ЯЙГЖМИОф
КУОУУЛаДЙ§СЫ,ЩдЩдМЧТМвЛЯТзюНќЕФЪеЛё,зюНќЯюФПЩЯашвЊгУЗжИюЭјТч,Ъ§ОнМЏЪЧБъзЂКУСЫ,ЕЋЪЧетБъзЂГіРДЕФЮФМўЪЧJSONИёЪН,ВЛФмжБНггУгкЗжИюЭјТчЁЃФбЪм,ВщСЫвЛЯТашвЊзЊГЩЖўжЕЛЏЕФКкАзЕФpngИёЪНЭМЯё,рХЁЄЁЄЁЄЁЄЁЄ,png,етjsonЛЙФмећГЩpng, рХЁЄЁЄЁЄЁЄЭјЩЯевСЫвЛЯТ,КУЖр,ЕЋЪЧИаОѕЖМВЛППЦз,ДѓЖрЖМЪЧАыГЩЦЗ,жЛЪЧРћгУСЫlabelmeздДјЕФФЧИіlabelme_json_to_dataset.exeЪЕЯжСЫЕквЛВНзЊЛЛ,етИіХњСПзЊГіРДУПИіjsonЖМаТНЈвЛИіЮФМўМа,етЫЖЅЕУзЁ,ЖјЧвжБНгзЊЛЛГіРДЕФpng,КЭашвЊЕФВЛвЛбљ,ЛЙашвЊдкзЊЛЛвЛДЮ,етЁЄЁЄЁЄЁЄЁЄ,ЬЋЗбЪТСЫ,зюКѓдкУЃУЃДѓКЃжаевЕНвЛЮЛВЉжї,етИіВЉжїаДЕФКУ,ЪЧецЕФКУ,ЮвНгЯТРДЫљзіЕФОЭЪЧАДееетИіВЉжїЕФВНжшећГіРД,ЫЕЕНетИаОѕЯёЪЧАзцЮЕФвЛбљ,ВЛ,ВЛЪЧЕФ,ЮвЛЙЖдДњТызіСЫИФНјгХЛЏ,ЫфШЛММЪѕадВЛЧП,ЕЋЪЧвВМЧТМвЛЯТ,ЙўЙўЙў,ЯаЬИЕНДЫНсЪјЁЃНјШые§ЮФ,ИНЩЯФЧЮЛЮвПДЕФФЧЮЛВЉжїЮФеТЕФСДНг
? ? ?ФЧЮЛВЉжїСДНг,ашвЊПЩздШЁ,ЙўЙўЙў? ? ??labelmeЪ§ОнБъзЂМАjsonБъЧЉЮФМўХњСПДІРэ![]() https://blog.csdn.net/ZhuiMengLQG/article/details/109383422,
https://blog.csdn.net/ZhuiMengLQG/article/details/109383422,
вЛЁЂLabelmeАВзА
етИіЛЙашвЊНЬГЬ???рХЁЄЁЄЁЄЁЄЁЄЖдгкЯёЮветбљЕФаЁАз,ШЗЪЕашвЊНЬГЬ,ЙўЙўЙў
ЯШЗХИіlabelmeЙйЗНДњТы:https://github.com/wkentaro/labelme![]() https://github.com/wkentaro/labelme
https://github.com/wkentaro/labelme
ЮвгУЕФОЭЪЧwindows,ЫљвджЛаДwindowsСЫ,linuxЕФздМКАйЖШвЛДѓЖб
1. windows
ЪзЯШФуЕУАбAnacondaзАКУ,етИіЭЦМізАminiconda,ОпЬх? ФуЖЎЕФ,ВЛЖЎЮввВУЛАьЗЈ
ДЫДІЪЁШЅAnacondaЕУАВзАЙ§ГЬ
# python3
# 1ЁЂЮЊlabelmeДДНЈвЛИіcondaЛЗОГ,УќУћЮЊlableme
conda create --name=labelme python=3.6
# МЄЛюИУЛЗОГ
activate labelme
# АВзАpyqt
pip install pyqt5
# АВзАlabelme
pip install labelme
# ШЋВПАВзАЭъГЩОЭokСЫ//ЗжИюЯп=======ПЩФм ЛсгіЕНЕФЮЪЬт===============
дкФугУpipАВзАЕФЪБКђПЩФмГіЯжЕФЮЪЬт:(ЕБШЛФуЕчФдзАСЫетИіЕФЛАПЯЖЈОЭВЛЛсгаетИіЮЪЬт)
ШчЙћгаетИіЮЪЬт
error: Microsoft Visual C++ 14.0 is required. pipАВзАДэЮѓ...
