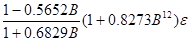第一章 时间序列的预处理
一、平稳性检验
时序图检验和自相关图检验
(一)时序图检验
根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常数值附近随机波动,而且波动的范围有界、无明显趋势及周期特征
例2.1:检验1964年――1999年中国纱年产量序列的平稳性
1.在Eviews软件中打开案例数据
图1:打开外来数据
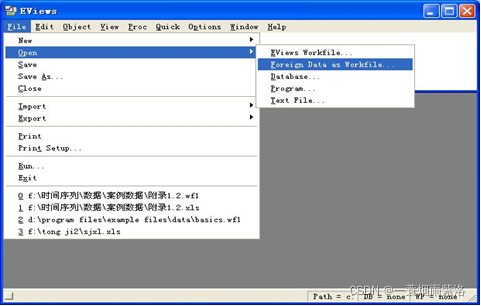
图2:打开数据文件夹中案例数据文件夹中数据
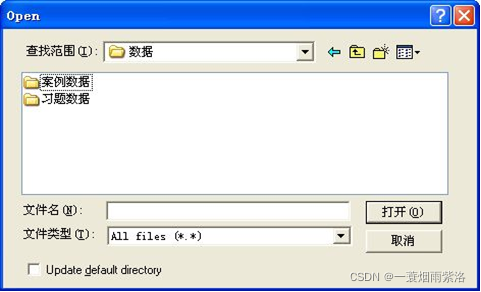
文件中序列的名称可以在打开的时候输入,或者在打开的数据中输入
图3:打开过程中给序列命名
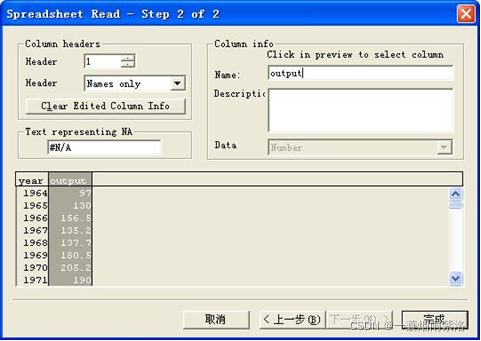
图4:打开数据
2.绘制时序图
可以如下图所示选择序列然后点Quick选择Scatter或者XYline;
绘制好后可以双击图片对其进行修饰,如颜色、线条、点等
图1:绘制散点图
图2:年份和产出的散点图
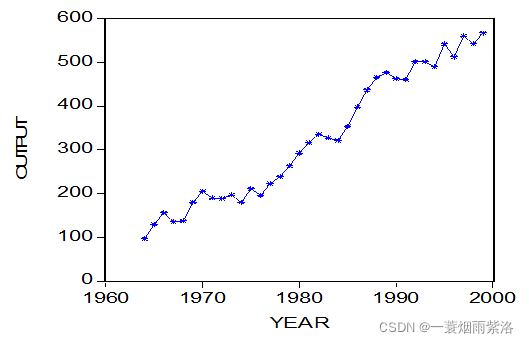
图3:年份和产出的散点图
(二)自相关图检验
例2.3
导入数据,方式同上;
在Quick菜单下选择自相关图,对Qiwen原列进行分析;
可以看出自相关系数始终在零周围波动,判定该序列为平稳时间序列。
图1:序列的相关分析
图2:输入序列名称
图2:选择相关分析的对象
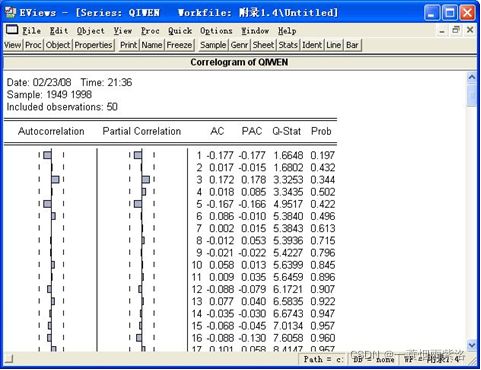
图3:序列的相关分析结果:1. 可以看出自相关系数始终在零周围波动,判定该序列为平稳时间序列2.看Q统计量的P值:该统计量的原假设为X的1期,2期……k期的自相关系数均等于0,备择假设为自相关系数中至少有一个不等于0,因此如图知,该P值都>5%的显著性水平,所以接受原假设,即序列是纯随机序列,即白噪声序列(因为序列值之间彼此之间没有任何关联,所以说过去的行为对将来的发展没有丝毫影响,因此为纯随机序列,即白噪声序列.) 有的题目平稳性描述可以模仿书本33页最后一段.
(三)平稳性检验还可以用:
单位根检验:ADF,PP检验等;
非参数检验:游程检验
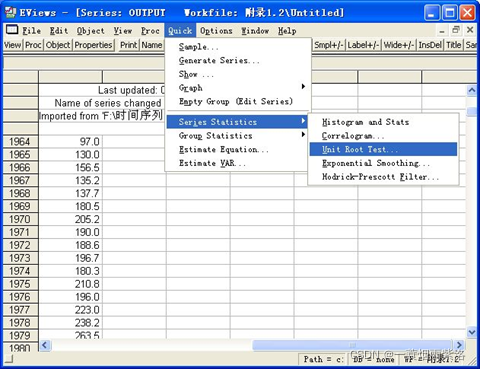
图1:序列的单位根检验
图2:单位根检验的方法选择
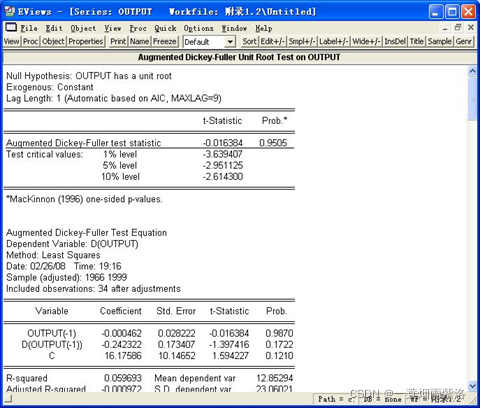
图3:ADF检验的结果:如图,单位根统计量ADF=-0.016384都大于EVIEWS给出的显著性水平1%-10%的ADF临界值,所以接受原假设,该序列是非平稳的。
二、纯随机性检验
计算Q统计量,根据其取值判定是否为纯随机序列。
例2.3的自相关图中有Q统计量,其P值在K=6、12的时候均比较大,不能拒绝原假设,认为 该序列是白噪声序列。
另外,小样本情况下,LB统计量检验纯随机性更准确。
第二章 平稳时间序列建模实验教程
一、模型识别
1.打开数据
图1:打开数据
2.绘制趋势图并大致判断序列的特征

