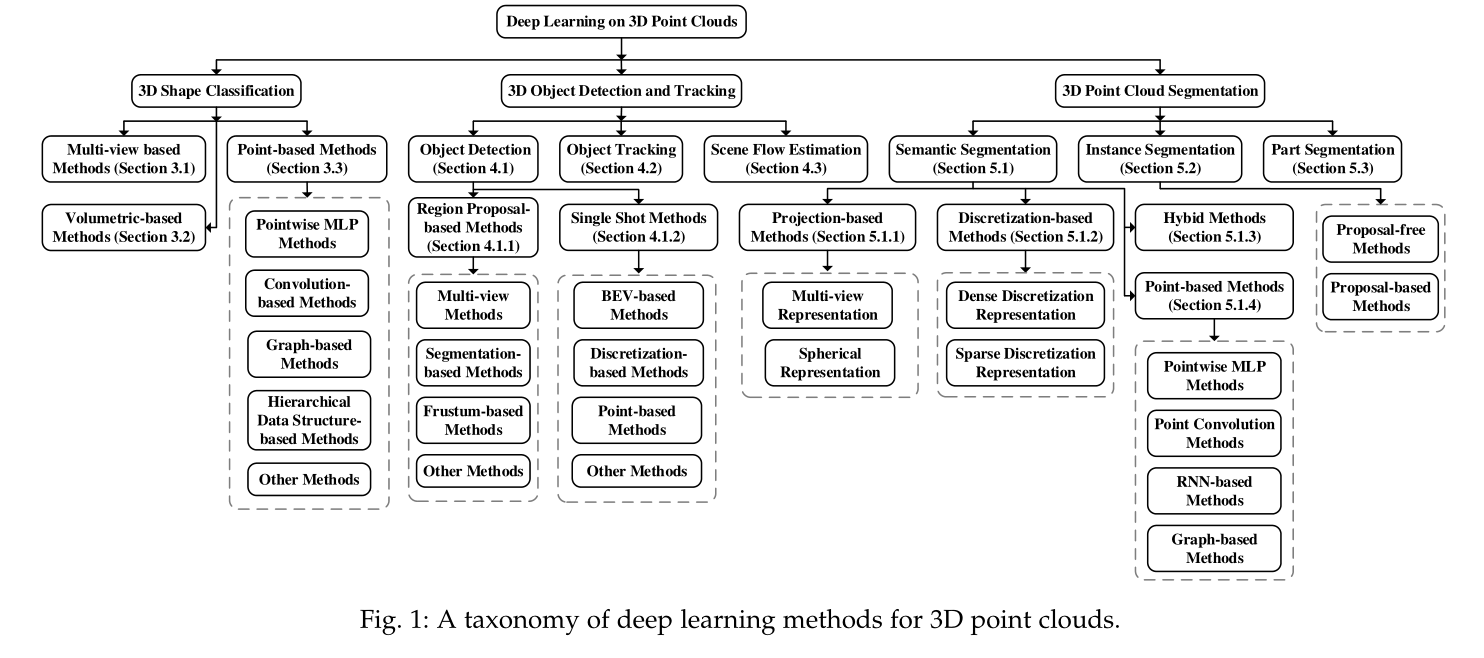
БОЮФЕФНсЙЙШчЯТЁЃЕк2НкНщЩмСЫИїздШЮЮёЕФЪ§ОнМЏКЭЦРЙРжИБъЁЃЕк3НкЛиЙЫСЫШ§ЮЌаЮзДЗжРрЕФЗНЗЈЁЃЕк4НкИХЪіСЫЯжгаЕФШ§ЮЌФПБъМьВтКЭИњзйЗНЗЈЁЃЕк5НкЛиЙЫСЫЕудЦЗжИюЕФЗНЗЈ,АќРЈгявхЗжИюЁЂЪЕР§ЗжИюКЭВПЗжЗжИюЁЃзюКѓ,Ек6НкзмНсСЫБОЮФЁЃЮвУЧЛЙЬсЙЉЖЈЦкИќаТЕФЯюФПвГУц:https://github.com/QingyongHu/SoTA-Point-Cloud.
