�������еļ��������ʧ����&��������softmax������
ǰ�������ѧϰ���űʼ�1�����ѧϰ���űʼ�2���Ѿ������˼��������ʧ����,������һЩ����,��Ҫ�ǽ���softmax��������ʧ������
�����
sigmoid����
�������о���ʹ�õ�һ�����������sigmoid������
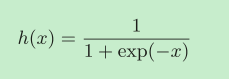
����ͼ����:
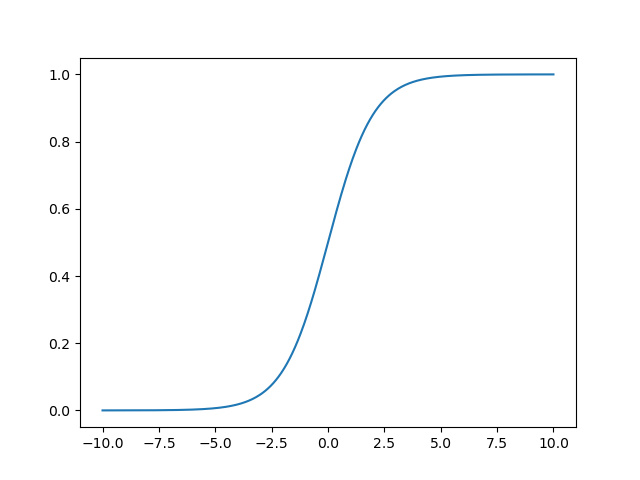
sigmoid���������ڻع����⡣
softmax����
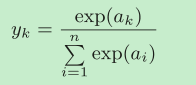
softmax�����ķ����������ź�ak��ָ������,��ĸ�����������źŵ�ָ�������ĺ͡�
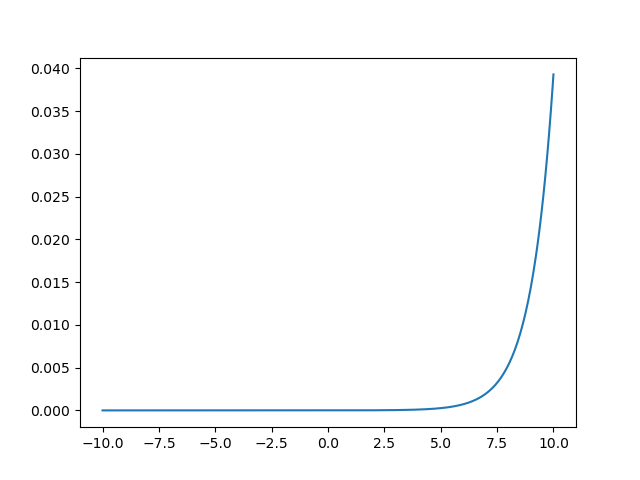
softmax�����������0.0��1.0֮���ʵ��������,softmax���������ֵ���ܺ���1,����softmax������һ����Ҫ���ʡ�����Ϊ�����������,���Dzſ�����softmax�������������Ϊ�����ʡ���
��softmax����������,��֪��Ӧ����һ����֮��Ӧ��hardmax,��ʵhardmax����ֱ�Ӽֱ���ѡ��һ�����ֵ,��softmax�����еĽ���Ը��ʵ���ʽ�����
softmax��������ȱ��
�ŵ��������ܲ��������͵��ݶ�,�־���һЩ���ŵ���ѧ������
- ��������͵��ݶȡ����������ѧϰ�к���Ҫ,sigmoid�������ⷽ��ͱ��ֵز��Ǻܺ�:sigmoid�����������ƽ̹���ݶ�,sigmoid���������б����0.25,���Ե�����Щ�ݶ��������ģ���е���һ������ʱ,��Щ�ݶ����ֻ�ܳ���4����������,�� sigmoid ����������С�ڨC2�����2ʱ,��Щ���������յ��ݶȽ�����Ϊ0,������Ϊ sigmoid(x) �� x = �C2 �� x = 2 ʱ������ƽ̹�ġ�����ζ��Ӱ����Щ������κβ��������յ���С���ݶ�,����������ѧϰ�ٶȻ����(��ʹ���ݶ��½���SGDʱ,�IJ���ֵ,Ȼ������۲췴���������ݶ�,Ȼ����Ϊsigmoid��������ƽ̹������,�����������ݶȼ���û��ʲô�仯,�����ζ��Ҫ���ж�ε��ݶ��½����ܿ���Ч��)