图2:绘制序列散点图
图3:输入散点图的两个变量
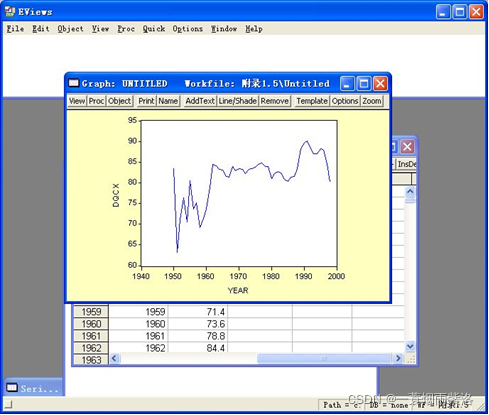
图4:序列的散点图
3.绘制自相关和偏自相关图
图1:在数据窗口下选择相关分析
图2:选择变量
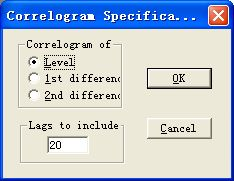
图3:选择对象
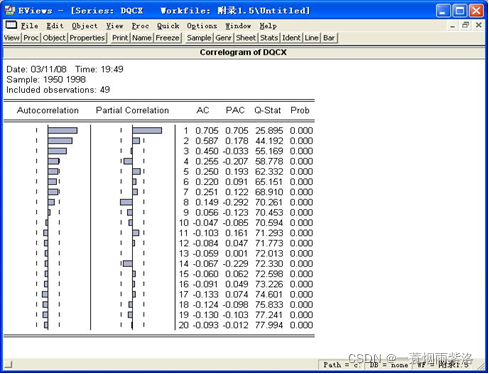
图4:序列相关图
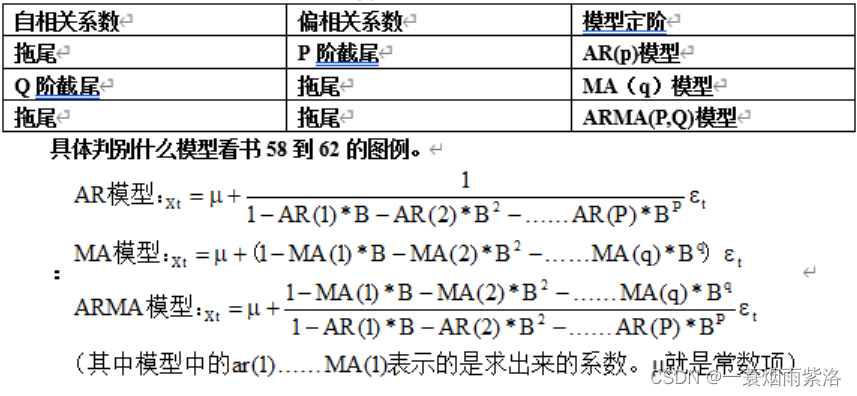
4.根据自相关图和偏自相关图的性质确定模型类型和阶数
如果样本(偏)自相关系数在最初的d阶明显大于两倍标准差范围,而后几乎95%的自相关系数都落在2倍标准差的范围以内,而且通常由非零自相关系数衰减为小值波动的过程非常突然。这时,通常视为(偏)自相关系数截尾。截尾阶数为d。
本例:
? 自相关图显示延迟3阶之后,自相关系数全部衰减到2倍标准差范围内波动,这表明序列明显地短期相关。但序列由显著非零的相关系数衰减为小值波动的过程相当连续,相当缓慢,该自相关系数可视为不截尾
? 偏自相关图显示除了延迟1阶的偏自相关系数显著大于2倍标准差之外,其它的偏自相关系数都在2倍标准差范围内作小值随机波动,而且由非零相关系数衰减为小值波动的过程非常突然,所以该偏自相关系数可视为一阶截尾
? 所以可以考虑拟合模型为AR(1)
自相关系数 偏相关系数 模型定阶
拖尾 P阶截尾 AR§模型
Q阶截尾 拖尾 MA(q)模型
拖尾 拖尾 ARMA(P,Q)模型
二、模型参数估计
根据相关图模型确定为AR(1),建立模型估计参数
在ESTIMATE中按顺序输入变量cx c cx(-1)或者cx c ar(1) 选择LS参数估计方法,查看输出结果,看参数显著性,该例中两个参数都显著。
细心的同学可能发现两个模型的C取值不同,这是因为前一个模型的C为截距项;后者的C则为序列期望值,两个常数的含义不同。
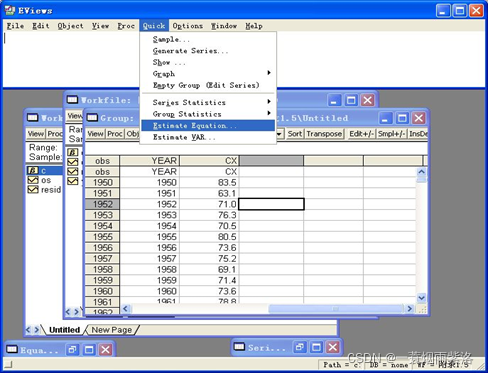
图1:建立模型
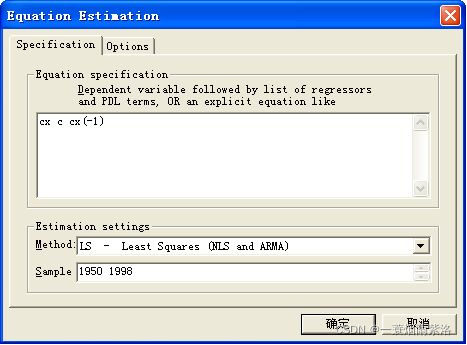
图2:输入模型中变量,选择参数估计方法