ВЮПМБ№ЕФВЉжїЕФНтОіАьЗЈ:
ЪзЯШШЗЖЈФувЊАВзАЕФVisual C++БрвыЦїАцБОЁЃУПИіPythonАцБОЖМЪЙгУЬиЖЈАцБОЕФБрвыЦї,вђДЫашвЊАВзАгыPythonАцБОЯрЖдгІЕФБрвыЦї:
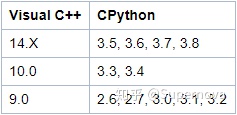
дкжДааВйзїжЎЧА,ЯШАВзАЛђЩ§МЖSetuptools PythonШэМўАќЁЃ
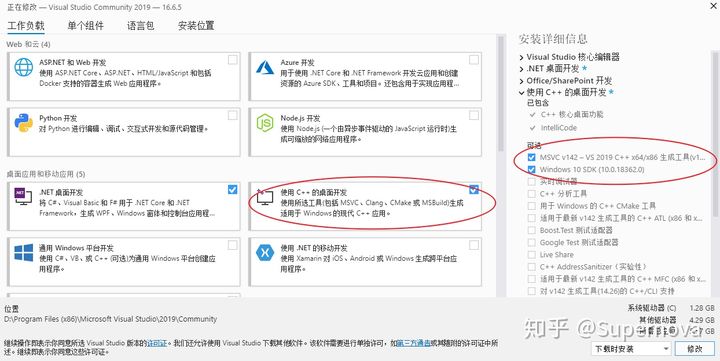
pip install --upgrade setuptoolsжБНггУ Visual C++ 14.2 БрвыЦїЕФ standalone,ВЛашвЊАВзАVisual Studio 2019ЁЃ
- АВзАMicrosoft Build Tools for Visual Studio 2019.;
- дк?Build Tools?жа,АВзАЁАЪЙгУC++ЕФзРУцПЊЗЂЁБВЂШЗБЃАВзАЯъЯИаХЯЂЕФЧАСНЯюЙДбЁЁЃ
- setuptools PythonАќЕФАцБОБиаыжСЩйЮЊ34.4.0ЁЃ
НгЯТРДОЭЪЧЯТвЛВН~~~~ЯТвЛВН,ЭъГЩ,жиаТАВзАИеВХАВзАЪЇАмЕФУќСюЁЃ
//ЗжИюЯп========end==============
ШЋВПАВзАЭъГЩКѓ,НгЯТРДОЭЪЧДђПЊlablmeВтЪдЪЧЗёГЩЙІСЫ
- дкcmdжаЪфШыactivate labelmeМЄЛюlabelmeЛЗОГЁЃ
- дкМЄЛюЛЗОГжаЪфШыlabelmeМДПЩДђПЊlabelmeНчУцЁЃ
- ЭЫГіЪфШыdeactivateМДПЩЁЃ
ЕСИіЭМЙўЙўЙў==========================================
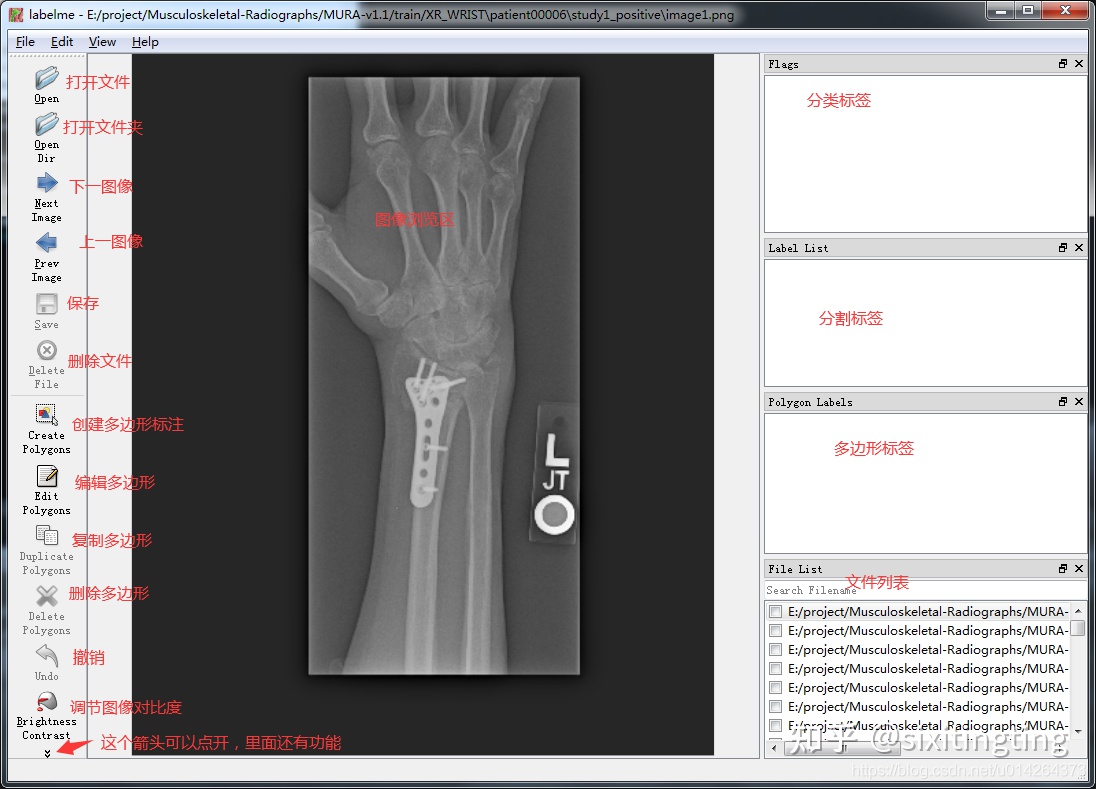
ДђПЊКѓЕУНчУц
ЕСЭМЭъБЯ=========================================
ЖўЁЂ Ъ§ОнБъзЂ
ЕуЛїopen dir,бЁдёБъзЂЮФМўЫљдкЕФЮФМўМа,ЛсЕМШыЮФМўФкЫљгаЭМЦЌЁЃ
ШЛКѓПЊЪМБъзЂ:ЕуЛїзѓЯТНЧЕФCreatePolygons,ЕЅЛїЪѓБъзѓМќЬэМгЖрБпаЮЖЅЕу,Ctrl+ZГЗЯњЩЯвЛИіЖЅЕу,зюКѓЕуЛїЦ№ЪМЕуЭъГЩЖрБпаЮЕФбЁдё,ЕЏГіУќУћПђЁЃЭЌвЛРрЯТгаЖрИіЪЕЬхЖдЯѓЪБ,ШчГЧЧјЖдЯѓЪБ,гУCity1,City2ЧјЗж,Ctrl+SБЃДцЩњГЩjsonЮФМў,ЭЌЪБгвЯТНЧЮФМўФПТМЯТИУЭМЯёЧАДђЙГЯдЪОвбБъзЂ,ШчЯТЭМЫљЪО:

?БъзЂЭъГЩКѓ,ЛсЩњГЩвЛИіjsonЮФМўЁЃ
Ш§ЁЂlabelmeБъЧЉХњСПзЊЛЛ
1. ЕЅеХЭМЦЌзЊЛЛ
jsonЮФМўашвЊзЊЛЛГЩpngЮФМў,ЛљБОзЊЛЛЗНЗЈЪЧдкАВзАСЫlabelmeЕФЛЗОГЯТ,ЪфШыЯТУцЕФДњТы:
# зЂвт.exeКѓБпгаИіПеИё
labelme_json_to_dataset.exe E:\image\1.json дк001.jsonЫљдкЮФМўМаФк,ЛсЩњГЩвЛИі001_jsonЕФЮФМўМа,РяУцга5ИіЮФМў,ЦфжаЕФlabel.pngЮЊЫљвЊЕФЗжИюбкФЄ,аТАцБОЕФlabelmeУЛга.yamlЮФМў