ЭМ1ЁЂ3DЕудЦЕФЩюЖШбЇЯАЗНЗЈЗжРрЁЃ
2 БГОА
2.1 Ъ§ОнМЏ
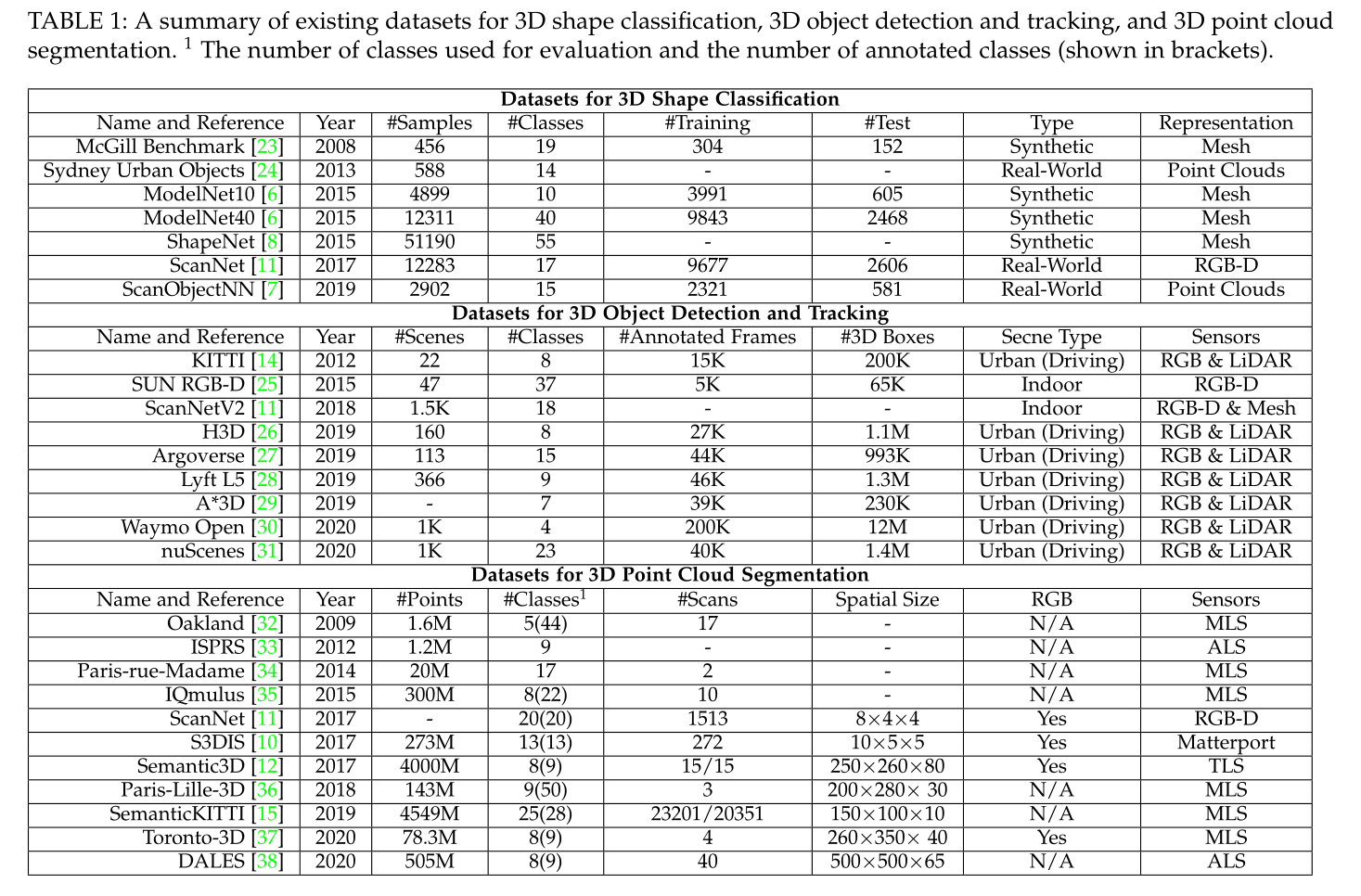
вбОЪеМЏСЫДѓСПЪ§ОнМЏРДЦРЙРЩюЖШбЇЯАЫуЗЈдкВЛЭЌ3DЕудЦгІгУжаЕФадФмЁЃБэ1СаГіСЫвЛаЉгУгк3DаЮзДЗжРрЁЂ3DФПБъМьВтКЭИњзйвдМА3DЕудЦЗжИюЕФЕфаЭЪ§ОнМЏЁЃЬиБ№ЪЧ,ЛЙзмНсСЫетаЉЪ§ОнМЏЕФЪєадЁЃ
Ждгк3DаЮзДЗжРр,гаСНжжРраЭЕФЪ§ОнМЏ:КЯГЩЪ§ОнМЏ[6]ЁЂ[8]КЭецЪЕЪРНчЪ§ОнМЏ[7]ЁЂ[11]ЁЃКЯГЩЪ§ОнМЏжаЕФФПБъЪЧЭъећЕФ,УЛгаШЮКЮекЕВКЭБГОАЁЃЯрБШжЎЯТ,ЯжЪЕЪРНчЪ§ОнМЏжаЕФФПБъБЛВЛЭЌМЖБ№ЕФекЕВ,вЛаЉФПБъБЛБГОАдыЩљЮлШОЁЃ
Ждгк3DФПБъМьВтКЭИњзй,гаСНжжРраЭЕФЪ§ОнМЏ:ЪвФкГЁОА[11]ЁЂ[25]КЭЪвЭтГЧЪаГЁОА[14]ЁЂ[28]ЁЂ[30]ЁЂ[31]ЁЃЪвФкЪ§ОнМЏжаЕФЕудЦвЊУДДгУмМЏЩюЖШЭМзЊЛЛЖјРД,вЊУДДг3DЭјИёжаВЩбљЁЃЛЇЭтГЧЪаЪ§ОнМЏзЈЮЊздЖЏМнЪЛЖјЩшМЦ,ЦфжаЮяЬхдкПеМфЩЯЗжРыСМКУ,етаЉЕудЦКмЯЁЪшЁЃ
Ждгк3DЕудЦЗжИю,етаЉЪ§ОнМЏгЩВЛЭЌРраЭЕФДЋИаЦїЛёШЁ,АќРЈвЦЖЏМЄЙтЩЈУшвЧ (MLS)[15]ЁЂ[34]ЁЂ[36]ЁЂКНПеМЄЙтЩЈУшвЧ(ALS)[33]ЁЂ[38]ЁЂОВЬЌЕиУцМЄЙтЩЈУшвЧ (TLS) [12]ЁЂRGBDЯрЛњ[11] КЭЦфЫћ3DЩЈУшвЧ [10]ЁЃетаЉЪ§ОнМЏПЩгУгкПЊЗЂИїжжЬєеНЕФЫуЗЈ,АќРЈРрЫЦЕФИЩШХЮяЁЂаЮзДВЛЭъећКЭРрБ№ВЛЦНКтЁЃ
2.2 ЦРМлжИБъ
вбОЬсГіСЫВЛЭЌЕФЦРЙРжИБъРДВтЪдетаЉЗНЗЈгУгкИїжжЕудЦРэНтШЮЮёЁЃЖдгк3DаЮзДЗжРр,змЬхзМШЗЖШ(OA)КЭЦНОљРрБ№зМШЗЖШ(mAcc)ЪЧзюГЃгУЕФадФмБъзМЁЃЁАOAЁБДњБэЫљгаВтЪдЪЕР§ЕФЦНОљОЋЖШ,ЁАmAccЁБДњБэЫљгааЮзДРрБ№ЕФЦНОљОЋЖШЁЃЖдгк3DФПБъМьВт,ЦНОљОЋЖШ(AP)ЪЧзюГЃгУЕФБъзМЁЃЫќБЛМЦЫуЮЊОЋШЗейЛиЧњЯпЯТЕФУцЛ§ЁЃ P r e c i s i o n Precision PrecisionКЭ S u c c e s s Success SuccessЭЈГЃгУгкЦРЙР3DЕЅИіФПБъИњзйЕФећЬхадФмЁЃAverage Multi-Object Tracking Accuracy(AMOTA) КЭAverage Multi-Object Tracking Precision (AMOTP) ЪЧЦРЙР3DЖрФПБъИњзйзюГЃгУЕФБъзМЁЃЖдгк3DЕудЦЗжИю,OAЁЂmean Intersection over Union(mIoU) КЭmean class Accuracy (mAcc) [10]ЁЂ[12]ЁЂ[15]ЁЂ[36]ЁЂ[37] ЪЧзюГЃгУЕФадФмЦРЙРБъзМЁЃЬиБ№ЪЧ,ЦНОљОЋЖШ (mAP) [39] вВгУгк3DЕудЦЕФЪЕР§ЗжИюЁЃ
Бэ1:гУгк3DаЮзДЗжРрЁЂ3DФПБъМьВтКЭИњзйвдМА3DЕудЦЗжИюЕФЯжгаЪ§ОнМЏЕФеЊвЊЁЃгУгкЦРЙРЕФРрЪ§КЭДјзЂЪЭЕФРрЪ§(ЯдЪОдкРЈКХжа)
3 3DаЮзДЗжРр
3.1 ЛљгкЖрЪгЭМЕФЗНЗЈ
етаЉЗНЗЈЪзЯШНЋ3DаЮзДЭЖгАЕНЖрИіЪгЭМжаВЂЬсШЁЪгЭМЬиеї,ШЛКѓШкКЯетаЉЬиеївдНјаазМШЗЕФаЮзДЗжРрЁЃЖдгкетаЉЗНЗЈРДЫЕ,ШчКЮНЋЖрИіЪгЭМЬиеїОлКЯГЩвЛИігаЧјБ№ЕФШЋОжБэЪОЪЧвЛИіЙиМќЕФЬєеНЁЃ
MVCNN [40] ЪЧвЛЯюПЊДДадЕФЙЄзї,ЫќМђЕЅЕиНЋЖрЪгЭМЬиеїзюДѓЛЏЮЊвЛИіШЋОжУшЪіЗћЁЃШЛЖј,max-poolingжЛБЃСєЬиЖЈЪгЭМжаЕФзюДѓдЊЫи,ЕМжТаХЯЂЖЊЪЇЁЃMHBN[41]ЭЈЙ§аЕїЫЋЯпадГиЛЏМЏГЩОжВПОэЛ§ЬиеївдВњЩњНєДеЕФШЋОжУшЪіЗћЁЃбюЕШШЫ[42]ЪзЯШРћгУЙиЯЕЭјТчРДРћгУвЛзщЪгЭМЩЯЕФЯрЛЅЙиЯЕ(Р§Шч,Чјгђ-ЧјгђЙиЯЕКЭЪгЭМ-ЪгЭМЙиЯЕ),ШЛКѓОлКЯетаЉЪгЭМвдЛёЕУгаЧјБ№ЕФ3DФПБъБэЪОЁЃДЫЭт,ЛЙЬсГіСЫЦфЫћМИжжЗНЗЈ[43]ЁЂ[44]ЁЂ[45]ЁЂ[46]РДЬсИпЪЖБ№ОЋЖШЁЃгывдЧАЕФЗНЗЈВЛЭЌ,WeiЕШШЫ[47]ЭЈЙ§НЋЖрИіЪгЭМЪгЮЊgrpahНкЕу,дкView-GCNжаЪЙгУСЫгаЯђЭМЁЃШЛКѓНЋгЩОжВПЭМОэЛ§ЁЂЗЧОжВПЯћЯЂДЋЕнКЭбЁдёадЪгЭМВЩбљзщГЩЕФКЫаФВугІгУгкЫљЙЙНЈЕФЭМЁЃзюжеЪЙгУЫљгаМЖБ№ЕФзюДѓГиЛЏНкЕуЬиеїЕФСЌНгРДаЮГЩШЋОжаЮзДУшЪіЗћЁЃ
3.2 ЛљгкЬхЛ§ЕФЗНЗЈ
етаЉЗНЗЈЭЈГЃНЋЕудЦЬхЫиЛЏЮЊ3DЭјИё,ШЛКѓдкЬхЛ§БэЪОЩЯгІгУ3DОэЛ§ЩёОЭјТч(CNN)НјаааЮзДЗжРрЁЃ
