TextFuseNet: Scene Text Detection with Richer Fused Features
һЩ�ܽ�,��������������:
ʵ������ȥͨ���ı�����ж༶���Ŀ���ںϵķ������������Ч����,���ļ�ֵ��ʵ����������
- �����һ������Mask-RCNN�������Լ����֦�Ľṹʵ�ֶ�������ںϷ���,��ȫ������->������+�ַ��������������ּ��Ч�����������Ʒdz��dz�����,���Ƕ�Ӧ�������ٶ���Խ���ResNet-50��backbone��ֻ��7-8FPS��
- ��һ���������û���ַ���ע������¸�����һ�����ֱ�۵����ල�ķ�ʽ���ƽ�ѵ����
������������˷���,���Ƿ�������������(🐻���˹۵�,����)��
Section 1 ����
��ǰ�ij����ı������Ҫ��Ϊ���ֲ�ͬ������,�����ַ��ͻ��ڴʵ���ʽ�ļ�⡣ǰ�ߵ��������ı����ַ������ܶࡢ���+�ںϵ��ٶ�����������Ч���ܲ�����(🐱����û˵Ч�����ÚG)����������ͨ��Ŀ�����pipeline������,���ܼ��������ڶ�������״�ı���֧�ֲ���̫�á�����Ҳ��һЩ����ʵ���ָ�ķ���,������ҪҲ����������Ҫȱ�ݡ�������������RoI��ȱ��ȫ���Ӿ���Ϣ,���¼��Ч�����ѡ�����,�����û�жԲ�ͬ�㼶�ĵ�������Ϣ���н�ģ,��ɼ����Ե����⡣���Բο���ͼ��

�ı������һ���µij����ı�����ܽ�TextFuseNet,�ο���Mask-RCNN��Mask-TextSpotterȻ����Ϊ����Ϊһ��ʵ���ָ�����������ع���Mask-RCNN,ʹ�����յ����ּ���ܹ��õ��ں�����levels�ϵ�������ʾ(�ַ����ʡ�ȫ��)��
��������,����������һ�����������ָ��֧������ȡ�ͱ���ȫ��������ʾ��ȫ������������Ϣ����ᱻ����ָ������MASK��֧��Ŀ��ֵԤ�⡣Ȼ������MASK-RCNN����еļ���֧��MASK��֧��ȡ�ַ��ʹʼ������������ԭʼ��MASK-RCNN���,TextFusedNetͬʱ���ͷָ��ַ����ʡ����ȫ������,�����˶�·�������ںϽṹ����ѧϰһ���������б�����������ʾ��
��Ե�ǰ���ݼ�����ȱ�ٵ����ַ��ı�ǩ�����Ϣ,��һ��������һ�����ලѧϰ�������Ӵʱ�ע���ݼ��������ַ�����ı�ע��Ϣ��
��������:
- �����TextFuseNet,�ں�������������������·�������ںϡ�
- ��������Ŀ��,������һ�����ල��ѧϰ����,ʹ��ģ���ܹ����Ӵʱ�ע��Ϣ�н���ѧϰ����Ҫ��ϸ���ַ���ע��Ϣ��
- SOTA��
Section 2 ��ع���
Character-based methods
ͨ�õ��ַ��������SWT, MSER, FASText,ͨ������ѡ�ַ�,Ȼ������һ���ַ�/���ַ��ķ�������ȥ�������ԡ����ʣ�µ��ַ���������֪ʶ���߾��ࡢ�����㷨�������ϡ����Ǵ�������ַ���ⷽ����Ҫ���ɵ���ƺͶ�εĴ�������ᵼ�����ջ�ģ�ͺܸ���,�����в����Ĵ���Ҳ���ۼ�,������������ʱ�����ܲ��ѡ�
Word-based methods
�ܵ�ͨ���ı����ķ���,���ڴʵļ�ⷽ��ֱ�Ӽ����ı���CTPN, TextBoxes++֮����ܶ�,������Щ��������������ˮƽ���߶�Ƕȵ����⡣
Ϊ�˽������Ƕ��ı���������,�������ʵ���ָ��ģ�ͱ����,SPCNet, PSENet֮��ĺܶࡣ
Section 3 ����
3.1 Framework
��ͼ������TextFuseNet�������ṹ��������ȡ��㼶��������ʾ,Ȼ�����ö�·�������ں���ʵ���ı���⡣��Ҫ����,��ܴ��������ģ��:
- FPN ������ȡ�������
- RPN �����ı������
- ����ָ��֧��ȫ��������Ϣ
- ����֧���ڼ���ַ�����ı�
- Mask��ʱ��ʵ���ָ��ַ�����ı�
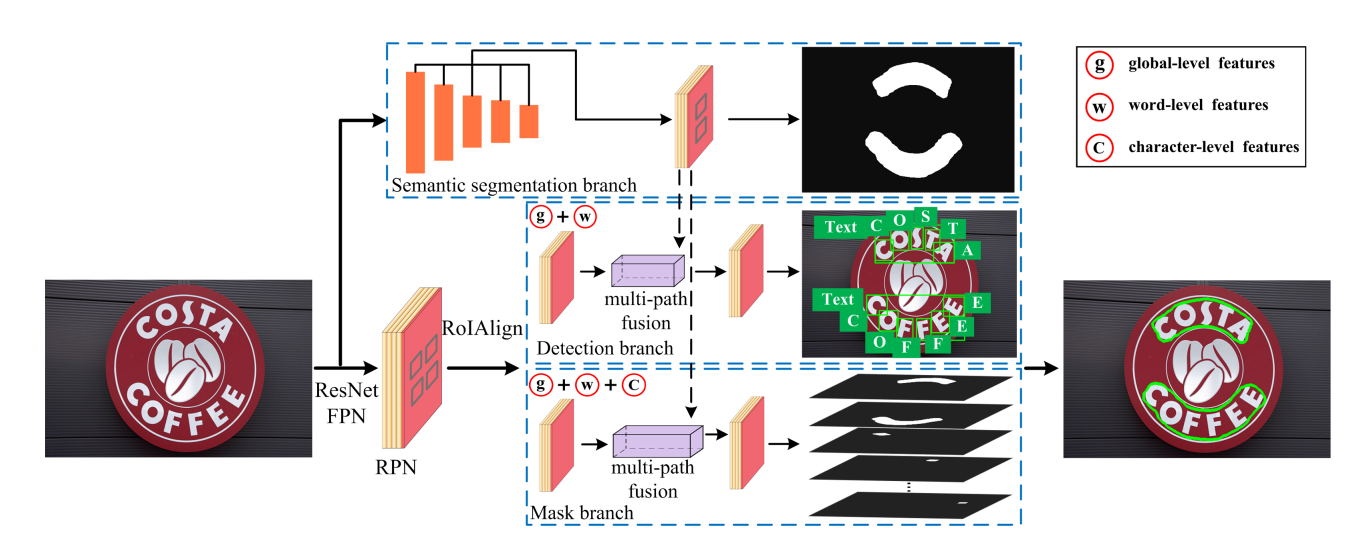
��TextFuseNet��,��Mask-RCNN�Լ�Mask-TextSpotterһ��,������ResNet��Ϊbackbone�Լ�FPN����������ʹ����RPN�������ı���������ں����ļ���MASK��֧��Ȼ��Ϊ����ȡ���������ʾ,���Dz��������µ�ʵ�֡�
- ����,����������һ���µ�����ָ��֧,������ͼ���������ָ�,�������ȫ�ּ���������
- �ڼ���֧��,ͨ��Ԥ������boudning box�ع�ķ������ı����������о�ϸ��,����ȡ���ں��˵��ʺ�ȫ�ּ��������,�Ӷ�ͬʱ��ⵥ�ʺ��ַ����뵱ǰ�ij��淽����һ���ĵط����ڳ��淽��ÿ�������ֻ���һ���ַ������ʱ���,��ϸ�ļ�3.2�½ڡ�
- ����ȡ�����������,���������һ�ֶ�·���ںϽṹ���ںϲ�ͬ�����������������״���ı�,ϸ�ڼ�3.3�½ڡ�
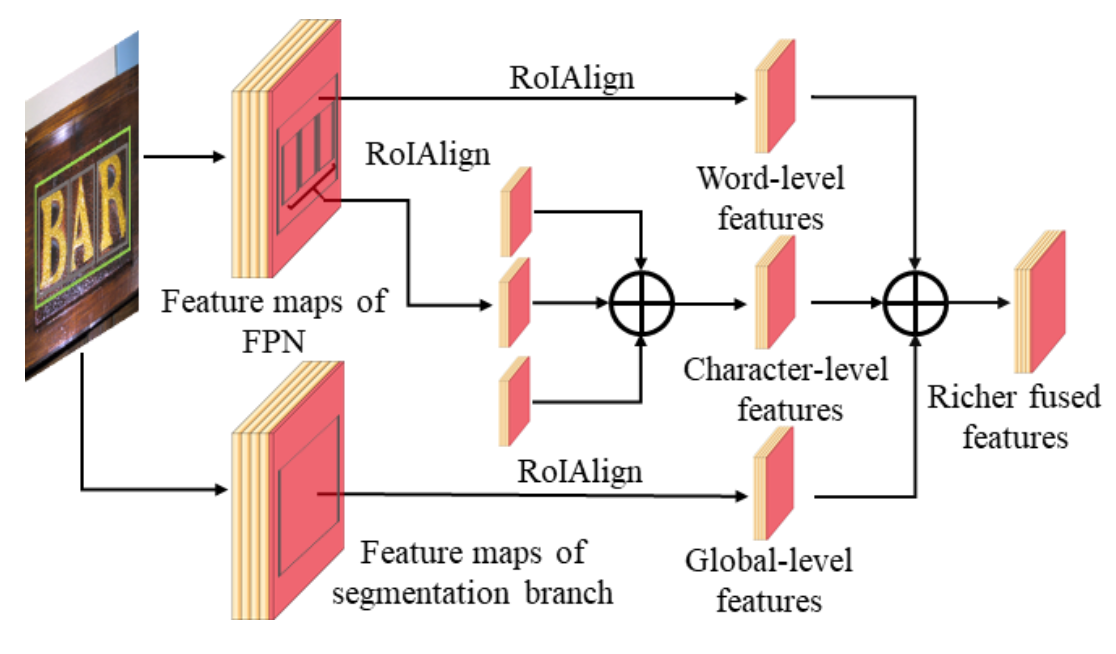
3.2 Multi-level Feature Representation
