所有的机器学习算法都需要输入数值型的向量数据,图嵌入通过学习从图的结构化数据到矢量表示的映射来获得节点的嵌入向量。它的最基本优化方法是将具有相似上下文的映射节点靠近嵌入空间。我们可以使用两种正交方法(同质性和结构等效性)之一或它们的组合来定义图中节点的上下文。
图数据库和机器学习
图数据库可以支持来自各种来源的相互关联数据的大数据应用。它们允许使用一种简洁的查询语言来分析数据中的复杂关系模式,例如PageRank、中心性检测、链接预测、模式识别等算法可以用简单直观的方式来表述。
大多数成熟的传统机器学习算法,如线性和逻辑回归、神经网络等,都是在数值向量表示上工作的。为了将图数据库和和机器学习结合就需要一种方法来以向量形式表示我们的数据网络。图嵌入就是从图中的数据中准确学习这种映射的一种形式。
图嵌入的目的
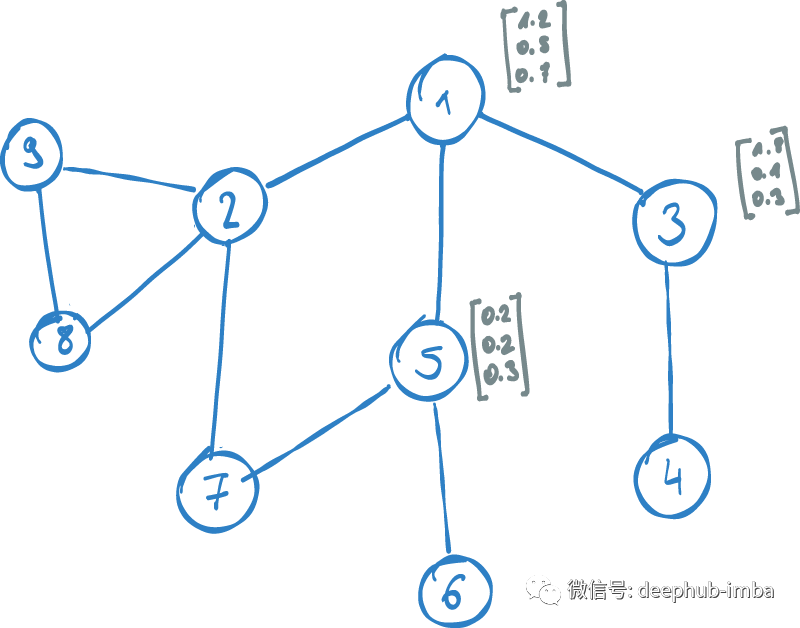
图嵌入的目标是找到图中每个节点的向量表示,该向量的映射代表节点的网络结构,而不是考虑节点的相关特征。换句话说,一个节点的嵌入向量应该基于它的关系和相邻节点。图结构中相似的节点应在向量空间中紧密映射。我们将节点映射到的向量空间称为嵌入空间。
上面的描述中有两个问题需要额外思考:
- 图中的两个节点相似怎么判断?
- 嵌入空间中的 “紧密” 是什么意思?
网络中的相似节点
为了详细说明图中的相似性,暂时考虑一个句子:

句子可以被理解为是一个单词的序列,每个单词都有一个确定的位置。因此,一个句子中的一个词恰好有一个祖先和一个后继。要定义句子中单词的上下文,可以使用围绕它的单词。例如,单词“capital”的距离一上下文是单词“the”和“of”。距离二的上下文是“is”、“the”、“of”、“Germany”。这被称为 n-gram 模型,也就是word2vec 嵌入使用的方法。
与n-gram类似我们可以在图中定义节点的上下文,并且在图结构中比在单词序列中有更多的选择。因为在一般的图中每个节点可能连接到两个以上的其他节点――而在一个句子中,一个单词只有一个直接祖先和后续节点。
一个句子是一个向量,可以通过沿着索引轴移动来探索单词的上下文。图被描述为一个二维邻接矩阵,节点的直接祖先是一个向量。在每个距离级别上探索节点的上下文有多个选择,必须决定如何遍历这些选择。
一般来说,探索网络上下文有两种正交方法:
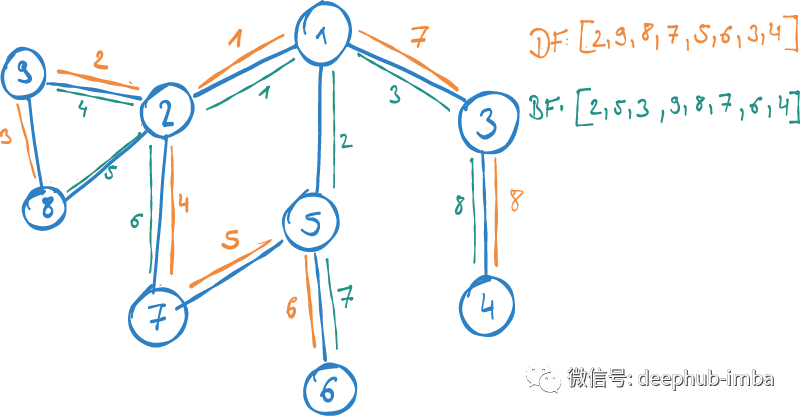
宽度优先:在(可能)移动到距离为2的节点之前,我们首先详细说明源节点的直接邻居。这也被称为同质性,源于一个社会学概念,即人们通常倾向于与相似的人密切互动。因此它是基于图中相似节点关系密切的假设。