рХЁЄЁЄЁЄЁЄЁЄетИігІИУгУДІВЛДѓСЫ,вЛИівЛИіЪжЖЏЩњГЩ,етЕУКяФъТэдТАЁ,жБНгећХњСПзЊЛЛЕФЁЃ
етИіашвЊаоИФlabelmeЕФвЛИіЮФМўСЫ,вВОЭЪЧетИіlabelme_json_to_dataset.pyЮФМў,
ЮветИіЮФМўЫљдкЕФЮЛжУЮЊD:\ProgramData\Miniconda3\envs\labelme\Lib\site-packages\labelme\cli/json_to_dataset.py,жївЊОЭЪЧевЕНФуЕФlabelmeАВзАЮЛжУ
гаШЫПЩФмОЭвЊЮЪСЫ,ЮвПДФуВЮПМЕФФЧИіВЉжїВЂУЛгаИФАЁ,ФуИщзХЯЙИФЪВУДЁЃ
ЯЙНтЪЭвЛВЈ===================
етОЭвЊРДЫЕЫЕдлУЧЕФФПЕФСЫ,ПЊЭЗЯЙГЖЕРяБпвВЬсЕНСЫ,длУЧвЊећвЛИіШЋздЖЏЛЏЕФ,жЛашвЊаоИФjsonЮФМўЕФТЗОЖЪЃЯТЕФЖМАДЮвУЧЩшЖЈКУЕФТЗОЖДцДЂОЭаа,ВЛашвЊећвЛВНИФвЛИіТЗОЖ
НтЪЭЭъБЯ=====================
2. ЖреХЭМЦЌХњСПзЊЛЛ
ЕквЛВНЁЂЯШПДПДlabelme_json_to_dataset.pyБЛЮвИФГЩСЫЪВУДбљзг(зЂвт,зЂвт,зЂвт,НЋlabelme_json_to_dataset.pyдЪМЕФБИЗнвЛЯТ,ЗРжЙФуИФрУЦЈСЫ)
жБНгЩЯДњТы,(ФуашвЊзіЕФ,ИДжЦ,еГЬљЕНФуЕФlabelme_json_to_dataset.pyЮФМўРяБп,ЙўЙўЙў,ЗНБуАб)
'''
аоИФКѓЕФjson_to_datasetЮФМў,жБНгИДжЦЬцЛЛФуздМКдЪМЕФjson_to_dataset
'''
import argparse
import base64
import json
import os
import os.path as osp
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
parser = argparse.ArgumentParser()
parser.add_argument("json_file")
parser.add_argument("-o", "--out", default=None)
args = parser.parse_args()
json_file = args.json_file
print(osp.dirname(json_file))
if osp.isdir(osp.join(osp.dirname(json_file),'json_data')) is False:
os.mkdir(osp.join(osp.dirname(json_file),'json_data'))
else:
print("ЮФМўвбДцдк")
if args.out is None:
out_dir = osp.basename(json_file).replace(".", "_")
out_dir1 = osp.join(osp.dirname(json_file), 'json_data')
out_dir = osp.join(out_dir1, out_dir)
print(out_dir)
print("#"*10)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(json_file), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {"_background_": 0}
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
lbl, imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))
utils.lblsave(osp.join(out_dir, "label.png"), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f:
for lbl_name in label_names:
f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir))
if __name__ == "__main__":
main()
НгЯТРДНјШыХњСПзЊЛЛЕФКЫаФ
ДѓжТСїГЬ,
? ?ЕквЛВН? ? ? ???pre_treatment() ? ?#дЄДІРэ,ДДНЈДцДЂЫљашЕФЯргІЮФМўМа
? ?ЕкЖўВН? ? ? ? ?json_png() ? ? ? ? #ЕїгУlabelmeЕФjsonзЊЛЛpngГЬађ
? ?ЕкШ§ВН? ? ? ? ?extract_png() ? ? ?#ДгзЊЛЛЕФЪ§ОнжаЬсШЁpngЭМЯё
? ?ЕкЫФВН? ? ? ? ?png_to_binary() ? ?#НЋpngзЊЛЛЮЊ8ЮЛЕФЕЅЭЈЕРКкАзЭМЯё,гУгкЗжИюбЕСЗ
рХЁЄЁЄЁЄЁЄЁЄНгЯТРДздМКНЈвЛИіpythonЙЄГЬ,АбЯТБуДњТыИДжЦНјШЅ,НгЯТРДФуашвЊзіОЭЪЧАбетИіТЗОЖИФГЩФуЕФТЗОЖЁЂ
'''
НЋlabelжаБъзЂЕФjsonЮФМў,зЊЛЏЮЊПЩгУгкЗжИюбЕСЗЕФБъЧЉЖўжЕЛЏКкАзpngЭМЦЌ
'''
import os
import cv2
import numpy as np
import shutil
import glob
# def json_png(): ЕквЛДЮзЊЛЛгУЕН
path_json = r'E:\pic3\json' # етРяЪЧжИ.jsonЮФМўЫљдкЮФМўМаЕФТЗОЖ
# ХњСПзЊЛЛ,аоИФДЫТЗОЖ
# ДЫТЗОЖЮЊ,jsonЮФМўЫљдкТЗОЖ
# def extract_png(): ЕкЖўДЮзЊЛЛгУЕН
path_json_to_data = os.path.join(path_json,"json_data") # jsonЮФМўМаЫљдкЮЛжУ
path_save_png = os.path.join(path_json,"json_png") # НЋБъЧЉЭМДгjsonЮФМўжаХњСПШЁГіКѓжИЖЈБЃДцЕФЮФМўФПТМ
path_save_png_binary = os.path.join(path_json,"json_png_binary") #ЖўжСЭМЯёзюжеБЃДцЕФТЗОЖ
def pre_treatment():
'''
ДДНЈШ§ИіЮФМўМагУгкДцДЂ
json_dataгУгкДцДЂjsonзЊЛЛimg.png label.png label_names.txt label_viz.pngЕФЮФМўМа
json_pngгУгкДцДЂДгjson_dataЬсШЁГіРДЕФlabelЁЃpng(зюжеДцДЂУћзжгыjsonЮФМўЖдгІ)
