 ? ? ?
? ? ?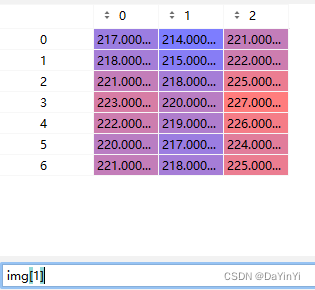
 ? ? ? ? ? ?
? ? ? ? ? ?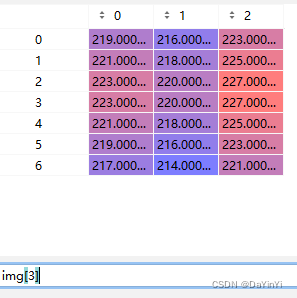
高度为4 宽度为7 通道为3? ?




? ??? ? ? ? ? ?
??? ? ? ? ? ?
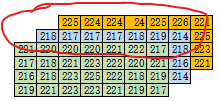
- 输出是?三维矩阵,这个判断比较简单,从第一个 “[” 开始数,直到第一个 “]” 时,有几个 “[” 就是几维的,这和输出的 img.shape 也肯定是对应的。
- 输出的图像 shape 为 H * W * 3,即 高度 * 宽度 * 3通道 或者 行数 * 列数 * 3通道。
- 图像的 shape 为 (4, 7, 3),第一维 4 表示有 4 行,所以有 4 个小的二维矩阵,每个二维矩阵是三通道图像中的一行
像素值以?矩阵方式?保存,矩阵的大小取决于图像采用的颜色模型。
如果是灰度图,那么图像就是单通道的,图像中的每个像素只需要一个矩阵元素来保存,一般就是 0~255 的值。
保存灰度图的矩阵长这样:

其中 Row0 和 Column0 的交点上的元素值就代表了图像上对应位置的像素的灰度值。
如果是彩色图,那么图像就是多通道的,一个像素需要多个矩阵元素来保存,矩阵中的列会包含多个子列,且子列数和通道数相等。
保存 RGB 图像的矩阵长这样:

?3个4*7的特征图,且由于pytorch做矩阵加减乘除以及卷积等运算是需要调用cuda和cudnn的函数的,而这些接口都设成成chw格式了,故而pytorch为了方便起见也设计成chw格式了
img = cv2.imread("test.jpg")
img_ = img[:,:,::-1].transpose((2,0,1))?在opencv里,图格式HWC,其余都是CHW,故使用方法transpose((2,0,1)),transpose(2,0,1)就是读入第三维的数C作为第一维的值,读入第一维的数H作为第二维,读入第二维的数作为第三维W,如果再高维,就再按照输入的读取顺序来读【4】。
img[:,:,::-1]对应H、W、C,彩图是3通道,即C是3层。opencv里对应BGR,故通过C通道的 ::-1 就是把BGR转为RGB,其中[::-1] 代表顺序相反操作。
先通过切割的算法,将图片的大小一步步缩小为小数字,以便观察
from PIL import Image
filename = r'01.png'
img = Image.open(filename)
size = img.size
print(size) #(1920, 1200)
# 准备将图片切割成9张小图片
weight = int(size[0] // 3)
height = int(size[1] // 3)
# 切割后的小图的宽度和高度
print(weight, height) #640 400
for j in range(3):
for i in range(3):
box = (weight * i, height * j, weight * (i + 1), height * (j + 1))
# (j, i) 左上右下
#(0,0/1/2) box00(0, 0, 640, 400) box01(640, 0, 1280, 400) box02(1280, 0, 1920, 400)
#(1,0/1/2) box10(0, 400, 640, 800) box01(640, 400, 1280, 800) box02(1280, 400, 1920, 800)
#(2,0/1/2) box20(0, 800, 640, 1200) box01(640, 800, 1280, 1200) box02(1280,800,1920, 1200)
region = img.crop(box) # 进行裁剪
region.save('{}{}.png'.format(j, i))然后,显示图片大小
# 导入需要的包
import PIL
from PIL import Image
import numpy as np
# 读入图片
image = PIL.Image.open('01.png').convert('RGB')
img = np.array(image).astype(np.float32)
# 查看数据形状,其形状是[H, W, 3],
print(img)
print(img.shape) # (1200, 1920, 3) 其中H代表高度, W是宽度,3代表RGB三个通道