ͨ����˵�༶���������������ȡ��,����������Ҫ��������ȡ������һ����������������ȡȫ��������������������һ��ʹ��һ������ָ��֧������ָ��֧����FPN�����,�ں������в�ε�������һ��ͳһ�ı�����ȥ�Ӷ����һ��ȫ�ֵķָ�������ʵ����,ʹ����1x1����������ͨ������,���resize����֤�ߴ�һ�¡�
3.3 Multi-path Fusion Architecture
��RPN�дӲ�ͬ��·������ȡ��ȫ�֡��ʼ��������,����Щ���������ں�,ʹ�������ܹ�����ַ��ʹʼ������ע�����ﲢû�м����ַ�����,��Ϊ�ַ������ڼ���֧֮ǰ����û�б��������ʵ����ʵ��,�ڸ���һ�����ɵ������,����ʹ��RoIAlign��7x7������ͼ������ȡȫ�ֺʹ�������Ȼ����element-wise add��һ��3x3 + 1x1������������,��ô������������������ڷ���Ϳ�ع顣
��MASK��֧,����ʹ��������ͬ��������������ں�����ʵ���ָ��ͼչʾ����ϸ�Ķ�·���ںϵĽṹ��
��ʽ��������,����һ���ʱ��Ϊ r i r_i ri?,����ʶ�����е��ַ���� C i C_i Ci?,ͨ���ַ���������IoU���ж��Ƿ������ʹ�� c j c_j cj?����ʾ�ַ�,��ô�ַ��� C i C_i Ci?�Ƿ����������ǾͿ��Ա���ʾΪ����ʽ
C i = { c i �O b i �� b j b j > T } C_i = \left\{ c_i | \frac{b_i \cap b_j }{b_j} > T \right\} Ci?={ci?�Obj?bi?��bj??>T}
���� b i bi bi�� b j b_j bj?��ʾ r i r_i ri?�ع����ַ�ʵ�� c j c_j cj?, T T TΪ��ֵ,����Ϊ0.8��
�����ַ���ʵ�������̶�,���Դ�û�е��ϰ�,��˳����ں��ַ��ļ��� C i C_i Ci?��Ӧ�������ں�Ϊһ��ͳһ�ı�ʾ��������������������RoIAlign��14x14��С������ͼ���� C i C_i Ci?������,Ȼ�����Щ����ͨ��element-wise add + 3x3 + 1x1�����ںϡ�
Overall Objective
��ʽ��������,��ʧ�������Ա�����Ϊ
L = L r p n + L s e g + L d e t + L m a s k L = L_{rpn} + L_{seg} + L_{det} + L_{mask} L=Lrpn?+Lseg?+Ldet?+Lmask?