图3:参数估计结果
图4:建立模型
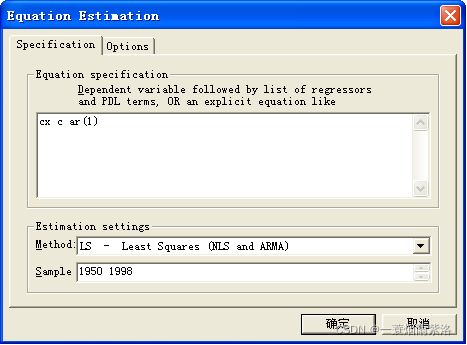
图5:输入模型中变量,选择参数估计方法

图6:参数估计结果
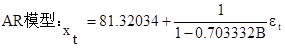
三、模型的显著性检验
检验内容:
整个模型对信息的提取是否充分;
参数的显著性检验,模型结构是否最简。
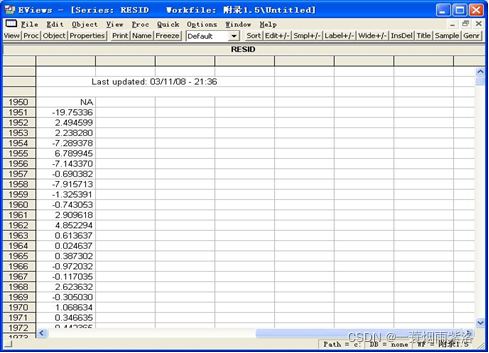
图1:模型残差
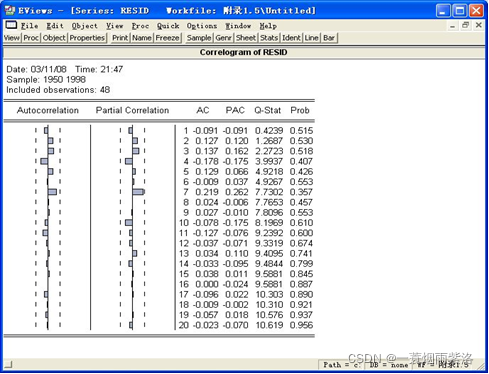
图2:残差的平稳性和纯随机性检验
对残差序列进行白噪声检验,可以看出ACF和PACF都没有显著异于零,Q统计量的P值都远远大于0.05,因此可以认为残差序列为白噪声序列,模型信息提取比较充分。
常数和滞后一阶参数的P值都很小,参数显著;因此整个模型比较精简,模型较优。
四、模型优化
当一个拟合模型通过了检验,说明在一定的置信水平下,该模型能有效地拟合观察值序列的波动,但这种有效模型并不是唯一的。
当几个模型都是模型有效参数显著的,此时需要选择一个更好的模型,即进行优化。
优化的目的,选择相对最优模型。
优化准则:
最小信息量准则(An Information Criterion)
? 指导思想
? 似然函数值越大越好
? 未知参数的个数越少越好
? AIC准则的缺陷
在样本容量趋于无穷大时,由AIC准则选择的模型不收敛于真实模型,它通常比真实模型所含的未知参数个数要多
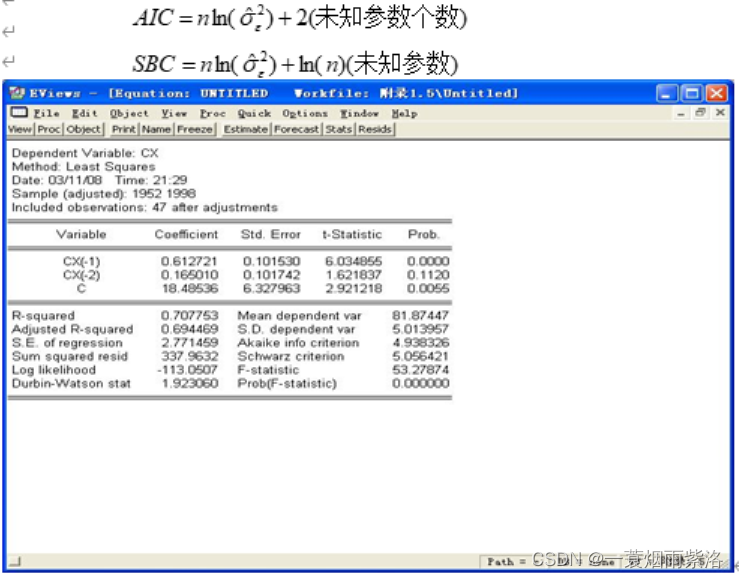
但是本例中滞后二阶的参数不显著,不符合精简原则,不必进行深入判断。
第三章 非平稳时间序列的确定性分析
第二章介绍了平稳时间序列的分析方法,但是自然界中绝大多数序列都是非平稳的,因而对非平稳时间序列的分析跟普遍跟重要,人们创造的分析方法也更多。这些方法分为确定性时序分析和随机时序分析两大类,本章主要介绍确定性时序分析方法。
一个序列在任意时刻的值能够被精确确定(或被预测),则该序列为确定性序列,如正弦序列、周期脉冲序列等。而某序列在某时刻的取值是随机的,不能给以精确预测,只知道取某一数值的概率,如白噪声序列等。Cramer分解定理说明每个序列都可以分成一个确定序列加一个随机序列,平稳序列的两个构成序列均平稳,非平稳时间序列则至少有一部分不平稳。本章先分析确定性序列不平稳的非平稳时间时间序列的分析方法。
确定性序列不平稳通常显示出非常明显的规律性,如显著趋势或者固定变化周期,这种规律性信息比较容易提取,因而传统时间序列分析的重点在确定性信息的提取上。
常用的确定性分析方法为因素分解。分析目的为:①克服其他因素的影响,单纯测度某一个确定性因素的影响;②推断出各种因素彼此之间作用关系及它们对序列的综合影响。
一、趋势分析
绘制序列的线图,观测序列的特征,如果有明显的长期趋势,我们就要测度其长期趋势,测度方法有:趋势拟合法、平滑法。
(一) 趋势拟合法
1.线性趋势拟合
例1:以澳大利亚政府1981-1990年每季度消费支出数据为例进行分析。
图1:导入数据
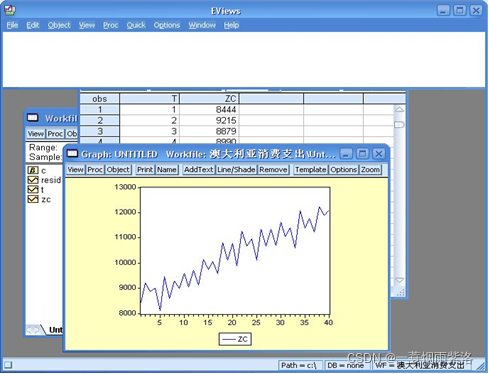
图2:绘制线图,序列有明显的上升趋势
长期趋势具备线性上升的趋势,所以进行序列对时间的线性回归分析。
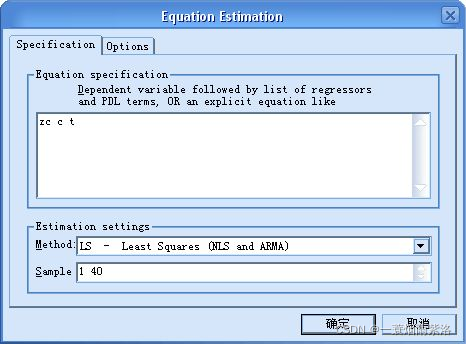
图3:序列支出(zc)对时间(t)进行线性回归分析
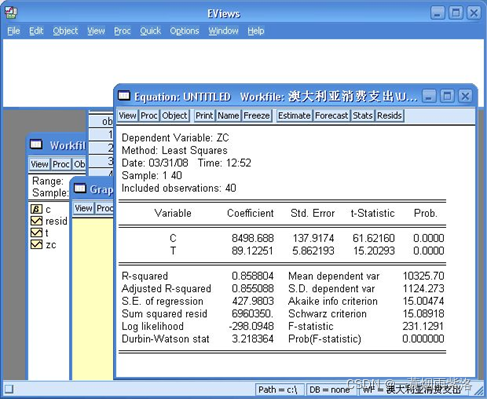
图4:回归参数估计和回归效果评价
可以看出回归参数显著,模型显著,回归效果良好,序列具有明显线性趋势。
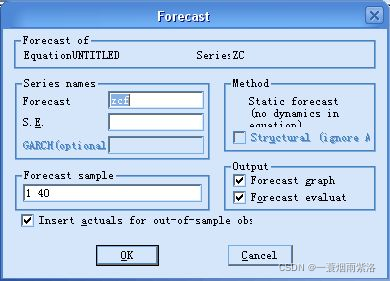
图5:运用模型进行预测
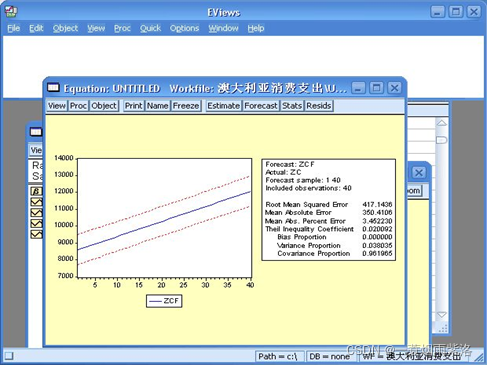
图6:预测效果(偏差率、方差率等)
图7:绘制原序列和预测序列的线图
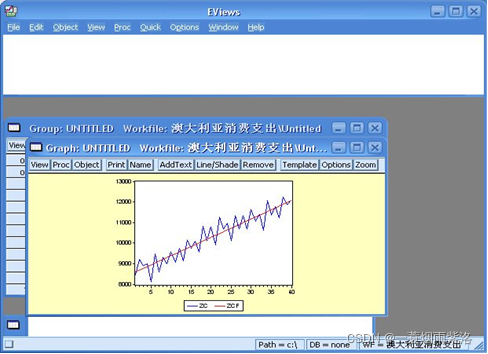
图8:原序列和预测序列的线图

图9:残差序列的曲线图
可以看出残差序列具有平稳时间序列的特征,我们可以进一步检验剔除了长期趋势后的残差序列的平稳性,第二章知识这里不在叙述。
2.曲线趋势拟合
例2:对上海证券交易所1991.1-2001.10每月月末上正指数序列进行拟合。
图1:导入数据
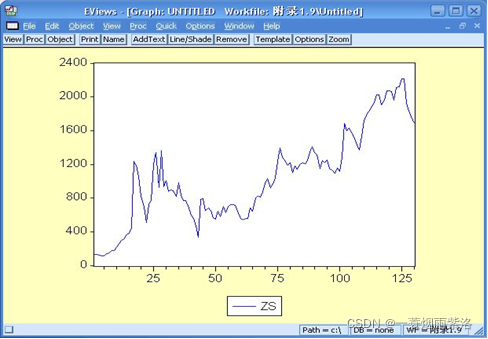
图2:绘制曲线图
可以看出序列不是线性上升,而是曲线上升,尝试用二次模型拟合序列的发展。
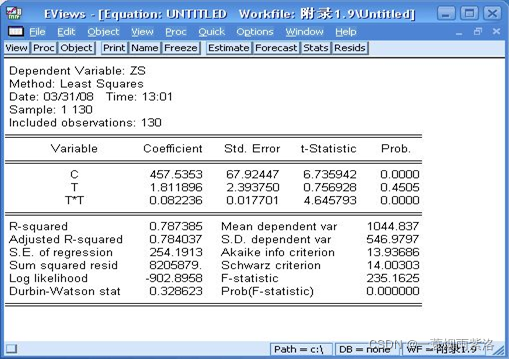
图3:模型参数估计和回归效果评价
因为该模型中T的系数不显著,我们去掉该项再进行回归分析。