深度优先:首先通过从源节点开始到其深度的路径来探索一个连接链,然后再继续下一个。与同质性相反,这个度量从更广泛的角度捕捉网络中节点的角色。不是着眼于密切的关系,而是寻找节点的结构角色:例如,它是如何嵌入到更大的社区环境中。这个度量称为结构等价。
可以使用这两种方法来查找节点的上下文――也可以将它们组合在一起。拥有一组描述每个节点上下文的节点,可以使用这些节点来比较每对节点的上下文相似性。例如,可以应用Jaccard相似性来度量两个上下文重叠的程度。这将为我们提供一种在图中找到具有相似网络结构的节点的方法。

上下文的抽样
但是有可能不能采样给定节点的整个上下文,因为这最终会导致捕获整个图。因此采用了一种近似的抽样策略。其思想是在源顶点中开始固定数量的随机游走,并探索其上下文生成一个随机样本。node2vec定义的抽样策略结合了同质性和结构等价性。它包含了决定在游走的每一步中,是应该保持在源节点附近(同质性),还是应该探索另一个距离水平(结构等效)的参数。
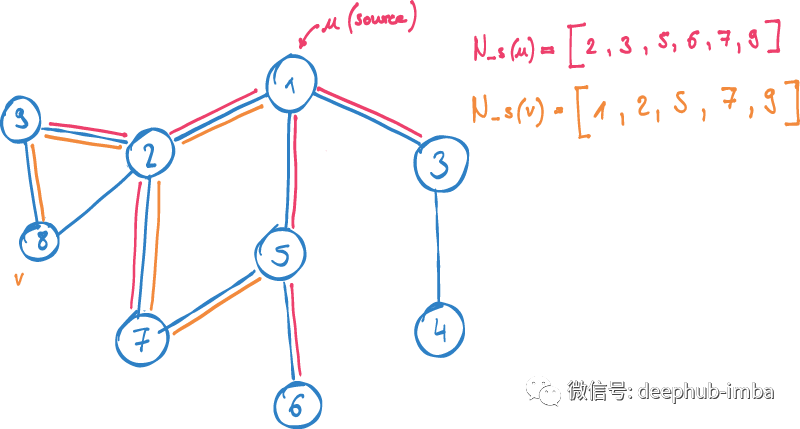
在node2vec中,没有使用前面描述的Jaccard相似性,而是尝试为每个节点找到一个数值向量。利用图中节点的采样上下文优化映射函数将具有相似上下文的节点映射到一起。
node2vec的数学原理
通过下面的例子来详细了解node2vec是如何工作的:
V:图中所有节点
N_S(u):由样本策略S确定的u的邻域
F (u):节点u到向量的映射函数
目标是找到V中所有节点u的嵌入,使具有相似上下文的节点的向量表示在嵌入空间中接近。虽然已经知道图中的相似上下文意味着什么,但仍然需要定义嵌入空间中的“接近”是如何表示的。

现在只考虑图中的两个节点:
u:源节点
V: u上下文中的节点
为了开始数学原理的介绍,简单地选择两个随机向量f(u), f(v)作为两个节点。度量嵌入空间中的相似性,需要使用两个向量的点积,也就是它们之间的夹角。

由于节点 v 在 u 的附近,所以可以逐步优化映射函数 f,以使它们的相似性最大化。
为了将相似性转化为概率,需要对其应用 softmax。softmax 将相似度得分 dot(f(u), f(v)) 归一化为 u 与 V 中所有其他向量 v 的所有相似度之和。因此点积被转换为 [0,1] 之间的数字 并且所有相似性加起来就是1, 结果就是从向量表示中在节点 u 的上下文中看到节点 v 的概率。现在,可以通过使用随机梯度下降更新我们的向量 f(u) 来逐步优化这个概率。
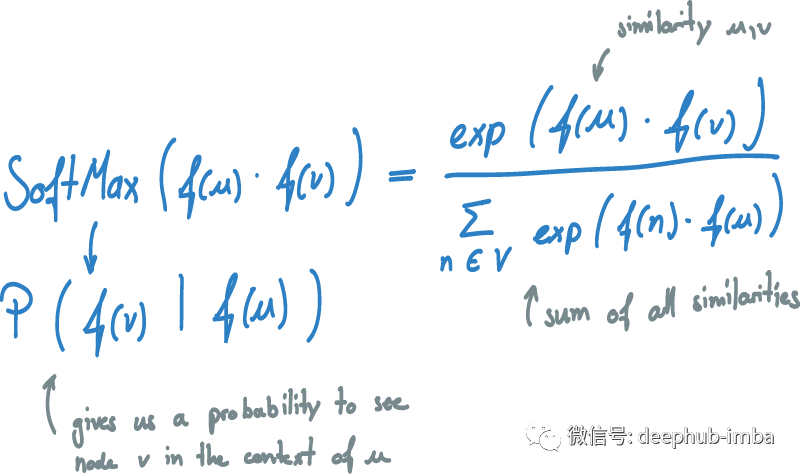