�������ֱַ�ΪRPN,����ָ��֧,����֧�Լ�MASK��֧��Ӧ����ʧ��
3.4 Weakly Supervised Learning
����TextFuseNet����ʽΪͬʱ�����ı����ַ�,ʵ�ֿ�ܵ�ѵ������Ҫ�ַ�����ı�ע��Ϣ����������֮ǰ������,�ַ�����ı�ע���ݼ��������ڡ����ǵ�ʱ��ͳɱ�����,����ȥ�������ලѧϰ�ķ�����ָ��ѧϰѵ������������Ϊ�����������ල���ݼ�ѵ��(🐻�������ߵ���˼�����������ݼ��ڰ������ַ��ʹ��ı����ּ��������)��Ԥѵ��ģ���������ַ�����ѵ��������Ȼ��,��ֻ���ʱ�ע���ݵ����ݼ� A A A������Ԥѵ���õ�ģ�� M M Mȥ�����ַ������ѵ��������
�����������,������ M M M�����ݼ� A A A��Ԥ��,�������ݼ� A A A�е�ÿһ��ͼ�������л��������º�ѡ����:
R = { r o ( c 0 , s 0 , b 0 , m 0 ) , r 1 ( c 1 , s 1 , b 1 , m 1 ) , ? ? , r i ( c i , s i , b i , m i ) , ? ? } R = \left\{ r_o(c_0, s_0, b_0, m_0), r_1(c_1, s_1, b_1, m_1), \dotsm, r_i(c_i, s_i, b_i, m_i), \dotsm \right\} R={ro?(c0?,s0?,b0?,m0?),r1?(c1?,s1?,b1?,m1?),?,ri?(ci?,si?,bi?,mi?),?}