图4:新模型参数估计和回归效果评价
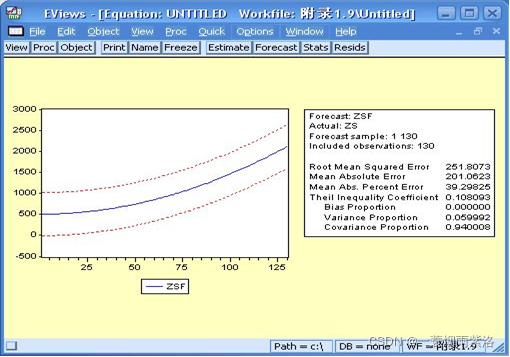
图5:新模型的预测效果分析

图6:原序列和预测序列值
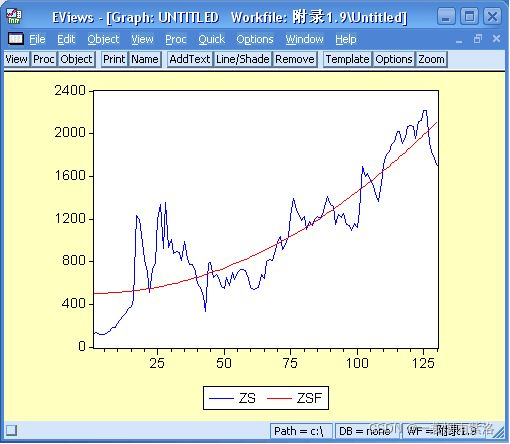
图7:原序列和预测序列值曲线图
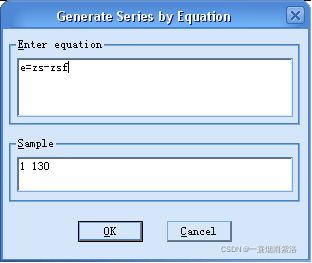
图8:计算预测误差
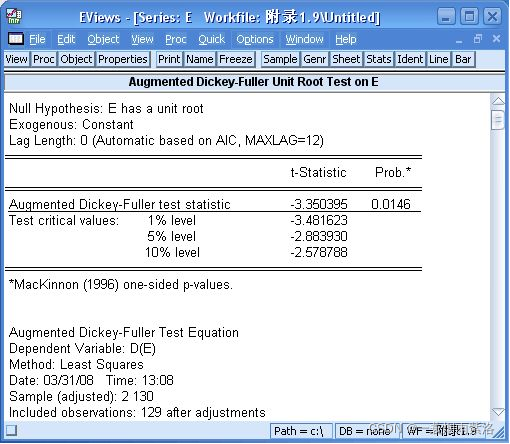
图9:对预测误差序列进行单位根检验
拒绝原假设,认为序列没有单位根,为平稳序列,说明模型对长期趋势拟合的效果还不错。
同样,序列与时间之间的关系还有很多中,比如指数曲线、生命曲线、龚柏茨曲线等等,其回归模型的建立、参数估计等方法与回归分析同,这里不再详细叙述。
(二) 平滑法
除了趋势拟合外,平滑法也是消除短期随机波动反应长期趋势的方法,而其平滑法可以追踪数据的新变化。平滑法主要有移动平均方法和指数平滑法两种,这里主要介绍指数平滑方法。
例3:对北京市1950-1998年城乡居民定期储蓄所占比例序列进行平滑。
图1:打开序列,进行指数平滑分析
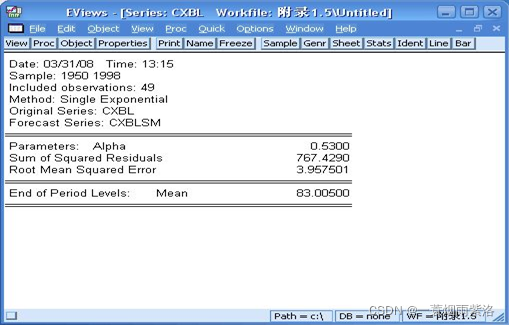
图2:系统自动给定平滑系数趋势
给定方法为选择使残差平方和最小的平滑系数,该例中平滑系数去0.53,超过0.5用一次平滑效果不太好
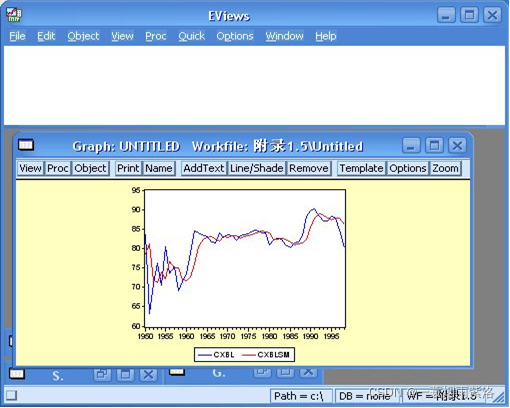
图3:平滑前后序列曲线图
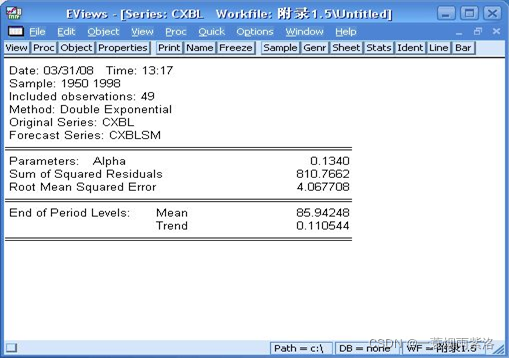
图4:用二次平滑修匀原序列
可以看出,平滑系数为0.134,平均差为4.067708,修匀或者趋势预测效果不错。
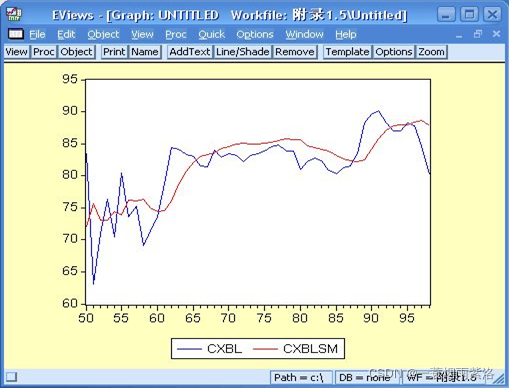
图5:二次平滑效果图
例4:对于有明显线性趋势的序列,我们可以采用Holt两参数法进行指数平滑
对北京市1978-2000年报纸发行量序列进行Holt两参数指数平滑
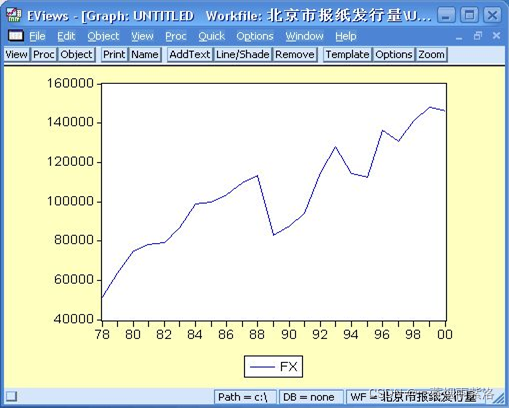
图1:报纸发行量的曲线图
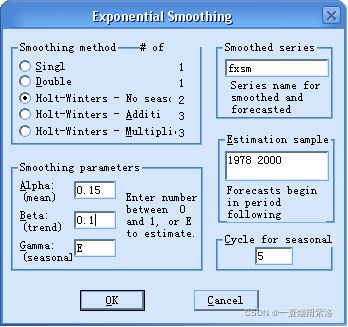
图2:Holt两参数指数平滑(指定平滑系数)
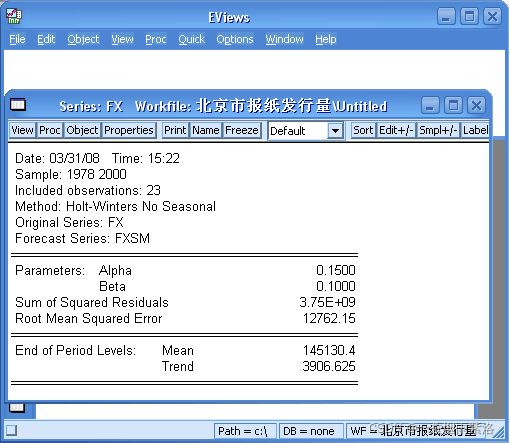
图3:预测效果检验
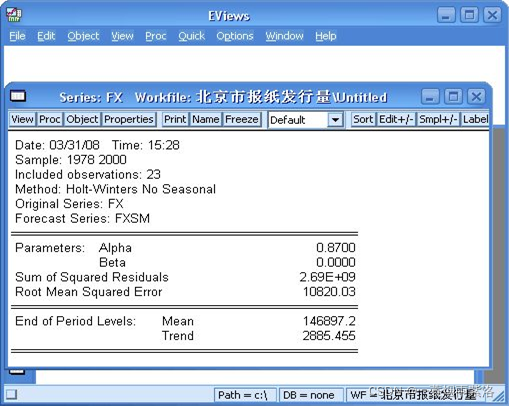
图4:系统自动给定平滑系数时平滑效果
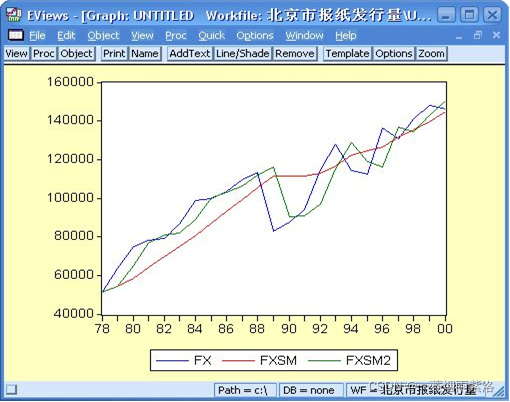
图5:原序列与预测序列曲线图
(其中FXSM为自己给定系数时的平滑值,FXSM2为系统给定系数时的平滑值)
二、季节效应分析
许多序列有季节效应,比如:气温、商品零售额、某景点旅游人数等都会呈现明显的季节变动规律。
例5:以北京市1995-2000年月平均气温序列为例,介绍季节效应分析操作。