sigmiod�����ĵ���ͼ������:
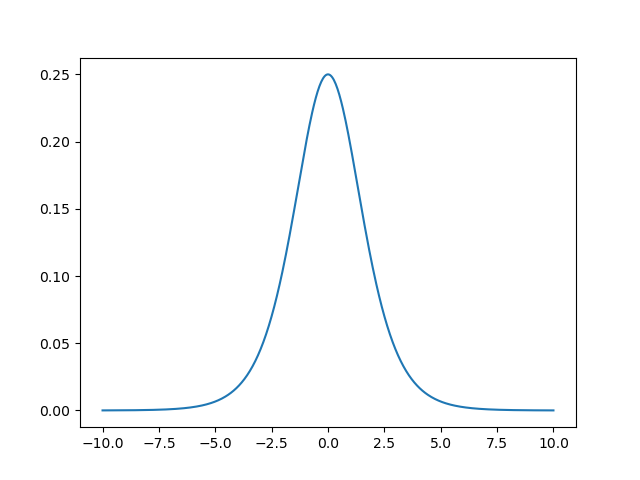
- ������ŵ���ѧ���ԡ������Ͻ�������ʧ����һ��˵����
ȱ�������������softmax������ʵ����Ҫ����ָ������������,���Ǵ�ʱָ��������ֵ�����ױ�÷dz�����,e10��ֵ �ᳬ��20000,e100����һ��������40���0�ij���ֵ,e1000�Ľ���᷵�� һ����ʾ������inf���������Щ����ֵ֮����г�������,�������֡���ȷ�����������
һ����������ǻ��ȡ�����е�����ֵ��ȥ����ֵ�е����ֵ,Ȼ���ٽ������㡣
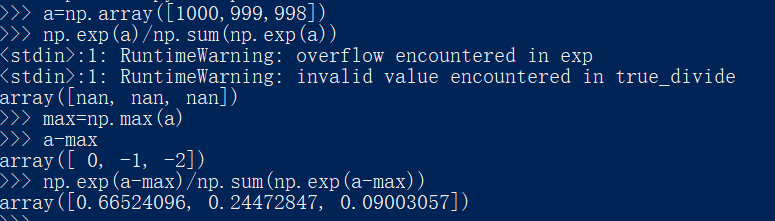
��ô�������������?�����,������Ϊ�ڽ���softmax��ָ������������ʱ,����(����ȥ) ij������������ı�����Ľ����
ReLU����
ReLU�����dz���,��� x С�� 0,�� ReLU �ض���Ϊ 0,������Ϊ x��
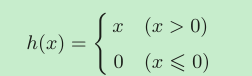
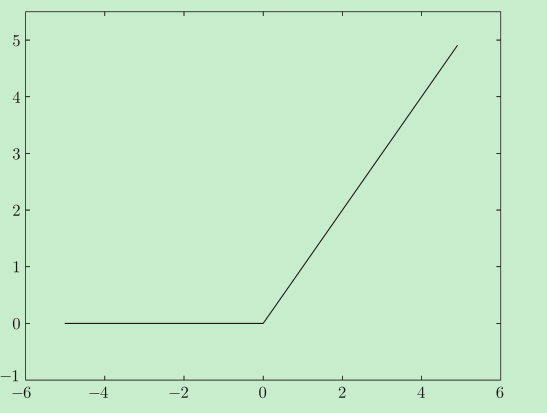
�ӵ����ͷ����ԵĽǶ�����,����һ������Ч���ļ���������������ݶ�Ҫ�� sigmoid ������ö�,�������������0,���ݶ�Ϊ1,���������Ϊ0,ƽ���ݶ�Ϊ0.5��ReLU ����������������ܹ����Ƿdz� ���е�ѡ��,������Ϊ����ȱ��(��С�� 0 �ʹ��� 0 ��ֵ֮���γ��˹������ԵIJ��)�� ��ͨ�������������ֲ���
ReLU��һЩ����:�� ReLU �����������С�� 0 ʱ,Leaky ReLU7 ������������ĸ�б��,�Ӷ���ǿ ReLU �����������ݶȵ������������Ӽ����ڼ����������濼��,ReLU�㹻Ӧ���ܶ�ij�����
Tanh����
Tanh��������sigmoid��ReLU ֮��,��һ�����з���,������״�� sigmoid ��������,�������ȡֵ��Χ�� �C1 ~ 1��
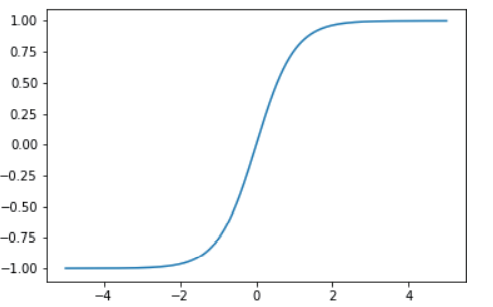