json_png_binary гУгкДцДЂзюжезЊЛЛКѓЕФ8ЮЛЕФЕЅЭЈЕРКкАзЭМЯё
:return:
'''
if os.path.isdir(os.path.join(path_json,"json_data")) is False:
os.mkdir(os.path.join(path_json,"json_data"))
else:
print('ЮФМўвбДцдк')
if os.path.isdir(os.path.join(path_json,"json_png")) is False:
os.mkdir(os.path.join(path_json,"json_png"))
else:
print('ЮФМўвбДцдк')
if os.path.isdir(os.path.join(path_json,"json_png_binary")) is False:
os.mkdir(os.path.join(path_json,"json_png_binary"))
else:
print('ЮФМўвбДцдк')
def json_png():
'''
ХњСПНЋjsonзЊЛЛЮЊimg.png label.png label_names.txt label_viz.png
ВЂДцДЂжСЕБЧАЮФМўМаЯТЕФjson_dateЮФМўМажа
:return: Юо
'''
json_file = glob.glob(os.path.join(path_json, "*.json"))
os.system("activate labelme") #МЄЛюlabelmeЛЗОГ(ИљОнздМКЩшжУЕФаоИФ)
for file in json_file:
os.system("labelme_json_to_dataset.exe %s" % (file)) #ЕїгУlabelme,здДјЕФГЬађНјааХњСПзЊЛЛ
#labelmeжа\.conda\envs\labelme\Lib\site-packages\labelme\cliжаЕФjson_to_dataset.pyБЛаоИФЙ§
# ОпЬхаоИФМћjson_to_dataset.py
def extract_png():
'''
НЋБъЧЉЭМДгjsonЮФМўжаХњСПШЁГі
:return:
'''
for eachfile in os.listdir(path_json_to_data):
path1 = os.path.join(path_json_to_data, eachfile) # ЛёШЁЕЅИіjsonЮФМўМаЕФФПТМ
if os.path.isdir(path1): #ХаЖЯpath1ТЗОЖЪЧЗёДцдк
if os.path.exists(path1 + '/label.png'): #ХаЖЯpath1ТЗОЖЯТlabel.pngЪЧЗёДцдк
path1 = os.path.join(path1, 'label.png') # ЛёШЁPNGЫљдкЕФТЗОЖ,зМБИЕШД§ИДжЦ
path2 = os.path.join(path_save_png, (eachfile.split('_')[0] + '.png')) # НЋpngИДжЦЕНpath2ТЗОЖЯТЕФЮФМўМажаШЅ
shutil.copy(path1, path2) #НЋpath1ЮФМўИДжЦЕНpath2
print(eachfile + ' successfully moved')
def png_to_binary():
'''