图1:建立月度数据新工作表
图2:新工作表中添加数据
图3:五年的月度气温数据
图4:进行季节调整(移动平均法)
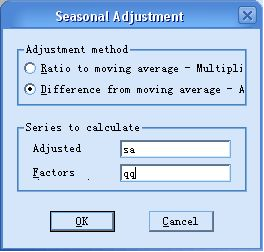
图5:移动平均季节加法
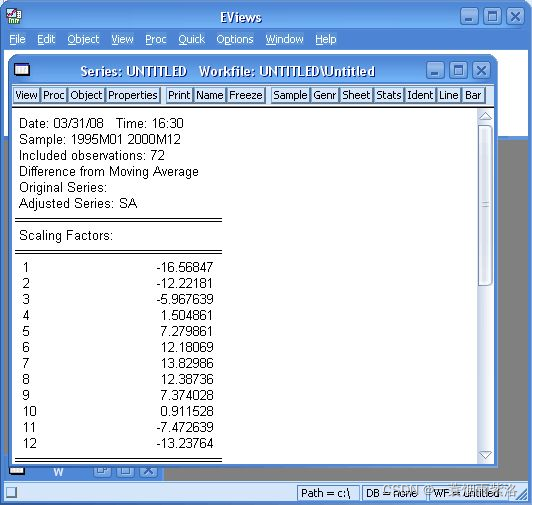
图6:12个月的加法调整因子
图7:打开三个序列(季节调整序列、原序列、调整后序列)
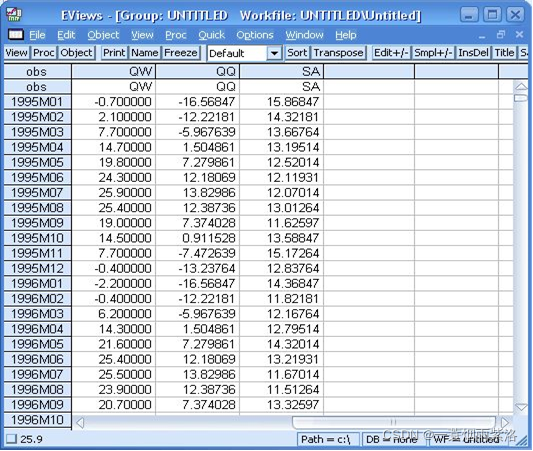
图8:三个序列(季节调整序列、原序列、调整后序列)取值
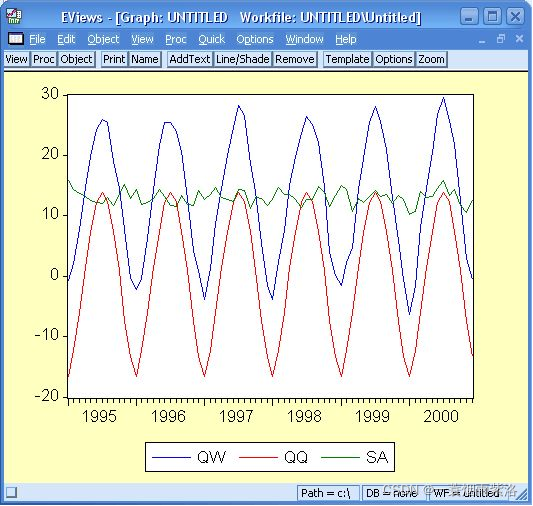
图9:三个序列(季节调整序列、原序列、调整后序列)曲线图
另外季节调整还可以用X11,X12等方法进行调整。
三、综合分析
前面两部分介绍了单独测度长期趋势和季节效应的分析方法,这里介绍既有长期趋势又有季节效应的复杂序列的分析方法。
附录1.11 对1993――2000年中国社会消费品零售总额序列进行确定性分析
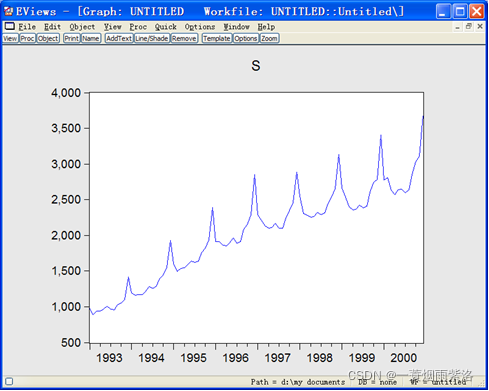
图1:绘制1993――2000年中国社会消费品零售总额时序图
可以看出序列中既有长期趋势又有季节波动
图2:进行季节调整

图3:12个月的季节因子
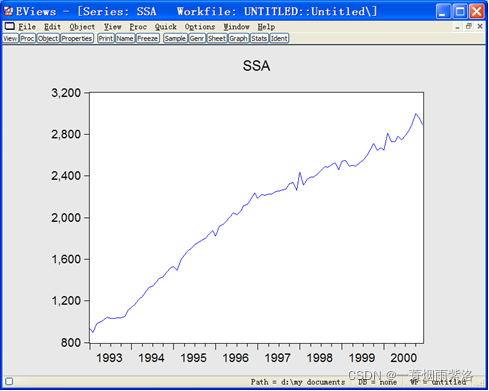
图4:经季节调整后的序列SSA
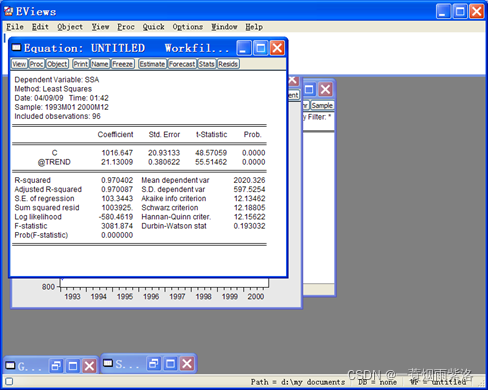
图5:对经季节调整后序列进行趋势拟合
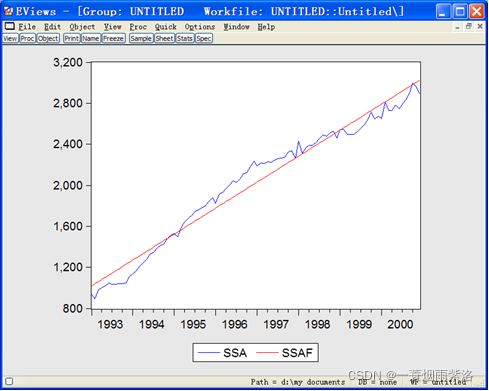
图6:趋势拟合序列SSAF与序列SSA的时序图