�������� sigmoid ���߸����͵��ݶ�:
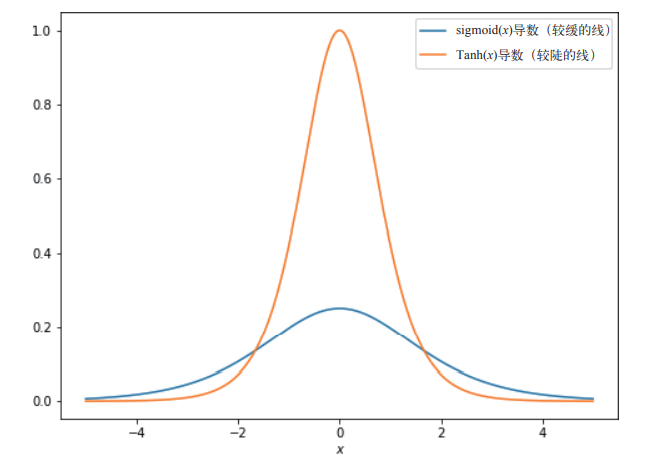
f=sigmoid(x)��f=Tanh(x)�����ŷ������ĵ���: f`=sigmoid(x)*(1-sigmoid(x)) �� f`=1-Tanh2(x) ��
��ʧ����
�������ѧϰ��Ҫͨ��ij��ָ���ʾ����ģ�͵�״̬,Ȼ�������ָ��Ϊ��,Ѱ������Ȩ�ز��������ָ���Ϊ��ʧ����(loss function)�������ʧ��������ʹ�����⺯��,��һ�����������������������ȡ�
֮ǰ���������ᵽ��Ϊʲô�����á�ȷ�ʡ�������ָ��,��Ϊ��ȷ�ʡ�����ɢ��,��������,û�а취ʹ���ݶ���Ѱ������Ȩ�ز�����
��ʧ�����DZ�ʾ���������ܵġ����ӳ̶ȡ���ָ��,����ǰ��������Լල�����ڶ��̶��ϲ����,�ڶ��̶��ϲ�һ����
MSE�������
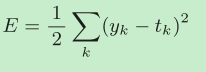
yk�DZ�ʾ����������,tk��ʾ�ල����,k��ʾ���ݵ�ά����
���������
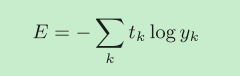
yk������������,tk����ȷ���ǩ������,tk��ֻ����ȷ���ǩ������Ϊ1,������Ϊ0,Ҳ���ǽ��������ȱ���(one-hot encoding)��
softmax������
�����غ�����softmax�������������һ��ʹ��,��ΪSoftmax-with-Loss��
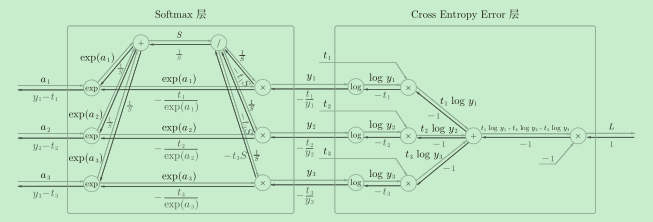
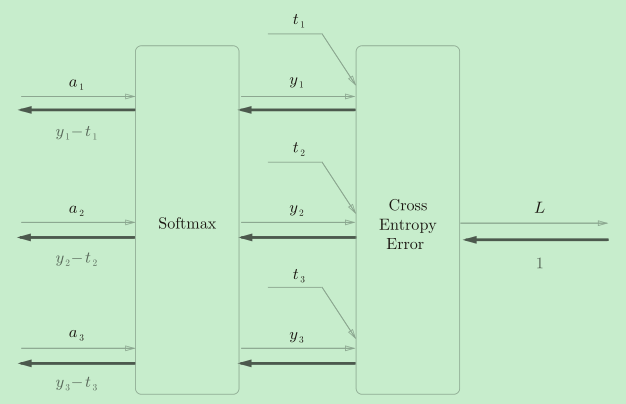
����һ�����,�ͻ���֡�ħ�������Ч��:���Կ���,Softmax��ķ����õ���(y1?t1, y2?t2, y3?t3)������Ư�����Ľ��,��Ҳ��softmax������ν�ġ����ŵ���ѧ���ԡ�����tensorflow����,һ��Ҳ�Ƽ�ʹ��ͳһ�Ľӿ�,�����ǵ���ʹ��Softmax�����뽻������ʧ������
softmax�����صļ���ͼ�Ƶ�����
](https://img-blog.csdnimg.cn/img_convert/62bf4bec7ba506ce84934cdf9f213335.png)
softmax�����صļ���ͼ�Ƶ�����
