运行环境
系统:Win10 CPU
解释器:Python
依赖包:Anaconda Pytorch
前言
本文无需了解任何AI先验知识(当然有更好),快速入门AI基本脉络,手把手教你一步步搭建神经网络,并解决一个分类手写数字的实际问题。
基本流程:
- 搭建环境,导入依赖包
- 下载MNIST数据集,并做预处理
- Dataset转化为Pytorch能识别的DataLoader
- 构建神经网络,设置各层神经元及优化方式
- 训练神经网络,进入学习阶段
- 测试神经网络,进入推理阶段
实现细节
搭建环境,安装依赖包
!conda install pytorch-cpu -c pytorch # 导入pytorch依赖包
!pip install torchvision # pytorch关于图像视频的包
导入依赖包
import torch
import torchvision
from sklearn.datasets import fetch_openml
import matplotlib.pyplot as plt
# % matplotlib inline
import torch
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from torch import nn
import numpy as np
数据集预处理
# pre-processing
mnist = fetch_openml('mnist_784', data_home='.')
X = mnist.data / 255
y = mnist.target
# dataloader
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=1/7, random_state=0) # 数据切分,训练集:测试集=6:1
X_train = np.array(X_train) # 将list转为numpy格式
X_test = np.array(X_test)
y_train = list(map(int, y_train)) # 将label的str类型转为int
y_test = list(map(int, y_test))
X_train = torch.Tensor(X_train) # 转为浮点tensor
X_test = torch.Tensor(X_test)
y_train = torch.LongTensor(y_train) # 转为整型tensor
y_test = torch.LongTensor(y_test)
ds_train = TensorDataset(X_train, y_train) # 转为Dataset
ds_test = TensorDataset(X_test, y_test)
# 转为Pytorch可以直接操作彻底DataLoader
loader_train = DataLoader(ds_train, batch_size=(64), shuffle=True)
loader_test = DataLoader(ds_test, batch_size=(64), shuffle=True)
搭建神经网络,Keras风格,选其一即可
# build nn with keras sytle
model = nn.Sequential() # 获取网络模型句柄
model.add_module('fc1', nn.Linear(28*28*1, 100)) # 第一层神经元,输入层
model.add_module('relu1', nn.ReLU()) # 第一层激活函数
model.add_module('fc2', nn.Linear(100, 100)) # 第二层神经元,中间层
model.add_module('relu2', nn.ReLU()) # 第二层激活函数
model.add_module('fc3', nn.Linear(100, 10)) # 第三层神经元,输出层
print(model)
输出结果如下:
Sequential(
(fc1): Linear(in_features=784, out_features=100, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=100, out_features=100, bias=True)
(relu2): ReLU()
(fc3): Linear(in_features=100, out_features=10, bias=True)
)
搭建神经网络,Chainer风格,选其一即可
# build nn with chainer style
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, n_in, n_mid, n_out):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_in, n_mid)
self.fc2 = nn.Linear(n_mid, n_mid)
self.fc3 = nn.Linear(n_mid, n_out)
def forward(self, x):
h1 = F.relu(self.fc1(x))
h2 = F.relu(self.fc2(h1))
output = self.fc3(h2)
return output
model = Net(n_in=28*28*1, n_mid=100, n_out=10)
print(model)
输出结果如下:
Net(
(fc1): Linear(in_features=784, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=100, bias=True)
(fc3): Linear(in_features=100, out_features=10, bias=True)
)
损失函数设置
# loss function
from torch import optim
loss_fn = nn.CrossEntropyLoss() # 选取交叉熵作为误差函数
optimizer = optim.Adam(model.parameters(), lr=0.01) # 设置优化器参数,学习率0.01
训练神经网络,设计学习阶段和推理阶段
# learning and predict process
# 训练阶段
def train(epoch):
model.train()
for data, targets in loader_train:
optimizer.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
print("epoch{}:结束\n".format(epoch))
# 推理阶段
def test():
model.eval()
correct = 0
with torch.no_grad():
for data, targets in loader_test:
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
correct += predicted.eq(targets.data.view_as(predicted)).sum()
data_sum = len(loader_test.dataset)
print("\n 测试数据的准确率 : {}/{} ({:.0f}%)\n".
format(correct, data_sum, 100. * correct / data_sum))
# 训练前的分类准确率
test()
# 训练3个epoch过程
for epoch in range(3):
train(epoch)
# 训练后的分类准确率
test()
输出结果如下:
测试数据的准确率 : 981/10000 (10%)
epoch0:结束
epoch1:结束
epoch2:结束
测试数据的准确率 : 9596/10000 (96%)
推理分类特定图片
# predict particular picture
# 推理第8505张图片的数字类别
index = 8505
model.eval()
data = X_test[index]
output = model(data)
_, predicted = torch.max(output.data, 0)
print("预测结果是{}".format(predicted))
X_test_show = (X_test[index]).numpy()
plt.imshow(X_test_show.reshape(28, 28), cmap='gray')
print("这一图像数据的正确标签是{:.0f}".format(y_test[index]))
输出结果如下:
测试数据的准确率 : 9548/10000 (95%)
预测结果是0
这一图像数据的正确标签是0
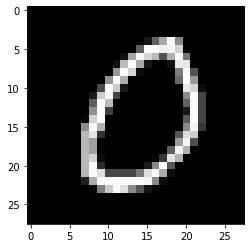
问题讨论
DataLoader的用途?
- pytorch与外界数据沟通的桥梁
- dataloader能供pytorch直接使用
- dataloader作为python自带的numpy数据类型中转
- 过程:numpy -> tensor -> dataset -> dataloader
遗留:
_,predict = torch.max(), 下划线_是啥意思?- conda和spyder的环境依赖关系是?
参考资料
- 边做边学深度强化学习,link
声明:本文主体代码来自于书籍《边做边学深度强化学习》,只是在手敲其代码的过程中,添加一些自己的理解,详情可以查阅对应章节。