图7:扩展时间区间后预测长期趋势值SSAF

图8:经季节调整预测2001年12个月的零售总额值

图9:预测2001年12个月的零售总额值
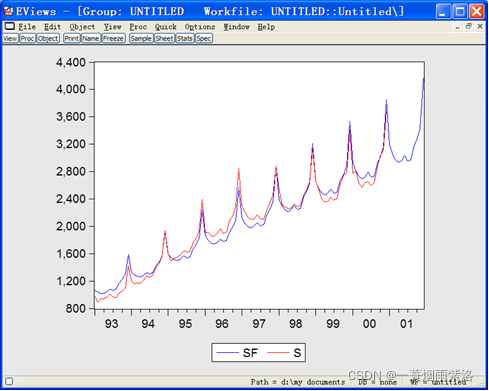
图10:预测序列与原序列的时序图
第四章 非平稳序列的随机分析
非平稳序列的确定性分析原理简单操作方便易于解释,但是只提取确定性信息,对随机信息浪费严重;且各因素之间确切的作用关系没有明确有效的判断方法。随机分析方法的发展弥补了这些不足,为人们提供更加丰富、更加精确的时序分析工具。
对非平稳时间序列的分析,要先提取确定性信息再研究随机信息。
一、差分法提取确定性信息
确定性信息的提取方法有第四章学习的趋势拟合、指数平滑、季节指数、季节多元回归等,本章主要介绍差分法提取确定性信息。
差分实质:自回归
差分方式:对线性趋势序列进行1阶差分、对曲线趋势序列进行低阶差分、对固定周期序列进行周期差分
线性趋势:对产出序列进行一阶差分
详细分析过程如下:

图1:导入数据
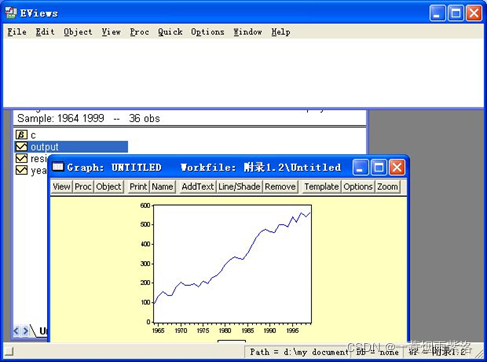
图2:绘制线性图,观察序列的特征
观察发现序列具有较明显的线性趋势
图3:进行一阶差分运算
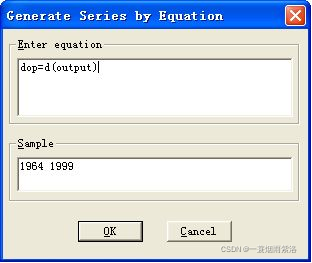
图4:一阶差分运算公式
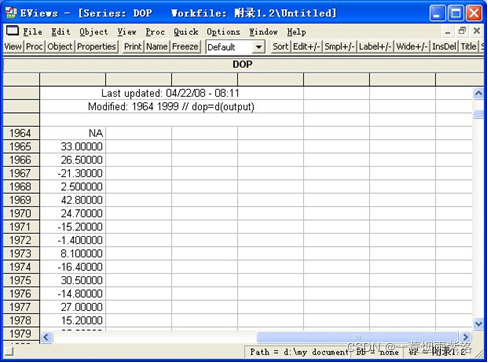
图5:一阶差分序列
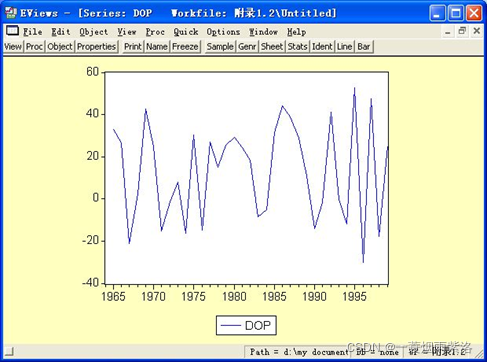
图6:一阶差分曲线图
观察一阶差分序列均值方差稳定,进一步进行平稳性分析。
图7:绘制一阶差分序列的相关图
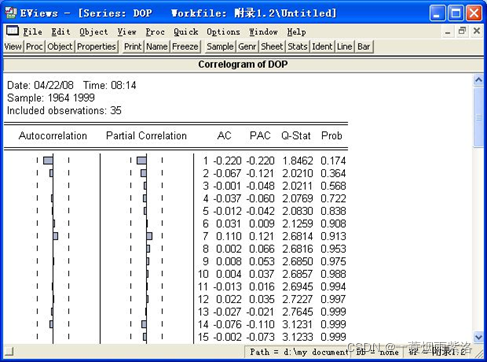
图8:自相关图均不显著,Q统计量不显著
因此,差分后序列问白噪声序列,一阶差分将序列的信息提取充分。
曲线序列:北京市民用车拥有量序列差分分析
图1:导入数据
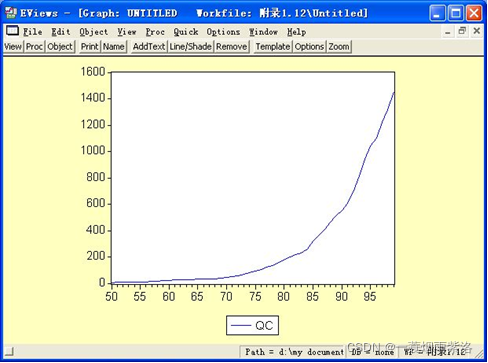
图2:绘制原序列曲线图
可以看出,1950年到1999年北京市居民民用车拥有量序列具有曲线趋势,现用低阶差分法提取确定性信息。
图3:绘制一阶差分序列的曲线图
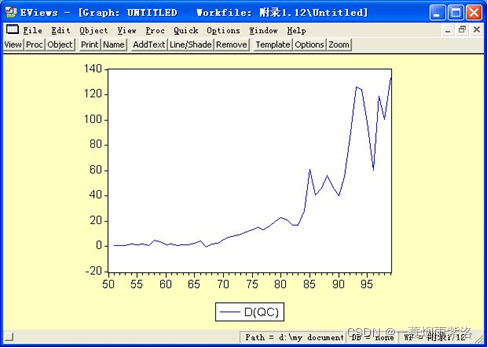
图4:一阶差分序列曲线图
可以看出一阶差分序列仍然具有趋势,继续进行差分分析;二阶差分的命令的D(QC,2),低阶差分的命令为D(QC,K)。
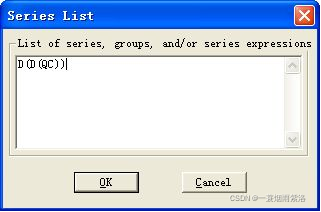
图5:对原序列进行二阶差分
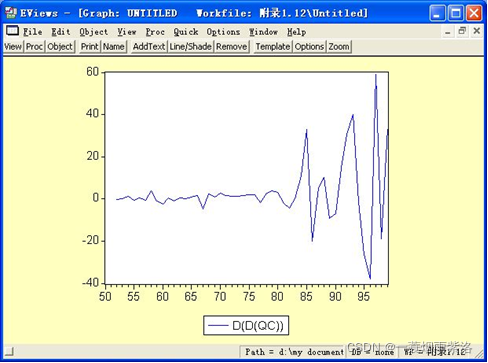
图6:二阶差分序列曲线图
从二阶差分序列曲线图可以看出二阶差分序列中没有中长期趋势,二阶差分提取了长期趋势。
图7:自相关分析
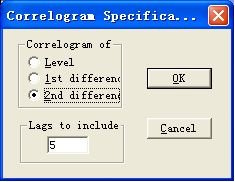
图8:对序列的二阶差分序列进行自相关分析
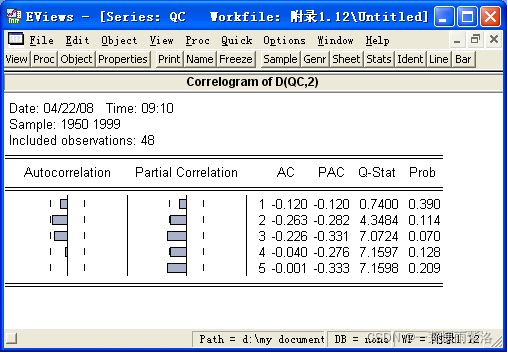
图9:二阶差分序列相关图
可以看出二阶差分序列具有短期相关性的特征,无确定性信息,为平稳序列。
固定周期序列:奶牛月产奶量序列差分分析
图1:导入数据(月度数据)
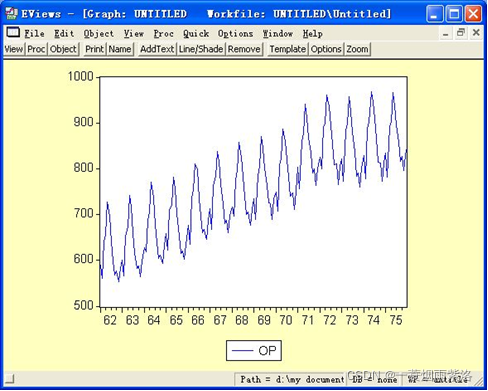
图2:绘制序列曲线图
可以看出本序列既有长期趋势又有周期性因素,因此我们首先进行一阶差分提取趋势特征,再进行12步周期差分提取周期信息。
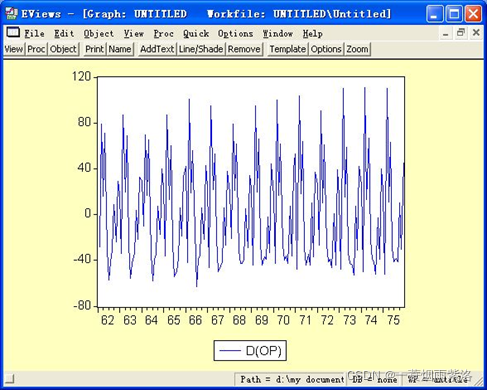
图3:一阶差分序列曲线图
可以看出序列不再具有趋势特征,一阶差分提取了线性趋势
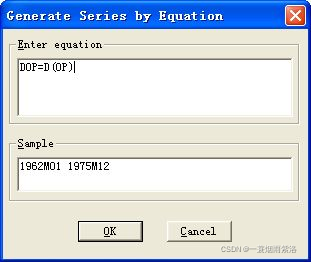
图4:对序列进行一阶差分
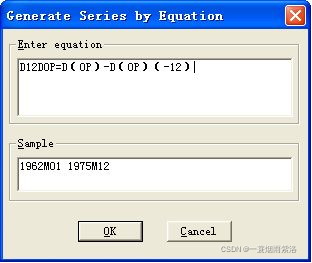
图5:对一阶差分序列进行12步周期差分
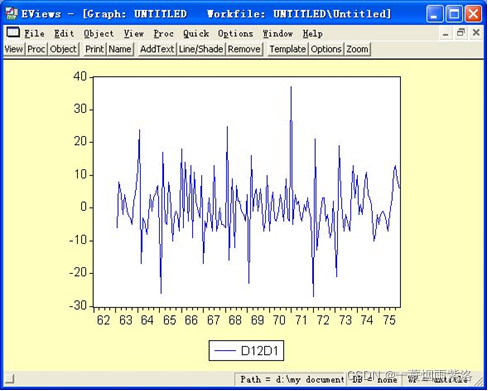
图6:绘制周期差分后序列
上述操作也可以用D(OP,1,12)命令来实现,即一阶――12步差分,因此直接绘制序列D(OP,1,12)的时序图结果如图6。
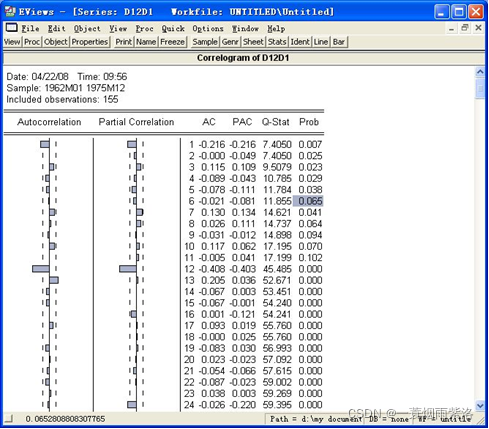
图7:周期差分后序列的相关图
可以看出序列自相关系数12阶显著,说明还是有一定的周期性