下一步是推广这个概念,不仅对 N_S(u) 中的一个节点 v 进行优化,而且对 u 上下文中的所有节点进行优化。如果给定节点 u,希望可以优化看到的整个采样上下文的概率。如果假设样本是独立的,可以将这个公式简化为简单概率的乘积。
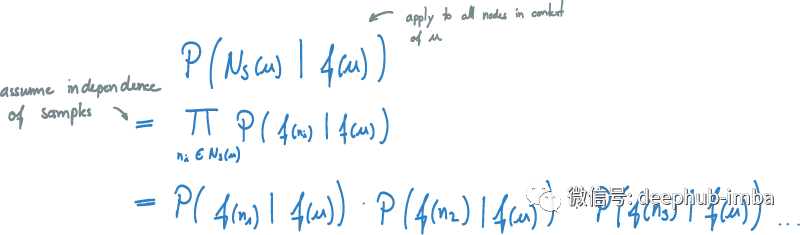
要学习图中每个源节点 u 的映射,需要将公式同时应用于图的所有节点。使用 SGD 通过调整映射 f 来优化总和,从而增加概率。通过多次迭代直到达到最大迭代次数或在优化问题中找到一个固定点。
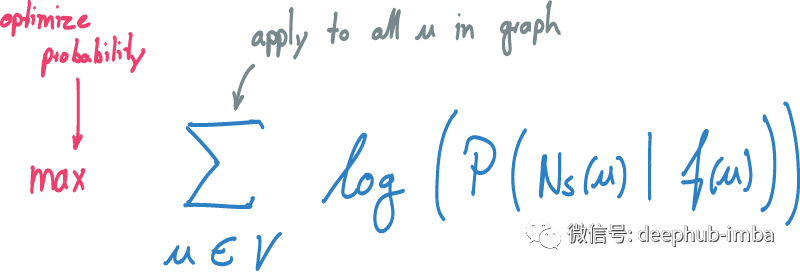
补充说明
该解决方案在大型数据集上运行时存在一个主要挑战是:当计算 softmax 以确定概率 P(f(v) | f(u)) 时,分母中的归一化项很难计算。这个归一化项是 u 和图中所有其他节点的所有相似性的总和。它在优化的整个迭代中保持固定,因此对于源节点 u 的总和的所有迭代也是固定的。
另外一个挑战是:在所有向量上计算这样一个因子非常昂贵。在每次迭代中,我们必须确定每个源节点 u 与图中所有其他向量的点积,才能够找到归一化因子。为了克服这个问题,一种称为负采样的技术被用来近似这个因素。
边嵌入
上述方法也可以应用于不同的基本假设:我们还可以设置不同的目标,将边缘映射到嵌入空间,通过使这些边缘接近共享相同的节点,而不是找到具有相似上下文的节点的映射。结合 node2vec 中的节点和边嵌入,可以推导出更通用图嵌入,它能够将相互关联的数据映射到向量表示。
总结
本文介绍了如何找到映射 f(u) 以将图的节点映射到向量空间,从而使相似的节点接近。有多种方法可以定义图上下文中节点的相似性:同质性和结构等效性,两者都具有正交方法并且 node2vec 定义了将两者组合成参数化采样策略的。
采样策略是一种查找节点上下文的方法,嵌入空间中的相似性依次定义为两个映射向量之间的点积。嵌入本身是使用随机梯度下降的迭代优化。它在每次迭代中调整所有节点的向量,以最大化从同一上下文中看到节点的概率。非常大的数据集的实现和应用需要一些统计近似来加速计算。
node2vec: Scalable Feature Learning for Networks. A. Grover, J. Leskovec. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016.
作者:Philipp Brunenberg
https://www.overfit.cn/post/4012a7b482bf477283c84fd0ec61c388