���� c i , s i , b i , m i c_i, s_i, b_i, m_i ci?,si?,bi?,mi?�ֱ��ʾ r i r_i ri?�е� i i i���ַ���Ԥ��������Ŷȡ��ع���Լ�mask��Ĥ��Ȼ���������Ŷ���ֵ�Լ�IoU�ȷ�ʽ�����ɵļ������������˵�,��������
P = { ( c i , s i ) �O c i �� C a n d s i > S a n d ( m i �� g i ) m i > T } P = \left\{ (c_i, s_i) | c_i \in C and s_i > S and \frac{(m_i \cap g_i)}{m_i} > T \right\} P={(ci?,si?)�Oci?��Candsi?>Sandmi?(mi?��gi?)?>T}
���� C C C��ʾ���б����������ַ����, S S S��ʾ�ж������Կ�����Ŷ���ֵ�� ( m i �� g i ) m i \frac{(m_i \cap g_i)}{m_i} mi?(mi?��gi?)?��ʾ�ʼ����ע�ͺ�ѡ�ַ���ע���غ϶�(🐻������ǰ���ڲ��ı���),��Ӧ����ֵ����Ϊ T T T������ֵһ����0.1һ����0.8��
Section 4 ʵ��
���岻����,���ݼ�����SynthText, ICDAR2013, ICDAR2015, Total-Text, CTW-1500��
ѵ���ֳ�������,������SynthText��Ԥѵ��(�����ַ��ʹʱ�ע),Ȼ����ICDAR2015, Total-Text, CTW-1500�������ַ���ע����,Ȼ������Щ�ַ���ע����ȥfinetuneģ�͡�
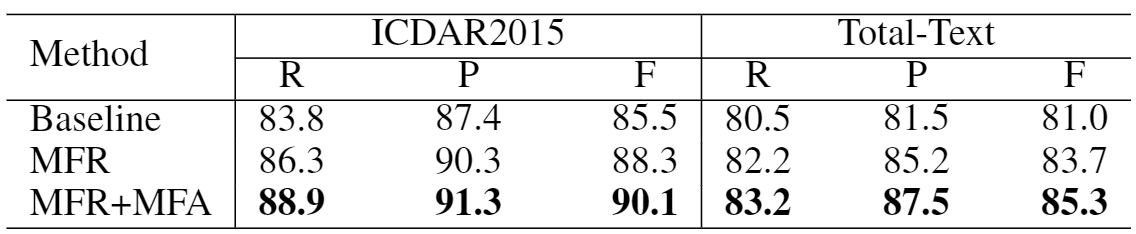
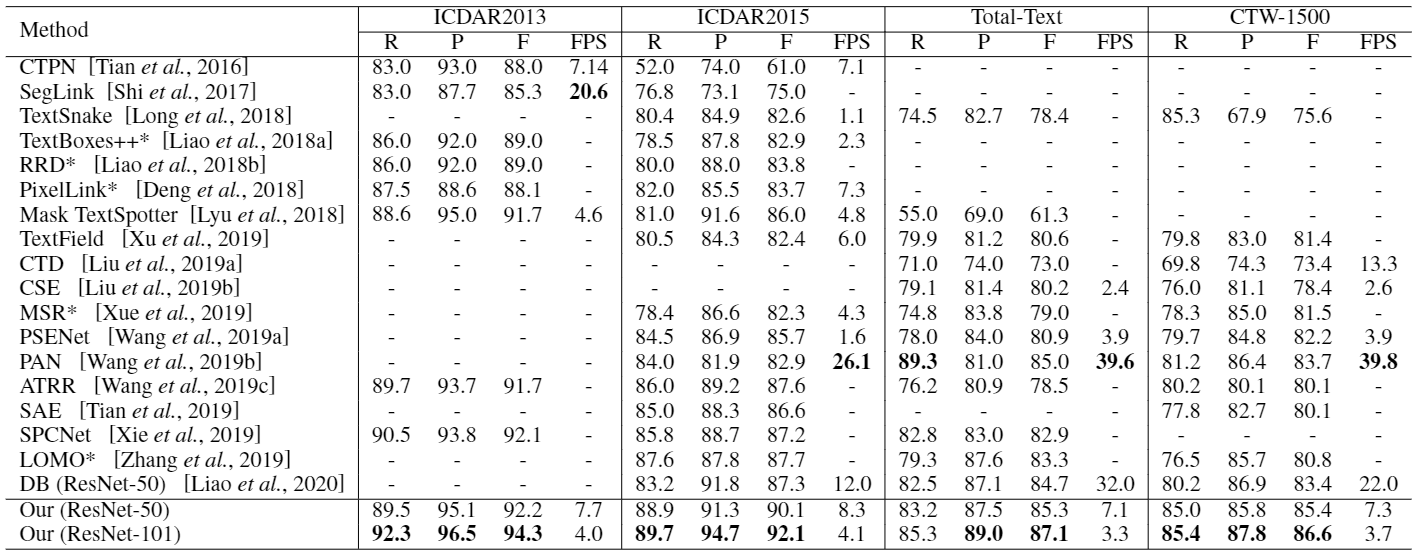
�������ܱ��ּ�����ı���
Section 5 �ܽ�
🐻�ܽ�!