�ݶ��½�
�ڻ���ѧϰ��,�����ǻع黹�Ƿ���,���Ǵֵ�Ŀ�����Ż���ʧ����ʹ����С,������û����ҵ�ʹ��ʧ������С�IJ���?�������ֵ�֪ʶ����֪���ں����ļ�Сֵ�㸽��,������ź����ݶȵķ�������,����ֵ���½���:
L
(
w
��
)
<
L
(
w
)
,
w
��
=
w
?
��
?
L
?
w
L(w')<L(w),w'=w-\alpha\frac{\partial{L}}{\partial{w}}
L(w��)<L(w),w��=w?��?w?L?
�����Իع�����Ϊ��(����ͼ),��ʧ����Ϊ���κ�����ʽ�е�aΪѧϰ��,��ѧϰ�ʽ�С��ʱ��,Ȩ���ݶ��Ż����ٶȽ���,��ʧÿ�α仯�ķ��Ƚ�С,��������Сֵ���ٶ�������֮ѧϰ�ʽϴ�ʱ,����ÿ�α仯���ȴ�,���ܵ��������Ż���Ϊ��ֵ���ȶ�,����������������ʵ��������ѡһ�����ʵ�ѧϰ�ʱȽ���Ҫ��
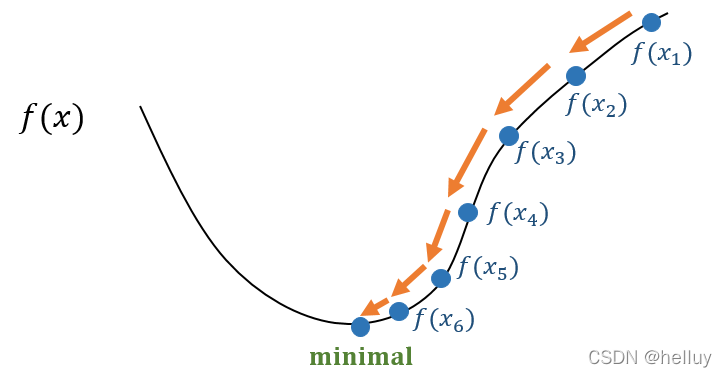
�ݶ��½�˼�������ѧϰ���Ż��Ļ���˼��,���DZ����ݶ��½�������������ʵ������,��Ϊÿһ��ִ���ݶ��½���Ҫ����ȫ����������ʧ,���ڵ��������е���˴�ļ�����,����Ҫ���ݶ��½��������Ż������õķ���Ϊ���¼�����
����ݶ��½�(SGD)
����ݶ��½�Ӧ�õ���ͳ��ѧ����������ķ���,����������ֱ�Ӽ���,���������ȡ�����������������������ƹ��ơ������ݶ��½�����ʧ��������:
f
(
x
)
=
1
n
��
i
=
1
n
l
i
(
x
)
f(x)=\frac{1}{n}\sum_{i=1}^{n}{l_i(x)}
f(x)=n1?i=1��n?li?(x)
����li(x)��ʾÿ����������ʧ,f(x)������ʱ��t�ϵ�����ʧ��
����ݶ��½�����ʱ��t������ȫ����������ʧ,���������ȡһ������ti����ʧ������ȫ����ʧf(x):
x
t
=
x
t
?
1
?
��
t
?
l
i
?
x
t
?
1
x_t=x_{t-1}-\alpha_{t}\frac{\partial{l_i}}{\partial{x_{t-1}}}
xt?=xt?1??��t??xt?1??li??
����xt,xt-1��ʾt��t-1ʱ�̵IJ���,atΪtʱ�̵�ѧϰ�ʡ�
Ϊʲô������ô��?��Ϊͳ��ѧ��,������������������������(�������������������ȡ4�����������������������������̫��,�ڴ�����������ȡ�п��Խ������),���������������ȡһ�������������:
E
[
?
l
i
(
x
)
]
=
E
[
?
f
(
x
)
]
E[\nabla l_i(x)]=E[\nabla f(x)]
E[?li?(x)]=E[?f(x)]����ĵȺŲ����ϸ����,���ǽ��������
����ݶ��½��ĺô������ҿ���ÿ�β�������ʱ��һ����������ʧ,����ݶ����ݶȸ���,����ļ����˺ķѵ���Դ��
С��������ݶ��½�
������֪����������ݶ��½���ÿ�γ�ȡһ������,���Ǻ��ȶ�(���и߷���),����ֱ�Ӵ�ȫ�����������1��,������ȫ���ķ�����(�е����Ż���ͷ��),���������С��������ݶ��½�:��ʱ��t�ϳ�ȡb������(�������ѧϰ�е�batchsize),ͨ��������b���������ݶȵ�ƽ�����ƽ�f(x)��
x
t
=
x
t
?
1
?
��
t
b
��
i
��
I
t
?
l
i
(
x
t
?
1
)
=
x
t
?
1
?
��
t
b
��
i
��
I
t
?
l
i
?
x
t
?
1
x_t=x_{t-1}-\frac{\alpha_{t}}{b}\sum_{i\in I_t}\nabla l_i(x_{t-1})=x_{t-1}-\frac{\alpha_{t}}{b}\sum_{i\in I_t}\frac{\partial{l_i}}{\partial{x_{t-1}}}
xt?=xt?1??b��t??i��It?��??li?(xt?1?)=xt?1??b��t??i��It?��??xt?1??li??
����It��ʾ����b�������ļ���,x�Dz�����
������ݶ��½���˼����ͬ,��Ҳ��һ����ƫ����,���ȱ�������ݶ��½����и�С�ķ��
������(momentum)
��ʵ��������,��Ե���ʧ��������ʮ�ֲ�ƽ��,��������ݶȵķ���������Ȩ�ػᵼ�²��ȶ�(��Ϊ��һʱ�̵��ݶȷ�����������һʱ����ȫ�෴),���һ��и�����:��������ֲ���С�����Կ�������һ������ʹ�ݶȵĸ��·�����ȫ������ǰ�ݶȵķ���,���ǻ�Ҫ����֮ǰ���ݶȷ���,ͨ��˵���������һ�����ܲ���������ͣ�»����й���ʹ��������ǰ��һ�ξ��롣����������Խ��һЩ����ֵ���ҵ�ȫ�ּ���ֵ��
g
t
=
1
b
��
i
��
I
t
?
l
i
(
x
t
?
1
)
g_t=\frac{1}{b}\sum_{i\in I_t}{\nabla l_i(x_{t-1})}
gt?=b1?i��It?��??li?(xt?1?)
��С��������ݶ��½�һ��,gt��ʾtʱ�̵Ľ����ݶȡ����dz����������Ը��ݶȸ��²���,������vt:
v
t
=
��
v
t
?
1
+
g
t
v_t=\beta v_{t-1}+g_t
vt?=��vt?1?+gt?
w
t
=
w
t
?
1
?
��
v
t
w_t=w_{t-1}-\alpha v_t
wt?=wt?1??��vt?
����
��
\beta
���Ǹ�С��1����0����,��vt�ĵ���ʽ���Կ���,vt�ۺ���֮ǰ���ݶ�(gt,gt-1,��,g1),ʹ����wt��������ʱ����֮ǰ���ݶȸ��·���,����ʱ����tʱ��Խ��,�Ե�ǰ���ݶȸ���Ӱ��Խ��
v
t
=
g
t
+
��
g
t
?
1
+
��
2
g
t
?
2
+
.
.
.
+
��
n
?
1
g
1
v_t=g_t+ \beta g_{t-1}+{\beta}^2g_{t-2}+ ... + {\beta}^{n-1}g_1
vt?=gt?+��gt?1?+��2gt?2?+...+��n?1g1?
��
��
\beta
��Ϊ0ʱ,��������ͬ��С��������ݶ��½���
Adam
Adam����һ���Ż��㷨,�������SGD��ѧϰ��û��ô����,Ҳ��ʵ����������õķ���֮һ��
����Ȩ�ظ��¹�ʽ����:
�ȼ�¼��������vt,st:
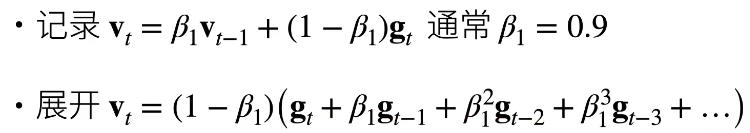
��tֵ��Сʱ,beta�ĵȱȼ����ĺͲ�Ϊ1,���Խ�vt����Ϊһ����ʽ:


Ȼ����в�������:

�����:
https://zhuanlan.zhihu.com/p/36564434
����C����ѧ���ѧϰv2
���ѧϰ�ʼ� 2022/02/26