MaturanaЕШШЫ[48]в§ШыСЫвЛИіГЦЮЊVoxNetЕФЬхЛ§еМгУЭјТчРДЪЕЯжЮШНЁЕФ3DФПБъЪЖБ№ЁЃWuЕШШЫ[6]ЬсГіСЫвЛжжЛљгкОэЛ§ЩюЖШаХФюЕФ3D ShapeNetsРДбЇЯАРДздИїжж3DаЮзДЕФЕуЕФЗжВМ(гЩЬхЫиЭјИёЩЯЕФЖўНјжЦБфСПЕФИХТЪЗжВМБэЪО)ЁЃЮтЕШШЫ[6]ЬсГіСЫвЛжжЛљгкОэЛ§ЩюЖШаХФюЕФ3D ShapeNetsРДбЇЯАРДздИїжж3DаЮзДЕФЕуЕФЗжВМ(гЩЬхЫиЭјИёЩЯЕФЖўдЊБфСПЕФИХТЪЗжВМБэЪО)ЁЃЫфШЛвбОШЁЕУСЫСюШЫЙФЮшЕФадФм,ЕЋетаЉЗНЗЈЮоЗЈКмКУЕиРЉеЙЕНУмМЏЕФ3DЪ§Он,вђЮЊМЦЫуКЭФкДцеМгУЫцзХЗжБцТЪЕФдіМгГЪСЂЗНдіГЄЁЃ
ЮЊДЫ,в§ШыСЫЗжВуКЭНєДеЕФНсЙЙ(Р§ШчАЫВцЪї)РДМѕЩйетаЉЗНЗЈЕФМЦЫуКЭДцДЂГЩБОЁЃOctNet[49]ЪзЯШЪЙгУЛьКЯЭјИёАЫВцЪїНсЙЙЖдЕудЦНјааЗжВуЛЎЗж,ИУНсЙЙБэЪОбиЙцдђЭјИёЕФЖрИіЧГАЫВцЪїЕФГЁОАЁЃВЩгУЮЛДЎБэЪОЗЈЖдАЫВцЪїНсЙЙНјаагааЇБрТы,ВЂЭЈЙ§МђЕЅЫуЗЈЖдУПИіЬхЫиЕФЬиеїЯђСПНјааЫїв§ЁЃ WangЕШШЫ[50]ЬсГіСЫвЛжжЛљгкАЫВцЪїЕФCNNШ§ЮЌаЮзДЗжРрЗНЗЈЁЃвдзюЯИЕФвЖАЫЗжЧјжаВЩбљЕФ3DФЃаЭ,етИіФЃаЭЕФЦНОљЗЈЯђСПБЛЪфШыЕНЭјТчжа,3D-CNNгІгУгк3DаЮзДБэУцеМОнЕФАЫЗжжЎвЛЁЃгыЛљгкУмМЏЪфШыЭјИёЕФЛљЯпЭјТчЯрБШ,OctNetЖдИпЗжБцТЪЕудЦЫљашЕФФкДцКЭдЫааЪБМфвЊЩйЕУЖрЁЃLeЕШШЫ[51]ЬсГіСЫвЛИіУћЮЊPointGridЕФЛьКЯЭјТч,ЫќМЏГЩСЫЕуКЭЭјИёБэЪО,вдЪЕЯжИпаЇЕФЕудЦДІРэЁЃдкУПИіЧЖШыЬхЛ§ЭјИёЕЅдЊФкВЩбљКуЖЈЪ§СПЕФЕу,етдЪаэЭјТчЭЈЙ§ЪЙгУ3DОэЛ§РДЬсШЁМИКЮЬиеїЁЃBen-ShabatЕШШЫ[52]НЋЪфШыЕудЦзЊЛЛЮЊ3DЭјИё,ВЂНјвЛВНЭЈЙ§3Dаое§Fisher Vector (3DmFV)ЗНЗЈБэЪО,ШЛКѓЭЈЙ§ГЃЙцCNNМмЙЙбЇЯАШЋОжБэЪОЁЃ
ЭМ2ЁЂзюЯрЙиЕФЛљгкЩюЖШбЇЯАЕФ3DаЮзДЗжРрЗНЗЈЕФЪБађИХЪіЁЃ
3.3 ЛљгкЕуЕФЗНЗЈ
ИљОнгУгкУПИіЕуЕФЬиеїбЇЯАЕФЭјТчНсЙЙ,етРрЗНЗЈПЩвдЗжЮЊж№ЕуMLPЁЂЛљгкОэЛ§ЁЂЛљгкЭМЁЂЛљгкЗжВуЪ§ОнНсЙЙЕФЗНЗЈКЭЦфЫћЕфаЭЗНЗЈЁЃ
3.3.1 ж№ЕуMLPЗНЗЈ
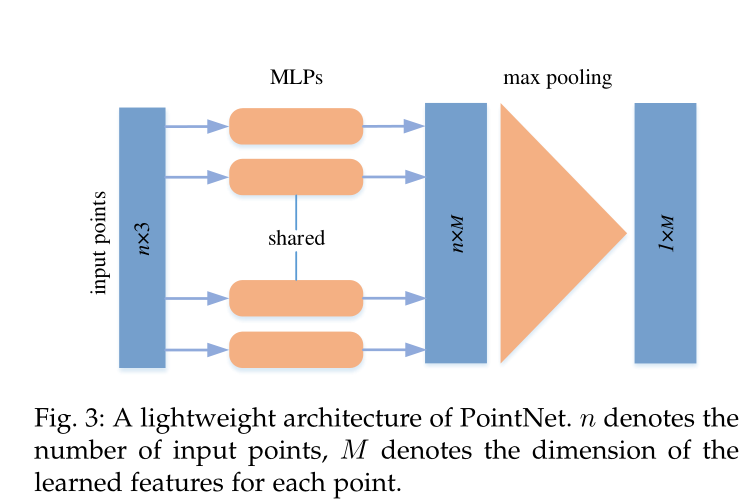
етаЉЗНЗЈгУМИИіЙВЯэЕФЖрВуИажЊ(MLP)ЖРСЂЕиЖдУПИіЕуНЈФЃ,ШЛКѓЪЙгУЖдГЦОлКЯКЏЪ§ОлКЯвЛИіШЋОжЬиеї,ШчЭМ3ЫљЪОЁЃ
ЭМ3ЁЂвЛжжЧсСПМЖЕФPointNetМмЙЙЁЃnБэЪОЪфШыЕуЕФЪ§СП,MБэЪОУПИіЕуЕФбЇЯАЬиеїЕФЮЌЪ§
гУгк2DЭМЯёЕФЕфаЭЩюЖШбЇЯАЗНЗЈгЩгкЦфЙЬгаЕФЪ§ОнВЛЙцдђадЖјВЛФмжБНггІгУгк3DЕудЦЁЃзїЮЊвЛЯюПЊДДадЕФЙЄзї,PointNet[5]жБНгвдЕудЦЮЊЪфШы,гУвЛИіЖдГЦКЏЪ§ЪЕЯжжУЛЛВЛБфадЁЃОпЬхРДЫЕ,PointNetЭЈЙ§МИИіMLPВуЖРСЂбЇЯАж№ЕуЬиеї,ВЂЭЈЙ§зюДѓГиЛЏВуЬсШЁШЋОжЬиеїЁЃDeep sets[53]ЭЈЙ§ЖдЫљгаБэЪОЧѓКЭВЂгІгУЗЧЯпадБфЛЛРДЪЕЯжжУЛЛВЛБфадЁЃгЩгкPointNet[5]жаУПИіЕуЕФЬиеїЖМЪЧЖРСЂбЇЯАЕФ,вђДЫЮоЗЈВЖЛёЕужЎМфЕФОжВПНсЙЙаХЯЂЁЃвђДЫ,QiЕШШЫ[54]ЬсГіСЫвЛжжЗжВуЭјТчPointNet++РДДгУПИіЕуЕФСкгђжаВЖЛёОЋЯИЕФМИКЮНсЙЙЁЃзїЮЊPointNet++ВуДЮНсЙЙЕФКЫаФ,ЫќЕФМЏКЯГщЯѓВугЩШ§ВузщГЩ:ВЩбљВуЁЂЗжзщВуКЭЛљгкPointNetЕФбЇЯАВуЁЃPointNet++ЭЈЙ§ЖбЕўМИИіМЏКЯГщЯѓВуДЮ,ДгвЛИіОжВПМИКЮНсЙЙжабЇЯАЬиеї,ВЂж№ВуГщЯѓОжВПЬиеїЁЃ
гЩгкЫќЕФМђЕЅадКЭЧПДѓЕФБэЪОФмСІ,аэЖрЭјТчЖМЪЧЛљгкPointNetПЊЗЂЕФ[5]ЁЃMo-Net[55]ЕФМмЙЙРрЫЦгкPointNet[5],ЕЋЫќвдгаЯоЕФОизїЮЊЪфШыЁЃPoint Attention Transformers(PATs)[56]ЭЈЙ§ЦфздЩэЕФОјЖдЮЛжУКЭЯрЖдгкЦфЯрСкЕФЯрЖдЮЛжУРДБэЪОУПИіЕу,ВЂЭЈЙ§MLPsбЇЯАИпЮЌЬиеїЁЃШЛКѓ,Group Shuffle Attention (GSA)РДВЖЛёЕужЎМфЕФЙиЯЕ,ВЂПЊЗЂжУЛЛВЛБфЁЂПЩЮЂЗжКЭПЩбЕСЗЕФЖЫЕНЖЫGumbel Subset Sampling(GSS)ВуРДбЇЯАЗжВуЬиеїЁЃЛљгкPointNet++[54],PointWeb[57]РћгУОжВПСкгђЕФЩЯЯТЮФ,ЭЈЙ§Adaptive Feature Adjustment(AFA)РДИФЩЦЕуЬиеїЁЃDuanЕШШЫ[58]ЬсГіСЫвЛжжStructural Relational Network(SRN)РДбЇЯАВЛЭЌОжВПНсЙЙжЎМфЕФНсЙЙЙиЯЕЬиеїЪЙгУMLPЁЃLinЕШШЫ[59]ЭЈЙ§ЮЊPointNetбЇЯАЕФЪфШыКЭКЏЪ§ПеМфЙЙНЈВщевБэРДМгЫйЭЦРэЙ§ГЬЁЃдкModelNetКЭShapeNetЪ§ОнМЏЩЯЕФЭЦРэЪБМфБШPointNetдкжааЭЛњЦїЩЯМгПьСЫ1.5msКЭ32БЖЁЃSRINet[60]ЪзЯШЭЖгАЕудЦвдЛёЕУа§зЊВЛБфБэЪО,ШЛКѓРћгУЛљгкЕуЭјЕФжїИЩЬсШЁШЋОжЬиеї,ВЂРћгУЛљгкЭМЕФОлКЯЬсШЁОжВПЬиеїЁЃдкPointASNLжа,YanЕШШЫ[61]РћгУAdaptive Sampling(AS)ФЃПщРДздЪЪгІЕїећFurthest Point Sampling(FPS)ЫуЗЈЫљВЩбљЕФЕуЕФзјБъКЭЬиеї,ВЂЬсГівЛИіlocal-non-local(L-NL)ФЃПщРДВЖзНетаЉВЩбљЕуЕФОжВПКЭдЖОрРывРРЕадЁЃ
3.3.2 ЛљгкОэЛ§ЕФЗНЗЈ
гыдк2DЭјИёНсЙЙ(Р§Шч,ЭМЯё)ЩЯЖЈвхЕФКЫЯрБШ,гЩгкЕудЦЕФВЛЙцдђад,гУгк3DЕудЦЕФОэЛ§КЫКмФбЩшМЦЁЃИљОнОэЛ§КЫЕФРраЭ,ЕБЧАЕФ3DОэЛ§ЗНЗЈПЩвдЗжЮЊСЌајКЭРыЩЂОэЛ§ЗНЗЈ,ШчЭМ4ЫљЪОЁЃ
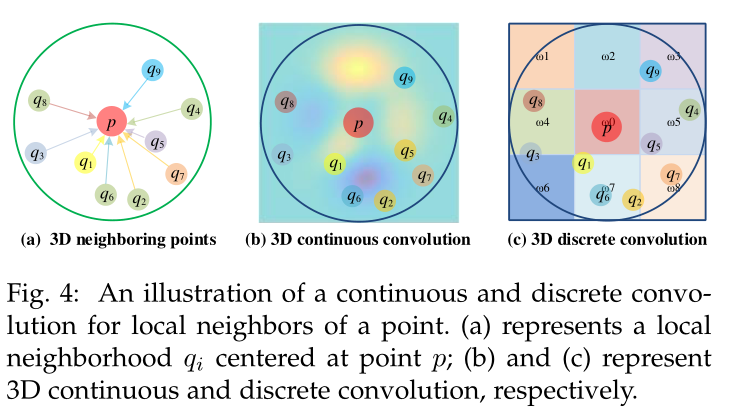
Ш§ЮЌСЌајОэЛ§ЗНЗЈЁЃ етаЉЗНЗЈдкСЌајПеМфЩЯЖЈвхОэЛ§КЫ,ЦфжаЯрСкЕуЕФШЈжигыЯрЖдгкжааФЕуЕФПеМфЗжВМЯрЙиЁЃ
ЭМ4ЁЂЕуЕФОжВПСкгђЕФСЌајКЭРыЩЂОэЛ§ЕФЭМЪОЁЃ(a)БэЪОвдЕу p p pЮЊжааФЕФОжВПСкгђ q i q_{i} qi?;(b)КЭ?ЗжБ№БэЪО3DСЌајКЭРыЩЂОэЛ§
3DОэЛ§ПЩвдНтЪЭЮЊИјЖЈзгМЏЩЯЕФМгШЈКЭЁЃзїЮЊRS-CNN[62]ЕФКЫаФВу,RSConvвдФГвЛЕужмЮЇЕФЕуЕФОжВПзгМЏзїЮЊЦфЪфШы,ЭЈЙ§бЇЯАОжВПзгМЏжаЕФЕужЎМфДгЕЭМЖЙиЯЕ(ШчХЗМИРяЕТОрРыКЭЯрЖдЮЛжУ)ЕНИпМЖЙиЯЕЕФгГЩф,ЪЙгУMLPЪЕЯжОэЛ§ЁЃдк[63]жа,дкЕЅЮЛЧђжаЫцЛњбЁдёКЫдЊЫиЁЃШЛКѓЪЙгУЛљгкMLPЕФСЌајКЏЪ§РДНЈСЂКЫдЊЫиЕФЮЛжУКЭЕудЦжЎМфЕФЙиЯЕЁЃдкDensePoint[64]жа,ОэЛ§БЛЖЈвхЮЊОпгаЗЧЯпадМЄЛюЕФSingleLayer Perceptron(SLP)ЁЃЭЈЙ§СЌНгРДздЫљгаЯШЧАВуЕФЬиеївдГфЗжРћгУЩЯЯТЮФаХЯЂРДбЇЯАЬиеїЁЃThomasЕШШЫ[65]ЬсГіСЫИеадКЭПЩБфаЮKernel Point Convolution(KPConv)Ыузг,гУгкЪЙгУвЛзщПЩбЇЯАЕФКЫЕуЕФ3DЕудЦЁЃConvPoint[66]НЋОэЛ§КЫЗжЮЊПеМфВПЗжКЭЬиеїВПЗжЁЃПеМфВПЗжЕФЮЛжУДгЕЅЮЛЧђжаЫцЛњбЁдё,ВЂЧвЭЈЙ§МђЕЅЕФMLPбЇЯАМгШЈКЏЪ§ЁЃ
вЛаЉЗНЗЈЛЙЪЙгУЯжгаЫуЗЈРДжДааОэЛ§ЁЃдкPointConv[67]жа,ОэЛ§БЛЖЈвхЮЊЙигкживЊадВЩбљЕФСЌај3DОэЛ§ЕФMonte CarloЙРМЦЁЃОэЛ§КЫгЩМгШЈКЏЪ§(ЭЈЙ§MLPВубЇЯА)КЭУмЖШКЏЪ§(ЭЈЙ§КЫЛЏУмЖШЙРМЦКЭMLPВубЇЯА)зщГЩЁЃЮЊСЫЬсИпДцДЂКЭМЦЫуаЇТЪ,3DОэЛ§БЛНјвЛВНМђЛЏЮЊСНИіВйзї:ОиеѓГЫЗЈКЭ2DОэЛ§ЁЃдкЯрЭЌЕФВЮЪ§ЩшжУЯТ,ЦфФкДцЯћКФПЩвдМѕЩй64БЖзѓгвЁЃдкMCCNN[68]жа,ОэЛ§БЛШЯЮЊЪЧвЛИівРРЕгкбљБОУмЖШКЏЪ§ЕФMonte CarloЙРМЦЙ§ГЬ(ЭЈЙ§MLPЪЕЯж)ЁЃВДЫЩХЬВЩбљШЛКѓБЛгУгкЙЙНЈЕудЦВуДЮЁЃДЫОэЛ§дЫЫуЗћПЩгУгкдкСНжжЛђЖржжВЩбљЗНЗЈжЎМфжДааОэЛ§,ВЂЧвПЩвдДІРэВЛЭЌЕФВЩбљУмЖШЁЃдкSpiderCNN[69]жа,SpiderConvЬсГіНЋОэЛ§ЖЈвхЮЊНздОКЏЪ§КЭЖЈвхдкkИізюНќСкЩЯЕФЬЉРееЙПЊЕФГЫЛ§ЁЃНздОКЏЪ§ЭЈЙ§ЖдОжВПВтЕиОрРыНјааБрТыРДВЖЛёДжТдЕФМИКЮаЮзД,ЖјЬЉРееЙПЊЭЈЙ§дкСЂЗНЬхЕФЖЅЕуДІВхжЕШЮвтжЕРДВЖЛёФкдкЕФОжВПМИКЮБфЛЏЁЃДЫЭт,ОэЛ§ЭјТчPCNN[70]вВЬсГіСЫШ§ЮЌЕудЦЕФЛљДЁЩЯОЖЯђЛљКЏЪ§ЁЃ
вбОЬсГіСЫМИжжЗНЗЈРДНтОі3DОэЛ§ЭјТчЫљУцСйЕФа§зЊЕШБфЮЪЬтЁЃEstevesЕШШЫ[71]ЬсГіСЫ3DЧђаЮCNNРДбЇЯА3DаЮзДЕФа§зЊЕШБфБэЪО,ЦфВЩгУЖржЕЧђаЮКЏЪ§зїЮЊЦфЪфШыЁЃЭЈЙ§гУЧђаГгђжаЕФУЊЕуВЮЪ§ЛЏЦЕЦзРДЛёЕУОжВПОэЛ§ТЫВЈЦїЁЃеХСПГЁЭјТч[72]БЛЬсвщНЋЕуОэЛ§дЫЫуЖЈвхЮЊПЩбЇЯАЕФОЖЯђКЏЪ§КЭЧђаГКЏЪ§ЕФГЫЛ§,ЦфЖдгк3Dа§зЊЁЂЦНвЦКЭжУЛЛЪЧОжВПЕШБфЕФЁЃ[73]жаЕФОэЛ§ЪЧЛљгкЧђаЮЛЅЯрЙиЖЈвхЕФ,ВЂЪЙгУЙувхПьЫйИЕСЂвЖБфЛЛ(FFT)ЫуЗЈЪЕЪЉЁЃЛљгкPCNN,SPHNet[74]ЭЈЙ§дкЬхЛ§КЏЪ§ЕФОэЛ§Й§ГЬжав§ШыЧђаГКЫРДЪЕЯжа§зЊВЛБфадЁЃ
ЮЊСЫМгПьМЦЫуЫйЖШ,Flex-Convolution[75]НЋОэЛ§КЫЕФШЈжиЖЈвхЮЊkНќСкЩЯЕФБъзМБъСПЛ§,ПЩвдЪЙгУCUDAНјааМгЫйЁЃЪЕбщНсЙћБэУї,ИУЫуЗЈдкВЮЪ§НЯЩйЁЂФкДцЯћКФНЯЕЭЕФаЁЪ§ОнМЏЩЯОпгаСМКУЕФадФмЁЃ
Ш§ЮЌРыЩЂОэЛ§ЗНЗЈЁЃ етаЉЗНЗЈдкЙцдђЭјИёЩЯЖЈвхОэЛ§КЫ,ЦфжаЯрСкЕуЕФШЈжигыЯрЖдгкжааФЕуЕФЦЋвЦгаЙиЁЃ
HuaЕШШЫ[76]НЋЗЧОљдШ3DЕудЦзЊЛЛЮЊОљдШЭјИё,ВЂдкУПИіЭјИёЩЯЖЈвхОэЛ§КЫЁЃ етИіЬсвщЕФ3DФкКЫЮЊТфШыЭЌвЛЭјИёЕФЫљгаЕуЗжХфЯрЭЌЕФШЈжиЁЃ ЖдгкИјЖЈЕФЕу,ЮЛгкЭЌвЛЭјИёЩЯЕФЫљгаЯрСкЕуЕФЦНОљЬиеїЖМЪЧДгЩЯвЛВуМЦЫуГіРДЕФЁЃ ШЛКѓ,ЖдЫљгаЭјИёЕФЦНОљЬиеїНјааМгШЈКЭЧѓКЭ,вдЩњГЩЕБЧАВуЕФЪфГіЁЃ LeiЕШШЫ[77]ЖЈвхСЫвЛИіЧђаЮОэЛ§КЫ,НЋвЛИі3DЧђаЮЯрСкЧјгђЛЎЗжЮЊЖрИіЬхЛ§ЕЅдЊ,ВЂНЋУПИіЕЅдЊгывЛИіПЩбЇЯАЕФМгШЈОиеѓЯрЙиСЊЁЃ вЛИіЕуЕФЧђаЮОэЛ§КЫЕФЪфГігЩЦфЯрСкЕуЕФМгШЈМЄЛюжЕЕФЦНОљжЕЕФЗЧЯпадМЄЛюРДШЗЖЈЁЃдкGeoConv[78]жа,вЛИіЕугыЦфЯрСкЕужЎМфЕФМИКЮЙиЯЕЪЧЛљгкСљИіЛљЯдЪННЈФЃЕФЁЃбизХЛљЕФУПИіЗНЯђЕФБпдЕЬиеїгЩЗНЯђЯрЙиЕФПЩбЇЯАОиеѓЖРСЂМгШЈЁЃШЛКѓИљОнИјЖЈЕуКЭЫќЕФЯрСкЕуаЮГЩЕФНЧЖШОлМЏетаЉЗНЯђЯрЙиЕФЬиеїЁЃЖдгкИјЖЈЕу,ЦфдкЕБЧАЭМВуЕФЬиеїБЛЖЈвхЮЊИјЖЈЕуЕФЬиеїгыЦфдкЧАвЛЭМВуЕФЯрСкБпЬиеїЕФзмКЭЁЃPointCNN[79]ЭЈЙ§Іж-convзЊЛЛ(ЭЈЙ§MLPЪЕЯж)НЋЪфШыЕузЊЛЛЮЊПЩФмЕФЙцЗЖЫГађ,ШЛКѓЖдзЊЛЛКѓЕФЬиеїгІгУЕфаЭЕФОэЛ§ЫузгЁЃЭЈЙ§НЋЕуЬиеїВхжЕЕНЯрСкЕФРыЩЂОэЛ§КЫШЈжизјБъ,MaoЕШШЫ[80]ЬсГіСЫВхжЕОэЛ§ЫузгInterpConv,вдВтСПЪфШыЕудЦКЭКЫШЈжизјБъжЎМфЕФМИКЮЙиЯЕЁЃеХЕШШЫ[81]ЬсГіСЫвЛжжRIConvЫузгРДЪЕЯжа§зЊВЛБфад,ЫќНЋlow-levelа§зЊВЛБфЕФМИКЮЬиеїзїЮЊЪфШы,ШЛКѓЭЈЙ§МђЕЅЕФbinningЗНЗЈНЋОэЛ§зЊЛЛЮЊвЛЮЌЁЃA-CNN[82]ЭЈЙ§ЯрЖдгкВщбЏЕуЕФУПИіЛЗЩЯЕФКЫЕФДѓаЁ,ШЛКѓбЛЗЯрСкЕуЕФеѓСаРДЖЈвхЛЗаЮОэЛ§,ВЂбЇЯАОжВПзгМЏжаЯрСкЕужЎМфЕФЙиЯЕЁЃ
ЮЊСЫНЕЕЭ3D CNNЕФМЦЫуКЭДцДЂГЩБО,KumawatЕШШЫ[83]ЬсГіСЫвЛжжЛљгк3DShort Term Fourier Transform(STFT)ЕФRectified Local Phase Volume(ReLPV)ПщРДЬсШЁ3DОжВПСкгђжаЕФЯрЮЛ,етЯджјМѕЩйСЫВЮЪ§Ъ§СПЁЃ дкSFCNN[84]жа,ЕудЦБЛЭЖгАЕНОпгаЖдЦыЕФЧђУцзјБъЕФе§ЖўЪЎУцЬхЭјИёЩЯЁЃШЛКѓ,ЭЈЙ§ОэЛ§зюДѓГиЛЏОэЛ§НсЙЙ,ЖдЧђУцОЇИёЖЅЕуМАЦфСкгђСЌНгЕФЬиеїНјааОэЛ§ЁЃSFCNNФмЙЛЕжПЙа§зЊКЭШХЖЏЁЃ