图8:对上面的序列再进行12步差分,绘制曲线图
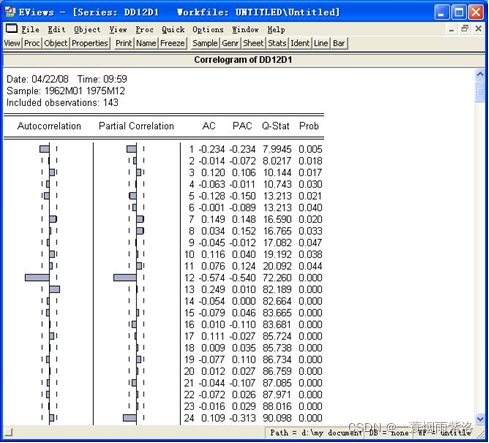
图9:序列的相关图
可以看出12阶相关系数仍然显著,且相关系数比D12D1序列的相关系数还大,因此我们就进行到上一步骤即可。
差分的方式小结
对线性趋势的序列,一阶差分即可提取确定性信息,命令为D(X);
对曲线趋势的序列,低阶差分即可提取序列的确定性信息,命令为D(X,a);
对具有周期性特点的序列,k步差分即可提取序列的周期性信息,命令为D(X,0,k)。
对既有长期趋势又有周期性波动的序列,可以采用低阶――k步差分的操作提取确定性信息,操作方法为D(X,a,k)。
非平稳序列如果经过差分变成平稳序列,则我们称这类序列为差分平稳序列,差分平稳序列可以使用ARIMA模型进行拟合。
二、ARIMA模型
差分平稳序列在经过差分后变成平稳时间序列,之后的分析可以用ARMA模型进行,差分过程加上ARMA模型对差分平稳序列进行的分析称为ARIMA模型。
分析1952-1988年中国农业实际国民收入指数序列
先观测序列的时序图,可知序列具有线性长期趋势,需要进行1阶差分。
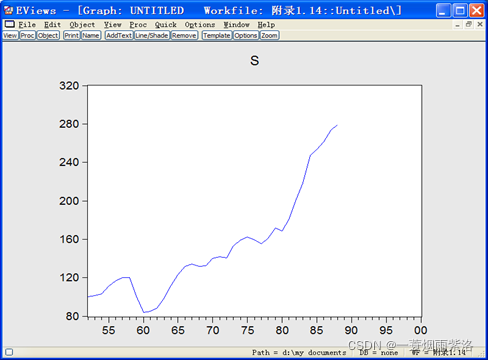
图1:1952-1988年中国农业实际国民收入指数时序图
再观测差分序列的时序图

图2:中国农业实际国民收入指数1阶差分后序列的时序图
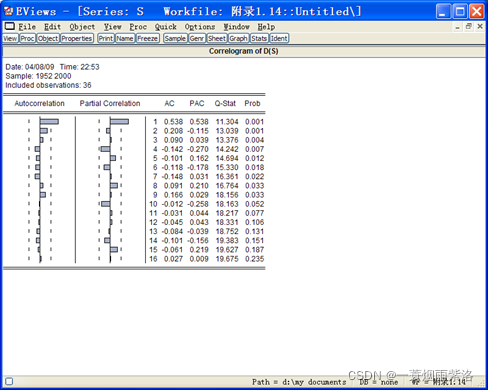
图3:国农业实际国民收入指数1阶差分后序列的相关分析
由图可知,序列1阶自相关显著,序列平稳;Q统计量P值小于0.05,非白噪声;同时,偏自相关拖尾、自相关一步截尾,建立ARIMA(0,1,1)模型。(建立ARIMA(0,1,1)模型,是因为偏自相关拖尾,所以第一个数值为0,然后因为序列进行了一阶差分,所以中间数值为1,又自相关图一阶截尾,所以最后一个数值为1.)

图4:中国农业实际国民收入指数的ARIMA(0,1,1)模型
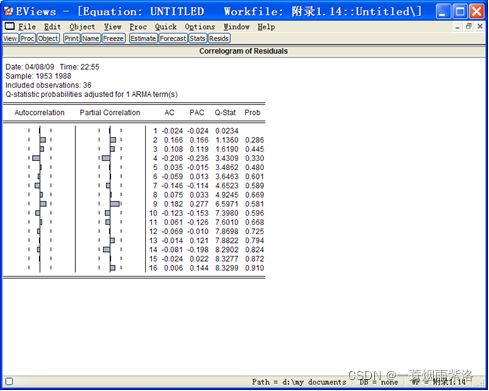
图5:模型残差的相关性分析
从图4和图5分析可知,残差为白噪声,模型信息提取充分;模型参数显著,模型精简,因此建立的ARIMA(0,1,1)模型合格,模型具体情况如下式:
(1-B)S=5.0156+(1-0.7082B)
图6:预测1989-2000年农业实际国民收入指数
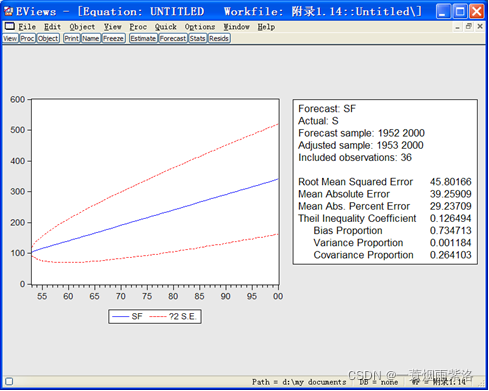
图7:1989-2000年农业实际国民收入指数预测图
三、季节模型
1.简单季节模型
附录1.13 对 1962.1――1975.12平均每头奶牛月产奶量序列进行分析
根据前面的分析可知,经过1――12步差分后, op变成平稳时间序列。
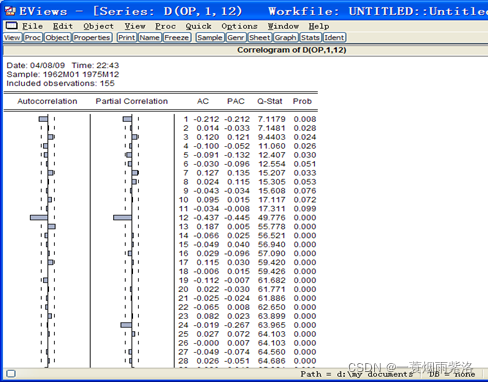
图1:序列D(OP,1,12)的相关分析图
经过相关分析看出自相关图具有短期相关性,是平稳时间序列;Q统计量的P值有小于0.05的情况,因此序列为平稳非白噪声序列。又观测自相关和偏自相关图,识别方程为一阶自回归方程

图2:序列D(OP,1,12)的AR(1)模型
图3:模型残差的相关分析
分析可知残差为白噪声,因而模型提取信息充分;观测图2可知模型参数显著,因而AR(1)模型可以提取平稳序列D(OP,1,12)的信息。
模型的具体信息为
(1-B)(1-B OP=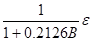
2.乘积季节模型
当序列中长期趋势、季节效应、随机波动可以很容易分开,我们用简单季节模型进行分析;但更为常见的是序列的三个部分不能简单分开,而是相互关联,这时要用乘积季节模型。
附录1.17 试分析1948-1981年美国女性(大于20岁)月度失业率序列
首先观测序列的时序图
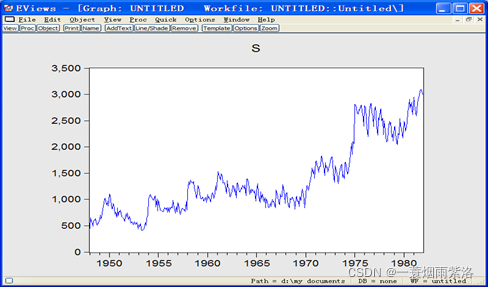
图1:1948-1981年美国女性(大于20岁)月度失业率序列时序图
由时序图可知,序列既有长期趋势又有周期性,因此进行1阶――12步差分
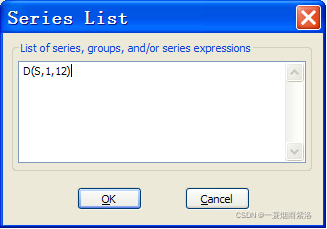
图2:进行1阶――12步差分
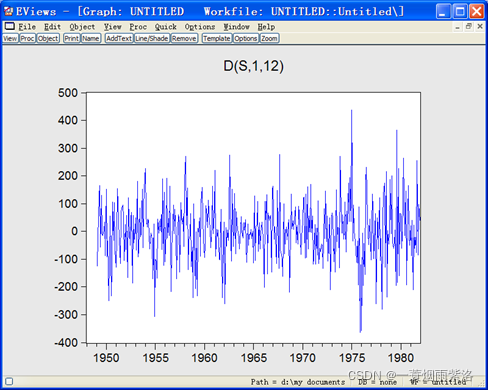
图3:D(S,1,12)的时序图
从时序图可以看出D(S,1,12)均值稳定,也没有明显的周期性,方差有界;通过相关分析,具体分析序列的平稳性,如图4。图4中可以看出自相关两阶显著,但是12阶也是显著的,因此在趋势平稳中又包含了周期性因素。
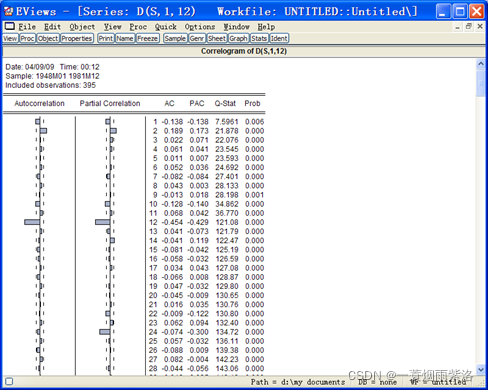
图4:D(S,1,12)的相关分析
用ARMA模型拟合序列D(S,1,12)尝试如下:

图5:AR(1,12)模型拟合序列D(S,1,12)

图6:AR(1,12)模型拟合序列D(S,1,12)的残差相关图
可以看出模型残差非白噪声,模型提取信息不充分。
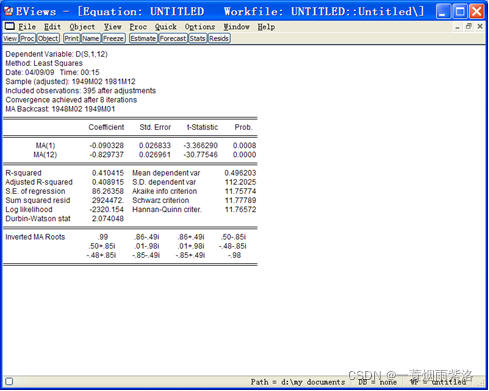
图7:MA(1,12)模型拟合序列D(S,1,12)
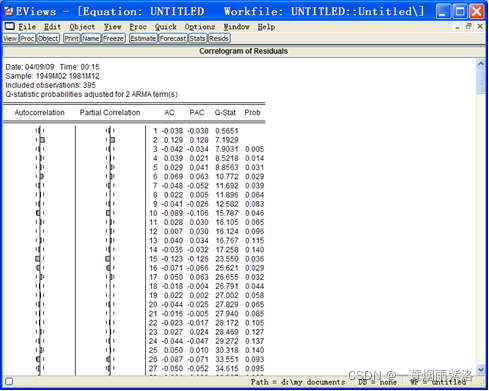
图8:MA(1,12)模型拟合序列D(S,1,12)残差相关图
可以看出模型残差也非白噪声,模型提取信息不充分。
这种情况下我们尝试乘积季节模型
图9:ARMA(1,1)×(1,0,1) 拟合序列D(S,1,12)
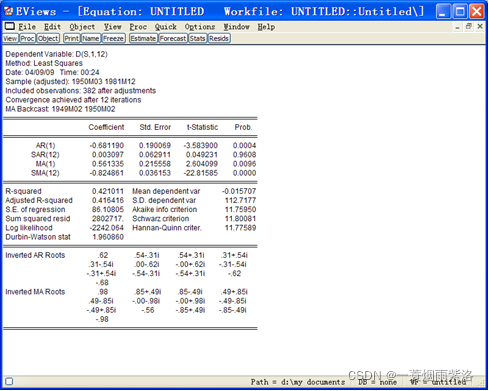
图10:ARMA(1,1)×(1,0,1) 模型的参数
可以看出SAR(12)的参数并不显著,因此删除该项。
图11:ARMA(1,1)×(0,0,1) 拟合序列D(S,1,12)

图12:ARMA(1,1)×(0,0,1) 模型的参数

图13:乘积模型的残差相关图
可以看出乘积模型的残差为白噪声序列,该模型提取序列的信息充分;参数都显著,因此模型精简;模型的具体形式为:
(1-B)(1-B )S=