гЩгкЪ§ОнМЏЪЧзіЖўЗжРрЗжИю,Ыљвд,ашвЊНЋground_truthзЊЛЛЮЊ8ЮЛЕФЕЅЭЈЕРКкАзЭМЯё,ВХФмзїЮЊбЕСЗЪБЕФlabelЪЙгУЁЃ
НЋЬсШЁГіРДЕФpngзЊЛЛЮЊ8ЮЛЕФЕЅЭЈЕРКкАзЭМЯё
'''
for im in os.listdir(path_save_png):
img = cv2.imread(os.path.join(path_save_png, im))
b, g, r = cv2.split(img)
r[np.where(r != 0)] = 255
cv2.imwrite(os.path.join(path_save_png_binary, im), r)
def process():
pre_treatment() #дЄДІРэ,ДДНЈДцДЂЫљашЕФЯргІЮФМўМа
json_png() #ЕїгУlabelmeЕФjsonзЊЛЛpngГЬађ
extract_png() #ДгзЊЛЛЕФЪ§ОнжаЬсШЁpngЭМЯё
png_to_binary() #НЋpngзЊЛЛЮЊ8ЮЛЕФЕЅЭЈЕРКкАзЭМЯё,гУгкЗжИюбЕСЗ
if __name__ == "__main__":
process()зЂ:НЋКьЩЋВПЗжЬцЛЛЮЛФуздМКЕФjsonЮФМўЕФТЗОЖ,етИіE:\pic3\jsonЪЧЮвЕФТЗОЖ,(ЬцЛЛЮЊФуздМКЕФТЗОЖ)
path_json = r'E:\pic3\json' # етРяЪЧжИ.jsonЮФМўЫљдкЮФМўМаЕФТЗОЖ # ХњСПзЊЛЛ,аоИФДЫТЗОЖ # ДЫТЗОЖЮЊ,jsonЮФМўЫљдкТЗОЖ
ЯраХФуПДЭъжЎКѓ,ПЯЖЈвВПЩвдЪЕЯжХњСП,здЖЏЪЕЯжjsonзЊpngСЫЁЃЙўЙўЙў
ДЫДІИНЩЯЮвздМКЕФЙЄГЬДњТы,АќРЈИФКУЕФlabelme_json_to_dataset.pyЮФМў
дйЯЙГЖМИОф:
? ? ? ? ГѕДЮбЇЯА,гаДэЮѓжЎДІ,вВПЩвдАяУІИФе§вЛЯТ,аЛаЛ
ВЮПМ
ЩюЖШбЇЯАЭМЯёБъЧЉБъзЂШэМўlabelmeГЌЯъЯИНЬГЬ - жЊКѕ (zhihu.com)![]() https://zhuanlan.zhihu.com/p/371756150(106ЬѕЯћЯЂ) labelmeХњСПжЦзїЪ§ОнМЏНЬГЬ_ZhuiMengLQGЕФВЉПЭ-CSDNВЉПЭ_labelme ХњСП
https://zhuanlan.zhihu.com/p/371756150(106ЬѕЯћЯЂ) labelmeХњСПжЦзїЪ§ОнМЏНЬГЬ_ZhuiMengLQGЕФВЉПЭ-CSDNВЉПЭ_labelme ХњСП![]() https://blog.csdn.net/ZhuiMengLQG/article/details/109383422ЁОlabelmeЁПХњСПНЋ.jsonЮФМўзЊЛЛГЩmask.pngЕШЮФМў - ДњТыЯШЗцЭј (codeleading.com)
https://blog.csdn.net/ZhuiMengLQG/article/details/109383422ЁОlabelmeЁПХњСПНЋ.jsonЮФМўзЊЛЛГЩmask.pngЕШЮФМў - ДњТыЯШЗцЭј (codeleading.com)![]() https://www.codeleading.com/article/21842739990/
https://www.codeleading.com/article/21842739990/