在以生成标签对应关键词为核心思想的半监督文本分类中,现有的大多数方法都以一种与上下文无关的方式生成伪标签,因此,人类语言的模糊性和上下文依赖性一直被忽视。本文利用词出现的上下文化表示和种子词信息来自动区分同一词的多种解释,从而创建上下文化语料库,该语境化语料库进一步以迭代的方式训练分类器和扩展种子词,最终提升半监督文本表示的性能。
Overview
问题的定义还是那几种符号,跳过:

本文提出了一个框架,ConWea,构建语境话的弱监督模型。在这里,语境化体现在两个方面:语料库和种子词。因此,相应地开发了两种新技术来实现这两种语境化。
- 选择BERT作为实现中的一个例子,以生成每个word occurrence的上下文化向量。这里的word occurrence可以理解为一个词的不同分身,用来表示一个相同的单词在不同句子、上下文中出现所体现的语境。
- 设计了一种有原则的比较排序方法,从语境化的语料库中选择高度标签指示性的关键词,从而得到语境化的种子词。具体来说,从种子词的所有可能的解释开始,并训练一个神经分类器。基于这些预测,我们比较和对比属于不同类别的文档,并根据标签指示性和频繁程度对上下文化的单词进行排序。
模型的总体迭代过程如图1所示。
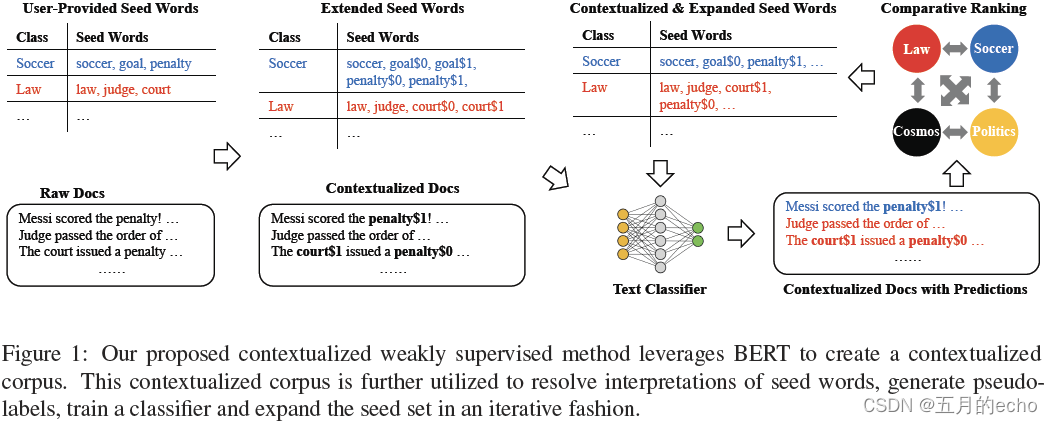
Document Contextualization
具体来说,给定一个单词
w
w
w,我们将它出现的所有次数都表示为
w
1
,
.
.
.
,
w
n
w_1,...,w_n
w1?,...,wn?,其中
n
n
n是它在语料库中出现的总次数。那么一个单词根据其情境的不同,可以有最多
n
n
n种表示。为了衡量不同语境的相似性,可以使用不同表示(
b
w
i
,
b
w
j
b_{w_i},b_{w_j}
bwi??,bwj??)的余弦相似度进行代替。
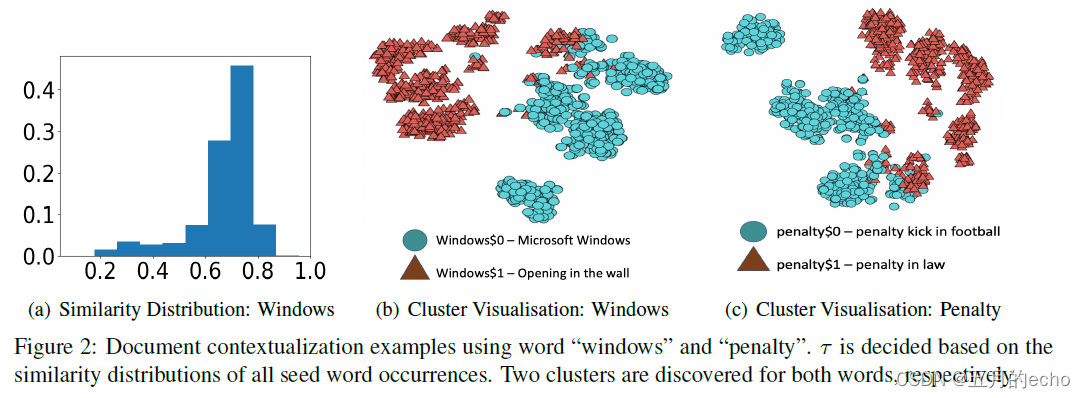
Choice of Clustering Methods。在有了单词表示之后,对相同单词的不同语境可以进行聚类,来统一相似的语境。在本文中使用了K-Means进行聚类。为了判定
w
i
,
w
j
w_i,w_j
wi?,wj?是否属于一个聚类,规定了参数
τ
\tau
τ。通过判断两个聚类中心向量的余弦相似度是否比
τ
\tau
τ大来判断两个聚类是否属于同一解释。因此,
K
K
K也就是聚类中心的个数可以表示为:
 c
i
c_i
ci?表示聚类中心的向量,并且
τ
\tau
τ根据用户提供的种子词进行调整:(1)对于任何种子词,其出现的大多数情况遵循用户的预期解释;(2)大多数种子词没有歧义――它们只有一种解释。因此,对于每个种子词
s
s
s,我们取其出现次数之间成对余弦相似度的中位数:
c
i
c_i
ci?表示聚类中心的向量,并且
τ
\tau
τ根据用户提供的种子词进行调整:(1)对于任何种子词,其出现的大多数情况遵循用户的预期解释;(2)大多数种子词没有歧义――它们只有一种解释。因此,对于每个种子词
s
s
s,我们取其出现次数之间成对余弦相似度的中位数:

也就是说
τ
(
s
)
\tau(s)
τ(s)剔除了一半不相似的种子词。同样,对所有的
τ
(
s
)
\tau(s)
τ(s)计算一个中位数,就可以得到
τ
\tau
τ:

下图是Windows以及penalty这个词在聚类过程中的实例可视化:
**Contextualized Corpus.**经过聚类之后,一个单词对应的“分身”便可以由其所属的cluster进行表示,形式化描述如下:
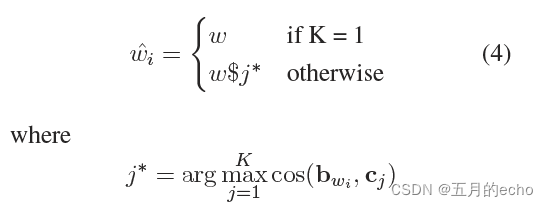
Pseudo-Label and Text Classifier
为文档生成为标签的过程依然采用简单的投票方式:

其中
t
f
(
)
tf()
tf()表示上下文化的单词
w
w
w在上下文化的文档
d
d
d中的词频,也就是说不同的cluster要根据上一步的计算结果区分来看。而至于文档的分类呢,采用了简单的HAN:
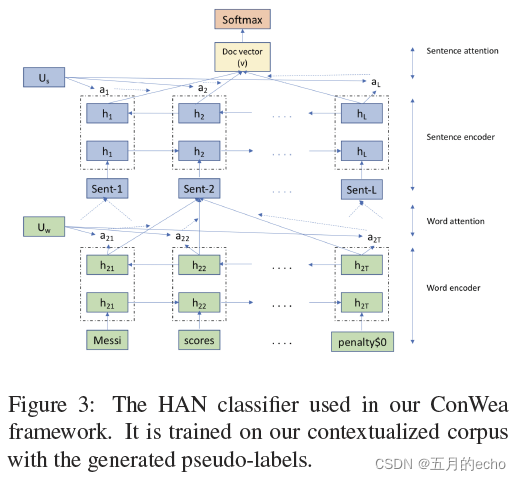
Seed Expansion and Disambiguation
给定上下文化的文档及其预测的类标签,我们建议对上下文化的单词进行排序,并将前几个单词添加到种子单词集中。这里,种子词的考虑包括三方面:
- Label-Indicative。也就是给定一个文档,合格的种子词
w
w
w其出现的句子
C
j
C_j
Cj?应该百分百属于种子词所属的标签。公式化描述为:

- Frequent。标签
l
l
l的种子词
s
s
s会以显著频率出现在属于标签
l
l
l的文档中。也就是:

- Unusual。希望高度标签指示性和频繁的单词是不寻常的。为了结合这一点,我们考虑逆文档频率(IDF):

最终,一个词是否称为关键词的得分为:

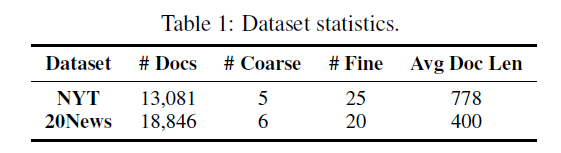
Experiments
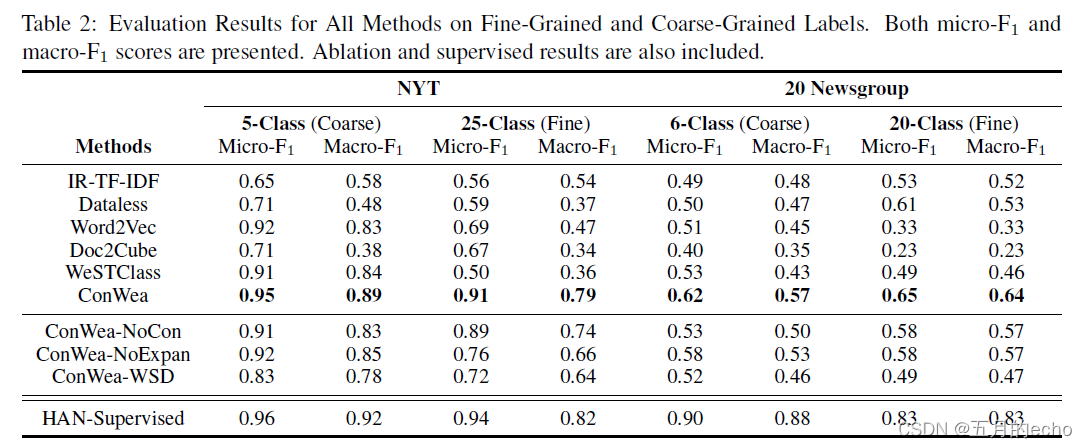
每个class种子词的数量:
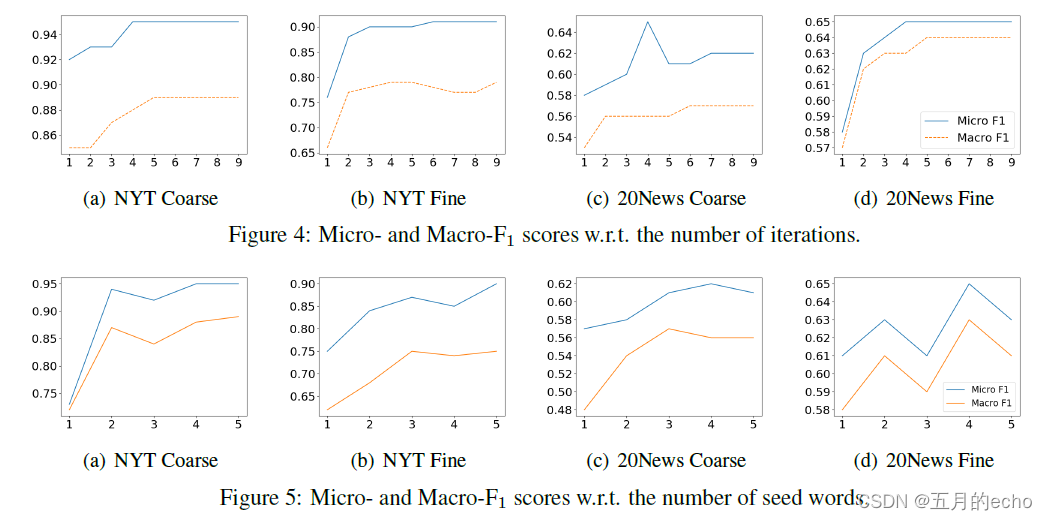
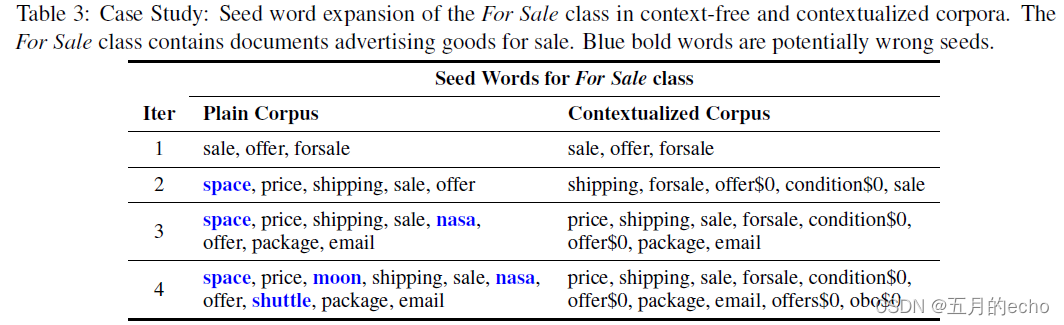
案例分析,编号代表迭代次数。可以看到随着迭代,本文的方法能够识别出来不同的情境的种子词,并做出有利的区分。